docker和K8S环境xxl-job定时任务不执行问题总结
文章目录
- xxl-job 任务调度原理
- 1 问题1 时区导致的任务没有执行的问题
- 解决方案
- 2 执行器注册和下线导致的问题(IP问题)
- 解决方案
- 3 问题3 `调度成功,但是执行器的定时任务未执行`
- 4 问题4 数据库性能问题,导致查询任务和操作日志数据卡主
- 解决方案
- 5. 问题5 定时任务方法中有事务,
xxl-job 任务调度原理
任务调度的详细原理主要包括以下几个步骤:
-
Cron表达式解析: Cron表达式是一种用于配置定时任务的表达式,它描述了一个定时规则。这个规则会被调度中心解析并生成具体的触发时间。
-
触发时间监控: 调度中心会实时监控当前时间,一旦当前时间达到了Cron表达式解析出的触发时间,就会开始进行任务调度。
-
任务参数获取: 调度中心调度任务时,首先会从数据库或内存中获取需要调度的任务的信息,包括任务类型、执行参数、执行器地址等。
-
任务路由策略选择: 根据预设的任务路由策略,调度中心会选择一个或多个执行器进行任务调度。路由策略可能是轮询、随机、一致性哈希、最少负载等。
-
执行器调度: 调度中心根据选择的执行器地址,通过RPC(远程过程调用)或者HTTP请求将任务调度请求发送到执行器。
-
调度日志记录: 调度中心在完成任务调度后,会记录任务调度日志,包括调度时间、执行器地址、任务参数等信息,以便后续分析和排查问题。
-
调度结果反馈: 执行器在接收到任务调度请求后,会立即返回一个调度结果给调度中心,调度中心根据这个结果更新任务调度日志。
1 问题1 时区导致的任务没有执行的问题
这个是最常见的问题。因为xxl-job 最核心的是通过时间计算获得下次任务执行的时间点,然后通过内置线程检查进行调度。
所以时间计算错误和时间点检查不匹配也是不会调度的。还有一种是调度了,执行器实际没有执行。我们后面也会讲到。
XXL-JOB是一种任务调度平台。虽然在配置时可能不需要你直接指定时区,但它实际上是根据服务器的时区设定来执行定时任务的。如果你没有特意去修改服务器的时区,那么它就会使用服务器默认的时区。
所以,你在配置XXL-JOB时实际上是考虑了时区的,只不过你可能并没有显式地去设定它。如果你的服务器在不同的时区,或者你需要调度的任务需要在特定的时区执行,那么你可能需要考虑到时区的影响。
如果需要修改服务器的时区,你可以通过在服务器上执行特定的命令来实现。这通常需要管理员权限。具体的命令可能会因操作系统的不同而不同。
如果你需要在XXL-JOB中设置定时任务在特定的时区执行,你可能需要查看XXL-JOB的文档或者联系其支持人员,看看它是否支持这种设定。
解决方案
将系统时间,数据库时间,容器时间设置统一。
- MySQL数据库时区
show variables like "%time_zone%";
数据库JDBC URL上的设置时区
url=jdbc:mysql://xxxx:3306/dddd?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=GMT%2B8
- 容器内时间设置,这一步要确保宿主机时间的正确
FROM openjdk:8-jre-slim
MAINTAINER xuxueliENV PARAMS=""ENV TZ=PRC
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezoneADD target/xxl-job-admin-*.jar /app.jarENTRYPOINT ["sh","-c","java -jar /app.jar $PARAMS"]
- Java应用程序时区问题
启动jar包添加参数 -Duser.timezone=GMT+08
在Java应用程序中,使用参数-Duser.timezone=GMT+08启动jar包可以设置应用程序的默认时区为GMT+08,也就是东八区(中国标准时间)。
当Java应用程序需要进行日期和时间相关的操作时,它会使用默认的时区来解释和表示日期和时间。默认情况下,Java使用操作系统的默认时区作为应用程序的默认时区。但是,通过使用-Duser.timezone参数,可以覆盖默认的时区设置,使应用程序在运行时使用指定的时区。
2 执行器注册和下线导致的问题(IP问题)
我们先来看执行器的配置
### 调度中心部署根地址 [选填]:如调度中心集群部署存在多个地址则用逗号分隔。执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调";为空则关闭自动注册;
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
### 执行器通讯TOKEN [选填]:非空时启用;
xxl.job.accessToken=
### 执行器AppName [选填]:执行器心跳注册分组依据;为空则关闭自动注册
xxl.job.executor.appname=xxl-job-executor-sample
### 执行器注册 [选填]:优先使用该配置作为注册地址,为空时使用内嵌服务 ”IP:PORT“ 作为注册地址。从而更灵活的支持容器类型执行器动态IP和动态映射端口问题。
xxl.job.executor.address=
### 执行器IP [选填]:默认为空表示自动获取IP,多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯实用;地址信息用于 "执行器注册" 和 "调度中心请求并触发任务";
xxl.job.executor.ip=
### 执行器端口号 [选填]:小于等于0则自动获取;默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口;
xxl.job.executor.port=9999
### 执行器运行日志文件存储磁盘路径 [选填] :需要对该路径拥有读写权限;为空则使用默认路径;
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
### 执行器日志文件保存天数 [选填] : 过期日志自动清理, 限制值大于等于3时生效; 否则, 如-1, 关闭自动清理功能;
xxl.job.executor.logretentiondays=30
这两行配置
-
xxl.job.executor.address=:执行器地址,一般不需要手动配置,系统会自动获取。如果手动配置,那么优先级会比自动获取的方式更高。 -
xxl.job.executor.ip=:执行器IP地址,可以手动配置,如果不配置则系统会自动获取。
这两个配置项的值取决于你的具体需求和实际的服务器情况。如果你的执行器是在本地服务器上,那么可能不需要填写这两个配置项,系统会自动获取。但是如果你的执行器在远程服务器上,那么你可能需要手动配置这两个项,指定执行器的地址和IP。
需要注意的是,通常情况下只需要配置xxl.job.executor.address=即可,因为XXL-JOB执行器会自动获取本机IP地址进行注册和通信。只有在特定需求下才需要同时配置两个地址。
一般容器环境出现问题核心的点就在这个配置上。
导致调度中心服务无法与定时任务执行器进行通信
容器环境的特殊性,在容器环境中,网络是隔离的。因此,容器中的应用程序在默认情况下只能看到容器内部的网络环境。这就导致了一些问题,比如 xxl.job.executor.address 和 xxl.job.executor.ip 配置问题。
无法预知容器的 IP 地址,因为它是在容器启动时动态分配的。这就导致了如果在配置文件中硬编码了这些值,可能会导致调度中心无法和执行器通信。
解决方案
将IP地址xxl.job.executor.ip=或者注册地址xxl.job.executor.address尝试改为k8s服务名,如果夸namespace的话,服务名前带上namespace 如 nsname.service名称
以下只是示例,实际根据你的的serveci命名命名替换
xxl.iob.admin.addresses = http://xxl-job-admin-service:8080/xxl-iob-admin
xxl.job.executor.ip=service名称:端口
xxl.job.executor.address=http://service名称:port/3 问题3 调度成功,但是执行器的定时任务未执行
这个问题最诡异,最坑,还无法快速的定位问题。
我们再聊一下xxl-job执行器执行任务的原理
show you code 然后talk
package com.xxl.job.core.thread;import com.xxl.job.core.biz.model.HandleCallbackParam;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.biz.model.TriggerParam;
import com.xxl.job.core.context.XxlJobContext;
import com.xxl.job.core.executor.XxlJobExecutor;
import com.xxl.job.core.handler.IJobHandler;
import com.xxl.job.core.log.XxlJobFileAppender;
import com.xxl.job.core.log.XxlJobLogger;
import java.io.PrintWriter;
import java.io.StringWriter;
import java.util.Collections;
import java.util.Date;
import java.util.HashSet;
import java.util.Set;
import java.util.concurrent.Callable;
import java.util.concurrent.FutureTask;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.TimeoutException;
import org.slf4j.Logger;
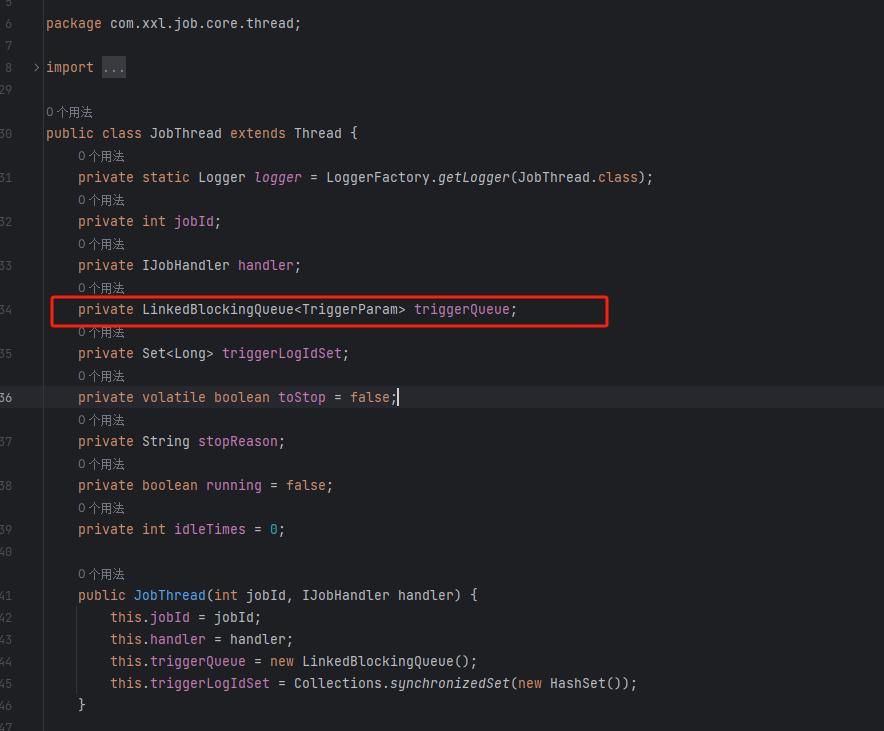
import org.slf4j.LoggerFactory;public class JobThread extends Thread {private static Logger logger = LoggerFactory.getLogger(JobThread.class);private int jobId;private IJobHandler handler;private LinkedBlockingQueue<TriggerParam> triggerQueue;private Set<Long> triggerLogIdSet;private volatile boolean toStop = false;private String stopReason;private boolean running = false;private int idleTimes = 0;public JobThread(int jobId, IJobHandler handler) {this.jobId = jobId;this.handler = handler;this.triggerQueue = new LinkedBlockingQueue();this.triggerLogIdSet = Collections.synchronizedSet(new HashSet());}public IJobHandler getHandler() {return this.handler;}public ReturnT<String> pushTriggerQueue(TriggerParam triggerParam) {if (this.triggerLogIdSet.contains(triggerParam.getLogId())) {logger.info(">>>>>>>>>>> repeate trigger job, logId:{}", triggerParam.getLogId());return new ReturnT(500, "repeate trigger job, logId:" + triggerParam.getLogId());} else {this.triggerLogIdSet.add(triggerParam.getLogId());this.triggerQueue.add(triggerParam);return ReturnT.SUCCESS;}}public void toStop(String stopReason) {this.toStop = true;this.stopReason = stopReason;}public boolean isRunningOrHasQueue() {return this.running || this.triggerQueue.size() > 0;}public void run() {// 尝试初始化处理器try {this.handler.init();} catch (Throwable var26) {// 如果有错误,记录错误日志logger.error(var26.getMessage(), var26);}final TriggerParam triggerParam;ReturnT executeResult;// 当线程没有被要求停止时while(!this.toStop) {this.running = false;++this.idleTimes;triggerParam = null;executeResult = null;boolean var16 = false;ReturnT stopResult;label348: {try {var16 = true;// 从触发队列中获取触发器参数,如果在3秒内获取不到,返回nulltriggerParam = (TriggerParam)this.triggerQueue.poll(3L, TimeUnit.SECONDS);// 如果触发器参数不为空if (triggerParam != null) {this.running = true;this.idleTimes = 0;// 从日志ID集合中移除触发器参数的日志IDthis.triggerLogIdSet.remove(triggerParam.getLogId());// 创建日志文件名称String logFileName = XxlJobFileAppender.makeLogFileName(new Date(triggerParam.getLogDateTime()), triggerParam.getLogId());// 设置XxlJob上下文XxlJobContext.setXxlJobContext(new XxlJobContext(triggerParam.getLogId(), logFileName, triggerParam.getBroadcastIndex(), triggerParam.getBroadcastTotal()));// 记录任务启动日志XxlJobLogger.log("<br>----------- xxl-job job execute start -----------<br>----------- Param:" + triggerParam.getExecutorParams(), new Object[0]);// 如果执行超时时间大于0if (triggerParam.getExecutorTimeout() > 0) {Thread futureThread = null;try {// 创建一个新的任务FutureTask<ReturnT<String>> futureTask = new FutureTask(new Callable<ReturnT<String>>() {public ReturnT<String> call() throws Exception {// 执行处理器return JobThread.this.handler.execute(triggerParam.getExecutorParams());}});// 在新线程中执行任务futureThread = new Thread(futureTask);futureThread.start();// 获取执行结果,如果在指定的超时时间内没有结果,抛出超时异常executeResult = (ReturnT)futureTask.get((long)triggerParam.getExecutorTimeout(), TimeUnit.SECONDS);} catch (TimeoutException var24) {// 记录任务超时日志XxlJobLogger.log("<br>----------- xxl-job job execute timeout", new Object[0]);XxlJobLogger.log(var24);// 设置超时的执行结果executeResult = new ReturnT(IJobHandler.FAIL_TIMEOUT.getCode(), "job execute timeout ");} finally {// 中断线程futureThread.interrupt();}} else {// 如果没有设置超时时间,则直接执行处理器executeResult = this.handler.execute(triggerParam.getExecutorParams());}// 如果执行结果为空if (executeResult == null) {// 设置执行失败的结果executeResult = IJobHandler.FAIL;} else {// 否则,设置执行结果的消息和内容executeResult.setMsg(executeResult != null && executeResult.getMsg() != null && executeResult.getMsg().length() > 50000 ? executeResult.getMsg().substring(0, 50000).concat("...") : executeResult.getMsg());executeResult.setContent((Object)null);}// 记录任务结束日志XxlJobLogger.log("<br>----------- xxl-job job execute end(finish) -----------<br>----------- ReturnT:" + executeResult, new Object[0]);var16 = false;} else if (this.idleTimes > 30) {// 如果连续30次都没有获取到触发器参数if (this.triggerQueue.size() == 0) {// 如果触发队列为空,则移除Job线程XxlJobExecutor.removeJobThread(this.jobId, "executor idle times over limit.");var16 = false;} else {var16 = false;}} else {var16 = false;}break label348;} catch (Throwable var27) {// 如果在执行过程中抛出异常if (this.toStop) {// 如果被要求停止,记录停止原因XxlJobLogger.log("<br>----------- JobThread toStop, stopReason:" + this.stopReason, new Object[0]);}// 获取异常信息StringWriter stringWriter = new StringWriter();var27.printStackTrace(new PrintWriter(stringWriter));String errorMsg = stringWriter.toString();// 设置执行结果为异常信息executeResult = new ReturnT(500, errorMsg);// 记录任务异常日志XxlJobLogger.log("<br>----------- JobThread Exception:" + errorMsg + "<br>----------- xxl-job job execute end(error) -----------", new Object[0]);var16 = false;} finally {if (var16) {// 如果触发器参数不为空if (triggerParam != null) {if (!this.toStop) {// 如果没有被要求停止,向回调队列中推送回调参数TriggerCallbackThread.pushCallBack(new HandleCallbackParam(triggerParam.getLogId(), triggerParam.getLogDateTime(), executeResult));} else {// 如果被要求停止,设置停止结果,并向回调队列中推送回调参数ReturnT<String> stopResult = new ReturnT(500, this.stopReason + " [job running, killed]");TriggerCallbackThread.pushCallBack(new HandleCallbackParam(triggerParam.getLogId(), triggerParam.getLogDateTime(), stopResult));}}}}// 如果触发器参数不为空if (triggerParam != null) {if (!this.toStop) {// 如果没有被要求停止,向回调队列中推送回调参数TriggerCallbackThread.pushCallBack(new HandleCallbackParam(triggerParam.getLogId(), triggerParam.getLogDateTime(), executeResult));} else {// 如果被要求停止,设置停止结果,并向回调队列中推送回调参数stopResult = new ReturnT(500, this.stopReason + " [job running, killed]");TriggerCallbackThread.pushCallBack(new HandleCallbackParam(triggerParam.getLogId(), triggerParam.getLogDateTime(), stopResult));}}continue;}// 如果触发队列不为空,且队列中还有元素while(this.triggerQueue != null && this.triggerQueue.size() > 0) {// 从队列中获取触发器参数triggerParam = (TriggerParam)this.triggerQueue.poll();// 如果触发器参数不为空if (triggerParam != null) {// 设置未执行的结果,并向回调队列中推送回调参数executeResult = new ReturnT(500, this.stopReason + " [job not executed, in the job queue, killed.]");TriggerCallbackThread.pushCallBack(new HandleCallbackParam(triggerParam.getLogId(), triggerParam.getLogDateTime(), executeResult));}}// 尝试销毁处理器try {this.handler.destroy();} catch (Throwable var23) {// 如果有错误,记录错误日志logger.error(var23.getMessage(), var23);}// 记录线程停止日志logger.info(">>>>>>>>>>> xxl-job JobThread stoped, hashCode:{}", Thread.currentThread());}
}
单从源码我们分析 JobThread 类源码的关键操作
-
pushTriggerQueue方法:该方法用于将任务触发器参数(TriggerParam)添加到任务队列(triggerQueue)中。如果队列中已经存在相同的日志ID,那么这个新的任务触发器就不会被添加。否则,将会添加到该队列中。 -
run方法
开始一个持续运行的循环
在循环中,尝试从触发队列中获取一个触发参数 (triggerParam),如果在3秒内没有获取到,返回null。
如果获取到触发参数:
- 将此线程标记为运行状态。
- 从日志ID集合中移除该触发参数的日志ID。
- 设置XxlJob的上下文。
- 记录任务开始执行的日志。
- 如果设置了执行超时时间,将在新线程中执行处理器,如果超过指定的超时时间仍未获取到结果,将记录任务超时日志,并设置超时的执行结果。
- 如果没有设置超时时间,直接执行处理器。
- 根据执行结果是否为空,设置相应的执行结果信息。
- 记录任务结束日志。
如果连续30次都没有获取到触发参数,且触发队列为空,将移除该Job线程。
总结一下就是任务调度和任务执行依靠队列 triggerQueue,这个是参数队列,调度直接往这个队列里面put参数对象。执行依靠是JobThread run方法,从队列中获取参数对象,能获取就执行,任务和线程是一一绑定的关系,调度成功,但没有结果回调。
所以核心的排查问题方法是我们要知道这个队列中还有多少个任务对象虽然已经被调度到任务队列但是没有被执行。
里面放到的对象为这个
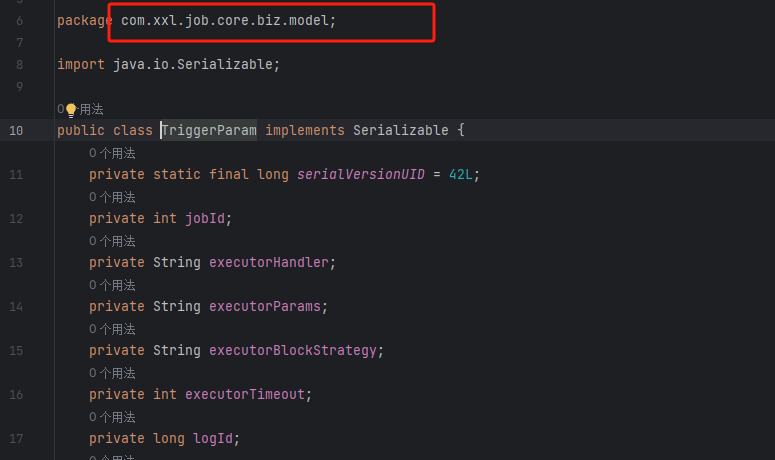
所以我们只需要看下这个容器
jmap -histo 进程ID | grep “com.xxl.job.core.biz.model.TriggerParam”
获取到有多少任务在等待。我们就能判断是不是卡在执行任务当中handler.execute();
这就是这个问题的排查思路。希望能帮助到大家。
4 问题4 数据库性能问题,导致查询任务和操作日志数据卡主
表:XXL_JOB_QRTZ_TRIGGER_LOG 约有 16.5 GB
执行
DELETE FROM XXL_JOB_QRTZ_TRIGGER_LOG WHERE trigger_time >= ‘2021-12-17 00:18:59’ AND trigger_time <= ‘2021-12-18 23:59:20’;
操作可能导致数据库 死锁或者CPU夯住了,导致 0 时执行的任务,没有执行成功。
它的主要功能是进行任务管理和调度。它在数据库中维护了一系列的日志和状态信息,以确保任务能够正确地调度和执行。在某些情况下,为了维护系统的性能和稳定性,可能会需要清理一些旧的,不再需要的数据。
DELETE FROM XXL_JOB_QRTZ_TRIGGER_LOG WHERE trigger_time >= ‘2021-12-17 00:18:59’ AND trigger_time <= ‘2021-12-18 23:59:20’;
这个操作是在XXL-JOB的任务调度日志表(XXL_JOB_QRTZ_TRIGGER_LOG)中删除特定时间范围内的日志记录。 为了进行日志清理,以释放存储空间和保持数据库性能。大量的删除操作可能会对数据库性能产生影响,尤其是在高并发或者大数据量的情况下。因此,这种操作通常需要在数据库的低峰期进行,并可能需要使用分批删除等技术以减少对数据库性能的影响。
解决方案
建议任务调度服务中的 XXL_JOB_QRTZ_TRIGGER_LOG 这张表保留最近一周的日志量,在业务低峰期定时执行脚本。
5. 问题5 定时任务方法中有事务,
事务的提交是当前方法结束 。由于任务执行时间很长,导致后续任务到达执行时间无法执行,甚至长事务导致其他服务性能问题引发连锁反应。
相关文章:
docker和K8S环境xxl-job定时任务不执行问题总结
文章目录 xxl-job 任务调度原理1 问题1 时区导致的任务没有执行的问题解决方案 2 执行器注册和下线导致的问题(IP问题)解决方案 3 问题3 调度成功,但是执行器的定时任务未执行4 问题4 数据库性能问题,导致查询任务和操作日志数据卡…...
)
【Leetcode】218.天际线问题(Hard)
一、题目 1、题目描述 城市的 天际线 是从远处观看该城市中所有建筑物形成的轮廓的外部轮廓。给你所有建筑物的位置和高度,请返回 由这些建筑物形成的 天际线 。 每个建筑物的几何信息由数组 buildings 表示,其中三元组 buildings[i] = [lefti, righti, heighti] 表示: l…...

try catch finally代码块的作用
try-catch-finally 代码块是用于处理程序中可能发生的异常情况的一种结构。它的作用在于: try 代码块中的代码用于包含可能会引发异常的代码。catch 代码块用于捕获并处理 try 代码块中抛出的异常。可以通过 catch 代码块中的逻辑来处理异常,如打印错误…...
【Sentinel】Sentinel簇点链路的形成
说明 一切节点的跟是 machine-root,同一个资源在不同链路会创建多个DefaultNode,但是在全局只会创建一个 ClusterNode machine-root/\/ \EntranceNode1 EntranceNode2/ \/ \DefaultNode(nodeA) DefaultNode(nodeA)|…...

Elasticsearch之mapping
文章目录 以显式的方式创建一个映射查看某个具体索引的mapping定义向已存在的映射中添加一个新的属性查看映射中指定字段的定义信息更新已存在映射的某个字段 1、 官方文档地址 2、 字段类型 1、定义:映射是定义文档及其包含的字段如何存储和索引的过程。 2、每个…...

6、PostgreSQL 数据类型之一:数字类型和货币类型
PostgreSQL 作为一个强大的开源关系型数据库管理系统,本身支持多种数据类型,包括标准 SQL 数据类型以及一些扩展数据类型。 PostgreSQL 支持多种数据类型的设计理念是为了满足不同应用场景的需求,提供更大的灵活性和数据处理能力。原因如下&…...

计算机视觉与深度学习 | 基于点线融合的视觉惯性SLAM前端
===================================================== github:[https://github.com/MichaelBeechan] CSDN:[https://blog.csdn.net/u011344545] ===================================================== 引言 本文中将介绍视觉惯性SLAM的前端部分,首先是传感器数据处理…...
MDK与keilC51共存的方法
MDK与keilC51共存的方法 在网上搜的资料MDK与KeilC51安装顺序都搞反了,而且大家都没成功过,反倒是转发了很多错误的教程。 用此安装方法解决了MDK与KeilC51的共存问题。所有功能完美运行。 因为MDK功能比KeilC51多,所以要先安装KeilC51 1、先…...

c_指针
文章目录 *(p1)1表示第 1 行第 1 个元素的地址。如何理解呢?下标运算符的规则括号 int a; // 1.一个整数 int *a; // 2.一个指向整数的指针 int **a; // 3.一个指向指针的指针, 它所指向的指针又指向一个整数型数据 ;一个指向 …...

循环队列c语言版
一、循环队列结构体 typedef int QueueDataType; #define CQ_MAX_SIZE 10typedef struct CircularQueue {QueueDataType data[CQ_MAX_SIZE];/**标记队列首*/QueueDataType head;/**标记队列尾部*/QueueDataType rear;} CircularQueue; 二、循环队列操作函数声明 /**创建队…...

SprringMVC拦截器
1、拦截器的配置 SpringMVC中的拦截器用于拦截控制器方法的执行 SpringMVC中的拦截器需要实现HandlerInterceptor SpringMVC的拦截器必须在SpringMVC的配置文件中进行配置: <bean class"com.test.interceptor.FirstInterceptor"></bean> …...

redis的实际使用
Redis是一种内存数据库,常用于缓存、会话管理、消息队列等。在项目中合理使用Redis可以提高系统性能和可扩展性。以下是一些使用Redis的建议: 1. 缓存常用数据:将经常使用的数据缓存在Redis中,以减少数据库的读取次数,…...
230102)
造车先做三蹦子-之二:自制数据集(5x5数据集)230102
#Jupyter Notebook231001import torch import torch.nn as nn import torch.optim as optim# 定义模型 class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.fc1 = nn.Linear(25, 50)self.fc2 = nn.Linear(50, 6)def forward(self, x):x = x.view(-1, 25…...

JS操作DOM及CSS
JS创造于1994年,其目的是为浏览器显示的文档赋予动态行为。 1 Web编程基础 本节讲解如何编写Web应用中的js程序,如果将这些程序加载到浏览器,以及如何获取输入、产出输出,如何运行响应事件的异步代码。 1.1 js 脚本 虽然现在不…...

Linux内核VFS详解
Linux内核VFS是什么? Linux内核VFS(Virtual File System)是Linux操作系统中的一个关键组件,用于提供文件系统抽象层。它允许用户空间和内核空间的各个部分以一种一致的方式访问不同类型的文件系统,包括磁盘文件系统(如EXT4、XFS、NTFS)、网络文件系统(如NFS、CIFS)、…...

在自己的服务器上部署个人博客和开源项目:实现数字存在感
在数字时代,拥有自己的服务器不再是一项难以实现的任务。通过云计算和开源技术的广泛应用,个人可以轻松地拥有自己的服务器,并在其上部署个人博客以及开源项目,为自己在互联网上创造一个数字存在感。本文将介绍如何在自己的服务器…...

【AI视野·今日Robot 机器人论文速览 第五十九期】Fri, 20 Oct 2023
AI视野今日CS.Robotics 机器人学论文速览 Fri, 20 Oct 2023 Totally 29 papers 👉上期速览✈更多精彩请移步主页 Daily Robotics Papers CCIL: Continuity-based Data Augmentation for Corrective Imitation Learning Authors Liyiming Ke, Yunchu Zhang, Abhay D…...

Chromium浏览器启动参数
文章目录 Chromium浏览器启动参数1. --disable-web-security2. --disable-gpu3. --incognito4. --no-sandbox5. --disable-infobars6. --disable-notifications7. --disable-extensions8. --disable-translate9. --disable-popup-blocking10. --remote-debugging-port=<port…...

【计算机视觉】MoCo v3 讲解
MoCo v3 论文信息 标题:An Empirical Study of Training Self-Supervised Vision Transformers 作者:Xinlei Chen, Saining Xie, Kaiming He 期刊:ICCV 2021 发布时间与更新时间:2021.04.05 2021.04.08 2021.05.05 2021.08.16 主题:计算机视觉、对比学习、MoCo arXiv:[21…...

MySQL - 对字符串字段创建索引
在数据库中,对字符串字段创建索引可以加速字符串字段的查询: 直接创建完整索引:这是最简单的方式,直接对整个字符串字段创建索引。这种方式占用的空间较大,但查询性能通常较好,特别是在精确匹配的情况下。…...

MIPI CSI调试实战:从时序不稳到稳定传输,我调了这三个关键点
MIPI CSI调试实战:从时序不稳到稳定传输的三大关键突破 调试MIPI CSI接口就像在解一道复杂的物理方程,每一个变量都可能成为图像花屏或数据丢包的罪魁祸首。去年在为一款工业摄像头模组开发驱动时,我遇到了令人抓狂的随机性图像撕裂问题——在…...

技术从业者的情绪管理:如何应对工作压力和职业焦虑
一、软件测试从业者的情绪困境:压力源与焦虑画像在敏捷开发与DevOps模式深度普及的今天,软件测试早已不是传统意义上的“事后把关”,而是贯穿需求分析、代码开发、上线运维全流程的质量核心环节。这种角色转变,也让测试从业者面临…...

STM32 HAL库实战:用CD74HC4067扩展模拟输入通道,附完整工程代码
STM32 HAL库实战:用CD74HC4067扩展模拟输入通道,附完整工程代码 在嵌入式开发中,模拟信号采集是常见需求,但MCU内置ADC通道数量往往有限。当面对多路传感器信号采集时,如何经济高效地扩展输入通道成为开发者必须解决的…...

慢时钟域到快时钟域控制信号传递:原理、方案与实战
1. 控制信号跨时钟域传递:一个资深工程师的实战拆解在数字电路设计里,尤其是涉及多时钟域的复杂系统,比如SoC、高速接口或者异构计算单元,控制信号的跨时钟域传递(CDC, Clock Domain Crossing)绝…...

XNBCLI终极指南:如何轻松解包打包星露谷物语XNB文件
XNBCLI终极指南:如何轻松解包打包星露谷物语XNB文件 【免费下载链接】xnbcli A CLI tool for XNB packing/unpacking purpose built for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/xn/xnbcli 想要深度定制星露谷物语游戏体验吗?…...

GD32C103RBT6 I2C 驱动全解析
一、I2C 通信基础概述 1. I2C 硬件接口 GD32C10x 提供 I2C0、I2C1 两组硬件 I2C: SCL:串行时钟线(由主机产生) SDA:串行数据线 需外接 上拉电阻(4.7kΩ 经典值) 支持 多主机、多从机 2. 通信模式 主机模式:MCU 主动发起通信(最常用) 从机模式:MCU 被其他主机访问 …...

Solidworks 2018+ 机器人模型避坑指南:用SW2URDF插件导出URDF,再导入Webots R2023a完整流程
SolidWorks 2018机器人模型导入Webots全流程避坑指南 在机器人仿真领域,将SolidWorks设计的机械模型准确导入Webots仿真环境是一个关键但充满挑战的环节。许多工程师和学生在初次尝试这一流程时,往往会在版本兼容性、文件路径、坐标系设置等环节遭遇各种…...

从‘看到’到‘看懂’:VSRN模型如何像人一样进行视觉语义推理?一个生动的案例拆解
从‘看到’到‘看懂’:VSRN模型如何像人一样进行视觉语义推理?一个生动的案例拆解 想象这样一个场景:你看到一张照片,画面中一只棕色的狗在绿色的草地上追逐飞盘。几乎瞬间,你的大脑就完成了从视觉感知到语义理解的完整…...

GoogleTest 使用指南 | 测试模板函数
GoogleTest 使用指南 | 测试模板函数GoogleTest 使用指南 | 测试模板函数GoogleTest 使用指南 | 测试模板函数 模板类和函数由于其泛型特性,需要在不同类型下进行测试,以确保其通用性和正确性。 下面是一个示例。 m…...

立模框架三维扫描检测:构建装配式生产装备的数字化精度基准
在建筑工业化与智能建造协同发展的浪潮中,装配式建筑已成为行业转型升级的主旋律。作为PC构件生产的核心工装,立模框架的几何精度直接决定了预制墙板、叠合梁柱等构件的成型质量,进而影响施工现场的装配效率与结构安全。图片来源网络…...