FoLR:Focus on Local Regions for Query-based Object Detection论文学习笔记
论文地址:https://arxiv.org/abs/2310.06470
自从DETR问询式检测器首次亮相以来,基于查询的方法在目标检测中引起了广泛关注。然而,这些方法面临着收敛速度慢和性能亚优等挑战。值得注意的是,在目标检测中,自注意力机制经常因其全局聚焦而妨碍了收敛。为了解决这些问题,作者提出了FoLR,一种仅包含解码器的类似Transformer的架构。作者通过隔离不相关目标之间的连接来增强自注意力机制,使其聚焦于局部区域而不是全局区域。作者还设计了自适应采样方法,从特征图中基于查询的局部区域提取有效特征。此外,作者采用了一种解码器的回溯策略,以保留先前的信息,然后使用特征混合器模块来融合特征和查询。实验结果表明,FoLR在基于查询的检测器中表现出卓越的性能,具有卓越的收敛速度和计算效率。
1. INTRODUCTION
通用目标检测旨在定位和分类图像中的现有目标,并使用矩形边界框对它们进行标记以显示存在的置信度。这些方法的框架主要可以分为两种类型:一阶段方法,如SSD和YOLO,以及多阶段检测器,如Faster R-CNN。最近,基于Transformer的目标检测器引起了关注,DETR引入了Transformer的编码器-解码器模块到目标检测中。与传统检测器不同,DETR消除了对Anchor Box设计的需求,依赖于一组可学习的向量,称为目标查询,用于检测。然而,DETR在收敛速度慢和性能问题方面面临挑战。具体来说,在COCO 2017数据集上取得与以前检测器相媲美的结果需要DETR训练超过500个Epoch,而Faster R-CNN通常只需要12个Epoch。
为了应对这一挑战,一些研究已经提出了解决这些问题的方法。然而,这些方法往往引入了大量的额外参数,增加了网络的大小,显著提高了训练成本。因此,在收敛速度和计算复杂性之间取得适当平衡仍然是一个挑战。此外,包含全局信息的注意力机制可以快速建立不相关目标之间的关联,对算法的收敛产生负面影响。这促使作者对全局信息的注意力机制进行了研究和增强。
在本文中,作者提出了FoLR,这是一种旨在解决上述挑战的新型基于查询的检测器。总之,作者的工作做出了以下贡献:
-
引入FoLR,这是一种新型的基于查询的目标检测方法,具有简化的解码器架构,可以增强自注意力与局部区域的交互。
-
设计和实现了Feature Mixer模块和基于DCN的自适应采样方法,以增强特征和查询之间的交互。此外,作者采用“回顾”策略来保留在先前阶段生成的数据。
-
通过在COCO数据集上的实验结果展示了FoLR的卓越性能,它有效地克服了传统方法在收敛速度缓慢和计算成本高的限制。
2. RELATED WORK
这部分跳过......
3. METHOD
3.1. Overview
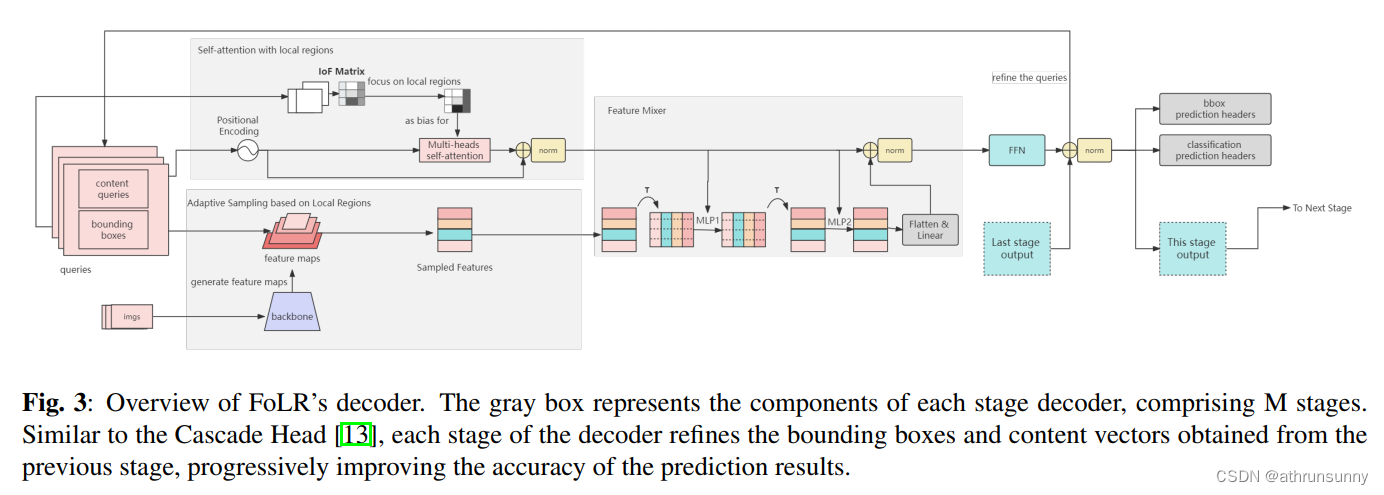
在本节中,作者详细介绍了作者的基于查询的检测器FoLR。FoLR是一个完全的解码器架构,包括以下几个关键组件:
-
带有局部区域的自注意力:该模块增强了查询的描述能力,代表目标的位置和语义信息。同时,它旨在减轻不相关查询之间的负面关系。
-
自适应采样方法(ASM):它有助于根据查询的位置从多尺度特征图中自适应地采样特征。
-
特征混合器:该组件促进了在ASM中采样的特征与查询之间的互动,实现了有效的信息融合。
-
预测Head:这些Head负责完成分类和回归任务。
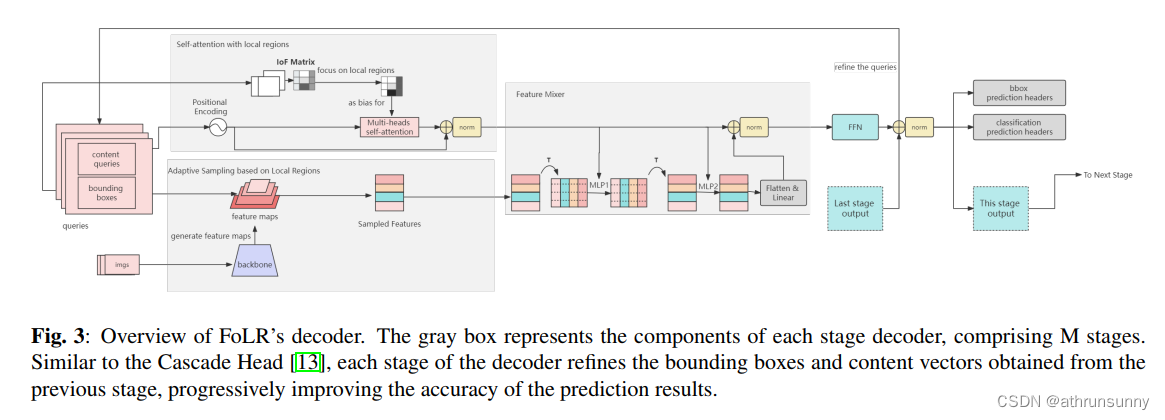
这些组件的相互作用塑造了FoLR的整体架构,赋予其有效提取特征和检测目标的能力。架构的视觉表示如图3所示。此外,FoLR采用了受Cascade R-CNN启发的多阶段细化策略。查询向量可以在每个后续阶段迭代地进行细化,以增强目标检测的准确性,如图2所示。

解耦分类和定位 在本文提出的方法中,作者利用了查询的概念,它合并了每个目标的语义和位置信息,就像Sparse RCNN等基于Transformer的算法中所看到的那样。先前的研究表明,将查询分解为这两个向量显著提高了模型的识别效率。作者通过将查询分解为两个不同的向量来扩展这种方法:内容向量(content vector)和边界框向量(bounding box vector)。
损失 模型的损失,采用DETR方法计算,包括用于预测分类的Focal Loss(),用于预测框坐标的L1损失(
)和GIoU(
)。总损失如下:
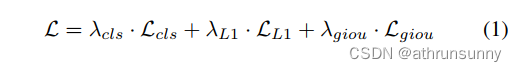
3.2. Self-Attention with Local Regions
自注意力是Transformer样式方法中常用的机制,用于增强查询的描述能力。它有助于在序列内建立关系。在目标检测任务中,自注意力增强了每个查询与其他查询之间的连接,增强了内容向量的描述能力。然而,作者的研究发现,这种具有全局焦点的注意力机制甚至建立了不相关查询之间的连接,如图1所示。这阻碍了检测任务,对模型产生了负面影响。

为了使模型能够识别和屏蔽负面连接,作者鼓励自注意力集中在局部区域。首先,作者使用方程2计算每个查询与其他查询之间的IoF(帧交集 (Intersection of Frame))矩阵。如果矩阵元素的值低于指定的阈值ε,作者将其替换为一个较大的负数。这表示该信息对于自注意力是有害的,应在后续操作中排除。
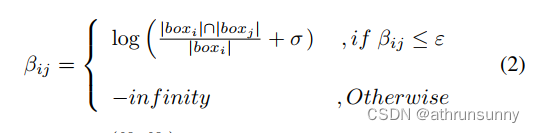
其中,由
和
索引,
是查询的数量,σ是一个设置为
的小常数,ε是从间隔[0,1]中取的一个常数。
3.3. Extract Multi-Scale Features
为了增强每个查询的有效性,从每个输入图像的Backbone生成的有意义和丰富的特征是至关重要的。在本节中,作者介绍了一种受可变卷积网络启发的自适应采样方法来提取特征。
Adaptive Sampling Method (ASM) 给定第i个边界框,作者使用以下方程来生成第个对应的采样点:

其中,Q代表内容向量。和
表示第j个采样点相对于第i个边界框的中心点
的偏移,
和
分别表示第
个边界框的宽度和高度。
Focus on Local Regions.
现在作者已经在特征图上获得了采样点,Sparse RCNN和AdaMixer的下一步涉及与查询交互地融合这些采样点。然而,作者认为以这种方式收集的特征是从特征图派生的,而不是从查询派生的。
与DETR的解码器在目标查询上应用位置编码类似,作者的方法旨在改进收集的采样点,以更好地与查询集成。在这里,作者使用线性层生成的一组参数来增强采样点:
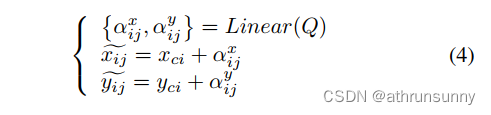
在作者的方法中,作者采用双线性插值方法来处理采样点的小数坐标。此外,作者采用了类似于自注意力中使用的多头机制的策略,以增强采样点的多样性。
具体来说,作者将特征图的维度,表示为d,分成个Head,其中每个头分配
个维度。这种划分确保每个头捕捉到特征的不同方面。对于本研究,作者保持d = 256和
= 4。
实际上,作者在每个特征图级别的每个查询中生成个采样点,总共产生了LN个采样点。然而,不同查询生成的采样点或不同特征图中相同查询生成的采样点不应具有相同的重要性。作者为第
个查询分配自适应和可学习的权重,权重方法如下:

在这里,S表示每个查询对应的边界框面积,计算为其宽度和高度的乘积。形状为的
表示每个查询在特征图的L个级别上的权重。
3.4. Feature Mixer
采样的多尺度特征与内容向量之间的相互作用在目标检测中至关重要。受MLPmixer和AdaMixer的启发,作者引入了Feature Mixer,一个MLP模块,用于增强这种交互作用。按照MLPmixer的方法,作者使用内容查询来训练两个MLP网络,用于混合采样特征的最后两个维度。然后将结果转换成内容查询的形状,并将其添加到内容查询中,如图3所示。
在作者的设计中,作者在每个查询和采样特征之间建立了直接连接,确保每个采样特征与其相应的查询进行交互。这个过程消除了无效的bins,生成了最终的目标特征。为了保持轻量级设计,作者使用两个连续的1×1卷积和GELU激活函数进行交互。这些卷积的参数是从相应的内容向量生成的。
4. EXPERIMENTS
4.3. Main Result
最终的结果如表1所示。值得注意的是,FoLR在平均精度(AP)方面优于密集检测器,使用ResNet-50和ResNet-101Backbone分别获得42.6 AP(与40.3 AP相比)和43.5 AP(与42.0 AP相比)。
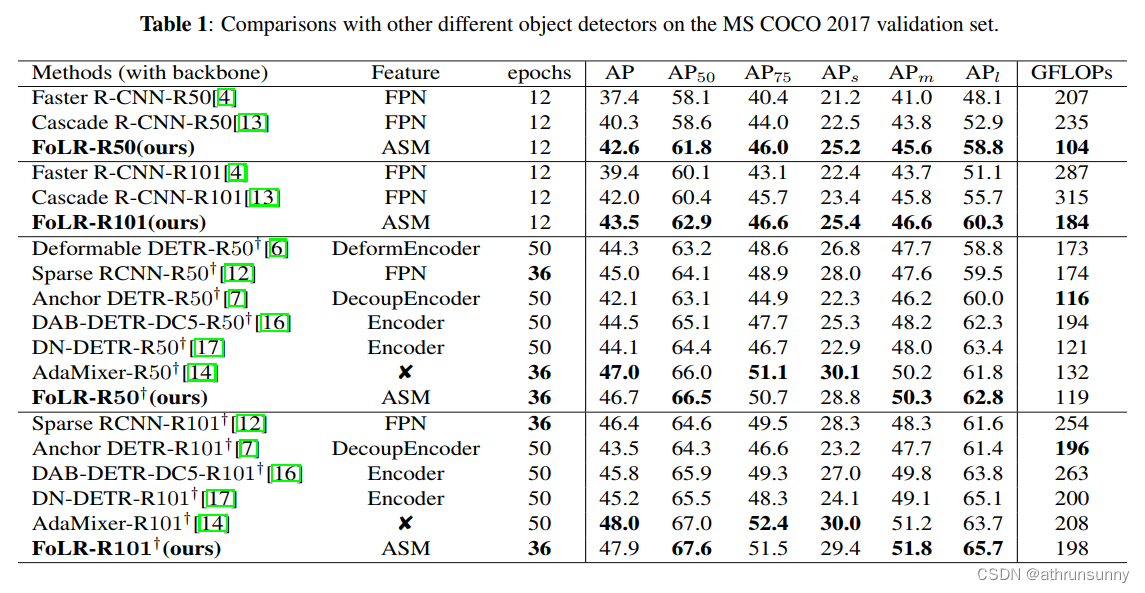
此外,FoLR在基于查询的检测器中获得了相对较高的分数,分别使用ResNet-50和ResNet-101Backbone达到46.7 AP和47.7 AP。此外,FoLR在其他指标(包括小目标准确性和计算成本)方面也表现出色。这些结果提供了有力的证据,表明FoLR在复杂性和性能之间有效地取得了平衡。
表2对比了FoLR和COCO 2017测试开发数据集上其他方法的结果。在使用ResNet-50和ResNet-101作为Backbone时,FoLR分别获得了47.2和48.1的AP分数。这些显著的结果进一步证明了FoLR的卓越性能也可以扩展和适应其他数据集。

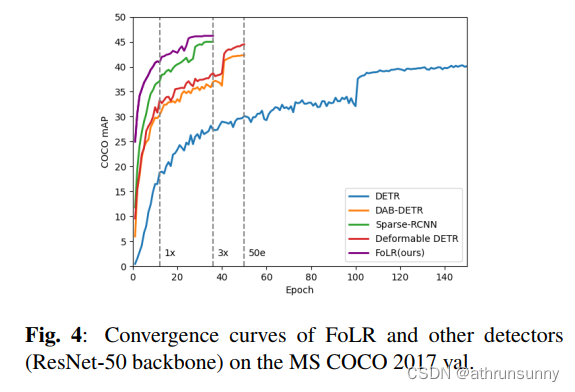
此外,如图4所示,作者通过与其他基于查询的检测器进行比较,全面分析了FoLR的收敛速度。结果清楚地表明,FoLR在训练的各个阶段都在收敛速度方面优于基于查询的检测器。具体而言,FoLR在使用更短的36个时期的training schedule时,实现了卓越的准确性,达到了46.7 AP(相对于可变形DETR的44.5 AP)。
4.4. Ablation Studies
在这里,作者还进行了消融实验,以评估FoLR中模块的有效性。由于计算约束,作者对这些实验使用了ResNet-50Backbone和1×training schedule。
Design of Attention with Local Regions. 作者进行了额外的实验,验证了FoLR方法中注意力模块的有效性。不同的ε值表示对局部区域的关注程度不同。具体来说,当ε=0时,意味着不应用局部区域策略。同时,作者在不同阶段的解码器中分配了不同的ε值。作者观察到,在最后三个阶段,ε分别为0.01、0.1和0.2时,算法显示出0.5 AP的提高。结果如表3所示。
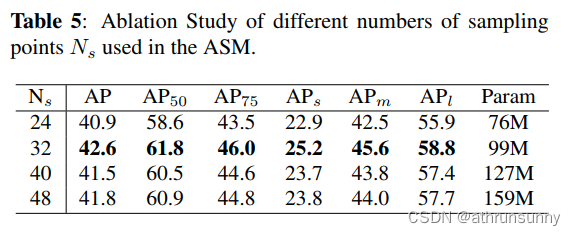
Design of Adaptive Sampling Method. 作者还比较了着重关注局部区域策略与不使用此策略的结果。表4中的结果表明,着重关注局部区域策略提高了0.7 AP的性能。同时,的选择影响了FoLR的收敛速度和所需的计算资源。为了在性能和计算负荷之间取得平衡,作者在[24, 48]范围内以8为步长进行了不同
值的实验。表5中的结果表明,
=32可以在性能和计算负载之间取得良好的平衡。
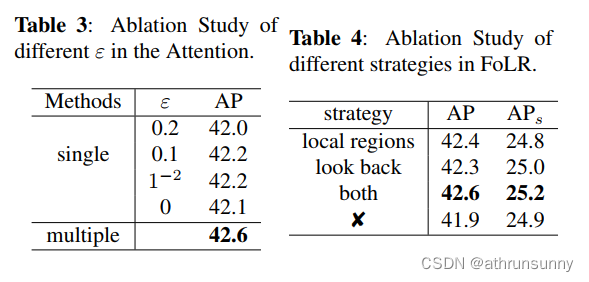
Look-Back Strategy Validation. 图4中的实验结果表明,使用回溯策略相对于没有回溯策略,准确性提高了0.4 AP。
相关文章:
FoLR:Focus on Local Regions for Query-based Object Detection论文学习笔记
论文地址:https://arxiv.org/abs/2310.06470 自从DETR问询式检测器首次亮相以来,基于查询的方法在目标检测中引起了广泛关注。然而,这些方法面临着收敛速度慢和性能亚优等挑战。值得注意的是,在目标检测中,自注意力机制…...
【QT开发(15)】QT在没有桌面的系统中可以使用
在没有桌面的系统中,可以使用QT库。QT库可以在没有图形用户界面(GUI)的环境中运行,例如在服务器或命令行终端中。 这样就可利用Qt的: 对象模型,信号和槽容器类多线程和多进程网络编程 等...

『heqingchun-Qt的艺术-优雅界面设计开发』
Qt的艺术-优雅界面设计开发 效果图 一、新建Qt窗口工程 二、准备资源文件 1.图标资源 链接: 图标资源 2.Qss资源 链接: Qss资源 三、设计开发 项目源码链接: CSDN资源...

webGL编程指南 第四章 平移+旋转.RotatdTanslatedTriangle.html
我会持续更新关于wegl的编程指南中的代码。 当前的代码不会使用书中的缩写,每一步都是会展开写。希望能给后来学习的一些帮助 git代码地址 :git 本篇文章将把旋转和平位移结合起来,因为矩阵的不存在交换法则 文章中设计的矩阵地址在这里…...
使用canvas实现时间轴上滑块的各种常用操作(仅供参考)
一、简介 使用canvas,模拟绘制时间轴区域,有时间刻度标尺,时间轴区域上会有多行,每行都有一个滑块。 1、时间刻度标尺可以拖动,会自动对齐整数点秒数,最小步数为0.1秒。 2、滑块可以自由拖动,…...

Netty优化-扩展自定义协议中的序列化算法
Netty优化-扩展自定义协议中的序列化算法 一. 优化与源码1. 优化1.1 扩展自定义协议中的序列化算法 一. 优化与源码 1. 优化 1.1 扩展自定义协议中的序列化算法 序列化,反序列化主要用在消息正文的转换上 序列化时,需要将 Java 对象变为要传输的数据…...
【Java网络编程】二
本文主要介绍了传输层的UDP协议和TCP协议,以及在Java中如何通过Socket套接字实现网络编程(内附UDP和TCP版本的回显服务器代码) 一.网络通信 网络编程,就是写一个应用程序,让这个程序可以使用网络通信,这里就…...

通过IP地址可以做什么
通过IP地址可以做很多事情,因为它是互联网通信的基础之一。本文将探讨IP地址的定义、用途以及一些可能的应用。 IP地址的用途 1. 设备标识:IP地址用于标识互联网上的每个设备,这包括计算机、服务器、路由器、智能手机等。它类似于我们日常生…...

前端 CSS 经典:clip、clip-path
1. clip 1.1 clip: auto | inherit | rect auto:默认,不裁剪 inherit:继承父级 clip 属性 rect:规则四边形裁剪 1.2 clip: rect(top, right, bottom, left) 注意: 1.裁剪只对 fixed 和 absolute 的元素有效。 2.top&…...
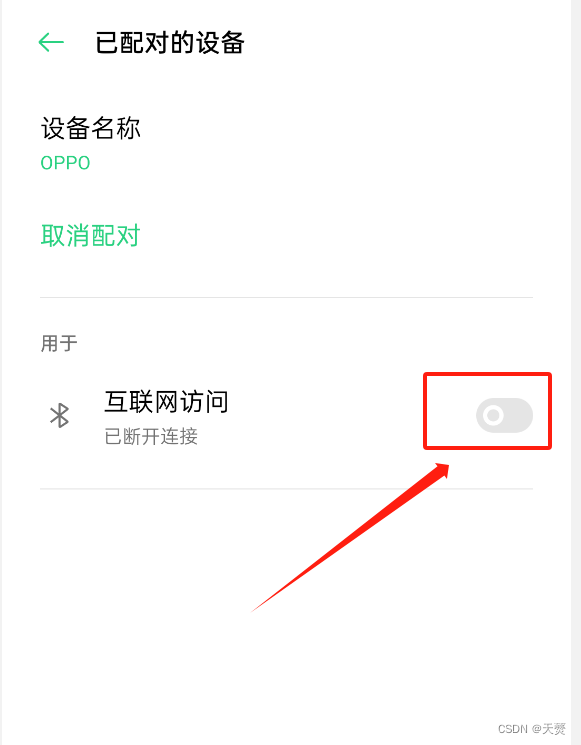
android 如何判断已配对的蓝牙是否打开了互联网访问开关
最近遇到一个需求,要判断已配对的蓝牙是否打开了互联网访问的开关。 经查看源码,得出以下方法。 1. 首先要判断蓝牙是否打开 2. 已打开的蓝牙是否已配对 3. 验证是否真正打开 /*** 是否打开蓝牙互联网访问*/SuppressLint("MissingPermission&quo…...
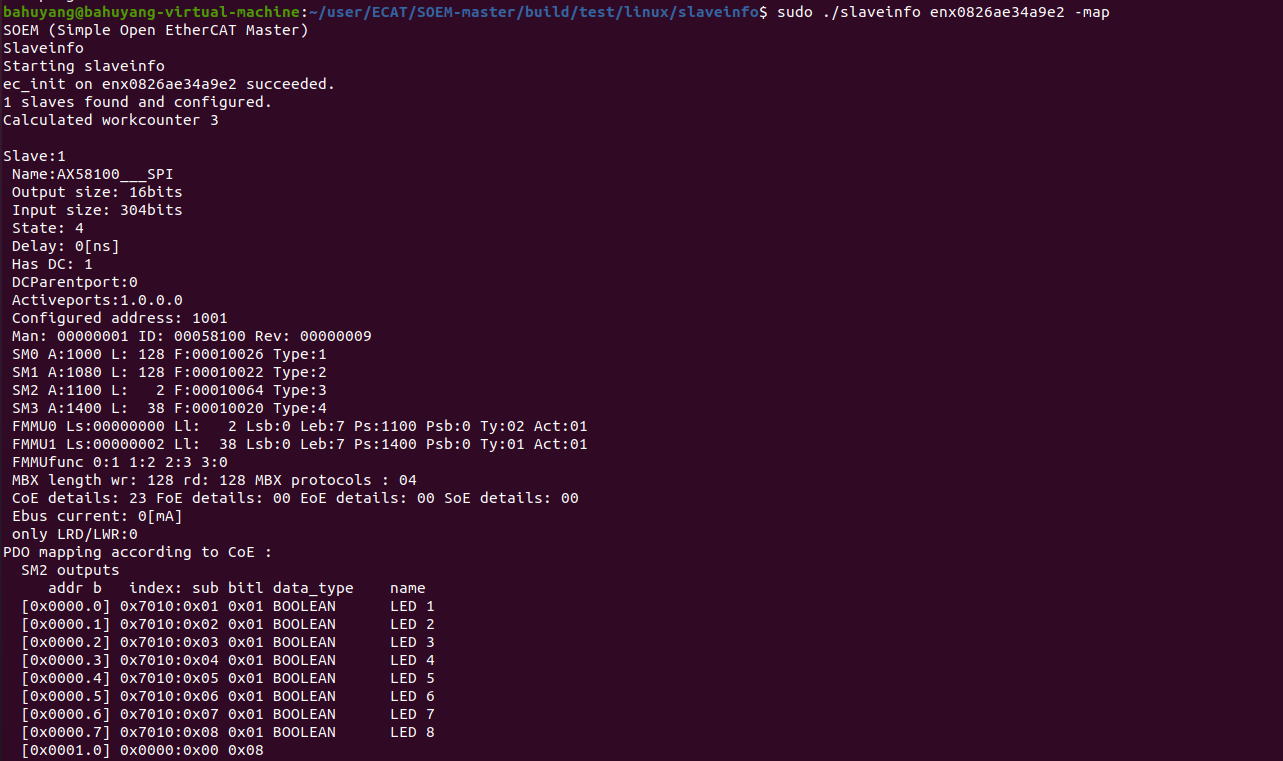
在Linux上实现ECAT主站
在Linux上实现ECAT主站 引言介绍EtherCATSOEM 使用下载ECAT主站编译 引言 EtherCAT由一个主站设备和多个从站设备组成。主站设备使用标准的以太网控制器,具有良好的兼容性,任何具有网络接口卡的计算机和具有以太网控制的嵌入式设备都可以作为EtherCAT的…...
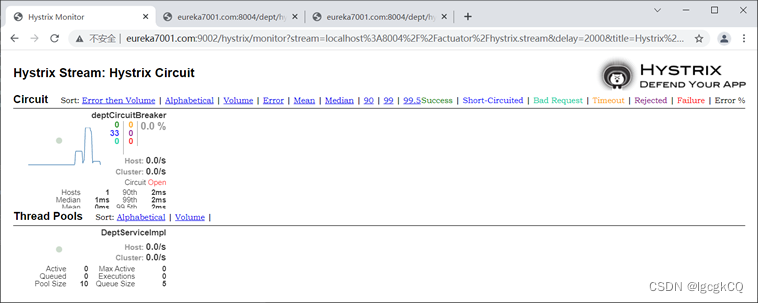
Spring Cloud之服务熔断与降级(Hystrix)
目录 Hystrix 概念 作用 服务降级 简介 使用场景 接口降级 服务端服务降级 1.添加依赖 2.定义接口 3.实现接口 4.Controller类使用 5.启动类添加注释 6.浏览器访问 客户端服务降级 1.添加依赖 2.application.yml 中添加配置 3.定义接口 4.Controller类使用 …...

HashMap 哈希碰撞、负载因子、插入方式、扩容倍数
HashMap 怎么解决的哈希碰撞问题? 主要采用了链地址法。具体来说: 每个哈希桶不仅存储一个键-值对,而是存储一个链表或树结构。这样,具有相同哈希值的键-值对可以被存储在同一个哈希桶中,并通过链表或树结构来解决碰…...
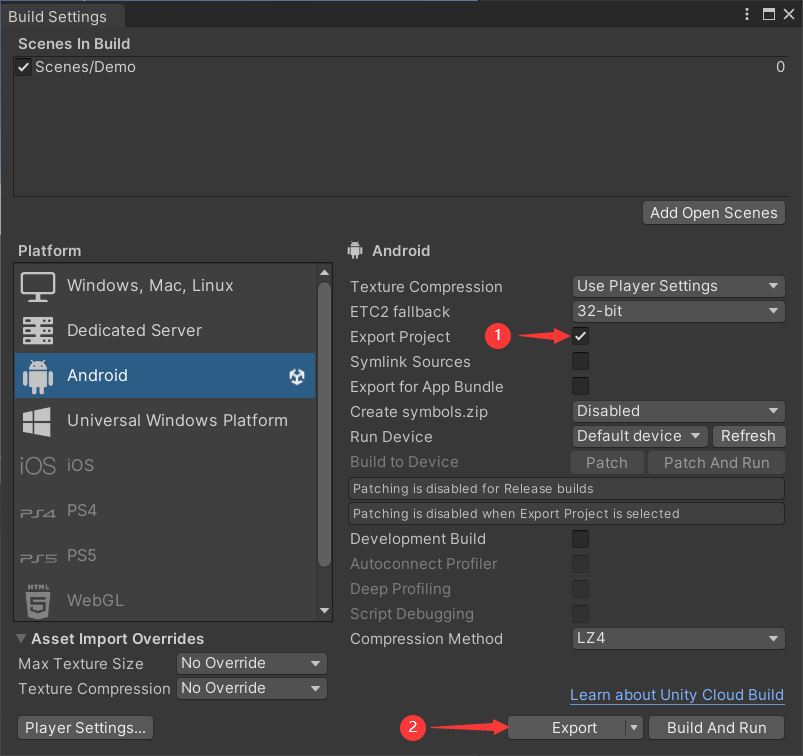
【Unity3D】Unity与Android交互
1 Unity 发布 apk 1.1 安装 Android Build Support 在 Unity Hub 中打开添加模块窗口,操作如下。 选择 Android Build Support 安装,如下(笔者这里已安装过)。 创建一个 Unity 项目,依次点击【File→Build Settings→…...
信号去噪算法
引言 在实际世界中,我们所获得的信号通常都包含了各种干扰和噪音。这些噪音可能来自电子设备、环境条件或传感器本身,它们会损害信号的质量,降低信息提取的准确性。因此,信号去噪和降噪技术在科学、工程和医学领域中扮演着至关重…...

GPT带我学-设计模式-10观察者模式
1 请你介绍一下观察者模式 观察者模式(Observer Pattern)是一种设计模式,它定义了对象之间的一对多依赖关系,当一个对象(被观察者)的状态发生改变时,所有依赖于它的对象(观察者&…...

JDK - 常用的设计模式
单例模式 : Runtime 类:Java 运行时环境是单例的,可以通过 Runtime.getRuntime() 方法获得实例。Calendar 类:Calendar.getInstance() 方法返回的是一个单例的 Calendar 实例。数据源连接池:连接池的管理通常采用单例模…...

华为OD机考算法题:寻找最大价值的矿堆
题目部分 题目寻找最大价值的矿堆难度难题目说明给你一个由 0(空地)、1(银矿)、2(金矿)组成的的地图,矿堆只能由上下左右相邻的金矿或银矿连接形成。超出地图范围可以认为是空地。 假设银矿价值…...

wf-docker集群搭建(未完结)
系列文章目录 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 系列文章目录前言一、redis集群二、mysql集群三、nacos集群1. 环境要求2. 拉取镜像2.1. 拉取镜像方式配置集群2.2. 自定义nacos镜像配置集群 3 自定义…...

uni-app 在 APP 端的版本强制更新与热更新
整包更新与热更新的区别 ① 整包更新是指下载完整 apk 文件进行覆盖安装 ② 热更新是指把 app 有改动的地方打包进 wgt 文件,只更新 wgt 文件中的内容,不进行整包安装,在用户视角也叫做省流量更新 版本号规则约束 建议严格遵循 Semantic …...

3分钟搞定!3DS游戏格式转换神器:让.3ds文件秒变可安装的CIA格式 [特殊字符]
3分钟搞定!3DS游戏格式转换神器:让.3ds文件秒变可安装的CIA格式 🎮 【免费下载链接】3dsconv Python script to convert Nintendo 3DS CCI (".cci", ".3ds") files to the CIA format 项目地址: https://gitcode.com/g…...

如何快速获取全网音乐歌词:免费开源工具的终极指南
如何快速获取全网音乐歌词:免费开源工具的终极指南 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为找不到心爱歌曲的歌词而烦恼吗?163Music…...
)
别再手动算矩阵了!CloudCompare 2025版点云变换保姆级教程(齐次/欧拉/轴角一键搞定)
别再手动算矩阵了!CloudCompare 2025版点云变换保姆级教程(齐次/欧拉/轴角一键搞定) 点云数据处理中,最让人头疼的莫过于各种空间变换操作。传统方法需要手动计算变换矩阵,不仅容易出错,还耗费大量时间。Cl…...

ESP32 Arduino IDE 看门狗实战:从硬件看门狗到Task Watchdog Timer的配置与避坑指南
1. ESP32看门狗机制入门:为什么你的程序总在重启? 刚接触ESP32的开发者经常会遇到一个诡异现象:程序运行得好好的,突然就重启了。这很可能就是看门狗(Watchdog Timer)在作祟。我第一次用ESP32做物联网传感器…...

从零到一:手把手完成Keil5 MDK环境搭建与ST-LINK驱动配置
1. 开发环境搭建前的准备工作 第一次接触STM32开发的朋友们,看到各种专业术语可能会有点懵。别担心,我刚开始也是这样。咱们先理清几个基本概念:Keil MDK是ARM公司推出的专业嵌入式开发工具,ST-LINK则是ST官方推出的调试下载器。…...

快手推荐算法实战解析:从三层漏斗架构到多目标优化
1. 项目概述:从“刷”到“懂”,快手推荐算法的冰山一角 刷快手,可能是很多人每天的习惯性动作。手指一划,一个接一个的短视频,好像总能精准地戳中你的笑点、泪点或是知识盲区。你有没有想过,为什么你看到的…...

如何用智能标记插件3秒筛选最新招聘岗位:开源求职助手完整指南
如何用智能标记插件3秒筛选最新招聘岗位:开源求职助手完整指南 【免费下载链接】NewJob 一眼看出该职位最后修改时间,绿色为2周之内,暗橙色为1.5个月之内,红色为1.5个月以上 项目地址: https://gitcode.com/GitHub_Trending/ne/…...

Next.js全栈开发最佳实践:从零搭建现代化Web应用
1. 项目概述:一个现代Web开发的“瑞士军刀”如果你和我一样,在过去几年里频繁地使用Next.js、TypeScript和Tailwind CSS来构建前端应用,那么你肯定也经历过无数次重复的“项目初始化”工作。从安装依赖、配置TypeScript和ESLint,到…...

基于RAG的智能文档问答系统:从原理到实践
1. 项目概述与核心价值如果你是一名开发者,或者经常需要处理各种技术文档、API参考、项目说明,那么你一定对“信息孤岛”深有体会。代码在一个仓库里,设计文档在另一个云盘,会议记录在Notion,而临时的讨论和决策可能散…...

终极APK安装指南:在Windows上轻松安装Android应用
终极APK安装指南:在Windows上轻松安装Android应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想过,在Windows电脑上直接运行Andr…...