0基础学习PyFlink——使用PyFlink的SQL进行字数统计
在《0基础学习PyFlink——Map和Reduce函数处理单词统计》和《0基础学习PyFlink——模拟Hadoop流程》这两篇文章中,我们使用了Python基础函数实现了字(符)统计的功能。这篇我们将切入PyFlink,使用这个框架实现字数统计功能。
PyFlink安装
安装Python
sudo apt install python3.10
sudo ln -s /usr/bin/python3.10 /usr/bin/python
安装虚拟环境
sudo apt install python3.10-venv
创建工程所在文件夹,并创建虚拟环境
mkdir pyflink-test
cd pyflink-test
python -m venv .env
进入虚拟环境,并安装PyFlink
source .env/bin/activate
pip3.10 install apache-flink
统计代码
Flink为开发者提供了如下不同层级的抽象。本篇我们将尽量使用SQL来实现功能。
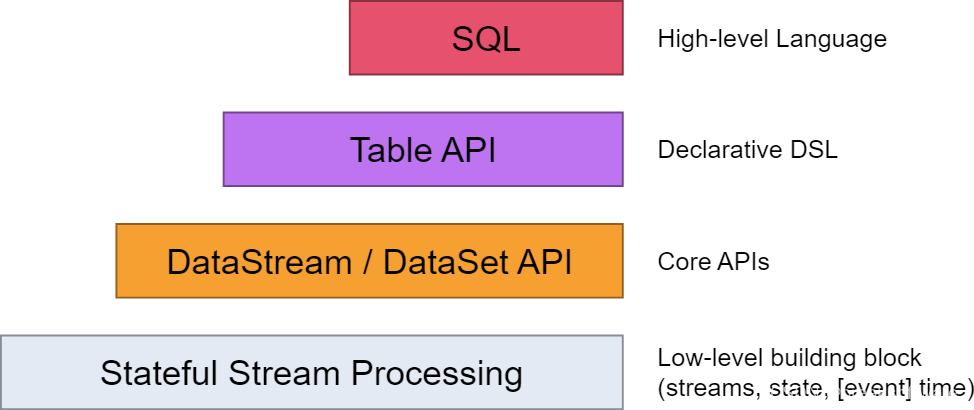
创建环境
执行环境用于设置任务的属性(batch还是stream),以及一些运行时参数(parallelism.default等)。
和Hadoop不同的是,Flink是流批一体(既可以处理流,也可以处理批处理)的引擎,而前者是批处理引擎。
批处理很好理解,即给一批数据,我们一次性、成批处理完成。
而流处理则是指,数据源源不断进入引擎,没有尽头。
本文不对此做过多展开,只要记得本例使用的是批处理模式(in_batch_mode)即可。
import argparse
import logging
import sysfrom pyflink.common import Configuration
from pyflink.table import (EnvironmentSettings, TableEnvironment)def word_count(input_path):config = Configuration()# write all the data to one fileconfig.set_string('parallelism.default', '1')env_settings = EnvironmentSettings \.new_instance() \.in_batch_mode() \.with_configuration(config) \.build()t_env = TableEnvironment.create(env_settings)
Source
在前两篇文章中,我们使用内存中的常规结构体,如dict等来保存Map过后的数据。而本文介绍的SQL方式,则是通过Table(表)的形式来存储,即输入的数据会Map到一张表中
# define the sourcemy_source_ddl = """create table source (word STRING) with ('connector' = 'filesystem','format' = 'csv','path' = '{}')""".format(input_path)t_env.execute_sql(my_source_ddl).print()tab = t_env.from_path('source')
这张表只有一个字段——String类型的word。它用于记录被切分后的一个个字符串。
这儿有个关键字with。它可以用于描述数据读写相关信息,即完成数据读写相关的设置。
connector用于指定连接方式,比如filesystem是指文件系统,即数据读写目标是一个文件;jdbc则是指一个数据库,比如mysql;kafka则是指一个Kafka服务。
format用于指定如何把二进制数据映射到表的列上。比如CSV,则是用“,”进行列的切割。
Execute
# execute insertmy_select_ddl = """select word, count(1) as `count`from sourcegroup by word"""t_env.execute_sql(my_select_ddl).wait()
上述SQL我们按source表中的word字段聚类,统计每个字符出现的个数。
完整输出如下
Using Any for unsupported type: typing.Sequence[~T]
No module named google.cloud.bigquery_storage_v1. As a result, the ReadFromBigQuery transform *CANNOT* be used with `method=DIRECT_READ`.
OK
+--------------------------------+----------------------+
| word | count |
+--------------------------------+----------------------+
| A | 3 |
| B | 1 |
| C | 2 |
| D | 2 |
| E | 1 |
+--------------------------------+----------------------+
5 rows in set
完整代码
# sql_print.py
import argparse
import logging
import sysfrom pyflink.common import Configuration
from pyflink.table import (EnvironmentSettings, TableEnvironment)def word_count(input_path):config = Configuration()# write all the data to one fileconfig.set_string('parallelism.default', '1')env_settings = EnvironmentSettings \.new_instance() \.in_batch_mode() \.with_configuration(config) \.build()t_env = TableEnvironment.create(env_settings)# define the sourcemy_source_ddl = """create table source (word STRING) with ('connector' = 'filesystem','format' = 'csv','path' = '{}')""".format(input_path)t_env.execute_sql(my_source_ddl).print()tab = t_env.from_path('source')my_select_ddl = """select word, count(1) as `count`from sourcegroup by word"""t_env.execute_sql(my_select_ddl).print()if __name__ == '__main__':logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s")parser = argparse.ArgumentParser()parser.add_argument('--input',dest='input',required=False,help='Input file to process.')argv = sys.argv[1:]known_args, _ = parser.parse_known_args(argv)word_count(known_args.input)
测试的输入文件
“A”,
“B”,
“C”,
“D”,
“A”,
“E”,
“C”,
“D”,
“A”,
运行的指令是
python sql_print.py --input input1.csv
参考资料
- https://nightlies.apache.org/flink/flink-docs-master/zh/docs/concepts/overview/
相关文章:
0基础学习PyFlink——使用PyFlink的SQL进行字数统计
在《0基础学习PyFlink——Map和Reduce函数处理单词统计》和《0基础学习PyFlink——模拟Hadoop流程》这两篇文章中,我们使用了Python基础函数实现了字(符)统计的功能。这篇我们将切入PyFlink,使用这个框架实现字数统计功能。 PyFl…...
【Java系列】ArrayList
ArrayList 添加元素访问元素修改元素删除元素计算大小迭代数组列表其他的引用类型ArrayList 排序Java ArrayList 方法系列文章系列文章版本记录 引言 ArrayList 类是一个可以动态修改的数组,与普通数组的区别就是它是没有固定大小的限制,我们可以添加或删…...

sqlalchemy 使用
Python中强大的通用ORM框架:SQLAlchemy - 知乎...

Python深度学习实战-基于class类搭建BP神经网络实现分类任务(附源码和实现效果)
实现功能 上篇文章介绍了用Squential搭建BP神经网络,Squential可以搭建出上层输出就是下层输入的顺序神经网络结构,无法搭出一些带有跳连的非顺序网络结构,这个时候我们可以选择类class搭建封装神经网络结构。 第一步:import ten…...
GIS 数据结构整理:网格索引
1 一维网格索引 把整个数据库数值空间划分成n*n的正方形网格,建立另一个倒排文件——栅格索引每一个网格在栅格索引中有一个索引条目(记录),在这个记录中登记所有位于或穿过该网格的物体的关键字 1.1 变长指针法 在这个网格的物体,按照序号…...
【打靶】vulhub打靶系列(一)—小白视野的渗透测试
主机探测 arpscan arp-scan -l 另一种方法arping for i in $(seq 1 200); do sudo arping -c 1 192.168.56.$i; done 注意这个必须是root权限 端口探测 nmap nmap -p- -sV -T4 192.168.56.104 发现8080端口 web测试 访问下web页面 1、通过逻辑点绕过 发送到xia_sq…...

kafka3.X集群安装(不使用zookeeper)
参考: 【kafka专栏】不用zookeeper怎么安装kafka集群-最新kafka3.0版本 一、kafka集群实例角色规划 在本专栏的之前的一篇文章《kafka3种zk的替代方案》已经为大家介绍过在kafka3.0种已经可以将zookeeper去掉。 上图中黑色代表broker(消息代理服务)&…...

2023 年 的 DBA 有哪些变化?
作者:Craig S. Mullins 数据库专家,IBM 优化冠军,DB2 金牌顾问以及 IDUG 名人堂成员,数据库类畅销书作者,著有《DB2 Developers Guide》、《Database Administration: The Complete Guide to DBA Practices & Pro…...

vs2022 使用git同步报错以及解决每次推送要输入密码问题
1.使用 git GUI工具,例如:TortoiseGit ,把全局配置文件这样设置一下 设置全局.config ,这样即可。 [credential] helper store 2.如果推送代码或拉取代码一直失败,在当前的仓库下面,使用以下命令来重置一下密码 git …...
有哪些适用于 Windows 的PDF 阅读器?免费 PDF 阅读器清单
探索适用于 Windows 10 和 11 的最佳 PDF 阅读器 适用于 Windows 10 和 Windows 11 的最佳 PDF 阅读器让您可以在台式计算机上查看和共享文档。 最好的PDF 编辑器和免费的 PDF 编辑器配备了先进的工具,可以跨不同的操作系统工作。但是,当您只需要查看和…...

避雷!新增2本期刊被标记为「On Hold」,1区TOP刊仍在调查中!
近期小编在Master Journal List上查询期刊时偶然发现,又有2本期刊被科睿唯安标记为「On Hold」! 这2本期刊分别为MIGRATION LETTERS和REVISTA DE GESTAO E SECRETARIADO-GESEC. 此外还有6本期刊被标记为「On Hold」,目前共计8本期刊被「On …...
iOS 配置通用链接(Universal Link)服务端和开发者后台都配置好了,还是跳转不到App
目录 一、什么是 Universal Link? 1.背景介绍 2.特点 3.运行机制原理&流程图 二、配置教程 1.第一步:开启 Associated Domains 服务 1.1 开通 Associated Domains 2.第二步:服务器配置 apple-app-site-association(AAS…...

【环境】Linux下Anaconda/ Miniconda安装+百度Paddle环境搭建+Cudnn(3090显卡+CUDA11.8+cudnn8.6.0)
清华源帮助链接:https://mirror.tuna.tsinghua.edu.cn/help/anaconda/ 下载链接:https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/ 其他深度学习环境相关博文:【stable-diffusion】4090显卡下dreambooth、lora、sd模型微调的GUI环境…...

【Python机器学习】零基础掌握AdaBoostRegressor集成学习
有没有经历过这样的状况:需要预测未来房价走势,但传统的预测方法并不总是准确? 房价预测一直是人们关注的热点话题,无论是房产商、购房者,还是政府,都需要准确地知道未来房价的走势。那么,有没有一种更加精准、稳定的预测方法呢?答案是有的——AdaBoost Regressor算法…...

各种添加路由的方法
Linux 篇: ipv4: #添加到主机的路由 # route add –host 192.168.168.110 dev eth0 # route add –host 192.168.168.119 gw 192.168.168.1 #添加到网络的路由 # route add –net IP netmask MASK eth0 # route add –net IP netmask MASK gw IP # route add –n…...

MySQL外键
目录 一.外键 1.表与表之间建立关系 2.什么是外键 3.一对多关系 4.多对多关系 (1)建表会遇到的问题 (2)解决循环建表的问题 5.一对一关系、 6.小结 二.多表查询 1.数据准备 2.多表查询案例 (1)…...
)
自制数据库迁移工具-C版-02-HappySunshineV1.1-(支持Gbase8a)
目录 一、环境信息 二、简述 三、升级点 四、支持功能 五、安装包下载地址 六、配置参数介绍 七、安装步骤 1、配置环境变量 2、生效环境变量 3、检验动态链接是否正常 4、修改配置文件MigrationConfig.txt 八、运行效果 一、环境信息 名称值CPUIntel(R) Core(TM) i…...

k8s创建pod-affinity亲和性时报错解决办法
1.如下报错 Error from server (BadRequest): error when creating “pod-required-affinity-demo-2.yaml”: Pod in version “v1” cannot be handled as a Pod: json: cannot unmarshal string into Go struct field LabelSelectorRequirement.spec.affinity.podAffinity.re…...
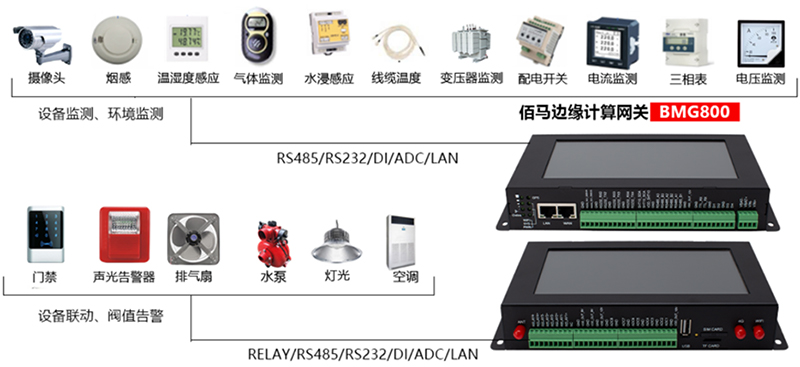
基于边缘智能网关的储能系统安全监测管理方案
“储能系统充电”是配套新能源汽车产业发展的重要应用之一。得益于电池技术的发展,新能源汽车正逐步迈入快充时代,由于在使用快速充电桩时,可能导致用电峰值负荷超过电网的承载能力,对于电网的稳定性和持续性会有较大影响…...

大数据Flink(一百零一):SQL 表值函数(Table Function)
文章目录 SQL 表值函数(Table Function) SQL 表值函数(Table Function) Python UDTF,即 Python TableFunction,针对每一条输入数据,Python UDTF 可以产生 0 条、1 条或者多条输出数据,此外,一条输出数据可以包含多个列。比如以下示例,定义了一个名字为 split 的Pyt…...

Bootstrap5 侧边栏导航
Bootstrap5 侧边栏导航 随着Web技术的发展,用户界面(UI)设计越来越受到重视。Bootstrap作为一个流行的前端框架,它为开发者提供了丰富的组件和工具,以快速构建响应式、移动优先的网站和应用程序。在Bootstrap 5中,侧边栏导航是一个重要的组件,它可以帮助用户在网站或应…...

2025终极免费IDM激活方案:一键永久解锁下载管理神器
2025终极免费IDM激活方案:一键永久解锁下载管理神器 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script 还在为Internet Download Manager(ID…...

codex出现Reconnecting和stream disconnected before completion:stream closed before response.complete解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...
)
CVPR投稿后,我是如何用一篇高质量的Rebuttal说服审稿人的(附真实邮件模板)
CVPR投稿后,我是如何用一篇高质量的Rebuttal说服审稿人的(附真实邮件模板) 在计算机视觉领域的顶级会议CVPR投稿过程中,Rebuttal环节往往成为决定论文命运的关键转折点。许多研究者花费数月精心打磨论文,却在收到审稿意…...

从Mid360到自主移动:基于Fast-LIO与Move_Base的机器人导航实战拆解
1. Mid360激光雷达与Fast-LIO的适配实战 第一次拿到Livox Mid360激光雷达时,我完全被它36059的超大视场角惊艳到了。这款固态激光雷达不仅体积小巧,而且完全不用担心传统机械式雷达的电机磨损问题。但真正开始用它做SLAM时,才发现实物开发和仿…...

TencentDB Agent Memory 架构拆解:告别 Agent 失忆,构建四层可追溯记忆与上下文治理系统
拆解 TencentDB Agent Memory 如何用分层记忆、上下文卸载和降级检索,让 Agent 留住工作现场。 原文链接:AI 小老六 Agent 真正难用的地方,往往不是它不会调用工具,而是它记不住工作现场。 你刚给它讲完项目背景、编码偏好、部署…...

个人开发者对比使用Taotoken前后在模型API管理与调用上的效率变化
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 个人开发者使用 Taotoken 前后在模型 API 管理与调用上的效率变化 作为一名个人开发者,在探索和应用大模型能力时&…...

逆向分析效率翻倍:深度挖掘IDA Pro的‘隐藏’窗口——段视图、签名、类型库的实战价值
逆向分析效率翻倍:深度挖掘IDA Pro的‘隐藏’窗口实战指南 在逆向工程领域,IDA Pro无疑是众多安全研究员和分析师的首选工具。然而,许多中级用户往往只停留在反汇编窗口的基础操作上,忽视了那些隐藏在界面角落却能极大提升分析效率…...

HPM6750 CAN FD实战:从波特率配置到高效收发,避坑指南
1. 项目概述:从经典CAN到CAN FD的实战入门作为一名长期在嵌入式领域摸爬滚打的开发者,我深知现场总线技术,尤其是CAN总线,在工业控制、汽车电子等领域的核心地位。随着数据吞吐量需求的激增,经典CAN的1Mbps带宽逐渐捉襟…...

如何快速掌握高效窗口管理:免费开源工具完整指南
如何快速掌握高效窗口管理:免费开源工具完整指南 【免费下载链接】AltSnap Maintained continuation of Stefan Sundins AltDrag 项目地址: https://gitcode.com/gh_mirrors/al/AltSnap 你是否曾经在Windows系统中为繁琐的窗口操作而烦恼?每次想要…...