Pytorch--3.使用CNN和LSTM对数据进行预测
这个系列前面的文章我们学会了使用全连接层来做简单的回归任务,但是在现实情况里,我们不仅需要做回归,可能还需要做预测工作。同时,我们的数据可能在时空上有着联系,但是简单的全连接层并不能满足我们的需求,所以我们在这篇文章里使用CNN和LSTM来对时间上有联系的数据来进行学习,同时来实现预测的功能。
1.数据集:使用的是kaggle上一个公开的气象数据集(CSV)
有需要的可以去kaggle下载,也可以在评论区留下mail,题主发送过去
2.导入我们所需要的库和完成前置工作
2.1导入相关的库
torch为人工智能的库,pandas用于数据读取,numpy为张量处理的库,matplotlib为画图库
import torch
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
import torch.nn as nn
import torch.optim as optim
import random
2.2设置相关配置
我们设置随机种子(方便代码的复现)和警告的忽律(防止出现太多警告看不到代码运行的效果)
warnings.filterwarnings('ignore')
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
torch.manual_seed(99)
np.random.seed(99)
random.seed(99)
print ("随机种子")
2.3数据的读入
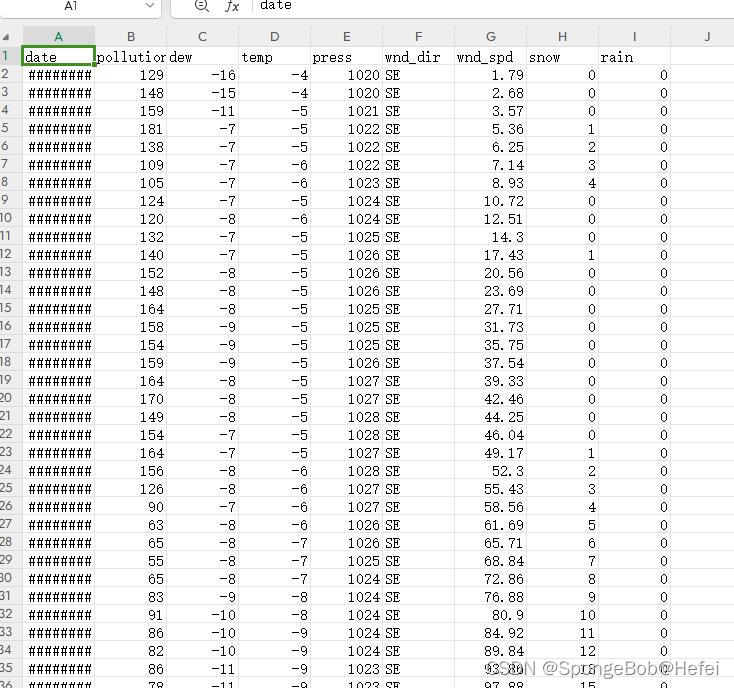
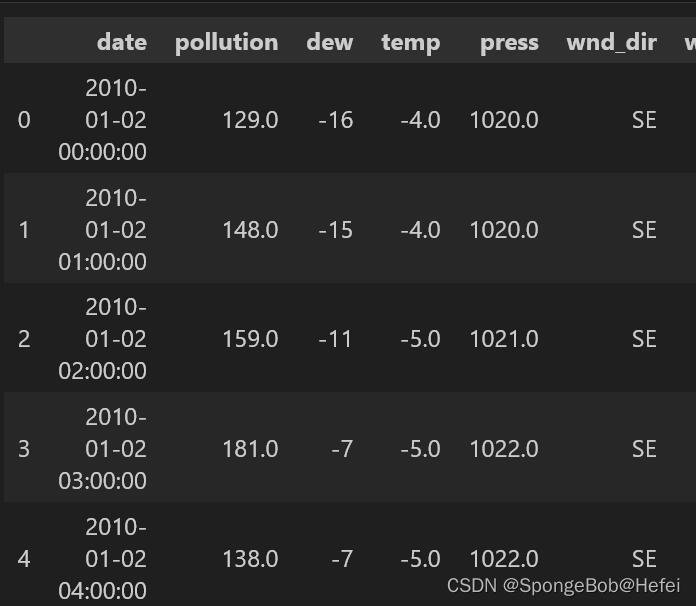
pd.read_csv里面的参数为相对位置,即代码和文件要在同一个文件夹下面。使用.head()函数来读一下数据的前几行,保证数据是存在的
train_data = pd.read_csv("LSTM-Multivariate_pollution.csv")
train_data.head()
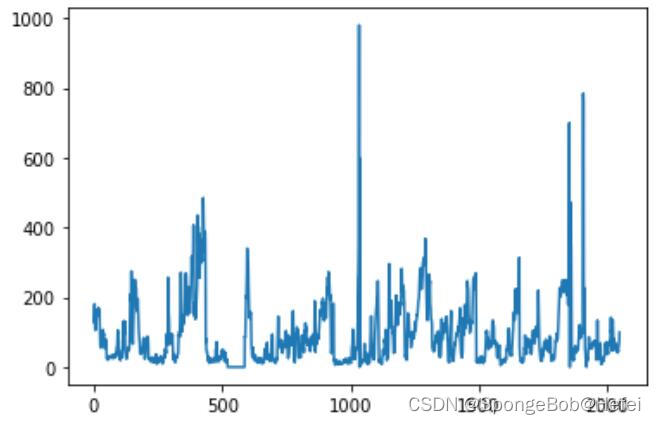
我们来看一下各个值的前2048个数据分布情况(方便挑选数据进行代码测试)
代码里面的pollution可以换成dew,temp等值(也就是上图里面的值),用于观看分布情况。
train_use = train_data["pollution"].values
plt.plot([i for i in range(2048)], pollution[:2048])
pollution:
dew:
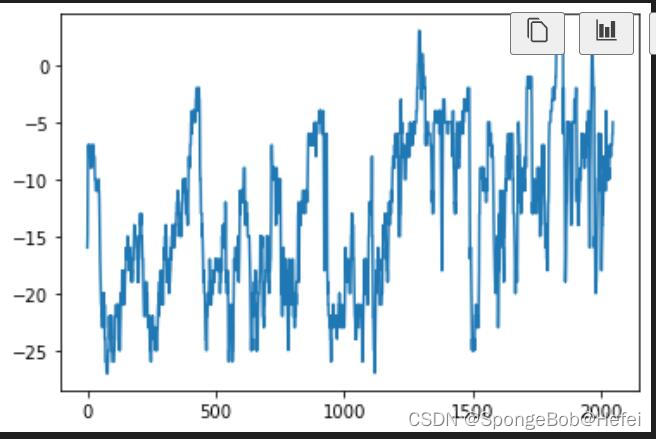
temp:
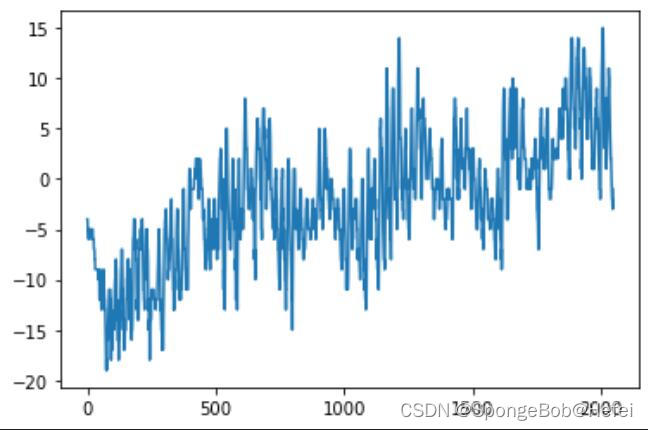
我们可以看到temp属性里面的数据整体呈现上升的趋势,所以我们使用属性为temp的值来进行学习和预测。
首先对数据进行归一化操作(因为值过大的话会导致神经网络损失不降低,同时神经网络难以达到收敛),我们使用minmax归一化后将其打印出来可以看到代码显示的效果
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
train_use = scaler.fit_transform(train_use.reshape(-1, 1))
print ((train_use))
print ("归一化处理")
可以看到归一化后的结果如下图所示:
我们将数据进行处理,默认使用30天的数据对第31天的数据进行预测,同时将数据进行升维处理,使得输入的训练数据为3维度,分别为batchsize,每次所需要的数据(30个数据),和数据的输入维度(1维度)
def split_data(data, time_step = 30):dataX = []dataY = []for i in range(len(data) - time_step):dataX.append(data[i:i + time_step])dataY.append(data[i + time_step])dataX = np.array(dataX).reshape(len(dataX), time_step, -1)dataY = np.array(dataY)return dataX, dataY
进行数据处理后,获得了可以训练的数据和标签
datax,datay = split_data(train_use, 30)
print ((datay))
结果如下:
紧接着我们划分训练集和测试集,默认为80%的数据用于做训练集,20%的数据用于做测试集,shuffle表示是否要将数据进行打乱,以此来测试训练效果
def train_test_split(dataX,datay,shuffle = True,percentage = 0.8):if shuffle:random_num = [i for i in range(len(dataX))]np.random.shuffle(random_num)dataX = dataX[random_num]datay = datay[random_num]split_num = int(len(dataX)*percentage)train_X = dataX[:split_num]train_y = datay[:split_num]testX = dataX[split_num:]testy = datay[split_num:]return train_X, train_y, testX, testy
获取我们的训练数据和测试数据,同时把源数据保存到X_train和y_train里面,方便以后对网络的性能进行评比。
train_X, train_y, testx,testy = train_test_split(datax,datay,False,0.8)
print (type(testx))
print("datax的形状为{},dataY的形状为{}".format(train_X.shape, train_y.shape))
X_train = train_X
y_train = train_y
定义我们的自定义网络
class CNN_LSTM(nn.Module):def __init__(self, conv_input, input_size, hidden_size, num_layers, output_size):super(CNN_LSTM, self).__init__()self.hidden_size = hidden_sizeself.num_layers = num_layersself.conv = nn.Conv1d(conv_input, conv_input, 1)self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first = True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x):x = self.conv(x)h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size)c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size)out, _= self.lstm(x,(h0,c0))out = self.fc(out[:,-1,:])return out
设置我们网络训练所需要的参数
test_X1 = torch.Tensor(testx)
test_y1 = torch.Tensor(testy)input_size = 1
conv_input = 30
hidden_size = 64
num_layers = 2output_size = 1model = CNN_LSTM(conv_input, input_size, hidden_size, num_layers,output_size)num_epoch = 1000
batch_size = 4optimizer = optim.Adam(model.parameters(), lr = 0.0001, betas=(0.5, 0.999))criterion = nn.MSELoss()
#print ((torch.Tensor(train_X[:batch_size])))
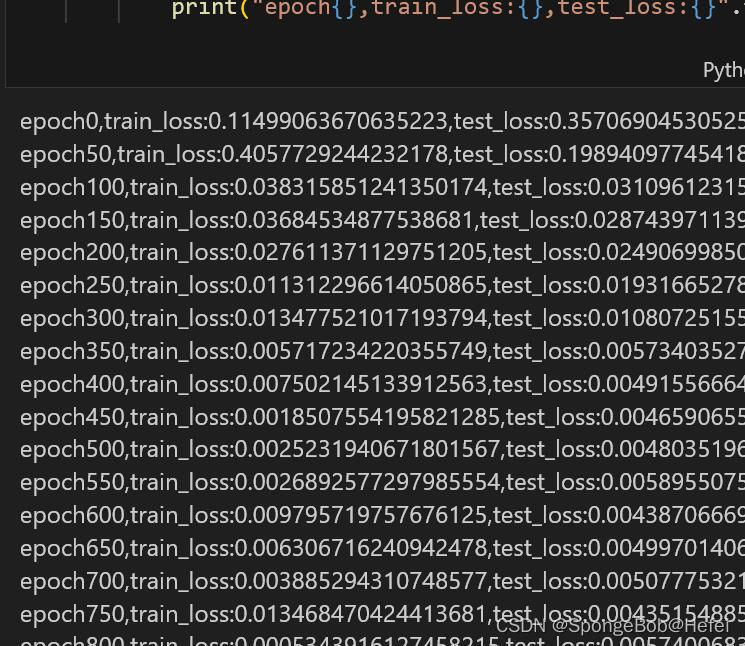
开始运行代码:
train_losses = []
test_losses = []
for epoch in range(num_epoch):random_num = [i for i in range(len(train_X))]np.random.shuffle(random_num)train_X = train_X[random_num]train_y = train_y[random_num]train_x1 = torch.Tensor(train_X[:batch_size])train_y1 = torch.Tensor(train_y[:batch_size])model.train()optimizer.zero_grad()output = model(train_x1)train_loss = criterion(output, train_y1)train_loss.backward()optimizer.step()if epoch%50 == 0 :model.eval()with torch.no_grad():output = model(test_X1)test_loss = criterion(output, test_y1)train_losses.append(train_loss)test_losses.append(test_loss)print("epoch{},train_loss:{},test_loss:{}".format(epoch, train_loss, test_loss))
自己手写一个mse计算函数(直接调库也可以),什么是mse?(均方误差,均方误差越小说明模型拟合的越好)
def mse(pred_y, true_y):return np.mean((pred_y - true_y) **2)
然后我们对模型进行测试,观察mse的值
train_X1 = torch.Tensor(X_train)
train_pred = model(train_X1).detach().numpy()
test_pred = model(test_X1).detach().numpy()pred_y = np.concatenate((train_pred, test_pred))
pred_y = scaler.inverse_transform(pred_y).T[0]true_y = np.concatenate((y_train, testy))
#print (true_y)
true_y = scaler.inverse_transform(true_y).T[0]
#print (true_y)
print (f"mse(pred_y, true_y):{mse(pred_y, true_y)}")
##print (pred_y)
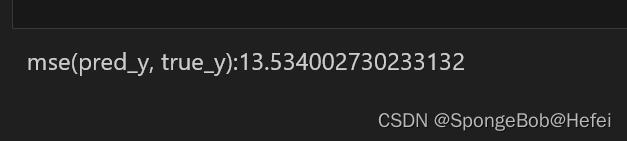
我们取前2048个值来看我们的预测的情况(因为数据有几万条,为了避免图形太过密集难以看出效果,所以我们只采用前2048个值来进行展示)
plt.title("CNN_LSTM")
x = [i for i in range(2048)]
plt.plot(x, pred_y[:2048], marker = "o", markersize =1, label="pred_y",color=(1, 0, 0))
plt.plot(x, true_y[:2048], marker = "x", markersize=1, label="true_y",color=(0, 0, 1))
plt.legend()
plt.show()
可以看出来,已经学习到了基本的上升趋势的
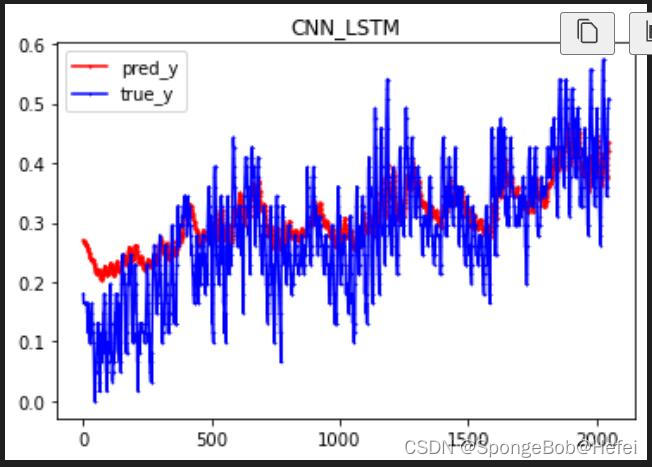
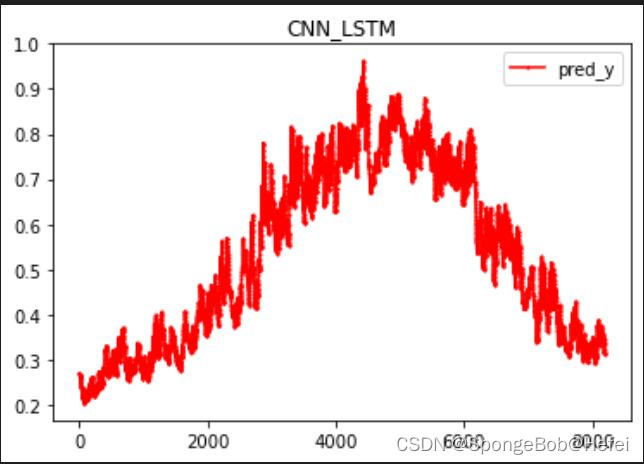
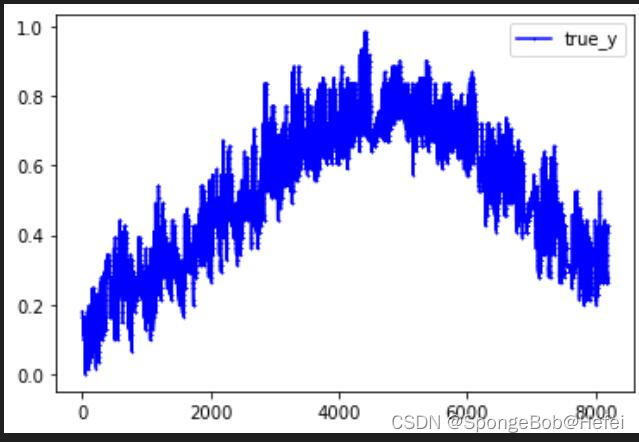
我们将两个图拆开来看,看到前8192个点的值,可以看到已经获得到了相对应的趋势。
码字不易,写代码不易,点个赞再走把
相关文章:
Pytorch--3.使用CNN和LSTM对数据进行预测
这个系列前面的文章我们学会了使用全连接层来做简单的回归任务,但是在现实情况里,我们不仅需要做回归,可能还需要做预测工作。同时,我们的数据可能在时空上有着联系,但是简单的全连接层并不能满足我们的需求࿰…...
)
爬虫进阶-反爬破解9(下游业务如何使用爬取到的数据+数据和文件的存储方式)
一、下游业务如何使用爬取到的数据 (一)常用数据存储方案 1.百万级别数据:单机数据库,搭建和使用方便快捷,成本低 2.千万级别数据:负载均衡的多台数据库,安全和稳定 3.海量数据:…...

Docker常用应用部署
Docker常用应用部署 一、Ubuntu系统Docker快速安装 Docker官网安装文档:https://docs.docker.com/engine/install/ubuntu/ # 文本处理的流编辑器 -i直接修改读取的文件内容,而不是输出到终端 # sed -i s/原字符串/新字符串/ /home/1.txt # 下面这个是修…...
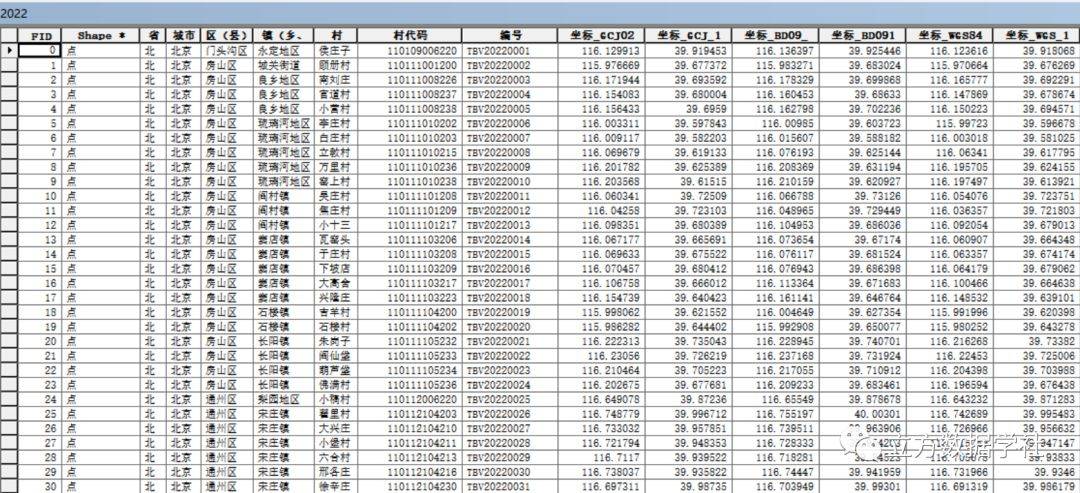
【数据分享】2014-2022年我国淘宝村点位数据(Excel格式/Shp格式)
电子商务是过去一二十年我国发展最快的行业,其中又以淘宝为代表,淘宝的发展壮大带动了一大批服务淘宝电子商务的村庄,这些村庄被称为淘宝村! 截至到目前,阿里研究院梳理并公布了2014-2022年共9个年份的淘宝村名单&…...
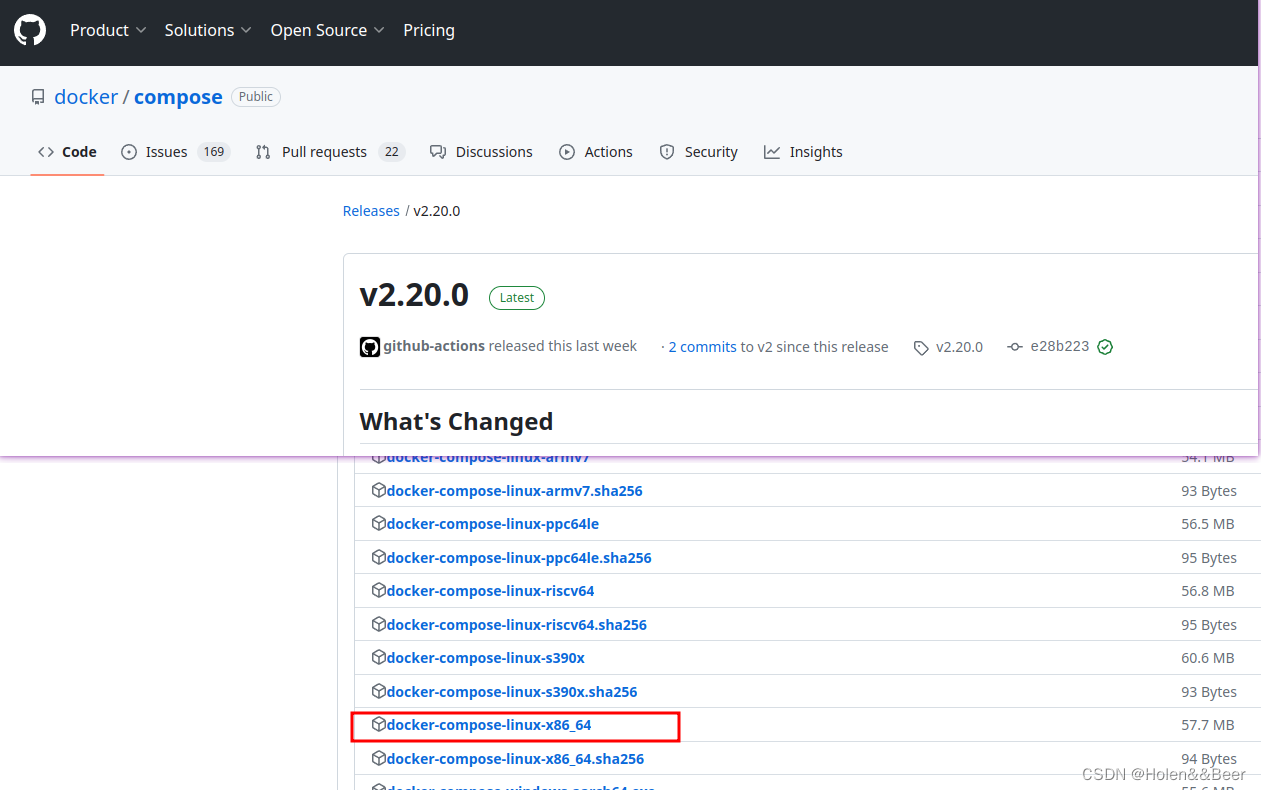
Ubuntu 安装 docker-compose
在Ubuntu上安装Docker Compose,可以按照以下步骤进行操作: 下载 Docker Compose 二进制文件 sudo curl -L "https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker…...

vue2、vue3中路由守卫变化
什么是路由守卫? 路由守卫就是路由跳转的一些验证,比如登录鉴权(没有登录不能进入个人中心页)等等等 路由守卫分为三大类: 全局守卫:前置守卫:beforeEach 后置钩子:afterEach 单个…...

Leetcode—547.省份数量【中等】
2023每日刷题(八) Leetcode—547.省份数量 实现代码 static int father[210] {0};int Find(int x) {if(x ! father[x]) {father[x] Find(father[x]);}return father[x]; }void Union(int x, int y) {int a Find(x);int b Find(y);if(a ! b) {fathe…...
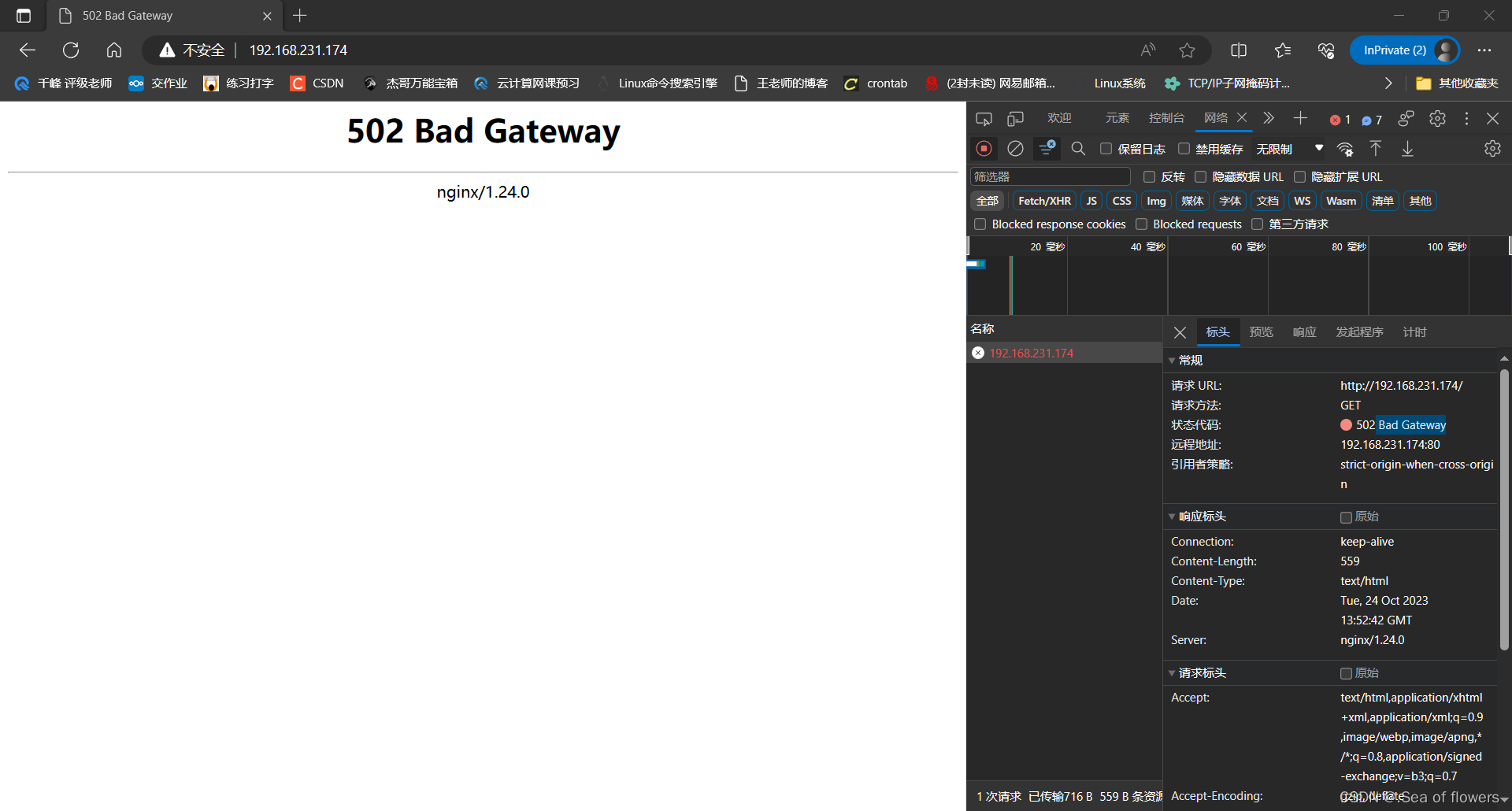
Nginx 防盗链
nginx防盗链问题 盗链: 就是a网站有一张照片,b网站引用了a网站的照片 。 防盗链: a网站通过设置禁止b网站引用a网站的照片。 nginx防止网站资源被盗用模块 ngx_http_referer_module 如何区分哪些是不正常的用户? HTTP Referer…...
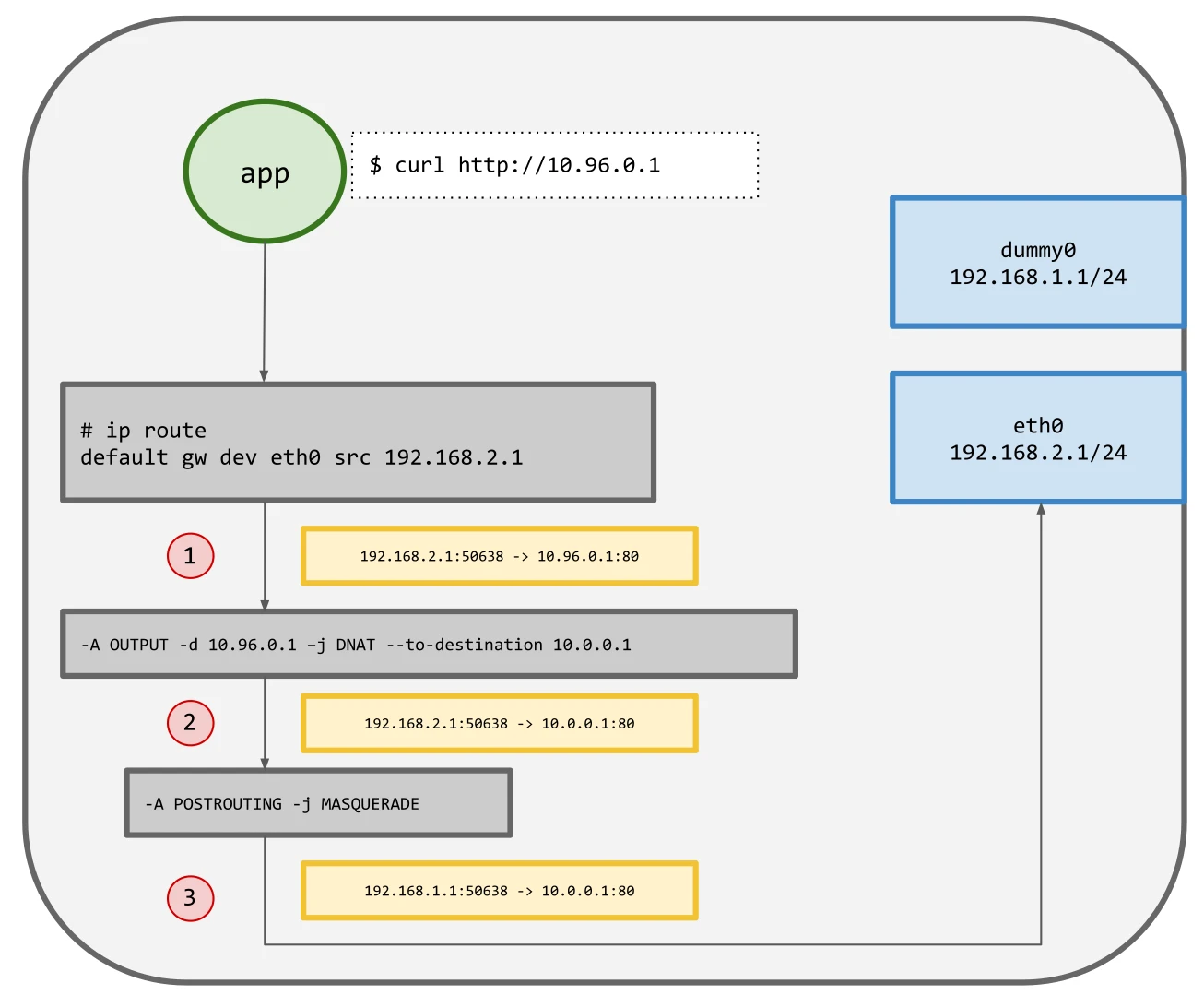
26. 通过 cilium pwru了解网络包的来龙去脉
pwru是一种基于eBPF的工具,可跟踪Linux内核中的网络数据包,并具有先进的过滤功能。它允许对内核状态进行细粒度检查,以便通过调试网络连接问题来解决传统工具(如iptables TRACE或tcpdump)难以解决甚至无法解决的问题。在本文中,我将介绍pwru如何在不必事先了解所有内容的…...

刷题笔记day01-数组
704 题 主要强调,左闭右闭的情况,就是每次查询都会和 [left, right] 进行比较。所以后面的都是mid-1,mid1 的情况。 package mainfunc search(nums []int, target int) int {// 二分查找方法// 每次查找都是左闭右闭的情况left : 0right : …...

C#调用C++ 的DLL传送和接收中文字符串
1 c#向c传送中文字符串 设置:将 字符集 改为 使用多字节字符集 cpp代码: extern "C"_declspec(dllexport) int input_chn_str(char in_str[]) {cout<<in_str<<endl;return 0; }c#代码: [DllImport("Demo.dll…...

【MySQL】数据库常见错误及解决
目录 2003错误:连接错误1251错误:身份验证错误1045错误:拒绝访问错误服务没有报告任何错误net start mysql 发生系统错误 5。 1064错误:语法错误1054错误:列名不存在1442错误:触发器中不能对本表增删改1303…...
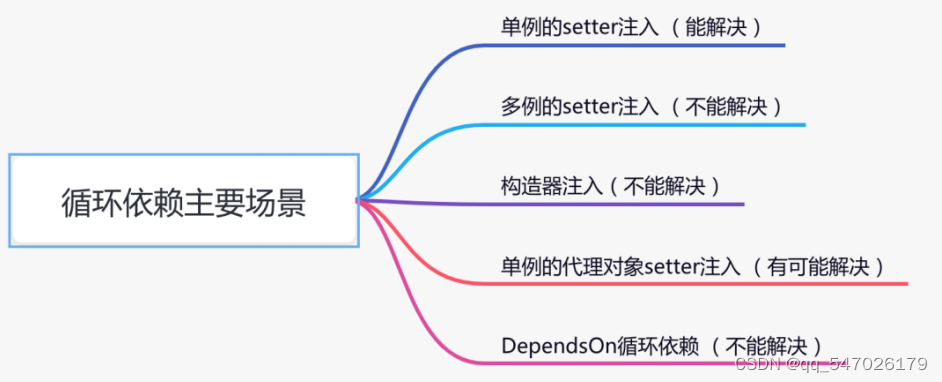
spring常见问题汇总
1. 什么是spring? Spring是一个轻量级Java开发框架,最早有Rod Johnson创建,目的是为了解决企业级应用开发的业务 逻辑层和其他各层的耦合问题。它是一个分层的JavaSE/JavaEE full-stack(一站式)轻量级开源框架, 为开…...

java8 Lambda表达式以及Stream 流
Lambda表达式 Lambda表达式规则 Lambda表达式可以看作是一段可以传递的代码, Lambda表达式只能用于函数式接口,而函数式接口只有一个抽象方法,所以可以省略方法名,参数类型等 Lambda格式:(形参列表&…...
基于Java的音乐网站管理系统设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding) 代码参考数据库参考源码获取 前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作者&am…...

【蓝桥】小蓝的疑问
1、题目 问题描述 小蓝和小桥上完课后,小桥回顾了课上教的树形数据结构,他在地上画了一棵根节点为 1 的树,并且对每个节点都赋上了一个权值 w i w_i wi。 小蓝对小桥多次询问,每次询问包含两个整数 x , k x,k x,kÿ…...
漏洞复现-海康威视综合安防管理平台信息泄露【附Poc】
目录 【产品介绍】 【产品系统UI】 【漏洞说明】 【指纹】 【Nuclei Poc】 【验证】 【产品介绍】 海康威视(Hikvision)是一家总部位于中国杭州的公司,是全球最大的视频监控产品供应商。除了传统的CCTV摄像机和网络摄像机,海…...

【完美世界】被骂国漫之耻,石昊人设战力全崩,现在真成恋爱世界了
【侵权联系删除】【文/郑尔巴金】 深度爆料,《完美世界》动漫第135集预告片已经更新了,但是网友们对此却是一脸槽点。从预告中可以看出,石昊在和战王战天歌的大战中被打成重伤,最后云曦也被战天歌抓住。在云曦面临生死危机的时候…...

34二叉树-BFS和DFS求树的深度
目录 LeetCode之路——104. 二叉树的最大深度 分析 解法一:广度优先遍历 解法二:深度优先遍历 总结 深度优先搜索 (DFS) 广度优先搜索 (BFS LeetCode之路——104. 二叉树的最大深度 给定一个二叉树 root ,返回其最大深度。 二叉树的…...
Android Glide判断图像资源是否缓存onlyRetrieveFromCache,使用缓存数据,Kotlin
Android Glide判断图像资源是否缓存onlyRetrieveFromCache,使用缓存数据,Kotlin import android.graphics.Bitmap import android.os.Bundle import android.util.Log import android.widget.ImageView import androidx.appcompat.app.AppCompatActivity…...

Go语言开源漏洞扫描器Abyss-Scanner:架构解析与CI/CD集成实践
1. 项目概述:一个为安全而生的开源漏洞扫描器最近在整理自己的开源项目工具箱,发现一个挺有意思的工具,叫 Abyss-Scanner。这名字起得挺有深意,“深渊扫描器”,听起来就有点探索未知、发现潜在风险的味道。简单来说&am…...

进化算法驱动机械爪设计优化:从原理到EvoClaw项目实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“EvoClaw”。光看这个名字,可能有点摸不着头脑,但点进去一看,发现这是一个关于“进化算法驱动的机械爪设计优化”的开源项目。简单来说,就是利用计算机…...

5大优势解析:如何高效使用免费离线OCR工具
5大优势解析:如何高效使用免费离线OCR工具 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。 项目…...

从分布式到可分发:大规模软件制品分发架构设计与实践
1. 项目概述:从“分布式”到“可分发”的思维跃迁最近在梳理团队内部的基础设施时,又翻出了distr-sh/distr这个项目。说实话,第一次看到这个仓库名,我下意识地把它归类为又一个“分布式系统”框架。但当我真正点进去,花…...

从零到一:基于GD32E230核心板的PCB设计实战与模块化解析
1. GD32E230核心板硬件设计基础 第一次拿到GD32E230这颗国产MCU时,说实话有点小激动。作为兆易创新基于Cortex-M23内核的拳头产品,它用55nm工艺把芯片面积压缩到了惊人的3x3mm,却集成了5个定时器、2个SPI、2个I2C这些实用外设。我在去年一个智…...

AI驱动全栈开发:Cursor集成模板与高效协作实践
1. 项目概述:当AI代码助手遇上全栈开发最近在GitHub上看到一个挺有意思的项目,叫“Cursor-FullStack-AI-App”。光看名字,你大概能猜到它和Cursor这个AI编程工具,以及全栈应用开发有关。作为一个在前后端都摸爬滚打过多年的开发者…...

OpenClaw实战教程:声明式配置驱动的高效数据抓取方案
1. 项目概述:一个关于“OpenClaw”的实战教程 最近在GitHub上看到一个挺有意思的项目,叫“OpenClawTuto”。光看名字,你可能会有点摸不着头脑,这“OpenClaw”到底是个啥?是某种开源机械爪?还是一个代号&…...

Simulink模型到汽车控制器:基于模型开发的完整路径
Simulink模型到汽车控制器:基于模型开发的完整路径 一辆智能电动汽车的"灵魂",通常写在300万行以上的嵌入式代码里。但如果每一行代码都要工程师手写,开发周期会从18个月变成……永远完成不了。 一个真实的问题 2023年,…...

构建个人技能图谱:从结构化设计到自动化可视化的实践指南
1. 项目概述:一个技能图谱的诞生最近在GitHub上看到一个挺有意思的项目,叫dortort/skills。初看这个仓库名,你可能会有点懵,dortort是作者,那skills是什么?点进去一看,发现它不是一个具体的工具…...

量子最优控制中的iLQR算法实践与优化
1. 量子最优控制基础与挑战量子最优控制(Quantum Optimal Control, QOC)是现代量子计算中的核心技术,其核心目标是通过精心设计的控制脉冲序列,实现对量子系统状态演化的精确操控。在超导量子计算体系中,这一技术尤为重…...