爬虫采集如何解决ip被限制的问题呢?
在进行爬虫采集的过程中,很多开发者会遇到IP被限制的问题,这给采集工作带来了很大的不便。那么,如何解决这个问题呢?下面我们将从以下几个方面进行探讨。

一、了解网站的反爬机制
首先,我们需要了解目标网站的反爬机制,包括哪些行为会导致IP被封禁。常见的反爬机制包括:限制IP访问频率、限制IP访问时间、检测请求的User-Agent等。通过对目标网站的反爬机制进行分析,我们可以采取相应的措施来避免被封禁。
二、使用代理IP
代理IP可以帮助我们隐藏真实的IP地址,从而避免被目标网站封禁。使用代理IP的优点是可以在短时间内更换大量的IP地址,适用于需要大量数据采集的情况。但是,代理IP的质量和可用性需要进行筛选和测试,否则可能会影响采集效率。
三、设置合理的采集频率
对于限制IP访问频率的反爬机制,我们可以设置合理的采集频率,以降低被封禁的风险。例如,可以将采集频率限制在每分钟10次以内,或者根据目标网站的规律进行波动性采集。
四、使用User-Agent伪装
有些目标网站会检测请求的User-Agent来判断是否为爬虫请求。为了伪装成正常用户,我们可以使用User-agent伪装技术,将请求的User-agent设置为浏览器的User-agent,从而避免被识别为爬虫请求。
五、增加随机延时
有些目标网站会检测请求的间隔时间来判断是否为爬虫请求。为了增加随机性,我们可以在请求之间添加一些随机的延时时间,从而避免被识别为固定的爬虫请求。
六、使用Web Scraper框架
Web Scraper框架可以帮助我们自动化处理网页内容,并避免触发反爬机制。使用Web Scraper框架可以减少对目标网站的访问次数,降低被封禁的风险。同时,Web Scraper框架还可以提供更多的选项和灵活性来进行定制化采集。
综上所述,解决IP被限制问题的方法有很多种,我们可以根据具体情况选择不同的方法来避免被封禁。需要注意的是,在进行爬虫采集时应该遵循法律法规和道德规范,尊重他人的劳动成果和知识产权,避免侵犯他人的合法权益。同时,在进行采集时应该先了解目标网站的使用条款和条件,以避免不必要的法律风险和经济损失。
相关文章:
爬虫采集如何解决ip被限制的问题呢?
在进行爬虫采集的过程中,很多开发者会遇到IP被限制的问题,这给采集工作带来了很大的不便。那么,如何解决这个问题呢?下面我们将从以下几个方面进行探讨。 一、了解网站的反爬机制 首先,我们需要了解目标网站的反爬机制…...

【ARM AMBA Q_Channel 详细介绍】
文章目录 1.1 Q_Channel 概述1.2 Q-Channel1.2.1 Q-Channel 接口1.2.2 Q-Channel 接口的握手状态1.2.3 握手信号规则 1.3 P_Channel的握手协议1.3.1 device 接受 PMU 的 power 请求1.3.2 device 拒绝 PMU 的 power 请求 1.4 device 复位信号与 Q _Channel 的结合1.4.1 RESETn 复…...
PDF Reader Pro v2.9.8(pdf编辑阅读器)
PDF Reader Pro是一款PDF阅读和编辑软件,具有以下特点: 界面设计简洁,易于上手。软件界面直观清晰,用户可以轻松浏览文档,编辑注释和填写表单。功能强大,提供了多种PDF处理工具,包括阅读、注释…...

【机器学习可解释性】1.模型洞察的价值
机器学习可解释性 1.模型洞察的价值2.排列的重要性3.部分图表4.SHAP Value5.SHAP Value 高级使用 正文 前言 本文是 kaggle上机器学习可解释性课程,共五部分,除第一部分介绍外,每部分包括辅导和练习。 此为第一部分,原文链接 如…...

网络安全保险行业面临的挑战与变革
保险业内大多数资产类别的数据可以追溯到几个世纪以前;然而,网络安全保险业仍处于初级阶段。由于勒索软件攻击、高度复杂的黑客和昂贵的数据泄漏事件不断增加,许多网络安全保险提供商开始感到害怕继续承保更多业务。 保险行业 根据最近的路…...

如何提高系统的可用性/高可用
提高系统可用性常用的一些方法,有缓存、异步、重试、幂等、补偿、熔断、降级、限流。 缓存 缓存的速度,比数据库快很多,添加缓存是简单有效的做法。 注意缓存与数据库的一致性,数据表记录变更时记得处理缓存。 Redis缓存的示例&…...
)
PCA和LDA数据降维计算(含数学例子推导过程)
PCA算法和LDA算法可以用于对数据进行降维,例如可以把一个2维的数据降低维度到一维,本文通过举例子来对PCA算法和LDA算法的计算过程进行教学展示。 PCA算法计算过程(文字版,想看具体计算下面有例子) 1.将原始数据排列成n行m列的矩阵…...
题目 1053: 二级C语言-平均值计算(python详解)——练气三层初期
✨博主:命运之光 🦄专栏:算法修炼之练气篇(C\C版) 🍓专栏:算法修炼之筑基篇(C\C版) 🍒专栏:算法修炼之练气篇(Python版) ✨…...
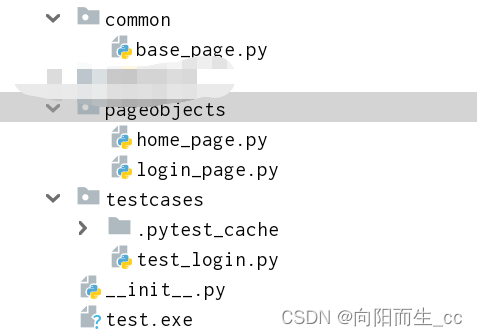
Python —— UI自动化之Page Object模式
1、Page Object模式简介 1、二层模型 Page Object Model(页面对象模型), 或者也可称之为POM。在UI自动化测试广泛使用的一种分层设计 模式。核心是通过页面层封装所有的页面元素及操作,测试用例层通过调用页面层操作组装业务逻辑。 1、实战 …...

职能篇—自动驾驶产品经理
自动驾驶产品开发流程 在讲自动驾驶产品经理之前,先简单了解一下自动驾驶的开发体系。如上图所示,从产品需求开始,经由系统需求、系统架构、软件需求、软件架构,最终分解到软件代码实现模块,再经由MIL、SIL、HIL、VIL完…...

ubuntu安装golang
看版本:https://go.dev/dl/ 下载: wget https://go.dev/dl/go1.21.3.linux-amd64.tar.gz卸载已有的go,可以apt remove go,也可以which go之后删除那个go文件,然后: rm -rf /usr/local/go && tar…...

ES 8 新特性
1. async 和 await async 和 await 两种语法结合可以让异步代码像同步代码一样。(即:看起来是同步的,实质上是异步的。) 先从字面意思理解,async 意为异步,可以用于声明一个函数前,该函数是异步的。await 意为等待,即等待一个异步方法完成。 1.1 async async 声明(…...

linux-防火墙
目录 一、防火墙概念 1.软件防火墙 2.iptables默认规则 3.iptables的五链 4.iptables动作 5.四表五链 6.iptables实例 一、防火墙概念 linux下防火墙一般分为软件防火墙、硬件防火墙 硬件防火墙:在硬件的级别实现防火墙过滤功能,性能高…...
Pytorch--3.使用CNN和LSTM对数据进行预测
这个系列前面的文章我们学会了使用全连接层来做简单的回归任务,但是在现实情况里,我们不仅需要做回归,可能还需要做预测工作。同时,我们的数据可能在时空上有着联系,但是简单的全连接层并不能满足我们的需求࿰…...
)
爬虫进阶-反爬破解9(下游业务如何使用爬取到的数据+数据和文件的存储方式)
一、下游业务如何使用爬取到的数据 (一)常用数据存储方案 1.百万级别数据:单机数据库,搭建和使用方便快捷,成本低 2.千万级别数据:负载均衡的多台数据库,安全和稳定 3.海量数据:…...

Docker常用应用部署
Docker常用应用部署 一、Ubuntu系统Docker快速安装 Docker官网安装文档:https://docs.docker.com/engine/install/ubuntu/ # 文本处理的流编辑器 -i直接修改读取的文件内容,而不是输出到终端 # sed -i s/原字符串/新字符串/ /home/1.txt # 下面这个是修…...
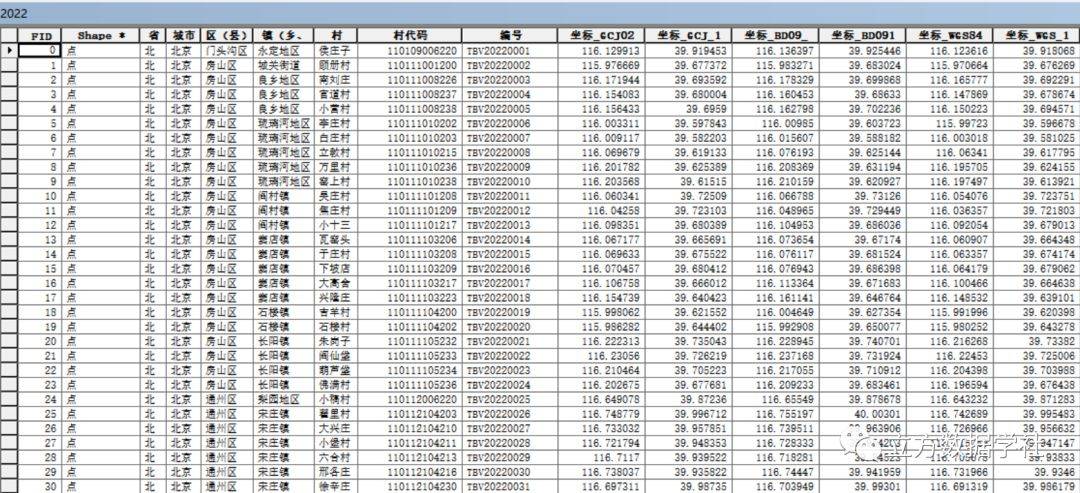
【数据分享】2014-2022年我国淘宝村点位数据(Excel格式/Shp格式)
电子商务是过去一二十年我国发展最快的行业,其中又以淘宝为代表,淘宝的发展壮大带动了一大批服务淘宝电子商务的村庄,这些村庄被称为淘宝村! 截至到目前,阿里研究院梳理并公布了2014-2022年共9个年份的淘宝村名单&…...
Ubuntu 安装 docker-compose
在Ubuntu上安装Docker Compose,可以按照以下步骤进行操作: 下载 Docker Compose 二进制文件 sudo curl -L "https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker…...

vue2、vue3中路由守卫变化
什么是路由守卫? 路由守卫就是路由跳转的一些验证,比如登录鉴权(没有登录不能进入个人中心页)等等等 路由守卫分为三大类: 全局守卫:前置守卫:beforeEach 后置钩子:afterEach 单个…...

Leetcode—547.省份数量【中等】
2023每日刷题(八) Leetcode—547.省份数量 实现代码 static int father[210] {0};int Find(int x) {if(x ! father[x]) {father[x] Find(father[x]);}return father[x]; }void Union(int x, int y) {int a Find(x);int b Find(y);if(a ! b) {fathe…...
)
极简风项目交付倒计时!:紧急修复MJ --v 6.2中隐藏的1.33倍宽高比偏移Bug,避免客户验收驳回(含补救Prompt包)
更多请点击: https://intelliparadigm.com 第一章:极简风项目交付倒计时! 当交付周期压缩至 72 小时,极简风不再是一种美学选择,而是工程效率的刚性约束。我们摒弃冗余文档、跳过非核心评审环节,聚焦于可…...

3步实现专业级AI换脸:roop-unleashed创新方案指南
3步实现专业级AI换脸:roop-unleashed创新方案指南 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed 在数字创意飞速发展的今天,AI换脸…...
研究(Matlab代码实现))
一种用于并网光伏系统的创新型多层逆变器,以降低总谐波失真(THD)研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...

开源技能库构建指南:Git+Markdown+Docsify打造个人技术知识体系
1. 项目概述:一个开源技能库的诞生与价值在技术领域,尤其是软件开发、运维和数据分析等方向,我们每天都在与海量的工具、框架和命令打交道。时间一长,一个很现实的问题就摆在了面前:那些曾经花了好几个小时才调通的复杂…...

百度网盘直链解析终极指南:如何实现高速下载的完整技术方案
百度网盘直链解析终极指南:如何实现高速下载的完整技术方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 在云存储服务普及的今天,百度网盘作为国内用…...

从开源物理拼图游戏学习Unity 2D物理引擎与游戏架构设计
1. 项目概述与核心价值 最近在GitHub上看到一个挺有意思的项目,叫“openclaw-puzzle-game”。光看名字,你可能会觉得这又是一个普通的开源拼图游戏,但点进去仔细研究后,我发现它的设计思路和实现方式,对于想学习游戏开…...

基于RAG的Obsidian智能插件:用AI对话重塑个人知识管理
1. 项目概述:当笔记遇上AI,一个插件如何重塑知识管理最近在折腾我的Obsidian知识库时,发现了一个让我眼前一亮的插件:Smart2Brain。这名字起得挺有意思,“Smart to Brain”,直译过来就是“从智能到大脑”。…...

轻量级HTTP代理monica-proxy:精准流量转发与多场景部署指南
1. 项目概述与核心价值最近在折腾一些需要跨网络环境访问特定服务的项目,发现一个挺有意思的工具叫ycvk/monica-proxy。这本质上是一个基于 Go 语言开发的轻量级 HTTP/HTTPS 代理服务器,但它和我们常见的那些“全能型”代理不太一样。它的设计初衷非常聚…...

fold命令行工具:高效文本数据聚合与分析的瑞士军刀
1. 项目概述:一个为“折叠”而生的高效工具 最近在折腾一些数据处理和文件整理的工作流时,我一直在寻找一个能让我“折叠”起来思考的工具。我说的“折叠”,不是物理上的,而是逻辑上的——把复杂的、多维度的信息,按照…...

Qwen2.5-14B实战指南:3个关键步骤突破本地大模型部署瓶颈
Qwen2.5-14B实战指南:3个关键步骤突破本地大模型部署瓶颈 【免费下载链接】Qwen2.5-14B 项目地址: https://ai.gitcode.com/hf_mirrors/ai-gitcode/Qwen2.5-14B 当开发者面对复杂的代码生成任务或技术文档分析需求时,往往会受限于云端API的延迟和…...