信息检索与数据挖掘 | 【实验】排名检索模型
文章目录
- 📚实验内容
- 📚相关概念
- 📚实验步骤
- 🐇分词预处理
- 🐇构建倒排索引表
- 🐇计算query和各个文档的相似度
- 🐇queries预处理及检索函数
- 🔥对输入的文本进行词法分析和标准化处理
- 🔥检索函数
- 🐇调试结果
📚实验内容
- 在Experiment1的基础上实现最基本的Ranked retrieval model
- Input:a query (like Ron Weasley birthday)
- Output: Return the top K (e.g., K = 100) relevant tweets.
- Use SMART notation: lnc.ltn
- Document: logarithmic tf (l as first character), no idf and cosine normalization
- Query: logarithmic tf (l in leftmost column), idf (t in second column), no normalization
- 改进Inverted index
- 在Dictionary中存储每个term的DF
- 在posting list中存储term在每个doc中的TF with pairs (docID, tf)
📚相关概念
- 信息检索与数据挖掘 | (五)文档评分、词项权重计算及向量空间模型
- 词项频率(term frequencey):t在文档中的出现次数。
- 文档集频率(collection frequency):词项在文档集中出现的次数。
- 文档频率(document frequency):出现t的所有文档的数目。
- 逆文档频率:
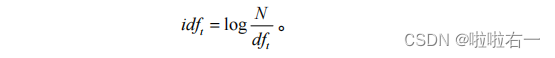
- t f − i d f t , d tf-idf_{t,d} tf−idft,d计算:
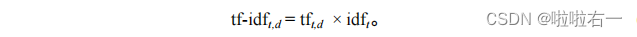

- 相似度计算:
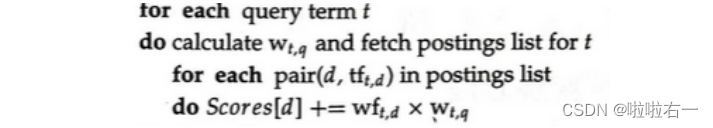
- 查询权重机制:

📚实验步骤
🐇分词预处理
-
将输入的推特文档转换为小写,这里统一处理,使得后续查询不区分大小写。
-
根据特定标记在推特文档中查找并确定关键部分信息的位置索引,并提取出推特文档中的tweetid和tweet内容。
-
对提取出的文本内容进行分词处理,并将单词转换为其单数形式。
-
对分词后的词列表进行词形还原,主要针对动词的还原操作。同时,筛去[“text”, “tweetid”]
-
将筛选出的有效词添加到最终结果列表中,并返回。
#分词预处理 def tokenize_tweet(document):# 统一处理使查询不区分大小写document = document.lower()# 根据特定标记在推特文档中查找并确定关键部分信息的位置索引# 这里的减1减3是对引号逗号切入与否的调整a = document.index("tweetid") - 1b = document.index("errorcode") - 1c = document.index("text") - 1d = document.index("timestr") - 3# 将推特文档中的tweetid和text内容主要信息提取出来document = document[a:b] + document[c:d]# 分词处理,并将单词转换为其单数形式terms = TextBlob(document).words.singularize()# 将分词后的词列表进行词形还原,并筛选出不属于无用词的有效词result = []for word in terms:# 将当前词转换为Word对象expected_str = Word(word)# 动词的还原操作expected_str = expected_str.lemmatize("v")if expected_str not in uselessTerm:# 筛去["text", "tweetid"],添加到result中result.append(expected_str)return result
🐇构建倒排索引表
- 存储term在每个doc中的TF with pairs (docID, tf)。

- 首先明确,在该过程计算文档词项的对应权重,采用lnc规则,即
logarithmic tf (l as first character), no idf and cosine normalization。 - 具体流程如下:
- 读取内容。文件中每行都代表一条推特。将每一行推特文本分解为单词(词条化),并存储在一个列表line中
- 利用一个全局变量N记录读取的推特文档数量。
- 从line中提取tweetid,并从line中删除。
- 创建一个空字典tf用于统计每个词在当前文档中的出现次数。遍历line中的每个词,通过判断词是否已经在tf字典的键中存在来更新词的出现次数。
- 对tf字典中的每个词项频率进行logarithmic tf的计算,即将出现次数加1并取对数。(对应
logarithmic tf (l as first character)) - 归一化(对应
cosine normalization),遍历tf字典的键(即词项),得到归一化因子。最后,代码再次遍历tf字典的键,并将每个词项的频率乘以归一化因子。得到最后的对应tf权重。 - 将line转换为集合unique_terms并遍历其中的每个词。
- 如果该词已经在postings字典的键中存在,则更新该词对应的字典项,将tweetid和权重加入其中。
- 如果该词不存在于postings字典的键中,则创建该键,并将tweetid和权重加入其中。
- 统计词频频率
# 统计词项频率,记录每个词在当前文档中的出现次数 tf = {}for word in line:if word in tf.keys():tf[word] += 1else:tf[word] = 1 - 1 + l o g ( t f t , d ) 1+log(tf_{t,d}) 1+log(tft,d)
# logarithmic tffor word in tf.keys():tf[word] = 1 + math.log(tf[word]) - 1 w 1 2 + w 2 2 + . . . + w m 2 \frac{1}{\sqrt{{w_1}^2+{w_2}^2+...+{w_m}^2}} w12+w22+...+wm21
# 归一化,cosine normalizationcosine = 0for word in tf.keys():cosine = cosine + tf[word] * tf[word]cosine = 1.0 / math.sqrt(cosine)for word in tf.keys():tf[word] = tf[word] * cosine
🐇计算query和各个文档的相似度
- 首先明确,该过程分为两个步骤,首先计算query词项的对应权重,然后求相似度(也即对应词项两个权重相乘并求和)并降序排序。Query权重采用ltn规则,即
logarithmic tf (l in leftmost column), idf (t in second column), no normalization。 - 具体流程如下:
- 遍历查询词列表query,对每个词进行词项频率统计,将结果存储在tf中。
- 遍历tf字典的键(即查询词),根据每个词在postings中的文档频率(文档出现的次数)计算文档频率df。若一个词不在postings中,则将文档频率设置为全局变量 N(表示总的文档数量)。
- 计算权重
tf[word] = (math.log(tf[word]) + 1) * math.log(N / df),对应ltn(logarithmic tf, idf, no normalization)。 - 对于每个查询词,检查它是否postings字典中存在。若存在,则遍历该查询词的倒排索引(文档编号及对应的词项权重),根据每个文档的词项权重和查询词的tf-idf值计算相似度得分。
- 存储得分并进行降序排序,得到一个按照相似度排名的列表,并将其返回作为结果。
def similarity(query):global score_tidtf = {}# 统计词项频率for word in query:if word in tf:tf[word] += 1else:tf[word] = 1# 统计文档频率for word in tf.keys():if word in postings:df = len(postings[word])else:df = N# 对应ltn,logarithmic tf (l in leftmost column), idf (t in second column), no normalizationtf[word] = (math.log(tf[word]) + 1) * math.log(N / df)# 计算相似度for word in query:if word in postings:for tid in postings[word]:if tid in score_tid.keys():score_tid[tid] += postings[word][tid] * tf[word]else:score_tid[tid] = postings[word][tid] * tf[word]# 按照得分(相似度)进行降序排序similarity = sorted(score_tid.items(), key=lambda x: x[1], reverse=True)return similarity
🐇queries预处理及检索函数
🔥对输入的文本进行词法分析和标准化处理
def token(doc):# 将输入文本转换为小写字母,以便统一处理。doc = doc.lower()# 将文本拆分为单个词项,并尝试将词项转换为单数形式terms = TextBlob(doc).words.singularize()# 将分词后的词列表进行词形还原,返回结果列表resultresult = []for word in terms:expected_str = Word(word)expected_str = expected_str.lemmatize("v")result.append(expected_str)return result
🔥检索函数
def Union(sets):return reduce(set.union, [s for s in sets])def do_search():query = token(input("please input search query >> "))result = []if query == []:sys.exit()# set()去除查询词列表中的重复项unique_query = set(query)# 生成一个包含每个查询词对应的tweet的id集合的列表,并且利用Union()函数将这些集合取并集relevant_tweetids = Union([set(postings[term].keys()) for term in unique_query])print("一共有" + str(len(relevant_tweetids)) + "条相关tweet!")if not relevant_tweetids:print("No tweets matched any query terms for")print(query)else:print("the top 100 tweets are:")scores = similarity(query)i = 1for (id, score) in scores:if i <= 100: # 返回前n条查询到的信息result.append(id)print(str(score) + ": " + id)i = i + 1else:breakprint("finished")
🐇调试结果
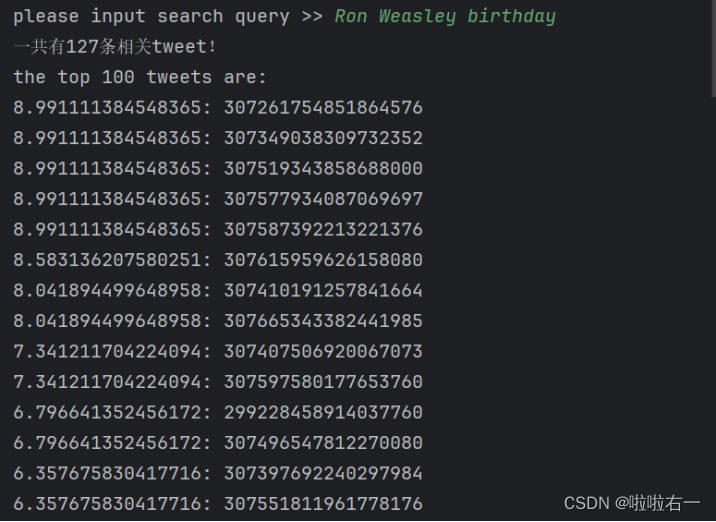
最终代码
import sys
from collections import defaultdict
from textblob import TextBlob
from textblob import Word
import math
from functools import reduceuselessTerm = ["text", "tweetid"]
# 构建倒排索引表,存储term在每个doc中的TF with pairs (docID, tf)
postings = defaultdict(dict)
# 文档数目N
N = 0
# 最终权值
score_tid = defaultdict(dict)#分词预处理
def tokenize_tweet(document):# 统一处理使查询不区分大小写document = document.lower()# 根据特定标记在推特文档中查找并确定关键部分信息的位置索引# 这里的减1减3是对引号逗号切入与否的调整a = document.index("tweetid") - 1b = document.index("errorcode") - 1c = document.index("text") - 1d = document.index("timestr") - 3# 将推特文档中的tweetid和text内容主要信息提取出来document = document[a:b] + document[c:d]# 分词处理,并将单词转换为其单数形式terms = TextBlob(document).words.singularize()# 将分词后的词列表进行词形还原,并筛选出不属于无用词的有效词result = []for word in terms:# 将当前词转换为Word对象expected_str = Word(word)# 动词的还原操作expected_str = expected_str.lemmatize("v")if expected_str not in uselessTerm:# 筛去["text", "tweetid"],添加到result中result.append(expected_str)return result# 构建倒排索引表,存储term在每个doc中的TF with pairs (docID, tf)
# lnc:logarithmic tf, no idf and cosine normalization
def get_postings():global postings, Ncontent = open(r"Tweets.txt")# 内容读取,每一条推特作为一个元素存储在lines中lines = content.readlines()for line in lines:N += 1# 预处理line = tokenize_tweet(line)# 提取处理后的词列表中的第一个元素,即推特文档的tweetidtweetid = line[0]# 提取后删除,不作为有效词line.pop(0)# 统计词项频率,记录每个词在当前文档中的出现次数tf = {}for word in line:if word in tf.keys():tf[word] += 1else:tf[word] = 1# logarithmic tffor word in tf.keys():tf[word] = 1 + math.log(tf[word])# 归一化,cosine normalizationcosine = 0for word in tf.keys():cosine = cosine + tf[word] * tf[word]cosine = 1.0 / math.sqrt(cosine)for word in tf.keys():tf[word] = tf[word] * cosine# 将处理后的词列表转换为集合,获取其中的唯一词unique_terms = set(line)for key_word in unique_terms:if key_word in postings.keys():postings[key_word][tweetid] = tf[key_word]else:postings[key_word][tweetid] = tf[key_word]# query标准化处理
def token(doc):# 将输入文本转换为小写字母,以便统一处理。doc = doc.lower()# 将文本拆分为单个词项,并尝试将词项转换为单数形式terms = TextBlob(doc).words.singularize()# 将分词后的词列表进行词形还原,返回结果列表resultresult = []for word in terms:expected_str = Word(word)expected_str = expected_str.lemmatize("v")result.append(expected_str)return result# 计算query和各个文档的相似度
def similarity(query):global score_tidtf = {}# 统计词项频率for word in query:if word in tf:tf[word] += 1else:tf[word] = 1# 统计文档频率for word in tf.keys():if word in postings:df = len(postings[word])else:df = N# 对应ltn,logarithmic tf (l in leftmost column), idf (t in second column), no normalizationtf[word] = (math.log(tf[word]) + 1) * math.log(N / df)# 计算相似度for word in query:if word in postings:for tid in postings[word]:if tid in score_tid.keys():score_tid[tid] += postings[word][tid] * tf[word]else:score_tid[tid] = postings[word][tid] * tf[word]# 按照得分(相似度)进行降序排序similarity = sorted(score_tid.items(), key=lambda x: x[1], reverse=True)return similaritydef Union(sets):return reduce(set.union, [s for s in sets])def do_search():query = token(input("please input search query >> "))result = []if query == []:sys.exit()# set()去除查询词列表中的重复项unique_query = set(query)# 生成一个包含每个查询词对应的tweet的id集合的列表,并且利用Union()函数将这些集合取并集relevant_tweetids = Union([set(postings[term].keys()) for term in unique_query])print("一共有" + str(len(relevant_tweetids)) + "条相关tweet!")if not relevant_tweetids:print("No tweets matched any query terms for")print(query)else:print("the top 100 tweets are:")scores = similarity(query)i = 1for (id, score) in scores:if i <= 100: # 返回前n条查询到的信息result.append(id)print(str(score) + ": " + id)i = i + 1else:breakprint("finished")def main():get_postings()while True:do_search()if __name__ == "__main__":main()
参考博客:信息检索实验2- Ranked retrieval model
相关文章:
信息检索与数据挖掘 | 【实验】排名检索模型
文章目录 📚实验内容📚相关概念📚实验步骤🐇分词预处理🐇构建倒排索引表🐇计算query和各个文档的相似度🐇queries预处理及检索函数🔥对输入的文本进行词法分析和标准化处理…...

玩转AIGC:打造令人印象深刻的AI对话Prompt
玩转AIGC:打造令人印象深刻的AI对话Prompt 《玩转AIGC:打造令人印象深刻的AI对话Prompt》摘要引言正文良好的Prompt:引发AI深度交流的法宝 ✨探讨不同的提问方式1. 常规提问2. 创意提问 对话交流的艺术:倾听与引导的巧妙平衡 ⚖️…...

uniapp vue国际化 i18n
一、安装 vue-i18n npm i vue-i18n 二、新建i18n目录 1、en.json 内容 {"loginPage":{"namePh":"Please enter your login account","passwordPh":"Please enter password"} } 2、zh-CN.json 内容 {"loginPage&qu…...

Docker 启动远程服务访问不了
今天一下午在弄这个 1、防火墙是否关了 firewall-cmd --state2、ip转发开没开 sysctl net.ipv4.ip_forward3、service iptables是不是打开并拦截了 4、检查docker启动的端口号是否一致,或者启动时对不对 5、检查docker的服务是否起来了,比如你的端口号…...
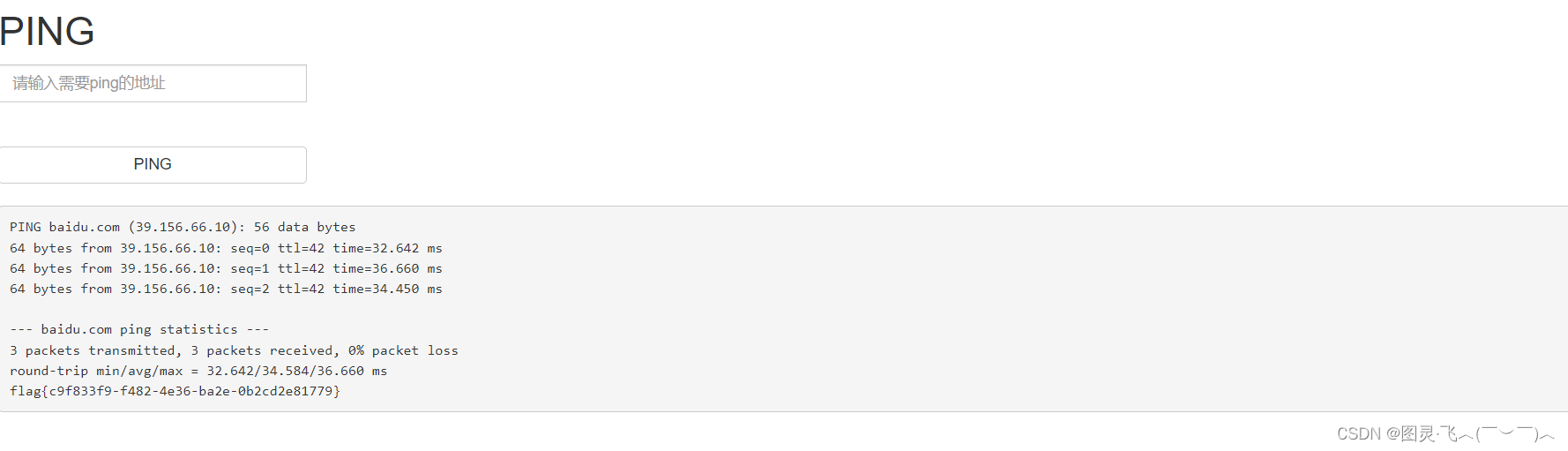
[ACTF2020 新生赛]Exec
【解题过程】 1.打开链接 得到一个能ping 的网站,可以推测这个可以在终端运行的网站。 2.解题思路 在执行的时候我们可以想到命令执行的“;”分号的作用:命令用分号分隔开来,表示它们是两个独立的命令,需要依次执行。…...

Git(三).git 文件夹详解
目录 一、初始化新仓库二、.git 目录2.1 hooks 文件夹2.2 info 文件夹2.3 logs 文件夹2.4 objects 文件夹【重要】2.5 refs 文件夹【重要】2.6 COMMIT_EDITMSG2.7 config2.8 description2.9 FETCH_HEAD2.10 HEAD【重要】2.11 index【重要】2.12 ORIG_HEAD2.13 packed-refs 官网…...

esp32-S3 + visual studio code 开发环境搭建
一、首先在下面链接网页中下载esp-idf v5.1.1离线安装包 ,并安装到指定位置。dl.espressif.cn/dl/esp-idf/https://dl.espressif.cn/dl/esp-idf/ 安装过程中会提示需要长路径支持,所以windows系统需要开启长路径使能 Step 1: 打开运行&…...

4.1 网络基础之网络IO
一、编写基本服务程序流程 1、创建套接字 #include <sys/types.h> #include <sys/socket.h>int socket(int domain, int type, int protocol);/* * 参数domain通讯协议族: * PF_INET IPv4互联网协议族(常用) * PF_INET6 …...
)
[100天算法】-和为 K 的子数组(day 39)
题目描述 给定一个整数数组和一个整数 k,你需要找到该数组中和为 k 的连续的子数组的个数。示例 1 :输入:nums [1,1,1], k 2 输出: 2 , [1,1] 与 [1,1] 为两种不同的情况。 说明 :数组的长度为 [1, 20,000]。 数组中元素的范围是 [-1000, 1000] ,且整…...

Leo赠书活动-02期 【信息科技风险管理:合规管理、技术防控与数字化】
✅作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人😉😉 🍎个人主页:Leo的博客 💞当前专栏: 赠书活动专栏 ✨特色专栏:…...

L2-026 小字辈 - java
L2-026 小字辈 时间限制 400 ms 内存限制 64 MB 题目描述: 本题给定一个庞大家族的家谱,要请你给出最小一辈的名单。 输入格式: 输入在第一行给出家族人口总数 N(不超过 100 000 的正整数) —— 简单起见,…...
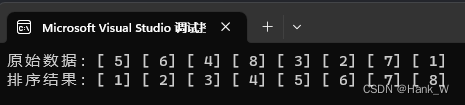
排序算法-堆积树排序法(HeapSort)
目录 排序算法-堆积树排序法(HeapSort) 1、说明 2、算法分析 3、C代码 排序算法-堆积树排序法(HeapSort) 1、说明 堆积树排序法是选择排序法的改进版,可以减少在选择排序法中的比较次数,进而减少排序…...

名词解释 MongoDB
MongoDB 是一个面向文档的数据库管理系统,它不使用传统的表格结构,而是将数据组织成类似文档的形式,通常使用JSON格式。 文档数据库:数据以文档的形式存储,每个文档可以包含不同的字段,就像一个文件可以包…...
)
Look Back(cf div3 905)
题意:给你一个长度为n((1≤n≤10^5)数组a[],你可以进行一个操作 使a[i]a[i]*2,问最少经过多少次这样的操作使的a[]不递减,a[i]>a[i-1]。 输入样例: 6 1 1 2 1 1 3 1 2 1 4 2 3 2 1 5 4 5 4 5 4 10 1 7 7 2 3 4 3 2 1 100 输出…...

Spring框架的发展历程
Spring框架的发展历程 自2004年以来,Spring框架已经成为Java开发人员最受欢迎的开源框架之一。它提供了一个全面的编程和配置模型,旨在简化企业级Java应用程序的开发过程。本文将详细介绍Spring框架的发展历程,以及它如何为Java开发人员提供…...

vue 级联查询5级--省/市/区/街道/社区
<template> <div> 1234 <el-select v-model="provinceVal" @change="selectProvinceFn" placeholder="请选择"> <el-option v-for="item in provinceList" :key="item.code" :label="item.name&q…...
 | 互斥量)
C++并发与多线程(8) | 互斥量
一、互斥量(mutex)的基本概念 互斥量(Mutex)是一种用于多线程编程的同步机制,用于管理共享资源的访问,以确保线程之间不会同时访问某个共享资源,从而避免竞态条件(Race Condition)和数据损坏。下面是互斥量的基本概念: 互斥性(Mutual Exclusion):互斥量用于确保一…...
Power BI 傻瓜入门 3. 选择Power BI的版本
本章内容包括: Excel与Power BI的比较选择Power BI的桌面版和服务版之间的差异了解Microsoft提供的许可选项 挑选正确版本的Power BI可能就像参观世界上最大的糖果店:你可以从许多细微差别的替代品中进行选择。选择可以归结为想要、需要、规模…...

BadNets:基于数据投毒的模型后门攻击代码(Pytorch)以MNIST为例
加载数据集 # 载入MNIST训练集和测试集 transform transforms.Compose([transforms.ToTensor(),]) train_loader datasets.MNIST(rootdata,transformtransform,trainTrue,downloadTrue) test_loader datasets.MNIST(rootdata,transformtransform,trainFalse) # 可视化样本 …...
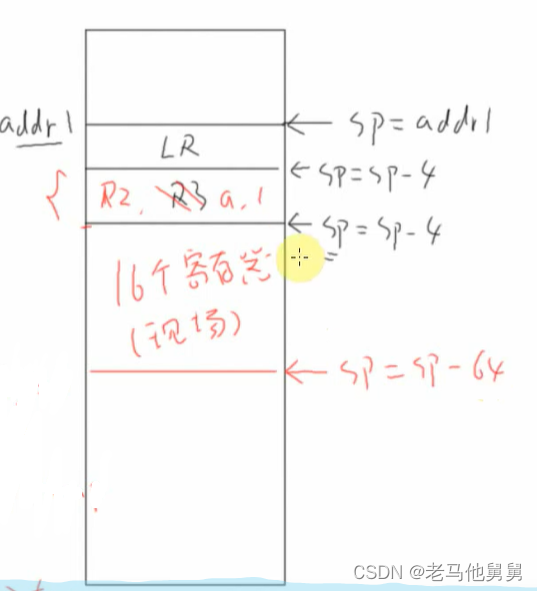
freeRTOS内部机制——栈的作用
上图中*pa 和*pb分别为R0,R1,调用C函数时,第一个参数保存在R0中第二个参数保存在R1中。这是约定。 指令保存在哪里? 指令保存在flash上面 LR等于什么? LR是返回地址,函数执行完了过后LR等于下一条指令的地址 运行…...

告别ET1100?聊聊AX58100这颗高性价比EtherCAT从站芯片的升级体验
告别ET1100?AX58100高性价比EtherCAT从站芯片的工业升级实战 当工业设备制造商面临从传统控制架构向实时以太网迁移时,EtherCAT从站芯片的选型往往成为关键转折点。十年前,ET1100凭借其稳定的性能和相对友好的开发门槛,成为许多工…...

如何快速免费管理游戏DLSS版本?DLSS Swapper终极指南
如何快速免费管理游戏DLSS版本?DLSS Swapper终极指南 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款革命性的开源工具,专为PC游戏玩家设计,能够智能管理、下载和…...

轻量级HTTP代理monica-proxy:精准流量转发与多场景部署指南
1. 项目概述与核心价值最近在折腾一些需要跨网络环境访问特定服务的项目,发现一个挺有意思的工具叫ycvk/monica-proxy。这本质上是一个基于 Go 语言开发的轻量级 HTTP/HTTPS 代理服务器,但它和我们常见的那些“全能型”代理不太一样。它的设计初衷非常聚…...
,现在必须掌握的3种替代渲染方案)
像素艺术家紧急预警:Midjourney即将关闭--tile参数兼容性(倒计时14天),现在必须掌握的3种替代渲染方案
更多请点击: https://intelliparadigm.com 第一章:像素艺术家紧急预警:Midjourney即将关闭--tile参数兼容性(倒计时14天) Midjourney v6.5 已正式宣布将于 14 天后终止对 --tile 参数的原生支持,此举将直…...

防火墙和手动启动都试了?ArcGIS License Server无响应,可能是这两个核心文件在捣鬼
ArcGIS许可服务故障深度解析:当核心文件成为隐形杀手 当你面对ArcGIS License Server无响应的红色报错框,已经尝试了关闭防火墙、调整服务配置、甚至重启服务器等一系列标准操作后,那个令人沮丧的"cannot connect to license server sys…...

嵌入式动画优化:DMA驱动位图渲染在SAMD21上的实现
1. 项目概述与核心思路如果你玩过嵌入式开发,尤其是想在小小的微控制器屏幕上搞点流畅的动画,大概率会被“卡顿”和“闪屏”折磨过。传统的逐像素绘制,在需要全屏更新时,CPU时间几乎全耗在了等待屏幕刷新上,用户体验大…...

ANSYS APDL函数方程加载:从GUI操作到命令流集成的完整指南
1. 项目概述:为什么我们需要函数方程加载?在ANSYS的仿真世界里,我们经常遇到一个头疼的问题:载荷不是一成不变的。比如,一个大型储罐的侧壁,水压会随着深度线性增加;一个高速旋转的叶片…...

GitHub宝藏项目:生成式AI公司全景导航图与实战应用指南
1. 项目概述:一份AI创业公司的全景导航图最近在GitHub上闲逛,发现了一个宝藏仓库,名字叫“awesome-generative-ai-companies”。这个项目,说白了,就是一个由社区驱动的、持续更新的生成式AI公司名录。它不像那些商业咨…...

Arm Neoverse CMN-700架构与寄存器配置详解
1. Arm Neoverse CMN-700架构概览在现代多核处理器设计中,如何高效实现缓存一致性一直是核心挑战。Arm Neoverse CMN-700(Coherent Mesh Network)作为第二代一致性网格网络IP,采用分布式架构解决了从16核到256核规模的数据一致性问…...

别再只用高斯噪声了!手把手教你为DDPG算法注入‘惯性’:Ornstein-Uhlenbeck噪声的Python实现与调参实战
突破DDPG探索瓶颈:Ornstein-Uhlenbeck噪声的工程实践指南 在机器人控制或自动驾驶仿真这类连续动作空间的任务中,DDPG算法常因探索效率低下导致训练停滞。当智能体在MuJoCo环境中反复"原地踏步"时,问题往往不在于算法本身…...