用Python做数据分析之数据筛选及分类汇总
1、按条件筛选(与,或,非)
为数据筛选,使用与,或,非三个条件配合大于,小于和等于对数据进行筛选,并进行计数和求和。与 excel 中的筛选功能和 countifs 和 sumifs 功能相似。
Excel 数据目录下提供了“筛选”功能,用于对数据表按不同的条件进行筛选。Python 中使用 loc 函数配合筛选条件来完成筛选功能。配合 sum 和 count 函数还能实现 excel 中 sumif 和 countif 函数的功能。
1)使用“与”条件进行筛选
条件是年龄大于 25 岁,并且城市为 beijing。筛选后只有一条数据符合要求。
1#使用“与”条件进行筛选
2df_inner.loc[(df_inner[‘age’] > 25) & (df_inner[‘city’] == ‘beijing’), [‘id’,‘city’,‘age’,‘category’,‘gender’]]
2)使用“或”条件进行筛选
年龄大于 25 岁或城市为 beijing。筛选后有 6 条数据符合要求。
1#使用“或”条件筛选
2df_inner.loc[(df_inner[‘age’] > 25) | (df_inner[‘city’] == ‘beijing’), [‘id’,‘city’,‘age’,‘category’,‘gender’]].sort
3([‘age’])
3)求和
在前面的代码后增加 price 字段以及 sum 函数,按筛选后的结果将 price 字段值进行求和,相当于 excel 中 sumifs 的功能。
1 #对筛选后的数据按 price 字段进行求和
2 df_inner.loc[(df_inner[‘age’] > 25) | (df_inner[‘city’] == ‘beijing’),
3 [‘id’,‘city’,‘age’,‘category’,‘gender’,‘price’]].sort([‘age’]).price.sum()
4)使用“非”条件进行筛选
城市不等于 beijing。符合条件的数据有 4 条。将筛选结果按 id 列进行排序。
1#使用“非”条件进行筛选
2df_inner.loc[(df_inner[‘city’]
!= ‘beijing’), [‘id’,‘city’,‘age’,‘category’,‘gender’]].sort([‘id’])
在前面的代码后面增加 city 列,并使用 count 函数进行计数。相当于 excel 中的 countifs 函数的功能。
1#对筛选后的数据按 city 列进行计数
2df_inner.loc[(df_inner[‘city’]
!= ‘beijing’), [‘id’,‘city’,‘age’,‘category’,‘gender’]].sort([‘id’]).city.count()
还有一种筛选的方式是用 query 函数。下面是具体的代码和筛选结果。
1#使用 query 函数进行筛选
2df_inner.query(‘city == [‘beijing’, ‘shanghai’]’)
在前面的代码后增加 price 字段和 sum 函数。对筛选后的 price 字段进行求和,相当于 excel 中的 sumifs 函数的功能。
1 #对筛选后的结果按 price 进行求和
2 df_inner.query(‘city == [‘beijing’, ‘shanghai’]’).price.sum()
3 12230
2、数据汇总
接下来是对数据进行分类汇总,Excel 中使用分类汇总和数据透视可以按特定维度对数据进行汇总,python 中使用的主要函数是 groupby 和 pivot_table。下面分别介绍这两个函数的使用方法。
1)分类汇总
Excel 的数据目录下提供了“分类汇总”功能,可以按指定的字段和汇总方式对数据表进行汇总。Python 中通过 Groupby 函数完成相应的操作,并可以支持多级分类汇总。
Groupby 是进行分类汇总的函数,使用方法很简单,制定要分组的列名称就可以,也可以同时制定多个列名称,groupby 按列名称出现的顺序进行分组。同时要制定分组后的汇总方式,常见的是计数和求和两种。
1 #对所有列进行计数汇总
2 df_inner.groupby(‘city’).count()
可以在 groupby 中设置列名称来对特定的列进行汇总。下面的代码中按城市对 id 字段进行汇总计数。
1 #对特定的 ID 列进行计数汇总
2 df_inner.groupby(‘city’)[‘id’].count()
3 city
4 beijing 2
5 guangzhou 1
6 shanghai 2
7 shenzhen 1
8 Name: id, dtype: int64
在前面的基础上增加第二个列名称,分布对 city 和 size 两个字段进行计数汇总。
1 #对两个字段进行汇总计数
2 df_inner.groupby([‘city’,‘size’])[‘id’].count()
3 city size
4 beijing A 1
5 F 1
6 guangzhou A 1
7 shanghai A 1
8 B 1
9 shenzhen C 1
10 Name: id, dtype: int64
除了计数和求和外,还可以对汇总后的数据同时按多个维度进行计算,下面的代码中按城市对 price 字段进行汇总,并分别计算 price 的数量,总金额和平均金额。
1 #对 city 字段进行汇总并计算 price 的合计和均值。
2 df_inner.groupby(‘city’)[‘price’].agg([len,np.sum, np.mean])
2)数据透视
Excel 中的插入目录下提供“数据透视表”功能对数据表按特定维度进行汇总。Python 中也提供了数据透视表功能。通过 pivot_table 函数实现同样的效果。
数据透视表也是常用的一种数据分类汇总方式,并且功能上比 groupby 要强大一些。下面的代码中设定 city 为行字段,size 为列字段,price 为值字段。分别计算 price 的数量和金额并且按行与列进行汇总。
1 #数据透视表
2pd.pivot_table(df_inner,index=[‘city’],values=[‘price’],columns=[‘size’],aggfunc=[len,np.sum],fill_value=0,margins=True)
文章来源:网络 版权归原作者所有
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系小编,我们将立即处理
相关文章:

用Python做数据分析之数据筛选及分类汇总
1、按条件筛选(与,或,非) 为数据筛选,使用与,或,非三个条件配合大于,小于和等于对数据进行筛选,并进行计数和求和。与 excel 中的筛选功能和 countifs 和 sumifs 功能相似…...
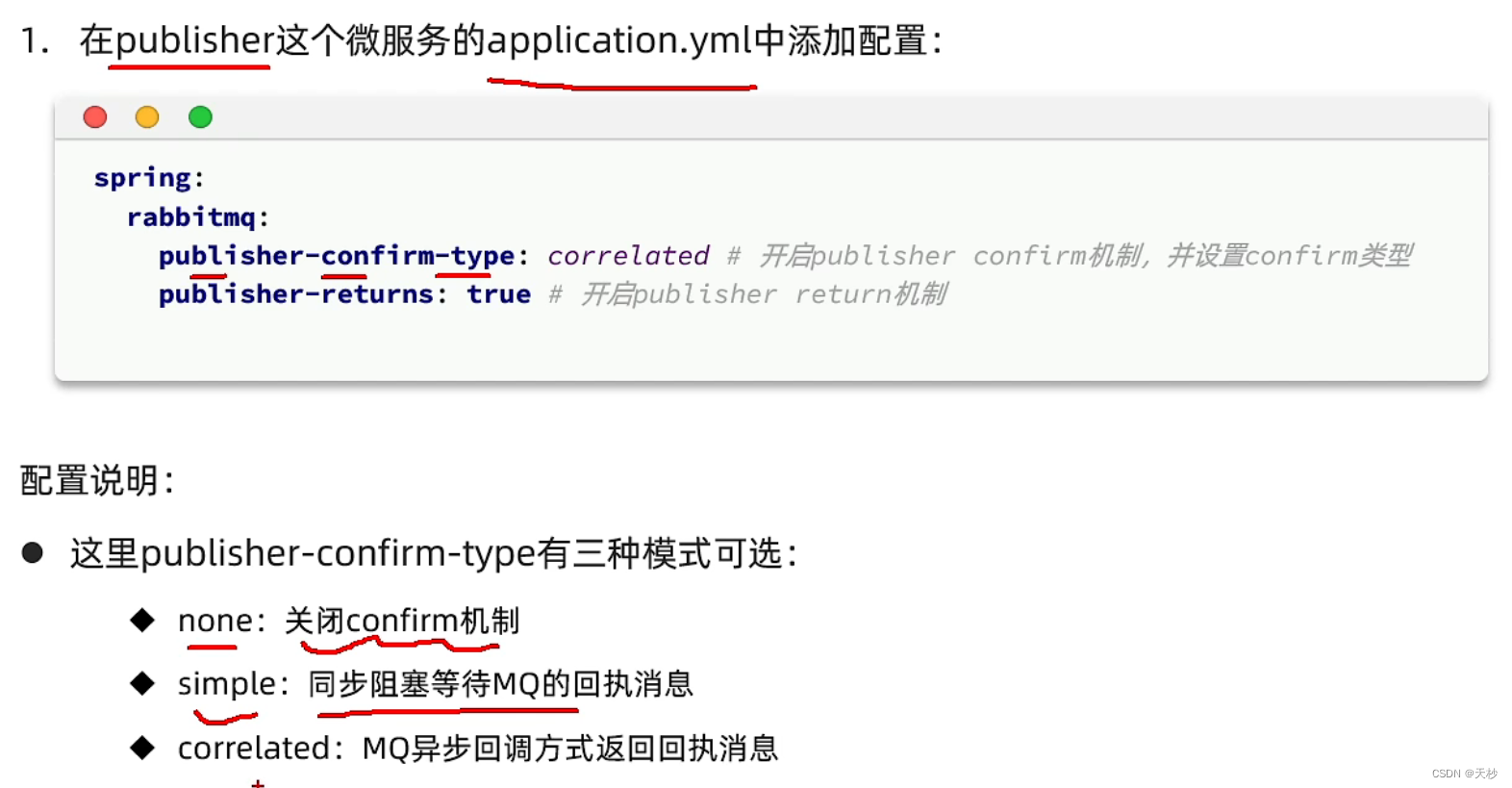
RabbitMQ高级篇 笔记
这是一些高级的内容。 RabbitMQ还是运行在网络上的,倘若遇到了网络故障,mq自己挂了,出异常了,都会造成最终状态不一致的问题。这就是可靠性问题。 可靠性:一个消息发送出去之后,至少被消费1次。 要解决这3个…...
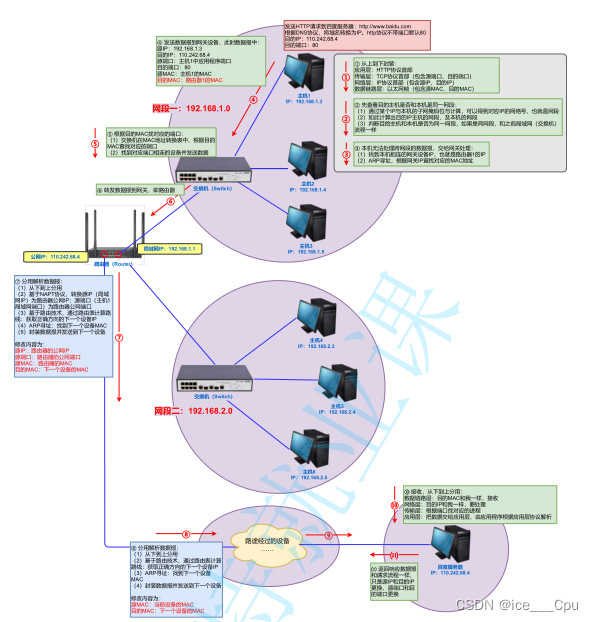
javaEE -9(7000字详解TCP/IP协议)
一: IP 地址 IP地址(Internet Protocol Address)是指互联网协议地址,又译为网际协议地址。 IP地址是IP协议提供的一种统一的地址格式,它为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物…...

在mybatis的xml中使用枚举来做判断条件
1.枚举类 import com.baomidou.mybatisplus.annotation.IEnum; import com.fasterxml.jackson.annotation.JsonCreator; import com.fasterxml.jackson.annotation.JsonValue; import com.shinkeer.common.utils.StringUtils;import java.util.HashMap; import java.util.Map;…...

scala集合的partition方法使用
在Scala中,partition 方法用于将集合(例如 List、Array ,Set等)中的元素根据给定的条件分成两个部分,并返回一个元组,其中包含两个新的集合,第一个包含满足条件的元素,另一个包含不满…...
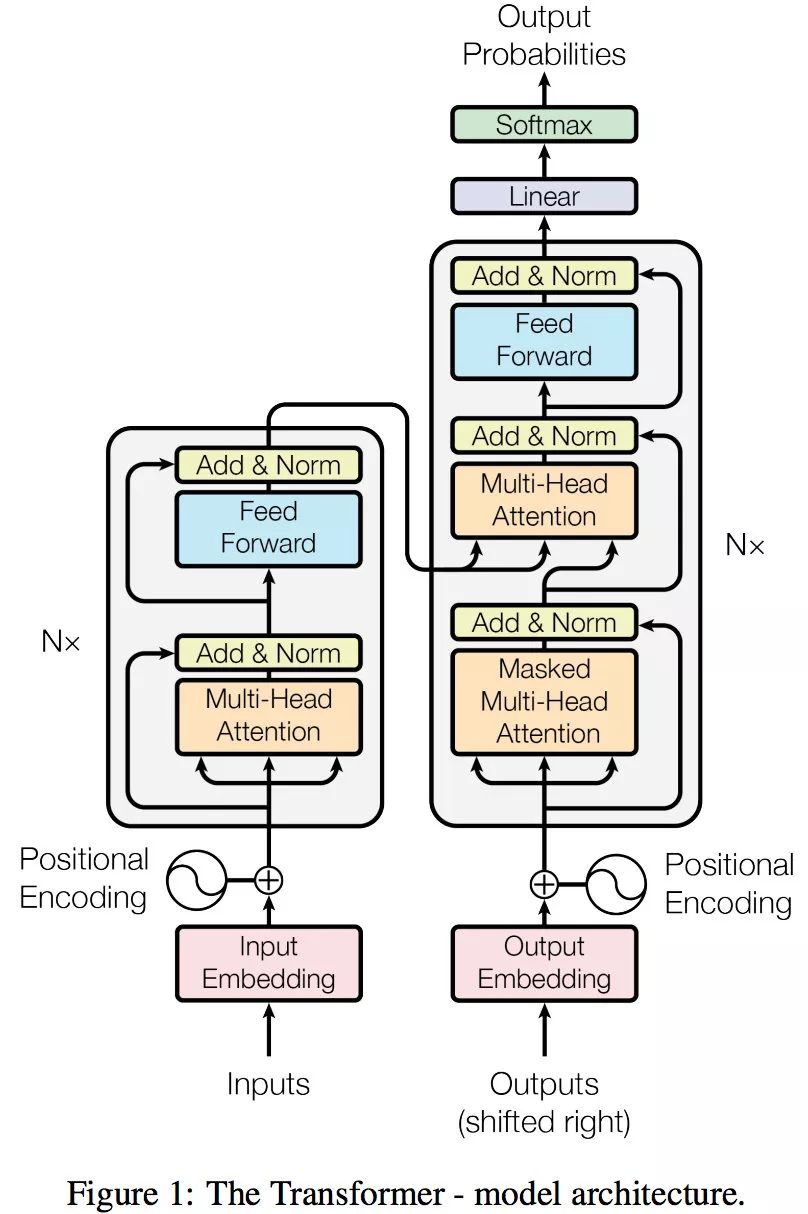
18 Transformer 的动态流程
博客配套视频链接: https://space.bilibili.com/383551518?spm_id_from333.1007.0.0 b 站直接看 配套 github 链接:https://github.com/nickchen121/Pre-training-language-model 配套博客链接:https://www.cnblogs.com/nickchen121/p/15105048.html 机…...
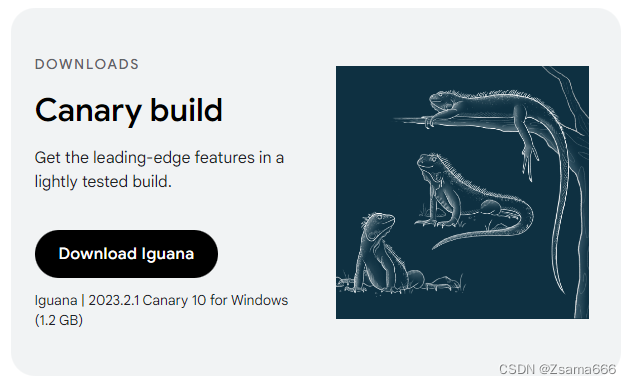
Android Studio新功能-设备镜像Device mirroring-在电脑侧显示手机实时画面并可控制
下载最新的灰测版本-蜥蜴 成功运行到真机后,点击右侧Running Devices选项卡,再点击号 选中当前设备; 非常丝滑同步,在电脑侧也可以顺畅控制真机 该功能大大方便了我们视线保持在显示器上专注开发,并且便于与UI视觉进行…...

MySQL身份验证绕过漏洞
搭建 vmihub靶场:vulhub靶场搭建与使用_剁椒鱼头没剁椒的博客-CSDN博客 运行漏洞: # 这里要改成自己的 /vulhub-master 存放目录 cd /etc/docker/vulhub-master/mysql/CVE-2012-2122# 关闭防火墙,不然就要放行3306端口 systemctl stop firewalld# 重启 Docker 服务 servic…...

0基础学习PyFlink——不可以用UDTAF装饰器装饰function的原因分析
在研究Flink的“用户自定义方法”(UserDefinedFunction)时,我们看到存在如下几种类型的装饰器: UDF:User Defined Scalar FunctionUDTF:User Defined Table FunctionUDAF:User Defined Aggrega…...

Spring Boot Endpoints:端点
Spring Boot 内置端点以及暴露端点列表: 端点被启用后,并不一定能够被访问,还要看端点是否被暴露,并且暴露的方式是怎样的。因为端点可能会包含敏感信息,所以需要谨慎暴露相关端点。Spring Boot 3.0.0 更改了默认暴露…...
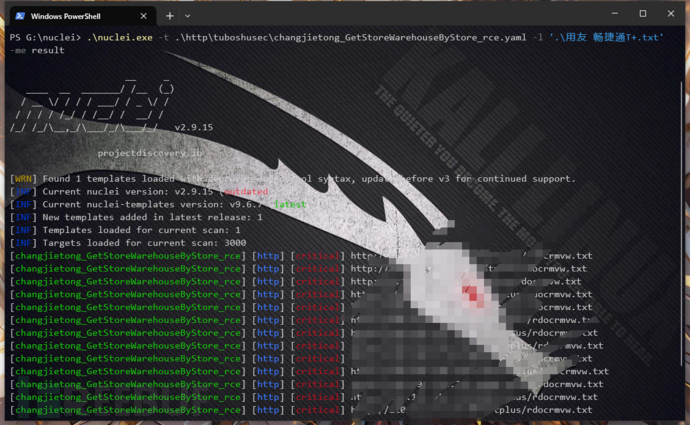
漏洞复现--用友 畅捷通T+ .net反序列化RCE
免责声明: 文章中涉及的漏洞均已修复,敏感信息均已做打码处理,文章仅做经验分享用途,切勿当真,未授权的攻击属于非法行为!文章中敏感信息均已做多层打马处理。传播、利用本文章所提供的信息而造成的任何直…...

PHP 共享茶室棋牌室无人软硬件结合开发小程序系统的开发优势
随着科技的发展和人们生活方式的改变,共享经济和智能化成为了越来越受欢迎的趋势。在这样一个背景下,PHP共享茶室棋牌室无人软硬件结合开发小程序系统的出现,为人们提供了一种全新的娱乐和生活方式。本文将详细介绍PHP共享茶室棋牌室无人软硬…...
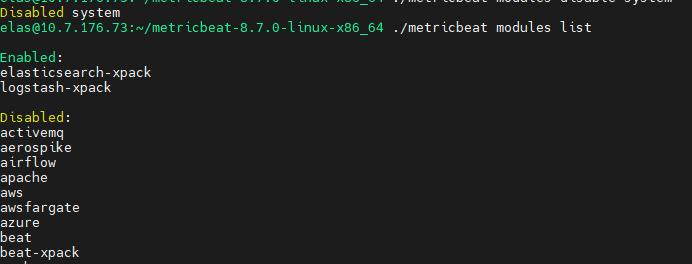
kibana监控
采取方式 Elastic Agent :更完善的功能 Metricbeat:轻量级指标收集(采用) 传统收集方法:使用内部导出器收集指标,已不建议 安装 metricbeat Download Metricbeat • Ship Metrics to Elasticsearch | E…...

基于 ARM+FPGA+AD平台的多类型同步信号采集仪开发及试验验证(二)板卡总体设计
2.2 板卡总体设计 本章开发了一款基于 AD7193RJ45 的多类型传感信号同步调理板卡,如图 2.4 所 示,负责将传感器传来的模拟电信号转化为数字信号,以供数据采集系统采集,实现了 单通道自由切换传感信号类型与同步采集多类型传…...

uniapp: 本应用使用HBuilderX x.x.xx 或对应的cli版本编译,而手机端SDK版本是 x.x.xx。不匹配的版本可能造成应用异常。
文章目录 前言一、原因分析二、解决方案2.1、方案一:更新HbuilderX版本2.2、方案二:设置固定的版本2.3、方案三:忽略版本(不推荐) 三、总结四、感谢 前言 项目场景:示例:通过使用HbuilderX打包…...
sqoop和flume简单安装配置使用
1. Sqoop 1.1 Sqoop介绍 Sqoop 是一个在结构化数据和 Hadoop 之间进行批量数据迁移的工具 结构化数据可以是MySQL、Oracle等关系型数据库 把关系型数据库的数据导入到 Hadoop 与其相关的系统 把数据从 Hadoop 系统里抽取并导出到关系型数据库里 底层用 MapReduce 实现数据 …...

什么是React Router?它的作用是什么?
聚沙成塔每天进步一点点 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 欢迎来到前端入门之旅!感兴趣的可以订阅本专栏哦!这个专栏是为那些对Web开发感兴趣、刚刚踏入前端领域的朋友们量身打造的。无论你是完全的新手还是有一些基础的开发…...
界面控件DevExtreme v23.1 - UI组件 UI模板库增强
DevExtreme拥有高性能的HTML5 / JavaScript小部件集合,使您可以利用现代Web开发堆栈(包括React,Angular,ASP.NET Core,jQuery,Knockout等)构建交互式的Web应用程序。从Angular和Reac,…...

Fedora Linux 38下Mariadb数据库设置utf8mb4字符编码
Fedora操作系统之下最好使用开源免费的MySQL替代品Mariadb来学习MySQL的知识,一点也不会耽搁。 连接上互联网后,打开shell命令行界面,Sudo dnf install mariadb-server mariadb -y就可以安装好 mariadb-server和 mariadb࿰…...
【单元测试】--高级主题
一、模拟与存根深入 在单元测试中,模拟(Mock)和存根(Stub)是两种常用的测试替代品,用于模拟外部依赖或模拟特定行为,以便测试能够独立运行。以下是深入了解模拟与存根的概念,以NUni…...

10xGenomics单细胞测序选3‘还是5‘?一文讲清免疫组库与基因表达分析的黄金选择
10xGenomics单细胞测序:3与5端策略在免疫组库与基因表达分析中的科学抉择 当实验室的离心机停止运转,科研人员往往面临一个关键抉择:该选择3还是5端单细胞测序?这个看似技术性的选择,实则直接影响着后续免疫组库分析的…...

OpenClaw主控Agent配置:任务分发、流程调度,打造专属SEO自动化团队
构建智能中枢:OpenClaw主控Agent的深度配置与SEO自动化团队实践引言在数字化营销日益激烈的今天,搜索引擎优化(SEO)已成为企业获取流量、提升品牌曝光不可或缺的策略。然而,传统的SEO操作往往涉及大量重复性、耗时耗力…...

Speech Seaco Paraformer问题解决:识别不准?试试热词功能提升准确率
Speech Seaco Paraformer问题解决:识别不准?试试热词功能提升准确率 1. 语音识别不准的常见困扰 语音识别技术在日常工作和生活中应用越来越广泛,但很多用户在使用过程中都会遇到一个共同问题:识别结果不准确。特别是当录音内容…...

pingfs安全分析:ICMP存储的数据安全性与风险防护指南
pingfs安全分析:ICMP存储的数据安全性与风险防护指南 【免费下载链接】pingfs Stores your data in ICMP ping packets 项目地址: https://gitcode.com/gh_mirrors/pi/pingfs 在当今网络安全日益重要的时代,pingfs作为一个创新的文件系统项目&…...

ubuntu20.04设置开机自动登录适用与GNOME桌面环境
默认arm版本ubuntu20.04未安装nano编辑器,so我们要安装一下, sudo apt update && sudo apt install nano设置方法: sudo nano /etc/gdm3/custom.conf添加或修改,用户名区分大小写。 AutomaticLoginEnableTrue AutomaticLo…...

AV1编解码器实战:如何在Chrome 85+和Firefox 86中启用AVIF图片支持
AV1编解码器实战:如何在Chrome 85和Firefox 86中启用AVIF图片支持 AVIF(AV1 Image File Format)作为新一代图像格式,凭借AV1编解码器的强大压缩能力,正在逐步改变Web图像分发的格局。对于追求极致性能的前端开发者而言…...

vLLM-v0.17.1镜像部署实战:从零开始搭建大模型推理服务
vLLM-v0.17.1镜像部署实战:从零开始搭建大模型推理服务 1. vLLM框架简介 vLLM是一个专为大型语言模型(LLM)设计的高性能推理和服务库,它通过创新的内存管理和批处理技术,显著提升了LLM的推理效率和服务吞吐量。这个项目最初由加州大学伯克利…...

如何使用NoFences实现高效的Windows桌面图标管理
如何使用NoFences实现高效的Windows桌面图标管理 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences NoFences是一款开源免费的Windows桌面管理工具,专门用于解决桌面…...
这玩意儿挺有意思的,核心就仨部件:跟踪微分器、扩张观测器、非线性反馈。咱们直接上硬货,手撕代码看门道)
自抗扰控制(ADRC)这玩意儿挺有意思的,核心就仨部件:跟踪微分器、扩张观测器、非线性反馈。咱们直接上硬货,手撕代码看门道
基于扩张状态观测器的自抗扰控制ADRC仿真模型 ①跟踪微分器TD:为系统输入安排过渡过程,得到光滑的输入信号以及输入信号的微分信号。 ②非线性状态误差反馈律NLSEF:把跟踪微分器产生的跟踪信号和微分信号与扩张状态观测器得到的系统的状态估计通过非线性函数进行适当…...

FRP内网穿透实战:从零配置到远程访问
1. 为什么需要内网穿透? 想象一下这个场景:你在家里搭建了一个NAS私有云,存了几百部高清电影;或者你在办公室电脑上跑了个数据库服务,出差时想随时查看数据。这时候你会发现——这些服务都在内网环境里,离…...