MySQL——EXPLAIN用法详解
EXPLAIN是MySQL官方提供的sql分析的工具之一,可以用于模拟优化器执行sql查询语句,从而知道MySQL是如何处理sql语句。EXPLAIN主要用于分析查询语句或表结构的性能瓶颈。
以下是基于MySQL5.7.19版本进行分析的,不同版本之间略有差异。
1、EXPLAIN使用
explain+sql语句,通过执行explain可以获得sql语句执行的相关信息。
2、EXPLAIN包含的信息
| 列名 | 说明 |
|---|---|
| id | 执行编号,标识select所属的行。如果在语句中没子查询或关联查询,只有唯一的select,每行都将显示1。否则,内层的select语句一般会顺序编号,对应于其在原始语句中的位置 |
| select_type | 显示本行是简单或复杂select。如果查询有任何复杂的子查询,则最外层标记为PRIMARY(DERIVED、UNION、UNION RESUlT) |
| table | 访问引用哪个表(引用某个查询,如“user”) |
| partitions | 匹配的分区 |
| type | 数据访问/读取操作类型(ALL、index、range、ref、eq_ref、const/system、NULL) |
| possible_keys | 揭示哪一些索引可能有利于高效的查找 |
| key | 显示mysql决定采用哪个索引来优化查询 |
| key_len | 显示mysql在索引里使用的字节数 |
| ref | 显示了之前的表在key列记录的索引中查找值所用的列或常量 |
| rows | 为了找到所需的行而需要读取的行数,估算值,不精确。通过把所有rows列值相乘,可粗略估算整个查询会检查的行数 |
| filtered | 表示此查询条件所过滤的数据的百分比 |
| extra | 额外信息,如using index、filesort等 |
2.1 id
id是用来顺序标识整个查询中SELELCT语句的,在嵌套查询中id越大的语句越先执行。该值可能为NULL,如果这一行用来说明的是其他行的联合结果。大致分为下面几种情况:
(1)id相同,执行顺序由上至下
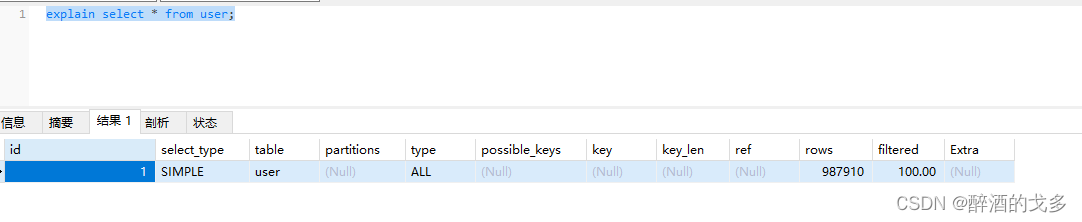
EXPLAIN select * from user,school,class where user.school_id = school.school_id and user.class_id = class.class_id
三个id都为1,表示具有相同的优先级,执行顺序由上而下,具体执行顺序由优化器决定,这里执行顺序为school,user,class。
(2)id不同,数字越大优先级越高
EXPLAIN select * from user where school_id = (select school_id from school where school_id = (select school_id from class where class_id = 2))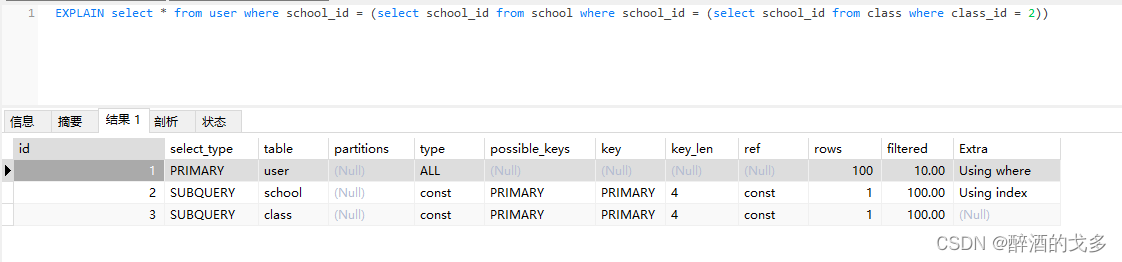 如果sql中存在子查询,那么id的序号会递增,id越大越先被执行。如上述查询,执行顺序是class、school、user,也就是说,最里面的子查询最先执行,由里往外执行。
如果sql中存在子查询,那么id的序号会递增,id越大越先被执行。如上述查询,执行顺序是class、school、user,也就是说,最里面的子查询最先执行,由里往外执行。
如果上述查询中的“=”换成“in”,则运行结果会发生变化,原因是每执行一次最外层子查询,里面的子查询都会被重复执行,这也就是sql优化中提到的尽量不要使用in关键字
使用in关键字示例:
EXPLAIN select * from user where school_id in (select school_id from school where school_id in (select school_id from class where class_id = 2))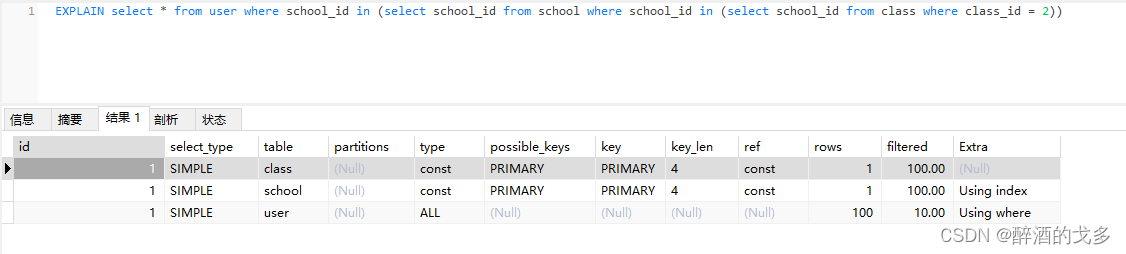
2.2 select_type
select_type表示查询的类型
| 类型 | 说明 |
| simple | 简单子查询,不包含子查询和union |
| primary | 包含union或者子查询,最外层的部分标记为primary |
| subquery | 一般子查询中的子查询被标记为subquery,也就是位于select列表中的查询 |
| derived | 派生表——该临时表是从子查询派生出来的,位于form中的子查询 |
| union | 位于union中第二个及其以后的子查询被标记为union,第一个就被标记为primary如果是union位于from中则标记为derived |
| union result | 用来从匿名临时表里检索结果的select被标记为union result |
EXPLAIN select * from user where school_id = (select school_id from school where school_id = (select school_id from class where class_id = 2))
2.3 table
table显示查询操作基于哪张表的。
EXPLAIN select user.* from user where school_id = (select school_id from school where school_id = 2)
union
select user.* from user where class_id = (select class_id from class where class_id = 2)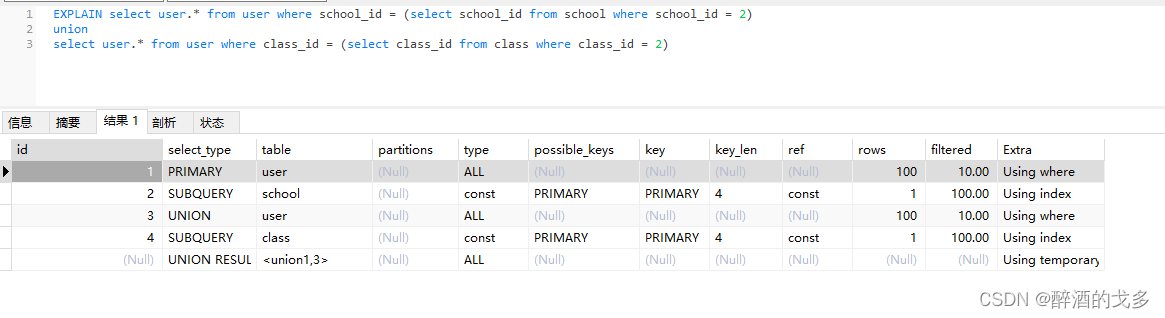
table列并不一定是真实存在的表,比如上面出现<union1,3>,一般来说会出现下面的取值:
- <union a,b>:输出结果中编号为 a 的行与编号为 b 的行的结果集的并集。
- < derived a>:输出结果中编号为 a 的行的结果集,derived 表示这是一个派生结果集,如 FROM 子句中的查询。
- < subquery a>:输出结果中编号为 a 的行的结果集,subquery 表示这是一个物化子查询。
2.4 partitions
partitions列是查询时匹配到的分区信息,对于非分区表值为NULL,当查询的是分区表时,partitions显示分区表命中的分区情况。
2.5 type
type显示的是访问类型,是较为重要的一个指标,性能从最好到最坏依次是 system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL。一般来说,得保证查询至少达到range级别,最好能达到ref。
| 类型 | 说明 |
| system | 这是const连接类型的一种特例,表仅有一行满足条件。 |
| const | 当确定最多只会有一行匹配的时候,MySQL优化器会在查询前读取它而且只读取一次,因此非常快。当主键放入where子句时,mysql把这个查询转为一个常量(高效) |
| eq_ref | 最多只返回一条符合条件的记录。使用唯一性索引或主键查找时会发生 (高效) |
| ref | 一种索引访问,它返回所有匹配某个单个值的行。此类索引访问只有当使用非唯一性索引或唯一性索引非唯一性前缀时才会发生。这个类型跟eq_ref不同的是,它用在关联操作只使用了索引的最左前缀,或者索引不是UNIQUE和PRIMARY KEY。ref可以用于使用=或<=>操作符的带索引的列。 |
| fulltext | 查询时使用 fulltext 索引。 |
| ref_or_null | 对于某个字段既需要关联条件,也需要null 值的情况下。查询优化器会选择用ref_or_null 连接查询。 |
| index_merge | 在查询过程中需要多个索引组合使用,通常出现在有or 关键字的sql 中。 |
| unique_subquery | 该联接类型类似于index_subquery。子查询中的唯一索引。在某些in子查询里,用于替换eq_ref |
| index_subquery | 利用索引来关联子查询,不再全表扫描。用于非唯一索引,子查询可以返回重复值。类似于unique_subquery,但用于非唯一索引 |
| range | 范围扫描,一个有限制的索引扫描。key 列显示使用了哪个索引。当使用=、 <>、>、>=、<、<=、IS NULL、<=>、BETWEEN 或者 IN 操作符,用常量比较关键字列时,可以使用 range |
| index | 和全表扫描一样。只是扫描表的时候按照索引次序进行而不是行。主要优点就是避免了排序, 但是开销仍然非常大。如在Extra列看到Using index,说明正在使用覆盖索引,只扫描索引的数据,它比按索引次序全表扫描的开销要小很多 |
| all | 全表扫描,性能最差。 |
2.6 possible_keys
查询时可能使用的索引,一个或多个。查询涉及到的字段上若存在索引,则该索引将被列出。注意是可能,实际查询时不一定会用到。
2.7 key
查询时实际使用的索引,没有使用索引则为NULL。查询时若使用了覆盖索引,则该索引只出现在key字段中。
2.8 key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好。
key_len显示的值是索引字段可能的最大长度,并非实际使用长度,即key_len是根据表定义计算得到,不是通过表内检索。
key_len 字段能够帮你检查是否充分的利用上了索引。ken_len 越长,说明索引使用的越充分。
注意:key_len只计算where条件中用到的索引长度,而排序和分组即便是用到了索引,也不会计算到key_len中。
2.9 ref
显示索引的哪一列被使用了,常见的取值有:const, func,null,字段名。
- 当使用常量等值查询,显示
const, - 当关联查询时,会显示相应关联表的
关联字段 - 如果查询条件使用了
表达式、函数,或者条件列发生内部隐式转换,可能显示为func - 其他情况
null
2.10 rows
rows 列表示 MySQL 认为它执行查询时可能需要读取的行数,一般情况下这个值越小越好!
2.11 filtered
filtered 是一个百分比的值,表示符合条件的记录数的百分比。简单点说,这个字段表示存储引擎返回的数据在经过过滤后,剩下满足条件的记录数量的比例。
在MySQL.5.7版本以前想要显示filtered需要使用explain extended命令。MySQL.5.7后,默认explain直接显示partitions和filtered的信息。
2.12 Extra
Extra是EXPLAIN输出中另外一个很重要的列,该列显示MySQL在查询过程中的一些详细信息,MySQL查询优化器执行查询的过程中对查询计划的重要补充信息。
| 类型 | 说明 |
| Using filesort | MySQL有两种方式可以生成有序的结果,通过排序操作或者使用索引,当Extra中出现了Using filesort 说明MySQL使用了后者,但注意虽然叫filesort但并不是说明就是用了文件来进行排序,只要可能排序都是在内存里完成的。大部分情况下利用索引排序更快,所以一般这时也要考虑优化查询了。使用文件完成排序操作,这是可能是ordery by,group by语句的结果,这可能是一个CPU密集型的过程,可以通过选择合适的索引来改进性能,用索引来为查询结果排序。 |
| Using temporary | 用临时表保存中间结果,常用于GROUP BY 和 ORDER BY操作中,一般看到它说明查询需要优化了,就算避免不了临时表的使用也要尽量避免硬盘临时表的使用。 |
| Not exists | MYSQL优化了LEFT JOIN,一旦它找到了匹配LEFT JOIN标准的行, 就不再搜索了。 |
| Using index | 说明查询是覆盖了索引的,不需要读取数据文件,从索引树(索引文件)中即可获得信息。如果同时出现using where,表明索引被用来执行索引键值的查找,没有using where,表明索引用来读取数据而非执行查找动作。这是MySQL服务层完成的,但无需再回表查询记录。 |
| Using index condition | 这是MySQL 5.6出来的新特性,叫做“索引条件推送”。简单说一点就是MySQL原来在索引上是不能执行如like这样的操作的,但是现在可以了,这样减少了不必要的IO操作,但是只能用在二级索引上。 |
| Using where | 使用了WHERE从句来限制哪些行将与下一张表匹配或者是返回给用户。注意:Extra列出现Using where表示MySQL服务器将存储引擎返回服务层以后再应用WHERE条件过滤。 |
| Using join buffer | 使用了连接缓存:Block Nested Loop,连接算法是块嵌套循环连接;Batched Key Access,连接算法是批量索引连接 |
| impossible where | where子句的值总是false,不能用来获取任何元组 |
| select tables optimized away | 在没有GROUP BY子句的情况下,基于索引优化MIN/MAX操作,或者对于MyISAM存储引擎优化COUNT(*)操作,不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化。 |
| distinct | 优化distinct操作,在找到第一匹配的元组后即停止找同样值的动作 |
相关文章:
MySQL——EXPLAIN用法详解
EXPLAIN是MySQL官方提供的sql分析的工具之一,可以用于模拟优化器执行sql查询语句,从而知道MySQL是如何处理sql语句。EXPLAIN主要用于分析查询语句或表结构的性能瓶颈。 以下是基于MySQL5.7.19版本进行分析的,不同版本之间略有差异。 1、EXP…...

69 划分字母区间
划分字母区间 题解1 贪心1(方法略笨,性能很差)题解2 贪心2(参考标答) 给你一个字符串 s 。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。 注意,划分结果需要满足&am…...
, 文件上传绕过原理)
文件上传漏洞(1), 文件上传绕过原理
文件上传漏洞 一, 前端校验上传文件 添加 Javascript 代码,然后在 form 表单中 添加 onsubmit"returb checkFile()" <script>function checkFile() {// var file document.getElementsByName(photo)[0].value;var file document.getElementByI…...

【ARM 嵌入式 C 入门及渐进 10 -- 冒泡排序 选择排序 插入排序 快速排序 归并排序 堆排序 比较介绍】
文章目录 排序算法小结排序算法C实现 排序算法小结 C语言中常用的排序算法包括冒泡排序、选择排序、插入排序、快速排序、归并排序、堆排序。下面我们来一一介绍: 冒泡排序(Bubble Sort):冒泡排序是通过比较相邻元素的大小进行排…...

虹科 | 解决方案 | 汽车示波器 学校教学方案
虹科Pico汽车示波器是基于PC的设备,特别适用于大课堂的教学、备课以及与师生的互动交流。老师展现讲解波形数据,让学生直观形象地理解汽车的工作原理 高效备课 课前实测,采集波形数据,轻松截图与标注,制作优美的课件&…...
)
广播和组播(多播)
广播 概述 广播(broadcast)是指封包在计算机网络中传输时,目的地址为网络中所有设备的一种传输方式。实际上,这里所说的“所有设备”也是限定在一个范围之中,称为“广播域”。并非所有的计算机网络都支持广播…...
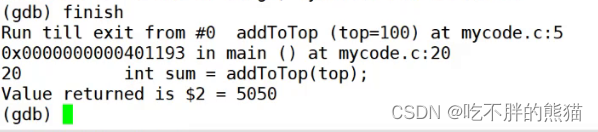
【Linux】gdb调试
目录 进入调试查看代码运行代码断点打断点查断点删断点从一个断点转跳至下一个断点保留断点但不会运行该断点 退出调试逐过程逐语句监视跳转至指定行运行结束当前函数 进入调试 指令:gdb 【可执行文件】: 查看代码 :l 【第几行】如果输入指…...

MySQL创建函数及其使用
MySQL创建函数及其使用 一、MySQL 创建函数二、示例 一、MySQL 创建函数 MySQL 函数是一种可重用的代码块,可以接受输入参数并返回值。你可以在 MySQL 中创建各种类型的函数,包括系统函数、用户定义函数和存储过程。在此处,我们将重点关注用…...
大数据-Storm流式框架(四)---storm容错机制
1、集群节点宕机 Nimbus服务器 硬件 单点故障?可以搭建HA jStorm搭建 nimbus的HA nimbus的信息存储到zookeeper中,只要下游没问题(进程退出)nimbus退出就不会有问题, 如果在nimbus宕机,也不能提交…...
SpringBoot项目把Mysql从5.7升级到8.0
首先你需要把之前的库导入到mysql库导入到8.0的新库中。(导入的时候会报错我是通过navcat备份恢复的) 1、项目中需要修改pom文件的依赖 mysql 和 jdbc <dependency><groupId>mysql</groupId><artifactId>mysql-connector-java&…...

RK3568-适配at24c04模块
将at24c04模块连接到开发板i2c2总线上 i2ctool查看i2c2总线上都有哪些设备 UU表示设备地址的从设备被驱动占用,卸载对应的驱动后,UU就会变成从设备地址。at24c04模块设备地址 0x50和0x51是at24c04模块i2c芯片的设备地址。这个从芯片手册上也可以得知。A0 A1 A2表示的是模块对…...
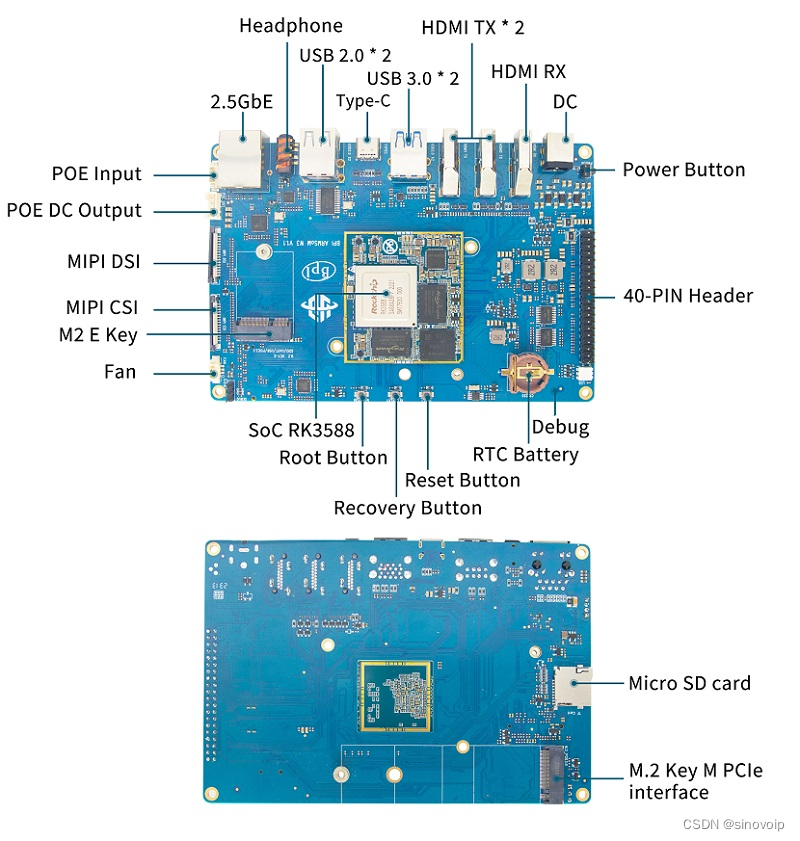
Banana Pi BPI-W3 ArmSoM-W3之RK3588-MIPI-DSI屏幕调试笔记
一. 简介 本文是基于RK3588平台,MIPI屏调试总结。 二. 环境介绍 硬件环境: ArmSoM-W3 RK3588开发板、MIPI-DSI显示屏( ArmSoM官方配件 )软件版本: OS:ArmSoM-W3 Debian11 三. MIPI屏幕调试 3.1 调试总览,调试步骤分…...
Git的远程仓库
Git的远程仓库 添加远程仓库从远程库克隆 添加远程仓库 你在本地创建了一个Git仓库后,又想在GitHub创建一个Git仓库,并且让这两个仓库进行远程同步,这样,GitHub上的仓库既可以作为备份,又可以让其他人通过该仓库来协作…...

Linux虚拟网络设备—Veth Pair
veth是Virtual Ethernet Device的缩写,是一种成对出现的Linux虚拟网络接口设备。它最常用的功能是用于将不同的Linux network namespaces 命名空间网络连接起来,让二个namespaces之间可以进行通信。我们可以简单的把veth pair理解为用一根网线࿰…...

Parcelable protocol requires the CREATOR object to be static on class com.test
对于 Parcelable 协议,确实要求 CREATOR 对象必须是静态的。这是因为在反序列化过程中,需要通过 CREATOR 对象来创建 Parcelable 对象的实例。 根据错误信息,涉及到了com.test类中的问题。通常情况下,如果一个内部类需要实现 Par…...

Python的Matplotlib库:数据可视化的利器
引言: Matplotlib是一款强大的Python库,专为数据可视化而设计。无论是绘制折线图、散点图、柱状图还是饼图,Matplotlib都能提供灵活且易于操作的绘图方法。 1. Matplotlib简介 Matplotlib是Python中最流行的绘图库之一,被广泛应…...

普通人做抖店,需要具备什么条件?一篇详解!
我是电商珠珠 抖音小店的热度一直很高,对于想开店的新手来说,不知道需要什么条件,今天我就来给大家详细的讲一下。 一、营业执照 在入驻抖音小店之前,需要准备一张营业执照。 营业执照一共有两种类型,一种为个体工…...
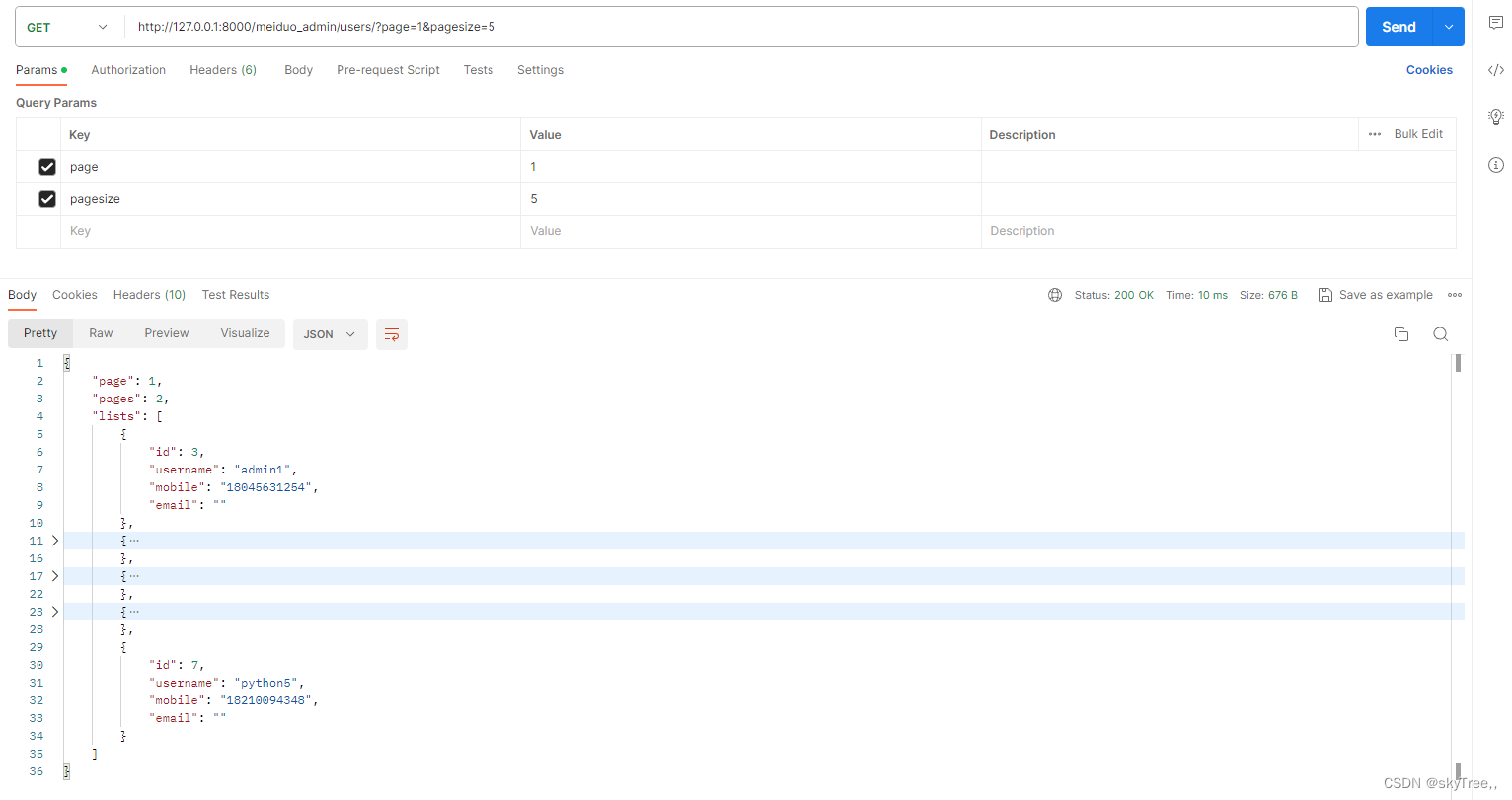
Django分页功能的使用和自定义分装
1. 在settings中进行注册 # drf配置 REST_FRAMEWORK {DEFAULT_AUTHENTICATION_CLASSES: (# rest_framework_jwt.authentication.JSONWebTokenAuthentication,rest_framework_simplejwt.authentication.JWTAuthentication,rest_framework.authentication.SessionAuthenticatio…...

React-hooks有哪些用法?
React Hooks 是 React 16.8 引入的一种新的特性,用于在函数组件中使用状态和其他 React 特性。下面列举了一些常见的 React Hooks 的用法: 1:useState:用于在函数组件中添加状态。: import React, { useState } from react;function MyComponent() {const [count, setCou…...
)
2024年CFA一级公示表,一级quicksheet(内附分享链接)
随着金融行业的迅速发展,CFA(特许金融分析师)认证成为了许多金融从业者追求的目标。2024年CFA一级公示表资料的自学,为那些渴望在金融领域取得突破的人们提供了宝贵的机会。 通过自学CFA一级公示表资料,我们可以深入了…...

从‘它怎么又挂了’到‘服务稳如狗’:我是如何用Prometheus+Grafana给自家小项目做监控的
从零搭建轻量级服务监控:PrometheusGrafana实战指南 凌晨三点,手机突然响起刺耳的警报声——这已经是本周第三次被线上服务宕机惊醒。作为独立开发者或小团队,我们往往身兼数职,既要写代码又要维护基础设施。服务崩溃时才发现问题…...

苹果全球推出关键MDM工具和企业服务
随着苹果在企业市场份额的稳步增长,该公司终于在美国以外地区推出了其面向中小型企业(SMB)的实用服务集合Apple Business Essentials,但这次它不再叫Apple Business Essentials,而且其中大部分服务都将免费提供。Apple…...

IPD实战指南:CBB模块化设计如何加速产品创新与资源整合
1. CBB模块化设计的本质与价值 第一次接触CBB这个概念时,我正负责一款智能家居产品的研发。当时团队为了赶进度,每个新产品都从零开始设计电路板,结果发现80%的功能模块都是重复的。这种低效的开发方式让我开始思考:能不能像搭积木…...

图像转3D模型:零基础制作个性化浮雕的完整指南
图像转3D模型:零基础制作个性化浮雕的完整指南 【免费下载链接】ImageToSTL This tool allows you to easily convert any image into a 3D print-ready STL model. The surface of the model will display the image when illuminated from the left side. 项目地…...

GitHub加速工具:解决开发者访问难题的终极方案
GitHub加速工具:解决开发者访问难题的终极方案 【免费下载链接】fetch-github-hosts 🌏 同步github的hosts工具,支持多平台的图形化和命令行,内置客户端和服务端两种模式~ | Synchronize GitHub hosts tool, support multi-platfo…...
)
R语言新手必看:如何用pkgbuild和Sys.which检查并安装Rtools(附绑定教程)
R语言开发环境配置全指南:从Rtools安装到编译环境搭建 刚接触R语言的开发者,在尝试从源代码编译安装某些扩展包时,常常会遇到"make not found"之类的错误提示。这通常意味着系统缺少必要的编译工具链。本文将详细介绍如何在Windows…...

ImageMagick安装后报错‘vcomp140.dll缺失’?手把手教你彻底解决Visual C++依赖问题
ImageMagick安装后报错‘vcomp140.dll缺失’?手把手教你彻底解决Visual C依赖问题 当你兴冲冲下载完ImageMagick准备大展身手时,命令行却突然弹出一串红色错误提示——"无法启动程序,因为计算机中丢失vcomp140.dll"。这种场景对于…...

深入解析FOC电机控制:从理论到实践的无传感器实现
1. 无传感器FOC控制的核心原理 磁场定向控制(FOC)本质上是在模拟直流电机的控制方式。想象一下小时候玩的四驱车——直流电机通过改变电压就能直接控制转速,简单粗暴。但三相交流电机就像个傲娇的艺术家,需要我们把三相电流"…...

Claude浏览器扩展漏洞允许通过任意网站实现零点击XSS提示注入
网络安全研究人员披露了Anthropic公司Claude谷歌浏览器扩展中存在的一个漏洞,攻击者只需诱使用户访问特定网页即可触发恶意提示注入。漏洞原理分析Koi Security研究员Oren Yomtov在提供给The Hacker News的报告中指出:"该漏洞允许任何网站静默地向该…...

SemanticKITTI数据集评测:DarkNet53Seg、PointNet++等模型谁更强?附复现代码
SemanticKITTI点云语义分割实战:模型选型与性能优化指南 点云语义分割技术正在重塑自动驾驶、机器人导航和三维场景理解等领域的研究范式。作为该领域最具挑战性的基准之一,SemanticKITTI数据集凭借其大规模、高密度标注和真实场景多样性,已成…...