机器学习(python)笔记整理
目录
一、数据预处理:
1. 缺失值处理:
2. 重复值处理:
3. 数据类型:
二、特征工程:
1. 规范化:
2. 归一化:
3. 标准化(方差):
三、训练模型:
如何计算精确度,召回、F1分数
一、数据预处理:
1. 缺失值处理:
在数据中存在缺失值的情况下,可以采用删除缺失值、均值填充、中位数填充、插值法等方式进行缺失值处理。
import pandas as pd
import numpy as np# 创建DataFrame,包含缺失值
df = pd.DataFrame({'A': [1, 2, np.nan, 4, 5], 'B': [6, np.nan, 8, np.nan, 10]})
print(df)# 删除缺失值
df.dropna(inplace=True)
print(df)# 均值填充
df.fillna(df.mean(), inplace=True)
print(df)# 中位数填充
df.fillna(df.median(), inplace=True)
print(df)# 插值法填充
df.interpolate(inplace=True)
print(df)2. 重复值处理:
在数据中存在重复值的情况下,可以采用删除重复值、保留重复值、统计重复值等方式进行重复值处理。
import pandas as pd
import numpy as np# 创建DataFrame,包含重复值
df = pd.DataFrame({'A': [1, 2, 2, 4, 5], 'B': [6, 6, 8, 8, 10]})
print(df)# 删除重复值
df.drop_duplicates(inplace=True)
print(df)# 保留重复值
df[df.duplicated(keep=False)]
print(df)# 统计重复值
df.duplicated()
print(df.duplicated().sum())3. 数据类型:
在数据中存在不同数据类型的情况下,可以采用转换数据类型、或者删除对模型影响不大的数据类型等方式进行数据类型处理。
import pandas as pd# 创建DataFrame,包含不同数据类型
df = pd.DataFrame({'A': [1, 2, 3], 'B': ['4', '5', '6']})
print(df)# 转换数据类型
df['B'] = df['B'].astype(int)
print(df)# 删除对模型影响不大的数据类型
df.drop(columns='B', inplace=True)
print(df)二、特征工程:
1. 规范化:
规范化的目的是将特征的值域缩小到[0,1]之间,以消除各特征值域不同的影响,并提高模型的精度。
1.one-hot编码
情况一 . 一个特征中两个不同的特征值(one-hot编码)
import pandas as pd
#情况一 一个特征中两个不同的特征值(one-hot编码)
'''
1 = male
0 = female
'''
df1 = pd.DataFrame({'Gender': ['female','male', 'female','female', 'male','male']})
df1['Gender'].replace({'female':1,'male':0})
情况二 一个特征中有多个不同的特征值(标签编码,一般1对应标签占位)
import pandas as pd#情况二 一个特征中有多个不同的特征值(标签编码,一般1对应标签占位)# 创建DataFrame,包含需要规范化的特征
df2 = pd.DataFrame({'A': ['one','one', 'three','twe', 'one','three']})#使用标签编码来规范化
'''
分析有三个不同值(将值1作为特征占位)
one twe three
1 0 0
0 1 0
0 0 1
'''
# 将值替换
df2=df2.replace({'one':'100','twe':'010','three':'001'}).astype('category')df2
2. 归一化:
归一化与规范化类似,也是将特征的值域缩小到[0,1]之间,但与规范化不同的是,归一化是对整个数据集的缩放,而规范化是对单个特征的缩放。示例代码:
import pandas as pd# 创建DataFrame,包含需要归一化的特征
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
print(df)# 将值转换为 0-1值,增加相似度
# 公式 :(x-min)/(max-min)df['A']=(df['A']-df['A'].min())/(df['A'].max()-df['A'].min())
df['B']=(df['B']-df['B'].min())/(df['B'].max()-df['B'].min())
df3. 标准化(方差):
标准化是将特征值转换为标准正态分布,使得特征值的均值为0,标准差为1,以消除特征值之间的量纲影响,并提高模型的精度。
数据转化到均值为0,方差为1的范围内,方差和标准差越趋近于0,则表示数据越集中;如果越大,表示数据越离散。
使用sklearn.preprocession import StandardScaler
import pandas as pd
from sklearn.preprocessing import StandardScaler
# 创建DataFrame,包含需要标准化的特征
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
print(df)# 使用StandardScaler标准化特征
scaler = StandardScaler()
df_norm = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)
print(df_norm)三、训练模型:
在对数据进行预处理和特征工程之后,就可以训练模型了。在这里,我们以xgboost模型为例进行训练。
示例代码:
# 这行代码是从sklearn.model_selection库中导入train_test_split函数,该函数用于将数据集分割为训练集和测试集。
from sklearn.model_selection import train_test_split# 这行代码将您的主数据集(特征)和目标变量(标签)分割为训练集和测试集。test_size=0.33表示测试集占总数据的33%,random_state=7用于每次分割都产生相同的数据分布,确保结果的可重复性。
X_train, X_test, y_train, y_test = train_test_split(df_train, df_y, test_size=0.33, random_state=7)# 这行代码从xgboost库中导入XGBClassifier类。这是一个实现了梯度提升决策树算法的分类器。
from xgboost import XGBClassifier# 创建XGBClassifier的一个实例。这里没有指定任何参数,所以模型会使用默认参数。
model = XGBClassifier()# eval_set是一个列表,其中包含将用于评估模型性能的测试数据集。这对于早期停止是必要的,以防止过拟合。
eval_set = [(X_test, y_test)]# 这行代码训练模型。early_stopping_rounds=10表示如果在10轮迭代中,性能没有提升,训练将停止。eval_metric='logloss'设置了评估标准。eval_set是我们之前设置的测试数据,verbose=True表示在训练时显示日志。
model.fit(X_train, y_train, early_stopping_rounds=10, eval_metric='logloss', eval_set=eval_set, verbose=True)# 使用训练好的模型对测试集进行预测。
y_pred = model.predict(X_test)# (这行代码被注释掉了,如果使用,它将执行以下操作)这行代码通过四舍五入预测值(因为梯度提升生成的是概率)来创建一个新的预测列表。
# predictions = [round(value) for value in y_pred]# (以下两行代码被注释掉了,如果使用,它们将执行以下操作)计算模型的准确度,即预测正确的比例。
# accuracy = accuracy_score(y_test, predictions)
# print(accuracy)# 从sklearn.metrics导入f1_score函数。
from sklearn.metrics import f1_score# 计算F1得分,这是准确率和召回率的加权平均值,通常用于评估分类模型的性能,尤其是在不平衡数据集中。
f1 = f1_score(y_test, y_pred)# 打印F1得分。
print(f1)

如何计算精确度,召回、F1分数
from sklearn.metrics import confusion_matrix, precision_score, recall_score, f1_score# 真实标签和模型预测结果
y_true = [0, 1, 1, 0, 1]
y_pred = [0, 1, 0, 0, 1]# 计算混淆矩阵
conf_matrix = confusion_matrix(y_true, y_pred)
TP, FP, TN, FN = conf_matrix.ravel()# 计算精确度、召回率和F1分数
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)print("Precision:", precision)
print("Recall:", recall)
print("F1 Score:", f1)相关文章:
机器学习(python)笔记整理
目录 一、数据预处理: 1. 缺失值处理: 2. 重复值处理: 3. 数据类型: 二、特征工程: 1. 规范化: 2. 归一化: 3. 标准化(方差): 三、训练模型: 如何计算精确度,召…...

微客云霸王餐系统 1.0 : 全面孵化+高额返佣
1、业务简介。业务模式是消费者以5-10元吃到原价15-25元的外卖,底层逻辑是帮外卖商家做推广,解决新店基础销量、老店增加单量、品牌打万单店的需求。 因为外卖店的平均生命周期只有6个月,不断有新店愿意送霸王餐。部分老店也愿意做活动&…...

极智开发 | Hello world for Manim
欢迎关注我的公众号 [极智视界],获取我的更多经验分享 大家好,我是极智视界,本文分享一下 Hello world for Manim。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码和资源下载,链接:https://t.zsxq.com/0aiNxERDq Manim 是什么呢?Manim 是一个用于创…...
【云上探索实验室-码上学堂】免费学习领好礼!
走过路过,不要错过!上云AI三步走,学着课程奖品有! 亚马逊云科技又放福利了,为了让同学们更快入手Amazon CodeWhisperer,官方推出《云上探索实验室-码上学堂》活动,作为一名Amazon CodeWhisperer…...
Flutter最全面试题大全
在理解这些问题之前,建议看一下Flutter架构原理,如下链接: https://blog.csdn.net/wang_yong_hui_1234/article/details/130427887?spm1001.2014.3001.5501 目录 一. 有个Text节点,由于文字内容过多,发生了溢出错误&…...
Linux---(四)权限
文章目录 一、shell命令及运行原理1.什么是操作系统?2.外壳程序3.用户为什么不直接访问操作系统内核?4.操作系统内核为什么不直接把结果显示出来?非要加外壳程序?5.shell理解重点总结(1)shell是什么?&…...
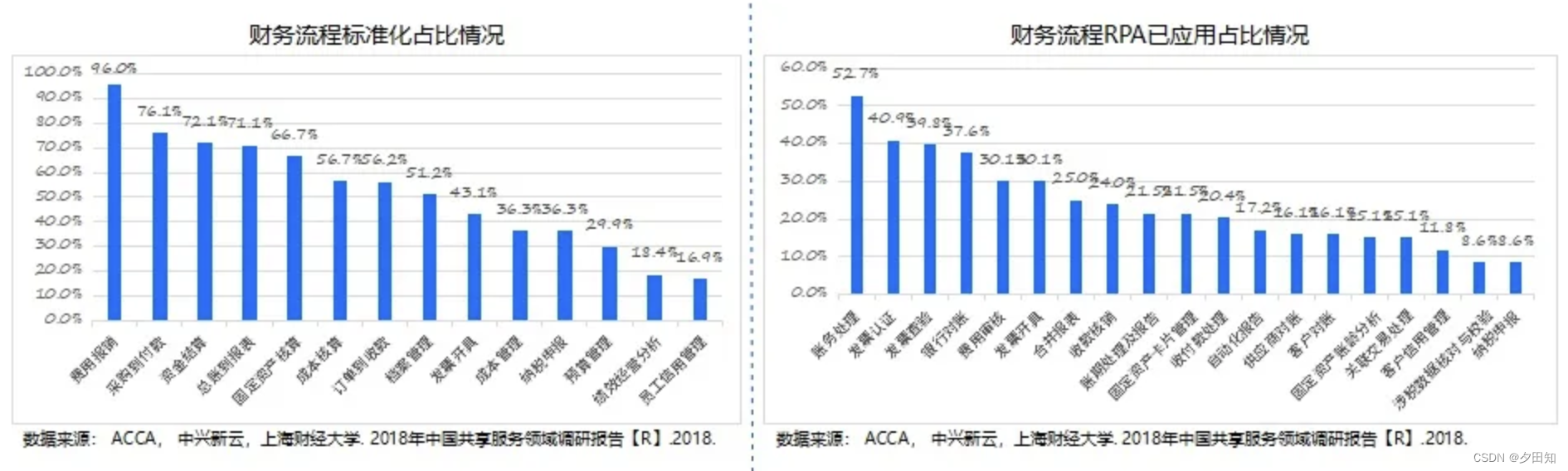
财务RPA机器人真的能提高效率吗?
财务部门作为一个公司的管理职能部门承担着一个公司在商业活动中各个方面的重要职责。理论上来说,一个公司的财务部门的实际工作包含但不限于对企业的盈亏情况进行评估、对风险进行预测、通过数据分析把握好公司的财务状况、税务管理等。 然而,实际上在…...

国产信号发生器 1442/1442A射频信号发生器
信号发生器 1442/A射频信号发生器 1442系列射频信号发生器是一款针对通信、电子等射频应用而设计开发的产品。覆盖了所有的常用射频频段。它采用模块化结构设计,全中文界面、大屏幕菜单控制,其输出信号相位噪声极低,频率分辨率和准确度高&am…...
Kafka与Spark案例实践
1.概述 Kafka系统的灵活多变,让它拥有丰富的拓展性,可以与第三方套件很方便的对接。例如,实时计算引擎Spark。接下来通过一个完整案例,运用Kafka和Spark来合理完成。 2.内容 2.1 初始Spark 在大数据应用场景中,面对…...

山西电力市场日前价格预测【2023-10-27】
日前价格预测 预测说明: 如上图所示,预测明日(2023-10-27)山西电力市场全天平均日前电价为347.06元/MWh。其中,最高日前电价为618.09元/MWh,预计出现在18: 15。最低日前电价为163.49元/MWh,预计…...
)
centos7安装redis(包含各种报错)
本文主要介绍如果在Centos7下安装Redis。 1.安装依赖 redis是由C语言开发,因此安装之前必须要确保服务器已经安装了gcc,可以通过如下命令查看机器是否安装: gcc -v如果没有安装则通过以下命令安装: yum install -y gcc2.下载r…...

使用GoQuery实现头条新闻采集
概述 在本文中,我们将介绍如何使用Go语言和GoQuery库实现一个简单的爬虫程序,用于抓取头条新闻的网页内容。我们还将使用爬虫代理服务,提高爬虫程序的性能和安全性。我们将使用多线程技术,提高采集效率。最后,我们将展…...

“一带一路”十周年:用英语讲好中华传统故事
图为周明霏小选手 2023年是“一带一路”倡议提出十周年。十年来,中国的“友谊圈”已经扩展到亚洲、非洲、欧洲、大洋洲和拉丁美洲,这一倡议已经成为提升我国文化软实力、传播中华传统文化的重要策略和途径之一。在这个广阔的交流平台上,使用…...

机器视觉兄弟们还有几个月就拿到年终奖了,但我想跑路了
大聪明的我一般会把年终奖拿了,再走。听说有人还没有年终奖,太伤心了,赶紧跑吧。注意,机器视觉小白不要轻举妄动。 今年太难了,真的是让人很难过,很不爽,很不舒服。 公司难,机器视…...
base_lcoal_planner的LocalPlannerUtil类中getLocalPlan函数详解
本文主要介绍base_lcoal_planner功能包中LocalPlannerUtil类的getLocalPlan函数,以及其调用的transformGlobalPlan函数、prunePlan函数的相关内容 一、getLocalPlan函数 getLocalPlan函数的源码如下: bool LocalPlannerUtil::getLocalPlan(const geomet…...
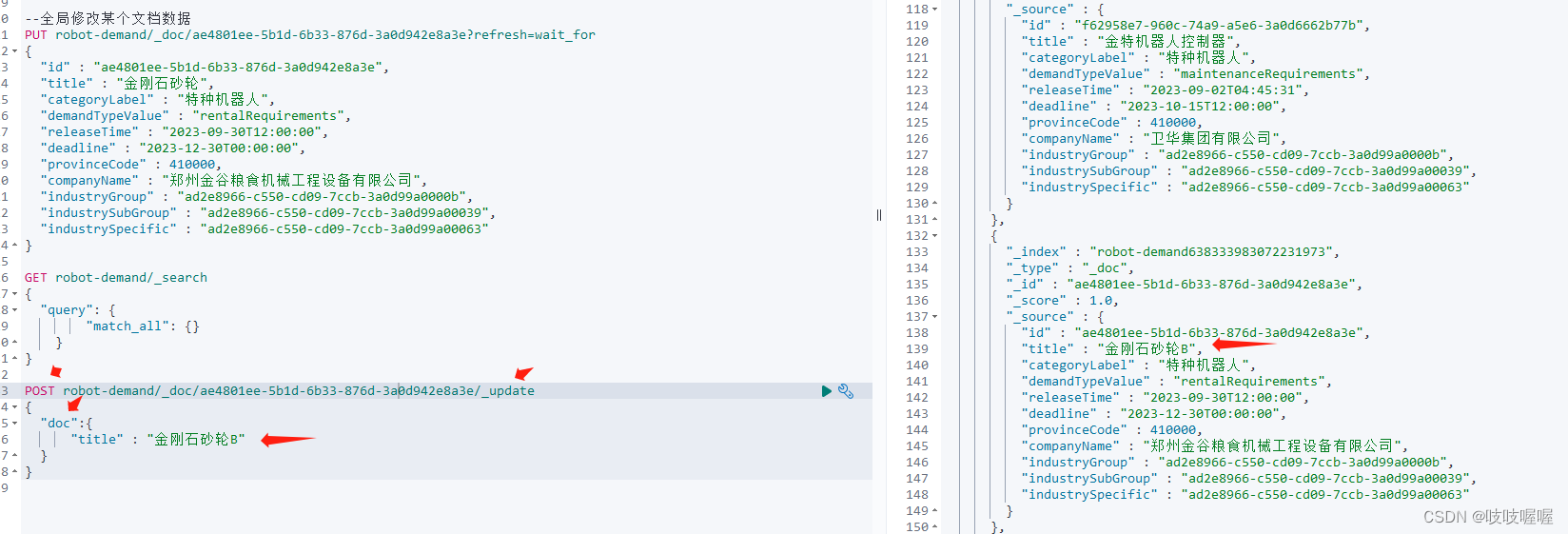
elasticSearch put全局更新和单个字段更新语法
1、如下:更新改类型未doc(文档)的全局字段数据 注意:如果你使用的是上面的语句,但是只写了id和title并赋值,图片上其他字段没有填写,执行命令后,则会把原文档中的其他字段都给删除了,你会发现查…...
记录一次时序数据库的实战测试
0x1.前言 本文章仅用于信息安全防御技术分享,因用于其他用途而产生不良后果,作者不承担任何法律责任,请严格遵循中华人民共和国相关法律法规,禁止做一切违法犯罪行为。文中涉及漏洞均以提交至教育漏洞平台。 0x2.背景 在某…...
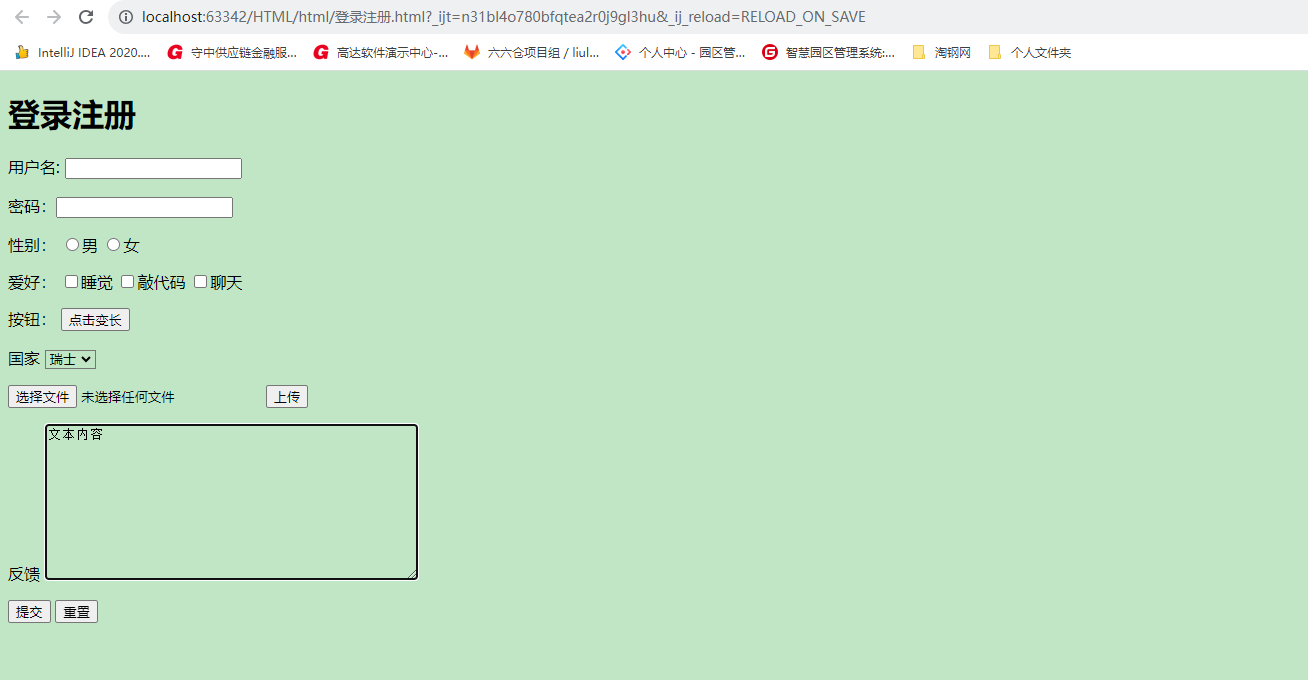
HTML中文本框\单选框\按钮\多选框
<!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Title</title> </head> <body> <h1>登录注册</h1> <form action"第一个网页.html" method"post&quo…...
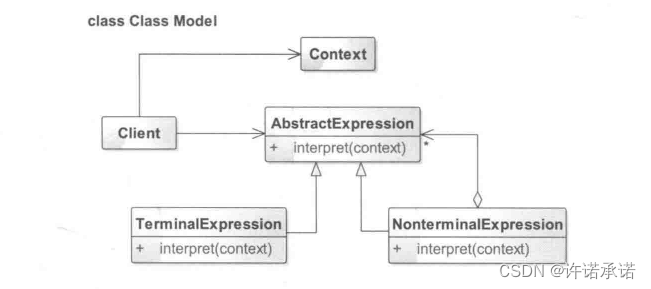
解释器模式——化繁为简的翻译机
● 解释器模式介绍 解释器模式(Interpreter Pattern)是一种用的比较少的行为型模式,其提供了一种解释语言的语法或表达的方式,该模式定义了一个表达式接口,通过该接口解释一个特定的上下文。在这么多的设计模式中&…...

【凡人修仙传】定档,四女神出场,韩立遭极阴岛陷阱,蛮胡子亮相
【侵权联系删除】【文/郑尔巴金】 距离凡人修仙传动画星海飞驰序章完结,已经过去了两个月的时间,相信大家等待的心情相当难熬,而且也愈发期待韩立结丹后在乱星海发生的故事。按照官方当初立下的FLAG,新年番动画即将在金秋十一月上…...
)
用什么来搭建知识库(写给小白的LLM工具选型系列:第六篇)
诸神缄默不语-个人技术博文与视频目录 (本文为AI生成,未做人工验证,也未列出参考资料。以后可能会更新) 本文面向小白读者,介绍基于AI的大规模知识库(RAG)的基本原理和常见方案。我们首先用通…...

课题申请:如何在评审专家的“黄金三分钟”内锁定胜局?
基金申报的战场硝烟弥漫,每一位科研人员都深知,一份标书的命运往往掌握在评审专家的手中。然而,现实情况是,评审工作极其繁重,专家们需要在短时间内审阅大量本子。据统计,评审专家在立项依据部分的停留时间…...

为什么ResNet的152层比VGG16快?图解残差连接的计算优化与内存管理
为什么ResNet的152层比VGG16快?图解残差连接的计算优化与内存管理 在深度学习领域,网络深度与计算效率似乎总是一对矛盾体——直到ResNet的出现打破了这一认知。当152层的ResNet在ImageNet竞赛中以更低计算量击败16层的VGG时,整个计算机视觉…...

Appstore 上架问题汇总--持续更新
一、Guideline 3.2.1(viii) - Business - Other Business Model Issues - Acceptable 问题: We still found the app provides loan services but the domains listed on the apps Product Pages are not clearly under your control or ownership. Since users m…...
跨语言数据处理的高效解决方案:json-translator全方位指南
跨语言数据处理的高效解决方案:json-translator全方位指南 【免费下载链接】json-translator jsontt 💡 - AI JSON Translator with GPT / Gemma / Mixtral / llama other FREE translation modules to translate your json/yaml files into other lang…...

如何在Windows系统中轻松访问Linux分区?Ext2Read的5个实用技巧
如何在Windows系统中轻松访问Linux分区?Ext2Read的5个实用技巧 【免费下载链接】ext2read A Windows Application to read and copy Ext2/Ext3/Ext4 (With LVM) Partitions from Windows. 项目地址: https://gitcode.com/gh_mirrors/ex/ext2read 你是否曾经在…...

Phi-4-mini-reasoning部署指南:多模型共存时GPU显存隔离与服务端口分配
Phi-4-mini-reasoning部署指南:多模型共存时GPU显存隔离与服务端口分配 1. 项目概述 Phi-4-mini-reasoning是微软推出的3.8B参数轻量级开源模型,专为数学推理、逻辑推导和多步解题等强逻辑任务设计。这个模型主打"小参数、强推理、长上下文、低延…...

这个 Plugin 让 OpenClaw 减少Skill 90%Token消耗
别让 Skill 列表烧光你的 Token——用一个 Plugin 让 OpenClaw 瘦身 90% 95 个 Skill,每轮对话就消耗 5000 多个 Token?本文将分享我们如何通过 Elasticsearch 语义搜索和一个 OpenClaw Plugin,将 Skill 列表从“全量注入”变为“按需加载”&…...

从实战案例出发:面阵与线阵相机选型策略及镜头配置全解析
1. 面阵与线阵相机的本质区别 第一次接触工业相机选型时,我也曾被各种参数搞得晕头转向。直到有次在产线上亲眼看到两种相机的实际表现,才真正理解了它们的差异。简单来说,面阵相机就像我们平时用的数码相机,一次拍摄就能获取整个…...

ONNX Runtime性能优化:InferenceSession.run函数的高效使用技巧
1. ONNX Runtime与InferenceSession.run函数基础 ONNX Runtime是一个高性能的推理引擎,专门用于部署ONNX格式的机器学习模型。在实际应用中,模型的推理性能往往直接影响整个系统的响应速度和资源利用率。而InferenceSession.run函数正是这个过程中的核心…...