Redis快速上手篇(三)(事务+Idea的连接和使用)
Redis事务
可以一次执行多个命令,本质是一组命令的集合。一个事务中的 所有命令都会序列化,按顺序地串行化执行而不会被其它命令插入,不许加塞。
单独的隔离的操作
官网说明
https://redis.io/docs/interact/transactions/
MULTI、EXEC、DISCARD、WATCH。这四个指令构成了 redis 事务处理的基础。
1.MULTI 用来组装一个事务;将命令存放到一个队列里面
2.EXEC 用来执行一个事务;相当于mysql的//commit
3.DISCARD 用来取消一个事务;相当于mysql的//rollback
4.WATCH 用来监视一些 key,一旦这些 key 在事务执行之前被改变,则取消事务的执行。
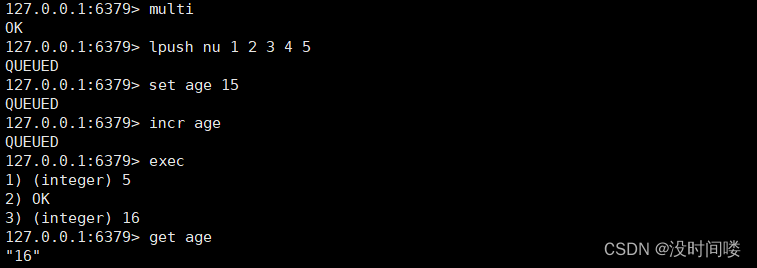
结束后统一执行
有关事务,经常会遇到的是两类错误:
调用 EXEC 之前的错误 如语法错误,事务不会被执行
调用 EXEC 之后的错误 如重复建,事务不会理睬错误(不会影响接下来的其他命令的执行)
WATCH
“WATCH”可以帮我们实现类似于“乐观锁”的效果,即 CAS(check and set)。
WATCH 本身的作用是“监视 key 是否被改动过”,而且支持同时监视多个 key,只要还没真正触发事务,WATCH 都会尽职尽责的监视,一旦发现某个 key 被修改了,在执行 EXEC 时就会返回 nil,表示事务无法触发。
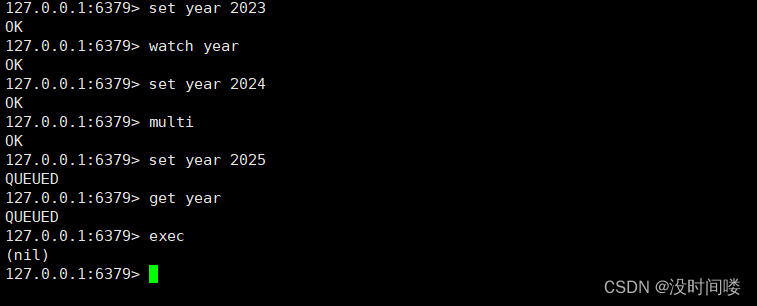
在 multi 之前 set year 修改了值所以 nil
事务回滚(discard)
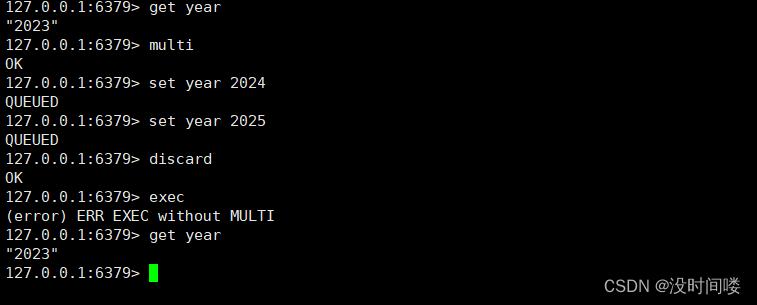
事务冲突
比如涉及金钱的操作,导致金额负数
解决方案
悲观锁(Pessimistic Lock)
顾名思义,就是很悲观
每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,
这样别人想拿这个数据就会block直到它拿到锁。
传统的关系型数据库里边就用到了很多这种锁机制,
比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
每次都会上锁影响效率
乐观锁(Optimistic Lock)
顾名思义,就是很乐观
每次去拿数据的时候都认为别人不会修改,所以不会上锁,
但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,
可以使用版本号等机制。乐观锁适用于多读的应用类型,
这样可以提高吞吐量。Redis就是利用这种check-and-set机制实现事务的。
redis与idea的连接
ssm
添加redis的依赖
<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>3.2.0</version>
</dependency>Jedis jds = new Jedis("IP")
jds.auth("密码")
jds.select(数据库) <!-- 0-15 -->
spring boot
加入redis的依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId><version>2.6.0</version>
</dependency><dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId>
</dependency>编写配置文件
#设置reis的索引
spring.redis.database=15
#设置连接redis的密码
spring.redis.password=yyl
#设置的redis的服务器
spring.redis.host=192.168.159.34
#端口号
spring.redis.port=6379
#连接超时时间(毫秒)
spring.redis.timeout=1800000
#连接池最大连接数(使用负值表示没有限制)
spring.redis.lettuce.pool.max-active=20
#最大阻塞等待时间(负数表示没限制)
spring.redis.lettuce.pool.max-wait=-1
#连接池中的最大空闲连接
spring.redis.lettuce.pool.max-idle=5
#连接池中的最小空闲连接
spring.redis.lettuce.pool.min-idle=0设置配置类
package com.example.demo;import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.cache.CacheManager;
import org.springframework.cache.annotation.CachingConfigurerSupport;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializationContext;
import org.springframework.data.redis.serializer.RedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;import java.time.Duration;@EnableCaching
@Configuration
public class RedisConfig extends CachingConfigurerSupport {/*** 连接池的设置** @return*/@Beanpublic JedisPoolConfig getJedisPoolConfig() {JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();return jedisPoolConfig;}/*** RedisTemplate* @param factory* @return*/@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {RedisTemplate<String, Object> template = new RedisTemplate<>();RedisSerializer<String> redisSerializer = new StringRedisSerializer();Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);ObjectMapper om = new ObjectMapper();// 指定要序列化的域,field,get和set,以及修饰符范围,ANY是都有包括private和publicom.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);// 指定序列化输入的类型,类必须是非final修饰的,final修饰的类,比如String,Integer等会跑出异常om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);jackson2JsonRedisSerializer.setObjectMapper(om);template.setConnectionFactory(factory);//key序列化方式template.setKeySerializer(redisSerializer);//value序列化template.setValueSerializer(jackson2JsonRedisSerializer);//value hashmap序列化template.setHashValueSerializer(jackson2JsonRedisSerializer);return template;}/*** 缓存处理* @param factory* @return*/@Beanpublic CacheManager cacheManager(RedisConnectionFactory factory) {RedisSerializer<String> redisSerializer = new StringRedisSerializer();Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
//解决查询缓存转换异常的问题ObjectMapper om = new ObjectMapper();om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);jackson2JsonRedisSerializer.setObjectMapper(om);
// 配置序列化(解决乱码的问题),过期时间600秒RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig().entryTtl(Duration.ofSeconds(600)).serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer)).serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer)).disableCachingNullValues();RedisCacheManager cacheManager = RedisCacheManager.builder(factory).cacheDefaults(config).build();return cacheManager;}
}编写测试代码
spring-data-redis针对jedis提供了如下功能:
1. 连接池自动管理,提供了一个高度封装的“RedisTemplate”类
2. RedisTemplate 对五种数据结构分别定义了操作
操作字符串
redisTemplate.opsForValue();
操作hash
redisTemplate.opsForHash();
操作list
redisTemplate.opsForList();
操作set
redisTemplate.opsForSet();
操作有序set
redisTemplate.opsForZSet();
String类型与List类型
Set类型
添加元素
redisTemplate.opsForSet().add(key, values)
移除元素(单个值、多个值)
redisTemplate.opsForSet().remove(key, values)删除并且返回一个随机的元素redisTemplate.opsForSet().pop(key)获取集合的大小redisTemplate.opsForSet().size(key)判断集合是否包含value
redisTemplate.opsForSet().isMember(key, value)获取两个集合的交集(key对应的无序集合与otherKey对应的无序集合求交集)
redisTemplate.opsForSet().intersect(key, otherKey)获取多个集合的交集(Collection var2)redisTemplate.opsForSet().intersect(key, otherKeys)key集合与otherKey集合的交集存储到destKey集合中(其中otherKey可以为单个值或者集合)redisTemplate.opsForSet().intersectAndStore(key, otherKey, destKey)key集合与多个集合的交集存储到destKey无序集合中redisTemplate.opsForSet().intersectAndStore(key, otherKeys, destKey)获取两个或者多个集合的并集(otherKeys可以为单个值或者是集合)redisTemplate.opsForSet().union(key, otherKeys)key集合与otherKey集合的并集存储到destKey中(otherKeys可以为单个值或者是集合)redisTemplate.opsForSet().unionAndStore(key, otherKey, destKey)获取两个或者多个集合的差集(otherKeys可以为单个值或者是集合)redisTemplate.opsForSet().difference(key, otherKeys)差集存储到destKey中(otherKeys可以为单个值或者集合)redisTemplate.opsForSet().differenceAndStore(key, otherKey, destKey)随机获取集合中的一个元素redisTemplate.opsForSet().randomMember(key)获取集合中的所有元素redisTemplate.opsForSet().members(key)随机获取集合中count个元素redisTemplate.opsForSet().randomMembers(key, count)获取多个key无序集合中的元素(去重),count表示个数redisTemplate.opsForSet().distinctRandomMembers(key, count)遍历set类似于Interator(ScanOptions.NONE为显示所有的)redisTemplate.opsForSet().scan(key, options)Hash类型
Long delete(H key, Object... hashKeys);
删除给定的哈希hashKeysSystem.out.println(template.opsForHash().delete("redisHash","name"));System.out.println(template.opsForHash().entries("redisHash"));1{class=6, age=28.1}Boolean hasKey(H key, Object hashKey);
确定哈希hashKey是否存在System.out.println(template.opsForHash().hasKey("redisHash","666"));System.out.println(template.opsForHash().hasKey("redisHash","777"));truefalseHV get(H key, Object hashKey);
从键中的哈希获取给定hashKey的值System.out.println(template.opsForHash().get("redisHash","age"));26Set<HK> keys(H key);
获取key所对应的散列表的keySystem.out.println(template.opsForHash().keys("redisHash"));//redisHash所对应的散列表为{class=1, name=666, age=27}[name, class, age]Long size(H key);
获取key所对应的散列表的大小个数System.out.println(template.opsForHash().size("redisHash"));//redisHash所对应的散列表为{class=1, name=666, age=27}3void putAll(H key, Map<? extends HK, ? extends HV> m);
使用m中提供的多个散列字段设置到key对应的散列表中Map<String,Object> testMap = new HashMap();testMap.put("name","666");testMap.put("age",27);testMap.put("class","1");template.opsForHash().putAll("redisHash1",testMap);System.out.println(template.opsForHash().entries("redisHash1"));{class=1, name=jack, age=27}void put(H key, HK hashKey, HV value);
设置散列hashKey的值template.opsForHash().put("redisHash","name","666");template.opsForHash().put("redisHash","age",26);template.opsForHash().put("redisHash","class","6");System.out.println(template.opsForHash().entries("redisHash"));{age=26, class=6, name=666}List<HV> values(H key);
获取整个哈希存储的值根据密钥System.out.println(template.opsForHash().values("redisHash"));[tom, 26, 6]Map<HK, HV> entries(H key);
获取整个哈希存储根据密钥System.out.println(template.opsForHash().entries("redisHash"));{age=26, class=6, name=tom}Cursor<Map.Entry<HK, HV>> scan(H key, ScanOptions options);
使用Cursor在key的hash中迭代,相当于迭代器。Cursor<Map.Entry<Object, Object>> curosr = template.opsForHash().scan("redisHash", ScanOptions.ScanOptions.NONE);while(curosr.hasNext()){Map.Entry<Object, Object> entry = curosr.next();System.out.println(entry.getKey()+":"+entry.getValue());}age:27class:6name:666| 命令 | 操作 | 返回值 |
| hash.delete(H key, Object... hashKeys) | 删除,可以传入多个map的key【hdel】 | Long |
| hash.hasKey(key, hashKey) | 查看hash中的某个hashKey是否存在【hexists】 | Boolean |
| hash.get(key, hashKey) | 获取值【hget】 | Object(HV 泛型约束对象) |
| hash.multiGet(H key, Collection<HK> hashKeys) | 批量获取集合中的key对应的值【hmget】 | List<HV> |
| hash.increment(H key, HK hashKey, long delta) | 对值进行+(delta值)操作【】 | Long |
| hash.increment(H key, HK hashKey, double delta) | ~ | double |
| hash.keys(key) | 返回map内hashKey的集合【hkeys】 | Set<HK> |
| hash.lengthOfValue(H key, HK hashKey) | 返回查询键关联的值的长度,为null则返回0【hstrlen】 | Long |
| hash.size(H key) | 获取hashKey的个数【hlen】 | Long |
| hash.putAll(H key, Map<? extends HK, ? extends HV> m) | 相当于map的putAll【hmset】 | void |
| hash.put(H key, HK hashKey, HV value) | 设置值,添加hashKey-value,hashKay相当于map的key 【hset】 | void |
| hash.putIfAbsent(H key, HK hashKey, HV value) | 仅当hashKey不存在时设置值 | Boolean |
| hash.values(key) | 返回value的集合【hvals】 | List<HV> |
| hase.entries(H key) | 获取map【hgetall】 | Map<HK, HV> |
| hash.scan(H key, ScanOptions options) | 基于游标的迭代查询【hscan】 | Cursor<Map.Entry<HK, HV>>(返回的Cursor要手动关闭,见下面示例2) |
| hash.getOperations() | 返回RedisOperation,它就是redis操作的接口 | RedisOperations<H, ?> |
ZSet类型
Boolean add(K key, V value, double score);
新增一个有序集合,存在的话为false,不存在的话为trueSystem.out.println(template.opsForZSet().add("zset1","zset-1",1.0));trueLong add(K key, Set<TypedTuple<V>> tuples);
新增一个有序集合ZSetOperations.TypedTuple<Object> objectTypedTuple1 = new DefaultTypedTuple<>("zset-5",9.6);ZSetOperations.TypedTuple<Object> objectTypedTuple2 = new DefaultTypedTuple<>("zset-6",9.9);Set<ZSetOperations.TypedTuple<Object>> tuples = new HashSet<ZSetOperations.TypedTuple<Object>>();tuples.add(objectTypedTuple1);tuples.add(objectTypedTuple2);System.out.println(template.opsForZSet().add("zset1",tuples));System.out.println(template.opsForZSet().range("zset1",0,-1));[zset-1, zset-2, zset-3, zset-4, zset-5, zset-6]
Long remove(K key, Object... values);
从有序集合中移除一个或者多个元素System.out.println(template.opsForZSet().range("zset1",0,-1));System.out.println(template.opsForZSet().remove("zset1","zset-6"));System.out.println(template.opsForZSet().range("zset1",0,-1));[zset-1, zset-2, zset-3, zset-4, zset-5, zset-6]1[zset-1, zset-2, zset-3, zset-4, zset-5]Long rank(K key, Object o);
返回有序集中指定成员的排名,其中有序集成员按分数值递增(从小到大)顺序排列System.out.println(template.opsForZSet().range("zset1",0,-1));System.out.println(template.opsForZSet().rank("zset1","zset-2"));[zset-2, zset-1, zset-3, zset-4, zset-5]0 //表明排名第一Set<V> range(K key, long start, long end);
通过索引区间返回有序集合成指定区间内的成员,其中有序集成员按分数值递增(从小到大)顺序排列System.out.println(template.opsForZSet().range("zset1",0,-1));[zset-2, zset-1, zset-3, zset-4, zset-5]
Long count(K key, double min, double max);
通过分数返回有序集合指定区间内的成员个数System.out.println(template.opsForZSet().rangeByScore("zset1",0,5));System.out.println(template.opsForZSet().count("zset1",0,5));[zset-2, zset-1, zset-3]3Long size(K key);
获取有序集合的成员数,内部调用的就是zCard方法System.out.println(template.opsForZSet().size("zset1"));6Double score(K key, Object o);
获取指定成员的score值System.out.println(template.opsForZSet().score("zset1","zset-1"));2.2Long removeRange(K key, long start, long end);
移除指定索引位置的成员,其中有序集成员按分数值递增(从小到大)顺序排列System.out.println(template.opsForZSet().range("zset2",0,-1));System.out.println(template.opsForZSet().removeRange("zset2",1,2));System.out.println(template.opsForZSet().range("zset2",0,-1));[zset-1, zset-2, zset-3, zset-4]2[zset-1, zset-4]Cursor<TypedTuple<V>> scan(K key, ScanOptions options);
遍历zsetCursor<ZSetOperations.TypedTuple<Object>> cursor = template.opsForZSet().scan("zzset1", ScanOptions.NONE);while (cursor.hasNext()){ZSetOperations.TypedTuple<Object> item = cursor.next();System.out.println(item.getValue() + ":" + item.getScore());}zset-1:1.0zset-2:2.0zset-3:3.0zset-4:6.0相关文章:
Redis快速上手篇(三)(事务+Idea的连接和使用)
Redis事务 可以一次执行多个命令,本质是一组命令的集合。一个事务中的 所有命令都会序列化,按顺序地串行化执行而不会被其它命令插入,不许加塞。 单独的隔离的操作 官网说明 https://redis.io/docs/interact/transactions/ MULTI、EXEC、…...
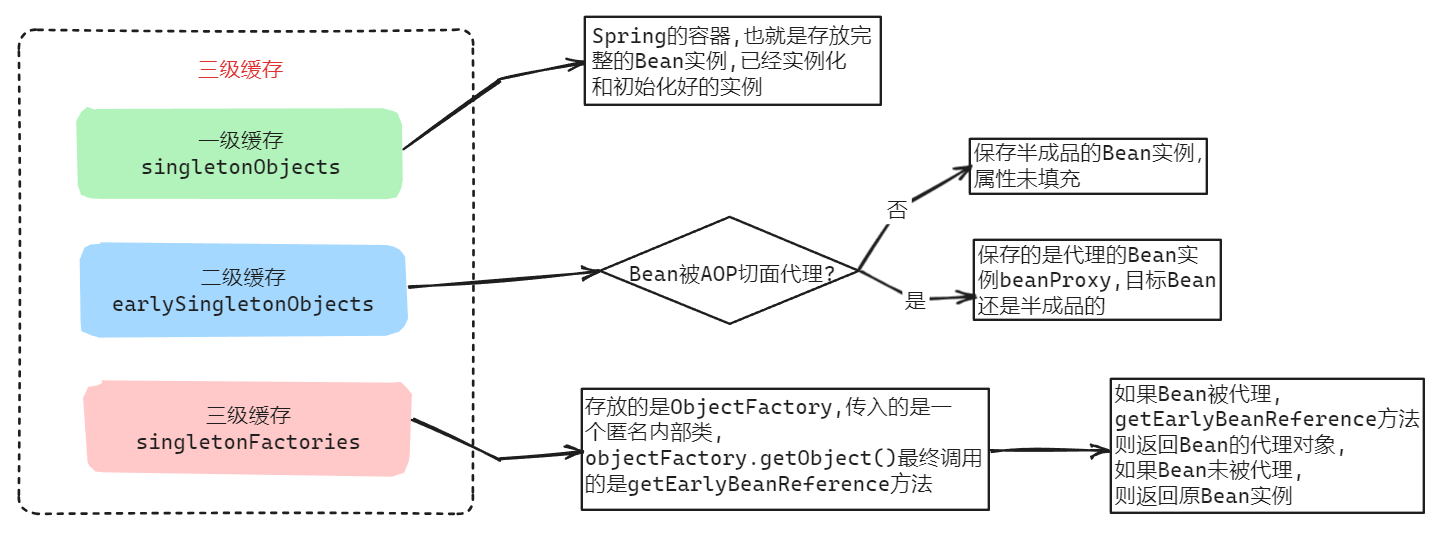
Spring三级缓存解决循环依赖问题
文章目录 1. 三级缓存解决的问题场景2. 三级缓存的差异性3. 循环依赖时的处理流程4. 源码验证 1. 三级缓存解决的问题场景 循环依赖指的是在对象之间存在相互依赖关系,形成一个闭环,导致无法准确地完成对象的创建和初始化;当两个或多个对象彼…...
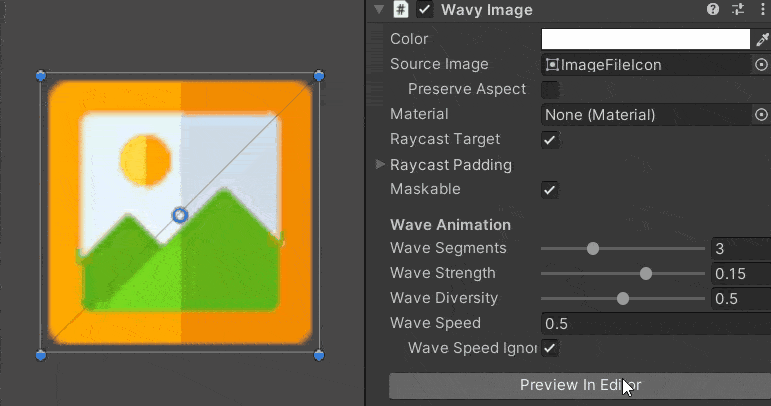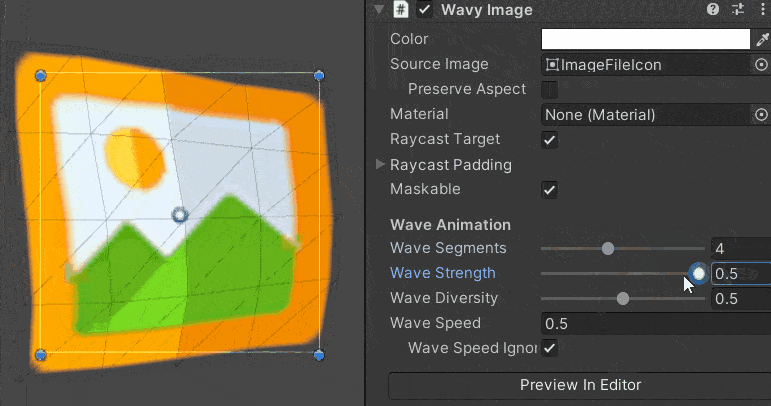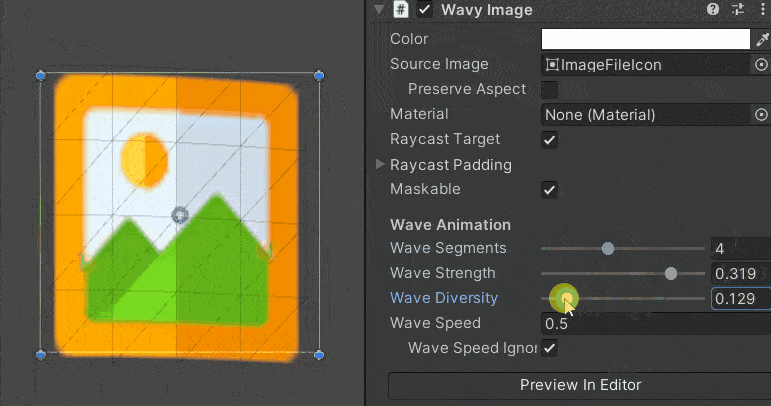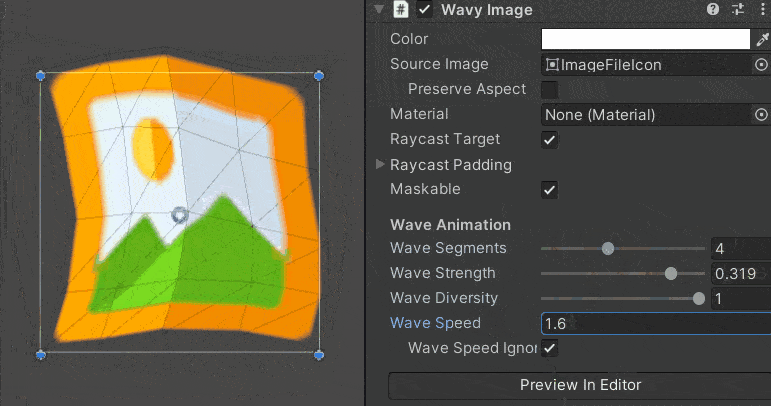
Unity 中使用波浪动画创建 UI 图像
如何使用 只需将此组件添加到画布中的空对象即可。强烈建议您将此对象放入其自己的画布/嵌套画布中,因为它会弄脏每一帧的画布并导致重新生成整个网格。 注意:不支持切片图像。 using System.Collections.Generic; using UnityEngine; using UnityEng…...

支付功能测试用例测试点?
支付功能测试用例测试点是指在测试支付功能时,需要关注和验证的各个方面。根据不同的支付场景和需求,支付功能测试用例测试点可能有所不同,但一般可以分为以下几类: 功能测试:主要检查支付功能是否符合设计和业务需求…...
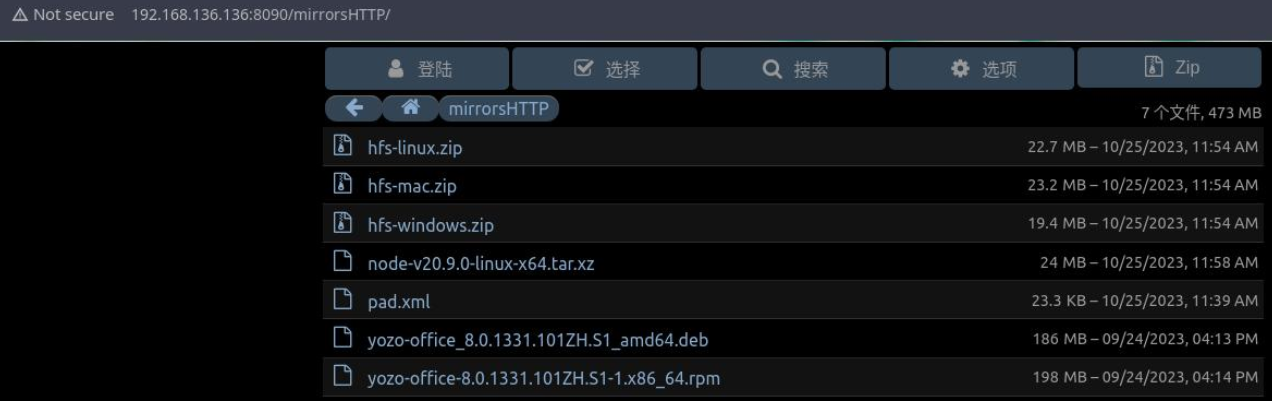
HFS 快速搭建 http 服务器
HFS 是一个轻量级的HTTP 服务工具,3.0版本前进提供Windows平台安装包,3.0版本开提供Linux和macOS平台的安装包。 HFS更适合在局域网环境中搭建文件共享服务或者安装配置源服务器。 甲 非守护进程的方式运行 HFS (Ubuntu 22.04) 一…...

学生专用台灯怎么选?双十一专业学生护眼台灯推荐
台灯应该是很多家庭都会备上一盏的家用灯具,很多大人平时间看书、用电脑都会用上它,不过更多的可能还是给家中的小孩学习、阅读使用的。而且现在的孩子近视率如此之高,这让家长们不得不重视孩子的视力健康问题。那么孩子学习使用的台灯应该怎…...

Go 常用标准库之 fmt 介绍与基本使用
Go 常用标准库之 fmt 介绍与基本使用 文章目录 Go 常用标准库之 fmt 介绍与基本使用一、介绍二、向外输出2.1 Print 系列2.2 Fprint 系列2.3 Sprint 系列2.4 Errorf 系列 三、格式化占位符3.1 通用占位符3.2 布尔型3.3 整型3.4 浮点数与复数3.5 字符串和[]byte3.6 指针3.7 宽度…...

antv/x6 导出图片方法exportPNG
antv/x6 导出图片方法exportPNG antv/x6 版本如下: "antv/x6": "2.14.1","antv/x6-plugin-export": "2.1.6",在文件中导入 import { Graph, Shape, StringExt } from antv/x6 import { Export } from antv/x6-plugin-exp…...
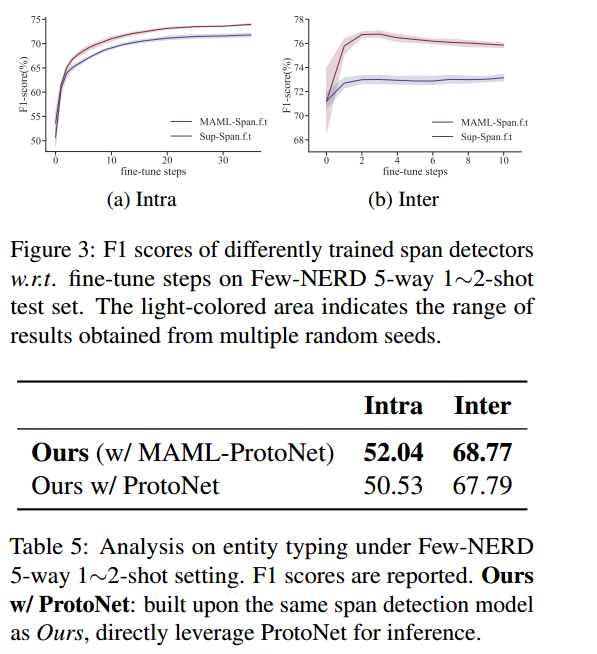
Decomposed Meta-Learning for Few-Shot Named Entity Recognition
原文链接: https://aclanthology.org/2022.findings-acl.124.pdf ACL 2022 介绍 问题 目前基于span的跨度量学习(metric learning)的方法存在一些问题: 1)由于是通过枚举来生成span,因此在解码的时候需要额…...

C++经典面试题:内存泄露是什么?如何排查?
1.内存泄露的定义:内存泄漏简单的说就是申请了⼀块内存空间,使⽤完毕后没有释放掉。 它的⼀般表现⽅式是程序运⾏时间越⻓,占⽤内存越多,最终⽤尽全部内存,整个系统崩溃。由程序申请的⼀块内存,且没有任何⼀…...
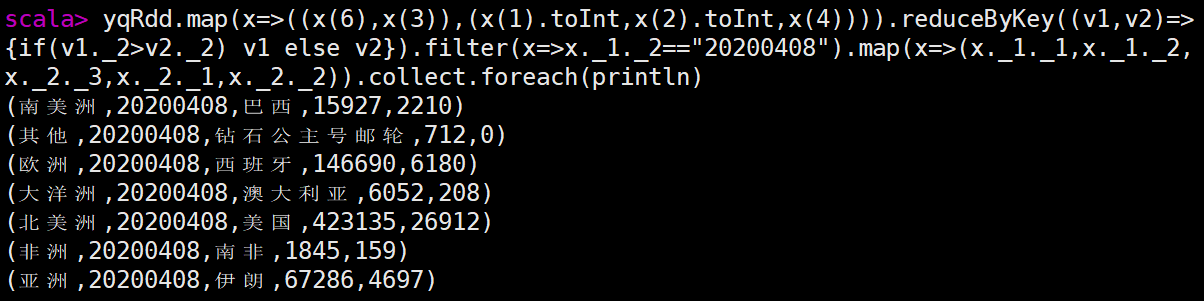
Hadoop+Hive+Spark+Hbase开发环境练习
1.练习一 1.数据准备 在hdfs上创建文件夹,上传csv文件 [rootkb129 ~]# hdfs dfs -mkdir -p /app/data/exam 查看csv文件行数 [rootkb129 ~]# hdfs dfs -cat /app/data/exam/meituan_waimai_meishi.csv | wc -l 2.分别使用 RDD和 Spark SQL 完成以下分析…...
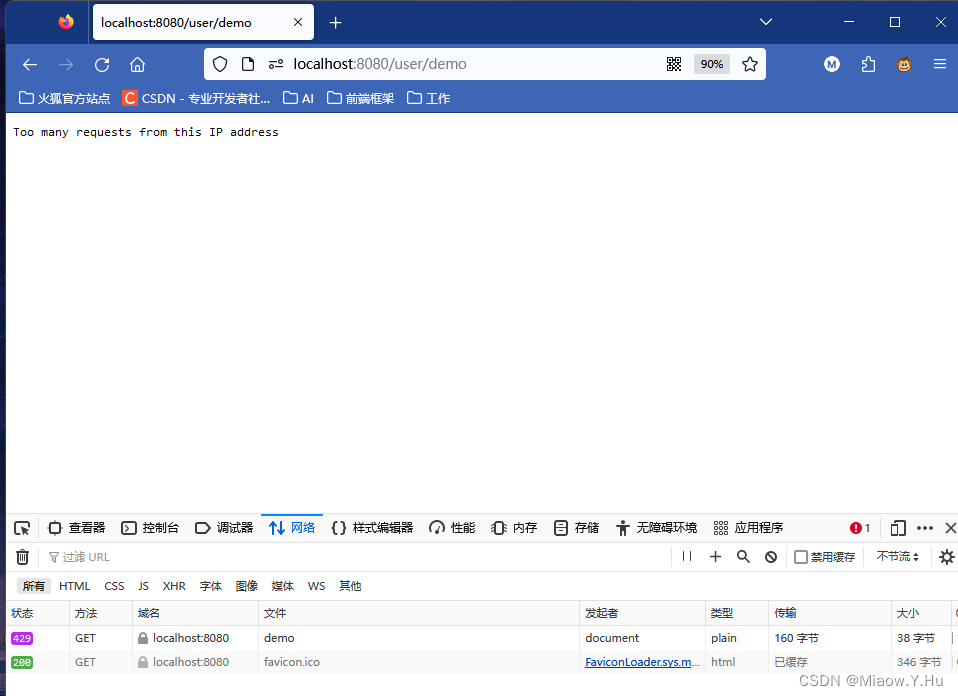
使用Spring Boot限制在一分钟内某个IP只能访问10次
有些时候,为了防止我们上线的网站被攻击,或者被刷取流量,我们会对某一个ip进行限制处理,这篇文章,我们将通过Spring Boot编写一个小案例,来实现在一分钟内同一个IP只能访问10次,当然具体数值&am…...
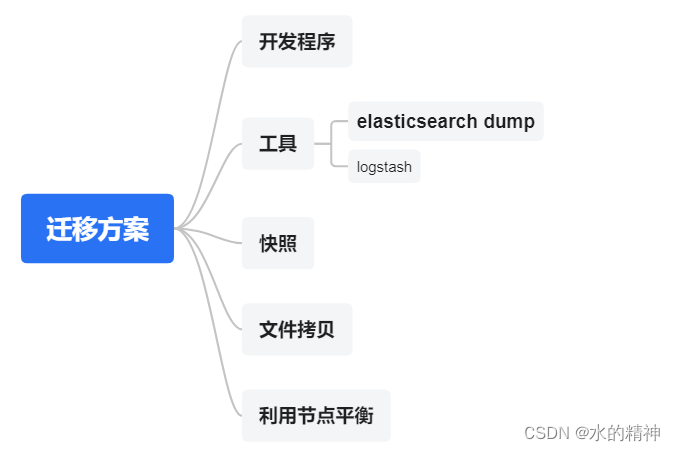
ES 数据迁移最佳实践
ES 数据迁移最佳实践与讲解 数据迁移是 Elasticsearch 运维管理和业务需求中常见的操作之一。以下是不同数据迁移方法的最佳实践和讲解: 一、数据迁移需求梳理 二、数据迁移方法梳理 三、各方案对比 方案 优点 缺点(限制) 适用场景 是否有…...

C++中低级内存操作
C中低级内存操作 C相较于C有一个巨大的优势,那就是你不需要过多地担心内存管理。如果你使用面向对象的编程方式,你只需要确保每个独立的类都能妥善地管理自己的内存。通过构造和析构,编译器会帮助你管理内存,告诉你什么时候需要进…...
)
Linux硬盘大小查看命令全解析 (linux查看硬盘大小命令)
Linux操作系统是一款广泛应用于服务器和嵌入式设备的操作系统,相比于Windows等其他操作系统,Linux的优点之一就是支持强大的命令行操作。在日常操作中,了解和掌握一些简单但实用的命令可以提高工作效率。比如硬盘大小查看命令,在L…...

什么是供应链金融?
一、供应链金融产生背景 供应链金融兴起的起源来自于供应链管理一个产品生产过程分为三个阶段:原材料 - 中间产品 - 成产品。由于技术进步需求升级,生产过程从以前的企业内分工,转变为企业间分工。那么整个过程演变了如今的供应链管理流程&a…...
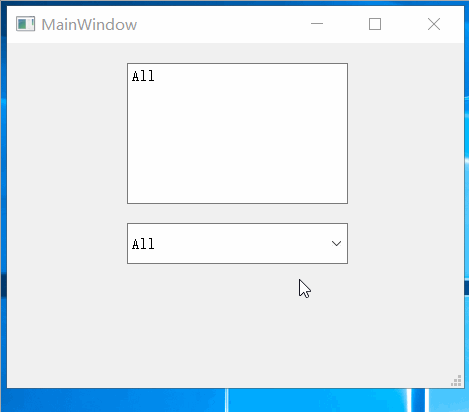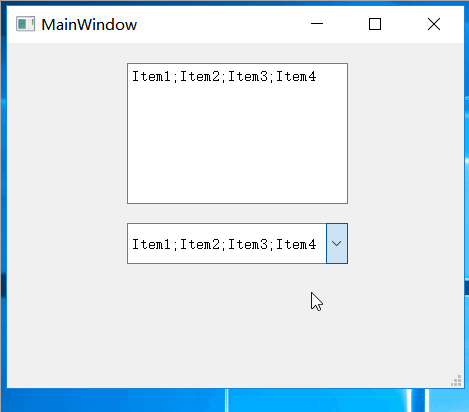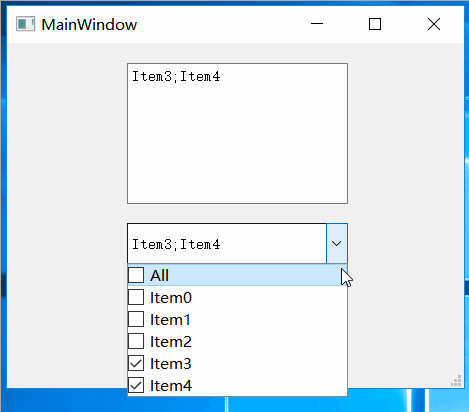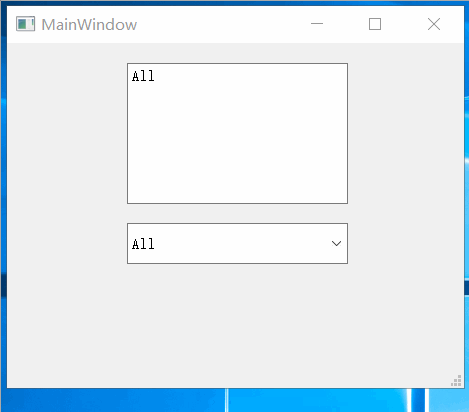
Qt之实现支持多选的QCombobox
一.效果 1.点击下拉列表的复选框区域 2.点击下拉列表的非复选框区域 二.实现 QHCustomComboBox.h #ifndef QHCUSTOMCOMBOBOX_H #define QHCUSTOMCOMBOBOX_H#include <QLineEdit> #include <QListWidget> #include <QCheckBox> #include <QComboBox>…...

【UI设计】Figma_“全面”快捷键
目录 1.快捷键与键位(mac与windows)2.基础快捷键3.操作区快捷键3.1视图3.2文字3.3选项3.4图层3.5组件 4.特殊技巧 Figma 是一个 基于浏览器 的协作式 UI 设计工具。【https://www.figma.com/】 Figma Sketch(UI 设计) InVision&a…...

计算机网络(谢希仁)第八版课后题答案(第一章)
1.计算机网络可以向用户提供哪些服务 连通性:计算机网络使上网用户之间可以交换信息,好像这些用户的计算机都可以彼此直接连通一样。 共享:指资源共享。可以是信息、软件,也可以是硬件共享。 2.试简述分组交换的要点 采用了存储转发技术。把报文(要发…...

argparse模块介绍
argparse是一个Python模块:命令行选项、参数和子命令解析器。argparse 模块可以让人轻松编写用户友好的命令行接口。程序定义了所需的参数,而 argparse 将找出如何从 sys.argv (命令行)中解析这些参数。argparse 模块还会自动生成…...

OpenClaw性能优化:GLM-4.7-Flash长任务链的Token节省技巧
OpenClaw性能优化:GLM-4.7-Flash长任务链的Token节省技巧 1. 问题背景:长任务链的Token消耗困境 上周我尝试用OpenClaw自动化处理一个典型的办公场景:从200页PDF中提取关键数据,整理成Excel表格后发送邮件。整个流程涉及PDF解析…...

技术日报|字节DeerFlow今日强势登顶日增3787星总量破4.6万,3D建筑编辑器黑马杀入前二
🌟 TrendForge 每日精选 - 发现最具潜力的开源项目 📊 今日共收录 12 个热门项目🌐 智能中文翻译版 - 项目描述已自动翻译,便于理解🏆 今日最热项目 Top 10 🥇 bytedance/deer-flow 项目简介: DeerFlow是一…...

如何快速配置HomeAssistant格力空调本地控制组件:完整操作指南
如何快速配置HomeAssistant格力空调本地控制组件:完整操作指南 【免费下载链接】HomeAssistant-GreeClimateComponent Custom Gree climate component written in Python3 for Home Assistant. Controls ACs supporting the Gree protocol. 项目地址: https://git…...

Onekey:Steam游戏清单管理的自动化解决方案 | 玩家与开发者必备工具
Onekey:Steam游戏清单管理的自动化解决方案 | 玩家与开发者必备工具 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 当独立游戏开发者小林第三次因为手动复制Steam App ID出错而导致…...

不止于集成:在RuoYi-Camunda流程设计器中实现自定义属性面板与FEEL表达式校验
深度定制RuoYi-Camunda流程设计器:从属性面板扩展到FEEL表达式校验实战 当标准BPMN设计器无法满足复杂业务需求时,定制化开发成为必经之路。某跨国零售企业的审批系统曾因无法在流程节点上定义"区域经理审批阈值"字段,导致每次业务…...

Proteus8.9 安装避坑指南:从下载到稳定运行的完整流程
1. 为什么选择Proteus8.9? Proteus作为电子设计自动化(EDA)领域的经典工具,在单片机仿真和电路设计方面一直备受工程师和学生青睐。8.9版本之所以成为众多用户的首选,主要在于它对新型单片机的支持更加完善。比如STC15…...

Windows Insider离线管理完全指南:无账户切换方法与命令行操作技巧
Windows Insider离线管理完全指南:无账户切换方法与命令行操作技巧 【免费下载链接】offlineinsiderenroll 项目地址: https://gitcode.com/gh_mirrors/of/offlineinsiderenroll 在Windows系统管理中,用户常常面临需要在不同更新通道间切换的需求…...

基于springboot框架个性化旅游线路推荐系统 景区门票 酒店 预订88u7sgf 有论文-idea maven vue
目录系统架构设计技术选型与工具数据库设计核心功能实现论文研究要点开发计划安排项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作系统架构设计 采用前后端分离架构,后端基于SpringBoot框架,前端使用Vue…...

终极免费逆向神器Ghidra:3分钟极速安装与新手入门指南
终极免费逆向神器Ghidra:3分钟极速安装与新手入门指南 【免费下载链接】ghidra_installer Helper scripts to set up OpenJDK 11 and scale Ghidra for 4K on Ubuntu 18.04 / 18.10 项目地址: https://gitcode.com/gh_mirrors/gh/ghidra_installer 还在为复杂…...

单片机Shell开发避坑指南:从Putty特殊字符处理到内存安全的7个实战经验
单片机Shell开发避坑指南:从Putty特殊字符处理到内存安全的7个实战经验 当你在深夜调试单片机Shell时,突然发现退格键会导致整个系统崩溃,或者用户输入超长字符串后设备莫名其妙重启——这些看似简单的交互问题,往往成为项目交付前…...