基于PyTorch的MNIST手写体分类实战
第2章对MNIST数据做了介绍,描述了其构成方式及其数据的特征和标签的含义等。了解这些有助于编写合适的程序来对MNIST数据集进行分析和识别。本节将使用同样的数据集完成对其进行分类的任务。
3.1.1 数据图像的获取与标签的说明
MNIST数据集的详细介绍在第2章中已经完成,读者可以使用相同的代码对数据进行获取,代码如下:
import numpy as np
x_train = np.load("./dataset/mnist/x_train.npy")
y_train_label = np.load("./dataset/mnist/y_train_label.npy")
基本数据的获取与第2章类似,这里就不过多阐述了,不过需要注意的是,在第2章介绍数据集时只使用了图像数据,没有对标签进行说明,在这里重点对数据标签,也就是y_train_label进行介绍。
我们可以使用下面语句打印出数据集的前10个标签:
print(y_train_label[:10])结果如下:
import numpy as np
import torch
x_train = np.load("./dataset/mnist/x_train.npy")
y_train_label = np.load("./dataset/mnist/y_train_label.npy")
x = torch.tensor(y_train_label[:5],dtype=torch.int64)
# 定义一个张量输入,因为此时有 5 个数值,且最大值为9,类别数为10
# 所以我们可以得到 y 的输出结果的形状为 shape=(5,10),即5行12列
y = torch.nn.functional.one_hot(x, 10) # 一个参数张量x,10为类别数
ptint(y)
结果如下:
tensor([[0, 0, 0, 0, 0, 1, 0, 0, 0, 0],[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 1, 0, 0, 0, 0, 0],[0, 1, 0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0, 0, 1]])
可以看到,one_hot的作用是将一个序列转换成以one_hot形式表示的数据集。所有的行或者列都被设置成0,而每个特定的位置都对应一个1来表示,如图3-1所示。

图3-1 one_hot形式表示的数据集
对于MNIST数据集的标签来说,这实际上就是一个60 000幅图片的60 000×10大小的矩阵张量[60 000,10]。前面的数指的是数据集中图片的个数为60 000个,后面的10指的是10个列向量。
下面使用PyTorch 2.0框架完成手写体的识别。
3.1.2 模型的准备(多层感知机)
在第2章已经讲过了,PyTorch最重要的一项内容是模型的准备与设计,而模型的设计最关键的一点就是了解输出和输入的数据结构类型。
通过第2章有关图像去噪的演示,读者已经了解了我们的输入数据格式是一个[28,28]大小的二维图像。而通过对数据结构的分析,我们可以知道,对于每个图形都有一个确定的分类结果,也就是0~10的一个确定数字。
下面将按这个想法来设计模型。从前面对图像的分析来看,对整体图形进行判别的一个基本想法就是将图像作为一个整体直观地进行判别,因此基于这种解决问题的思路,简单的模型设计就是同时对图像所有参数进行计算,即使用一个多层感知机(Multi-Layer Perceptron,MLP)对图像进行分类。整体的模型设计结构如图3-2所示。
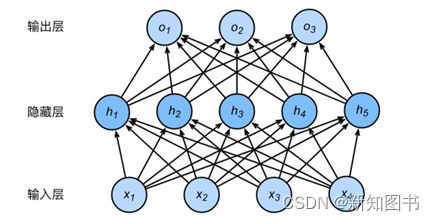
图3-2 整体的模型设计结构
从图3-2可以看到,一个多层感知机模型就是将数据输入后,分散到每个模型的节点(隐藏层),进行数据计算后,再将计算结果输出到对应的输出层中。多层感知机的模型结构如下:
class NeuralNetwork(nn.Module):def __init__(self):super(NeuralNetwork, self).__init__()self.flatten = nn.Flatten()self.linear_relu_stack = nn.Sequential(nn.Linear(28*28,312),nn.ReLU(),nn.Linear(312, 256),nn.ReLU(),nn.Linear(256, 10))def forward(self, input):x = self.flatten(input)logits = self.linear_relu_stack(x)return logits
3.1.3 损失函数的表示与计算
第2章使用了MSELoss作为目标图形与预测图形的损失值,而在本例中,我们需要预测的目标是图形的“分类”,而不是图形表示本身,因此我们需要寻找并使用一种新的能够对类别归属进行“计算”的函数。
本例所使用的交叉熵损失函数为torch.nn.CrossEntropyLoss。PyTorch官方网站对其介绍如下:
CLASS torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=- 100,reduce=None, reduction='mean', label_smoothing=0.0)该损失函数计算输入值(Input)和目标值(Target)之间的交叉熵损失。交叉熵损失函数CrossEntropyLoss可用于训练单类别或者多类别的分类问题。给定参数weight时,会为传递进来的每个类别的计算数值重新加载一个修正权重。当数据集分布不均衡时,这是很有用的。
同样需要注意的是,因为torch.nn.CrossEntropyLoss内置了Softmax运算,而Softmax的作用是计算分类结果中最大的那个类。从图3-3所示的对PyTorch 2.0中CrossEntropyLoss的实现可以看到,此时CrossEntropyLoss已经在计算的同时实现了Softmax计算,因此在使用torch.nn.CrossEntropyLoss作为损失函数时,不需要在网络的最后添加Softmax层。此外,label应为一个整数,而不是One-Hot编码形式。
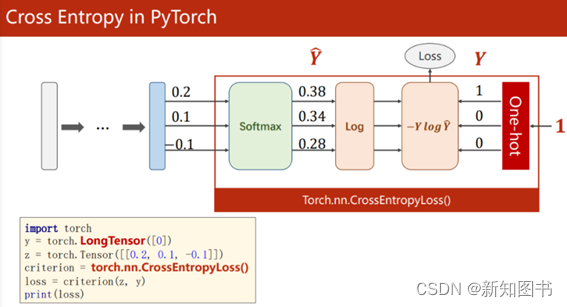
图3-3 使用torch.nn.CrossEntropyLoss()作为损失函数
CrossEntropyLoss示例代码如下:
import torch
y = torch.LongTensor([0])
z = torch.Tensor([[0.2,0.1,-0.1]])
criterion = torch.nn.CrossEntropyLoss()
loss = criterion(z,y)
print(loss)
CrossEntropyLoss的数学公式较为复杂,建议学有余力的读者查阅相关内容进行学习,目前只需要掌握这方面内容即可。
3.1.4 基于PyTorch的手写体识别的实现
下面介绍基于PyTorch的手写体识别的实现。通过前文的介绍,我们还需要定义深度学习的优化器部分,在这里采用Adam优化器,相关代码如下:
model = NeuralNetwork()
optimizer = torch.optim.Adam(model.parameters(), lr=2e-5) #设定优化函数
在这个实战案例中首先需要定义模型,之后将模型参数传入优化器中,lr是对学习率的设定,根据设定的学习率进行模型计算。完整的手写体识别模型如下:
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #指定GPU编号
import torch
import numpy as np
from tqdm import tqdm
batch_size =320#设定每次训练的批次数
epochs=1024 #设定训练次数
#device="cpu" #PyTorch的特性,需要指定计算的硬件,如果没有GPU,就使用CPU进行计算
device="cuda" #在这里默认使用GPU,如果读者运行出现问题,可以将其改成CPU模式#设定的多层感知机网络模型
class NeuralNetwork(torch.nn.Module):def __init__(self):super(NeuralNetwork, self).__init__()self.flatten = torch.nn.Flatten()self.linear_relu_stack = torch.nn.Sequential(torch.nn.Linear(28*28,312),torch.nn.ReLU(),torch.nn.Linear(312, 256),torch.nn.ReLU(),torch.nn.Linear(256, 10))def forward(self, input):x = self.flatten(input)logits = self.linear_relu_stack(x)return logitsmodel = NeuralNetwork()
model = model.to(device) #将计算模型传入GPU硬件等待计算
model = torch.compile(model) #PyTorch 2.0的特性,加速计算速度
loss_fu = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=2e-5) #设定优化函数#载入数据
x_train = np.load("../../dataset/mnist/x_train.npy")
y_train_label = np.load("../../dataset/mnist/y_train_label.npy")
train_num = len(x_train)//batch_size#开始计算
for epoch in range(20):train_loss = 0for i in range(train_num):start = i * batch_sizeend = (i + 1) * batch_sizetrain_batch = torch.tensor(x_train[start:end]).to(device)label_batch = torch.tensor(y_train_label[start:end]).to(device)pred = model(train_batch)loss = loss_fu(pred,label_batch)optimizer.zero_grad()loss.backward()optimizer.step()train_loss += loss.item() # 记录每个批次的损失值# 计算并打印损失值train_loss /= train_numaccuracy = (pred.argmax(1) == label_batch).type(torch.float32).sum().item() / batch_sizeprint("train_loss:", round(train_loss,2),"accuracy:",round(accuracy,2))
此时模型的训练结果如图3-4所示。

图3-4 模型的训练结果
可以看到随着模型循环次数的增加,模型的损失值在降低,而准确率在增高,具体请读者自行验证测试。
本文节选自《PyTorch 2.0深度学习从零开始学》。

相关文章:
基于PyTorch的MNIST手写体分类实战
第2章对MNIST数据做了介绍,描述了其构成方式及其数据的特征和标签的含义等。了解这些有助于编写合适的程序来对MNIST数据集进行分析和识别。本节将使用同样的数据集完成对其进行分类的任务。 3.1.1 数据图像的获取与标签的说明 MNIST数据集的详细介绍在第2章中已…...

conda 复制系统环境
直接复制 想要通过 conda 直接复制一个已存在的环境,你可以使用 conda create 命令并配合 --clone 参数。以下是具体步骤: 查看现有的环境: 首先,你可以使用以下命令来查看所有的 conda 环境: conda env list这会给你一个环境列表…...
如何在Microsoft Visual Studio 中使用Cpp代码调用python代码
Microsoft Visual Studio中Cpp调用Python代码 本文介绍如何在Microsoft Visual Studio中,开发cpp项目时,调用python代码。 文章目录 Microsoft Visual Studio中Cpp调用Python代码前言一、Cpp生成exe文件1.1 安装python环境1.2 配置Microsoft Visual Stu…...
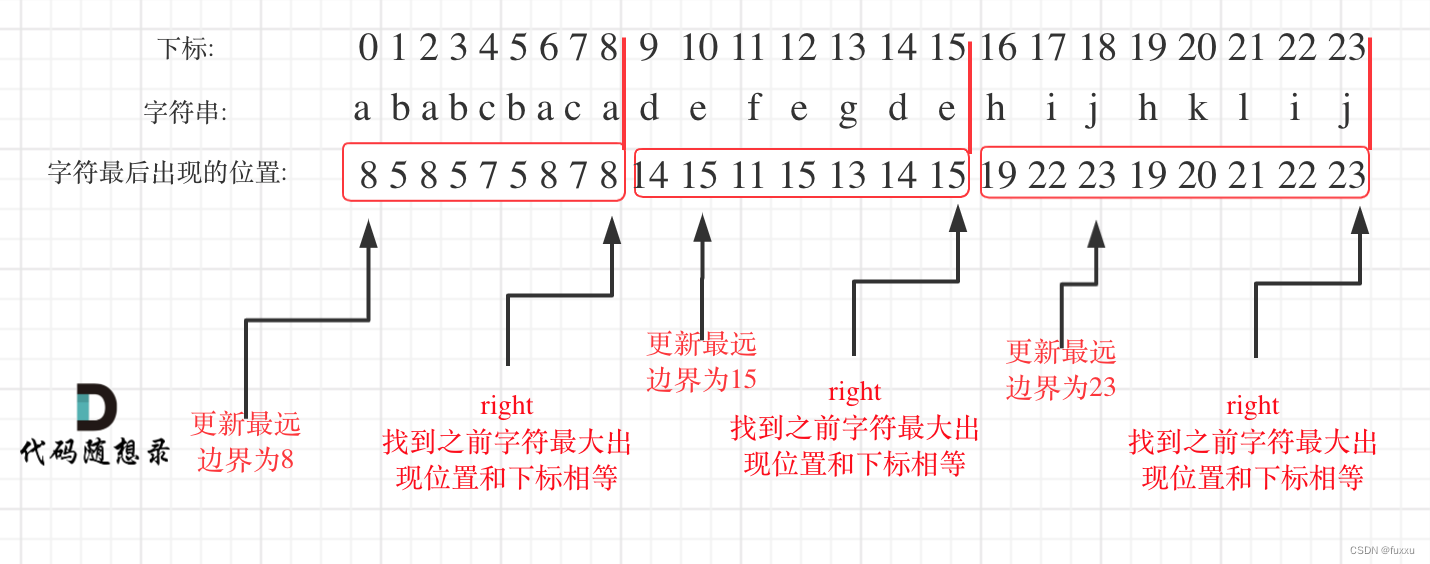
DAY35 435. 无重叠区间 + 763.划分字母区间 + 56. 合并区间
435. 无重叠区间 题目要求:给定一个区间的集合,找到需要移除区间的最小数量,使剩余区间互不重叠。 注意: 可以认为区间的终点总是大于它的起点。 区间 [1,2] 和 [2,3] 的边界相互“接触”,但没有相互重叠。 示例 1: 输入: [ […...
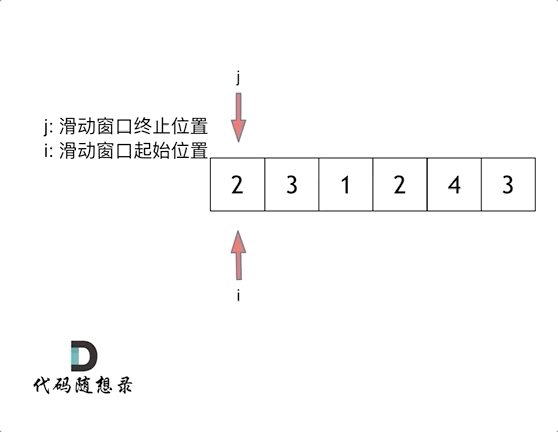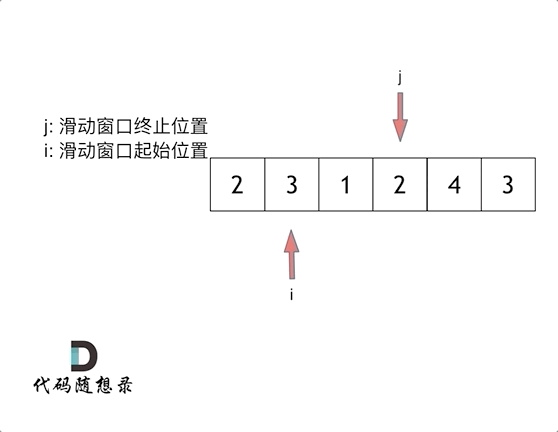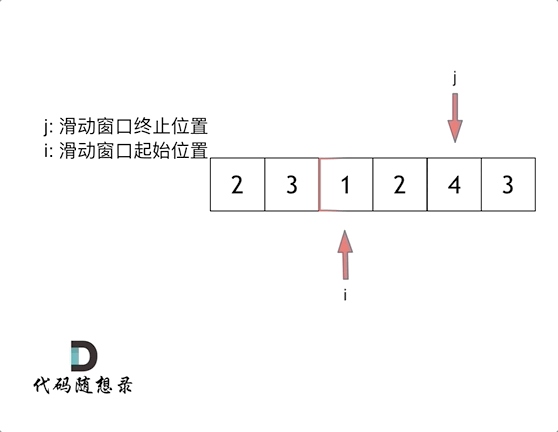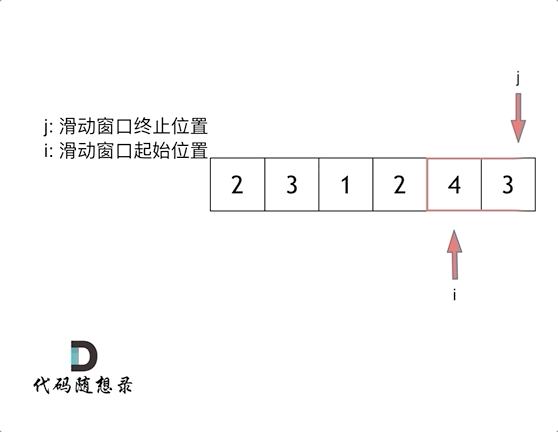
代码随想录算法训练营第2天| 977有序数组的平方、209长度最小的子数组。
JAVA代码编写 977. 有序数组的平方 给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。 示例 1: 输入:nums [-4,-1,0,3,10] 输出:[0,1,9,16,100] 解释&…...

微信小程序通过startLocationUpdate,onLocationChange获取当前地理位置信息,配合腾讯地图解析获取到地址
先创建个getLocation.js文件 //获取用户当前所在的位置 const getLocation () > {return new Promise((resolve, reject) > {let _locationChangeFn (res) > {resolve(res) // 回传地里位置信息wx.offLocationChange(_locationChangeFn) // 关闭实时定位wx.stopLoc…...

C/C++字符三角形 2020年12月电子学会青少年软件编程(C/C++)等级考试一级真题答案解析
目录 C/C字符三角形 一、题目要求 1、编程实现 2、输入输出 二、算法分析 三、程序编写 四、程序说明 五、运行结果 六、考点分析 C/C字符三角形 2020年12月 C/C编程等级考试一级编程题 一、题目要求 1、编程实现 给定一个字符,用它构造一个底边长5个字…...

Python数据挖掘:入门、进阶与实用案例分析——基于非侵入式负荷检测与分解的电力数据挖掘
文章目录 摘要01 案例背景02 分析目标03 分析过程04 数据准备05 属性构造06 模型训练07 性能度量08 推荐阅读赠书活动 摘要 本案例将根据已收集到的电力数据,深度挖掘各电力设备的电流、电压和功率等情况,分析各电力设备的实际用电量,进而为电…...
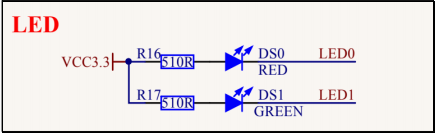
基于 Qt控制开发板 LED和C语言控制LED渐变亮度效果
## 资源简介 在STM32开发板,板载资源上有两个可自由控制的 LED。如下图原理 图其中我们以操作 LED1 为示例,LED1 为出厂系统的心跳指示灯。 ## 应用实例 想要控制这个 LED,首先出厂内核已经默认将这个 LED 注册成了 gpio-leds类型设备。所以我们可以直接在应用层接口直接…...
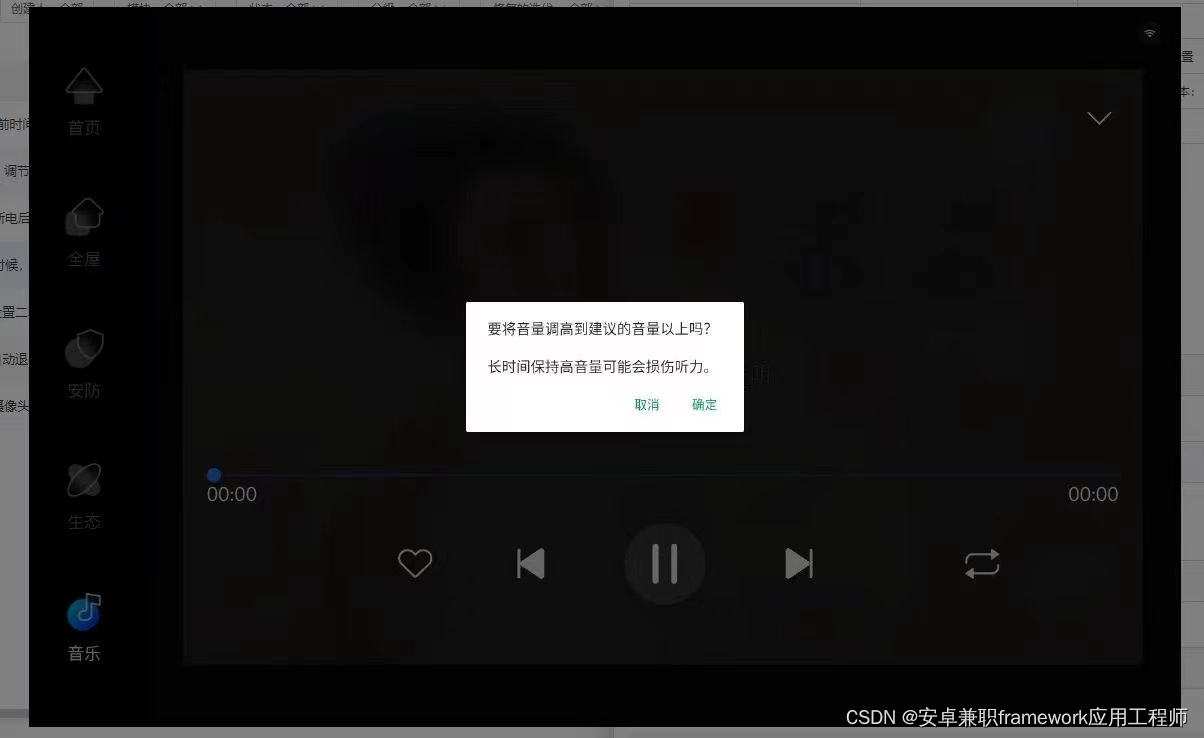
Android 11.0 禁用插入耳机时弹出的保护听力对话框
1.前言 在11.0的系统开发中,在某些产品中会对耳机音量调节过高限制,在调高到最大音量的70%的时候,会弹出音量过高弹出警告,所以产品 开发的需要要求去掉这个音量弹窗警告功能 2.禁用插入耳机时弹出的保护听力对话框的核心类 frameworks\base\packages\SystemUI\src\com\and…...
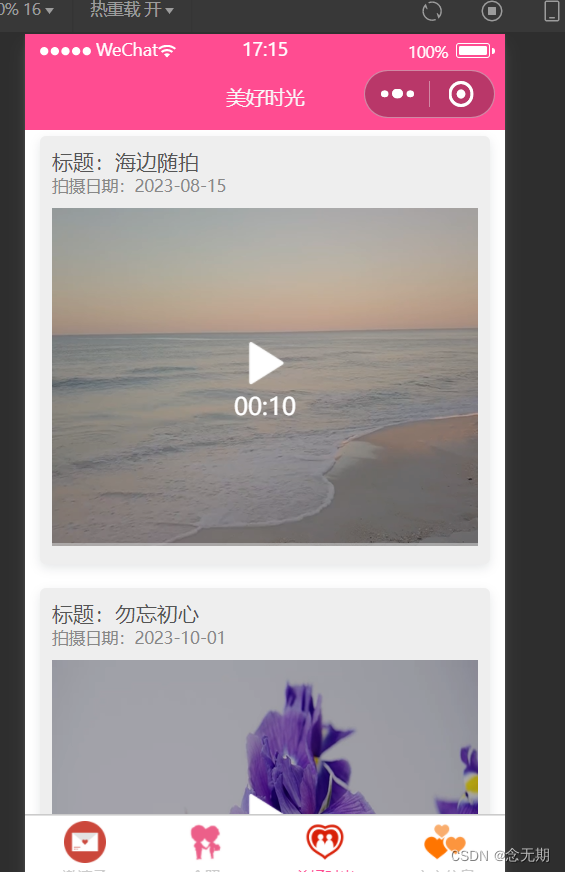
微信小程序案例2-3:婚礼邀请函
文章目录 一、运行效果二、知识储备(一)导航栏配置(二)标签栏配置(三)vw、vh单位(四)video组件(五)表单组件(六)Node.js概述 三、实现…...
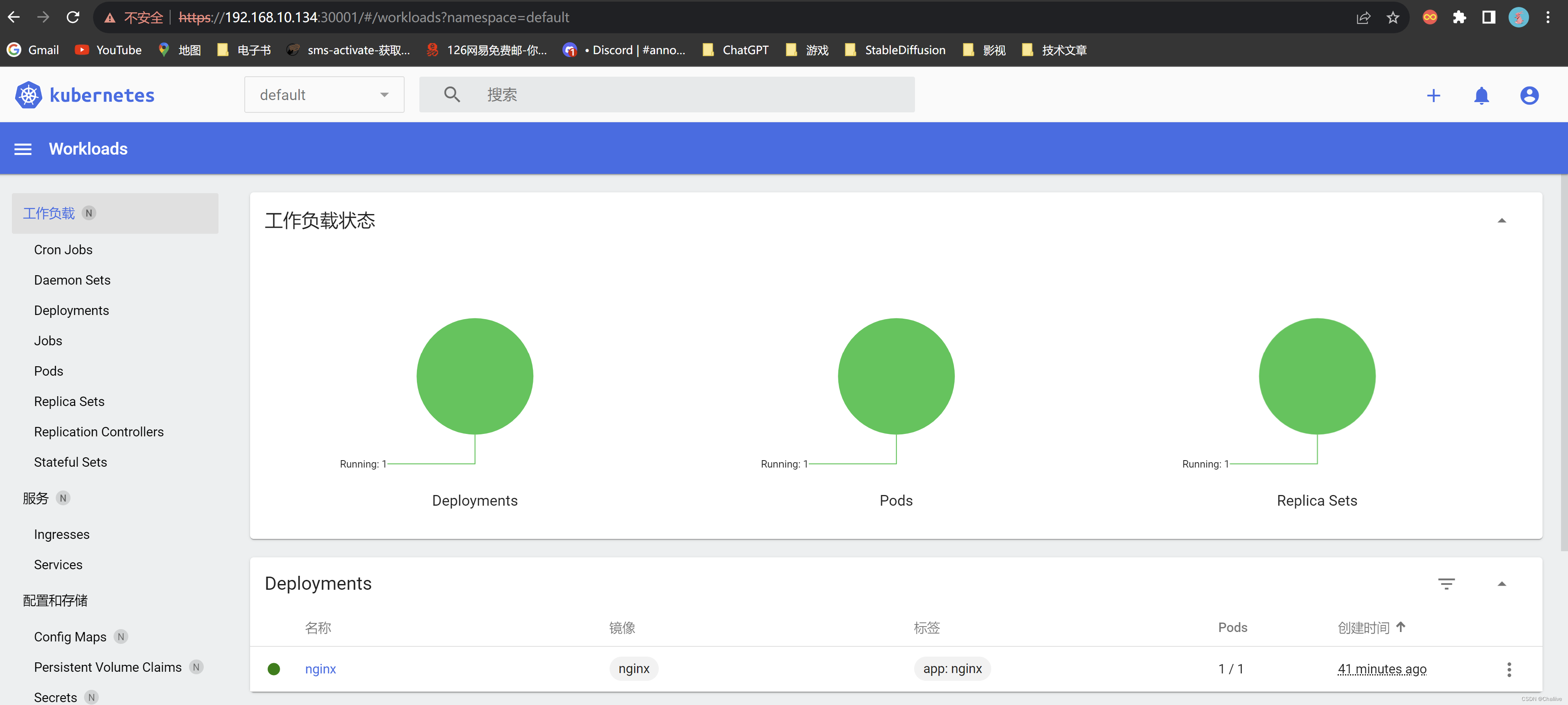
K8S部署Dashboard
获取recommended.yaml文件 Dashboard是官方提供的一个UI,可用于基本管理K8s资源。 YAML下载地址: wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.4.0/aio/deploy/recommended.yaml如果网络错误无法直接下载,可以直接访问…...

【OJ比赛日历】快周末了,不来一场比赛吗? #10.29-11.04 #7场
CompHub[1] 实时聚合多平台的数据类(Kaggle、天池…)和OJ类(Leetcode、牛客…)比赛。本账号会推送最新的比赛消息,欢迎关注! 以下信息仅供参考,以比赛官网为准 目录 2023-10-29(周日) #3场比赛2023-10-30…...

常用应用安装教程---在centos7系统上安装Docker
在centos7系统上安装Docker 1:切换镜像源 wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo2:查看当前镜像源中支持的docker版本 yum list docker-ce --showduplicates | sort -r3&#x…...
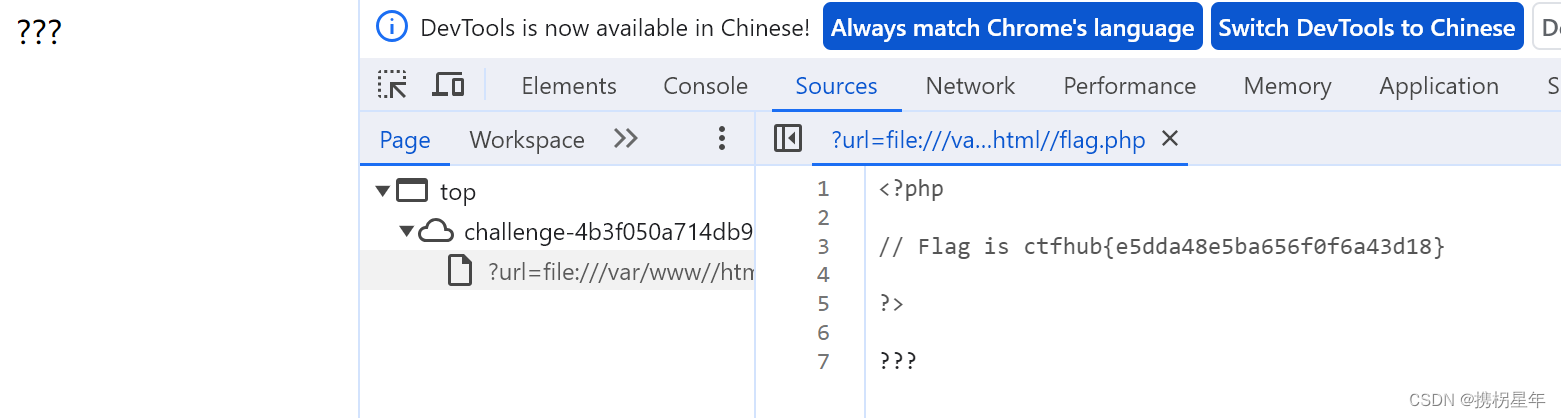
CTFHub-SSRF-读取伪协议
WEB攻防-SSRF服务端请求&Gopher伪协议&无回显利用&黑白盒挖掘&业务功能点-CSDN博客 伪协议有: file:/// — 访问本地文件系统 http:/// — 访问 HTTP(s) 网址 ftp:/// — 访问 FTP(s) URLs php:/// — 访问各个输入/输出流(I/O streams) dic…...

推荐一款适合科技行业的CRM系统
推荐您一款科技行业好用的CRM系统——Zoho CRM客户管理系统,旨在帮助企业管理客户数据、销售过程、营销活动以及服务支持,助力业务增长及数字化转型,实现“以客户为中心”的企业管理和运营模式。 近些年,随着政府鼓励政策的出台、…...
ChatGPT 与 Python Echarts 完成热力图实例
热力图是一种数据可视化方式,它通过颜色的变化来表示数据的差异和分布。以下是使用热力图的一些作用和好处: 数据可视化:热力图可以将复杂的数据集转化为更直观、更易理解的形式。这对于很多人来说,尤其是那些没有深入统计学或数…...

vue3项目报错The template root requires exactly one element.eslint-plugin-vue
解决方案: 1.禁用 Vetur 并改用Volar》它现在是 Vue 3 项目的官方推荐。【必须重启vsCode】 从官方迁移指南: 建议使用带有我们官方扩展 Volar (opens new window) 的 VSCode,它为 Vue 3 提供了全面的 IDE 支持。 2.package.json文件中 &…...
【C++系列】STL容器——vector类的例题应用(12)
前言 大家好吖,欢迎来到 YY 滴C系列 ,热烈欢迎!本章主要内容面向接触过C的老铁,下面是收纳的一些例题与解析~ 主要内容含: 目录 【例1] 只出现一次的数字i(范围for与模等(^))【例2]…...

常用应用安装教程---在centos7系统上安装JDK8
在centos7系统上安装JDK8 1:进入oracle官网下载jdk8的tar.gz包: 2:将下载好的包上传到每个服务器上: 3:查看是否上传成功: [rootkafka01 ~]# ls anaconda-ks.cfg jdk-8u333-linux-x64.tar.gz4…...
)
告别Fiddler和Charles,用Proxyman在Android 13上抓HTTPS包(附network_security_config.xml配置)
移动端开发者必备:Proxyman在Android 13上的HTTPS抓包实战指南 如果你是一名移动端开发者,一定遇到过这样的场景:应用在测试环境中表现良好,但上线后却出现各种网络请求异常。传统的Fiddler和Charles虽然功能强大,但在…...

Windows下OpenClaw全攻略:Qwen3.5-9B-AWQ-4bit接入与避坑指南
Windows下OpenClaw全攻略:Qwen3.5-9B-AWQ-4bit接入与避坑指南 1. 为什么选择OpenClawQwen3.5组合? 去年我在处理大量图片素材归档时,发现手动分类效率极低。直到尝试将OpenClaw与Qwen3.5-9B-AWQ-4bit镜像结合,才真正体会到本地A…...
一种动态旋转的图形元素(如圆圈、齿轮状动画))
前端开发中的加载指示器(Loading Spinners)一种动态旋转的图形元素(如圆圈、齿轮状动画)
在 Android 中,Spinner 是一个下拉选择控件,用于从预定义列表中选择一项。以下是标准、稳定、兼容性好的实现方式(基于 ViewBinding ArrayAdapter,适配 AndroidX 和 API 21):✅ 一、绑定数据(以…...
的使用)
Linux:模式通配符 * 和globstar **(bash4新增)的使用
相关文章 Linux专栏https://blog.csdn.net/weixin_45791458/category_12234591.html 在bash的使用过程中,模式通配符可以说是最常见、也最实用的一类功能。很多时候我们在命令行里处理文件,并不是靠把完整文件名一个个手工敲出来,而是通过ba…...

LAION CLAP音频分类控制台效果展示:交通噪声中精准识别‘救护车鸣笛’真实案例
LAION CLAP音频分类控制台效果展示:交通噪声中精准识别‘救护车鸣笛’真实案例 1. 引言:从嘈杂背景中听清关键声音 想象一下这个场景:你正在一个繁忙的城市路口,周围充斥着汽车引擎声、喇叭声、人声和风声。突然,一阵…...

网站页面标题和描述如何设置更有利于SEO_网站标题、标题标签、副标题如何设置
网站页面标题和描述如何设置更有利于SEO_网站标题、标题标签、副标题如何设置 在当今数字化时代,网站的SEO(搜索引擎优化)至关重要。如何设置网站的页面标题和描述,不仅能提升网站的可见度,还能吸引更多的点击和流量。…...

华硕笔记本性能控制终极指南:如何用G-Helper替代臃肿的Armoury Crate
华硕笔记本性能控制终极指南:如何用G-Helper替代臃肿的Armoury Crate 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, …...

AI股票分析师daily_stock_analysis的VLOOKUP跨表应用
AI股票分析师daily_stock_analysis的VLOOKUP跨表应用 1. 为什么金融分析师需要VLOOKUP来增强AI分析报表 每天打开Excel处理股票数据时,你是不是也经历过这样的场景:一份是daily_stock_analysis生成的AI决策仪表盘,另一份是公司基本面数据表…...

为什么Restormer能在图像修复任务上超越CNN?深入拆解它的三个核心设计
为什么Restormer能在图像修复任务上超越CNN?深入拆解它的三个核心设计 在图像修复领域,从早期的传统滤波方法到后来的深度卷积网络,技术迭代始终围绕着一个核心矛盾:如何平衡局部细节修复与全局结构一致性。当U-Net等CNN架构在去噪…...

Klipper固件全攻略:从配置到优化解决3D打印核心难题
Klipper固件全攻略:从配置到优化解决3D打印核心难题 【免费下载链接】klipper Klipper is a 3d-printer firmware 项目地址: https://gitcode.com/GitHub_Trending/kl/klipper 3D打印技术面临精度不足、振动干扰和配置复杂等挑战,Klipper固件通过…...