常见面试题-MySQL专栏(一)
为什么 mysql 删了行记录,反而磁盘空间没有减少?
答:
在 mysql 中,当使用 delete 删除数据时,mysql 会将删除的数据标记为已删除,但是并不去磁盘上真正进行删除,而是在需要使用这片存储空间时,再将其从磁盘上清理掉,这是 MySQL 使用延迟清理的方式。
延迟清理的优点:
- 如果 mysql 立即删除数据,会导致磁盘上产生大量的碎片,使用延迟清理可以减少磁盘碎片,提高磁盘的读写效率
- 如果删除数据时立即清理磁盘上的数据,会消耗大量的性能。(如果一个大表存在索引,只删除其中一行,整个索引结构就会发生变化)
延迟清理的缺点:
- 这些被标记为删除的数据,就是数据空洞,不仅浪费空间,还影响查询效率。
mysql 是以数据页为单位来存储和读取数据,如果一个表有大量的数据空洞,那么 mysql 读取一个数据页,可能被标记删除的数据就占据了大量的空间,导致需要读取很多个数据页,影响查询效率
如何回收未使用空间:
optimize table 表名
索引的结构?
答:
索引是存储在引擎层而不是服务层,所以不同存储引擎的索引的工作方式也不同,我们只需要重点关注 InnoDB 存储引擎和 InnoDB 存储引擎中的索引实现,以下如果没有特殊说明,则都为 InnoDB 引擎。
mysql 支持两种索引结构: B-tree 和 HASH
- B-tree 索引
B-tree 索引结构使用 B+ 树来进行实现,结构如下图(粉色区域存放索引数据,白色区域存放下一级磁盘文件地址):

B-tree 索引(B+ 树实现)的一些特点:
- B+ 树叶子节点之间按索引数据的大小顺序建立了双向链表指针,适合按照范围查找
- 使用 B+ 树非叶子节点只存储索引,在 B 树中,每个节点的索引和数据都在一起,因此使用 B+ 树时,通过一次磁盘 IO 拿到相同大小的存储页,B+ 树可以比 B 树拿到的索引更多,因此减少了磁盘 IO 的次数。
- B+ 树查询性能更稳定,因为数据只保存在叶子节点,每次查询数据,磁盘 IO 的次数是稳定的
为什么索引能提高查询速度?
答:
索引可以让服务器快速定位到表的指定位置,索引有以下几个优点:
- 索引大大减少了服务器需要扫描的数据量
- 索引可以帮助服务器避免排序和临时表
- 索引可以将随机 IO 变为顺序 IO
前缀索引和索引的选择性?
答:
索引的选择性:指的是不重复的索引值与数据表的记录总数的比值。
索引的选择性越高,查询效率也越高,因为选择性高的索引可以让 mysql 在查找时过滤掉更多的行。唯一索引的选择性是1,这也是最好的索引选择性,性能也是最好的
前缀索引:
有时候为了提高索引的性能,并且节省索引的空间,只对字段的前一部分字符进行索引,但是存在的缺点就是:降低了索引的选择性
如何选择前缀索引的长度呢?
前缀索引的长度选择我们要兼顾索引的选择性和存储索引的空间两个方面,因此既不能太长也不能太短,可以通过计算不同前缀索引长度的选择性,找到最接近完整列的选择性的前缀长度,通过以下 sql 进行计算不同前缀索引长度的选择性:
select
count(distinct left(title, 6)) / count(*) as sel6,
count(distinct left(title, 7)) / count(*) as sel7,
count(distinct left(title, 8)) / count(*) as sel8,
count(distinct left(title, 9)) / count(*) as sel9,
count(distinct left(title, 10)) / count(*) as sel10,
count(distinct left(title, 11)) / count(*) as sel11,
count(distinct left(title, 12)) / count(*) as sel12,
count(distinct left(title, 13)) / count(*) as sel13,
count(distinct left(title, 14)) / count(*) as sel14,
count(distinct left(title, 15)) / count(*) as sel15,
count(distinct left(title, 16)) / count(*) as sel16,
count(distinct left(title, 17)) / count(*) as sel17,
count(distinct left(title, 18)) / count(*) as sel18,
count(distinct left(title, 19)) / count(*) as sel19,
count(distinct left(title, 20)) / count(*) as sel20,
count(distinct left(title, 21)) / count(*) as sel21
from interview_experience_article
计算结果如下:

再计算完整列的选择性:
select count(distinct title)/count(*) from interview_experience_article
计算结果如下:

完整列的选择性是 0.6627,而前缀索引在长度为 16 的时候选择性为(sel16=0.6592),就已经很接近完整列的选择性了,此使再增加前缀索引的长度,选择性的提升幅度就已经很小了,因此在本例中,可以选择前缀索引长度为 16
本例中的数据是随便找的一些文本数据,类型是 text
如何创建前缀索引:
alter table table_name add key(title(16))
如何选择合适的索引顺序?
答:
来源于《高性能MySQL》(第4版)
对于选择合适的索引顺序来说,有一条重要的经验法则:将选择性最高的列放到索引的最前列
在通常境况下,这条法则会有所帮助,但是存在一些特殊情况:
对于下面这个查询语句来说:
select count(distinct threadId) as count_value
from message
where (groupId = 10137) and (userId = 1288826) and (anonymous = 0)
order by priority desc, modifiedDate desc
explain 的结果如下(只列出使用了哪个索引):
id: 1
key: ix_groupId_userId
可以看出选择了索引(groupId, userId),看起来比较合理,但是我们还没有考虑(groupId、userId)所匹配到的数据的行数:
select count(*), sum(groupId=10137), sum(userId=1288826), sum(anonymous=0)
from message
结果如下:
count(*): 4142217
sum(groupId=10137): 4092654
sum(userId=1288826): 1288496
sum(anonymous=0): 4141934
可以发现通过 groupId 和 userId 基本上没有筛选出来多少条数据
因此上边说的经验法则一般情况下都适用,但是在特殊形况下,可能会摧毁整个应用的性能
上边这种情况的出现是因为这些数据是从其他应用迁移过来的,迁移的时候把所有的消息都赋予了管理组的用户,因此导致这样查询出来的数据量非常大,这个案例的解决情况是修改应用程序的代码:区分这类特殊用户和组,禁止针对这类用户和组执行这个查询
聚簇索引和非聚簇索引的区别?非聚集索引一定回表查询吗?
答:
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。
当表里有聚簇索引时,它的数据行实际上存放在索引的叶子节点中。
聚簇表示数据行和相邻和键值存储在一起
InnoDB 根据主键来聚簇数据,如果没有定义主键的话,InnoDB 会隐式定义一个主键来作为聚簇索引,
聚簇索引的优点:
- 数据访问更快。聚簇索引将数据和索引保存在同一个 B-tree 中,获取数据比非聚簇索引更快
- 使用覆盖索引扫描的查询可以直接使用叶节点的主键值
聚簇索引的缺点:
- 提升了 IO 密集型应用的性能。(如果数据全部放在内存中的话,不需要执行 IO 操作,聚集索引就没有什么优势了)
- 插入速度严重依赖于插入顺序。按照主键的顺序插入行是将数据加载到 InnoDB 表中最快的方式。
如果不是按照逐渐顺序加载数据,在加载完之后最好使用 optimize table 重新组织一下表,该操作会重建表。重建操作能更新索引统计数据并释放聚簇索引中的未使用的空间。
可以使用show table status like '[table_name]'查看优化前后表占用的存储空间 - 更新聚集索引的代价很高。因为会强制 InnoDB 将每个被更新的行移动到新的位置
- 基于聚簇索引的表在插入新行是或者主键被更新到只需要移动行的时候,可能面临 页分裂 的问题,当行的主键值需要插入某个已经满了的页中时,存储引擎会将该页分裂成两个页面来存储,也就是页分裂操作,页分裂会导致表占用更多的磁盘空间
- 聚簇索引可能会导致全表扫描变慢,尤其是行比较稀疏或者由于页分裂导致数据存储不连续的时候
- 二级索引(也是非聚簇索引)可能比想象的要更大,因为在二级索引的叶子节点存储了指向行的主键列。
- 二级索引访问需要两次索引查找,而不是一次。
二级索引中,叶子节点保存的是指向行的主键值,那么如果通过二级索引进行查找,找到二级索引的叶子节点,会先获取对应数据的主键值,然后再根据这个值去聚簇索引中查找对应的行数据。(两次索引查找)
二级索引是什么?为什么已经有了聚集索引还需要使用二级索引?
答:
二级索引是非主键索引,也是非聚集索引(索引和数据分开存放),也就是在非主键的字段上创建的索引就是二级索引。
比如我们给一张表里的 name 字段加了一个索引,在插入数据的时候,就会重新创建一棵 B+ 树,在这棵 B+ 树中,就来存放 name 的二级索引。
即在二级索引中,索引是 name 值,数据(data)存放的是主键的值,第一次索引查找获取了主键值,之后根据主键值再去聚集索引中进行第二次查找,才可以找到对应的数据。
常见的二级索引:
- 唯一索引
- 普通索引
- 前缀索引:只适用于字符串类型的字段,取字符串的前几位字符作为前缀索引。
为什么已经有了聚簇索引还需要使用二级索引?
聚簇索引的叶子节点存储了完整的数据,而二级索引只存储了主键值,因此二级索引更节省空间。
如果需要为表建立多个索引的话,都是用聚簇索引的话,将占用大量的存储空间。
为什么在 InnoDB 表中按逐渐顺序插入行速度更快呢?
答:
向表里插入数据,主键可以选择整数自增 ID 或者 UUID。
- 如果选择自增 ID 作为主键
那么在向表中插入数据时,插入的每一条新数据都在上一条数据的后边,当达到页的最大填充因子(InnoDB 默认的最大填充因子是页大小的 15/16,留出部分空间用于以后修改)时,下一条记录就会被写入到新的页中。
- 如果选择 UUID 作为主键
在插入数据时,由于新插入的数据的主键的不一定比之前的大,所以 InnoDB 需要为新插入的数据找到一个合适的位置——通常是已有数据的中间位置,有以下缺点:
- 写入的目标也可能已经刷到磁盘上并从内存中删除,或者还没有被加载到内存中,那么 InnoDB 在插入之前,需要先将目标页读取到内存中。这会导致大量随机 IO
- 写入数据是乱序的,所以 InnoDB 会频繁执行页分裂操作
- 由于频繁的页分裂,页会变得稀疏并且被不规则地填充,最终数据会有碎片
什么时候使用自增 ID 作为主键反而更糟?
在高并发地工作负载中,并发插入可能导致间隙锁竞争。
相关文章:
常见面试题-MySQL专栏(一)
为什么 mysql 删了行记录,反而磁盘空间没有减少? 答: 在 mysql 中,当使用 delete 删除数据时,mysql 会将删除的数据标记为已删除,但是并不去磁盘上真正进行删除,而是在需要使用这片存储空间时&…...
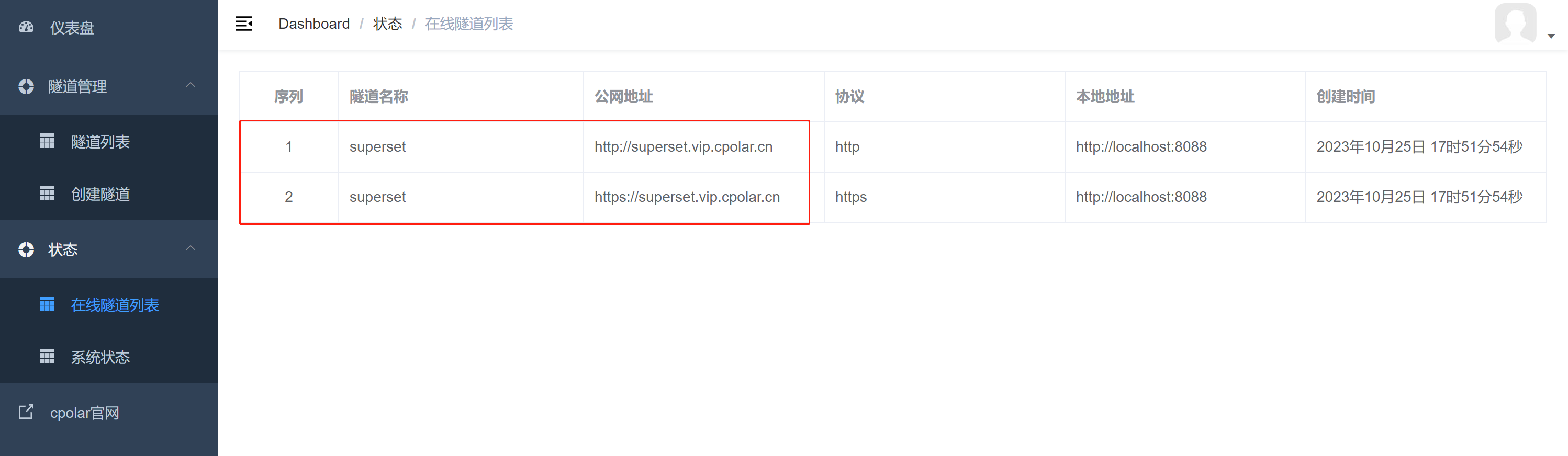
使用Docker部署Apache Superset并实现公网远程访问
大数据可视化BI分析工具Apache Superset实现公网远程访问 文章目录 大数据可视化BI分析工具Apache Superset实现公网远程访问前言1. 使用Docker部署Apache Superset1.1 第一步安装docker 、docker compose1.2 克隆superset代码到本地并使用docker compose启动 2. 安装cpolar内网…...
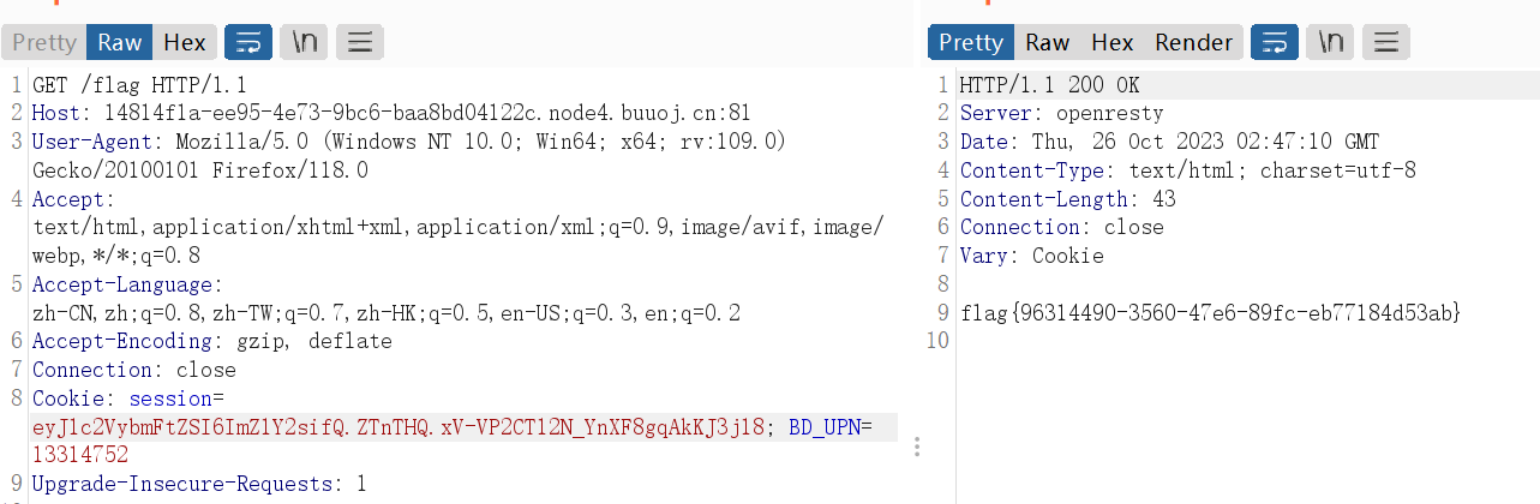
buuctf_练[CISCN2019 华东南赛区]Web4
[CISCN2019 华东南赛区]Web4 文章目录 [CISCN2019 华东南赛区]Web4掌握知识解题思路代码分析正式解题 关键paylaod 掌握知识 根据url地址传参结构来判断php后端还是python后端;uuid.getnode()函数的了解,可以返回主机MAC地址十六进制;pyt…...
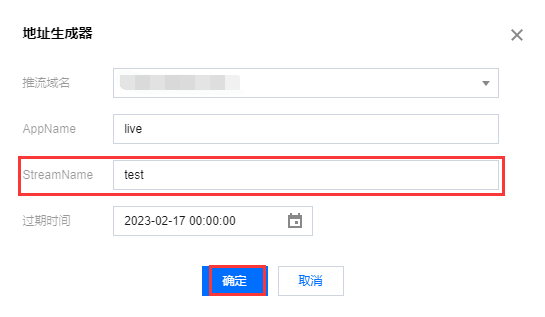
国际腾讯云直播推流配置教程!
云直播的服务本质是一个广播的过程,类似于电视台的直播节目通过有线电视网发送给千家万户。为了完成这个过程,云直播需要有采集和推流设备(类似摄像头)、云直播服务(类似电视台的有线电视网)和播放设备&…...

RocketMQ与Kafka差异对比:从架构到性能细节,解析两者在可靠性、扩展性和可用性等方面的优劣
淘宝内部的交易系统使用了淘宝自主研发的Notify消息中间件,使用Mysql作为消息存储媒介,可完全水平扩容,为了进一步降低成本,我们认为存储部分可以进一步优化,2011年初,Linkin开源了Kafka这个优秀的消息中间…...

【数智化人物展】同方有云联合创始人兼总经理江琦:云计算,引领数智化升级的动能...
江琦 本文由同方有云联合创始人兼总经理江琦投递并参与《2023中国企业数智化转型升级先锋人物》榜单/奖项评选。 数据智能产业创新服务媒体 ——聚焦数智 改变商业 在这个飞速发展的数字时代,我们置身于一个前所未有的机遇与挑战并存的时刻。数字化转型不再仅仅是一…...
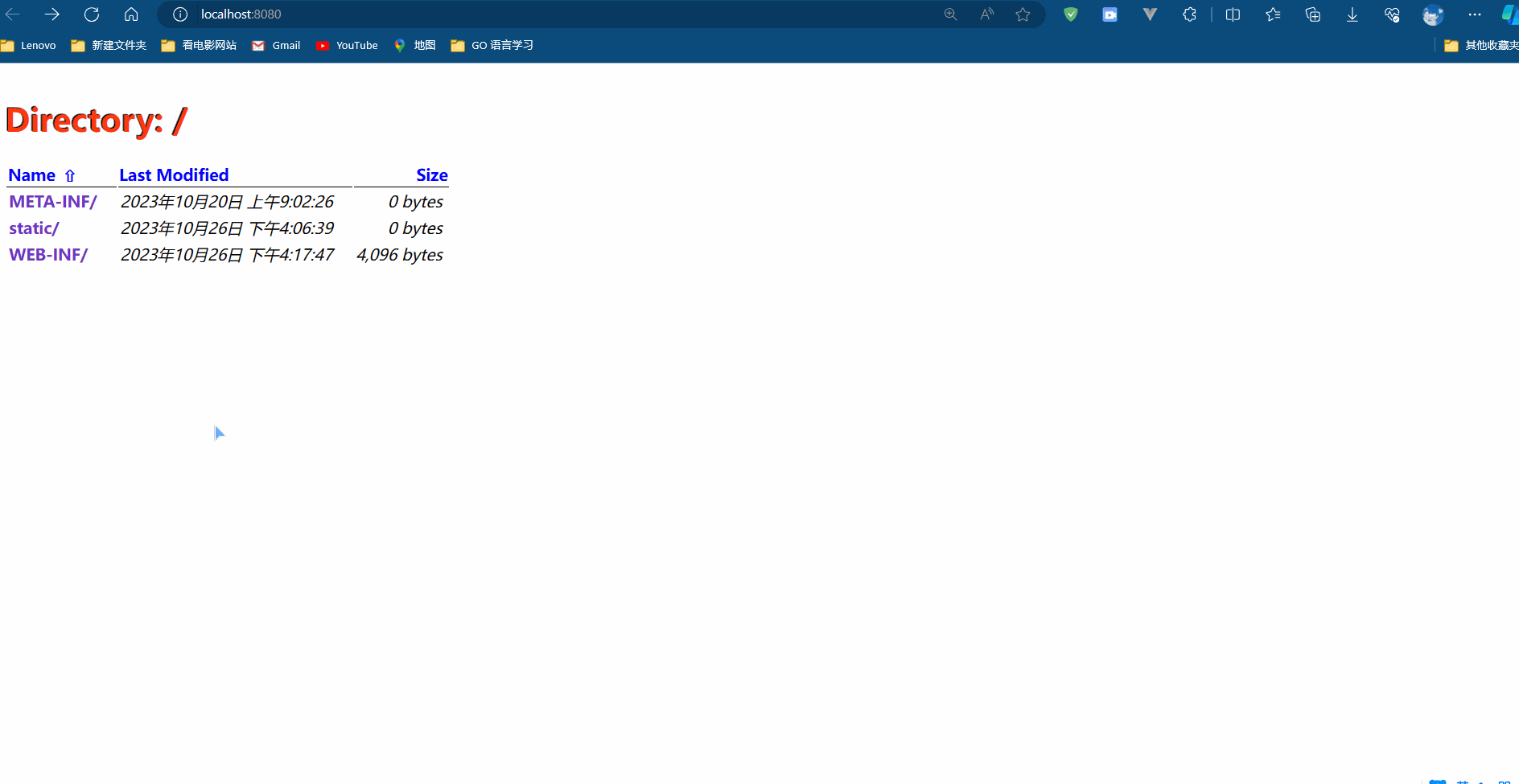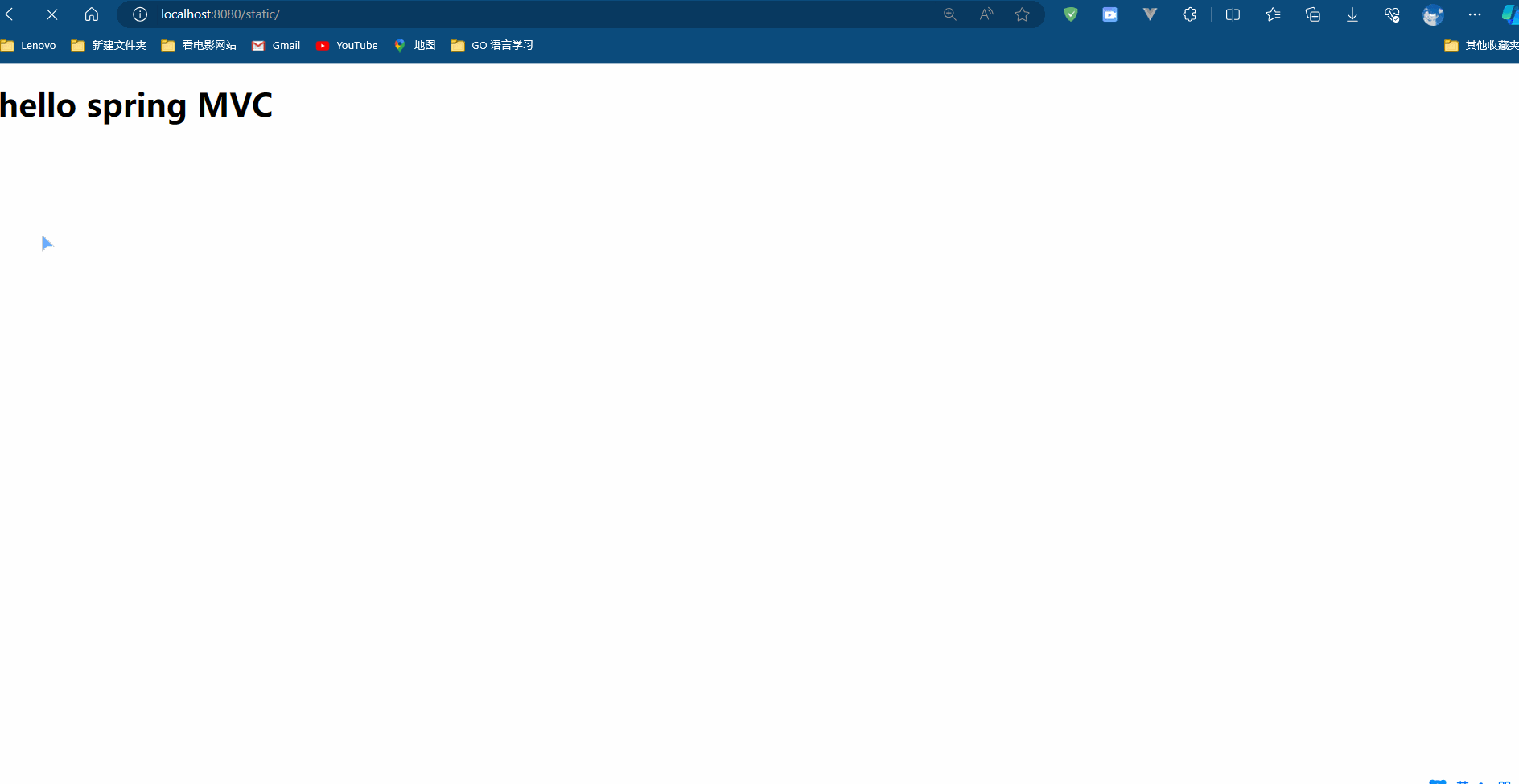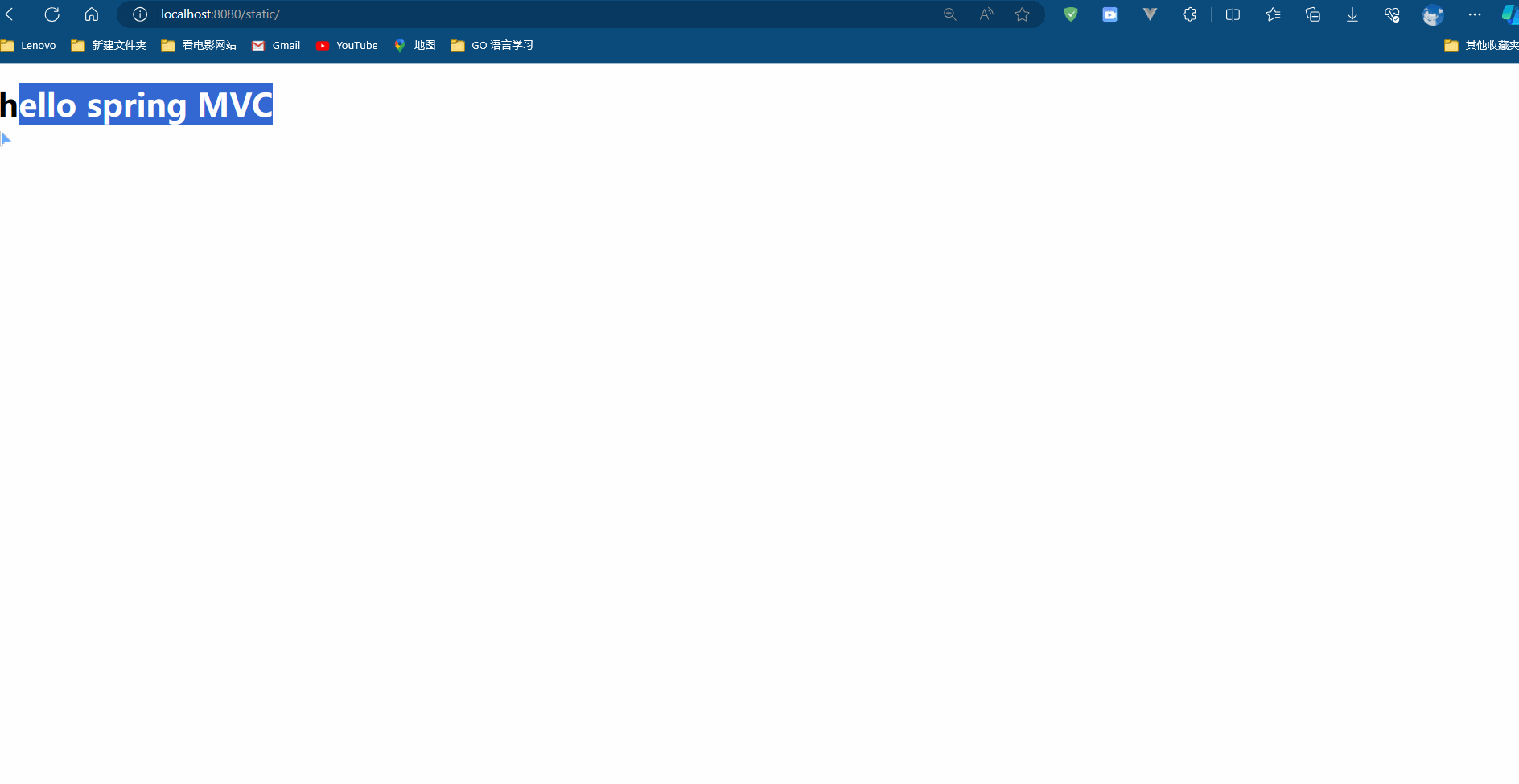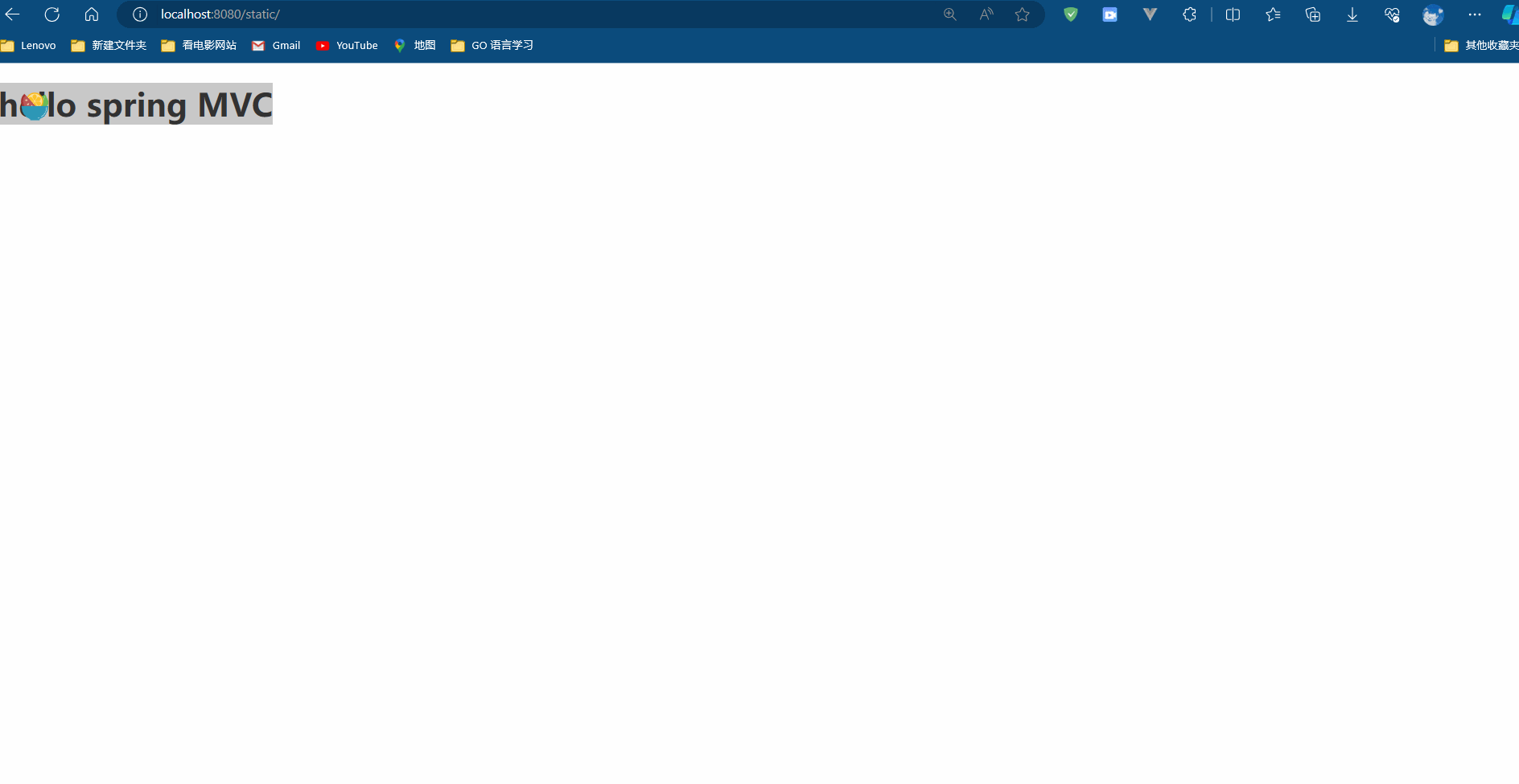
SpringMVC Day 03 : 处理静态资源
前言 欢迎来到第三天的 SpringMVC 学习系列!在前两天的教程中,我们已经学习了如何搭建 SpringMVC 环境、创建控制器和处理请求等基础知识。今天,我们将继续探索 SpringMVC 的功能,并学习如何处理静态资源。 在现代 Web 应用程序…...
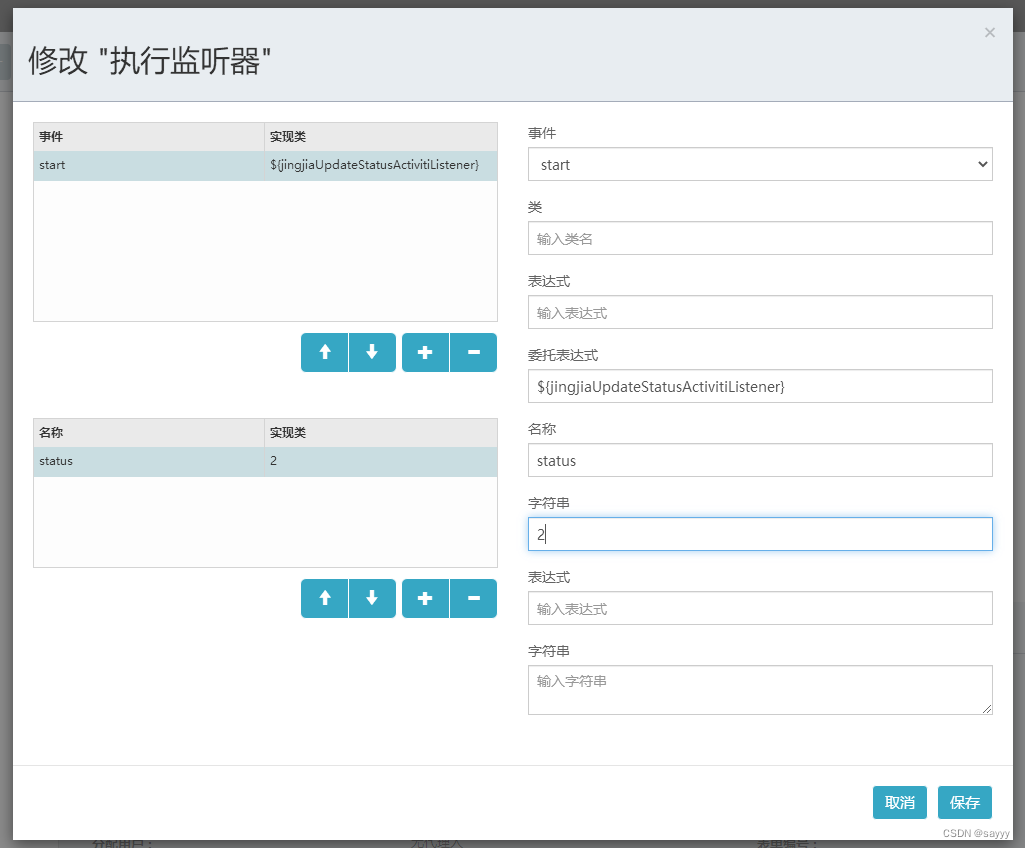
activiti 用户任务中的执行监听器
前言 略 用户任务中的执行监听器配置界面 监听器事件 用户任务中的执行监听器可以监听到的事件有: start:开始时触发。end:结束时触发。take:执行时触发。 监听器执行方式 监听器的执行方式: 类(classÿ…...

leetcode做题笔记200. 岛屿数量
给你一个由 1(陆地)和 0(水)组成的的二维网格,请你计算网格中岛屿的数量。 岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。 此外,你可以假设该网格的四条边…...
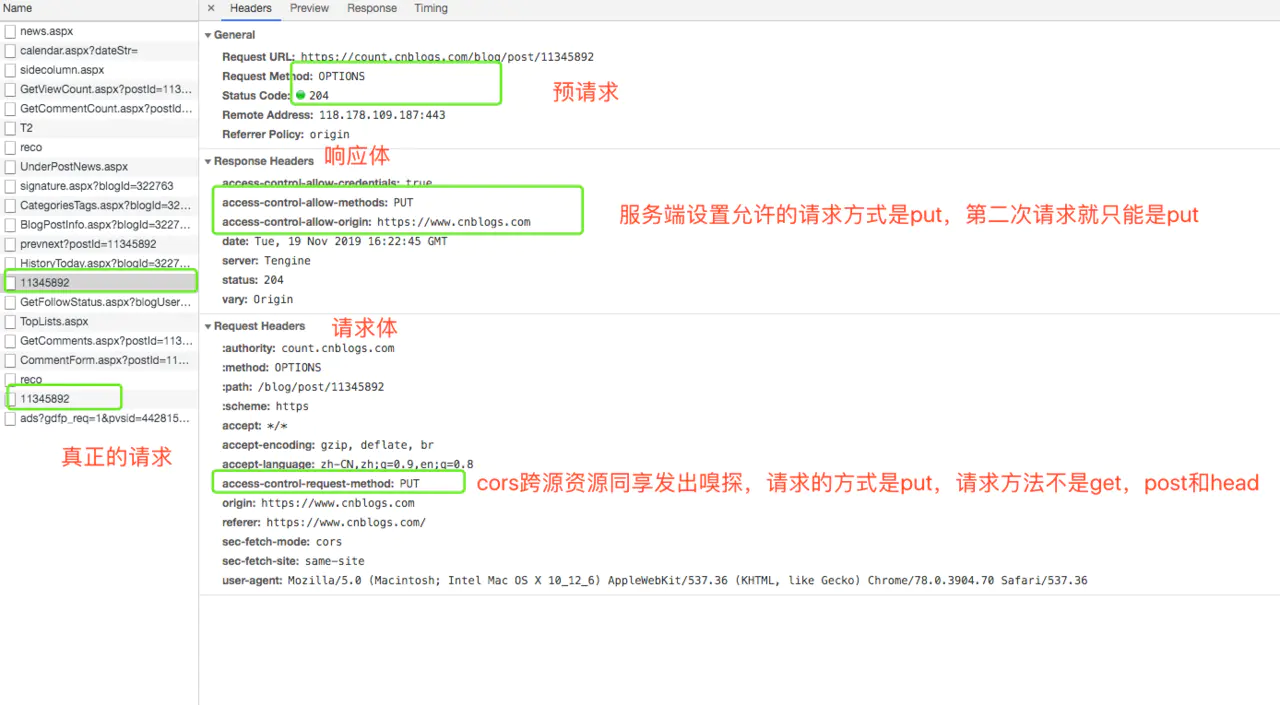
HTTP 之 options预请求 nginx 解决跨域 postman调试跨域问题
一、HTTP一共有八种常见请求方法 get:参数在url上,浏览器长度有限制,不安全post:参数不可见,长度不受限制put:上传最新内容到指定位置delete:删除请求的url所表示的资源head:不返回…...

MFC知识点
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、pandas是什么?二、使用步骤 1.引入库2.读入数据总结 前言 提示:这里可以添加本文要记录的大概内容: 例如:…...

Spring-手写模拟Spring底层原理
概述 模拟大致的底层原理,为学习Spring源码做铺垫。 实现的功能:扫描路径、依赖注入、aware回调、初始化前、初始化、初始化后、切面 未实现的功能:构造器推断、循环依赖 重点:BeanDefinition、BeanPostProcessor 学习Spring…...
】)
Scala【集合常用方法和函数操作(下)】
Fold、FoldLeft 和 FoldRight object Test03_Fold {def main(args: Array[String]): Unit {// 称作集合外的参数val list List(1,2,3,4)// fold的底层仍然是调用的 foldLeft// 第一个参数是一个值(称作集合内的参数,必须和集合外的参数类型一致)// 第二个参数是一…...

JS加密/解密之那些不为人知的基础逻辑运算符
不多说,直接上干货 使用逻辑非运算符 ! 和双重逻辑非运算符 !!:例如 ![]、!![]、!0、!!0 和 !""、!!""。空字符串的转换:!"" 和 !!""。数组和对象的类型转换:[] []、[] - []、{} [] 和…...
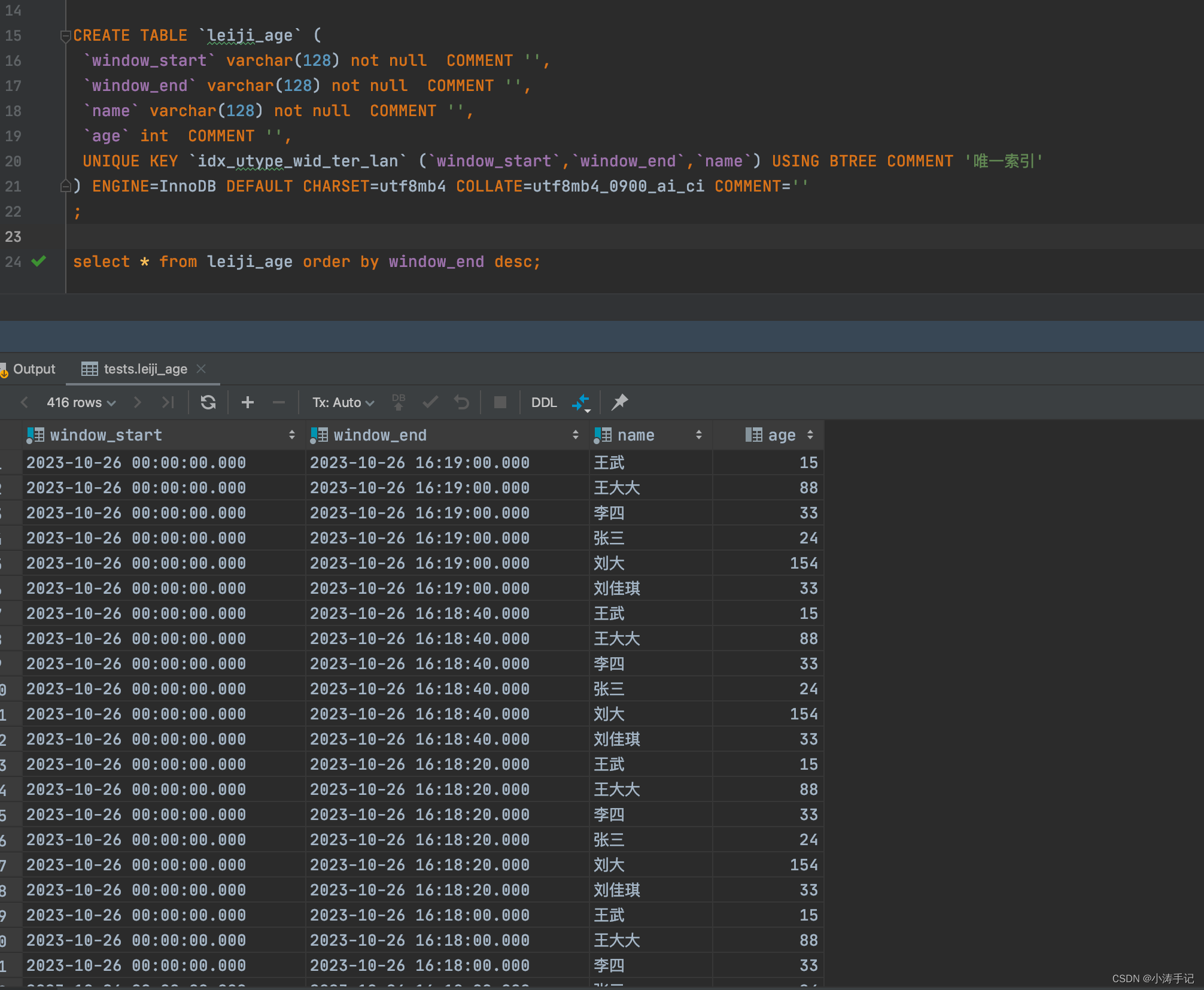
flinksql kafka到mysql累计指标练习
flinksql 累计指标练习 数据流向:kafka ->kafka ->mysql 模拟写数据到kafka topic:wxt中 import com.alibaba.fastjson.JSONObject; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.Produ…...
pdf转jpg的方法【ps和工具方法】
pdf转jpg的方法: 1.photoshop办法: pdf直接拖入ps中,另存为*.Jpg文件即可 另外注意的时候,有时候别人给你pdf文件中包含你需要的jpg文件,千万不要截图进入ps中,直接把文件拖入ps中,这样的文件…...

【已解决】Qt发送信号后,槽函数没有响应
Qt发送信号后,槽函数没有响应 检查有没有连接正确的信号和槽函数,有时候,大意了,会写错检查connect函数返回值,有没有连接成功检查对象的创建方式,确保在信号发送前,以及槽函数接收前ÿ…...
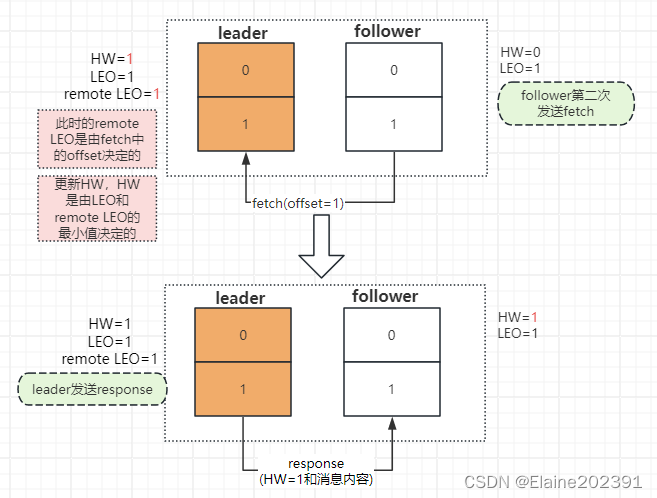
Kafka入门05——基础知识
目录 副本数据同步原理 HW和LEO的更新流程 第一种情况 第二种情况 数据丢失的情况 解决方案 Leader副本的选举过程 日志清除策略和压缩策略 日志清除策略 日志压缩策略 Kafka存储手段 零拷贝(Zero-Copy) 页缓存(Page Cache&…...
配置邮箱发送功能)
WordPress(7)配置邮箱发送功能
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、注册登陆163邮箱1. 配置SMTP二、开启smtp1.添加授权码二.在网站中配置smtp服务1.在主题的Boxmoe主题设置中开启邮箱设置三.安装所需要的插件1.安装完毕开启插件即可四.SMTP邮箱服务测试总结…...
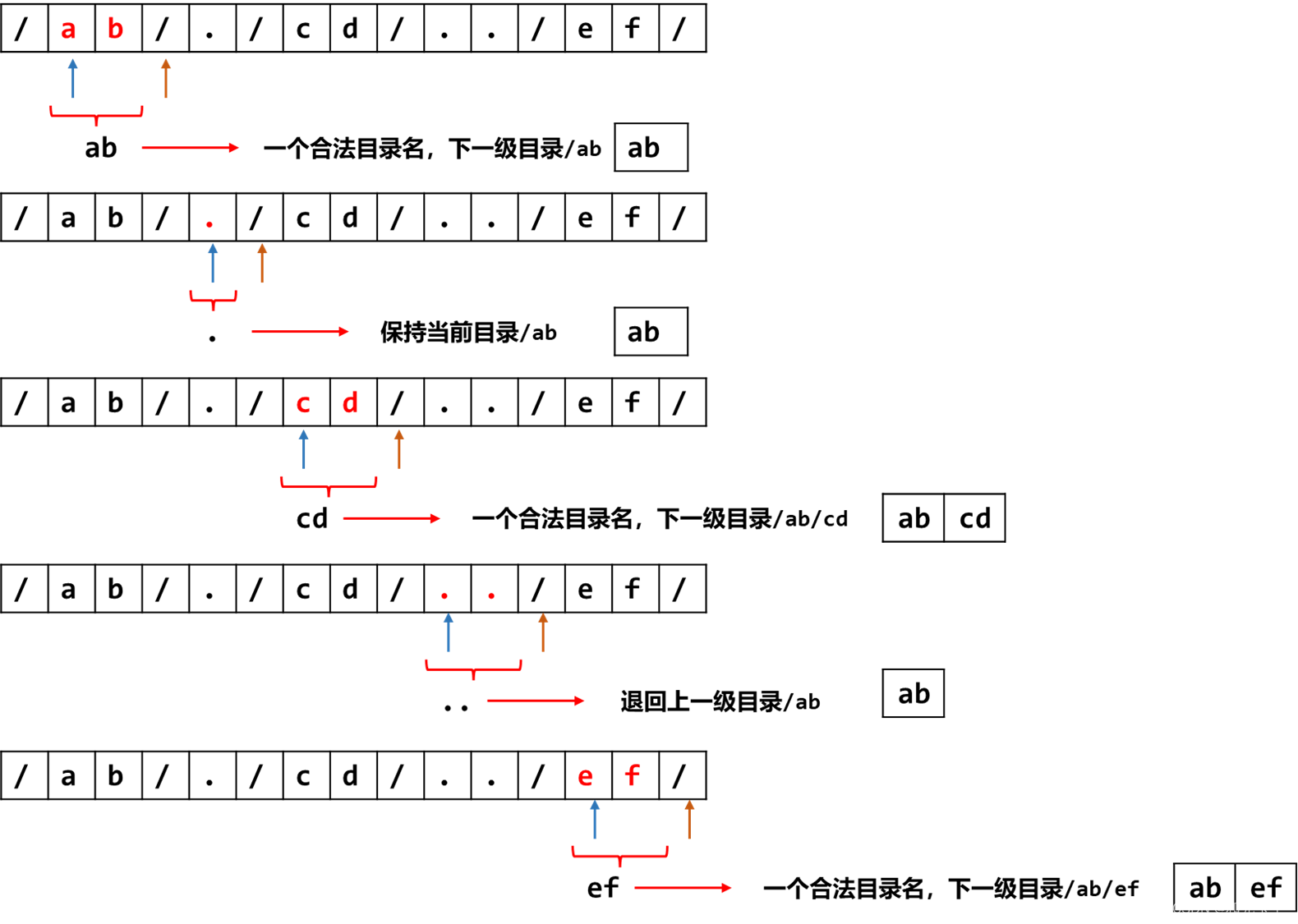
简化路径(C++解法)
题目 给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 / 开头),请你将其转化为更加简洁的规范路径。 在 Unix 风格的文件系统中,一个点(.)表示当前目录本身࿱…...

Python EXE解包工具终极指南:轻松提取源代码的完整教程
Python EXE解包工具终极指南:轻松提取源代码的完整教程 【免费下载链接】python-exe-unpacker A helper script for unpacking and decompiling EXEs compiled from python code. 项目地址: https://gitcode.com/gh_mirrors/py/python-exe-unpacker Python …...
Pixel Aurora Engine开发者指南:Diffusers集成与LoRA热加载详解
Pixel Aurora Engine开发者指南:Diffusers集成与LoRA热加载详解 1. 像素极光引擎概述 Pixel Aurora Engine是一款专为像素艺术生成设计的AI绘图工作站,采用复古8-bit游戏风格界面,将现代扩散模型技术与经典像素美学完美结合。这款引擎的核心…...

macOS音频工具:系统声音录制、多应用音频混合与低延迟音频转发解决方案
macOS音频工具:系统声音录制、多应用音频混合与低延迟音频转发解决方案 【免费下载链接】Soundflower MacOS system extension that allows applications to pass audio to other applications. Soundflower works on macOS Catalina. 项目地址: https://gitcode.…...

5个高效步骤打造Dell G15终极散热控制中心
5个高效步骤打造Dell G15终极散热控制中心 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 为什么专业游戏玩家和工程师都在抛弃官方散热软件?在高性…...

Leather Dress Collection 网络协议分析与API接口设计规范
Leather Dress Collection 网络协议分析与API接口设计规范 最近在内部项目里,我们接入了好几个类似Leather Dress Collection这样的AI模型服务。一开始大家调用得挺开心,但用着用着问题就来了:有的服务突然响应变慢,有的接口偶尔…...

OpenClaw 控制面板侧边栏工具说明书
这份说明书基于 OpenClaw 官方文档整理,帮助你理解控制面板各个功能模块。版本:2026.3.31 📋 侧边栏工具概览 工具对应功能用途代理Agents(多代理)管理多个独立 AI 代理技能Skills安装和管理自定义技能节点Nodes配对的…...

专业解决方案:Windows 11 LTSC系统一键安装微软商店完整指南
专业解决方案:Windows 11 LTSC系统一键安装微软商店完整指南 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore Windows 11 LTSC系统以其卓越…...

零侵入、极简适配!飞桨CINN实现类CUDA硬件“即插即用”
简介继飞桨框架3.1版本推出“插件式 CUDA兼容类硬件接入方案”(飞桨实现插件式硬件图接入方案,模型推理加速2.2倍),实现运行时(Runtime)与算子(Kernel)的高效复用后,飞桨…...

Sambert语音合成镜像新手教程:Web界面操作,简单易上手
Sambert语音合成镜像新手教程:Web界面操作,简单易上手 1. 为什么选择Sambert语音合成镜像 语音合成技术正在改变我们与数字世界的交互方式。Sambert多情感中文语音合成镜像是一个开箱即用的解决方案,特别适合没有深度学习背景但需要快速实现…...

百度网盘限速难题如何破解?BaiduPCS-Web带来的下载体验革新
百度网盘限速难题如何破解?BaiduPCS-Web带来的下载体验革新 【免费下载链接】baidupcs-web 项目地址: https://gitcode.com/gh_mirrors/ba/baidupcs-web 三个直击痛点的灵魂拷问 你是否经历过这样的场景:加班回家想下载一份工作资料,…...