大模型 | NEFTune之引入随机噪声对大模型训练的收益
大模型 | NEFTune之引入随机噪声对大模型训练的收益
paper中提到,在模型foward过程中,对inputs_embedding增加适度的随机噪声,会带来显著的收益。
Paper: https://arxiv.org/pdf/2310.05914.pdf
Github: https://github.com/neelsjain/NEFTune
文章目录
- 大模型 | NEFTune之引入随机噪声对大模型训练的收益
- 理论
- 一. 实践方法
- 1.1 等待Hugging发布该功能
- 1.2 直接封装model
- 1.3 改写compute_loss
理论
核心是输入经过Embedding层后,再加入一个均匀分布的噪声,噪声的采样范围为 [ − α L d , α L d ] [-\frac{\alpha}{\sqrt{Ld}},\frac{\alpha}{\sqrt{Ld}}] [−Ldα,Ldα]之间,其中 α \alpha α为噪声超参,L为输入长度,d为Embedding层维度(即hidden维度)
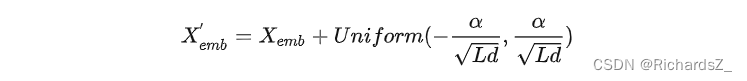
在AlpacaEval榜单上,利用GPT4作为评分器,在多个数据上微调Llama2-7B模型,NEFTune方法相较于直接微调方法,均有显著提高。

可以缓解模型在指令微调阶段的过拟合现象,可以更好的利用预训练阶段的知识内容。
一. 实践方法
1.1 等待Hugging发布该功能
进度:等待hugging face正式发布此功能,2023-10-26
[10/17/2023] NEFTune has been intregrated into the Huggingface’s TRL (Transformer Reinforcement Learning) library. See Annoucement.
1.2 直接封装model
进度:直接对模型进行如下封装,原理是对model.embed_tokens.forward()进行改写,经实践,这种方法不管用,会报堆栈溢出的error。
from torch.nn import functional as Fdef NEFTune(model, noise_alpha=5)def noised_embed(orig_embed, noise_alpha):def new_func(x):# during training, we add noise to the embedding# during generation, we don't add noise to the embeddingif model.training:embed_init = orig_embed(x)dims = torch.tensor(embed_init.size(1) * embed_init.size(2))mag_norm = noise_alpha/torch.sqrt(dims)return embed_init + torch.zeros_like(embed_init).uniform_(-mag_norm, mag_norm)else:return orig_embed(x)return new_func##### NOTE: this is for a LLaMA model ##### ##### For a different model, you need to change the attribute path to the embedding #####model.base_model.model.model.embed_tokens.forward = noised_embed(model.base_model.model.model.embed_tokens, noise_alpha)return model
1.3 改写compute_loss
进度:loss能够正常计算,但optimzer会报错,可能与精度有关,尚未解决
由于损失函数是自己写的,因此尝试在model(**input)前,追加噪声代码。注意,原先传入model的是input_ids,而当下由于我们将inputs_embeds增加了噪声,因此传入model的将直接替换为inputs_embeds,代码如下
class TargetLMLossNeft(Loss):def __init__(self, ignore_index):super().__init__()self.ignore_index = ignore_indexself.loss_fn = nn.CrossEntropyLoss(ignore_index=ignore_index)def __call__(self, model, inputs, training_args, return_outputs=False):input_ids = inputs['input_ids'] # B x L [3, 964]attention_mask = inputs['attention_mask'] # B x L target_mask = inputs['target_mask'] # B x L### ----------------------------- add noise to embedsneftune_alpha = 5embed_device = model.base_model.model.model.embed_tokens.weight.deviceembeds_init = model.base_model.model.model.embed_tokens.forward(input_ids).to(embed_device) # 先forward一下, 变成B X L X hidden_state# embed_device = model.model.embed_tokens.weight.device# embeds_init = model.model.embed_tokens.forward(input_ids).to(embed_device)input_mask = attention_mask.to(embeds_init) # B x Linput_lengths = torch.sum(input_mask, 1) # B, 计算每个sample的实际长度noise_ = torch.zeros_like(embeds_init).uniform_(-1,1) # B X L X hidden_state, 且值域在[-1,1]正态分布delta = noise_ * input_mask.unsqueeze(2) # 追加一个维度,由B X L 变成 B X L X hidden_statedims = input_lengths * embeds_init.size(-1)mag = neftune_alpha / torch.sqrt(dims)delta = (delta * mag.view(-1, 1, 1)).detach() # B X L X hidden_stateinputs_embeds = delta + embeds_init### ----------------------------- add noise to embeds# 模型前馈预测, 原来传入的是input_ids,而现在需要直接将增加了noise的inputs_embeds传入# outputs = model(input_ids=input_ids, attention_mask=attention_mask, return_dict=True)outputs = model(inputs_embeds=inputs_embeds, attention_mask=attention_mask, return_dict=True)logits = outputs["logits"] if isinstance(outputs, dict) else outputs[0] # 正常应该是torch.float32#logits.requires_grad = True # 奇怪,为什么这里会默认为False, 难道是因为上边的detach()# 将labels中不属于target的部分,设为ignore_index,只计算target部分的losslabels = torch.where(target_mask == 1, input_ids, self.ignore_index)shift_logits = logits[..., :-1, :].contiguous()shift_labels = labels[..., 1:].contiguous()# Flatten the tokensloss = self.loss_fn(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)) # float32loss.requires_grad = Truereturn (loss, outputs) if return_outputs else loss
相关文章:
大模型 | NEFTune之引入随机噪声对大模型训练的收益
大模型 | NEFTune之引入随机噪声对大模型训练的收益 paper中提到,在模型foward过程中,对inputs_embedding增加适度的随机噪声,会带来显著的收益。 Paper: https://arxiv.org/pdf/2310.05914.pdf Github: https://github.com/neelsjain/NEFT…...
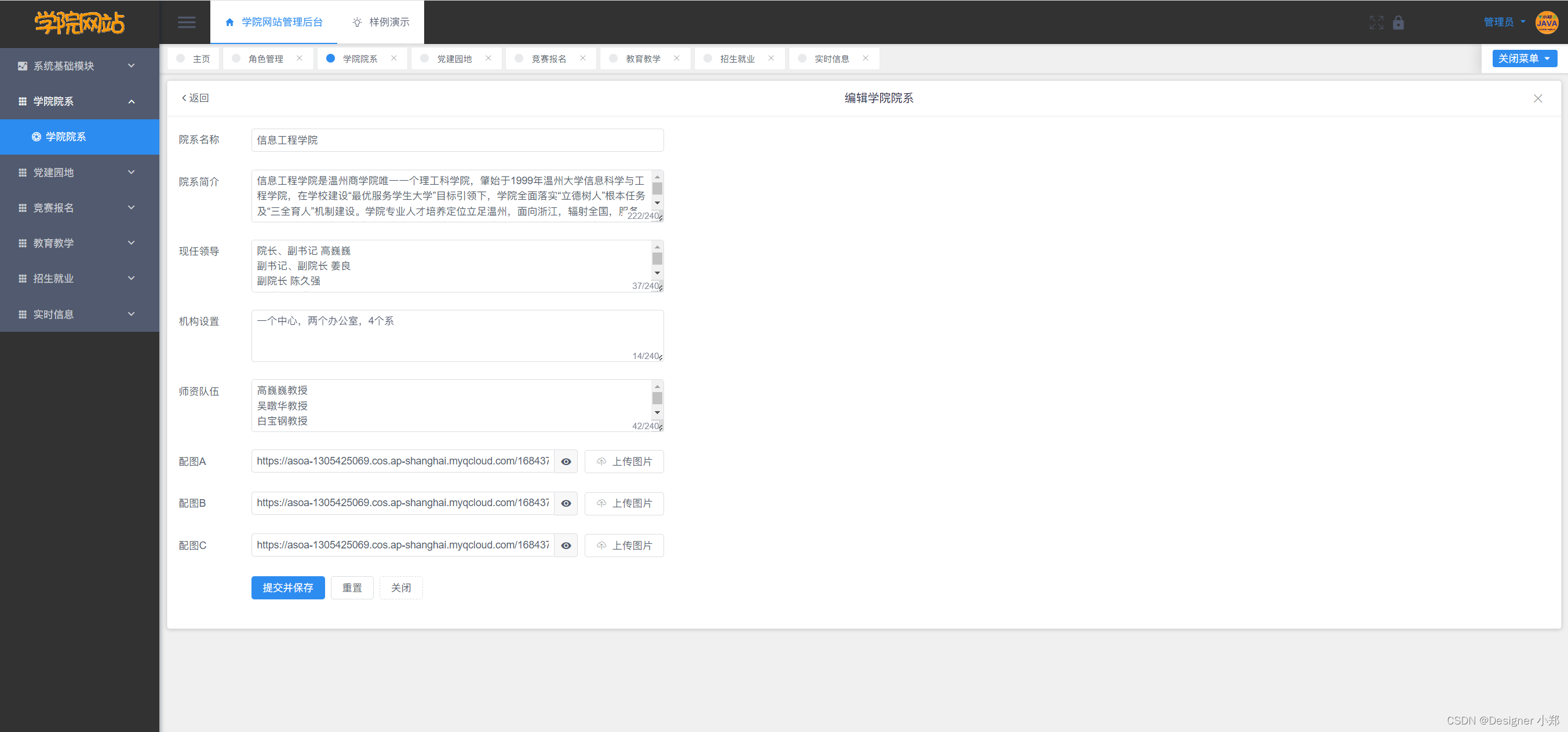
【开源】基于SpringBoot的高校学院网站的设计和实现
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 学院院系模块2.2 竞赛报名模块2.3 教育教学模块2.4 招生就业模块2.5 实时信息模块 三、系统设计3.1 用例设计3.2 数据库设计3.2.1 学院院系表3.2.2 竞赛报名表3.2.3 教育教学表3.2.4 招生就业表3.2.5 实时信息表 四、系…...

什么是云原生?土生土长?
“云原生”(Cloud Native)是一种构建和运行应用程序的方法,这种方法充分利用了云计算的优势。云原生应用程序是为云环境设计的,通常是在容器中运行,并被设计为在微服务架构中运行,这使得它们能够快速扩展和…...

2011-2021年北大数字普惠金融指数数据(包括省市县)第四期
2011-2021年北大省市县数字普惠金融指数数据(第四期) 1、时间:2011-2021年 2、指标:index_aggregate、coverage_breadth、usage_depth、payment、insurance、monetary_fund、investment、credit、credit_investigation、digitiz…...

ch3_6多线程举例
作者丨billom 来源丨投稿 编辑丨GiantPandaCV 云端深度学习的服务的性能加速通常需要算法和工程的协同加速,需要模型推理和计算节点的融合,并保证整个“木桶”没有太明显的短板。 如何在满足时延前提下让算法工程师的服务的吞吐尽可能高,尽…...

javaEE -7(网络原理初识 --- 7000字)
一:网络初识 计算机的独立模式是指多台计算机在网络中相互独立运行,彼此之间不共享资源或信息。在早期,计算机主要采用独立模式,每台计算机都拥有自己的操作系统、应用程序和数据,它们之间没有直接的连接或通信。 在…...

新生儿弱视:原因、科普和注意事项
引言: 新生儿弱视,也被称为婴儿弱视或婴儿屈光不正,是一个在婴儿和幼儿时期非常重要的视觉问题。虽然它是一种潜在的视觉障碍,但早期的诊断和干预可以显著改善儿童的视觉发育。本文将科普新生儿弱视的原因,提供相关信…...
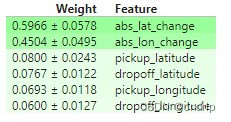
【机器学习可解释性】2.特征重要性排列
机器学习可解释性 1.模型洞察的价值2.特征重要性排列3.偏依赖图 ( partial dependence plots )4.SHAP Value5.SHAP Value 高级使用 正文 前言 你的模型认为哪些特征最重要? 介绍 我们可能会对模型提出的最基本的问题之一是:哪…...

机器学习之朴素贝叶斯
朴素贝叶斯: 也叫贝叶算法推断,建立在主管判断的基础上,不断地进行地修正。需要大量的计算。1、主观性强2、大量计算 贝叶斯定理:有先验概率和后验概率区别:假如出门堵车有两个因素:车太多与交通事故先验概…...
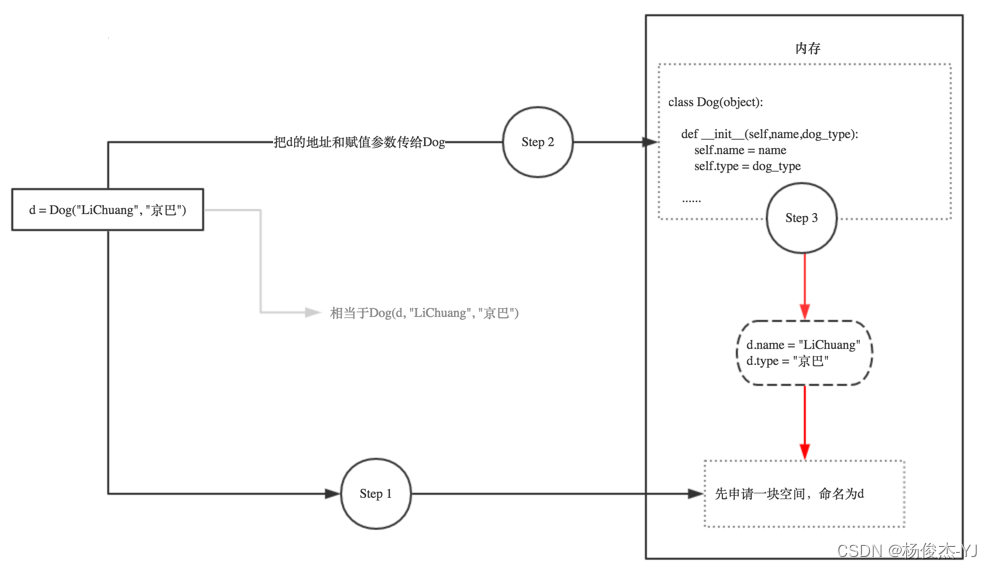
Python中if __name__ == ‘__main__‘,__init__和self 的解析
一、 if __name__ __main__ if __name__ __main__的意思是: 当.py文件被直接运行时,if __name__ __main__之下的代码块将被运行; 当.py文件以模块形式被导入时,if __name__ __main__之下的代码块不被运行。 1.1、一个 xxx.p…...

【Superset】自定义授权认证,接入内部系统二次开发
想要将内部系统认证与superset打通,必须要了解superset的认证体系。 Superset的认证体系 Superset的认证体系可以通过以下几种方式进行配置: 基于LDAP认证:Superset可以集成LDAP以验证用户身份。在这种情况下,Superset将根据LDAP…...

私有云:【1】ESXI的安装
私有云:【1】ESXI的安装 1、使用VMware Workstation创建虚拟机2、启动配置虚拟机3、登录ESXI管理台 1、使用VMware Workstation创建虚拟机 新建虚拟机 选择典型安装 稍后安装操作系统 选择VMware ESXI 选择虚拟机安装路径 硬盘设置300G或者更多 自定义硬件 内存和处…...

Mac怎么删除文件和软件?苹果电脑删除第三方软件方法
Mac删除程序这个话题为什么一直重复说或者太多人讨论呢?因为如果操作不当,可能会导致某些不好的影响。因为Mac电脑如果有太多无用的应用程序,很有可能会拖垮Mac系统的运行速度。或者如果因为删除不干净,导致残留文件积累在Mac电脑…...

【开题报告】基于微信小程序的旅游攻略分享平台的设计与实现
1.研究背景及意义 旅游已经成为现代人生活中重要的组成部分,人们越来越热衷于探索新的目的地和体验不同的文化。然而,对于旅游者来说,获取准确、可靠的旅游攻略信息并不容易。传统的旅游攻略书籍或网站往往无法提供实时、个性化的建议。因此…...

布隆过滤器(Bloom Filter)初学习
目录 1、布隆过滤器是什么 2、布隆过滤器的优缺点 3、使用场景 4、⭐基于Redis的布隆过滤器插件安装 4.1 下载布隆过滤器 4.2 创建文件夹并上传文件 4.3 安装gcc 4.4 解压RedisBloom压缩包 4.5 在解压好的文件夹下输入make 4.6 将编译的好的插件拷贝到docker redis容…...
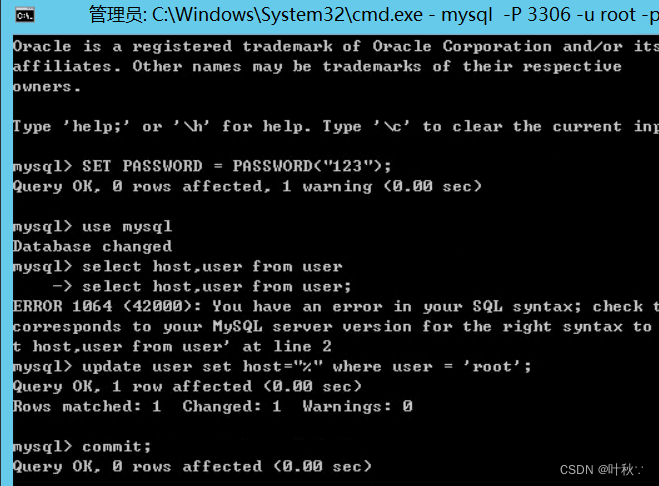
“深入探讨操作系统和虚拟化技术“
目录 引言1.操作系统1.1.什么是操作系统1.2.常见操作系统1.3.个人版本和服务器版本的区别1.4.Linux的各个版本 2.安装VMWare虚拟机1.VMWare虚拟机介绍2.VMWare虚拟机安装3.VMWare虚拟机配置 3.安装配置Windows Server 2012 R24.完成电脑远程访问电脑5.服务器环境搭建配置jdk配置…...

远程连接异地主机可能遇到的问题及处理
0.现状 公司的一套系统内部有多个节点的内网,要把数据上传至客户的办公网环境中的服务器。客户办公网为我们提供了一台类似路由的设备,办公网无法让内网地址的数据包透传至服务器。现场条件所限,只有有限数量的技术服务人员可以维持…...
的分类)
使用 PointNet 进行3D点集(即点云)的分类
点云分类 介绍 无序3D点集(即点云)的分类、检测和分割是计算机视觉中的核心问题。此示例实现了开创性的点云深度学习论文PointNet(Qi 等人,2017)。 设置 如果使用 colab 首先安装 trimesh !pip install trimesh。 import os import glob import trimesh import numpy as…...
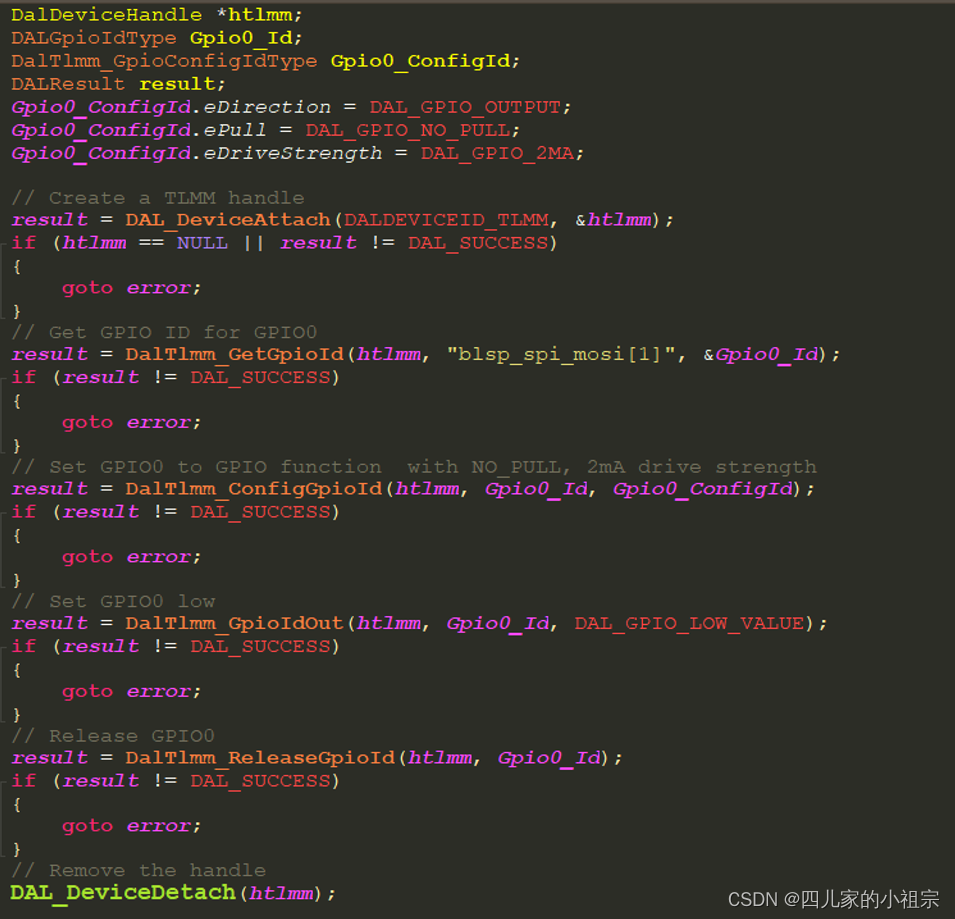
高通平台GPIO引脚复用指导
高通平台GPIO引脚复用指导 1. 概述1.1 平台有多少个GPIO?1.2 这些GPIO都有哪些可复用的功能? 2. 软件配置2.1 TZ侧GPIO配置2.2 SBL侧GPIO配置2.3 AP侧GPIO配置2.3.1 Linux DTS机制与设备驱动模型概述2.3.2高通平台的pinctrl控制器2.3.2.1 SDX12 CPU pinc…...

华为机试题:HJ5 进制转换
目录 第一章、算法题1.1)题目描述1.2)解题思路与答案1.3)派仔的解题思路与答案1.3)牛客链接 友情提醒: 先看文章目录,大致了解文章知识点结构,点击文章目录可直接跳转到文章指定位置。 第一章、算法题 1.…...

HarmonyOS 6学习:语音识别准确率提升与错误纠正方案
引言 在HarmonyOS 6应用开发中,语音识别能力已成为构建智能交互体验的核心技术。随着AI技术的快速发展,语音识别已广泛应用于教育、办公、智能家居等多个场景。然而,在实际开发过程中,开发者常面临一个普遍问题:语音识…...

Emby高级功能革新解锁方案:emby-unlocked颠覆式技术实现与部署指南
Emby高级功能革新解锁方案:emby-unlocked颠覆式技术实现与部署指南 【免费下载链接】emby-unlocked Emby with the premium Emby Premiere features unlocked. 项目地址: https://gitcode.com/gh_mirrors/em/emby-unlocked 在数字媒体日益普及的今天…...

多线程——基础
普通线程与多线程示意图 通常 系统中运行的程序/软件当做一个进程[迅雷],迅雷里面多个任务看做多个线程。 总结:一个程序一个进程,一个进程可多个线程。线程是CPU调度和执行的的单位。多线程中至少一个为主线程 注意:真正多线程…...

从演示到实战:基于快马平台构建一个功能完整的AI绘画社区应用
今天想和大家分享一个很有意思的实战项目 - 在InsCode(快马)平台上构建一个功能完整的AI绘画社区应用。这个想法来源于阿里悟空官网展示的AI绘画应用场景,但我们要做的是更贴近真实产品的综合性解决方案。 项目整体规划 首先需要明确,一个完整的AI绘画社…...

OpenClaw对话日志分析:Qwen3.5-9B优化任务执行成功率
OpenClaw对话日志分析:Qwen3.5-9B优化任务执行成功率 1. 问题背景与数据准备 去年开始使用OpenClaw对接Qwen3.5-9B模型时,我发现一个有趣现象:同样的自动化任务,在不同时段执行成功率波动很大。有时能完美完成文件整理和邮件发送…...

Phi-4-mini-reasoning从零开始:CSDN GPU实例上免配置Web服务部署
Phi-4-mini-reasoning从零开始:CSDN GPU实例上免配置Web服务部署 1. 模型介绍 Phi-4-mini-reasoning 是一款专注于推理任务的文本生成模型,特别擅长处理需要多步逻辑分析的场景。与通用聊天模型不同,它更专注于"问题输入→推理过程→最…...

3种方法彻底移除Windows Defender:释放系统性能,恢复完全控制权
3种方法彻底移除Windows Defender:释放系统性能,恢复完全控制权 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcod…...

自主飞行控制探索:PX4开源飞控的模块化架构与行业应用价值
自主飞行控制探索:PX4开源飞控的模块化架构与行业应用价值 【免费下载链接】PX4-Autopilot PX4 Autopilot Software 项目地址: https://gitcode.com/gh_mirrors/px/PX4-Autopilot PX4开源飞控系统作为无人机领域的核心解决方案,通过模块化架构设计…...

MongoDB中大型文本字段怎么存_GridFS切分与外部存储对比
会。MongoDB单文档上限16MB,但超2MB字符串易致客户端OOM或超时;GridFS非自动魔法,需手动管理分块、拼接与清理;大文本应优先存OSS/S3,Mongo仅存元数据。大文本存MongoDB会撑爆内存吗?会。MongoDB单文档上限…...

新手开发者的第一课:用快马打造零基础的mc指令学习助手
作为一个刚接触《我的世界》指令系统的玩家,我最初完全搞不懂那些复杂的斜杠命令。直到自己动手做了一个指令查询工具,才发现原来理解指令可以这么简单。今天就来分享如何用InsCode(快马)平台快速打造一个零基础友好的MC指令助手。 为什么需要专门的指令…...