ExoPlayer架构详解与源码分析(7)——SampleQueue
系列文章目录
ExoPlayer架构详解与源码分析(1)——前言
ExoPlayer架构详解与源码分析(2)——Player
ExoPlayer架构详解与源码分析(3)——Timeline
ExoPlayer架构详解与源码分析(4)——整体架构
ExoPlayer架构详解与源码分析(5)——MediaSource
ExoPlayer架构详解与源码分析(6)——MediaPeriod
ExoPlayer架构详解与源码分析(7)——SampleQueue
文章目录
- 系列文章目录
- 前言
- ProgressiveMediaPeriod
- SampleQueue
- SampleQueue动态分析
- SpannedData< SharedSampleMetadata >
- SampleDataQueue
- Allocator
- 总结
前言
ProgressiveMediaPeriod中的SampleQueue部分相对其他部分,结构相对完整独立,没有像加载媒体那部分拆分出很多其他的概念,所以优先了解下SampleQueue。本篇主要解答媒体数据是如何在播放器内部缓存的,以及ExoPlayer是如何保证这些数据稳定高效的读写。
ProgressiveMediaPeriod
先预习下上篇的整体结构,本篇主要分析左半部分的SampleQueue:

SampleQueue
这是一个保存Sample的队列。MediaoPeriod向外提供的SampleStream其实就是从SampleQueue中读取的数据,一个SampleQueue就对应一个SampleStream。
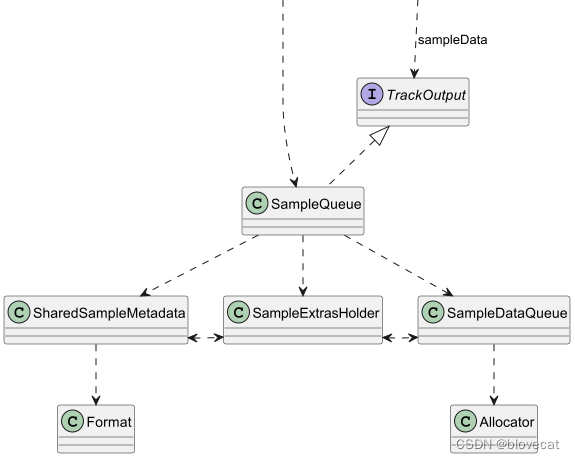
SampleQueue主要有3大功能:
-
管理 通过内部的一个环形Info数组(包含offsets数组、sizes数等sampleData数据)管理SampleDataQueue和SharedSampleMetadata这2个数据源。SampleQueue实际的数据其实是保存在SampleDataQueue和SharedSampleMetadata中的,数据的管理实现在SampleQueue里。
这部分可以从SampleQueue初始化部分源码看出来:private final SampleDataQueue sampleDataQueue;//用于播放的数据private final SampleExtrasHolder extrasHolder;private final SpannedData<SharedSampleMetadata> sharedSampleMetadata;//Meta数据private int capacity;//Info数组的总长度private long[] offsets;//每段SampleData的数据偏移量private int[] sizes;//每段SampleData的数据大小private int[] flags;//每段SampleData flags 数据private long[] timesUs;//每段SampleData 时间戳private int length;//有效的(没有被释放且已分配的数据)Info数组数据的长度private int absoluteFirstIndex;//绝对的开始位置,指向数据段的开始位置,+readPosition就是当前读取的绝对位置private int relativeFirstIndex;//一个在Info数据上循环的相对位置private int readPosition;//当前的读取位置,这个值是相对relativeFirstIndex的位置偏移量protected SampleQueue(Allocator allocator,@Nullable DrmSessionManager drmSessionManager,@Nullable DrmSessionEventListener.EventDispatcher drmEventDispatcher) {...sampleDataQueue = new SampleDataQueue(allocator);//内存分配器供SampleDataQueue使用extrasHolder = new SampleExtrasHolder();capacity = SAMPLE_CAPACITY_INCREMENT;//默认的分段属是1000sourceIds = new long[capacity];offsets = new long[capacity];timesUs = new long[capacity];flags = new int[capacity];sizes = new int[capacity];sharedSampleMetadata =new SpannedData<>(/* removeCallback= */ metadata -> metadata.drmSessionReference.release());...}上面主要是初始化出一个SampleDataQueue和一个sharedSampleMetadata数据集,然后初始化出一个1000个块的Info数组,用于管理这2块数据。这里将offsets、timesUs、sourceIds 、flags、sizes 几个数组统称为 Info数组,因为这里面共同保存着每个Sample的信息。
-
输入 同时SampleQueue实现了TrackOutput接口,对外提供sampleMetadata、format 函数使得调用者可以输入Meta信息,sampleData函数可以输入播放数据。这里的输入调用者主要是后面要说的ProgressiveMediaPeriod另一部分。
下面分析下源码数据是如何输入的://输入Metadata@Overridepublic void sampleMetadata(long timeUs,//与当前数据关联的媒体时间戳@C.BufferFlags int flags,//是否关键帧int size,//样本数据大小int offset,//块间偏移量,距离上一次已经SmapleMeta的SampleData的偏移量,我们知道媒体文件中用于播放数据不一定是连续的,其中可能包含一些其他数据,这些数据可以看成是之间的偏移量@Nullable CryptoData cryptoData) {if (upstreamFormatAdjustmentRequired) {format(Assertions.checkStateNotNull(unadjustedUpstreamFormat));}boolean isKeyframe = (flags & C.BUFFER_FLAG_KEY_FRAME) != 0;if (upstreamKeyframeRequired) {//从关键帧开始Sampleif (!isKeyframe) {return;}upstreamKeyframeRequired = false;}timeUs += sampleOffsetUs;if (upstreamAllSamplesAreSyncSamples) {if (timeUs < startTimeUs) {// 如果所有轨道都是同步的,那么在当前Smaple点之前的时间数据就可以丢弃了return;}if ((flags & C.BUFFER_FLAG_KEY_FRAME) == 0) {if (!loggedUnexpectedNonSyncSample) {Log.w(TAG, "Overriding unexpected non-sync sample for format: " + upstreamFormat);loggedUnexpectedNonSyncSample = true;}flags |= C.BUFFER_FLAG_KEY_FRAME;//保证设置为关键帧}}if (pendingSplice) {//判断是否是拼接数据,如HLS切换流的时候就会用到if (!isKeyframe || !attemptSplice(timeUs)) {return;}pendingSplice = false;}//当前Info的偏移量=数据总长度-样本数据长度-块间偏移量long absoluteOffset = sampleDataQueue.getTotalBytesWritten() - size - offset;commitSample(timeUs, flags, absoluteOffset, size, cryptoData);}private synchronized void commitSample(long timeUs,@C.BufferFlags int sampleFlags,long offset,int size,@Nullable CryptoData cryptoData) {if (length > 0) {// 保证最后一个的end位置要小于等于下一个的开始位置int previousSampleRelativeIndex = getRelativeIndex(length - 1);checkArgument(offsets[previousSampleRelativeIndex] + sizes[previousSampleRelativeIndex] <= offset);}isLastSampleQueued = (sampleFlags & C.BUFFER_FLAG_LAST_SAMPLE) != 0;largestQueuedTimestampUs = max(largestQueuedTimestampUs, timeUs);int relativeEndIndex = getRelativeIndex(length);//获取Info里的下一个位置索引timesUs[relativeEndIndex] = timeUs;//开始赋值offsets[relativeEndIndex] = offset;sizes[relativeEndIndex] = size;flags[relativeEndIndex] = sampleFlags;cryptoDatas[relativeEndIndex] = cryptoData;sourceIds[relativeEndIndex] = upstreamSourceId;if (sharedSampleMetadata.isEmpty()|| !sharedSampleMetadata.getEndValue().format.equals(upstreamFormat)) {//开始写入MetadatasharedSampleMetadata.appendSpan(getWriteIndex(),new SharedSampleMetadata(checkNotNull(upstreamFormat), drmSessionReference));}length++;//有效长度++if (length == capacity) {//如果写入数据已经超过Info的最大长度// Increase the capacity.int newCapacity = capacity + SAMPLE_CAPACITY_INCREMENT;//则将Info数组长度扩展至2倍long[] newSourceIds = new long[newCapacity];long[] newOffsets = new long[newCapacity];long[] newTimesUs = new long[newCapacity];int[] newFlags = new int[newCapacity];int[] newSizes = new int[newCapacity];CryptoData[] newCryptoDatas = new CryptoData[newCapacity];//将旧的数据,移入新的数组,将相对开始位置作为新数组的第一个位置int beforeWrap = capacity - relativeFirstIndex;System.arraycopy(offsets, relativeFirstIndex, newOffsets, 0, beforeWrap);System.arraycopy(timesUs, relativeFirstIndex, newTimesUs, 0, beforeWrap);System.arraycopy(flags, relativeFirstIndex, newFlags, 0, beforeWrap);System.arraycopy(sizes, relativeFirstIndex, newSizes, 0, beforeWrap);System.arraycopy(cryptoDatas, relativeFirstIndex, newCryptoDatas, 0, beforeWrap);System.arraycopy(sourceIds, relativeFirstIndex, newSourceIds, 0, beforeWrap);int afterWrap = relativeFirstIndex;System.arraycopy(offsets, 0, newOffsets, beforeWrap, afterWrap);System.arraycopy(timesUs, 0, newTimesUs, beforeWrap, afterWrap);System.arraycopy(flags, 0, newFlags, beforeWrap, afterWrap);System.arraycopy(sizes, 0, newSizes, beforeWrap, afterWrap);System.arraycopy(cryptoDatas, 0, newCryptoDatas, beforeWrap, afterWrap);System.arraycopy(sourceIds, 0, newSourceIds, beforeWrap, afterWrap);offsets = newOffsets;timesUs = newTimesUs;flags = newFlags;sizes = newSizes;cryptoDatas = newCryptoDatas;sourceIds = newSourceIds;relativeFirstIndex = 0;capacity = newCapacity;}}//获取当前Info数组的相对位置,传入相对第一个位置的偏移量private int getRelativeIndex(int offset) {int relativeIndex = relativeFirstIndex + offset;return relativeIndex < capacity ? relativeIndex : relativeIndex - capacity;//环形指针}//获取当前写入MetaData的绝对位置public final int getWriteIndex() {return absoluteFirstIndex + length;//等于当前绝开始位置+有效的长度} //输入Format@Overridepublic final void format(Format format) {Format adjustedUpstreamFormat = getAdjustedUpstreamFormat(format);upstreamFormatAdjustmentRequired = false;unadjustedUpstreamFormat = format;boolean upstreamFormatChanged = setUpstreamFormat(adjustedUpstreamFormat);if (upstreamFormatChangeListener != null && upstreamFormatChanged) {upstreamFormatChangeListener.onUpstreamFormatChanged(adjustedUpstreamFormat);}}Metadata输入主要分3部分:
- 确保当前为关键帧。
- 获取Info环形数组的下一个索引,将当前Sampledata的数据保存到Info数组并记录Meta信息。
- 确保Info数组足够大可以容纳足够多的数据。
下面看下sampleData部分
@Overridepublic final void sampleData(ParsableByteArray data, int length, @SampleDataPart int sampleDataPart) {sampleDataQueue.sampleData(data, length);}没了就这么多。😂,你只管告诉sampleDataQueue数据的大小和长度,sampleDataQueue来添加,具体sampleDataQueue是怎么有效管理数据的后面会讲到,现在不是重点
通过sampleDataQueue和sampleMetadata对比你会发现sampleMetadata比sampleDataQueue复杂多个,而且sampleMetadata方法添加了synchronized 同步块,多线程的时候会阻塞,而sampleDataQueue没有任何同步代码包括到sampleDataQueue里也一样。这样做是因为sampleMetadata的数据量很少,即使阻塞也能很高效的执行。而sampleData数据量往往比较大,写入的时间也比较长,所以不能阻塞。那么为什么要这么做呢,后面我们看到数据的读取部分就能理解了。
-
输出 SampleQueue提供了read方法输出数据
分析下对应源码:public int read(FormatHolder formatHolder,DecoderInputBuffer buffer,@ReadFlags int readFlags,boolean loadingFinished) {//首先读取Metadataint result =peekSampleMetadata(formatHolder,buffer,/* formatRequired= */ (readFlags & FLAG_REQUIRE_FORMAT) != 0,loadingFinished,extrasHolder);if (result == C.RESULT_BUFFER_READ && !buffer.isEndOfStream()) {boolean peek = (readFlags & FLAG_PEEK) != 0;if ((readFlags & FLAG_OMIT_SAMPLE_DATA) == 0) {if (peek) {sampleDataQueue.peekToBuffer(buffer, extrasHolder);} else {sampleDataQueue.readToBuffer(buffer, extrasHolder);//将sampleData的位置信息通过extrasHolder传递给sampleDataQueue读取数据}}if (!peek) {readPosition++;//读取位置++}}return result;}//读取Metadataprivate synchronized int peekSampleMetadata(FormatHolder formatHolder,DecoderInputBuffer buffer,boolean formatRequired,boolean loadingFinished,SampleExtrasHolder extrasHolder) {...Format format = sharedSampleMetadata.get(getReadIndex()).format; //用绝对开始位置+读取位置(absoluteFirstIndex + readPosition)获取读取的绝对位置...int relativeReadIndex = getRelativeIndex(readPosition);//获取当前Info数组的相对位置...extrasHolder.size = sizes[relativeReadIndex];//取出Info数据extrasHolder.offset = offsets[relativeReadIndex];extrasHolder.cryptoData = cryptoDatas[relativeReadIndex];return C.RESULT_BUFFER_READ;}//获取读取的绝对位置public final int getReadIndex() {return absoluteFirstIndex + readPosition;}要读取sampleData和sampleMetadata的数据,首先要确定当前读取点的Info的位置,然后通过Info数组才能知道读取的位置和长度,最后读取sampleData,同样sampleMetadata读取是加锁的,而sampleData没有。可以看出sampleData的读写是不受线程限制的,通过SampleQueue内部维护的Info数组来维护sampleData,可以最大化保证多线程下sampleData读写的效率。
-
释放 通过discardSamples等释放不需要的数据
分析下对应源码:public final void discardTo(long timeUs, boolean toKeyframe, boolean stopAtReadPosition) {sampleDataQueue.discardDownstreamTo(discardSampleMetadataTo(timeUs, toKeyframe, stopAtReadPosition));//先释放Metadata}private synchronized long discardSampleMetadataTo(long timeUs, boolean toKeyframe, boolean stopAtReadPosition) {if (length == 0 || timeUs < timesUs[relativeFirstIndex]) {return C.INDEX_UNSET;}int searchLength = stopAtReadPosition && readPosition != length ? readPosition + 1 : length;//根据时间戳来确定要释放数据块的数量int discardCount = findSampleBefore(relativeFirstIndex, searchLength, timeUs, toKeyframe);if (discardCount == -1) {return C.INDEX_UNSET;}return discardSamples(discardCount); }private long discardSamples(int discardCount) {largestDiscardedTimestampUs =max(largestDiscardedTimestampUs, getLargestTimestamp(discardCount));length -= discardCount;//有效长度=有效长度-释放数量absoluteFirstIndex += discardCount;//绝对开始位置后移relativeFirstIndex += discardCount;//相对开始位置后移if (relativeFirstIndex >= capacity) {//环形数组relativeFirstIndex -= capacity;}readPosition -= discardCount;//因为relativeFirstIndex后移,相对它的位置在缩小if (readPosition < 0) {readPosition = 0;}sharedSampleMetadata.discardTo(absoluteFirstIndex);//释放Metadataif (length == 0) {int relativeLastDiscardIndex = (relativeFirstIndex == 0 ? capacity : relativeFirstIndex) - 1;return offsets[relativeLastDiscardIndex] + sizes[relativeLastDiscardIndex];} else {return offsets[relativeFirstIndex];//返回SampleData的释放偏移量} }同样数据的释放和读写一样,通过内部的Info来管理,释放后会更新Info上的相关位置。
SampleQueue动态分析
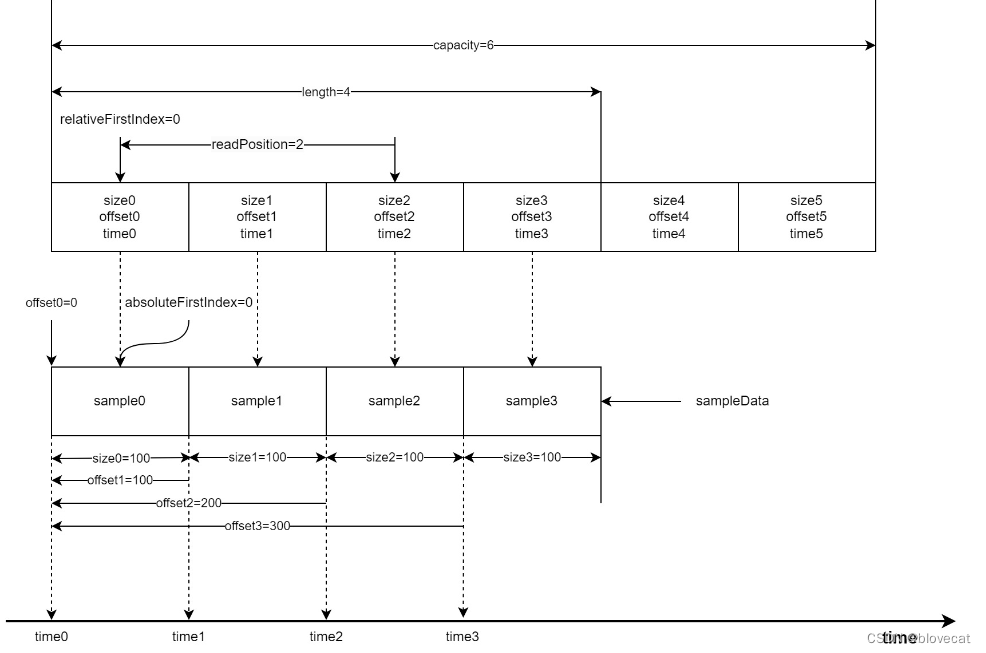
上面一直在说环形数组,静态的看代码可能感受不到这点,下面我们通过几个图来动态分析下SampleQueue的运作原理,这部分需要结合上面的源码一起看才好理解。
首先为了方便分析假设数组最大长度为capacity=6,当前已经写入了4段sampleData对应图中的sample0-3,同时也写入了4个数据到Info数组对应图中的0-2的size、offset、time结构,每个结构的size、offset、time在图的最下方都有标记,这里可以看下加深下对这个结构数值的含义的理解,所以此时有效长度length=4,由于是刚开始读写这个时候的relativeFirstIndex=absoluteFirstIndex=0处于开始位置,当前的读取位置相对于relativeFirstIndex也就是和relativeFirstIndex差值,readPosition=2。接下来sample会从右侧箭头处不断写入。同样上方的Info数组随着读取也会不断变化。
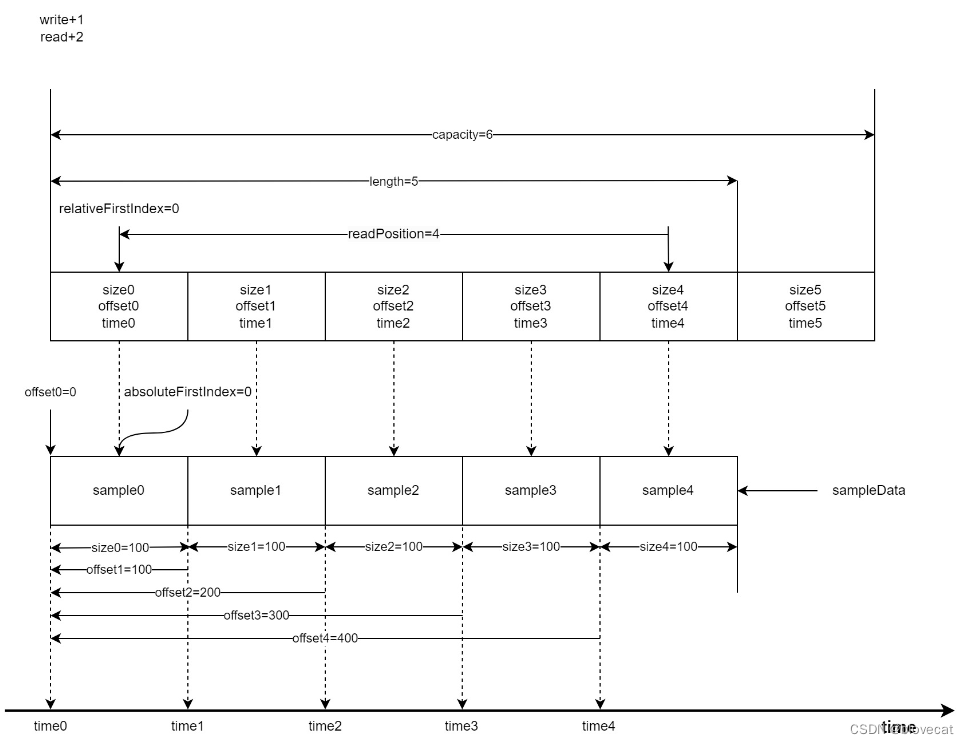
好了,此时先向Sample队列写入一个Sample length+1,然后同时读取2个Sample readPosition+2=4
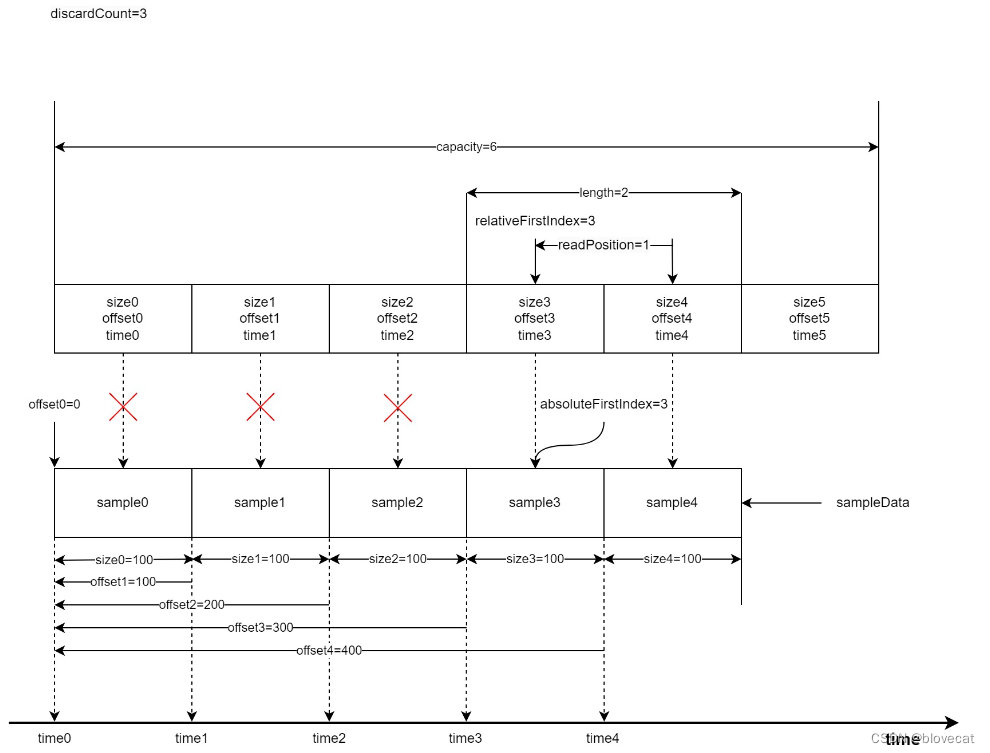
随着数据被使用(已经播放)之前的数据需要丢弃,以便下次写入,释放3个Sample,可以看到relativeFirstIndex和absoluteFirstIndex同时前移,虽然readPosiition的位置没有移动,也就是没有读取新的数据,但是readPosiition的值变小,有效长度缩小为2。到这里relativeFirstIndex还是和absoluteFirstIndex相等的还看不出环形的特性。
此时开始写入3个Sample,这个时候就可以看出Info环形特性,之前释放的0号和1号会重新指向数据队列的最前端,同时更新offset,size相关数据,有效数据长度增加到5,length=5。
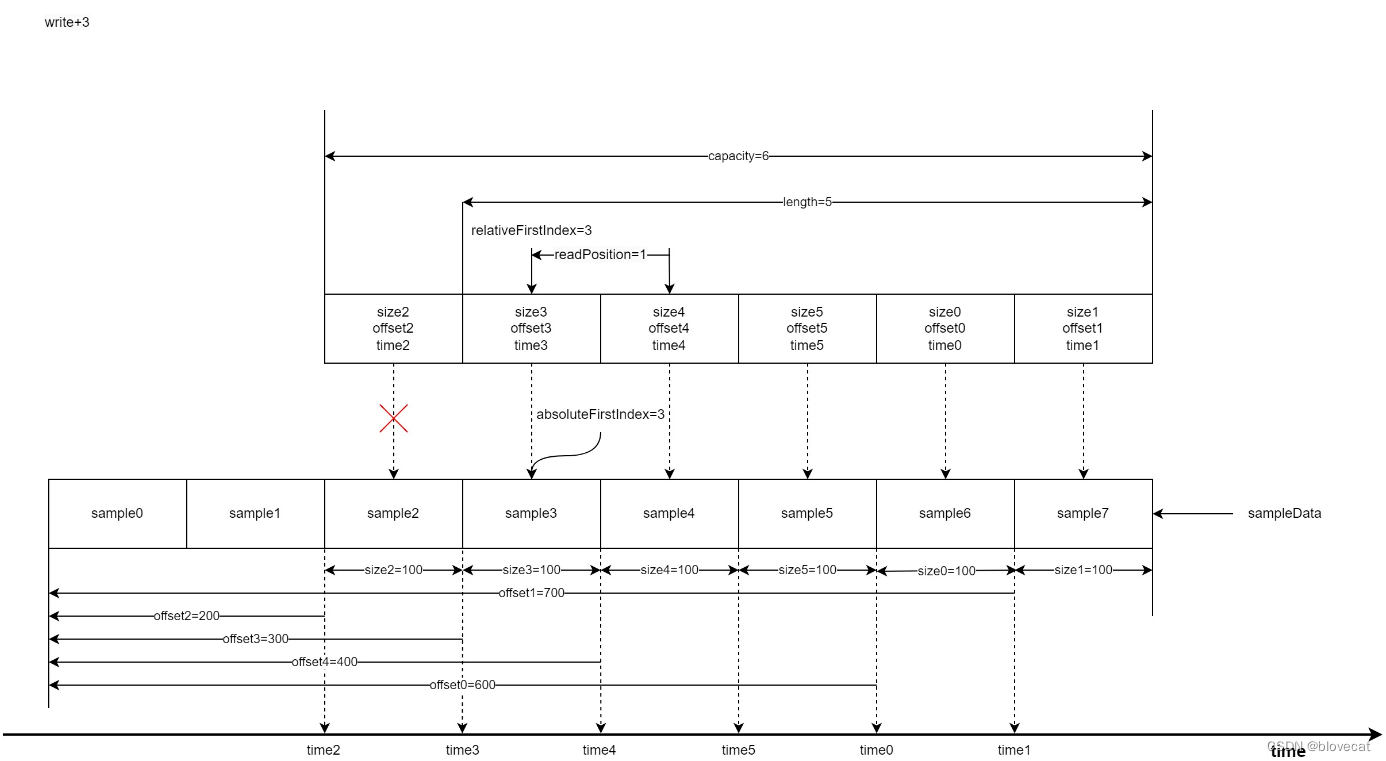
这个时候再读取3个Sample时,readPosiition的值增加3此时指向Info数组的下标1,readPosiition=4。
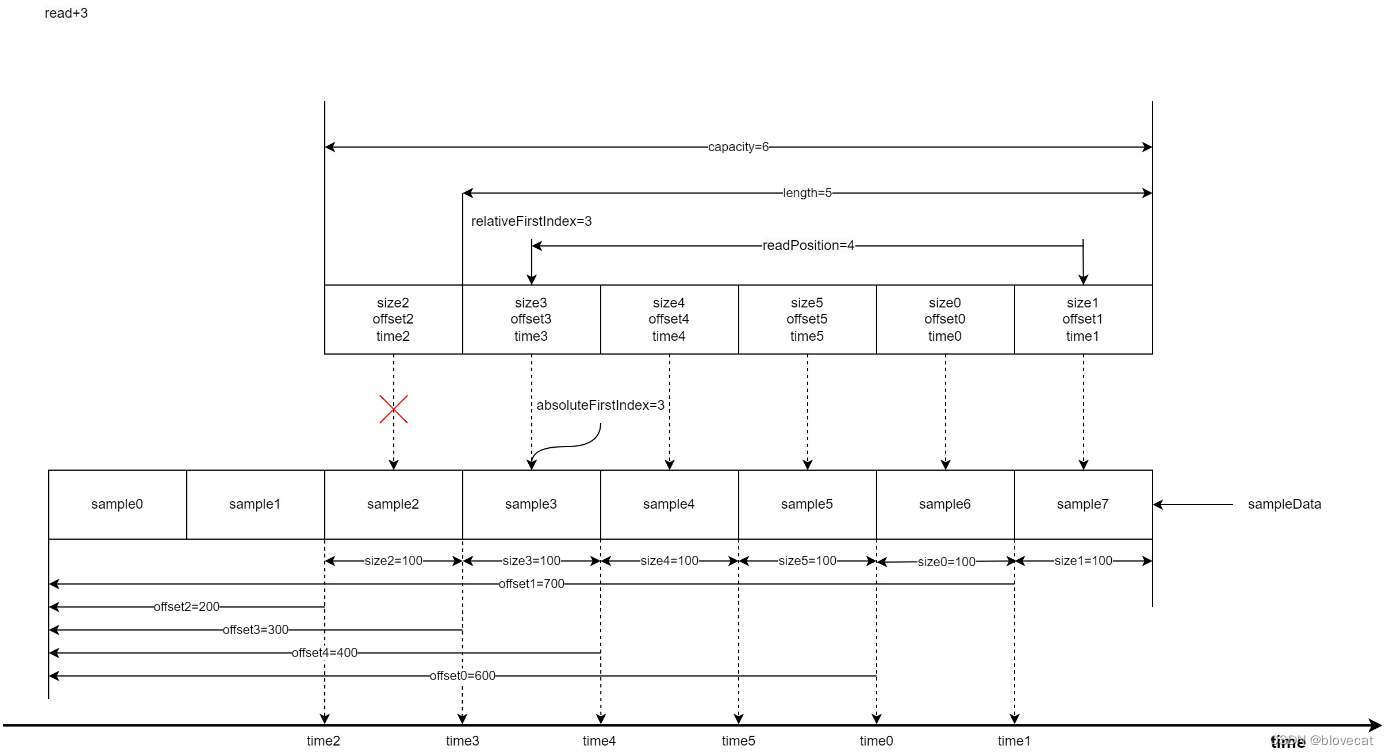
好了我们继续释放数据,这次再次释放3个,可以看到relativeFirstIndex和absoluteFirstIndex值开始不一样了,由于又回到了Info数组的开始位置所以relativeFirstIndex=0,readPosiition缩短为1,有效长度length=2,而absoluteFirstIndex是相对于Smaple的绝对位置,这个时候absoluteFirstIndex继续后移到6号位置的sample6。
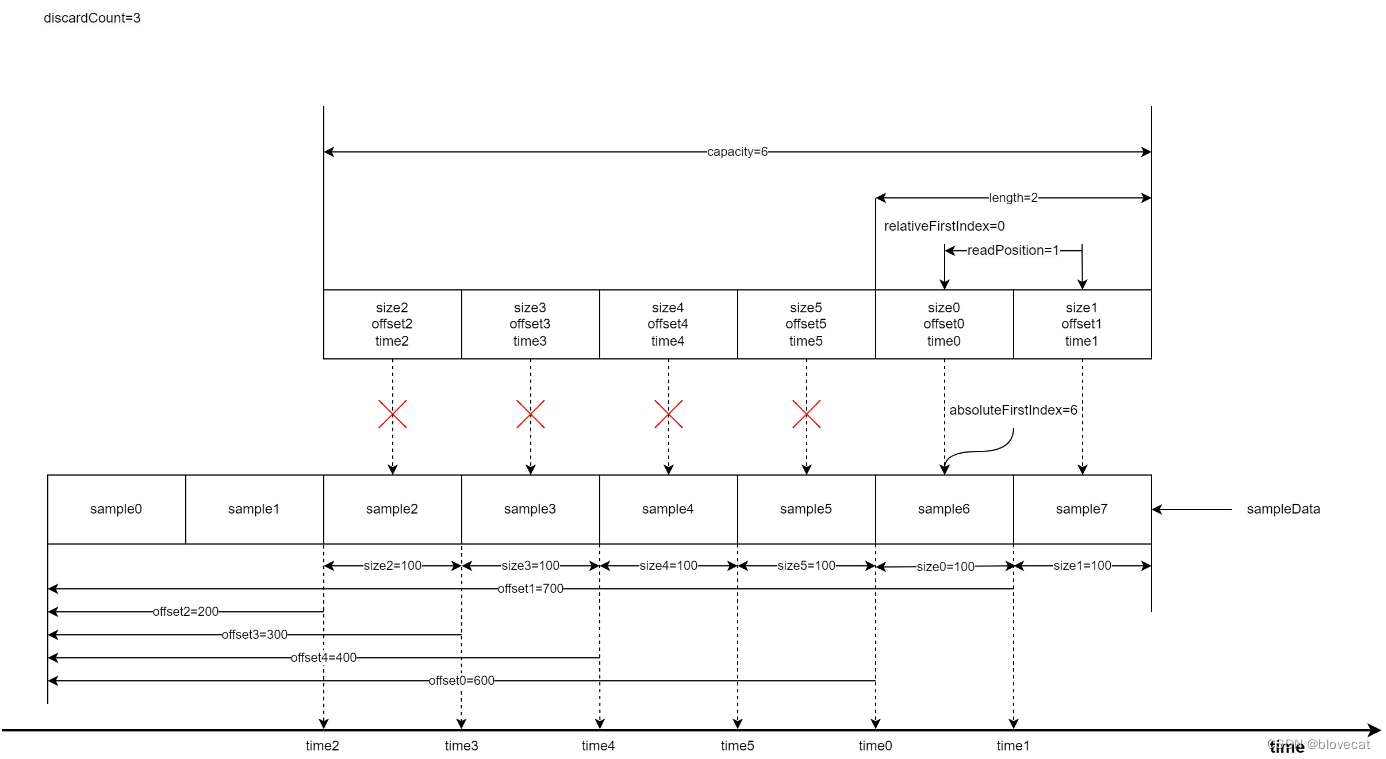
把上面的图连续不断的执行,可以想象出,Info数组像一个不断前行的履带在sample铺的道路上不断前行(读取)。被履带压过的道路(已经读取过的数据)就会被释放,此时路还在不断的向前铺设(新的sample数据在不断的写入到SampleQueen中),整个过程中履带的大小是不变的。
至此我们可以总结出几个规律:
- 当前写入数据的绝对位置永远等于absoluteFirstIndex+length
- 当前读取数据的绝对位置永远等于absoluteFirstIndex + readPosition
- Info数组可以理解成一个首尾相连的环形数组,数组最后一个位置的下个位置就是数组的开始位置
这几个规律在源码中经常被用到,感兴趣的同学可以深入阅读下。
下面来分析下实际存储数据的2个结构
SpannedData< SharedSampleMetadata >
本质是一个Android里实现SparseArray的map,通过int 类型key可以快速向指定key存入数据或者取出数据,这里数据跟随SampleQueue里的Info来管理,添加或者释放指定位置的Metadata数据。
SampleDataQueue
重点来说下SampleDataQueue,由于SampleData的数据量要远远大于Metadata,而且还需要频繁的读写释放,所以向SpannedData<SharedSampleMetadata>那样简单粗暴的管理数据,效率会非常低,因为JVM要频繁的申请内存GC释放内存。为了解决这个问题SampleDataQueue内部维护了一个链表,同时维护了链表中3个重要的节点,firstAllocationNode,readAllocationNode,writeAllocationNode,用于快速获取读写点。
private AllocationNode firstAllocationNode;//第一个节点位置private AllocationNode readAllocationNode;//当前读取节点位置private AllocationNode writeAllocationNode;//当前写入节点位置
这里顺带提下AllocationNode的数据结构,主要就是封装了Allocation,allocation才是实际存储数据的部分,同时提供了next AllocationNode 提供下一个AllocationNode 的指针,形成一个链表结构。
private static final class AllocationNode implements Allocator.AllocationNode {public long startPosition;//此段allocation的开始位置public long endPosition;//此段allocation的结束位置public Allocation allocation;//实际缓存数据部分public AllocationNode next;//指向下一个...public void initialize(Allocation allocation, AllocationNode next) {this.allocation = allocation;this.next = next;}...
回到SampleDataQueue中,调用sampleData循环写入数据时,每次循环写入主要分为3步:
- 调用preAppend初始化通过writeAllocationNode,同时也初始化出了下个writeAllocationNode。重点看下allocator.allocate(),这里才是初始化了AllocationNode的实际内存数据allocation的地方,后面会详细分析。
- 将数据循环写入writeAllocationNode的实际缓存位置allocation.data中。
- 调用preAppend更新SampleDataQueue已写入总长度,如果总长度已经超过当前写入节点的结束位置,将当前写入节点,更新为下一写入节点。
private int preAppend(int length) {if (writeAllocationNode.allocation == null) {writeAllocationNode.initialize(allocator.allocate(),//分配内存new AllocationNode(writeAllocationNode.endPosition, allocationLength));}return min(length, (int) (writeAllocationNode.endPosition - totalBytesWritten));}public void sampleData(ParsableByteArray buffer, int length) {while (length > 0) {int bytesAppended = preAppend(length);buffer.readBytes(writeAllocationNode.allocation.data,writeAllocationNode.translateOffset(totalBytesWritten),bytesAppended);length -= bytesAppended;postAppend(bytesAppended);}}private void postAppend(int length) {totalBytesWritten += length;//增加总长度if (totalBytesWritten == writeAllocationNode.endPosition) {//总长度已经超过当前写入节点的结束位置writeAllocationNode = writeAllocationNode.next;//将当前写入节点,更新为下一写入节点}}
读取和写入类似,直接看下释放数据的地方,首先释放指定位置之前的链表数据,其次重置开始节点和读取节点。
public void discardDownstreamTo(long absolutePosition) {if (absolutePosition == C.INDEX_UNSET) {return;}while (absolutePosition >= firstAllocationNode.endPosition) {//从第一个节点开始依次取出下一个节点通过allocator释放内存,并清除AllocationNode,一直到指定的absolutePositionallocator.release(firstAllocationNode.allocation);firstAllocationNode = firstAllocationNode.clear();}if (readAllocationNode.startPosition < firstAllocationNode.startPosition) {//保证当前的读取位置在开始节点之后readAllocationNode = firstAllocationNode;}}
看完是不是发现目前也没没有解决上面说的内存问题,内存感觉是在不断新增的。注意看下上面源码实际获取内存的地方allocator.allocate(),原来这些都交给了Allocator,通过Allocator实现内存的循环高效利用。
Allocator
这是一个接口用于媒体数据的内存分配,默认有一个DefaultAllocator实现。
先看下主要的源码
public final class DefaultAllocator implements Allocator {private static final int AVAILABLE_EXTRA_CAPACITY = 100;//额外的初始化Allocation数量private final boolean trimOnReset;private final int individualAllocationSize;@Nullable private final byte[] initialAllocationBlock;//初始化的一个连续的数组,指向默认数量的的Allocations,参考下图private int targetBufferSize;private int allocatedCount;//已分配的Allocation数量,参考下图private int availableCount;//可用的Allocation数量,参考下图private @NullableType Allocation[] availableAllocations;//可用的Allocations,参考下图public DefaultAllocator(boolean trimOnReset, int individualAllocationSize, int initialAllocationCount) {this.trimOnReset = trimOnReset;this.individualAllocationSize = individualAllocationSize;this.availableCount = initialAllocationCount;this.availableAllocations = new Allocation[initialAllocationCount + AVAILABLE_EXTRA_CAPACITY];//添加了部分冗余if (initialAllocationCount > 0) {//将初始化的Allocations通过指定offset分配initialAllocationBlockinitialAllocationBlock = new byte[initialAllocationCount * individualAllocationSize];for (int i = 0; i < initialAllocationCount; i++) {int allocationOffset = i * individualAllocationSize;availableAllocations[i] = new Allocation(initialAllocationBlock, allocationOffset);}} else {initialAllocationBlock = null;}}//这个方法用于获取一个Allocation,注意在调用此方法后必须调用release方法将分配Allocation返还@Overridepublic synchronized Allocation allocate() {allocatedCount++;//已分配数量+1Allocation allocation;if (availableCount > 0) {allocation = Assertions.checkNotNull(availableAllocations[--availableCount]);//从尾部取出,可用数量-1availableAllocations[availableCount] = null;//清空} else {allocation = new Allocation(new byte[individualAllocationSize], 0);//不够用了,创建新的Allocation,直接初始化出一段新的数组分配给它if (allocatedCount > availableAllocations.length) {//可用Allocations扩充2倍availableAllocations = Arrays.copyOf(availableAllocations, availableAllocations.length * 2);}}return allocation;}//返还分配的Allocation@Overridepublic synchronized void release(Allocation allocation) {availableAllocations[availableCount++] = allocation;//可用数量加1allocatedCount--;//已分配数量减1}...
}@Override//释无用的空块
public synchronized void trim() {//如果重新定义了缓存区大小,计算需要的Allocation块总数量int targetAllocationCount = Util.ceilDivide(targetBufferSize, individualAllocationSize);int targetAvailableCount = max(0, targetAllocationCount - allocatedCount);//减去目前空余的块,则为剩余需要的块数量//不存在冗余,无需trimif (targetAvailableCount >= availableCount) {return;}if (initialAllocationBlock != null) {// 从头尾查找第一个不是空的块,将其位置向前int lowIndex = 0;int highIndex = availableCount - 1;while (lowIndex <= highIndex) {//未分配出的Allocation 不可能为nullAllocation lowAllocation = Assertions.checkNotNull(availableAllocations[lowIndex]);if (lowAllocation.data == initialAllocationBlock) {//当前低位为初始值,从未被分配过lowIndex++;//lowIndex后移} else {//当前低位Allocation已分配过//未分配出的Allocation 不可能为nullAllocation highAllocation = Assertions.checkNotNull(availableAllocations[highIndex]);if (highAllocation.data != initialAllocationBlock) {//当前高位Allocation已分配过highIndex--;//highIndex前移} else {//当前高位Allocation未分配过//将当前未分配过高位和已分配过的低位交换位置,未分配过的放到数组低位availableAllocations[lowIndex++] = highAllocation;availableAllocations[highIndex--] = lowAllocation;}}}//到这里lowIndex之前的所有Allocation都是未分配过的初始initialAllocationBlock// 获取他们的最大值,也就是最大可释放targetAvailableCount = max(targetAvailableCount, lowIndex);//只有一种情况lowIndex正好等于availableCount,也就是当前未分配块都是初始值,从未被分配,当前可能为初始状态跳过trimif (targetAvailableCount >= availableCount) {return;}}// 释放空块Arrays.fill(availableAllocations, targetAvailableCount, availableCount, null);availableCount = targetAvailableCount;}
Allocator保存了一组Allocation列表,和一个默认的字节数组,每个Allocation对于数据块的长度由individualAllocationSize决定,通过offset确定在数组中的起始位置。同时维护着可用数量和已分配数量,当外部需要新的Allocation时会调用allocate获取,使用完毕后调用release将Allocation返还。可以看到这种设计特别适合播放器的缓冲数据,开始播放时分配一个默认的缓冲区域大小,随着播放进度,当前播放位置前会不断获取新Allocation用于提前缓冲,当这些数据已被渲染播放,离开了缓冲区域,这个时候又会将之前获取Allocation返还,依次循环,滚动的循环利用已分配的内存,整个过程只要不超最大值,就不会再分配新的内存,效率非常高。
下面用一张图来解释下整个过程:

如上图,是一个有着6个Allocation的Allocator,单个Allocation包含2个block(individualAllocationSize=2),initialAllocationBlock也就是block数组总长度为initialAllocationCountindividualAllocationSize=62=12。
初始化时会将每个Allocation依次指向initialAllocationBlock中的Block,通过Offset记录位置,当前已经分配出2个Allocation(上图表示为null),空余4个Allocation可分配,此时如果外部再需要获取Allocation时,也就是调用allocate,会将Allocation4,分配出去同时置为null,这个时候Allocation4的指向的Block并没有变化,外部调用者会向Block中填充数据用于缓存。
如果外部释放Allocation时,也就是调用release,会将Allocation填充至Allocation4后面一个位置,记为Allocation5,此过程Allocation5一直都是指向initialAllocationBlock的某段Block的。
这两个过程availableCount和allocatedCount也会相应增加或者减少,如果一个Allocation从来没有被分配过,则Block为初始值initialAllocationBlock,如上图的Allocation1,可以通过判断当前的Allocation的data是否等于initialAllocationBlock判断当前Allocation是否被分配过。
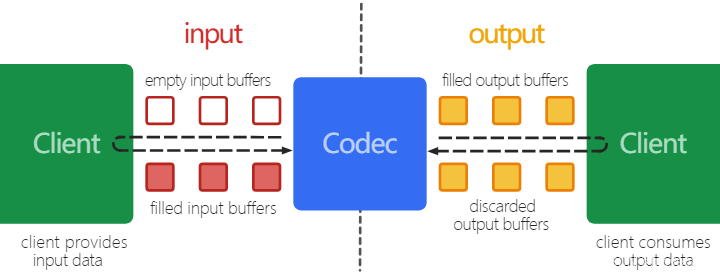
整个过程会让人不禁联想到 Android MediaCodec缓冲区,这里部分应该在Renderer部分提到,这里先提前贴下Android MediaCodec缓冲区使用的图,看看是不是很相似呢。
总结
SampleQueue只对Info数组这种小数据量的读写操作做多线程加锁操作,通过短时间阻塞读取Info数组的方式,查询读取关联的sampleData的数据,保证对sampleData这种大数据量耗时的读写不会阻塞,保证了数据的读写效率。
同时SampleQueue的环形数组的数据管理方式令人印象深刻,这种结构特别适合媒体播放这种场景,完美的平衡了性能与内存使用之间的矛盾。
有了SampleQueue这个数据大总管,ProgressiveMediaPeriod就可以随心所欲的写入数据并将媒体数据提供给上游读取。
到这里算是讲完了ProgressiveMediaPeriod的SampleQueue部分。后面将会讲到数据是如何加载到SampleQueue的,也就是首图的右半部分。
版权声明 ©
本文为CSDN作者山雨楼原创文章
转载请注明出处
原创不易,觉得有用的话,收藏转发点赞支持
相关文章:
ExoPlayer架构详解与源码分析(7)——SampleQueue
系列文章目录 ExoPlayer架构详解与源码分析(1)——前言 ExoPlayer架构详解与源码分析(2)——Player ExoPlayer架构详解与源码分析(3)——Timeline ExoPlayer架构详解与源码分析(4)—…...

第二证券:基本面改善预期强化 机构聚焦科技成长
沪指日前迎来“三连涨”。10月26日,上证指数、深证成指和创业板指全部收红,分别收涨0.48%、0.40%、0.65%。此前的两个交易日,上证指数、深证成指也均收涨,创业板指24日涨幅也达到了0.85%。 从近期密布发布的策略报告来看…...
大语言模型在天猫AI导购助理项目的实践!
本文主要介绍了Prompt设计、大语言模型SFT和LLM在手机天猫AI导购助理项目应用。 ChatGPT基本原理 “会说话的AI”,“智能体” 简单概括成以下几个步骤: 预处理文本:ChatGPT的输入文本需要进行预处理。 输入编码:ChatGPT将经过预…...

【STM32】GPIO控制LED(HAL库版)
STM32最新固件库v3.5/Libraries/CMSIS/CM3/DeviceSupport/ST/STM32F10x/system_stm32f10x.c 林何/STM32F103C8 - 码云 - 开源中国 (gitee.com) STM32最新固件库v3.5/Libraries/STM32F10x_StdPeriph_Driver/src/stm32f10x_gpio.c 林何/STM32F103C8 - 码云 - 开源中国 (gitee.…...

第27届亚洲国际动力传动与控制技术展览会盛大开幕,意大利国家展团闪耀回归
2023年10月24日,第27届亚洲国际动力传动与控制技术展览会(PTC ASIA)在上海新国际博览中心正式拉开帷幕。作为亚太地区动力传动行业的风向标,PTC ASIA致力于为来自世界各地的参展企业提供专业的采供、技术信息交互平台,…...
永恒之蓝漏洞 ms17_010 详解
文章目录 永恒之蓝 ms 17_0101.漏洞介绍1.1 影响版本1.2 漏洞原理 2.信息收集2.1 主机扫描2.2 端口扫描 3. 漏洞探测4. 漏洞利用5.后渗透阶段5.1创建新的管理员账户5.2开启远程桌面5.3蓝屏攻击 永恒之蓝 ms 17_010 1.漏洞介绍 永恒之蓝(ms17-010)爆发于…...

汽车托运全流程介绍
从来没有办理过小轿车托运的客户都很好奇究竟汽车是如何被托运的呢?整个托运的过程介绍又是怎样的呢?因为托运汽车装车时客户本人都不在场,看不到整个的托运过程。今天具体的捋顺下整个的操作过程。 托运汽车装车前的准备工作 1.整个车辆装载过程中需要用到2名拥有…...
【API篇】八、Flink窗口函数
文章目录 1、增量聚合之ReduceFunction2、增量聚合之AggregateFunction3、全窗口函数full window functions4、增量聚合函数搭配全窗口函数5、会话窗口动态获取间隔值6、触发器和移除器7、补充 //窗口操作 stream.keyBy(<key selector>).window(<window assigner>)…...
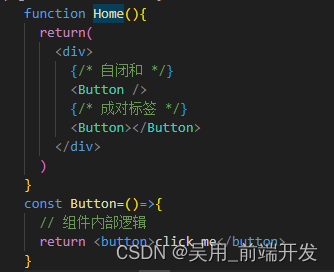
React JSX常用语法总结
React JSX语法 什么是React JSX JSX(javascript xml) 就是JavaScript和XML结合的一种格式,是JavaScript的语法扩展,只要把HTML代码写在JS中,就为JSX。用于动态构建用户界面的Javascript库,发送请求获取数据…...
DVWA-Cross Site Request Forgery (CSRF)
大部分网站都会要求用户登录后,使用相应的权限在网页中进行操作,比如发邮件、购物或者转账等都是基于特定用户权限的操作。浏览器会短期或长期地记住用户的登录信息,但是,如果这个登录信息被恶意利用呢?就有可能发生CSRF CSRF的英文全称为Cross Site Request Forgery,中文…...

浅谈安科瑞可编程电测仪表在老挝某项目的应用
摘要:本文介绍了安科瑞多功能电能表在老挝某项目的应用。AMC系列交流多功能仪表是一款专门为电力系统、工矿企业、公用事业和智能建筑用于电力监控而设计的智能电表。 Abstract:This article introduces the application of the multi-function energy …...

Java项目源码合集
以下只是源码合集的一部分,源码均已本地正常调试运行,如需请与我联系。 序号项目名称演示地址1springbootvue药店销售管理系统https://pan.baidu.com/s/1n-Vk5Pr5z7s3IcN3WsCkdg?pwdve6z 2基于ssm协同过滤技术的旅游景点购票系统https://pan.baidu.com…...
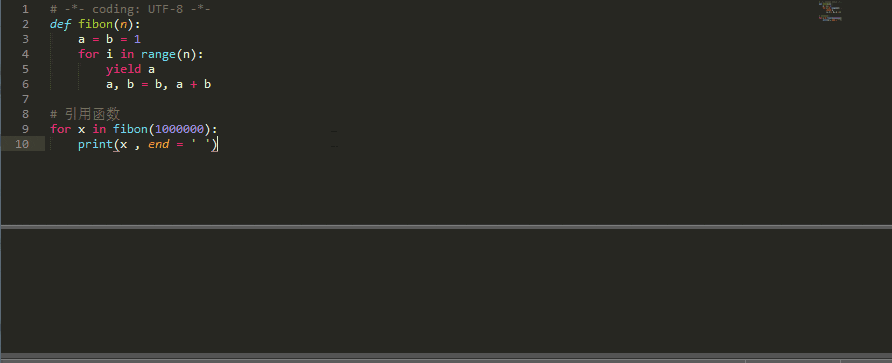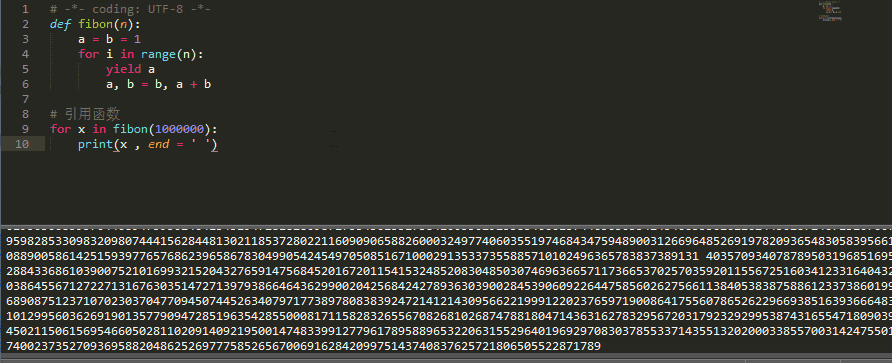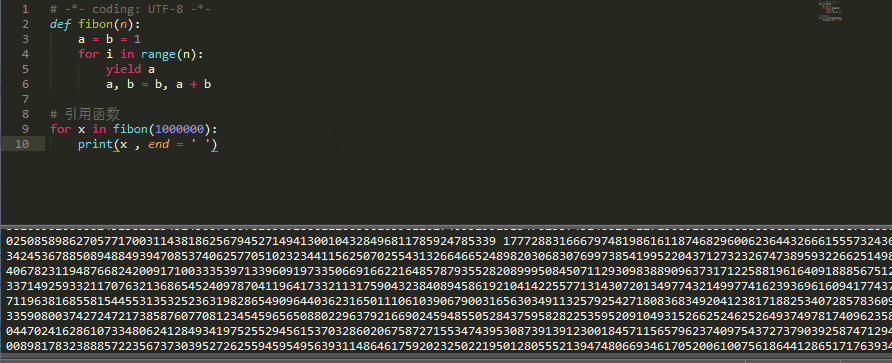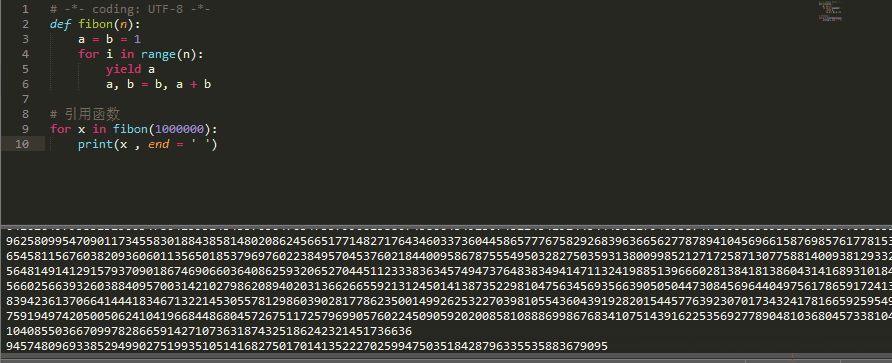
Python学习笔记--生成器
四、生成器 1、为什么需要生成器 通过上面的学习,可以知道列表生成式,我们可以直接创建一个列表。 但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含 1000 万个元素的列表,不仅占用很大的存储…...

【Python学习】—Python基础语法(五)
【Python学习】—Python基础语法(五) 一、循环的嵌套使用 二、九九乘法表 #外层循环表示行数 for i in range(1,10):#内层循环表示每一行的数据for j in range(1,i1):#输出每一行的内容print(f"{i} * {j} {i * j} \t",end"") #外层…...
定时器的方法:)
【js】JavaScript清除所有(多个)定时器的方法:
文章目录 一、停止单个定时器二、暂停与恢复定时器三、使用Promise来管理定时器四、使用ES6特性管理定时器五、案例(定时获取页面列表数据) 一、停止单个定时器 #在某些情况下,我们可能只需要停止单个定时器。 #在JavaScript中,我…...
java实现周易64卦并返回对应的卦象(含百度百科链接)
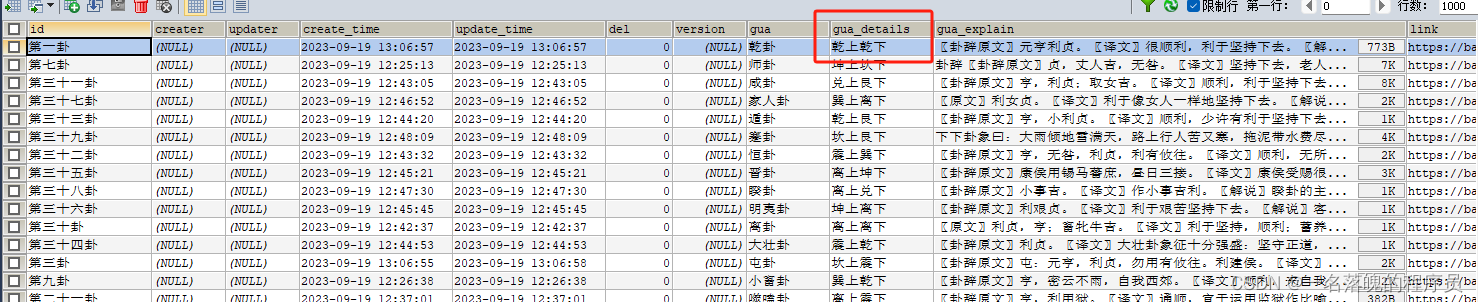
《易经》是中华民族传统思想文化中自然哲学与人文实践的理论根源,是古代汉民族思想、智慧的结晶,被誉为“大道之源”,是古代帝王之学,政治家、军事家、商家的必修之术。 《易经》含盖万有,纲纪群伦,是中华…...

# 算法与程序的灵魂
文章目录 前言算法与程序的关系例子1:冒泡排序例子2:斐波那契数列算法优化与进阶总结 前言 大家好我是艾老虎尤,算法与程序是计算机科学中两个非常重要的概念。算法是解决问题的方法和步骤,而程序是算法的具体实现。在计算机科学…...

2023-10-21 美团2024秋招后端开发岗笔试题
1 考察dfs和拓扑排序 1.1 题目描述(如果拓扑排序不清楚可以去做一下lc 207. 课程表) 1.2 答案 import java.util.*;public class Meituan {static int m,n;public static void main(String[] args) {Scanner in new Scanner(System.in);m in.nextInt…...

汽车托运是怎样收费
汽车托运是如何收费的呢?一般来说,汽车托运的费用是会随着每公里来增加,目前的托运的每公里费用在1.2-1.8元之间,托运的距离越远那么它的托运单价费用就会越低,如果你运气好找到一家在搞活动的汽车托运公司,那么你就算…...
使用docker-compose私有化部署 GitLab
在软件开发和协作过程中,版本控制是至关重要的一环。GitLab 是一个功能强大的开源平台,提供了完整的代码管理功能,包括版本控制、问题跟踪以及持续集成等。这使得团队能够更高效地协作开发。前段时间翻阅笔记时,偶然发现了之前公司…...

STM32CubeMX外设配置实战——以F103C8T6的CAN与DMA为例
1. STM32CubeMX与F103C8T6开发基础 STM32CubeMX是ST官方推出的图形化配置工具,它能极大简化STM32系列MCU的外设初始化流程。对于刚接触STM32开发的工程师来说,这个工具就像"乐高积木说明书"——通过可视化操作就能完成80%的底层配置工作。我最…...

从8K游戏到HDR电影:拆解Xilinx HDMI 2.1 IP如何支持VRR、ALLM和动态HDR这些炫酷特性
从8K游戏到HDR电影:Xilinx HDMI 2.1 IP如何重塑视听体验 当PS5玩家在《战神:诸神黄昏》中感受到无撕裂的流畅战斗画面,或是家庭影院爱好者在《沙丘》中看到沙漠场景的每一粒沙粒都呈现出惊人的动态范围时,背后都离不开HDMI 2.1的关…...

Performance-Fish:深度解析《环世界》400%性能优化核心技术
Performance-Fish:深度解析《环世界》400%性能优化核心技术 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish Performance-Fish 是专为《环世界》(RimWorld&#…...

FPGA高速ADC数据采集实战——基于AD9253 LVDS接口与ISERDESE2设计
1. AD9253高速ADC核心特性解析 AD9253这颗14位125MSPS四通道ADC芯片,在通信和医疗成像领域堪称经典。我经手过的多个雷达项目中,它的信噪比表现总能带来惊喜——75.3dBFS的实测数据比手册标称值还要稳定。但真正让工程师们又爱又恨的,是它那个…...

3步实现专业级AI换脸:roop-unleashed创新方案指南
3步实现专业级AI换脸:roop-unleashed创新方案指南 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed 在数字创意飞速发展的今天,AI换脸…...

平衡车PID积分饱和问题
你发现了PID最致命的坑! 你说的完全正确:积分(Ki)是累加的,会无限叠加,直接让PWM爆掉、车猛冲、失控! 这就是积分饱和 —— 99%初学者死在这里。 我现在彻底讲透积分为什么炸、怎么修复、平衡车…...

AI项目脚手架:标准化与自动化提升工程效率
1. 项目概述:一个为AI项目量身定制的“脚手架”如果你和我一样,在AI领域摸爬滚打多年,从早期的机器学习模型到现在的深度学习、大语言模型应用,肯定经历过无数次从零开始搭建项目的“阵痛”。每次新建一个项目,都要重复…...

基于Claude API构建可编程AI智能体:从对话到自动化生产单元
1. 项目概述:从Claude中“招聘”一个AI伙伴最近在GitHub上看到一个挺有意思的项目,叫“hire-from-claude”。初看这个标题,你可能会有点摸不着头脑:Claude不是Anthropic公司开发的那个AI助手吗?怎么还能从它那里“招聘…...

DOM 浏览器
DOM 浏览器 引言 DOM(文档对象模型)是浏览器中处理HTML和XML文档的标准方式。它允许开发人员通过编程方式访问和操作网页内容。本文将详细介绍DOM的概念、其在浏览器中的运用以及相关的编程技巧。 DOM简介 什么是DOM? DOM(Document Object Model)是一种跨平台和语言独…...

ESP32边缘AI部署实战:从模型量化到嵌入式推理全流程解析
1. 项目概述:当ESP32遇见AI,边缘智能的微型革命最近在捣鼓一个挺有意思的开源项目,叫wangzongming/esp-ai。光看名字,你可能觉得这又是一个把AI模型塞进微控制器的尝试,但实际深入后,我发现它的野心和实现方…...