移动端ViT新利器!苹果提出稀疏专家混合模型Mobile V-MoEs

文章链接:https://arxiv.org/abs/2309.04354
最近,专家混合模型MoE受到了学术界和工业界的广泛关注,其能够对任意输入来激活模型参数中的一小部分来将模型大小与推理效率分离,从而实现模型的轻量化设计。目前MoE已经在自然语言处理和计算机视觉进行了广泛的应用,本文介绍一篇来自Apple的最新工作,在这项工作中,苹果转而探索使用稀疏的MoE来缩小视觉Transformer模型(ViT)的参数规模,使其能够在移动端的推理芯片上更加流畅的运行。为此,本文提出了一种简化且适合移动设备的Mobile V-MoEs模型,将整个图像而不是单个patch路由输入给专家,并且提出了一种更加稳定的MoE训练范式,该范式可以使用超类信息来指导路由过程。作者团队通过大量的实验表明,与对应的密集ViT相比,本文提出的Mobile V-MoE可以在性能和效率之间实现更好的权衡,例如,对于 ViT-Tiny模型,Mobile V-MoE在ImageNet-1k上的性能比其密集模型提高了3.39%。对于推理成本仅为54M FLOPs的更小的ViT版本,本文方法实现了4.66%的改进。
01. 引言
稀疏专家混合模型是一种可以将模型大小与推理效率解耦的神经网络加速手段,直观上理解,MoEs[1]是一种可以被划分为多个“专家”模块的神经网络,“专家”模块与一个路由模块联合训练,在MoEs中,每个输入仅由一小部分模型参数处理(又称条件计算)。相比之下,普通的密集模型则会激活每个与输入有关的参数,如下图所示(b)(c)所示,MoE首先使用路由模块从输入图像中选取一些patch,然后再将这些patch送入到专家模块中进行计算。
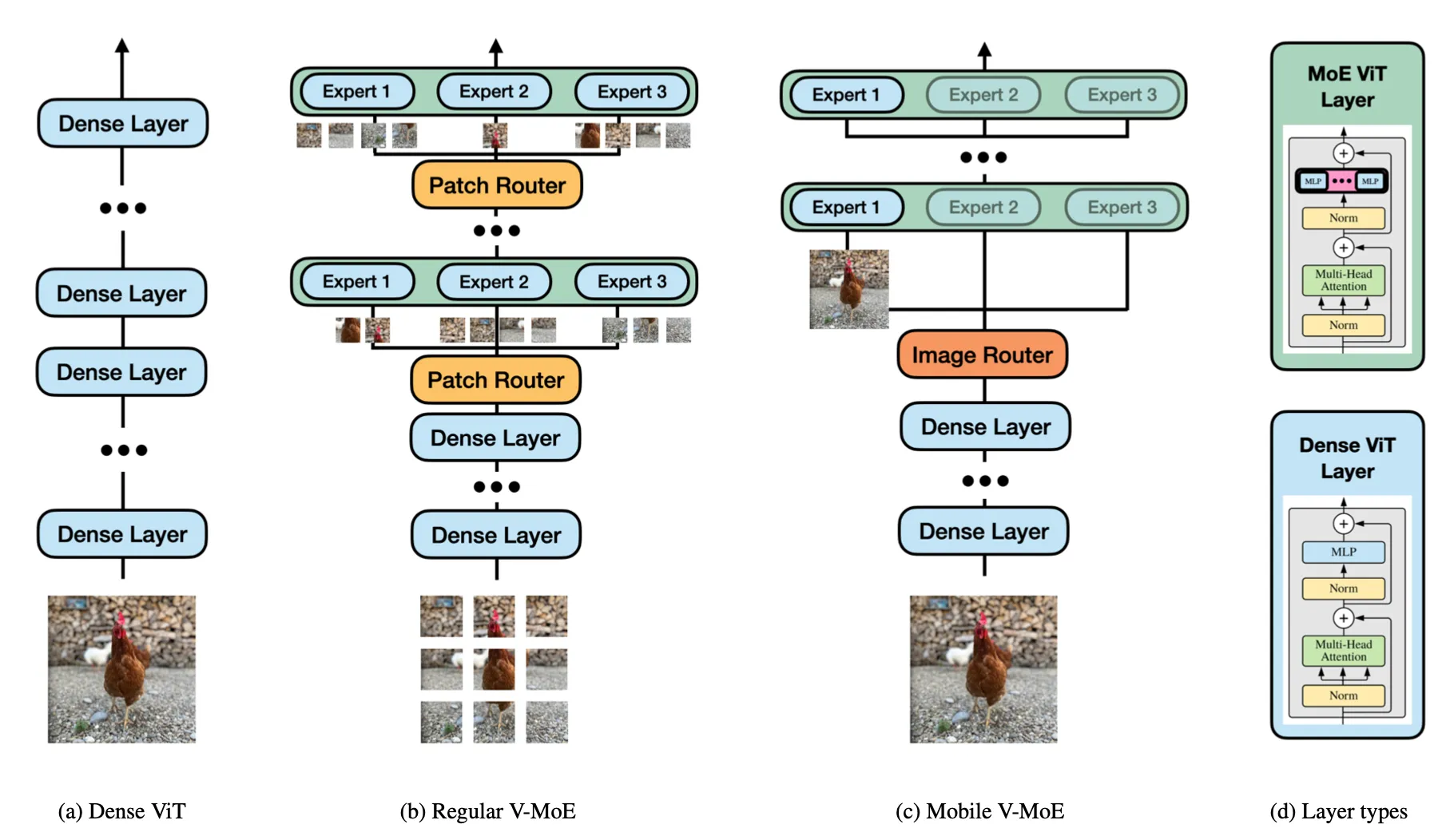
虽然目前在CV领域,Transformer架构代替CNN架构已经成为一种趋势,但是现有基于ViT架构的MoEs方法仍然无法像卷积结构一样很好的在移动端进行部署,因此,本文作者想使用条件计算来将注意力头的计算量进行缩减,此外提出了一种更加简化且更适合于移动设备的稀疏MoE设计,即首先使用路由模块将整个图像的表征(而不是图像块)直接分配给专家模块,作者还对这一结构设计了一套专门的训练范式,引入了语义超类的概念来指导路由器的训练来避免专家分配不平衡的问题。本文通过广泛的实验表明,所提出的稀疏MoE方法可以达到ViT模型性能与效率之间的全新平衡。
02. 本文方法
2.1 稀疏MoEs

2.2 适用于轻量级ViT的MoEs


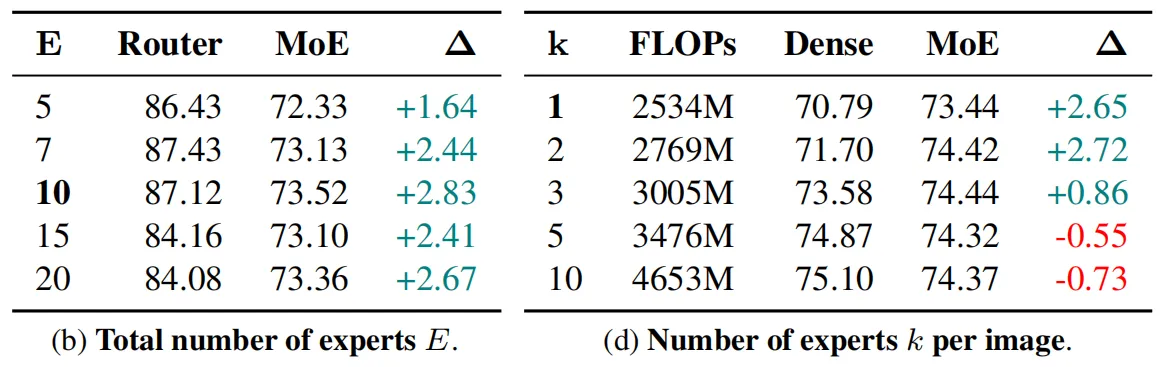
03. 实验效果
本文的实验在ImageNet-1K数据集上进行,该数据集包含大约128万张训练图像,本文所有的对比方法和模型版本均在该训练集上从头端到端训练,然后在包含5万张图像的验证集上计算top-1识别准确率。
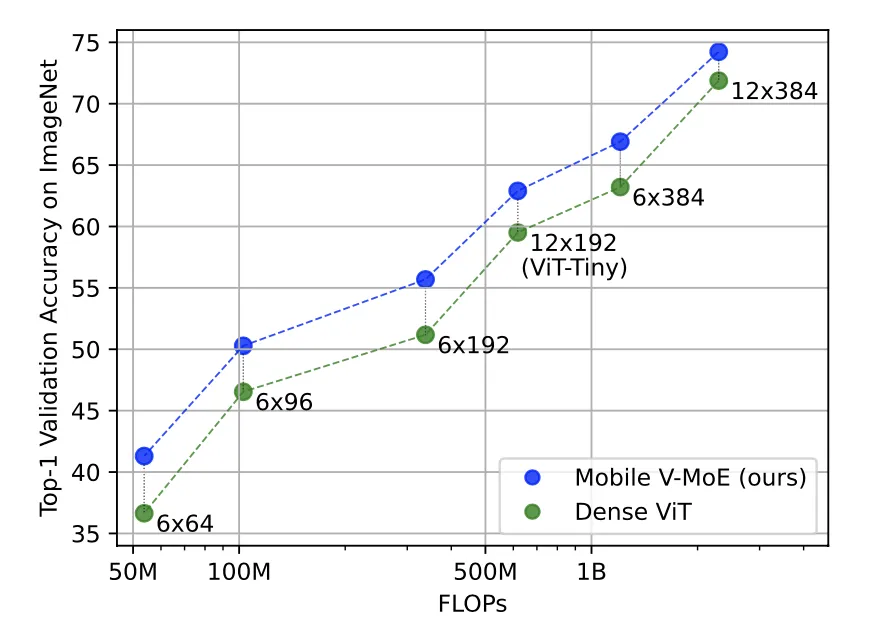
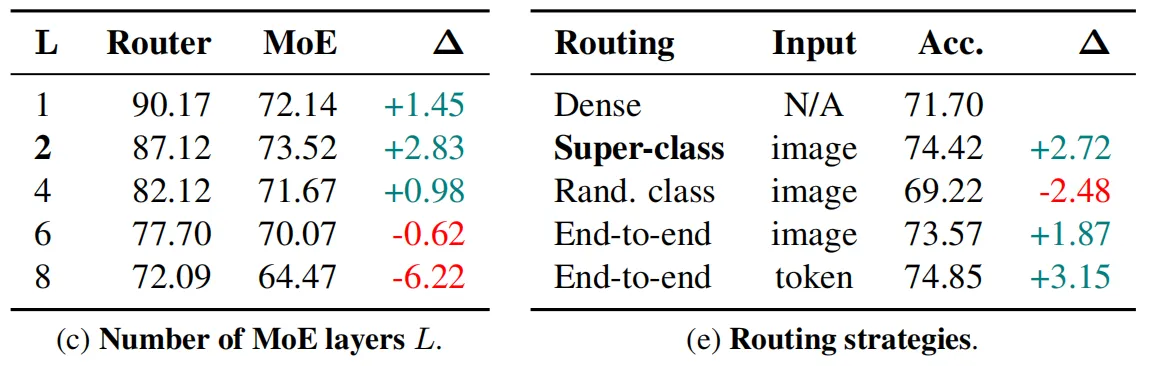
作者通过缩放Transformer总层数(12、9、6)和隐藏层特征维度(384、192、96和64)来控制Mobile V-MoEs与其对应的密集ViT的模型大小。上图展示了本文方法与其对应参数规模的ViT模型的识别准确率对比,可以看到本文提出的Mobile V-MoEs在所有的模型规模上都优于对应的ViT模型。从视觉ViT的基本范式出发,模型内部MLP的嵌入特征维度应是隐藏层特征维度的4倍。
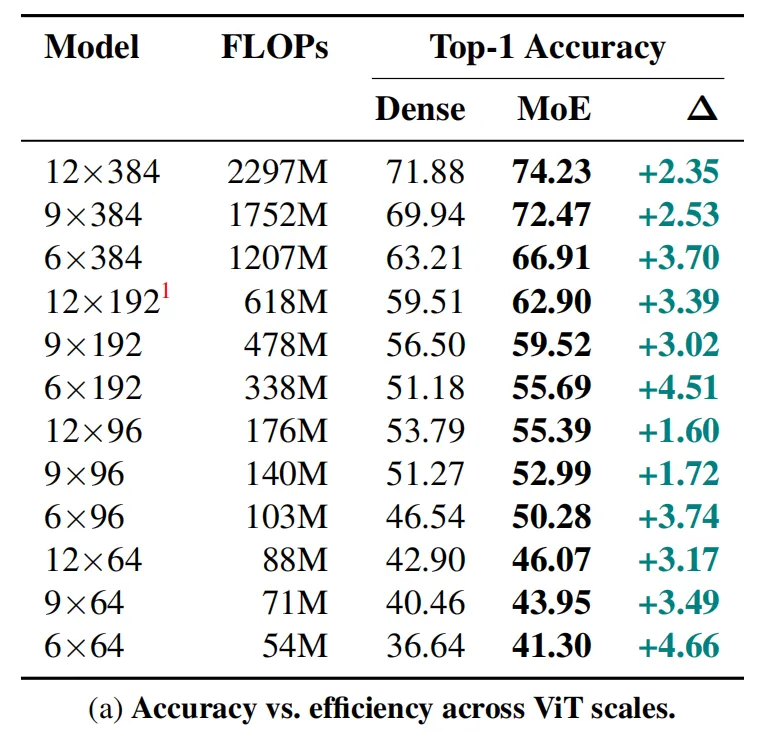
此外,本文涉及到的MoEs模型均由2个MoE-ViT层构成,在这些层的前面是不同数量级的密集ViT层,输入的patch大小为 32×32 。这样设置的目的是因为patch大小可以有效的控制FLOPs与模型参数数量之间的权衡,由于本文的目标是针对模型FLOPs进行优化,因此较大的patch大小使得我们可以更加专注于控制patch的计算效率,此外,作者还在 32×32的基础上尝试了更小的 16×16 尺寸,实验结果的趋势与大尺寸保持一致,上表展示了详细的实验效果。


04. 总结
目前,在深度学习模型落地部署领域,正在经历着从CNN向视觉ViT过度的大潮流,基于CNN的移动端轻量级网络(如MobileNet)也亟待升级。本文介绍了一种移动端ViT轻量化的最新技术,作者将稀疏MoEs迁移到视觉ViT模型架构中,与其对应的密集ViT相比,稀疏MoE可以实现高效的性能与效率权衡,这使得将更多类型的视觉ViT模型部署到移动端计算设备上成为可能。此外本文作者展望到,如果能将稀疏MoEs技术应用到CNN和视觉ViT结合的算法模型上,可能会得到更好的推理效果。
参考
[1] Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy
Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538, 2017.
[2] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herv´e J´egou. Training data-efficient image transformers & distillation through attention. In International conference on machine learning, pages 10347–10357. PMLR, 2021.
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区
相关文章:
移动端ViT新利器!苹果提出稀疏专家混合模型Mobile V-MoEs
文章链接:https://arxiv.org/abs/2309.04354 最近,专家混合模型MoE受到了学术界和工业界的广泛关注,其能够对任意输入来激活模型参数中的一小部分来将模型大小与推理效率分离,从而实现模型的轻量化设计。目前MoE已经在自然语言处理…...

【linux系统】服务器安装Pycharm
文章目录 安装pycharm步骤1. 进入pycharm官网2. 上传到服务器3. 安装过程 摘要:pycharm是Python语言的图形化开发工具。因为如果在Linux环境下的Python shell 中直接进行编程,其无法保存与修改,在大型项目当中这是很不方便的,而py…...

便利连锁:如何增加收益?教你一招轻松搞定!
自动售货机,作为零售行业的一项颠覆性技术,正逐渐改变着我们的购物方式和商业格局。这一创新技术不仅重新定义了零售业务模式,还为企业提供了更多的机会来满足不断演变的消费者需求。 客户案例 便利连锁店 成都某便利连锁店面临一系列挑战&am…...
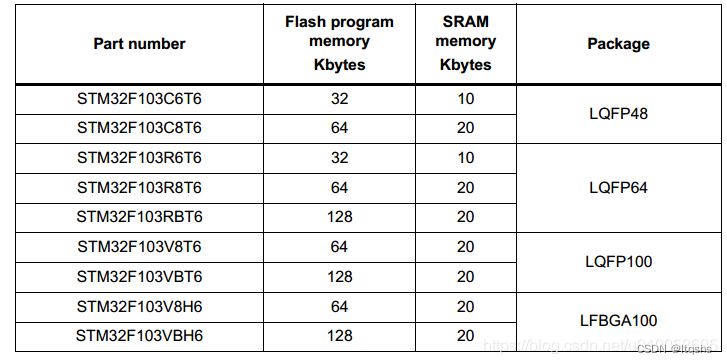
STM32-程序占用内存大小计算
STM32中程序占用内存容量 Keil MDK下Code, RO-data,RW-data,ZI-data这几个段: Code存储程序代码。 RO-data存储const常量和指令。 RW-data存储初始化值不为0的全局变量。 ZI-data存储未初始化的全局变量或初始化值为0的全局变量。 占用的FlashCode RO Data RW Data; 运行消…...
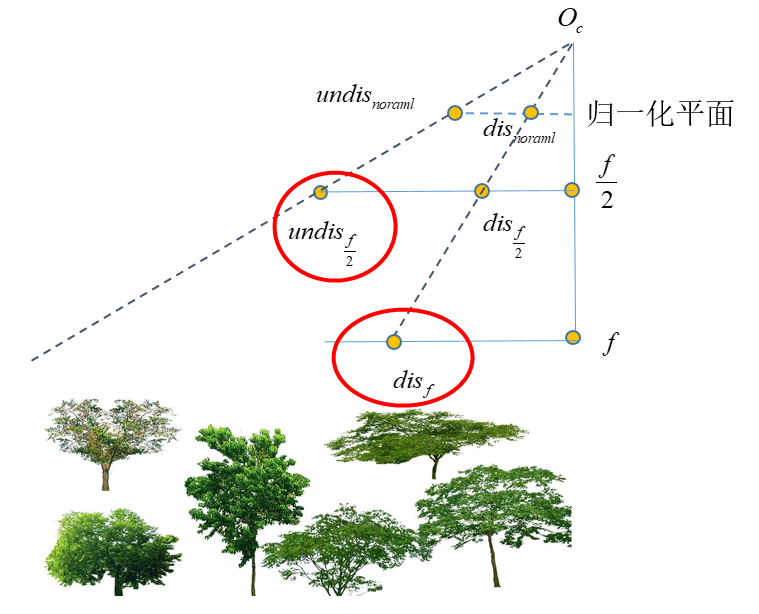
鱼眼图像去畸变python / c++
#鱼眼模型参考链接 本文假设去畸变后的图像与原图大小一样大。由于去畸变后的图像符合针孔投影模型,因此不同的去畸变焦距得到不同的视场大小,且物体的分辨率也不同。可以见上图,当焦距缩小为一半时,相同大小的图像(横…...
文心一言简单体验
百度正式发布文心一言,文心一言 这里的插件模式挺有意思: 测试了一下图解说明,随意上传了一张图片: 提供图解让反过来画,抓住了部分重点,但是还是和原图有比较大的差异! 百宝箱 暂未逐个体验&am…...

css正确的语法
Cascading Style Sheets (CSS) 是一种用于定义网页元素外观和样式的标记语言。以下是正确的 CSS 语法要点: 选择器 (Selector): 选择器用于指定要应用样式的 HTML 元素。例如,选择器可以是标签名、类名、ID、属性等。例如: 标签名选择器&…...

【PG】PostgresSQL角色管理
目录 角色概念 查询现有角色 列出当前角色 创建角色 删除角色 更改角色 创建角色举例 预定义角色 角色属性 登陆角色 超级用户角色 创建数据库角色 创建role角色 复制角色 创建带有密码的角色 角色成员关系 角色组概念 角色组增加成员 角色组移除成员 删除角…...

百度智能云获评Forrester中国市场人工智能/机器学习平台领导者
写在前面百度智能云AI平台,打造企业智能化转型的基础设施大模型时代,百度智能云AI平台迎来全面升级 写在前面 日前,国际权威咨询机构 Forrester 发布了最新的《The Forrester Wave™:中国市场人工智能/机器学习平台厂商评测&…...
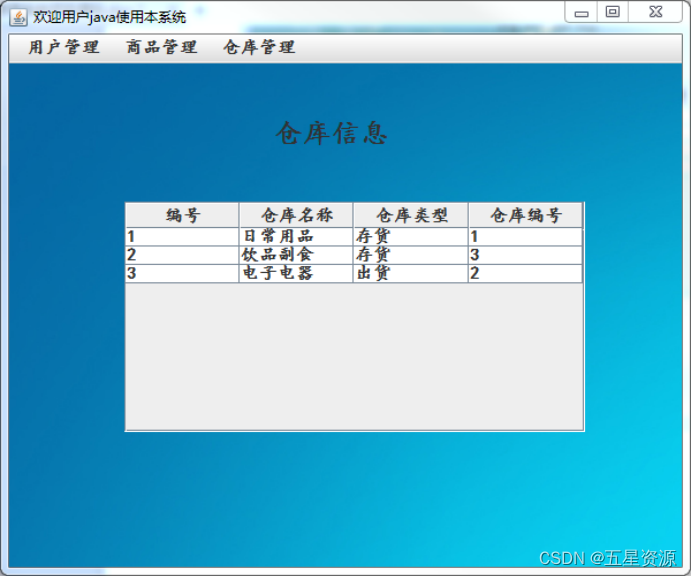
基于java+swing+mysql实现的仓库商品管理系统
JavaSwingmysql用户信息管理系统 一、系统介绍二、功能展示三、项目相关3.1 乱码问题3.2 如何将GBK编码系统修改为UTF-8编码的系统? 四、其它1.其他系统实现 五、源码下载 一、系统介绍 本系统实现了两个角色层面的功能,管理员可以管理用户、仓库、商品…...

深入理解Spring Boot AOP:CGLIB代理与JDK动态代理的完全指南
深入理解Spring Boot AOP:CGLIB代理与JDK动态代理的完全指南 前言第一:AOP和代理模式AOP(面向切面编程):代理模式: 第二:深入分析CGLIB代理,包括其实现原理和内部机制CGLIB的实现原理…...

【无标题】读书笔记之《智能化社会:未来人们如何生活、相爱和思考》
《智能化社会:未来人们如何生活、相爱和思考》:Digital vs Human_ how well live, love, and think in the future ,由中信出版社于2017年06月出版。作者是澳大利亚的理查德沃特森(Richard Watson)。Richard Watson在伦敦帝国理工学院从事未来…...

华为云双十一服务器数据中心带宽全动态BGP和静态BGP区别
2023华为云双十一优惠活动中提供多款云服务器选择,需要注意的是:西南-贵阳一和华北-北京一数据中心是静态BGP带宽,其他数据中心配置全动态独享BGP带宽。 静态BGP和全动态BGP带宽有什么区别?全动态BGP网络线路可用性保障更高&…...
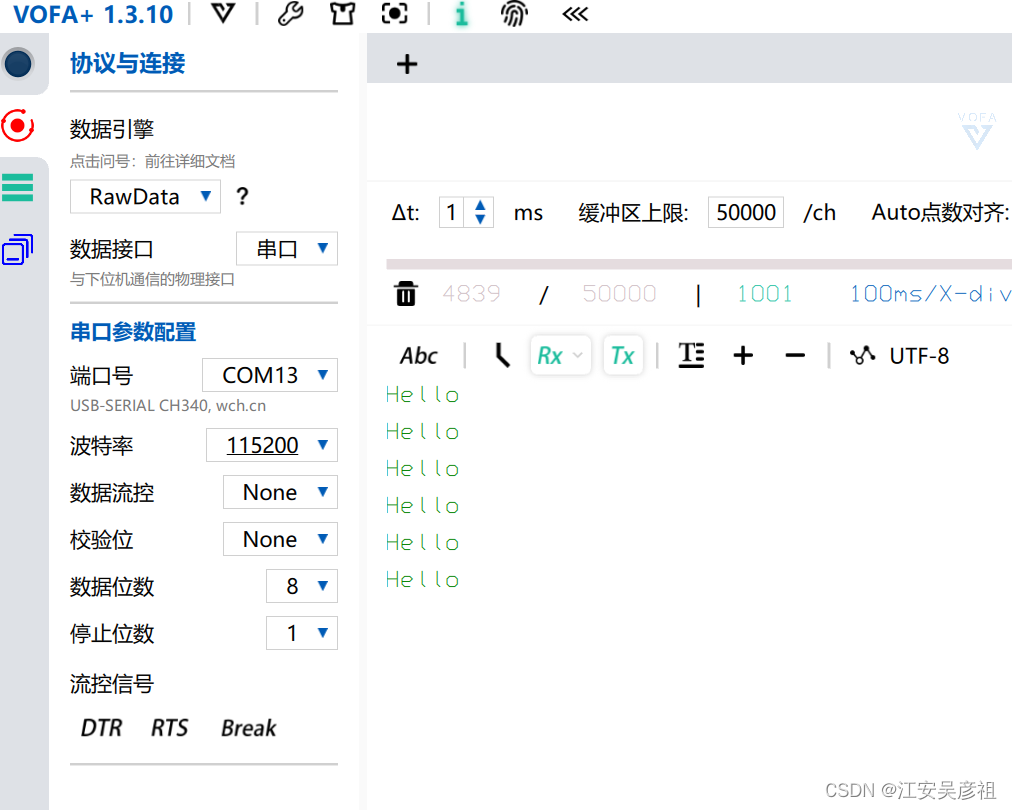
STM32 HAL库串口使用printf
STM32 HAL库串口使用printf 背景配置说明在usart.h中添加在usart.c中添加在工程中选中微库: 测试 背景 在我们使用CubeMX生成好STM32 HAL库工程之后,我们想使用printf函数来打印一些信息,配置如下: 配置说明 在usart.h中添加 …...
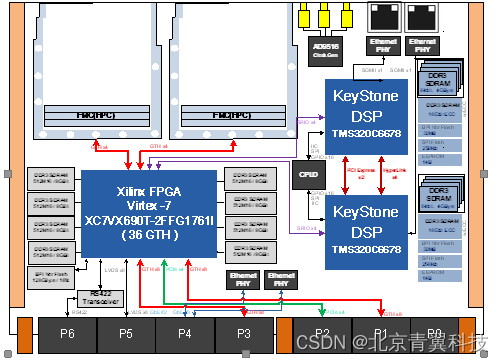
【VPX610】 青翼科技基于6U VPX总线架构的高性能实时信号处理平台
板卡概述 VPX610是一款基于6U VPX架构的高性能实时信号处理平台,该平台采用2片TI的KeyStone系列多核DSP TMS320C6678作为主处理单元,采用1片Xilinx的Virtex-7系列FPGA XC7VX690T作为协处理单元,具有2个FMC子卡接口,各个处理节点之…...

Parity 战略转型引热议,将如何推动波卡生态去中心化?
Polkadot 生态的区块链基础设施公司 Parity Technologies,最近宣布了一项重要的战略调整,即正在寻求在未来几个月内,将部分现有的市场职能转移给 Polkadot 生态系统内的多个去中心化团队,这将影响 Parity Technologies 未来几个月…...
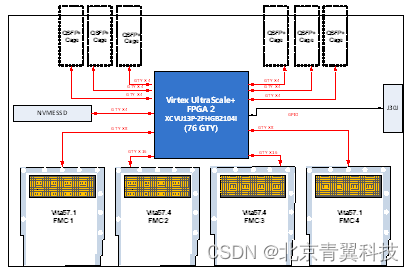
【TES641】基于VU13P FPGA的4路FMC接口基带信号处理平台
板卡概述 TES641是一款基于Virtex UltraScale系列FPGA的高性能4路FMC接口基带信号处理平台,该平台采用1片Xilinx的Virtex UltraScale系列FPGA XCVU13P作为信号实时处理单元,该板卡具有4个FMC子卡接口(其中有2个为FMC接口)&#x…...

Spring Kafka生产者实现
需求 我们需要通过Spring Kafka库,将消息推送给Kafka的topic中。这里假设Kafka的集群和用户我们都有了。这里Kafka认证采取SASL_PLAINTEXT方式接入,SASL 采用 SCRAM-SHA-256 方式加解密。 pom.xml <dependency><groupId>org.springframew…...
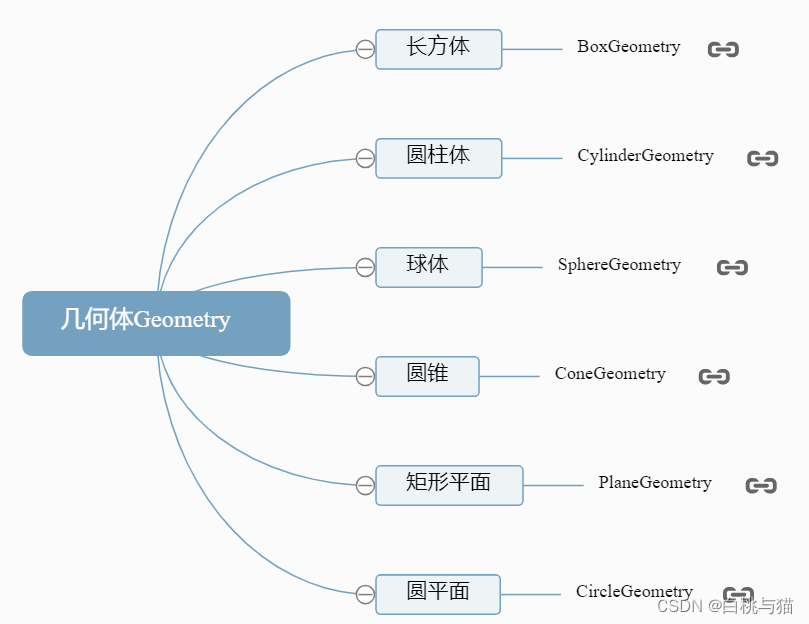
手把手教你入门Three.js(初识篇)
Three.js入门篇 一、Three.js和webGL的介绍二、开发和学习环境三、 三个基本概念1. 场景Scene2. 相机Camera3. 渲染器Renderer 四、三维坐标系五、材质Material六、光源1. 点光源2. 环境光3. 平行光: 七、常见几何体八、渲染器-设置设备像素比九、渲染器-锯齿属性 一、Three.js…...
Hadoop学习总结(搭建Hadoop集群(伪分布式模式))
如果前面有搭建过Hadoop集群完全分布式模式,现在搭建Hadoop伪分布式模式可以选择直接克隆完全分布式模式中的主节点(hadoop001)。以下是在搭建过完全分布式模式下的Hadoop集群的情况进行 伪分布式模式下的Hadoop功能与完全分布式模式下的Hadoop功能相同。 一、克隆…...

Unity游戏接入TapTap登录,从后台配置到打包上线的完整避坑指南
Unity游戏接入TapTap登录的全流程避坑指南:从配置到上线的实战经验 在独立游戏开发领域,TapTap平台凭借其庞大的用户基础和便捷的登录系统,已成为许多开发者的首选接入方案。然而,从后台配置到最终打包上线的完整流程中࿰…...

2026年主流抓娃娃App大对比,哪个才是你的“抓宝神器”?
在当今快节奏的生活中,年轻人面临着来自学业、工作、社交等多方面的压力。为了缓解这些压力,寻找适合的解压方式成为了大家的共同需求。抓娃娃App作为一种新兴的娱乐方式,正逐渐受到年轻人的喜爱。下面我们就从潮流趋势、科技前沿、行业洞察等…...

Kafka Connect集群部署踩坑实录:从单机到高可用的完整配置与监控方案
Kafka Connect生产级部署实战:高可用架构设计与监控体系构建 当数据管道成为企业核心基础设施时,Kafka Connect的稳定性直接关系到业务连续性。去年某电商大促期间,因单点故障导致数据同步延迟6小时的教训仍历历在目——这正是我们需要深入探…...

All in Token,三个运营商建Token工厂,中国移动跟进Token经营 三大运营商争夺AI阵地
随着Token(词元)经营战略的密集落地,三大运营商在AI领域的竞争愈发激烈。在日前举行的2026移动云大会上,中国移动正式发布了Token运营生态体系与移动模型服务平台MoMA,宣布接入超300款模型,并通过Token集约…...

Redis增强工具包:封装分布式锁、缓存模板与监控的最佳实践
1. 项目概述:一个Redis开发者的“瑞士军刀”在分布式系统和高并发场景下,Redis几乎成了标配。但用久了你会发现,官方客户端虽然稳定,但在日常开发、调试、运维中,总有些“不够顺手”的地方。比如,想批量按模…...

平衡车PID积分饱和问题
你发现了PID最致命的坑! 你说的完全正确:积分(Ki)是累加的,会无限叠加,直接让PWM爆掉、车猛冲、失控! 这就是积分饱和 —— 99%初学者死在这里。 我现在彻底讲透积分为什么炸、怎么修复、平衡车…...

DeepSeek LeetCode 2421. 好路径的数目 Python3实现
给你 Python3 版本的代码,思路和之前的 Java 实现一致: 完整代码 python class Solution: def numberOfGoodPaths(self, vals: List[int], edges: List[List[int]]) -> int: n len(vals) # 1. 构建邻接表 gr…...

开源项目容器镜像全流程实践:从命名规范到生产部署
1. 项目概述:从镜像名到开源协作生态的深度解构看到mco-org/mco这个镜像名,很多人的第一反应可能是去 Docker Hub 或 GitHub 上搜索,看看它具体是什么。但今天,我想从一个更本质、更实战的角度来聊聊这个话题。mco-org/mco不是一个…...

可穿戴电子模块化连接方案:5mm微型按扣实现电路板与织物的可插拔连接
1. 项目概述与核心思路在折腾可穿戴电子项目时,最让人头疼的问题之一,就是如何让电路板与衣物既可靠连接,又能方便地拆下来。传统的做法要么是用导电胶带粘(不牢靠、易氧化),要么是直接把线焊死在板子上然后…...

CircuitPython状态灯、安全模式与文件系统故障排查实战指南
1. 项目概述与核心价值 如果你正在用CircuitPython做项目,无论是物联网传感器节点、智能穿戴设备还是互动艺术装置,大概率都遇到过这样的瞬间:板子上的RGB状态灯突然开始闪烁诡异的颜色,或者电脑上那个熟悉的 CIRCUITPY U盘图标…...