统计学习方法 支持向量机(下)
文章目录
- 统计学习方法 支持向量机(下)
- 非线性支持向量机与和核函数
- 核技巧
- 正定核
- 常用核函数
- 非线性 SVM
- 序列最小最优化算法
- 两个变量二次规划的求解方法
- 变量的选择方法
- SMO 算法
统计学习方法 支持向量机(下)
学习李航的《统计学习方法》时,关于支持向量机的相关笔记。
非线性支持向量机与和核函数
核技巧
非线性分类问题:前面提到的两种 SVM 都是线性的。但有时分类问题是非线性的,需要 R n \R^n Rn 中的一个超曲面将正负类分开。此时我们可以使用核技巧,对训练实例进行非线性变换,映射过后变成了线性问题,就可以使用原来的方法求解:
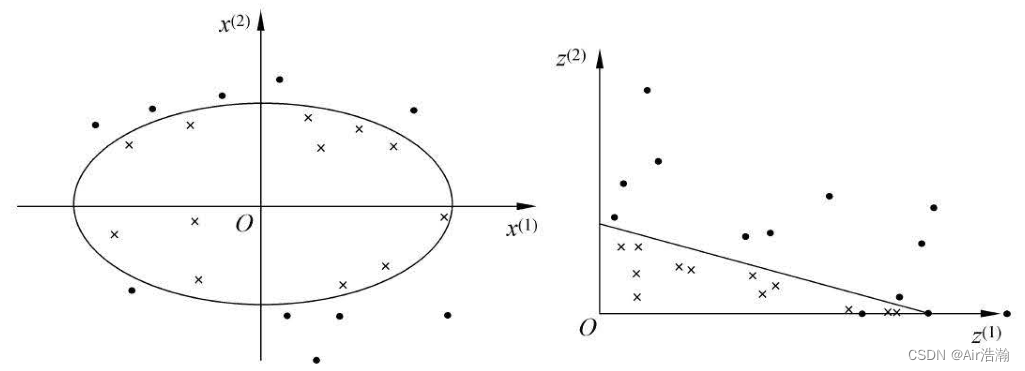
希尔伯特空间:希尔伯特空间是一个向量空间,它具有内积结构、完备性,通常是无限维度的,用于处理向量、函数或序列的数学空间。
- 内积结构允许定义向量之间的夹角和长度;
- 完备性表示空间中的柯西序列都有极限;
核函数:设 X \mathcal{X} X 是输入空间(欧氏空间 R n \R^n Rn 的子集或离散集合),又设 H \mathcal{H} H 为特征空间(希尔伯特空间),如果存在一个从 X \mathcal{X} X 到 H \mathcal{H} H 的映射:
ϕ ( x ) : X → H \phi(x): \, \mathcal{X}\to\mathcal{H} ϕ(x):X→H
函数 K ( x , z ) K(x,z) K(x,z) 代表映射后的内积函数,即对所有的 x x x , z ∈ X z\in\mathcal{X} z∈X ,满足条件:
K ( x , z ) = ϕ ( x ) ⋅ ϕ ( z ) K(x,z)=\phi(x)\cdot \phi(z) K(x,z)=ϕ(x)⋅ϕ(z)
则称 K ( x , z ) K(x,z) K(x,z) 为核函数, ϕ ( x ) \phi(x) ϕ(x) 为映射函数。我们往往不需要直接定义 ϕ ( x ) \phi(x) ϕ(x) 核特征空间,只需要定义满足条件的 K ( x , z ) K(x,z) K(x,z) (满足线性性、对称性和正定性),就可以把训练实例映射到某一个高维空间,就有可能使得数据集变为线性的。
核函数在支持向量机中的应用:我们所要求解的对偶问题为:
W ( α ) = 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ( x i ⋅ x j ) − ∑ i = 1 N α i W(\alpha)=\frac{1}{2}\sum\limits_{i=1}^{N}\sum\limits_{j=1}^{N}\alpha_i\alpha_jy_iy_j(x_i\cdot x_j)-\sum\limits_{i=1}^{N}\alpha_i W(α)=21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−i=1∑Nαi
并且最终得到的分离超平面为:
f ( x ) = sign ( ∑ i = 1 N α i ∗ y i ( x i ⋅ x ) + b ∗ ) f(x)=\text{sign}\left(\sum\limits_{i=1}^{N}\alpha_i^{\ast}y_i(x_i\cdot x)+b^\ast\right) f(x)=sign(i=1∑Nαi∗yi(xi⋅x)+b∗)
也就是说,所有训练实例 x i x_i xi 在算法中都以内积的形式出现,因此我们可以直接定义核函数 K ( x , z ) K(x,z) K(x,z) ,将问题转化为:
W ( α ) = 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j K ( x i , x j ) − ∑ i = 1 N α i W(\alpha)=\frac{1}{2}\sum\limits_{i=1}^{N}\sum\limits_{j=1}^{N}\alpha_i\alpha_jy_iy_jK(x_i, x_j)-\sum\limits_{i=1}^{N}\alpha_i W(α)=21i=1∑Nj=1∑NαiαjyiyjK(xi,xj)−i=1∑Nαi
超平面的方程可以变为:
f ( x ) = sign ( ∑ i = 1 N α i ∗ y i K ( x i , x ) + b ∗ ) f(x)=\text{sign}\left(\sum\limits_{i=1}^{N}\alpha_i^{\ast}y_iK(x_i, x)+b^\ast\right) f(x)=sign(i=1∑Nαi∗yiK(xi,x)+b∗)
核函数的选择往往是基于领域知识、经验和实验验证的。
正定核
核函数代表内积运算,需要满足线性性、对称性和正定性。通常所说的核函数就是正定核函数。因此,对于一个函数 K ( x , z ) K(x,z) K(x,z) 是否能被用作核函数,需要满足以下条件:
Th 7.5(正定核函数的充要条件):设 K : X × X → R K:\,\mathcal{X}\times\mathcal{X}\to\R K:X×X→R 是对称函数,则 K ( x , z ) K(x,z) K(x,z) 为正定核函数的充分必要条件是:对任意 x i ∈ X x_i\in \mathcal{X} xi∈X ( i = 1 , 2 , ⋯ , m i=1,2,\cdots,m i=1,2,⋯,m) , K ( x , z ) K(x,z) K(x,z) 对应的 Gram 矩阵:
K = [ K ( x i , x j ) ] m × m K=[K(x_i,x_j)]_{m\times m} K=[K(xi,xj)]m×m
是半正定矩阵。
证明必要性:由于 K ( x , z ) K(x,z) K(x,z) 是 X × X \mathcal{X}\times\mathcal{X} X×X 上的正定核,所以存在从 X \mathcal{X} X 到希尔伯特空间 H \mathcal{H} H 的映射 ϕ ( x ) \phi(x) ϕ(x) ,使得:
K ( x , z ) = ϕ ( x ) ⋅ ϕ ( z ) K(x,z)=\phi(x) \cdot \phi(z) K(x,z)=ϕ(x)⋅ϕ(z)
于是,对于任意 x i ∈ X x_i\in \mathcal{X} xi∈X ( i = 1 , 2 , ⋯ , m i=1,2,\cdots,m i=1,2,⋯,m)的 K ( x , z ) K(x,z) K(x,z) 的 Gram 矩阵 [ K ( x i , x j ) ] m × m [K(x_i,x_j)]_{m\times m} [K(xi,xj)]m×m ,我们要证明该 Gram 矩阵是半正定的,只需要证明其二次型是大于等于 0 的(因为 Gram 矩阵已经对称了)。
对于任意 c = [ c 1 , c 2 , ⋯ , c m ] T ∈ R m c=[c_1,c_2,\cdots,c_m]^\text{T} \in \R^m c=[c1,c2,⋯,cm]T∈Rm ,有:
c T K c = ∑ i , j = 1 m c i c j K ( x i , x j ) = ∑ i , j = 1 m c i c j ( ϕ ( x i ) ⋅ ϕ ( x j ) ) = ( ∑ i c i ϕ ( x i ) ) ⋅ ( ∑ j c j ϕ ( x j ) ) = ∥ ∑ i c i ϕ ( x i ) ∥ 2 ≥ 0 \begin{aligned} c^TKc =&\, \sum\limits_{i,j=1}^{m}c_ic_jK(x_i,x_j) \\ =&\, \sum\limits_{i,j=1}^{m}c_ic_j(\phi(x_i)\cdot \phi(x_j)) \\ =&\, \left(\sum\limits_{i}c_i\phi(x_i)\right)\cdot\left(\sum\limits_{j}c_j\phi(x_j)\right) \\ =&\, \left\| \sum\limits_{i}c_i\phi(x_i) \right\|^2 \geq 0 \end{aligned} cTKc====i,j=1∑mcicjK(xi,xj)i,j=1∑mcicj(ϕ(xi)⋅ϕ(xj))(i∑ciϕ(xi))⋅(j∑cjϕ(xj)) i∑ciϕ(xi) 2≥0
因此该 Gram 矩阵是半正定的。
证明充分性:我们需要依照这样的 K ( x , z ) K(x,z) K(x,z) ,去构造一个希尔伯特空间。分为三步:
- 定义映射,构成向量空间:首先定义映射:
ϕ : x → K ( ⋅ , x ) \phi: x\to K(\cdot, x) ϕ:x→K(⋅,x)
这里 ⋅ \cdot ⋅ 是一个占位符,表示一个参数。就是说 ϕ \phi ϕ 把 x x x 映射成了一个函数 K ( ⋅ , x ) K(\cdot,x) K(⋅,x) ,函数的参数为 ⋅ \cdot ⋅ ;根据这个映射,我们定义线性组合:
f ( ⋅ ) = ∑ i = 1 m α i K ( ⋅ , x i ) f(\cdot)=\sum\limits_{i=1}^m \alpha_i K(\cdot, x_i) f(⋅)=i=1∑mαiK(⋅,xi)
考虑由线性组合为元素构成的集合 S S S ,它对加法和数乘运算是封闭的,所以 S S S 构成一个向量空间。( S S S 中的每个元素都是函数)
- 在 S S S 上定义内积,使其成为内积空间:对于任意 f f f , g ∈ S g \,\in S g∈S :
f ( ⋅ ) = ∑ i = 1 m α i K ( ⋅ , x i ) g ( ⋅ ) = ∑ j = 1 l β j K ( ⋅ , z j ) \begin{aligned} f(\cdot)=&\, \sum\limits_{i=1}^m \alpha_i K(\cdot, x_i) \\ g(\cdot)=&\, \sum\limits_{j=1}^l \beta_j K(\cdot, z_j) \end{aligned} f(⋅)=g(⋅)=i=1∑mαiK(⋅,xi)j=1∑lβjK(⋅,zj)
在 S S S 上定义二元运算 ∗ \ast ∗ :
f ∗ g = ∑ i = 1 m ∑ j = 1 l α i β j K ( x i , z j ) f\ast g=\sum\limits_{i=1}^m\sum\limits_{j=1}^l \alpha_i\beta_jK(x_i,z_j) f∗g=i=1∑mj=1∑lαiβjK(xi,zj)
要证明 ∗ \ast ∗ 是空间 S S S 中的内积,需要证明线性性、对称性和正定性;线性性和对称性是挺明显的,现在证明正定性,即:
f ∗ f ≥ 0 ; f ∗ f = 0 ⟺ f = 0 f\ast f \geq 0;\quad f\ast f=0 \iff f=0 f∗f≥0;f∗f=0⟺f=0
有:
f ∗ f = ∑ i , j = 1 m α i α j K ( x i , x j ) f\ast f=\sum\limits_{i,j=1}^m\alpha_i\alpha_j K(x_i,x_j) f∗f=i,j=1∑mαiαjK(xi,xj)
由 Gram 矩阵的半正定性得,这玩意儿 f ∗ f ≥ 0 f\ast f \geq 0 f∗f≥0 ;对于 f ∗ f = 0 ⟺ f = 0 f\ast f=0 \iff f=0 f∗f=0⟺f=0 ,充分性显然,下面证明必要性。
首先证明 Cauchy-Shwarz 不等式,设 f f f , g ∈ S g \,\in S g∈S , λ ∈ R \lambda \in \R λ∈R ,则 f + λ g ∈ S f+\lambda g \in S f+λg∈S ,有:
( f + λ g ) ∗ f + λ g ≥ 0 ⇒ f ∗ f + 2 λ ( f ∗ g ) + λ 2 ( g ∗ g ) ≥ 0 \begin{aligned} (f+\lambda g)\ast f+\lambda g \geq 0 \\ \Rightarrow f\ast f+2\lambda(f\ast g)+\lambda^2(g\ast g) \geq 0 \end{aligned} (f+λg)∗f+λg≥0⇒f∗f+2λ(f∗g)+λ2(g∗g)≥0
由于非负,因此判别式小于等于零,有:
( f ∗ g ) 2 − ( f ∗ f ) ( g ∗ g ) ≤ 0 (f\ast g)^2-(f\ast f)(g\ast g) \leq 0 (f∗g)2−(f∗f)(g∗g)≤0
于是得到柯西不等式:
∣ f ∗ g ∣ 2 ≤ ( f ∗ f ) ( g ∗ g ) |f\ast g|^2 \leq (f\ast f)(g\ast g) ∣f∗g∣2≤(f∗f)(g∗g)
利用柯西不等式,我们可以得到,对于任意 x ∈ X x\in\mathcal{X} x∈X ,有:
K ( ⋅ , x ) ∗ f = ∑ i = 1 m α i K ( x , x i ) = f ( x ) K(\cdot,x)\ast f=\sum\limits_{i=1}^m \alpha_i K(x,x_i)=f(x) K(⋅,x)∗f=i=1∑mαiK(x,xi)=f(x)
于是:
∣ f ( x ) ∣ 2 = ∣ K ( ⋅ , x ) ∗ f ∣ 2 ≤ ( K ( ⋅ , x ) ∗ K ( ⋅ , x ) ) ( f ∗ f ) = K ( x , x ) ( f ∗ f ) |f(x)|^2=|K(\cdot,x)\ast f|^2 \leq (K(\cdot,x)\ast K(\cdot,x))(f\ast f)=K(x,x)(f\ast f) ∣f(x)∣2=∣K(⋅,x)∗f∣2≤(K(⋅,x)∗K(⋅,x))(f∗f)=K(x,x)(f∗f)
即:
∣ f ( x ) ∣ 2 ≤ K ( x , x ) ( f ∗ f ) |f(x)|^2\leq K(x,x)(f\ast f) ∣f(x)∣2≤K(x,x)(f∗f)
于是,当 f ∗ f = 0 f\ast f=0 f∗f=0 时,对于任意 x x x 都有 f ( x ) = 0 f(x)=0 f(x)=0 ,因此 f = 0 f=0 f=0 ;
至此,我们证明了 ∗ \ast ∗ 是 S S S 中的内积运算, S S S 是一个内积空间,我们以仍然以 ⋅ \mathcal{\cdot} ⋅ 表示 ∗ \ast ∗ ,这是比较常用的内积符号(但是和前面的占位符不一样)。
- 将内积空间 S S S 完备为希尔伯特空间:由前面内积的定义可以得到范数:
∥ f ∥ = f ⋅ f \|f\|=\sqrt{f\cdot f} ∥f∥=f⋅f
因此, S S S 是一个赋范向量空间。由泛函分析的某些理论可得,对于不完备的赋范向量空间 S S S ,一定可以使之完备化(虽然我也不知道为啥),由此可以得到完备的赋范向量空间 H \mathcal{H} H ,就是希尔伯特空间。
至此,我们证明了正定核的充分条件。正定核的定义也可以写为:
正定核的等价定义:设 X ⊂ R n \mathcal{X}\subset \R^n X⊂Rn , K ( x , z ) K(x,z) K(x,z) 是定义在 X × X \mathcal{X}\times\mathcal{X} X×X 上的对称函数,如果对任意 x i ∈ X x_i\in\mathcal{X} xi∈X , i = 1 , 2 , ⋯ , m i=1,2,\cdots,m i=1,2,⋯,m , K ( x , z ) K(x,z) K(x,z) 对应的 Gram 矩阵:
K = [ K ( x i , x j ) ] m × m K=[K(x_i,x_j)]_{m\times m} K=[K(xi,xj)]m×m
是半正定矩阵,则称 K ( x , z ) K(x,z) K(x,z) 是正定核。
常用核函数
多项式核函数:对应的支持向量机是一个 p p p 此多项式分类器:
K ( x , z ) = ( x ⋅ z + 1 ) p K(x,z)=(x\cdot z+1)^p K(x,z)=(x⋅z+1)p
分类决策函数为:
f ( x ) = sign ( ∑ i = 1 N α i ∗ y i ( x i ⋅ x + 1 ) p + b ∗ ) f(x)=\text{sign}\left( \sum\limits_{i=1}^{N}\alpha_i^\ast y_i(x_i\cdot x+1)^p+b^\ast \right) f(x)=sign(i=1∑Nαi∗yi(xi⋅x+1)p+b∗)
高斯核函数:使用高斯径向函数(RBF):
K ( x , z ) = exp ( − ∥ x − z ∥ 2 2 σ 2 ) K(x,z)=\text{exp}\left(-\frac{\|x-z\|^2}{2\sigma^2} \right) K(x,z)=exp(−2σ2∥x−z∥2)
分类决策函数为:
f ( x ) = sign ( ∑ i = 1 N α i ∗ y i exp ( − ∥ x − x i ∥ 2 2 σ 2 ) + b ∗ ) f(x)=\text{sign}\left( \sum\limits_{i=1}^{N}\alpha_i^\ast y_i\text{exp}\left(-\frac{\|x-x_i\|^2}{2\sigma^2} \right)+b^\ast \right) f(x)=sign(i=1∑Nαi∗yiexp(−2σ2∥x−xi∥2)+b∗)
字符串核函数:定义有限字符表 Σ \Sigma Σ :
-
字符串 s s s 是从 Σ \Sigma Σ 中取出有限个字符的序列,其长度表示为 ∣ s ∣ |s| ∣s∣ 。
-
两个字符串 s s s 和 t t t 的连接记为 s t st st
-
所有长度为 n n n 的字符串集合记作 Σ n \Sigma^n Σn ;
-
所有字符串的集合记作 Σ ∗ = ⋃ i = 1 ∞ Σ i \Sigma^\ast =\bigcup\limits_{i=1}^\infty \Sigma^i Σ∗=i=1⋃∞Σi ;
给定一个下标序列 i = ( i 1 , i 2 , ⋯ , i ∣ u ∣ ) i=(i_1,i_2,\cdots,i_{|u|}) i=(i1,i2,⋯,i∣u∣) ,其中 1 ≤ i 1 < i 2 < ⋯ < i ∣ u ∣ ≤ ∣ s ∣ 1\leq i_1\lt i_2 \lt \cdots \lt i_{|u|} \leq |s| 1≤i1<i2<⋯<i∣u∣≤∣s∣ ,考虑 s s s 字符串的子串 u = s [ i ] u=s[i] u=s[i] ,定义 l ( i ) = i ∣ u ∣ − i 1 + 1 l(i)=i_{|u|}-i_1+1 l(i)=i∣u∣−i1+1 ,代表下标的跨度。若 i i i 是连续的,则 l ( i ) = ∣ u ∣ l(i)=|u| l(i)=∣u∣ ,否则 l ( i ) > ∣ u ∣ l(i)\gt |u| l(i)>∣u∣ 。
设 S S S 是长度大于等于 n n n 的字符串的集合,设 s ∈ S s\in S s∈S 。先建立字符串集合 S S S 到特征空间 H n = R ∣ Σ n ∣ \mathcal{H}_{n}=\R^{|\Sigma^n|} Hn=R∣Σn∣ 的映射 ϕ n ( s ) \phi_n(s) ϕn(s) 。其中 ∣ Σ n ∣ |\Sigma^n| ∣Σn∣ 代表集合 Σ n \Sigma^n Σn 的基数, R ∣ Σ n ∣ \R^{|\Sigma^n|} R∣Σn∣ 中向量的每一维对应某个字符串 u ∈ Σ n u\in \Sigma^n u∈Σn 。
定义 R ∣ Σ n ∣ \R^{|\Sigma^n|} R∣Σn∣ 中向量在 u u u 维上的取值为:
[ ϕ n ( s ) ] u = ∑ i : s ( i ) = u λ l ( i ) [\phi_n(s)]_u=\sum\limits_{i:s(i)=u}\lambda^{l(i)} [ϕn(s)]u=i:s(i)=u∑λl(i)
这里 0 < λ ≤ 1 0\lt \lambda \leq 1 0<λ≤1 是一个衰减参数,求和表示在 s s s 中所有为 u u u 的子串上进行;
例:对于英文字符串, n = 3 n=3 n=3 ,现将 S S S 映射到 H 3 \mathcal{H}_3 H3 。设 H 3 \mathcal{H}_3 H3 中的向量的第一维对应于字符串 asd ,则对于两个字符串 Nasdaq 和 lass das ,它们在第一维上的取值分别为:
- [ ϕ 3 ( Nasdaq ) ] asd = λ 3 [\phi_3(\text{Nasdaq})]_{\text{asd}}=\lambda^3 [ϕ3(Nasdaq)]asd=λ3 :因为
Nasdaq只有一个子串为asd,下标为 ( 2 , 3 , 4 ) (2,3,4) (2,3,4) ,所以 l ( ( 2 , 3 , 4 ) ) = 3 l((2,3,4))=3 l((2,3,4))=3 ; - [ ϕ 3 ( lass das ) ] asd = 2 λ 5 [\phi_3(\text{lass das})]_{\text{asd}}=2\lambda^5 [ϕ3(lass das)]asd=2λ5 :
lass das有两个子串为asd,且对应的l(i)均为 5;
我们定义字符串 s s s 和 t t t 的核函数为:
K n ( s , t ) = ∑ u ∈ Σ n [ ϕ n ( s ) ] u [ ϕ n ( t ) ] u = ∑ u ∈ Σ n ∑ ( i , j ) : s ( i ) = t ( j ) = u λ l ( i ) λ l ( j ) \begin{aligned} K_n(s,t)=&\,\sum\limits_{u\in\Sigma^n}[\phi_n(s)]_u[\phi_n(t)]_u \\ =&\, \sum\limits_{u\in\Sigma^n}\sum\limits_{(i,j):s(i)=t(j)=u}\lambda^{l(i)}\lambda^{l(j)} \end{aligned} Kn(s,t)==u∈Σn∑[ϕn(s)]u[ϕn(t)]uu∈Σn∑(i,j):s(i)=t(j)=u∑λl(i)λl(j)
可以理解为,两个字符串共同子串越多,二者就越相似。字符串核函数可以由动态规划来快速计算。
非线性 SVM
非线性支持向量机:给定非线性分类训练集,通过核函数与软间隔最大化,或对应的对偶最优化问题,学习得到的分类决策函数:
f ( x ) = sign ( ∑ i = 1 N α i ∗ y i K ( x , x i ) + b ∗ ) f(x)=\text{sign}\left( \sum\limits_{i=1}^{N}\alpha_i^\ast y_iK(x,x_i)+b^\ast \right) f(x)=sign(i=1∑Nαi∗yiK(x,xi)+b∗)
称为非线性支持向量机, K ( x , z ) K(x,z) K(x,z) 是正定核函数。
算法:非线性支持向量机学习算法
- 输入:线性可分训练数据集 T = { ( x 1 , t 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } T=\set{(x_1,t_1),(x_2,y_2),\cdots,(x_N,y_N)} T={(x1,t1),(x2,y2),⋯,(xN,yN)} ,其中 x i ∈ X ⊆ R n x_i\in\mathcal{X}\subseteq \R^n xi∈X⊆Rn , y i ∈ Y = { 1 , − 1 } y_i\in\mathcal{Y}=\set{1,\,-1} yi∈Y={1,−1}
- 输出:分类决策函数
- 选取适当的核函数 K ( x , z ) K(x,z) K(x,z) 和超参数 C C C ,构造求解最优化问题:
min α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j K ( x i , x j ) − ∑ i = 1 N α i s.t. ∑ i = 1 N α i y i = 0 α i ≥ 0 , i = 1 , 2 , ⋯ , N \begin{aligned} \min_{\alpha}&\, \frac{1}{2}\sum\limits_{i=1}^{N}\sum\limits_{j=1}^{N}\alpha_i\alpha_jy_iy_jK(x_i, x_j)-\sum\limits_{i=1}^{N}\alpha_i \\ \text{s.t.}&\,\, \sum_{i=1}^{N}\alpha_iy_i=0 \\ &\,\, \alpha_i\geq 0,\quad i=1,2,\cdots,N \end{aligned} αmins.t.21i=1∑Nj=1∑NαiαjyiyjK(xi,xj)−i=1∑Nαii=1∑Nαiyi=0αi≥0,i=1,2,⋯,N
得到最优解 α ∗ \alpha^\ast α∗ ;
-
选择 α ∗ \alpha^\ast α∗ 的一个正分量 α j ∗ \alpha_j^\ast αj∗ ,计算:
b ∗ = y j − ∑ i = 1 N α i ∗ y i ( x i ⋅ x j ) b^\ast=y_j-\sum\limits_{i=1}^{N}\alpha_i^\ast y_i(x_i\cdot x_j) b∗=yj−i=1∑Nαi∗yi(xi⋅xj) -
构造决策函数:
f ( x ) = sign ( ∑ i = 1 N α i ∗ y i K ( x , x i ) + b ∗ ) f(x)=\text{sign}\left( \sum\limits_{i=1}^{N}\alpha_i^\ast y_iK(x,x_i)+b^\ast \right) f(x)=sign(i=1∑Nαi∗yiK(x,xi)+b∗)
当 K ( x , z ) K(x,z) K(x,z) 是正定核函数时,该问题是凸二次规划问题,解是存在的。
序列最小最优化算法
我们在求解对偶的凸二次规划问题时,当样本量很大时, 一般的最优化算法会变得很低效:
min α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j K ( x i , x j ) − ∑ i = 1 N α i s.t. ∑ i = 1 N α i y i = 0 0 ≤ α i ≤ C , i = 1 , 2 , ⋯ , N \begin{aligned} \min_{\alpha}&\, \frac{1}{2}\sum\limits_{i=1}^{N}\sum\limits_{j=1}^{N}\alpha_i\alpha_jy_iy_jK(x_i, x_j)-\sum\limits_{i=1}^{N}\alpha_i \\ \text{s.t.}&\,\, \sum_{i=1}^{N}\alpha_iy_i=0 \\ &\,\, 0\leq\alpha_i\leq C,\quad i=1,2,\cdots,N \end{aligned} αmins.t.21i=1∑Nj=1∑NαiαjyiyjK(xi,xj)−i=1∑Nαii=1∑Nαiyi=00≤αi≤C,i=1,2,⋯,N
SMO(序列最小最优化)算法是一种启发式算法,思路为:
- 如果所有变量的解都满足 KKT 条件,则解就得到了;
- 否则,选取两个变量,固定其他变量,针对这两个变量构建一个二次规划问题。两个变量的二次规划问题可以直接通过解析方法求解。这个二次规划问题关于这两个变量的解应当比原来更接近原始二次规划问题的解;
- 子问题有两个变量:一个是违反 KKT 条件最严重的那个,另一个由约束条件自动确定;
- 通过不断地将原问题分解为子问题,并且求解子问题,从而迭代地达到求解原问题的目的。
注意,子问题的两个变量只有一个是自由变量,例如,假设 α 1 \alpha_1 α1 和 α 2 \alpha_2 α2 为变量,其余 α \alpha α 固定,则可以得到:
α 1 = − y 1 ∑ i = 2 N α i y i \alpha_1=-y_1\sum\limits_{i=2}^N\alpha_iy_i α1=−y1i=2∑Nαiyi
如果 α 2 \alpha_2 α2 确定,则 α 1 \alpha_1 α1 也随之确定。
SMO 算法包含两个部分:两个变量二次规划问题的解析解和选择变量的启发式方法。
两个变量二次规划的求解方法
两个变量二次规划问题:同样地,假设 α 1 \alpha_1 α1 和 α 2 \alpha_2 α2 为变量,其余 α \alpha α 固定(我们将 α 2 \alpha_2 α2 看作自由变量),则可以得到(注意 y i 2 = 1 y_i^2=1 yi2=1):
min α 1 , α 2 W ( α 1 , α 2 ) = 1 2 K 11 α 1 2 + 1 2 K 2 α 2 2 + y 1 y 2 K 12 α 1 α 2 − ( α 1 + α 2 ) + y 1 α 1 ∑ i = 3 N y i α i K i 1 + y 2 α 2 ∑ i = 3 N y i α i K i 2 s.t. α 1 y 1 + α 2 y 2 = − ∑ i = 3 N y i α i = ζ 0 ≤ α i ≤ C , i = 1 , 2 \begin{aligned} \min_{\alpha_1,\alpha_2}&\, W(\alpha_1,\alpha_2) =\frac{1}{2}K_{11}\alpha_1^2+\frac{1}{2}K_{2}\alpha_2^2+y_1y_2K_{12}\alpha_1\alpha_2 \\ &\quad\quad\quad\quad\quad-(\alpha_1+\alpha_2) +y_1\alpha_1\sum\limits_{i=3}^Ny_i\alpha_iK_{i1} +y_2\alpha_2\sum\limits_{i=3}^Ny_i\alpha_iK_{i2} \\ \text{s.t.}&\,\, \alpha_1y_1+\alpha_2y_2=-\sum\limits_{i=3}^{N}y_i\alpha_i=\zeta \\ &\,\, 0\leq\alpha_i\leq C,\quad i=1,2 \end{aligned} α1,α2mins.t.W(α1,α2)=21K11α12+21K2α22+y1y2K12α1α2−(α1+α2)+y1α1i=3∑NyiαiKi1+y2α2i=3∑NyiαiKi2α1y1+α2y2=−i=3∑Nyiαi=ζ0≤αi≤C,i=1,2
其中 K i j = K ( x i , x j ) K_{ij}=K(x_i,x_j) Kij=K(xi,xj) , ζ \zeta ζ 为常数;
约束条件:注意到 y i y_i yi 只有 ± 1 \pm 1 ±1 的取值,因此约束有两种情况( α 2 \alpha_2 α2 是纵坐标, α 1 \alpha_1 α1 是横坐标):
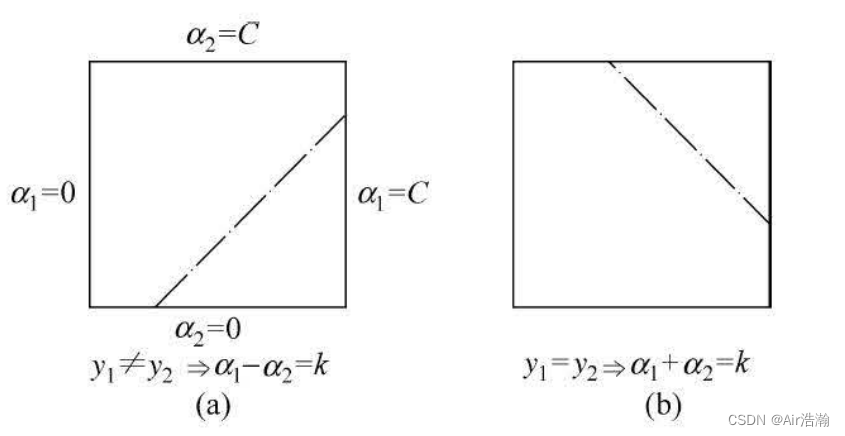
约束是 [ 0 , C ] [0,\,C] [0,C] 的正方形内的一条对角线,方程为 α 2 − α 2 old + y 1 y 2 ( α 1 − α 1 old ) = 0 \alpha_2-\alpha_2^{\text{old}}+y_1y_2(\alpha_1-\alpha_1^{\text{old}})=0 α2−α2old+y1y2(α1−α1old)=0 ;
假设初始可行解为 α 1 old \alpha_1^{\text{old}} α1old , α 2 old \alpha_2^{\text{old}} α2old ,最优解为 α 1 new \alpha_1^{\text{new}} α1new , α 2 new \alpha_2^{\text{new}} α2new ;并且假设在沿着约束方向未经 0 ≤ α i ≤ C 0\leq\alpha_i\leq C 0≤αi≤C 剪辑时 α 2 \alpha_2 α2 的最优解为 α 2 new unc \alpha_2^{\text{new unc}} α2new unc 。
最优解 α 2 new \alpha_2^{\text{new}} α2new 的取值范围需满足条件:
L ≤ α 2 new ≤ H L\leq\alpha_2^{\text{new}}\leq H L≤α2new≤H
L L L 和 H H H 就是对角线段的端点,如果 y 1 ≠ y 2 y_1\not=y_2 y1=y2 ,则直线的表达式为 α 2 = α 1 + α 2 old − α 1 old \alpha_2=\alpha_1+\alpha_2^{\text{old}}-\alpha_1^{\text{old}} α2=α1+α2old−α1old :
L = max ( 0 , α 2 old − α 1 old ) , H = min ( C , C + α 2 old − α 1 old ) L=\max(0,\,\alpha_2^{\text{old}}-\alpha_1^{\text{old}}),\quad H=\min(C,\,C+\alpha_2^{\text{old}}-\alpha_1^{\text{old}}) L=max(0,α2old−α1old),H=min(C,C+α2old−α1old)
如果 y 1 = y 2 y_1=y_2 y1=y2 ,则直线的表达式为 α 2 = − α 1 + α 2 old + α 1 old \alpha_2=-\alpha_1+\alpha_2^{\text{old}}+\alpha_1^{\text{old}} α2=−α1+α2old+α1old :
L = max ( 0 , α 2 old + α 1 old − C ) , H = min ( C , α 2 old + α 1 old ) L=\max(0,\,\alpha_2^{\text{old}}+\alpha_1^{\text{old}}-C),\quad H=\min(C,\,\alpha_2^{\text{old}}+\alpha_1^{\text{old}}) L=max(0,α2old+α1old−C),H=min(C,α2old+α1old)
求解 α 2 new \alpha_2^{\text{new}} α2new:我们的思想是,先求得 α 2 new unc \alpha_2^{\text{new unc}} α2new unc ,再使用 [ L , H ] [L,\,H] [L,H] 剪辑得到 α 2 new \alpha_2^{\text{new}} α2new :
α 2 new = { H , α 2 new unc > H α 2 new unc , L ≤ α 2 new unc ≤ H L , α 2 new unc < L \alpha_2^{\text{new}}=\left\{ \begin{array}{ll} H, & \alpha_2^{\text{new unc}} \gt H \\ \alpha_2^{\text{new unc}}, & L \leq \alpha_2^{\text{new unc}} \leq H \\ L, & \alpha_2^{\text{new unc}} \lt L \end{array} \right. α2new=⎩ ⎨ ⎧H,α2new unc,L,α2new unc>HL≤α2new unc≤Hα2new unc<L
而 α 1 new \alpha_1^{\text{new}} α1new 为:
α 1 new = α 1 old − y 1 y 2 ( α 2 new − α 2 old ) \alpha_1^{\text{new}}=\alpha_1^{\text{old}}-y_1y_2(\alpha_2^{\text{new}}-\alpha_2^{\text{old}}) α1new=α1old−y1y2(α2new−α2old)
求解 α 2 new unc \alpha_2^{\text{new unc}} α2new unc:记:
g ( x ) = ∑ i = 1 N α i old y i K ( x i , x ) + b old g(x)=\sum\limits_{i=1}^N \alpha_i^{\text{old}}y_iK(x_i,x)+b^{\text{old}} g(x)=i=1∑NαioldyiK(xi,x)+bold
其中 b old b^{\text{old}} bold 是以当前迭代到的可行解 α old \alpha^{\text{old}} αold 计算得到的 b b b ; g ( x ) g(x) g(x) 其实就是以当前迭代到的可行解 α old \alpha^{\text{old}} αold 计算得到的去掉符号函数的决策函数;令:
E i = g ( x i ) − y i = ( ∑ j = 1 N α j old y j K ( x j , x i ) + b old ) − y i , i = 1 , 2 E_i=g(x_i)-y_i=\left( \sum\limits_{j=1}^N \alpha_j^{\text{old}}y_jK(x_j,x_i)+b^{\text{old}} \right)-y_i,\quad i=1,2 Ei=g(xi)−yi=(j=1∑NαjoldyjK(xj,xi)+bold)−yi,i=1,2
再引入记号( Φ \Phi Φ 为核函数 K ( x , z ) K(x,z) K(x,z) 所对应的输入空间到特征空间的映射):
η = K 11 + K 22 − 2 K 12 = ∥ Φ ( x 1 ) − Φ ( x 2 ) ∥ 2 \eta=K_{11}+K_{22}-2K_{12}=\|\Phi(x_1)-\Phi(x_2)\|^2 η=K11+K22−2K12=∥Φ(x1)−Φ(x2)∥2
则可以得到两个变量二次规划问题在沿着约束方向未经剪辑时 α 2 \alpha_2 α2 的最优解为:
α 2 new unc = α 2 old + y 2 ( E 1 − E 2 ) η \alpha_2^{\text{new unc}}=\alpha_2^{\text{old}}+\frac{y_2(E_1-E_2)}{\eta} α2new unc=α2old+ηy2(E1−E2)
证明:引进记号(为了方便书写,去掉了 old \text{old} old 上标。没有特殊说明都是 old \text{old} old):
v i = ∑ j = 3 N α j y j K ( x i , x j ) = g ( x i ) − ∑ j = 1 2 α j y j K ( x i , x j ) − b , i = 1 , 2 v_i=\sum\limits_{j=3}^N \alpha_jy_j K(x_i,x_j)=g(x_i)-\sum\limits_{j=1}^2 \alpha_jy_jK(x_i,x_j)-b,\quad i=1,2 vi=j=3∑NαjyjK(xi,xj)=g(xi)−j=1∑2αjyjK(xi,xj)−b,i=1,2
则目标函数写成:
W ( α 1 , α 2 ) = 1 2 K 11 α 1 2 + 1 2 K 2 α 2 2 + y 1 y 2 K 12 α 1 α 2 − ( α 1 + α 2 ) + y 1 α 1 ∑ i = 3 N y i α i K i 1 + y 2 α 2 ∑ i = 3 N y i α i K i 2 = 1 2 K 11 α 1 2 + 1 2 K 2 α 2 2 + y 1 y 2 K 12 α 1 α 2 − ( α 1 + α 2 ) + y 1 v 1 α 1 + y 2 v 2 α 2 \begin{aligned} W(\alpha_1,\alpha_2) =&\,\frac{1}{2}K_{11}\alpha_1^2+\frac{1}{2}K_{2}\alpha_2^2+y_1y_2K_{12}\alpha_1\alpha_2 \\ -&\,(\alpha_1+\alpha_2) +y_1\alpha_1\sum\limits_{i=3}^Ny_i\alpha_iK_{i1} +y_2\alpha_2\sum\limits_{i=3}^Ny_i\alpha_iK_{i2} \\ =&\,\frac{1}{2}K_{11}\alpha_1^2+\frac{1}{2}K_{2}\alpha_2^2+y_1y_2K_{12}\alpha_1\alpha_2 \\ -&\,(\alpha_1+\alpha_2)+y_1v_1\alpha_1+y_2v_2\alpha_2 \end{aligned} W(α1,α2)=−=−21K11α12+21K2α22+y1y2K12α1α2(α1+α2)+y1α1i=3∑NyiαiKi1+y2α2i=3∑NyiαiKi221K11α12+21K2α22+y1y2K12α1α2(α1+α2)+y1v1α1+y2v2α2
现在这个目标函数同时含有 α 1 \alpha_1 α1 和 α 2 \alpha_2 α2 ,我们要计算 α 2 new unc \alpha_2^{\text{new unc}} α2new unc ,因此只保留约束条件 α 1 y 1 + α 2 y 2 = ζ \alpha_1y_1+\alpha_2y_2=\zeta α1y1+α2y2=ζ ,消去 α 1 \alpha_1 α1 ,仅保留 α 2 \alpha_2 α2 :
α 1 = y 1 ( ζ − α 2 y 2 ) \alpha_1=y_1(\zeta-\alpha_2y_2) α1=y1(ζ−α2y2)
将其带入目标函数,得到:
W ( α 2 ) = 1 2 K 11 ( ζ − α 2 y 2 ) 2 + 1 2 K 2 α 2 2 + y 2 K 12 ( ζ − α 2 y 2 ) α 2 − y 1 ( ζ − α 2 y 2 ) − α 2 + v 1 ( ζ − α 2 y 2 ) + y 2 v 2 α 2 \begin{aligned} W(\alpha_2)=&\,\frac{1}{2}K_{11}(\zeta-\alpha_2y_2)^2+\frac{1}{2}K_{2}\alpha_2^2+y_2K_{12}(\zeta-\alpha_2y_2)\alpha_2 \\ -&\,y_1(\zeta-\alpha_2y_2)-\alpha_2+v_1(\zeta-\alpha_2y_2)+y_2v_2\alpha_2 \end{aligned} W(α2)=−21K11(ζ−α2y2)2+21K2α22+y2K12(ζ−α2y2)α2y1(ζ−α2y2)−α2+v1(ζ−α2y2)+y2v2α2
现在只有一个变量了,FOC 为:
∂ W ∂ α 2 = K 11 α 2 − K 11 ζ y 2 + K 22 α 2 + K 12 ζ y 2 − 2 K 12 α 2 + y 1 y 2 − 1 − v 1 y 2 + v 2 y 2 = 0 \begin{aligned} \frac{\partial W}{\partial \alpha_2}=&\, K_{11}\alpha_2-K_{11}\zeta y_2+K_{22}\alpha_2+K_{12}\zeta y_2-2K_{12}\alpha_2+y_1y_2-1-v_1y_2+v_2y_2 \\ =&\, 0 \\ \end{aligned} ∂α2∂W==K11α2−K11ζy2+K22α2+K12ζy2−2K12α2+y1y2−1−v1y2+v2y20
得到:
( K 11 + K 22 − 2 K 12 ) α 2 = y 2 ( K 11 ζ − K 12 ζ − y 1 + y 2 + v 1 − v 2 ) = y 2 [ K 11 ζ − K 12 ζ − y 1 + y 2 + ( g ( x 1 ) − ∑ j = 1 2 α j y j K 1 j − b ) − ( g ( x 2 ) − ∑ j = 1 2 α j y j K 2 j − b ) ] = y 2 ( K 11 ζ − K 12 ζ + E 1 − E 2 − ∑ j = 1 2 α j y j K 1 j + ∑ j = 1 2 α j y j K 2 j ) = y 2 ( E 1 − E 2 + α 2 y 2 ( K 11 + K 22 − 2 K 12 ) ) \begin{aligned} (K_{11}+K_{22}-2K_{12})\alpha_2=&\, y_2(K_{11}\zeta-K_{12}\zeta-y_1+y_2+v_1-v_2) \\ =&\, y_2[K_{11}\zeta-K_{12}\zeta-y_1+y_2 \\ +&\,\left( g(x_1)-\sum\limits_{j=1}^2\alpha_jy_jK_{1j}-b \right) \\ -&\,\left( g(x_2)-\sum\limits_{j=1}^2\alpha_jy_jK_{2j}-b \right) ] \\ =&\, y_2\left( K_{11}\zeta-K_{12}\zeta+E_1-E_2-\sum\limits_{j=1}^2\alpha_jy_jK_{1j}+\sum\limits_{j=1}^2\alpha_jy_jK_{2j} \right) \\ =&\, y_2(E_1-E_2+\alpha_2y_2(K_{11}+K_{22}-2K_{12})) \end{aligned} (K11+K22−2K12)α2==+−==y2(K11ζ−K12ζ−y1+y2+v1−v2)y2[K11ζ−K12ζ−y1+y2(g(x1)−j=1∑2αjyjK1j−b)(g(x2)−j=1∑2αjyjK2j−b)]y2(K11ζ−K12ζ+E1−E2−j=1∑2αjyjK1j+j=1∑2αjyjK2j)y2(E1−E2+α2y2(K11+K22−2K12))
-
中间带入了 E i = g ( x i ) − y i E_i=g(x_i)-y_i Ei=g(xi)−yi 和 ζ = α 1 old y 1 + α 2 old y 2 \zeta=\alpha_1^{\text{old}}y_1+\alpha_2^{\text{old}}y_2 ζ=α1oldy1+α2oldy2 ;
-
注意 K 12 = K 21 K_{12}=K_{21} K12=K21 ;
再带入 η = K 11 + K 22 − 2 K 12 \eta=K_{11}+K_{22}-2K_{12} η=K11+K22−2K12 ,就能得到:
α 2 new unc = α 2 old + y 2 ( E 1 − E 2 ) η \alpha_2^{\text{new unc}}=\alpha_2^{\text{old}}+\frac{y_2(E_1-E_2)}{\eta} α2new unc=α2old+ηy2(E1−E2)
变量的选择方法
SMO 算法在每个子问题中选择两个变量优化,其中至少一个变量时违反 KKT 条件的。
第一个变量的选择:该过程称为外层循环,选取所有训练样本中违反 KKT 条件最严重的样本点作为第一个变量 α 1 \alpha_1 α1 。KKT 条件为:
α i = 0 ⟺ y i g ( x 1 ) ≥ 1 0 < α i < C ⟺ y i g ( x 1 ) = 1 α i = C ⟺ y i g ( x 1 ) ≤ 1 \begin{aligned} \alpha_i=0 \iff y_ig(x_1) \geq 1 \\ 0\lt \alpha_i \lt C \iff y_ig(x_1) = 1 \\ \alpha_i=C \iff y_ig(x_1) \leq 1 \\ \end{aligned} αi=0⟺yig(x1)≥10<αi<C⟺yig(x1)=1αi=C⟺yig(x1)≤1
SMO 算法往往有一个超参数为精度 ε \varepsilon ε ,该检查是在 ε \varepsilon ε 的误差范围内进行的。 外层循环先检查 0 < α i < C 0\lt \alpha_i \lt C 0<αi<C (间隔边界上)的样本点,再检验其他样本点;
第二个变量的选择:该过程称为内层循环,选择标准为能使得 α 2 \alpha_2 α2 有足够大的变化。
- α 2 new \alpha_2^{\text{new}} α2new 是依赖于 ∣ E 1 − E 2 ∣ |E_1-E_2| ∣E1−E2∣ 的,在 α 1 \alpha_1 α1 确定的情况下, E 1 E_1 E1 也随之确定了。所以选择一个使得 ∣ E 1 − E 2 ∣ |E_1-E_2| ∣E1−E2∣ 最大的 α 2 \alpha_2 α2 即可;为了加速计算,可以在变量选择时提前算好所有的 E i E_i Ei ;
- 有时上述方法得到的 α 2 \alpha_2 α2 不能使得目标函数有足够的下降,可以采用启发式规则继续选择 α 2 \alpha_2 α2 :首先检查间隔边界上( 0 < α i < C 0\lt \alpha_i \lt C 0<αi<C )的样本点作为 α 2 \alpha_2 α2 试用,使得目标函数有足够的下降;再试用其他样本点;最后都不行的话,放弃 α 1 \alpha_1 α1 并重新选择;
计算偏移量 b b b 和差值 E i E_i Ei :每次完成两个变量的优化后,就要用新的 α \alpha α 计算 b b b 。
当 0 < α 1 new < C 0\lt \alpha_1^{\text{new}}\lt C 0<α1new<C 时,由 KKT 条件可知:
b = y 1 − ∑ i = 1 N α i y i K 1 i = y 1 − ∑ i = 3 N α i y i K 1 i − α 1 new y 1 K 11 − α 2 new y 2 K 12 \begin{aligned} b=&\, y_1-\sum\limits_{i=1}^{N}\alpha_iy_iK_{1i} \\ =&\, y_1-\sum\limits_{i=3}^{N}\alpha_iy_iK_{1i}-\alpha_1^{\text{new}}y_1K_{11}-\alpha_2^{\text{new}}y_2K_{12} \end{aligned} b==y1−i=1∑NαiyiK1iy1−i=3∑NαiyiK1i−α1newy1K11−α2newy2K12
带入 E 1 E_1 E1 得到:
b 1 new = − E 1 − y 1 K 11 ( α 1 new − α 1 old ) − y 2 K 12 ( α 2 new − α 2 old ) + b old b_{1}^{\text{new}}=-E_1-y_1K_{11}(\alpha_{1}^{\text{new}}-\alpha_{1}^{\text{old}})-y_2K_{12}(\alpha_{2}^{\text{new}}-\alpha_{2}^{\text{old}})+b^{\text{old}} b1new=−E1−y1K11(α1new−α1old)−y2K12(α2new−α2old)+bold
若 0 < α 2 new < C 0\lt\alpha_2^{\text{new}}\lt C 0<α2new<C ,则:
b 2 new = − E 2 − y 1 K 12 ( α 1 new − α 1 old ) − y 2 K 22 ( α 2 new − α 2 old ) + b old b_{2}^{\text{new}}=-E_2-y_1K_{12}(\alpha_{1}^{\text{new}}-\alpha_{1}^{\text{old}})-y_2K_{22}(\alpha_{2}^{\text{new}}-\alpha_{2}^{\text{old}})+b^{\text{old}} b2new=−E2−y1K12(α1new−α1old)−y2K22(α2new−α2old)+bold
对于 E i E_i Ei 值的更新,直接按照定义式算就可以了,但是需要用到 b new b^{\text{new}} bnew :
E i new = ∑ j = 1 N y j α i K ( x i , x j ) + b new − y i E_{i}^{\text{new}}=\sum\limits_{j=1}^{N}y_j\alpha_i K(x_i,x_j)+b^{\text{new}}-y_i Einew=j=1∑NyjαiK(xi,xj)+bnew−yi
这里不一定需要从 j = 1 j=1 j=1 遍历到 N N N ,因为只有支持向量的 α j ≠ 0 \alpha_j\not=0 αj=0 ,所以可以维护一个支持向量的集合 S S S ;
SMO 算法
输入:线训练数据集 T = { ( x 1 , t 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } T=\set{(x_1,t_1),(x_2,y_2),\cdots,(x_N,y_N)} T={(x1,t1),(x2,y2),⋯,(xN,yN)} ,其中 x i ∈ X ⊆ R n x_i\in\mathcal{X}\subseteq \R^n xi∈X⊆Rn , y i ∈ Y = { 1 , − 1 } y_i\in\mathcal{Y}=\set{1,\,-1} yi∈Y={1,−1} ;精度 ε \varepsilon ε ;
输出:近似解 α ^ \hat{\alpha} α^ ;
- 选取初值 α ( 0 ) = 0 \alpha^{(0)}=0 α(0)=0 ,令计步数 k = 0 k=0 k=0 ;
- 以上述选取变量方法选取优化变量 α 1 ( k ) \alpha_1^{(k)} α1(k) 和 α 2 ( k ) \alpha_2^{(k)} α2(k) ,直接用解析方程得到二者最优解 α 1 ( k + 1 ) \alpha_1^{(k+1)} α1(k+1) 和 α 2 ( k + 1 ) \alpha_2^{(k+1)} α2(k+1) ,此时 α \alpha α 更新为 α ( k + 1 ) \alpha^{(k+1)} α(k+1) ;
- 若在精度 ε \varepsilon ε 范围内满足停机条件(约束条件):
∑ i = 1 N α i y i = 0 , 0 ≤ α i ≤ C , i = 1 , 2 , ⋯ , N \sum\limits_{i=1}^{N}\alpha_iy_i=0,\quad 0\leq \alpha_i\leq C,\quad i=1,2,\cdots,N i=1∑Nαiyi=0,0≤αi≤C,i=1,2,⋯,N
和:
y i g ( x i ) { ≥ 1 , { x i ∣ α i = 0 } = 1 , { x i ∣ 0 < α i < C } ≤ 1 , { x i ∣ α i = C } y_ig(x_i)\left\{ \begin{array}{ll} \geq 1, & \set{x_i|\alpha_i=0} \\ = 1, & \set{x_i|0\lt\alpha_i\lt C} \\ \leq 1, & \set{x_i|\alpha_i=C} \\ \end{array} \right. yig(xi)⎩ ⎨ ⎧≥1,=1,≤1,{xi∣αi=0}{xi∣0<αi<C}{xi∣αi=C}
其中:
g ( x i ) = ∑ j = 1 N α j y j K ( x i , x j ) + b g(x_i)=\sum\limits_{j=1}^{N}\alpha_jy_jK(x_i,x_j)+b g(xi)=j=1∑NαjyjK(xi,xj)+b
- 返回 α ^ = α ( k + 1 ) \hat\alpha=\alpha^{(k+1)} α^=α(k+1) ;
相关文章:
统计学习方法 支持向量机(下)
文章目录 统计学习方法 支持向量机(下)非线性支持向量机与和核函数核技巧正定核常用核函数非线性 SVM 序列最小最优化算法两个变量二次规划的求解方法变量的选择方法SMO 算法 统计学习方法 支持向量机(下) 学习李航的《统计学习方…...

【python】如何注释
一:通过#注释行 #这个是个注释 print(hello world) 二:通过或"""注释段落 这个注释段落 这是注释段落 这是注释段落print(hello world) """ 这是多行注释,用三个双引号 这是多行注释,用三个双引…...
C++——C++入门(二)
C 前言一、引用引用概念引用特性常引用使用场景传值、传引用效率比较值和引用的作为返回值类型的性能比较 引用和指针的区别 二、内联函数概念特性知识点提升 三、auto关键字类型别名思考auto简介auto的使用细则auto不能推导的场景 四、基于范围的for循环范围for的语法范围for的…...
容联七陌百度营销通BCP解决方案,让营销更精准
百度营销通作为一个快速迭代、满足客户多元化营销需求的高效率营销工具成为众多企业的选择,通过百度营销通BCP对接,企业就可以在百度咨询页接入会话,收集百度来源的访客搜索关键词,通过百度推广获取更多的精准客户,从而…...
Transformer模型 | 用于目标检测的视觉Transformers训练策略
基于视觉的Transformer在预测准确的3D边界盒方面在自动驾驶感知模块中显示出巨大的应用,因为它具有强大的建模视觉特征之间远程依赖关系的能力。然而,最初为语言模型设计的变形金刚主要关注的是性能准确性,而不是推理时间预算。对于像自动驾驶这样的安全关键系统,车载计算机…...

贪心区间类题目
一、先排序 1、一般统计有几个重复区间、判断是否有重复区间,对右边界经行排序。 2、合并区间,对左边界经行排序,且尽量想到先放入一个元素到res中,然后不断更新res的右边界 二、判断重复 判断i是否和i-1重复,如果…...
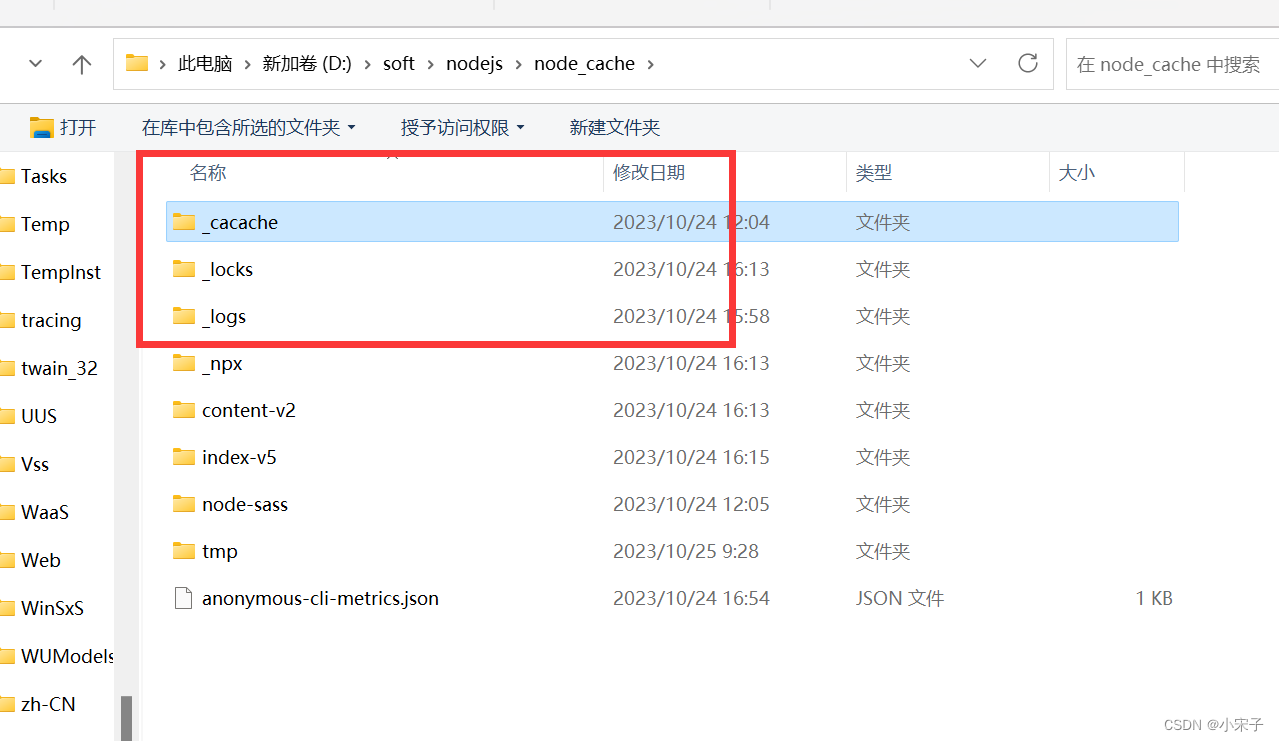
npm改变npm缓存路径和改变环境变量
在安装nodejs时,系统会自动安装在系统盘C, 时间久了经常会遇到C盘爆满,有时候出现红色,此时才发现很多时候是因为npm 缓存保存在C盘导致的,下面就介绍下如何改变npm缓存路径。 1、首先找到安装nodejs的路径,…...

string到QString出现中文乱码
【C】string 和 QString 之间的转化及乱码问题(非常实用)_string转qstring乱码_散修-小胖子的博客-CSDN博客 std::string str "连111";QString str1 QString::fromStdString(str);qDebug() << str1;//中文乱码QString str2 QString::fromLocal8Bit(str.data…...

【Linux精讲系列】——yum软件包管理
作者主页 📚lovewold少个r博客主页 ⚠️本文重点:Linux系统软件包管理工具yum讲解 😄每日一言:踏向彼岸的每一步,都是到达彼岸本身。 目录 前言 Linux系统下的软件下载方式 yum 查看软件包 如何安装软件 如何卸…...
浅谈一下Vue3的TreeShaking特性
什么是Treeshaking? Treeshaking是一个术语,通常用于描述移除JavaScript中无用代码的过程。 在Vue3中,借助于它的编译优化,可以显著减少打包后的大小。 Vue3的Treeshaking实现 Vue3中的Treeshaking主要通过以下两点实现: 源码级的Tree-shaking Vue3源码采用ES mo…...

【牛牛送书 | 第二期】《ChatGPT 驱动软件开发:AI 在软件研发全流程中的革新与实践》
目录 前言: 本书目录: 内容简介: 专家评价: 适合对象: 送书规则: 前言: 现如今,随着计算机技术的不断发展和互联网的普及,我们已经迈入了一个高效的信息处理和传…...

Qt基础之三十九:Qt Creator调试技巧
目录 一.开始调试(F5) 二.调试dll 1.Attach to Running Application 2.Attach to Unstarted Application 3.Start and Debug External Application...

Docker Nginx安装使用以及踩坑点总结
Docker Nginx安装使用以及踩坑点总结 拉取nginx镜像 docker pull nginx:latest运行镜像 暂时不需要配置volume挂载 docker run --name nginx -p 80:80 -d nginx参数详解: --name nginx 指定容器的名称 -p 80:80 映射端口 -d 守护进程运行 创建volume目录 mk…...
单位建数字档案室的意义和作用
单位建立数字档案室的意义和作用包括: 1.提高档案管理效率。数字档案室可以高效地收集、整理和存储电子文档,通过数字化处理,文档的查找和检索速度大幅提升。 2.降低管理成本。数字档案室可以通过节约空间和人力成本,降低管理成本…...

JavaWeb——关于servlet种mapping地址映射的一些问题
6、Servlet 6.4、Mapping问题 一个Servlet可以指定一个映射路径 <servlet-mapping><servlet-name>hello</servlet-name><url-pattern>/hello</url-pattern> </servlet-mapping>一个Servlet可以指定多个映射路径 <servlet-mapping>&…...

NTRU 加密方案
参考文献: [Rivest97] Rivest R L. All-or-nothing encryption and the package transform[C]//Fast Software Encryption: 4th International Workshop, FSE’97 Haifa, Israel, January 20–22 1997 Proceedings 4. Springer Berlin Heidelberg, 1997: 210-218.[…...

第一章前端开发ES6基础
认识ES6 概述 ES6表示ECMAScript规范的第六版,正式名称为ECMAScript 2015,ECMAScript是由ECMA国际标准组织制定的一项脚本语言的标准规范化,引入了许多新特性和语法。 其中包括箭头函数、let和const声明、类、模板字符串、解构赋值、参数默…...

【算法练习Day30】无重叠区间 划分字母区间合并区间
📝个人主页:Sherry的成长之路 🏠学习社区:Sherry的成长之路(个人社区) 📖专栏链接:练题 🎯长路漫漫浩浩,万事皆有期待 文章目录 无重叠区间划分字母区间合并…...
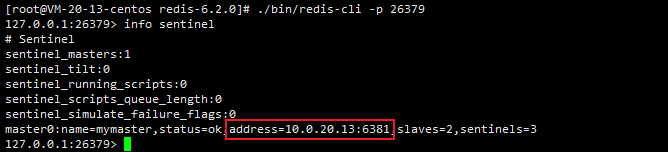
Linux部署Redis哨兵集群 一主两从三哨兵(这里使用Redis6,其它版本类似)
目录 一、哨兵集群架构介绍二、下载安装Redis2.1、选择需要安装的Redis版本2.2、下载并解压Redis2.3、编译安装Redis 三、搭建Redis一主两从集群3.1、准备配置文件3.1.1、准备主节点6379配置文件3.1.2、准备从节点6380配置文件3.1.3、准备从节点6381配置文件 3.2、启动Redis主从…...

VR结合|山海鲸虚拟展厅解决方案
方案背景 虚拟现实技术是另一项革命性的创新,它可以将用户带入一个完全虚拟的环境中。借助VR头盔和控制器,用户可以亲临虚拟现实中,与数字世界互动,仿佛置身于其中。 山海鲸根据用户实际需求变化将数字孪生与虚拟现实技术相结合…...

毫米波ISAC技术:车联网中的感知与通信融合方案
1. 毫米波ISAC系统概述在智能交通系统快速发展的今天,毫米波集成感知与通信(ISAC)技术正成为解决车联网(V2X)需求的关键方案。这项技术的核心创新点在于,它巧妙地将雷达感知和无线通信两大功能整合到同一硬件平台上,通过共享60GHz毫米波频段资…...

基于MCP协议构建Reddit社区趋势分析工具:架构、部署与应用
1. 项目概述:一个实时洞察社区脉搏的利器最近在做一个社区运营相关的项目,需要实时追踪几个特定话题在Reddit上的讨论热度变化。手动刷帖、统计关键词频率这种笨办法效率太低,而且很难量化趋势。就在我琢磨着是不是要自己写个爬虫加分析脚本的…...

Camera Graph™相机拓扑图谱引擎技术白皮书
前言在数字孪生、全域感知、智能安防等领域快速发展的今天,多镜头协同感知已成为实现全域覆盖、精准识别、连续追踪的核心基础。然而,传统多相机部署模式下,各镜头始终处于“孤立工作”状态,数据互通存在壁垒、时空对齐精度不足、…...

Horos:让医学影像分析像翻阅相册一样简单
Horos:让医学影像分析像翻阅相册一样简单 【免费下载链接】horos Horos™ is a free, open source medical image viewer. The goal of the Horos Project is to develop a fully functional, 64-bit medical image viewer for OS X. Horos is based upon OsiriX an…...

面向科学计算Agent的Harness数值稳定性校验
面向科学计算Agent的Harness数值稳定性校验关键词:科学计算Agent、Harness框架、数值稳定性校验、数值误差溯源、Agent-数值系统交互、可复现科学、边界条件自动化测试摘要:随着大语言模型(LLM)与多模态AI的崛起,科学计…...

从零到一:基于Ultralytics框架与自定义数据集实战RT-DETR模型训练
1. RT-DETR与Ultralytics框架初探 第一次接触RT-DETR时,我被它的"实时检测Transformer"组合惊艳到了。这个由百度开发的检测器,完美解决了传统Transformer模型在实时场景下的性能瓶颈。不同于YOLO系列的锚框机制,RT-DETR采用端到端…...
)
别再死记硬背公式了!用Python手把手带你‘画’出GBDT的每一棵树(附完整代码)
用Python动态可视化GBDT:从零构建每棵决策树的实战指南 在机器学习领域,GBDT(Gradient Boosting Decision Tree)因其出色的预测性能而广受欢迎。但对于初学者来说,理解这个"黑箱"内部的运作机制往往令人望而…...

图像质量评估新视角:抛开PSNR和SSIM,聊聊如何用‘变异系数’量化局部细节清晰度
图像质量评估新视角:用变异系数量化局部细节清晰度的实战指南 在数字图像处理领域,评估图像质量一直是核心挑战。传统指标如PSNR(峰值信噪比)和SSIM(结构相似性)虽然广泛应用,但面对复杂场景时往…...

告别水下照片的蓝绿色偏:手把手教你用OpenCV和Python实现图像增强与色彩还原
告别水下照片的蓝绿色偏:手把手教你用OpenCV和Python实现图像增强与色彩还原 每次从潜水旅行回来,看着相机里那些本该绚丽多彩的珊瑚礁照片变成一片蓝绿色,总是让人感到沮丧。水下摄影爱好者、海洋生物研究者或是从事水下工程的专业人士都面临…...

系统安装:安装Ubuntu 26.04 LTS
1. EFI以及UEFI,什么用途? https://baike.baidu.com/item/EFI/2025809 EFI(Extensible Firmware Interface,可扩展固件接口)是由英特尔公司开发的固件接口标准,用于替代传统BIOS以实现更高效的硬件初始化和…...