【智能大数据分析】实验1 MapReduce实验:单词计数
【智能大数据分析】实验1 MapReduce实验:单词计数
文章目录
- 【智能大数据分析】实验1 MapReduce实验:单词计数
- 一、实验目的
- 二、实验要求
- 三、实验原理
- 1 MapReduce编程
- 2 Java API解析
- 四、实验步骤
- 1 启动Hadoop
- 2 验证HDFS上没有wordcount的文件夹
- 3 上传数据文件到HDFS
- 4 编写MapReduce程序
- 5 使用命令将代码打包
- 6 在Hadoop集群上提交jar文件来运行MapReduce作业
在我之前的一篇博客中:云计算中的大数据处理:尝试HDFS和MapReduce的应用有过类似的操作,具体不会的可以去这篇博客中看看。
一、实验目的
基于MapReduce思想,编写WordCount程序。
二、实验要求
1.理解MapReduce编程思想;
2.会编写MapReduce版本WordCount;
3.会执行该程序;
4.自行分析执行过程。
三、实验原理
MapReduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。这样做的好处是可以在任务被分解后,可以通过大量机器进行并行计算,减少整个操作的时间。
适用范围:数据量大,但是数据种类小可以放入内存。
基本原理及要点:将数据交给不同的机器去处理,数据划分,结果归约。
理解MapReduce和Yarn:在新版Hadoop中,Yarn作为一个资源管理调度框架,是Hadoop下MapReduce程序运行的生存环境。其实MapRuduce除了可以运行Yarn框架下,也可以运行在诸如Mesos,Corona之类的调度框架上,使用不同的调度框架,需要针对Hadoop做不同的适配。
一个完成的MapReduce程序在Yarn中执行过程如下:
(1)ResourcManager JobClient向ResourcManager提交一个job。
(2)ResourcManager向Scheduler请求一个供MRAppMaster运行的container,然后启动它。
(3)MRAppMaster启动起来后向ResourcManager注册。
(4)ResourcManagerJobClient向ResourcManager获取到MRAppMaster相关的信息,然后直接与MRAppMaster进行通信。
(5)MRAppMaster算splits并为所有的map构造资源请求。
(6)MRAppMaster做一些必要的MR OutputCommitter的准备工作。
(7)MRAppMaster向RM(Scheduler)发起资源请求,得到一组供map/reduce task运行的container,然后与NodeManager一起对每一个container执行一些必要的任务,包括资源本地化等。
(8)MRAppMaster 监视运行着的task 直到完成,当task失败时,申请新的container运行失败的task。
(9)当每个map/reduce task完成后,MRAppMaster运行MR OutputCommitter的cleanup 代码,也就是进行一些收尾工作。
(10)当所有的map/reduce完成后,MRAppMaster运行OutputCommitter的必要的job commit或者abort APIs。
(11)MRAppMaster退出。
1 MapReduce编程
编写在Hadoop中依赖Yarn框架执行的MapReduce程序,并不需要自己开发MRAppMaster和YARNRunner,因为Hadoop已经默认提供通用的YARNRunner和MRAppMaster程序, 大部分情况下只需要编写相应的Map处理和Reduce处理过程的业务程序即可。
编写一个MapReduce程序并不复杂,关键点在于掌握分布式的编程思想和方法,主要将计算过程分为以下五个步骤:
(1)迭代。遍历输入数据,并将之解析成key/value对。
(2)将输入key/value对映射(map)成另外一些key/value对。
(3)依据key对中间数据进行分组(grouping)。
(4)以组为单位对数据进行归约(reduce)。
(5)迭代。将最终产生的key/value对保存到输出文件中。
2 Java API解析
(1)InputFormat:用于描述输入数据的格式,常用的为TextInputFormat提供如下两个功能:
数据切分: 按照某个策略将输入数据切分成若干个split,以便确定Map Task个数以及对应的split。
为Mapper提供数据:给定某个split,能将其解析成一个个key/value对。
(2)OutputFormat:用于描述输出数据的格式,它能够将用户提供的key/value对写入特定格式的文件中。
(3)Mapper/Reducer: Mapper/Reducer中封装了应用程序的数据处理逻辑。
(4)Writable:Hadoop自定义的序列化接口。实现该类的接口可以用作MapReduce过程中的value数据使用。
(5)WritableComparable:在Writable基础上继承了Comparable接口,实现该类的接口可以用作MapReduce过程中的key数据使用。(因为key包含了比较排序的操作)。
四、实验步骤
本实验主要分为,确认前期准备,编写MapReduce程序,打包提交代码。查看运行结果这几个步骤,详细如下:
1 启动Hadoop

2 验证HDFS上没有wordcount的文件夹

此时HDFS上应该是没有wordcount文件夹。
3 上传数据文件到HDFS
wordcount.txt:


4 编写MapReduce程序
主要编写Map和Reduce类,其中Map过程需要继承org.apache.hadoop.mapreduce包中Mapper类,并重写其map方法;Reduce过程需要继承org.apache.hadoop.mapreduce包中Reduce类,并重写其reduce方法。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;import java.io.IOException;
import java.util.StringTokenizer;public class WordCount {public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {private final static IntWritable one = new IntWritable(1);private Text word = new Text();//map方法,划分一行文本,读一个单词写出一个<单词,1>public void map(Object key, Text value, Context context)throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {word.set(itr.nextToken());context.write(word, one);//写出<单词,1>}}}//定义reduce类,对相同的单词,把它们中的VList值全部相加public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values,Context context)throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();//相当于<Hello,1><Hello,1>,将两个1相加}result.set(sum);context.write(key, result);//写出这个单词,和这个单词出现次数<单词,单词出现次数>}}public static void main(String[] args) throws Exception {//主方法,函数入口Configuration conf = new Configuration(); //实例化配置文件类Job job = new Job(conf, "WordCount"); //实例化Job类job.setInputFormatClass(TextInputFormat.class); //指定使用默认输入格式类TextInputFormat.setInputPaths(job, args[0]); //设置待处理文件的位置job.setJarByClass(WordCount.class); //设置主类名job.setMapperClass(TokenizerMapper.class); //指定使用上述自定义Map类job.setCombinerClass(IntSumReducer.class); //指定开启Combiner函数job.setMapOutputKeyClass(Text.class); //指定Map类输出的,K类型job.setMapOutputValueClass(IntWritable.class); //指定Map类输出的,V类型job.setPartitionerClass(HashPartitioner.class); //指定使用默认的HashPartitioner类job.setReducerClass(IntSumReducer.class); //指定使用上述自定义Reduce类job.setNumReduceTasks(Integer.parseInt(args[2])); //指定Reduce个数job.setOutputKeyClass(Text.class); //指定Reduce类输出的,K类型job.setOutputValueClass(Text.class); //指定Reduce类输出的,V类型job.setOutputFormatClass(TextOutputFormat.class); //指定使用默认输出格式类TextOutputFormat.setOutputPath(job, new Path(args[1])); //设置输出结果文件位置System.exit(job.waitForCompletion(true) ? 0 : 1); //提交任务并监控任务状态}
}

5 使用命令将代码打包
上述代码在编译运行的时候会进行报错:

主要是在Hadoop版本3.x中,Job构造函数已过时,需要使用Job.getInstance构造函数。另外,有一个潜在的问题是设置job.setOutputValueClass为Text.class,但您的Reduce类输出类型是IntWritable,这两者需要匹配。
下面是修改之后的代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;
import java.util.StringTokenizer;public class WordCount {public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Context context) throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {word.set(itr.nextToken());context.write(word, one);}}}public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result);}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf, "WordCount");job.setJarByClass(WordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path(args[0])); // 输入路径FileOutputFormat.setOutputPath(job, new Path(args[1])); // 输出路径System.exit(job.waitForCompletion(true) ? 0 : 1);}
}
下面是打包过程:
-
在我们创建的java项目根目录下创建一个名为
src的文件夹。 -
将所有的Java源代码文件(
.java)移动到src文件夹中。 -
在项目根目录中创建一个名为
Manifest.txt的文件,用于指定JAR文件的入口点。 -
在
Manifest.txt文件中,添加以下内容:Main-Class: <Main-Class>将
<Main-Class>替换为包含main方法的主类的完整类名,例如我的是SalesDriver -
回到项目根目录下,使用以下命令编译Java源代码并创建一个临时目录来保存编译后的类文件:
mkdir classes javac -d classes src/*.java如果你在使用编译命令时出现
程序包×××存在的问题,这个时候我们需要将Hadoop相关的jar文件添加到编译路径中才可以解决:javac -classpath /usr/local/servers/hadoop/share/hadoop/common/hadoop-common-3.1.3.jar:/usr/local/servers/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-core-3.1.3.jar -d classes src/*.java注意上面的命令是一个而不是多个。
-
创建一个空的JAR文件,命名为
WordCount.jar:jar -cvf WordCount.jar -C classes/ . -
将编译后的类文件和
Manifest.txt添加到JAR文件中:jar -uf WordCount.jar -C classes/ .jar -uf WordCount.jar Mainfest.txt
到现在,我们的整个java项目就打包成功了。
6 在Hadoop集群上提交jar文件来运行MapReduce作业
我们将打包好的WordCount.jar使用如下命令提交到集群上面:
hadoop jar WordCount.jar WordCount /user/wordcount.txt /wordcount
顺利执行之后终端会打印如下信息:

然后我们查看我们的输出目录:
hdfs dfs -ls /wordcount

红框所示就是我们需要的结果,我们将其下载下来进行查看:
hdfs dfs -get /wordcount1/part-r-00000 /root/WordCount
vim part-r-00000

可以看见运行出我们想要的结果了,至此本次实验结束。
相关文章:
【智能大数据分析】实验1 MapReduce实验:单词计数
【智能大数据分析】实验1 MapReduce实验:单词计数 文章目录 【智能大数据分析】实验1 MapReduce实验:单词计数一、实验目的二、实验要求三、实验原理1 MapReduce编程2 Java API解析 四、实验步骤1 启动Hadoop2 验证HDFS上没有wordcount的文件夹3 上传数据…...

KV STUDIO的安装与实践(一)
目录 什么是KV STUDIO? 如何安装KV STUDIO? 如何学习与使用KV STUDIO(在现实中的应用)? 应用一(在现实生活中机器内部plc的读取与替换) 读取 KV STUDIO实现显示器的检测!&#…...
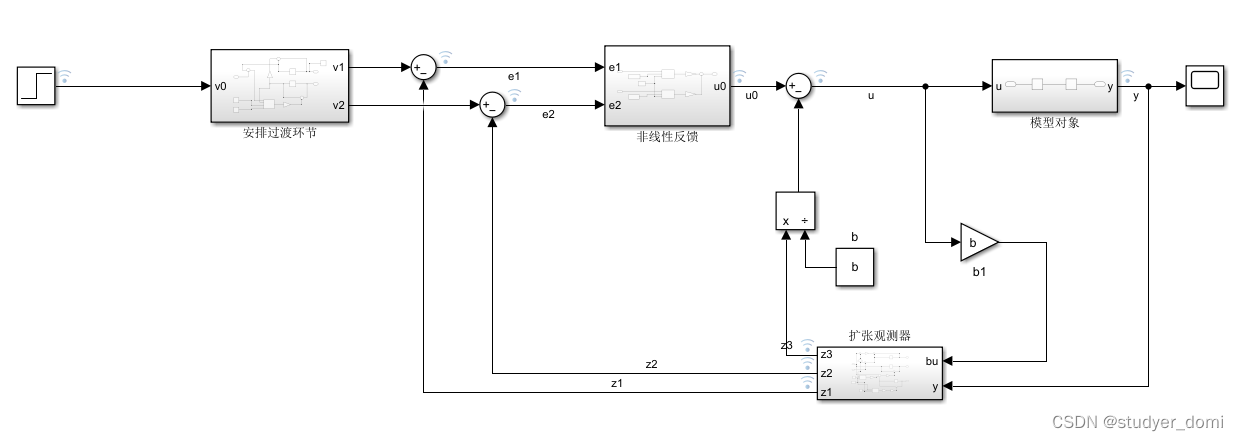
matlab simulink ADRC控制样例
1、内容简介 略 3-可以交流、咨询、答疑 2、内容说明 用adrc控制传递函数,保证输出达到预期 ADRC控制器、传递函数 3、仿真分析 4、参考论文 略...

我是如何走上测试管理岗的
最近有小伙伴问了一个问题:他所在的测试团队规模比较大,有 50 多个人,分成了 4 ~ 5 个小组。这位同学觉得自己的技术能力在团队里应该属于比较不错的,但疑惑的是在几次组织架构调整中,直属领导一直没有让他来管理一个小…...

回溯法:雀魂启动!
题目链接:雀魂启动!_牛客题霸_牛客网 题解: 回溯法 1、用哈希思想构建映射表,标记已有的卡的种类和个数 2、遍历卡池,先从卡池中抽一张卡,因为只能抽一张卡,所以一种卡只判断一次 3、抽到卡后找…...
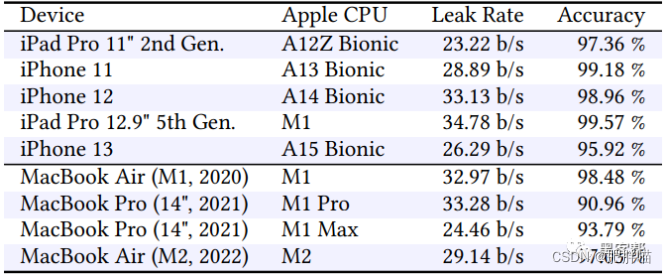
新的iLeakage攻击从Apple Safari窃取电子邮件和密码
图片 导语:学术研究人员开发出一种新的推测性侧信道攻击,名为iLeakage,可在所有最新的Apple设备上运行,并从Safari浏览器中提取敏感信息。 攻击概述 iLeakage是一种新型的推测性执行攻击,针对的是Apple Silicon CPU和…...
Java练习题2021-1
"从大于等于N的正整数里找到一个最小的数M,使之满足: M和M的逆序数(如1230的逆序数为321)的差的绝对值为一个[100000,200000]区间内的值。 输入说明:起始数字N; 输出说明:找到的第一个符合…...

微信小程序input输入字母自动转大写不生效问题解决
uniapp中开发的小程序,采用 style"text-transform:uppercase" H5中正常小写变大写,编译小程序后不生效 解决办法 uniapp中 input增加 input"TransFormationsFn" <input type"text" value"" input"…...
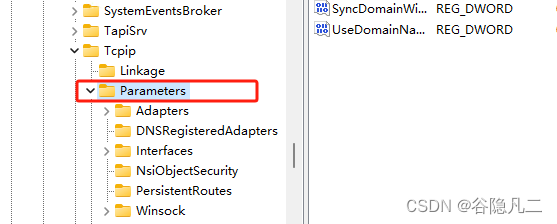
jmeter报Java.NET.BindException: Address already in use: connect
1、windows10和window11上: 修改注册表的内容: HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters: 新建dword(值)的类型: MaxUserPort 65334 TcpTimedWaitDelay 30window...

2023手工测试转自动化测试后,薪资可以达到多少?
目前手工测试工作了8个月,现已辞职在家学习全栈自动化测试的课程中,之前想着学完后工资期望7.5k,开发朋友说太少了 ,想了解下这样的情况在日后找工作,薪资可以达到多少? 说到底,软件测试是技术…...

01 _ 为什么要学习数据结构和算法?
今天我们就来详细聊一聊,为什么要学习数据结构和算法。 想要通关大厂面试,千万别让数据结构和算法拖了后腿 很多大公司,比如BAT、Google、Facebook,面试的时候都喜欢考算法、让人现场写代码。有些人虽然技术不错,但每…...
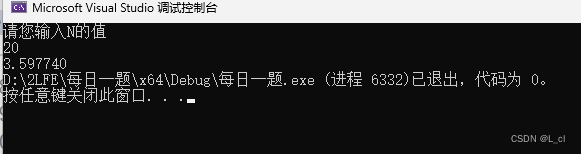
C语言 每日一题 PTA 10.27 day5
1.高速公路超速处罚 按照规定,在高速公路上行使的机动车,达到或超出本车道限速的10 % 则处200元罚款; 若达到或超出50 % ,就要吊销驾驶证。请编写程序根据车速和限速自动判别对该机动车的处理。 输入格式 : 输入在一行中给出2个正…...

Unity Shader当用户靠近的时候会出现吃鸡一样的光墙
效果图片 靠近墙壁 远离墙壁 材质球的设置 两张图片 使用方式 把这个脚本放到墙上,将player赋值给"_player",然后运行,用户靠近就会根据距离显示光墙。 using UnityEngine;public class NewBehaviourScript : MonoBehaviour {pr…...
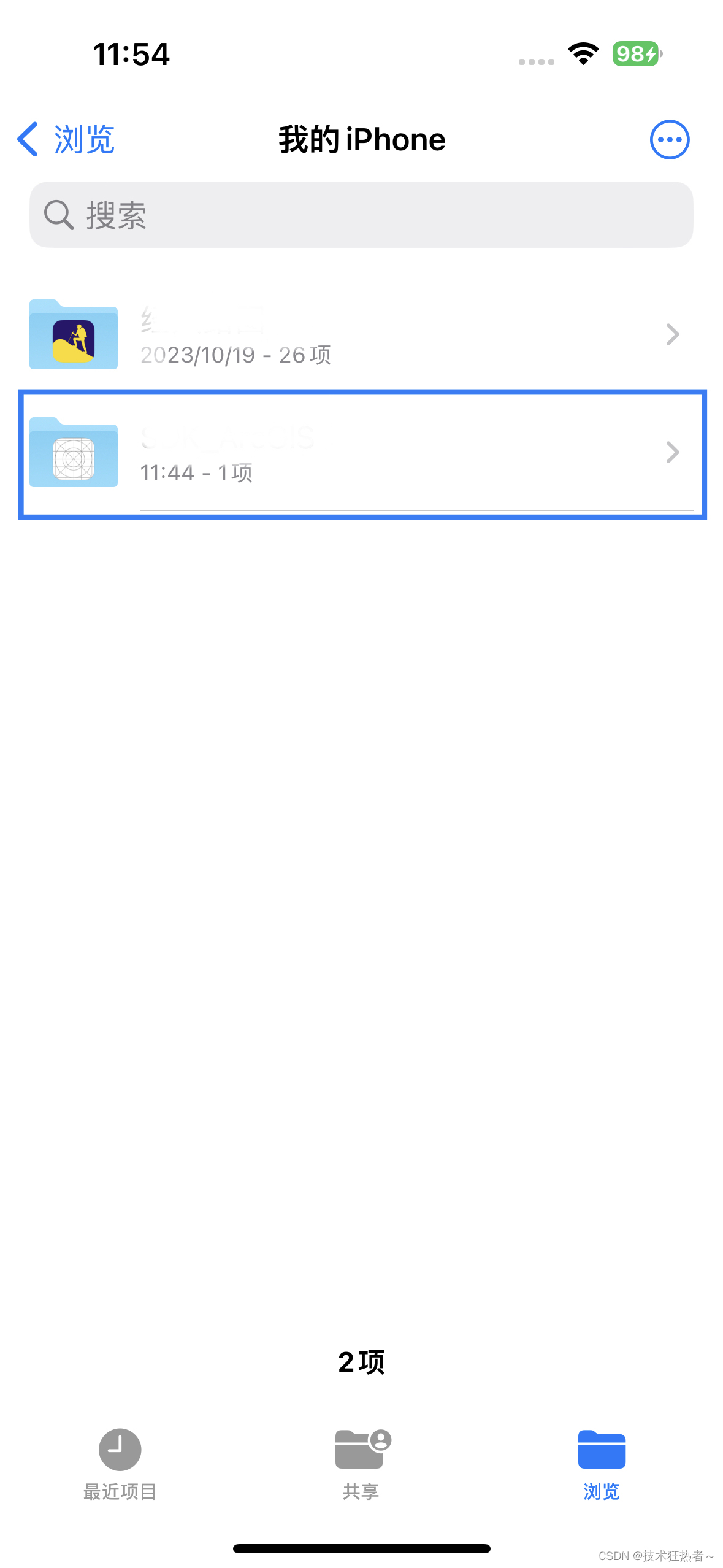
Xcode iOS app启用文件共享
在info.plist中添加如下两个配置 Supports opening documents in place Application supports iTunes file sharing 结果都为YES,如下图所示: 然后,iOS设备查看,文件->我的iPhone列表中有一个和你工程名相同的文件夹出现&…...
任务的创建和删除)
STM32H750之FreeRTOS学习--------(二)任务的创建和删除
FreeRTOS 二、任务的创建和删除 任务创建 动态方式创建任务 BaseType_t xTaskCreate ( TaskFunction_t pxTaskCode, /* 指向任务函数的指针 */ const char * const pcName, /* 任务名字,最大长度configMAX_TASK_NAME_LEN */const configSTACK_…...
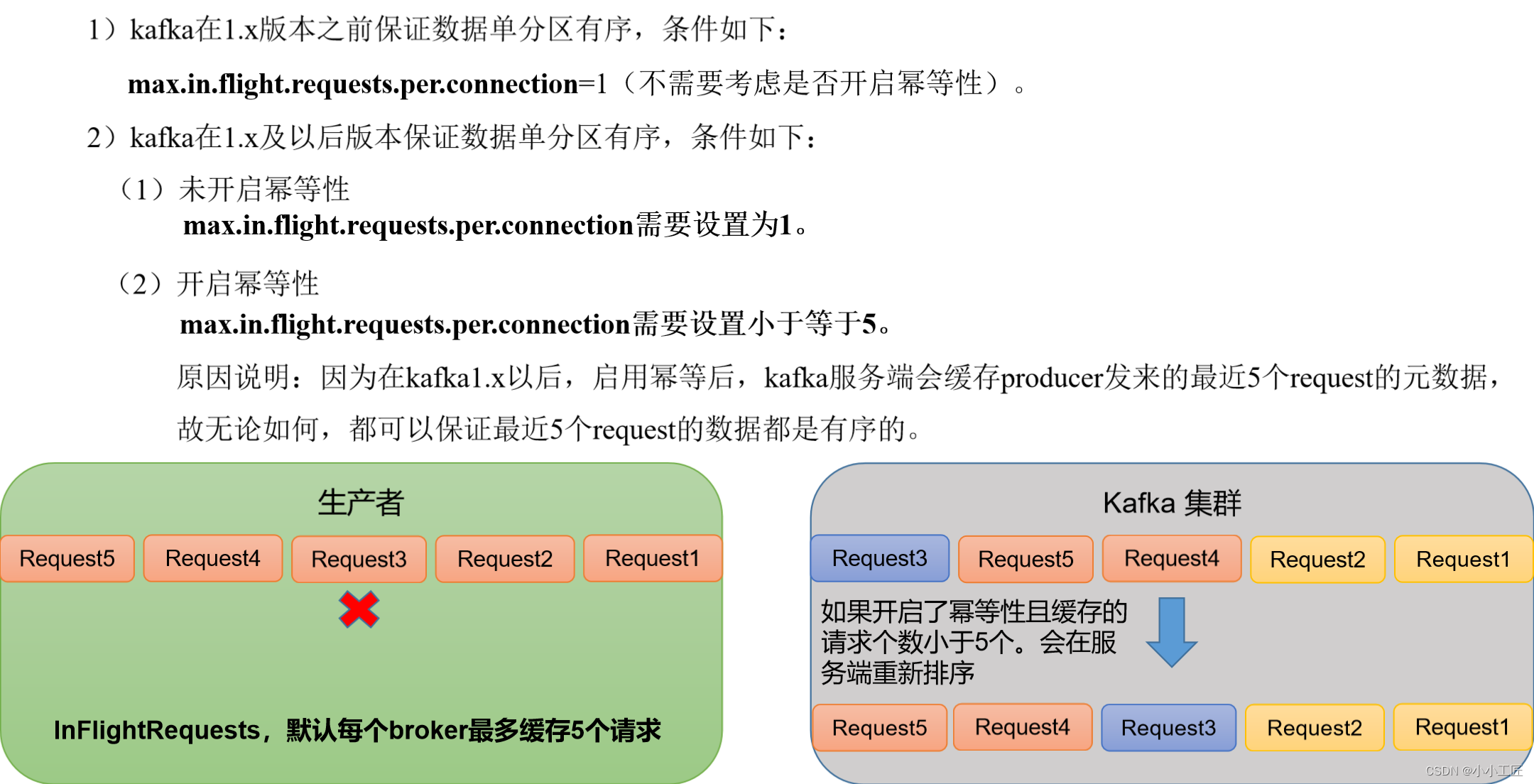
Kafka - 3.x Producer 生产者最佳实践
文章目录 生产经验_生产者提高吞吐量核心参数Code 生产经验_数据可靠性消息的发送流程ACK应答机制ack应答级别应答机制 小结Code 生产经验_数据去重数据传递语义幂等性幂等性原理开启幂等性配置(默认开启) 生产者事务kafka事务原理事务代码流程 生产经验…...
进行迁移学习提升性能)
对于多分类问题,使用深度学习(Keras)进行迁移学习提升性能
本文是仿照前面的文章,使用Keras迁移学习提升性能,原文是针对二分类问题,使用迁移学习的方式来提升准确率,本文用迁移学习的方式来提升多分类问题的准确率。 同时,在前面的文章中,使用普通的小型3层卷积网络+2层全连接层实现了多分类的85%左右的准确率, 此处将用迁移学…...
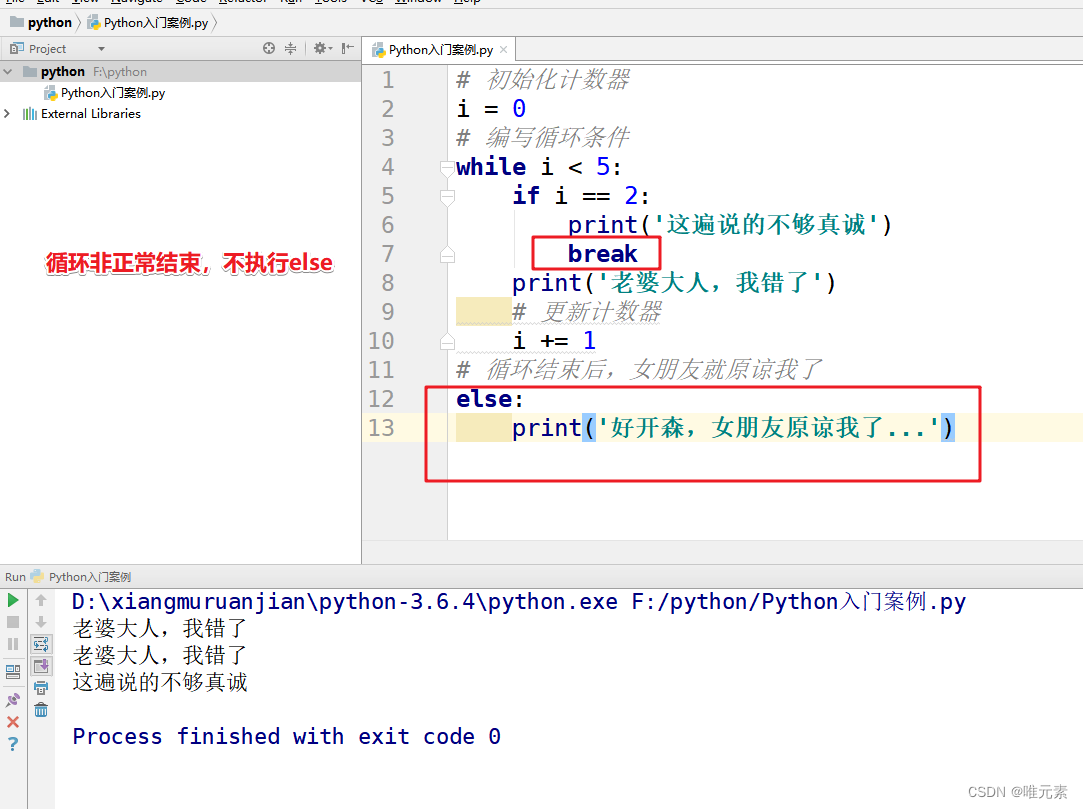
Python----break关键字对while...else结构的影响
案例: 女朋友生气,要求道歉5遍:老婆大人,我错了。道歉到第三遍的时候,媳妇埋怨这一遍说的不真诚,是不是就是要退出循环了?这个退出有两种可能性: ① 更生气,不打算原谅…...

js实现将文本生成二维码(腾讯云cos)
示例 页面代码 import { getQCodeUrl } from /utils/cosInstance; import { PageContainer } from ant-design/pro-components; import { Access, useAccess } from umijs/max; import { Button, Image } from antd; import { useState } from react;const AccessPage: Reac…...

机架式服务器介绍
大家都知道服务器分为机架式服务器、刀片式服务器、塔式服务器三类,今天小编就分别讲一讲这三种服务器,第一篇先来讲一讲机架式服务器的介绍。 机架式服务器定义:机架式服务器是安装在标准机柜中的服务器,一般采用19英寸的标准尺寸…...

接口响应慢排查指南:从分层框架到实战优化
1. 问题定位:从现象到根源的排查框架接口响应慢,这几乎是每个后端开发者、运维工程师乃至测试同学都会遇到的“经典”问题。它不像一个明确的错误,会直接抛出异常或返回错误码,而是像一个隐形的性能瓶颈,悄无声息地拖慢…...

【ArcGIS实战指南】利用属性连接与符号化,一键生成柱状图与饼状图
1. 从零开始:理解ArcGIS图表制作的核心逻辑 第一次接触ArcGIS的图表功能时,我也被各种专业术语搞得晕头转向。直到在西北农业干旱评估项目中,我才真正搞明白属性连接和符号化的配合使用逻辑。简单来说,这就像给地图数据"穿衣…...

终极指南:如何使用webSpoon快速构建企业级数据集成平台
终极指南:如何使用webSpoon快速构建企业级数据集成平台 【免费下载链接】pentaho-kettle webSpoon is a web-based graphical designer for Pentaho Data Integration with the same look & feel as Spoon 项目地址: https://gitcode.com/gh_mirrors/pen/pent…...

财联支付申请开通的门槛门槛高不高?
在数字支付蓬勃发展的当下,支付方式的便捷性和安全性成为了商户和消费者关注的焦点。财联支付作为数字支付领域的佼佼者,以其创新的技术和优质的服务吸引了众多商户的目光。然而,很多人对于财联支付申请开通的门槛存在疑问,究竟它…...

Python 开发者五分钟接入 Taotoken 调用 GPT 与 Claude 模型指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python 开发者五分钟接入 Taotoken 调用 GPT 与 Claude 模型指南 对于习惯使用 OpenAI 官方 Python SDK 的开发者来说,…...
)
从设备树到驱动:在RK3566上点亮一个LED的完整实战(GPIO0_B4为例)
从设备树到驱动:在RK3566上点亮一个LED的完整实战(GPIO0_B4为例) 当你第一次拿到一块Rockchip RK3566开发板时,最令人兴奋的莫过于让硬件真正"活"起来。而点亮一个LED,就像嵌入式世界的"Hello World&q…...

《Java 100 天进阶之路》第23篇:缓冲区数据结构 ByteBuffer
第23篇:缓冲区数据结构 ByteBuffer 📌 系列导航:《Java 100 天进阶之路》完整目录 | ⬅️ 上一篇:第22篇:Java字符串简介 | ➡️ 下一篇:第24篇:Java枚举类型 enum 用法👈 待发布 一…...

DayZ社区离线模式完全指南:打造你的专属末日沙盒世界
DayZ社区离线模式完全指南:打造你的专属末日沙盒世界 【免费下载链接】DayZCommunityOfflineMode A community made offline mod for DayZ Standalone 项目地址: https://gitcode.com/gh_mirrors/da/DayZCommunityOfflineMode 想在DayZ中完全掌控自己的生存命…...

Ren`Py 引擎初探:从零搭建你的Python视觉小说项目
1. 为什么选择RenPy开发视觉小说? 第一次听说RenPy是在三年前,当时我正在寻找能用Python开发的游戏引擎。试过Unity、Unreal这些主流引擎后,发现它们要么需要学习C#,要么对2D支持不够友好。直到偶然在论坛看到有人用RenPy做文字冒…...

Obsidian Projects:开源文本项目管理的终极解决方案
Obsidian Projects:开源文本项目管理的终极解决方案 【免费下载链接】obsidian-projects Plain text project planning in Obsidian 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-projects 在当今信息爆炸的时代,高效的项目管理工具已成…...