Elasticsearch:使用 Open AI 和 Langchain 的 RAG - Retrieval Augmented Generation (四)
这篇博客是之前文章:
- Elasticsearch:使用 Open AI 和 Langchain 的 RAG - Retrieval Augmented Generation (一)
- Elasticsearch:使用 Open AI 和 Langchain 的 RAG - Retrieval Augmented Generation (二)
-
Elasticsearch:使用 Open AI 和 Langchain 的 RAG - Retrieval Augmented Generation (三)
的续篇。在这篇文章中,我们将学习如何把从 Elasticsearch 搜索到的结果传递到大数据模型以得到更好的结果。

如果你还没有创建好自己的环境,请参考第一篇文章进行详细地安装。
创建应用并展示
安装包
#!pip3 install langchain导入包
from dotenv import load_dotenv
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import ElasticsearchStore
from langchain.text_splitter import CharacterTextSplitter
from langchain.prompts import ChatPromptTemplate
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.runnable import RunnableLambda
from langchain.schema import HumanMessage
from urllib.request import urlopen
import os, jsonload_dotenv()openai_api_key=os.getenv('OPENAI_API_KEY')
elastic_user=os.getenv('ES_USER')
elastic_password=os.getenv('ES_PASSWORD')
elastic_endpoint=os.getenv("ES_ENDPOINT")
elastic_index_name='langchain-rag'添加文档并将文档分成段落
with open('workplace-docs.json') as f:workplace_docs = json.load(f)print(f"Successfully loaded {len(workplace_docs)} documents")
metadata = []
content = []for doc in workplace_docs:content.append(doc["content"])metadata.append({"name": doc["name"],"summary": doc["summary"],"rolePermissions":doc["rolePermissions"]})text_splitter = CharacterTextSplitter(chunk_size=50, chunk_overlap=0)
docs = text_splitter.create_documents(content, metadatas=metadata)
Index Documents using ELSER - SparseVectorRetrievalStrategy()
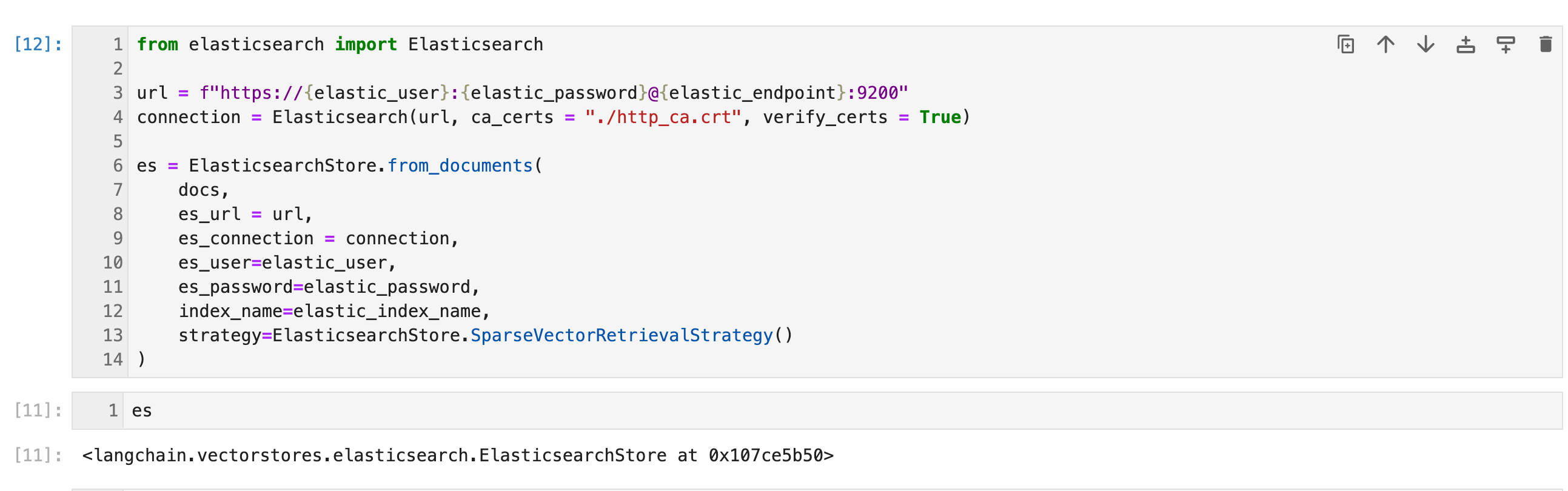
from elasticsearch import Elasticsearchurl = f"https://{elastic_user}:{elastic_password}@{elastic_endpoint}:9200"
connection = Elasticsearch(url, ca_certs = "./http_ca.crt", verify_certs = True)es = ElasticsearchStore.from_documents(docs,es_url = url,es_connection = connection,es_user=elastic_user,es_password=elastic_password,index_name=elastic_index_name,strategy=ElasticsearchStore.SparseVectorRetrievalStrategy()
)
如果你还没有配置好自己的 ELSER,请参考之前的文章 “ Elasticsearch:使用 Open AI 和 Langchain 的 RAG - Retrieval Augmented Generation (三)”。
在执行完上面的命令后,我们可以在 Kibana 中进行查看:
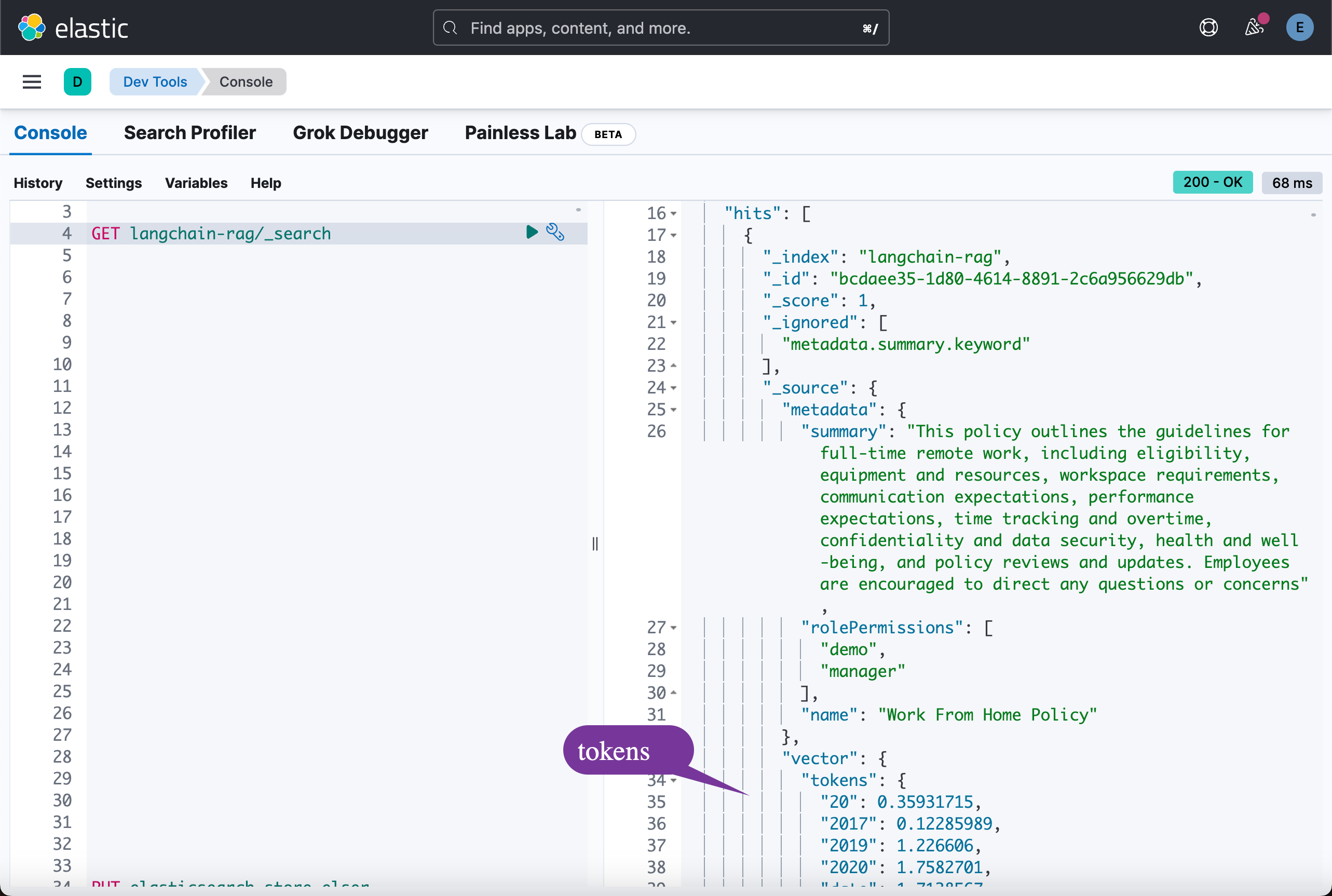
展示结果
def showResults(output):print("Total results: ", len(output))for index in range(len(output)):print(output[index])Search
r = es.similarity_search("work from home policy")
showResults(r)
RAG with Elasticsearch - Method 1 (Using Retriever)
retriever = es.as_retriever(search_kwargs={"k": 4})template = """Answer the question based only on the following context:
{context}Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)chain = ({"context": retriever, "question": RunnablePassthrough()} | prompt | ChatOpenAI() | StrOutputParser()
)chain.invoke("vacation policy")
RAG with Elasticsearch - Method 2 (Without Retriever)
Add Context
def add_context(question: str):r = es.similarity_search(question)context = "\n".join(x.page_content for x in r)return contextChain
template = """Answer the question based only on the following context:
{context}Question: {question}
"""prompt = ChatPromptTemplate.from_template(template)chain = ({"context": RunnableLambda(add_context), "question": RunnablePassthrough()}| prompt| ChatOpenAI()| StrOutputParser()
)chain.invoke("canada employees guidelines")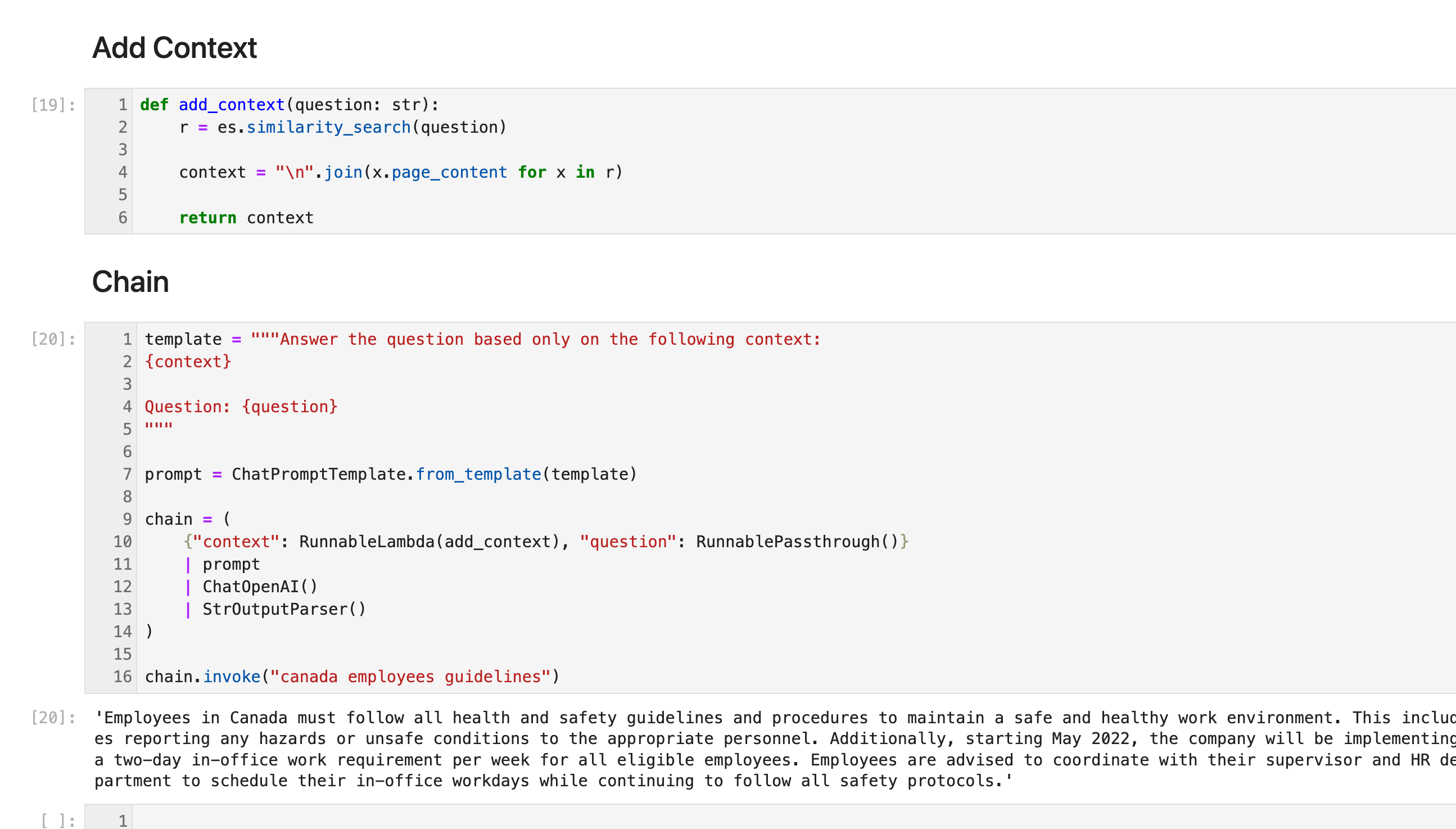
Compare with RAG and without RAG
q = input("Ask Question: ")## Question to OpenAIchat = ChatOpenAI()messages = [HumanMessage(content=q)
]gpt_res = chat(messages)# Question with RAGgpt_rag_res = chain.invoke(q)# Responsess = f"""
ChatGPT Response:{gpt_res}ChatGPT with RAG Response:{gpt_rag_res}
"""print(s)

上面的 jupyter notebook 的代码可以在地址 https://github.com/liu-xiao-guo/semantic_search_es/blob/main/RAG-langchain-elasticsearch.ipynb 下载。
相关文章:
Elasticsearch:使用 Open AI 和 Langchain 的 RAG - Retrieval Augmented Generation (四)
这篇博客是之前文章: Elasticsearch:使用 Open AI 和 Langchain 的 RAG - Retrieval Augmented Generation (一)Elasticsearch:使用 Open AI 和 Langchain 的 RAG - Retrieval Augmented Generation (二&a…...

YOLOv7优化:渐近特征金字塔网络(AFPN)| 助力小目标检测
💡💡💡本文改进:渐近特征金字塔网络(AFPN),解决多尺度削弱了非相邻 Level 的融合效果。 AFPN | 亲测在多个数据集能够实现涨点,尤其在小目标数据集。 收录: YOLOv7高阶自研专栏介绍: http://t.csdnimg.cn/tYI0c ✨✨✨前沿最新计算机顶会复现 🚀🚀🚀…...

J2EE项目部署与发布(Windows版本)
🎬 艳艳耶✌️:个人主页 🔥 个人专栏 :《Spring与Mybatis集成整合》《Vue.js使用》 ⛺️ 越努力 ,越幸运。 1.单机项目的部署 1.1们需要将要进行部署的项目共享到虚拟机中 在部署项目之前,我们先要检查一下…...

使用AWS Lambda函数的最佳实践!
主题 函数代码 函数配置 指标和警报 处理流 安全最佳实践 有关 Lambda 应用程序最佳实践的更多信息,请参阅 Serverless Land 中的 Application design。 函数代码 从核心逻辑中分离 Lambda 处理程序。这样您可以创建更容易进行单元测试的函数。在 Node.js 中…...

【计算机毕设小程序案例】基于SpringBoot的小演员招募小程序
前言:我是IT源码社,从事计算机开发行业数年,专注Java领域,专业提供程序设计开发、源码分享、技术指导讲解、定制和毕业设计服务 👉IT源码社-SpringBoot优质案例推荐👈 👉IT源码社-小程序优质案例…...

老年少女测试媛入职感想
作为一枚从事通信行业测试的老年少女测试媛,入职离职也有两三次了。现在又在一家企业入职了。虽然心里也清楚离职和入职,无非也就是从一个公司的坑里跳出来,再跳到另外一个公司的坑里罢了,明明知道老东家的坑是填不完的了…...
StreamSaver.js入门教程:优雅解决前端下载文件的难题
本文简介 点赞 关注 收藏 学会了 本文介绍一个能让前端优雅下载大文件的工具:StreamSaver.js ⚡️ StreamSaver.js GitHub地址⚡️ 官方案例 StreamSaver.js 可用于实现在Web浏览器中直接将大文件流式传输到用户设备的功能。 传统的下载方式可能导致大文件的加…...
element-ui vue2 iframe 嵌入外链新解
效果如图 实现原理 在路由中通过 props 传值 {path: /iframe,component: Layout,meta: { title: 小助手, icon: example },children: [{path: chatglm,name: chatglm,props: { name: chatglm,url: https://chatglm.cn },component: () > import(/views/iframe/common),me…...
win10 + VS2017 编译libjpeg(jpeg-9b)
需要用到的文件: jpeg-9b.zip win32.mak 下载链接链接:https://pan.baidu.com/s/1Z0fwbi74-ZSMjSej-0dV2A 提取码:huhu 步骤1:下载并解压jpeg-9b。 这里把jpeg-9b解压到文件夹"D:\build-libs\jpeg\build\jpeg-9b" …...
如何实现公网远程桌面访问Ubuntu?VNC+cpolar内网穿透!
文章目录 前言1. ubuntu安装VNC2. 设置vnc开机启动3. windows 安装VNC viewer连接工具4. 内网穿透4.1 安装cpolar【支持使用一键脚本命令安装】4.2 创建隧道映射4.3 测试公网远程访问 5. 配置固定TCP地址5.1 保留一个固定的公网TCP端口地址5.2 配置固定公网TCP端口地址5.3 测试…...

SpringMvc接收参数
接受参数:1.路径设置RequestMapping(value"地址",method"请求方式") 类|方法GetMapping PostMapping 方法2.接受参数[重点]param直接接收---handler(类型 形参名) 形参名请求参数名注解指定---handler(RequestParam(name"请求参…...
计算机网络文章荟萃
脑残式网络编程入门(二):我们在读写Socket时,究竟在读写什么?-网络编程/专项技术区 - 即时通讯开发者社区! 1.什么是 socket - 掘金2.socket 的实现原理 - 掘金本文讲述了 socket 在 linux 操作系统下的数据结构,以及阻塞 IO 利用…...
C# Socket通信从入门到精通(4)——多个异步TCP客户端C#代码实现
前言: 在之前的文章C# Socket通信从入门到精通(3)——单个异步TCP客户端C#代码实现我介绍了单个异步Tcp客户端的c#代码实现,但是有的时候,我们需要连接多个服务器,并且对于每个服务器,我们都有一些比如异步连接、异步发送、异步接收的操作,那么这时候我们使用之前单个…...
设置默认代码缩进(tabsize))
GitHub为自己的仓库(Repository)设置默认代码缩进(tabsize)
无意中发现GitHub默认显示tab为8个空格的大小,十分不适,故想改成四个字节的缩进 流程 GitHub是支持EditorConfig的。所有只需在Repository根目录下(注意不是.git文件夹下)新建文件 .editorconfig vim .editorconfig内容如下 # top-most EditorConfig…...
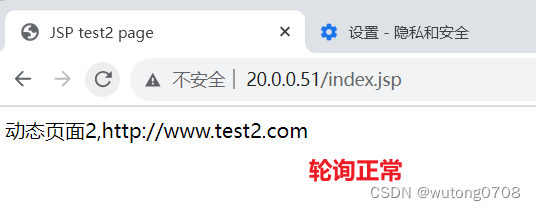
Tomcat的动静分离
一、动态负载均衡 3、台虚拟机模拟: 代理服务器:51 tomcat动态页面:53,54 关闭防火墙和安全机制 配置代理服务器,由于做的是七层代理,所以要在http模块配置 配置前端页面 <!DOCTYPE html> <html> <…...

Chimera:混合的 RLWE-FHE 方案
参考文献: [HS14] S. Halevi and V. Shoup. Algorithms in HElib. In Advances in Cryptology–CRYPTO 2014, pages 554–571. Springer, 2014.[HS15] S. Halevi and V. Shoup. Bootstrapping for HElib. In Advances in Cryptology–EUROCRYPT 2015, pages 641–6…...
MySQL 连接出现 Authentication plugin ‘caching_sha2_password的处理方法(使用第二种)
出现这个原因是mysql8 之前的版本中加密规则是mysql_native_password,而在mysql8之后,加密规则是caching_sha2_password, 解决问题方法有两种,一种是升级navicat驱动,一种是把mysql用户登录密码加密规则还原成mysql_native_password. 1. 升级MySQL版本 较早的MySQL版本可能不…...

设置Ubuntu 20.04的静态IP地址(wifi模式下)
一、引言 自己家用的Ubuntu的,重启后ip地址经常会改变,这个时候就需要我们手动配置静态IP了。 二、优点 给Ubuntu设置一个静态IP地址有以下几个好处: 持久性:静态IP地址是固定不变的,与设备的MAC地址绑定。这意味着…...
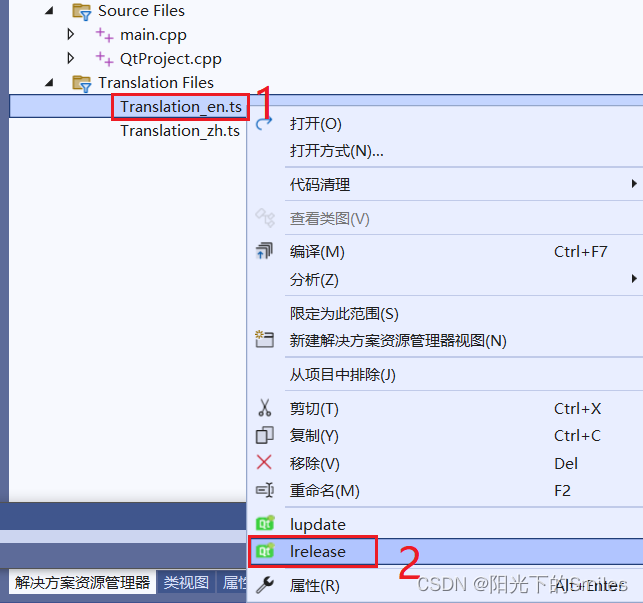
Qt界面实现中英文切换
要实现的效果,是下拉列表切换中文和English实现按钮文本中英文内容切换。 实现步骤: 1.在VS中鼠标对Translation Files文件右击,选择“添加”--->“模块”. 在弹窗的窗口中选择“Qt”--->“Qt Translation File”。 添加Translation_e…...

Python 编写确定个位、十位以上方法及各数位的和程序
Python 编写确定数字位方法 Python 编写确定个位、十位Python 编写确定个位、十位、百位方法解析:Python 各数位的和程序 利用%(取余符号)、//(整除)符号。 Python 编写确定个位、十位 num 17 a num % 10 b num /…...
实战选型指南)
别再乱用分支了!Flowable四种网关(排他/并行/包容/事件)实战选型指南
Flowable四大网关实战选型:从混乱到精准的决策艺术当你在设计一个请假审批流程时,是否遇到过这样的困惑:部门经理审批后需要同时通知HR和财务,但某些特殊情况下又需要跳过财务直接归档?这种看似简单的业务需求…...
)
从测速到配置:一套完整的cFosSpeed网络加速保姆级教程(适用于小白)
从零开始掌握cFosSpeed:网络加速全流程实战指南对于经常进行在线游戏、视频会议或大文件传输的用户来说,网络延迟和带宽利用率低下往往是影响体验的关键痛点。cFosSpeed作为一款专业的网络流量优化工具,能够显著改善这些问题,但许…...

深度学习从心电信号中解码呼吸频率:原理、实现与临床价值
1. 项目概述:从心电信号中“听”到呼吸声呼吸频率,这个我们每分钟都在进行却很少被精确量化的生命体征,在临床医学中扮演着至关重要的角色。它不仅是评估呼吸系统功能的直接指标,更是反映全身代谢、循环乃至神经系统状态的“窗口”…...

服务器日志分析实战:用Python追踪HTTP 404错误并可视化异常频率
作为一名爬虫开发者或网站运维人员,服务器日志就像飞机的“黑匣子”——它记录了每个请求的来龙去脉。而404错误(页面未找到)尤其值得关注:它可能是用户输错了网址,可能是你爬虫的URL构造逻辑有漏洞,也可能是网站改版后旧的链接失效了。更严重的是,大量突然涌出的404请求…...

串口通信粘包问题:成因深度解析与项目实战解决方案
在嵌入式开发、工业工控、上位机下位机交互项目中,串口(RS232/RS485)是最基础、最常用的通信方式。绝大多数开发者都遇到过这样的问题:串口接收的数据偶尔错乱、解析报错、数据拼接异常,单次接收的数据时而半包、时而多…...

echarts中heatmap鼠标滚动禁用缩放,向下滚动
配置如下效果如下...
)
别再只测accuracy!DeepSeek集成测试必须监控的5个隐性指标(P99首token延迟、context bleed率、tool-call schema漂移)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek集成测试的核心范式演进 DeepSeek大模型的工程化落地对集成测试提出了全新挑战:传统基于接口响应码与字段校验的测试范式已难以覆盖语义一致性、推理链鲁棒性、上下文敏感度等高阶质…...

从RD、CS到WK:一文讲透SAR主流成像算法的演进与选型实战
从RD、CS到WK:SAR成像算法选型实战指南 当无人机掠过灾区上空,或卫星扫描地球表面时,合成孔径雷达(SAR)正通过电磁波穿透云层和黑暗,将地面信息转化为高分辨率图像。而决定图像质量的关键,在于工…...

机器学习驱动储氢材料发现:从特征工程到DFT/MD验证的完整指南
1. 项目概述与核心思路氢能被视为未来清洁能源体系的关键一环,但如何安全、高效、经济地储存氢气,一直是制约其大规模应用的瓶颈。在众多储氢技术路线中,固态储氢,特别是基于金属氢化物的储氢材料,因其高体积储氢密度和…...

深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南
深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 在当今网络设备管理领域,获取设备完整控制…...