自动驾驶之—LaneAF学习相关总结
0.前言:
最近在学习自动驾驶方向的东西,简单整理一些学习笔记,学习过程中发现宝藏up 手写AI
1. 概述
Laneaf思想是把后处理放在模型里面。重点在于理解vaf, haf,就是横向聚类:中心点,纵向聚类:利用vaf学到的单位向量去预测下一行中心点与haf预测到的当前中心点做匹配,根据距离error阈值判断是否属于同一个lane id。主要了解标签和decode,decode就是标签制作的逆过程,decode部分主要是cost代价矩阵理解,loss针对正负样本不平衡,可以使用OHEM或者focal loss。
2. 算法结构
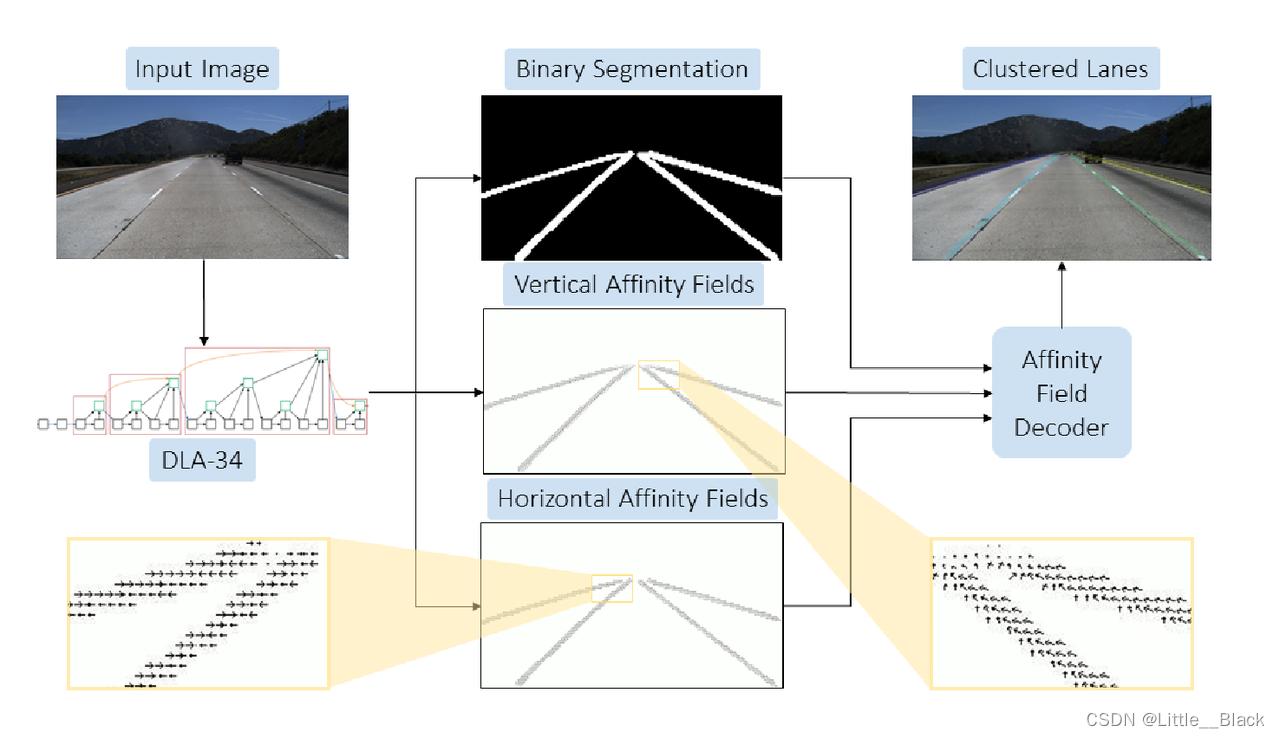
使用DLA-34作为Backbone,网络输出二值的分割结果、Vertical Affinity Field(VAF)和Horizontal Affinity Field(HAF)。其中:Affinity Field. 亲和域
使用HAF、VAF,结合二值分割结果(三个头可以产生一个实例),能够在后处理中对任意数量的车道线进行聚类,得到多个车道线实例。
3. Affinity Field 构建
给定图像中的每个位置 ( x , y ) (x,y) (x,y),HAF和VAF为每个位置分配一个向量,将HAF记作 H → ( ⋅ , ⋅ ) \overset{\rightarrow}H(\cdot,\cdot) H→(⋅,⋅),将VAF记作 V → ( ⋅ , ⋅ ) \overset{\rightarrow}V(\cdot,\cdot) V→(⋅,⋅)。
AF的生成都是从最下面一行往上面扫描
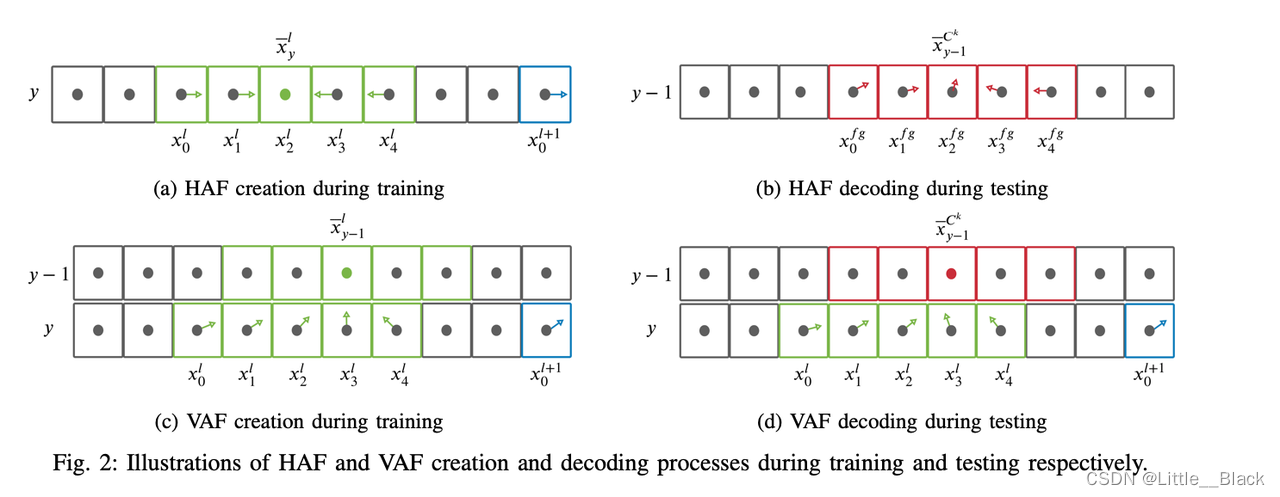
使用ground truth构建HAF和VAF,将ground truth到HAF和VAF的映射函数分别记作 H → g t ( ⋅ , ⋅ ) \overset{\rightarrow}H_{gt}(⋅,⋅) H→gt(⋅,⋅)和 V → g t ( ⋅ , ⋅ ) \overset{\rightarrow}V_{gt}(⋅,⋅) V→gt(⋅,⋅)。
对于图像第 y y y行中车道线 l l l所包含的每个点 ( x i l , y ) (x_i^l, y) (xil,y),HAF由下式得到:
H → g t ( x i l , y ) = ( x − y l − x i l ∣ x − y l − x i l ∣ , y − y ∣ y − y ∣ ) T = ( x − y l − x i l ∣ x − y l − x i l ∣ , 0 ) T \overset{\rightarrow}H_{gt}(x^l_i , y) = (\frac{{\overset{-} x}^l_y − x^l _i} {|{\overset{-} x}^l_ y − x^ l_ i | }, \frac{y − y}{ |y − y|})^T = (\frac{{\overset{-} x}^l_ y − x^l_i} {|{\overset{-} x}^ l_ y − x ^l _i | }, 0 )^T H→gt(xil,y)=(∣x−yl−xil∣x−yl−xil,∣y−y∣y−y)T=(∣x−yl−xil∣x−yl−xil,0)T
上式中的 x − y l \overset{-}x^l_y x−yl表示第 y y y行中属于车道线 l l l的所有点的横坐标平均值,求解HAF的过程如下图所示:
![[Image]](https://img-blog.csdnimg.cn/994db47f2f884001b465da0015fb6a85.png)
上图中绿色框表示属于车道线 l l l的点,蓝色框表示属于车道线 l + 1 l+1 l+1的点。箭头表示某个位置处HAF中的向量。
对于图像第 y y y行中属于车道线 l l l的每个点 ( x i l , y ) (x^l_i,y) (xil,y),VAF由下式得到:
V → g t ( x i l , y ) = ( x − y − 1 l − x i l ∣ x − y − 1 l − x i l ∣ , y − 1 − y ∣ y − 1 − y ∣ ) T = ( x − y − 1 l − x i l ∣ x − y − 1 l − x i l ∣ , − 1 ) T \overset{\rightarrow}V_{gt}(x^l_i , y) = (\frac{{\overset{-} x}^l_{y-1} − x^l _i} {|{\overset{-} x}^l_ {y-1} − x^ l_ i | }, \frac{y -1− y}{ |y -1− y|})^T = (\frac{{\overset{-} x}^l_ {y-1} − x^l_i} {|{\overset{-} x}^ l_ {y-1} − x ^l _i | }, -1)^T V→gt(xil,y)=(∣x−y−1l−xil∣x−y−1l−xil,∣y−1−y∣y−1−y)T=(∣x−y−1l−xil∣x−y−1l−xil,−1)T
上式中的 x − y − 1 l \overset{-}x^l_{y-1} x−y−1l示第 y − 1 y-1 y−1行中属于车道线 l l l的所有点的横坐标平均值。求解VAF的过程如下图所示:
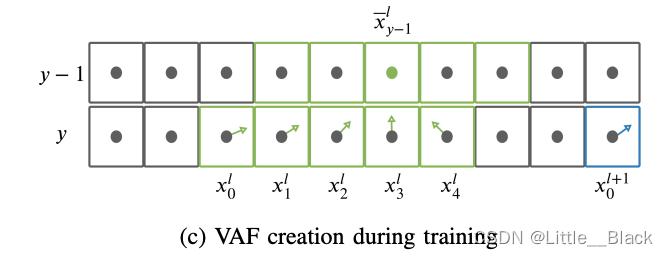
需要注意的是,VAF中每行的向量指向上一行中属于该车道线实例的点的平均位置。
- HAF parsing
水平方向的聚类就是逐行根据点的像素判断,直接根据两个邻近像素的HAF是否符合如下规则来判断是否属于同一个群组(cluster), 当然邻近像素如果相隔的位置超过设定的阈值,也会被分配到不同的cluster。
只有当前面像素指向左并且当前像素指向右时,才会为当前像素重新分配一个cluster,令 H → p r e d \overset{\rightarrow}H_{pred} H→pred表示HAF的预测结果, i i i表示列, y y y表示行。
c h a f ∗ ( x i f g , y − 1 ) = { C k + 1 i f H ⃗ p r e d ( x i − 1 f g , y − 1 ) 0 ≤ 0 ∧ H ⃗ p r e d ( x i f g , y − 1 ) 0 > 0 , C k otherwise, c_{haf}^*(x_i^{fg},y-1)=\begin{cases}C^{k+1}&\mathrm{if}\quad\vec{H}_{pred}(x_{i-1}^{fg},y-1)_0\leq0\\&\wedge\vec{H}_{pred}(x_i^{fg},y-1)_0>0,\\C^k&\text{otherwise,}&\end{cases} chaf∗(xifg,y−1)=⎩ ⎨ ⎧Ck+1CkifHpred(xi−1fg,y−1)0≤0∧Hpred(xifg,y−1)0>0,otherwise, - VAF parsing
那由haf聚类的clusters是怎么在行与行之间进行匹配呢?
这个时候VAF就派上用场了。前面我们提到过,VAF表示指向上一行车道线实例中心像素的单位向量,那么上一行车道线实例中心像素可以由两种方式计算得到,第一种方式是直接对cluster取平均,另外一种方式就是由active lane里的end points加上向量表示的平移得到,只不过网络预测出来的HAF是单位向量,需要考虑向量的模长而已。那这两种方式计算出来的结果都表示上一行车道线实例中心像素,它们之间的距离即可表示前面的误差。下面公式是在计算每一个线头坐标点结合vaf推算出来的点坐标与当前行的聚类点之间的dist_error。
d C k ( l ) = 1 N y l ∑ i = 0 N y l − 1 ∣ ∣ ( x ‾ C k , y − 1 ) ⊺ − ( x i l , y ) ⊺ − V ⃗ p r e d ( x i l , y ) ⋅ ∣ ∣ ( x ‾ C k , y − 1 ) ⊺ − ( x i l , y ) ⊺ ∣ ∣ ∣ ∣ \begin{aligned} d^{C^k}(l)=& \frac1{N_y^l}\sum_{i=0}^{N_y^l-1}\left|\left|(\overline{x}^{C^k},y-1)^\intercal-(x_i^l,y)^\intercal\right.\right. \\ &-\vec{V}_{pred}(x_i^l,y)\cdot||(\overline{x}^{C^k},y-1)^\intercal-(x_i^l,y)^\intercal||\bigg|\bigg| \end{aligned} dCk(l)=Nyl1i=0∑Nyl−1 (xCk,y−1)⊺−(xil,y)⊺−Vpred(xil,y)⋅∣∣(xCk,y−1)⊺−(xil,y)⊺∣∣ - label generate code
由于网络的AF分支会预测每个像素点的HAF和VAF,因此Affinity Fields需要作为ground truth来监督这一过程。算法流程也很简单,自底向上逐行扫描,在每一行对属于当前车道线实例的像素点按照计算HAF和VAF,即为当前像素点的Affinity Fields编码。
VAF,HAF,label,模型监督三者,知道三者可以反向求解
这段代码定义了一个名为generateAFs的函数,它的目的是为输入的车道标签图生成锚帧(AFs)。代码中涉及两种锚帧:垂直锚帧(VAF)和水平锚帧(HAF)。
def generateAFs(label, viz=False):# 创建透视场数组num_lanes = np.amax(label) # 获取车道线的数量VAF = np.zeros((label.shape[0], label.shape[1], 2)) # 垂直透视场HAF = np.zeros((label.shape[0], label.shape[1], 1)) # 水平透视场# 对每条车道线进行循环处理for l in range(1, num_lanes+1):# 初始化先前的行和列值prev_cols = np.array([], dtype=np.int64)prev_row = label.shape[0]# 从下到上解析每一行for row in range(label.shape[0]-1, -1, -1):# [0] :np.where 返回一个元组,其每一维都是一个数组,表示该维度上满足条件的索引。# 在这里,我们只关心列索引,所以我们取出这个元组的第一个元素cols = np.where(label[row, :] == l)[0] # 获取当前行的前景列值(即车道线位置)# 为每个列值生成水平方向向量for c in cols:if c < np.mean(cols):HAF[row, c, 0] = 1.0 # 向右指示elif c > np.mean(cols):HAF[row, c, 0] = -1.0 # 向左指示else:HAF[row, c, 0] = 0.0 # 保持不变 # 检查先前的列和当前的列是否都非空if prev_cols.size == 0: # 如果没有先前的行/列,更新并继续prev_cols = colsprev_row = rowcontinueif cols.size == 0: # 如果当前没有列,继续continuecol = np.mean(cols) # 计算列的均值# 为先前的列生成垂直方向向量for c in prev_cols:# 计算方向向量的位置vec = np.array([col - c, row - prev_row], dtype=np.float32)# 单位标准化vec = vec / np.linalg.norm(vec) # 标准化为单位向量 # 模VAF[prev_row, c, 0] = vec[0]VAF[prev_row, c, 1] = vec[1] # 具有像两方向的增值# 使用当前的行和列值更新先前的行和列值prev_cols = colsprev_row = row
decode code
cost矩阵:
当提到“建立每条线与头坐标与当前行聚类点之间的cost矩阵”,这很有可能是在一个场景中,例如图像或传感器数据处理,你想要在平面上追踪或匹配多个线对象。让我为你详细解释一下。
背景概念
- 线对象:这可能是在图像或其他数据源中检测到的直线或曲线。
- 头坐标:每条线的起始点或参考点。
- 当前行的聚类点:这可能是在某一特定行(水平方向)上检测到的点,它们可能是由于某种特性(例如颜色、强度等)而被聚类在一起的。
- 目的:为了确定哪条线与哪个聚类点最为匹配或最为接近,你需要计算每个线与聚类点之间的距离或相似度。Cost矩阵就是用来存储这些计算结果的。
- 矩阵形状:假设你有m条线和n个聚类点,那么你的cost矩阵将是一个m x n的矩阵。
- 元素的值:矩阵中的每个元素代表一条线与一个聚类点之间的“cost”。这个“cost”可以是他们之间的距离、差异或其他度量方式。较低的cost意味着线和点之间的匹配度较高;较高的cost意味着匹配度较低。
应用
一旦你有了cost矩阵,你可以使用一些优化算法(如匈牙利算法)来确定最佳的匹配方式,这样每条线都将与一个聚类点匹配,以最小化总体的cost。
简而言之,通过构建一个cost矩阵,你可以量化每条线与每个聚类点之间的关系,并使用这个矩阵来找出最佳的匹配方案。

AF loss
语义分割图:分类损失+iou 损失;
AF损失: 回归损失;
L B C E = − 1 N ∑ i [ w ⋅ t i ⋅ l o g ( o i ) + ( 1 − t i ) ⋅ l o g ( 1 − o i ) ] L_{BCE}=-\frac1N\sum_i\left[w\cdot t_i\cdot log(o_i)+(1-t_i)\cdot log(1-o_i)\right] LBCE=−N1i∑[w⋅ti⋅log(oi)+(1−ti)⋅log(1−oi)]
L I o U = 1 N ∑ i [ 1 − t i ⋅ o i t i + o i − t i ⋅ o i ] L_{IoU}=\frac1N\sum_i\left[1-\frac{t_i\cdot o_i}{t_i+o_i-t_i\cdot o_i}\right] LIoU=N1i∑[1−ti+oi−ti⋅oiti⋅oi]
L A F = 1 N f g ∑ i [ ∣ t i h a f − o i h a f ∣ + ∣ t i v a f − o i v a f ∣ ] L_{AF}=\frac1{N_{fg}}\sum_i\left[|t_i^{haf}-o_i^{haf}|+|t_i^{vaf}-o_i^{vaf}|\right] LAF=Nfg1i∑[∣tihaf−oihaf∣+∣tivaf−oivaf∣]
相关文章:
自动驾驶之—LaneAF学习相关总结
0.前言: 最近在学习自动驾驶方向的东西,简单整理一些学习笔记,学习过程中发现宝藏up 手写AI 1. 概述 Laneaf思想是把后处理放在模型里面。重点在于理解vaf, haf,就是横向聚类:中心点,纵向聚类&…...
)
软考系统架构之案例篇(Redis相关概念)
案例篇-Redis相关概念 1. Redis与Memcache能力对比2. Redis集群切片的常见方式3. Redis分布式存储方案4. Redis数据分片方案5. Redis持久化 1. Redis与Memcache能力对比 工作MemCacheRedis数据类型简单 key/value 结构丰富的数据结构持久性不支持支持分布式存储客户端哈希分片…...

黑客入门指南,学习黑客必须掌握的技术
黑客一词,原指热心于计算机技术,水平高超的电脑专家,尤其是程序设计人员。是一个喜欢用智力通过创造性方法来挑战脑力极限的人,特别是他们所感兴趣的领域,例如电脑编程等等。 提起黑客,总是那么神秘莫测。在…...

定档11月2日,YashanDB 2023年度发布会完整议程公布
数据库作为支撑核心业务的关键技术,对数字经济的发展有着重要的支撑作用,随着云计算、AI等技术的迅猛发展和数据量的爆发式增长,推动着数据库技术的加速创新。 为了应对用户日益复杂的数据管理需求,赋能行业国产化建设和数字化转型…...
composer安装thinkphp6报错
composer安装thinkphp6报错, 查看是否安装了对应的PHP扩展,我这边使用的是宝塔的环境,全程可以可视化操作 这样就可以安装完成了...
此页面不能正确地重定向
这种是由于条件判断有误,程序不断的重定向到一个页面,而造成的死循环的情况 下面列举一个常出现的场景之一 1、使用过滤器实现登录验证错误处理 解释:当用户访问login.jsp进行登录的时候,这个时候请求会被Filter捕获࿰…...

【Apache Flink】实现有状态函数
文章目录 在RuntimeContext 中声明键值分区状态通过ListCheckPonitend 接口实现算子列表状态使用CheckpointedFunction接口接收检查点完成通知参考文档 在RuntimeContext 中声明键值分区状态 Flink为键值分区状态(Keyed State)提供了几种不同的原语&…...
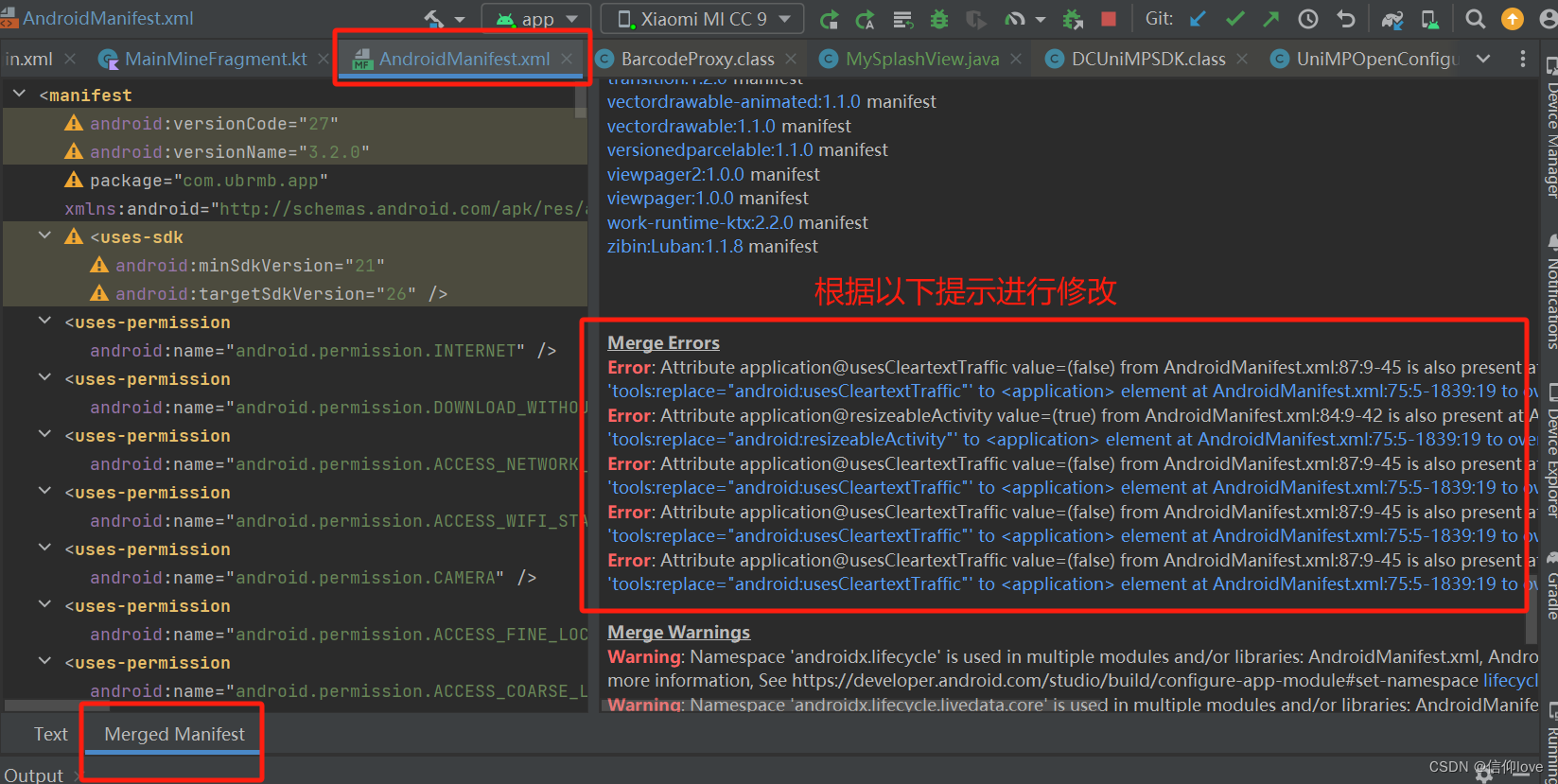
Android原生项目集成uniMPSDK(Uniapp)遇到的报错总结
uni小程s序SDK 集成到Android原生项目:老项目中用到的库较多,会出现几种冲突问题,总结如下: 报错1: Execution failed for task :app:processDebugManifest. > Manifest merger failed with multiple errors, see logs Andro…...

Linux redis 安装
1、解压 tar -zxvf redis-5.0.10.tar.gz 2、cd /data/redis-5.0.10 文件夹 3、make 等待make命令执行完成即可。 make命令报错:cc 未找到命令,系统中缺少gcc,执行命令安装 gcc: yum -y install gcc automake autocon…...
在Win11上部署ChatGLM3详细步骤
023年10月27日,智谱AI于2023中国计算机大会(CNCC)上,推出了全自研的第三代基座大模型ChatGLM3及相关系列产品,这也是智谱AI继推出千亿基座的对话模型ChatGLM和ChatGLM2之后的又一次重大突破。此次推出的ChatGLM3采用了…...

系列七、动态代理
一、概述 二、Jdk动态代理案例 2.1、Star /*** Author : 一叶浮萍归大海* Date: 2023/10/27 17:16* Description:*/ public interface Star {/*** 唱歌* param name 歌曲名字* return*/String sing(String name);/*** 跳舞*/void dance(); } 2.2、BigStar /*** Author : 一叶…...
Kafka集群搭建与SpringBoot项目集成
本篇文章的目的是帮助Kafka初学者快速搭建一个Kafka集群,以及怎么在SpringBoot项目中使用Kafka。 kafka集群环境包地址:百度网盘 请输入提取码 提取码:x9yn 一、Kafka集群搭建 1、准备环境 (1)准备三台…...
)
一个简单的注册的页面,如有错误请指正;(3.JavaScript)
这段代码是一个JavaScript函数,实现了用户登录和上传图片的功能,并包含了一些辅助函数。让我一一解释: 1. login():这个函数用于登录操作。首先,通过$(#name).val()来获取ID为name的元素的值,同理获取其他…...
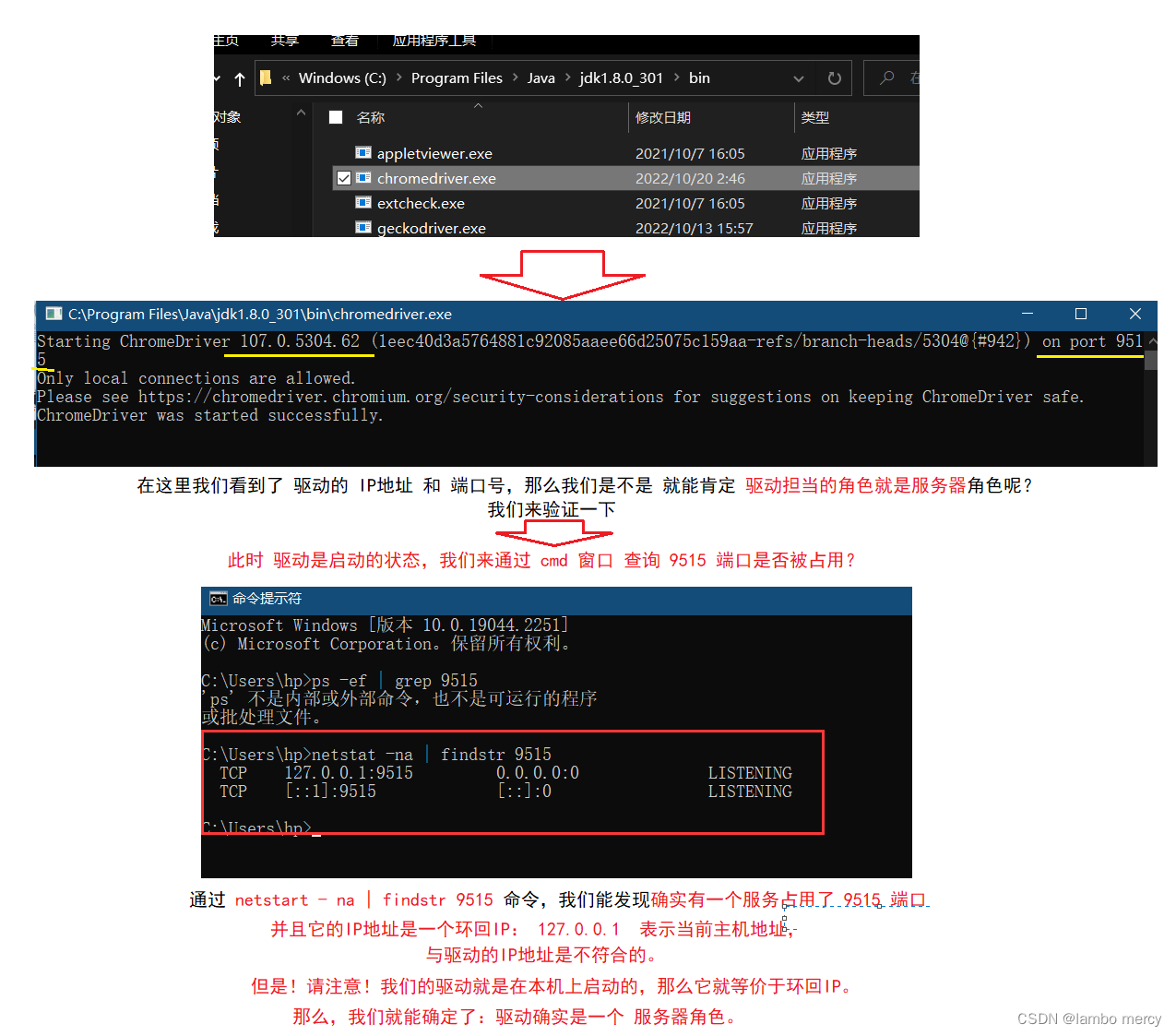
selenium (自动化概念 测试环境配置)
什么是自动化测试 自动化测试介绍 自动化测试指软件测试的自动化,在预设状态下运行应用程序或者系统. 预设条件包括正常和异常,最后评估运行结果。 自动化测试,就是将人为驱动的测试行为转化为机器执行的过程。 【机器 代替 人工】 自动化…...
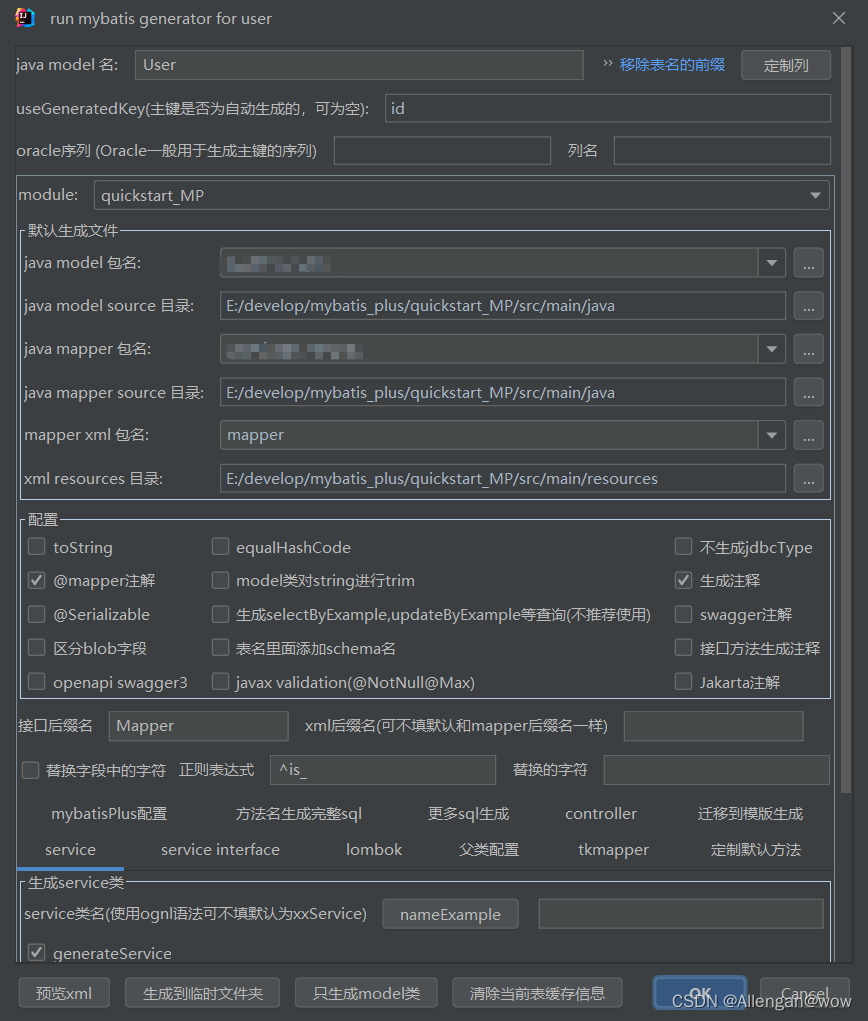
Mybatis-Plus(企业实际开发应用)
一、Mybatis-Plus简介 MyBatis-Plus是MyBatis框架的一个增强工具,可以简化持久层代码开发MyBatis-Plus(简称 MP)是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。 官网&a…...
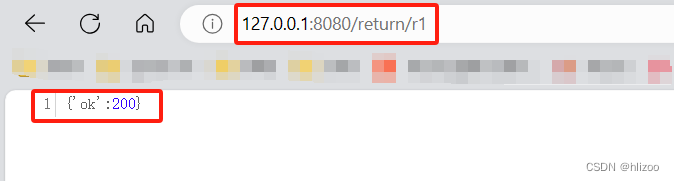
Spring Web MVC入门
一:了解Spring Web MVC (1)关于Java开发 🌟Java开发大多数场景是业务开发 比如说京东的业务就是电商卖货、今日头条的业务就推送新闻;快手的业务就是短视频推荐 (2)Spring Web MVC的简单理解 💗Spring Web MVC:如何使…...
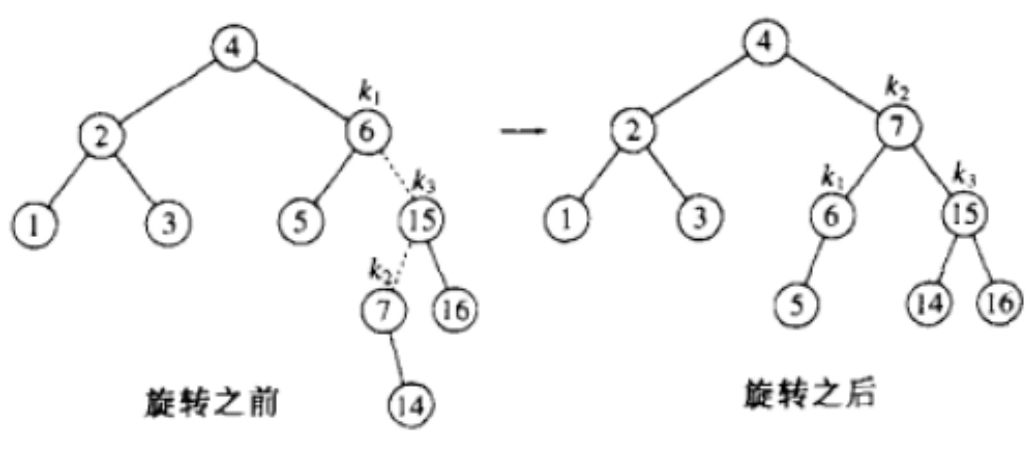
【C++】mapset的底层结构 -- AVL树(高度平衡二叉搜索树)
前面我们对 map / multimap / set / multiset 进行了简单的介绍,可以发现,这几个容器有个共同点是:其底层都是按照二叉搜索树来实现的。 但是二叉搜索树有其自身的缺陷,假如往树中插入的元素有序或者接近有序,二叉搜索…...
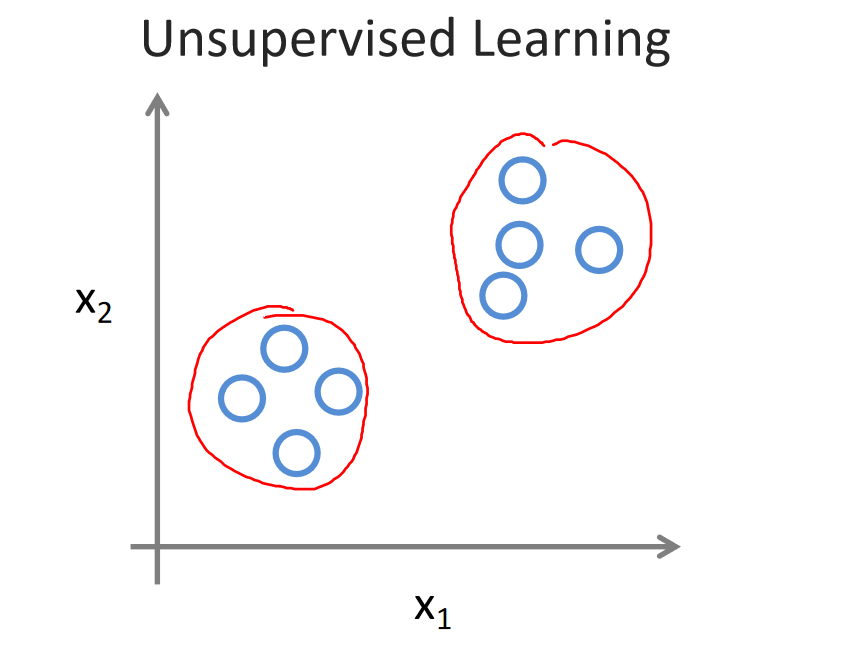
吴恩达《机器学习》1-4:无监督学习
一、无监督学习 无监督学习就像你拿到一堆未分类的东西,没有标签告诉你它们是什么,然后你的任务是自己找出它们之间的关系或者分成不同的组,而不依赖于任何人给你关于这些东西的指导。 以聚类为例,无监督学习算法可以将数据点分成…...
)
一个简单的注册页面,如有错误请指正(2.css)
这段CSS代码定义了页面的样式,让我逐个解释其功能: 1. * {}:通配符选择器,用于将页面中的所有元素设置统一的样式。这里将margins和paddings设置为0,以去除默认的边距。 2. div img {}:选择页面中所有div…...

【Unity精华一记】特殊文件夹
👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 收录于专栏:uni…...

别再手动改路径了!用LabVIEW + MATLAB Script做自动化测试,这份环境配置指南让你效率翻倍
LabVIEW与MATLAB深度整合:构建自动化测试系统的工程实践指南在工业自动化与测试测量领域,LabVIEW和MATLAB的组合堪称黄金搭档。LabVIEW擅长硬件接口和实时控制,而MATLAB在算法开发和数据分析方面具有无可比拟的优势。本文将深入探讨如何将两者…...

2026年HR招聘偏好白皮书:这5项附加技能出现频率暴涨
2026 年的招聘市场,正在从“看你会什么岗位技能”,转向“看你能不能把岗位做得更智能”。HR筛简历时,越来越关注候选人的AI应用能力、数据化思维和业务落地能力。人社部近年发布的新职业中,已经出现生成式人工智能系统应用员、人工…...

从Office功能区的“局外人“到“掌控者“:Office RibbonX Editor深度指南
从Office功能区的"局外人"到"掌控者":Office RibbonX Editor深度指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/g…...

ESP32多任务水位监测:从Arduino到ESP-IDF的FreeRTOS实战
1. 项目概述:从Arduino到ESP-IDF的跃迁去年我在做毕业设计时,为了搭建一个ESP32的传感器节点演示程序,第一次深入使用了FreeRTOS。那段时间,我几乎天天和任务调度、队列、信号量打交道,从最初的一头雾水到后来能流畅地…...

Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器
Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是否曾经在MacBook的触控板和鼠标之间切换时࿰…...

HarmonyOS ArkTS DateUtil 日期增减与日历计算完整指南
文章目录 背景一、引言二、日期增减方法详解使用示例 三、日历计算方法详解四、Demo 演示:日期增减结果展示五、Demo 演示:月历视图完整实现六、日历视图关键点解析为什么要填充前置空格?getLastDayOfMonth 的实现技巧 七、小结 背景 近期发现…...
)
CentOS 8.5最小化安装后,这5个必做的安全与效率优化设置(附一键脚本)
CentOS 8.5最小化安装后的5个必做安全与效率优化刚完成CentOS 8.5最小化安装的系统就像一张白纸——干净但缺乏生产力。作为运维老手,我见过太多人跳过基础优化直接部署应用,结果在后续使用中频繁遇到权限混乱、软件安装慢、SSH爆破等问题。本文将分享我…...

解决claude code频繁封号与token不足的taotoken接入方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code频繁封号与Token不足的Taotoken接入方案 1. 问题背景:Claude Code用户面临的挑战 对于依赖Claude Cod…...

Facebook登录协议逆向解析:appsecret_proof与e2e加密机制
1. 这不是“爬虫教程”,而是一次对现代Web身份协议的解剖实验你有没有试过,在调试一个Facebook登录集成时,浏览器Network面板里突然冒出一串带sig、access_token、e2e、c_user的请求,参数长度动辄上千字符,加密方式五花…...

从Figma设计到Python GUI:Tkinter-Designer如何重塑可视化开发范式
从Figma设计到Python GUI:Tkinter-Designer如何重塑可视化开发范式 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发领域&am…...