Kafka集群搭建与SpringBoot项目集成
本篇文章的目的是帮助Kafka初学者快速搭建一个Kafka集群,以及怎么在SpringBoot项目中使用Kafka。
kafka集群环境包地址:百度网盘 请输入提取码 提取码:x9yn

一、Kafka集群搭建
1、准备环境
(1)准备三台LINUX服务器:
xxx.xxx.xxx.1
xxx.xxx.xxx.2
xxx.xxx.xxx.3
(2)jdk版本大于1.8即可,我是1.8.0_181
(3)在三台服务器上创建用户admin,将环境放到admin用户下,嫌麻烦的同学也可以直接使用root用户安装(真实生产上不建议这么做)
tips:LINUX怎么给普通用户赋文件夹操作权限?
- 切换到root用户
- 使用chown -R admin:admin /home/admin命令
- 执行su - admin命令就可以切换用户并定位到/home/admin下
(4)一定要关闭三台服务器的防火墙,不然安装肯定会出问题,切记!这个真的很重要!
2、搭建Zookeeper集群
(1)解压zookeeper-3.4.12.tar.gz,进入zookeeper文件夹

(2)进入conf文件夹
1)复制zoo.cfg文件 cp zoo.cfg zoo_sample.cfg2)修改zoo.cfg文件 vim zoo.cfg

这里的3个IP的作用如下:
2181:对cline端提供服务
3888:选举leader使用
2888:集群内机器通讯使用(Leader监听此端口)
(3)进入data文件夹,若没有自己创建一个
在data文件夹下创建myid文件,三台机器分别填入server对应的ID,这里我是1、2、3

(4)启动zookeeper集群
- 1. 启动ZK服务: sh bin/zkServer.sh start
- 2. 查看ZK服务状态: sh bin/zkServer.sh status
- 3. 停止ZK服务: sh bin/zkServer.sh stop
- 4. 重启ZK服务: sh bin/zkServer.sh restart
(5)三台机器都需要重复上述操作,注意myid中的ID要对应
3、搭建Kafka集群
(1)解压kafka_2.12-2.5.0.tgz,进入kafka文件夹

(2)进入config文件夹,修改 server.properties内容
# Kafka使用唯一的一个整数来标识每个broker,该参数默认是-1。如果不指定,kafka会自动生成一个唯一值
broker.id=1
# broker监听器的CSV列表,格式是[协议]://[主机名]:[端口]。
listeners=PLAINTEXT://xxx.xxx.xxx.1:9092
# 非常重要的参数!该参数指定了kafka持久化消息的目录。该参数可以设置多个目录,以逗号分隔,比如/home/kafka1,/home/kafka2,多目录的做法是推荐的
log.dirs=/tmp/kafka-logs
# 同样是很重要的参数!这个参数完全没有默认值,是必须要自己设置的
zookeeper.connect=xxx.xxx.xxx.1:2181,xxx.xxx.xxx.2:2181,xxx.xxx.xxx.3:2181
# 是否开启unclean leader选举。由于开始可能不能保证数据一致性,所以设置为false
unclean.leader.election.enable=false
# topic 在当前 broker 上的分区个数
num.partitions=1
# 用来恢复和清理 data 下数据的线程数量
num.recovery.threads.per.data.dir=1
# segment文件保留的最长时间,超时将被删除
log.retention.hours=16
# 删除 topic 功能使能 ( 允许删除数据 ) ( 手动指定 )
delete.topic.enable=true
# 处理网络请求的线程数量
num.network.threads=3
# 用来处理磁盘 IO 的线程数量
num.io.threads=8
# 发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
# 接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
# 请求套接字的缓冲区大小
socket.request.max.bytes=10485760(3)配置环境变量
vim ~/.bash_profile
# KAFKA_HOME
export KAFKA_HOME=/export/servers/kafka_2.11-0.11.0.0
export PATH=$PATH:$KAFKA_HOME/bin(4)启动kafka集群
启动 :bin/kafka-server-start.sh config/server.properties &
关闭 :bin/kafka-server-stop.sh stop
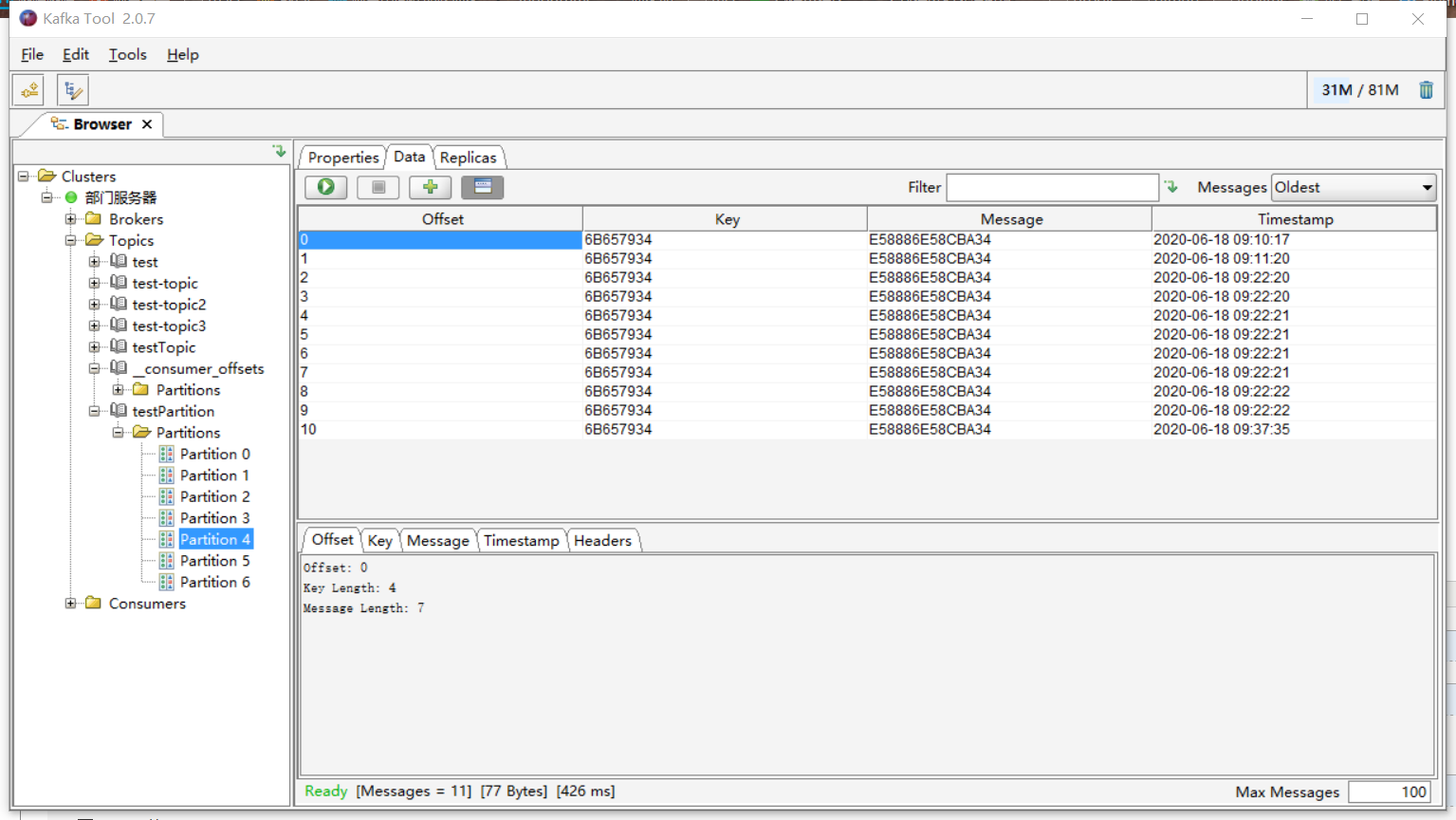
二、使用kafkatool工具操作Kafka
这里提供一篇详细操作:https://www.cnblogs.com/frankdeng/p/9452982.html
三、Kafka与SpringBoot集成
1、pom.xml导入
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.3.0.RELEASE</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.sunyard.bigdata</groupId><artifactId>springbootkafka</artifactId><version>0.0.1-SNAPSHOT</version><name>springbootkafka</name><description>Demo project for Spring Boot</description><properties><java.version>1.8</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope><exclusions><exclusion><groupId>org.junit.vintage</groupId><artifactId>junit-vintage-engine</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka-test</artifactId><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>2、application.properties配置
server.port=9001
spring.application.name=kafka#### kafka配置生产者 begin ####
# 指定kafka server的地址,集群配多个,中间,逗号隔开
spring.kafka.bootstrap-servers=xxx.xxx.xxx.1:9092,xxx.xxx.xxx.2:9092,xxx.xxx.xxx.3:9092
# 写入失败时,重试次数。当leader失效,一个repli节点会替代成为leader节点,此时可能出现写入失败,
# 当retris为0时,produce不会重复。retirs重发,此时repli节点完全成为leader节点,不会产生消息丢失。
spring.kafka.producer.retries=0
# 每次批量发送消息的数量,produce积累到一定数据,一次发送
spring.kafka.producer.batch-size=16384
# produce积累数据一次发送,缓存大小达到buffer.memory就发送数据
spring.kafka.producer.buffer-memory=33554432
#procedure要求leader在考虑完成请求之前收到的确认数,用于控制发送记录在服务端的持久化,其值可以为如下:
#acks = 0 如果设置为零,则生产者将不会等待来自服务器的任何确认,该记录将立即添加到套接字缓冲区并视为已发送。在这种情况下,无法保证服务器已收到记录,并且重试配置将不会生效(因为客户端通常不会知道任何故障),为每条记录返回的偏移量始终设置为-1。
#acks = 1 这意味着leader会将记录写入其本地日志,但无需等待所有副本服务器的完全确认即可做出回应,在这种情况下,如果leader在确认记录后立即失败,但在将数据复制到所有的副本服务器之前,则记录将会丢失。
#acks = all 这意味着leader将等待完整的同步副本集以确认记录,这保证了只要至少一个同步副本服务器仍然存活,记录就不会丢失,这是最强有力的保证,这相当于acks = -1的设置。
#可以设置的值为:all, -1, 0, 1
spring.kafka.producer.acks=1
# 指定消息key和消息体的编解码方式
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
#### kafka配置生产者 end ######## kafka配置消费者 start ####
# 指定默认消费者group id --> 由于在kafka中,同一组中的consumer不会读取到同一个消息,依靠groud.id设置组名
spring.kafka.consumer.group-id=test1
# smallest和largest才有效,如果smallest重新0开始读取,如果是largest从logfile的offset读取。一般情况下我们都是设置smallest
spring.kafka.consumer.auto-offset-reset=earliest
# enable.auto.commit:true --> 设置自动提交offset
spring.kafka.consumer.enable-auto-commit=true
#如果'enable.auto.commit'为true,则消费者偏移自动提交给Kafka的频率(以毫秒为单位),默认值为5000。
spring.kafka.consumer.auto-commit-interval=1000
# 指定消息key和消息体的编解码方式
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
#### kafka配置消费者 end ####3、启动类代码
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.kafka.annotation.EnableKafka;@SpringBootApplication
@EnableKafka
public class SpringbootkafkaApplication {public static void main(String[] args) {SpringApplication.run(SpringbootkafkaApplication.class, args);}
}4、生产者代码
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.*;@RestController
@RequestMapping("/api/kafka/")
public class KafkaController {@Autowiredprivate KafkaTemplate<String, Object> kafkaTemplate;@GetMapping("send")@ResponseBodypublic boolean send(@RequestParam String message) {try {kafkaTemplate.send("test-topic", message);kafkaTemplate.send("test-topic2", message);System.out.println("消息发送成功...");} catch (Exception e) {e.printStackTrace();}return true;}@GetMapping("test")@ResponseBodypublic String test() {System.out.println("hello world!");return "ok";}
}5、消费者代码
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;@Component
public class ConsumerListener {@KafkaListener(topics = "test-topic")public void onMessage1(String message) {System.out.println("我是第一个消费者:" + message);}@KafkaListener(topics = "test-topic2")public void onMessage2(String message) {System.out.println("我是第二个消费者:" + message);}
}相关文章:
Kafka集群搭建与SpringBoot项目集成
本篇文章的目的是帮助Kafka初学者快速搭建一个Kafka集群,以及怎么在SpringBoot项目中使用Kafka。 kafka集群环境包地址:百度网盘 请输入提取码 提取码:x9yn 一、Kafka集群搭建 1、准备环境 (1)准备三台…...
)
一个简单的注册的页面,如有错误请指正;(3.JavaScript)
这段代码是一个JavaScript函数,实现了用户登录和上传图片的功能,并包含了一些辅助函数。让我一一解释: 1. login():这个函数用于登录操作。首先,通过$(#name).val()来获取ID为name的元素的值,同理获取其他…...
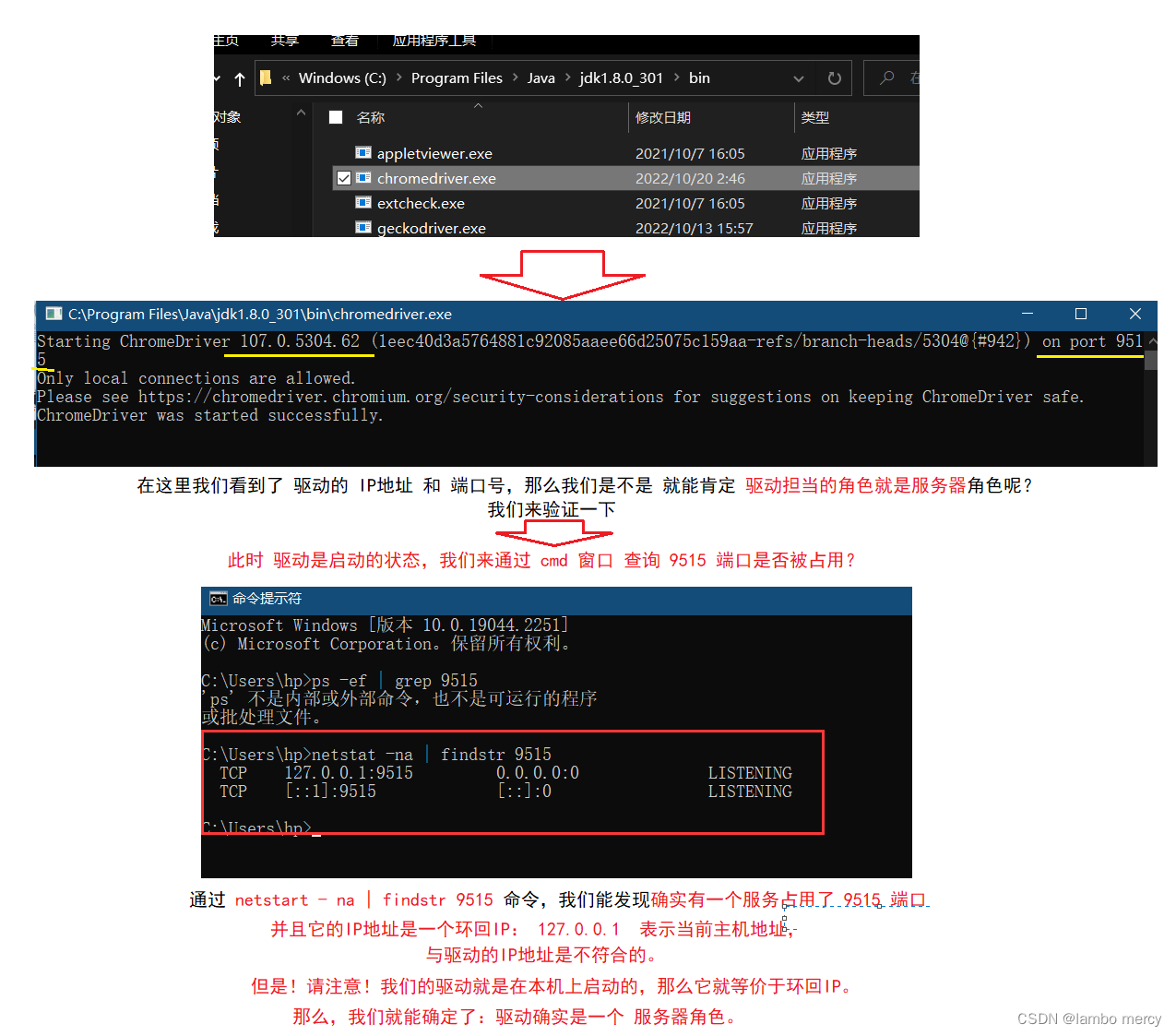
selenium (自动化概念 测试环境配置)
什么是自动化测试 自动化测试介绍 自动化测试指软件测试的自动化,在预设状态下运行应用程序或者系统. 预设条件包括正常和异常,最后评估运行结果。 自动化测试,就是将人为驱动的测试行为转化为机器执行的过程。 【机器 代替 人工】 自动化…...
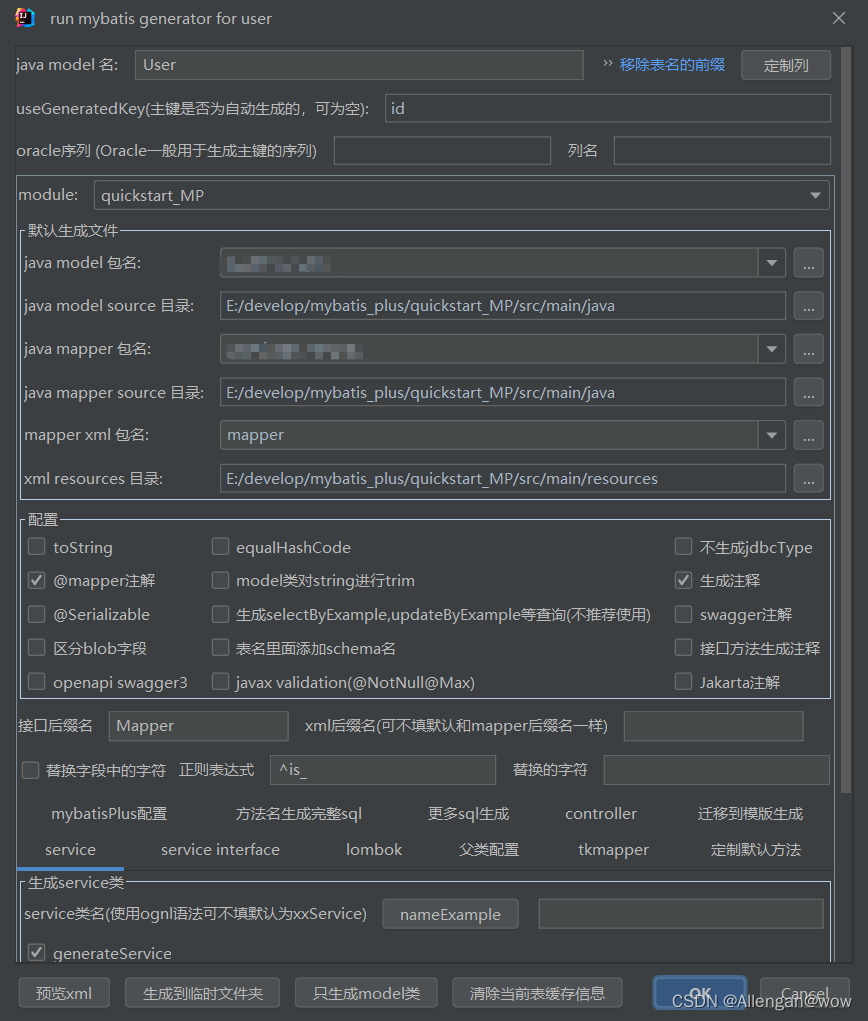
Mybatis-Plus(企业实际开发应用)
一、Mybatis-Plus简介 MyBatis-Plus是MyBatis框架的一个增强工具,可以简化持久层代码开发MyBatis-Plus(简称 MP)是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。 官网&a…...
Spring Web MVC入门
一:了解Spring Web MVC (1)关于Java开发 🌟Java开发大多数场景是业务开发 比如说京东的业务就是电商卖货、今日头条的业务就推送新闻;快手的业务就是短视频推荐 (2)Spring Web MVC的简单理解 💗Spring Web MVC:如何使…...
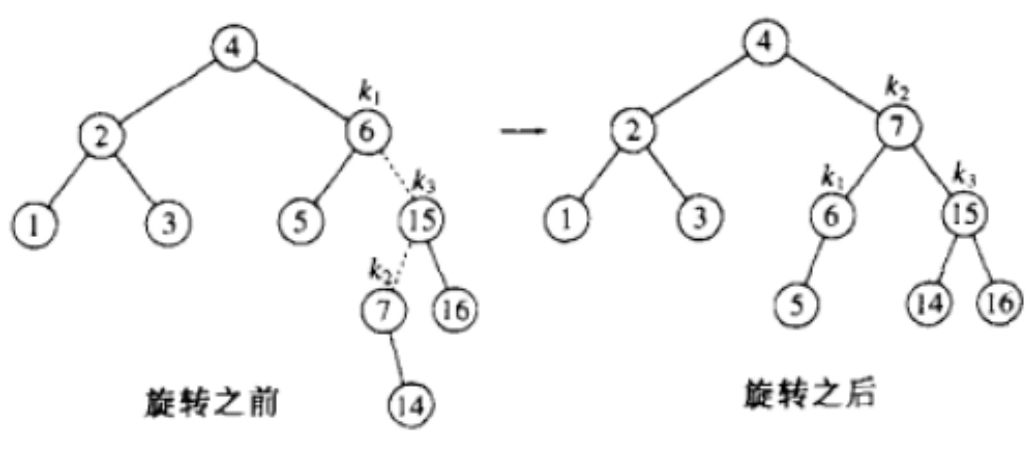
【C++】mapset的底层结构 -- AVL树(高度平衡二叉搜索树)
前面我们对 map / multimap / set / multiset 进行了简单的介绍,可以发现,这几个容器有个共同点是:其底层都是按照二叉搜索树来实现的。 但是二叉搜索树有其自身的缺陷,假如往树中插入的元素有序或者接近有序,二叉搜索…...
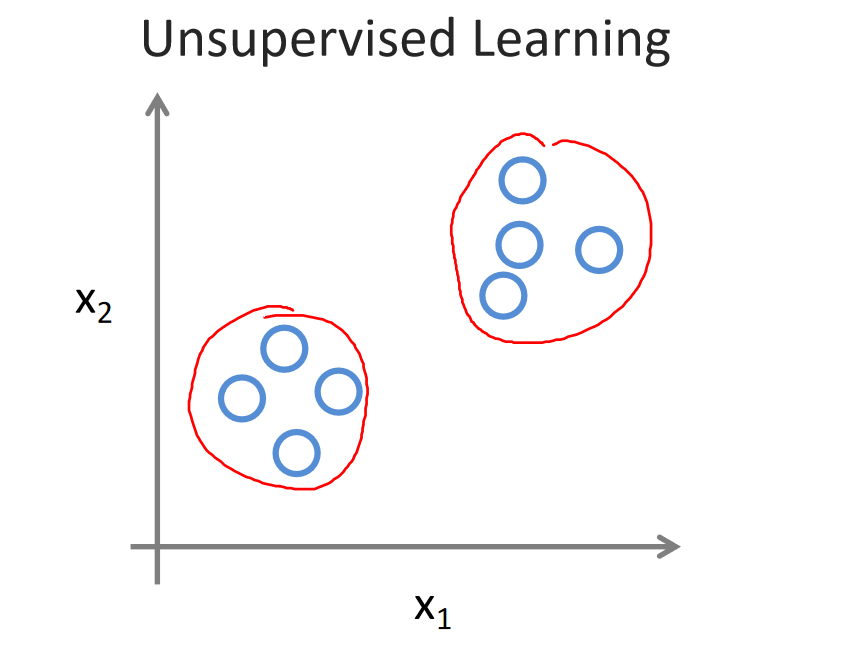
吴恩达《机器学习》1-4:无监督学习
一、无监督学习 无监督学习就像你拿到一堆未分类的东西,没有标签告诉你它们是什么,然后你的任务是自己找出它们之间的关系或者分成不同的组,而不依赖于任何人给你关于这些东西的指导。 以聚类为例,无监督学习算法可以将数据点分成…...
)
一个简单的注册页面,如有错误请指正(2.css)
这段CSS代码定义了页面的样式,让我逐个解释其功能: 1. * {}:通配符选择器,用于将页面中的所有元素设置统一的样式。这里将margins和paddings设置为0,以去除默认的边距。 2. div img {}:选择页面中所有div…...

【Unity精华一记】特殊文件夹
👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 收录于专栏:uni…...
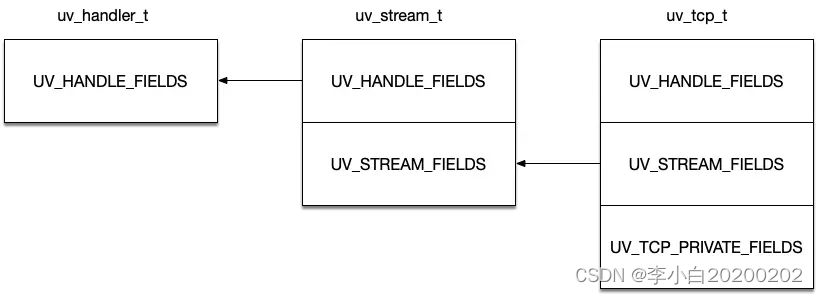
Node.js中的单线程服务器
为了解决多线程服务器在高并发的I/O密集型应用中的不足,同时避免早期简单单线程服务器的性能障碍,Node.js采用了基于"事件循环"的非阻塞式单线程模型,实现了如下两个目标: (1)保证每个请求都可以…...

如何删除数组中的某个元素?
如何删除数组中的某个元素? 例:给你一个数组 nums 和一个值 val,你需要移除所有数值等于 val 的元素,并返回移除后数组的新长度。 三种方法 1.元素前移(时间复杂度:O(N^2),空间复杂度&#x…...
Apache ActiveMQ RCE漏洞复现(CNVD-2023-69477)
0x01 产品简介 ActiveMQ是一个开源的消息代理和集成模式服务器,它支持Java消息服务(JMS) API。它是Apache Software Foundation下的一个项目,用于实现消息中间件,帮助不同的应用程序或系统之间进行通信。 0x02 漏洞概述 Apache ActiveMQ 中存…...

【BUG】Nginx转发失败解决方案
最近在做项目的时候出现了一个问题,琢磨了好久,来浅浅记录一下。 这个项目后端使用的是gateway网关和nacos实现动态的路由,前端使用nginx来管理前端资源,大体流程:浏览器发起请求,经过nginx代理,…...
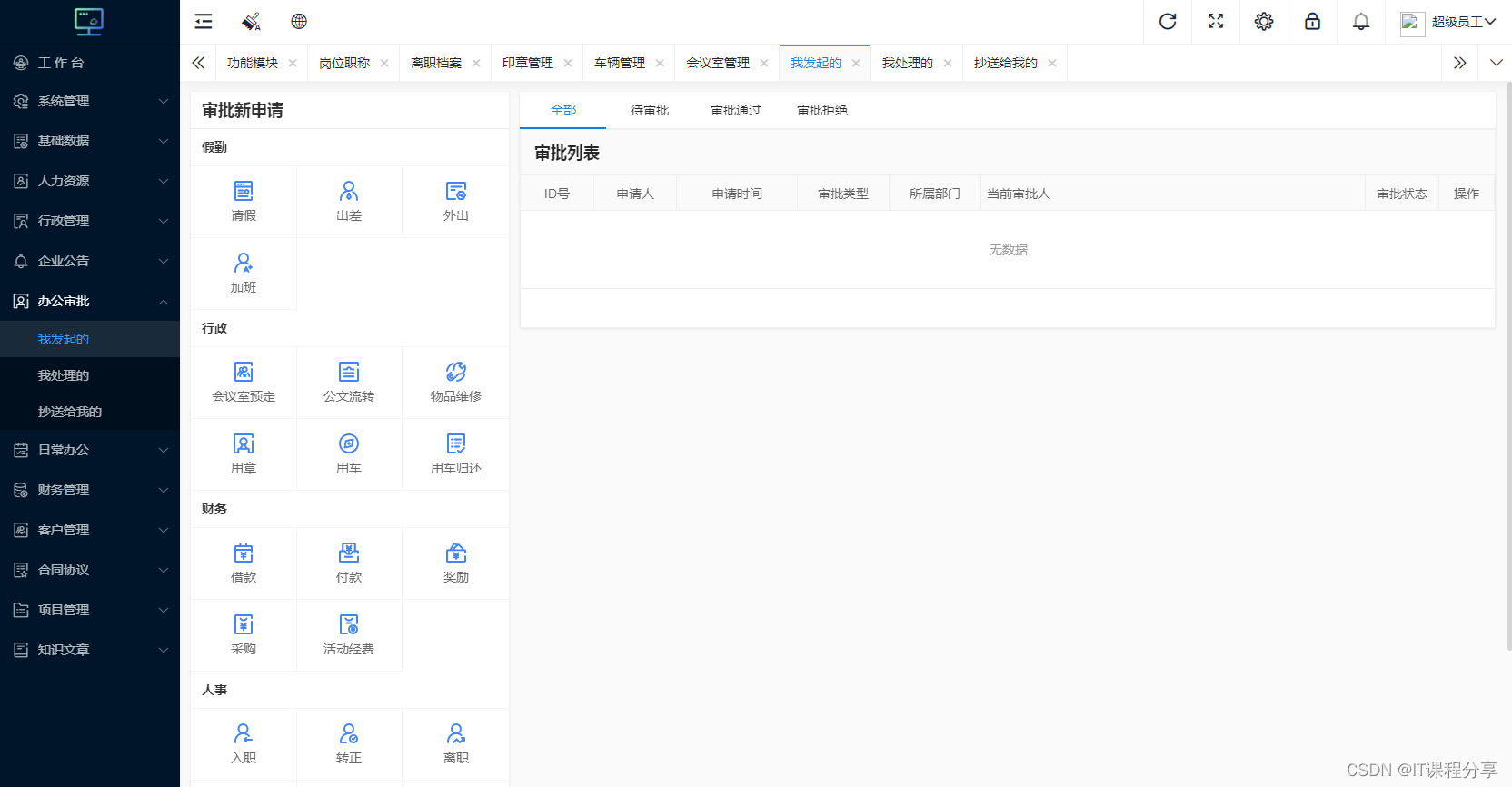
综合OA管理系统源码 OA系统源码
综合OA管理系统源码 OA系统源码 功能介绍: 编号:LQ10 一:系统管理 系统配置,功能模块,功能节点,权限角色,操作日志,备份数据,还原数据 二:基础数据 审批…...
)
9-MySQL提高数据管理效率(分库分表实践)
MySQL提高数据管理效率(分库分表实践) 在当今的互联网时代,随着业务规模的不断扩大,数据量也呈现出爆炸性的增长。如何有效地管理和存储这些数据,以及提高数据库的性能和可扩展性,成为了一个迫切需要解决的…...
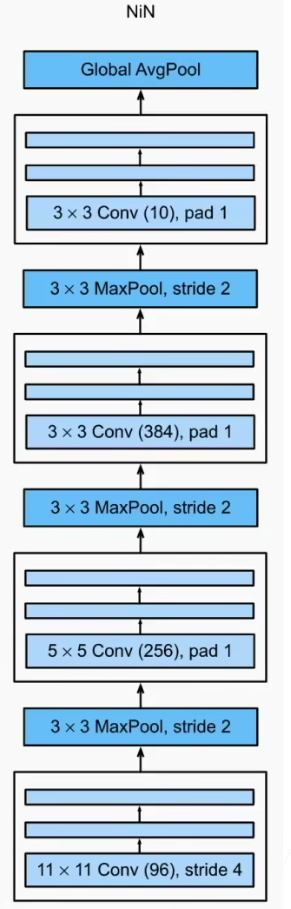
经典卷积神经网络 - NIN
网络中的网络,NIN。 AlexNet和VGG都是先由卷积层构成的模块充分抽取空间特征,再由全连接层构成的模块来输出分类结果。但是其中的全连接层的参数量过于巨大,因此NiN提出用1*1卷积代替全连接层,串联多个由卷积层和“全连接”层构成…...

leetcode_2558 从数量最多的堆取走礼物
1. 题意 给定一个数组,每次从中取走最大的数,返回开根号向下取整送入堆中,最后计算总和。 从数量最多的堆取走礼物 2. 题解 直接用堆模拟即可 2.1 我的代码 用了额外的空间O( n ) priority_queue会自动调用make_heap() 、pop_heap() c…...

01. 嵌入式与人工智能是如何结合的?
CPU是Arm A57的 GPU是128cuda核 一.小车跟踪的需求和设计方法 比如有一个小车跟踪的项目。 需求是:小车识别出罪犯,然后去跟踪他。方法:摄像头采集到人之后传入到开发板,内部做一下识别,然后控制小车去跟随。在人工智…...
vue3.0运行npm run dev 报错Cannot find module node:url
vue3.0运行npm run dev 报错Cannot find module 问题背景 近期用vue3.0写项目,npm init vuelatest —> npm install 都正常,npm run dev的时候报错如下: failed to load config from F:\code\testVue\vue-demo\vite.config.js error when starting…...

26. 删除排序数组中的重复项、Leetcode的Python实现
博客主页:🏆看看是李XX还是李歘歘 🏆 🌺每天分享一些包括但不限于计算机基础、算法等相关的知识点🌺 💗点关注不迷路,总有一些📖知识点📖是你想要的💗 ⛽️今…...

多自由度冗余空间机械臂位姿一体化规划与控制【附代码】
✨ 长期致力于空间机械臂、对偶四元数、位姿一体化、路径规划、跟踪控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于对偶四元数的冗余机械臂运…...

网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程
网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经从网易云音乐下载了心爱的歌曲,却发现只能在特定播放器上收听?NCM格式的限制让音乐…...

别再乱算相似度了!用Python实战二元变量聚类:从Jaccard系数到病人分组
医疗数据分析实战:用Python实现基于Jaccard系数的病人症状聚类在医疗数据分析领域,如何从海量病人症状数据中发现潜在规律一直是临床研究的难点。传统方法往往依赖医生经验或简单统计,而现代数据挖掘技术为我们提供了更科学的解决方案。本文将…...

Redis分布式锁进阶第二十篇
一、本篇前置衔接 第二十篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争抢…...

OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心
OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为官方…...

java项目011-ssm 宠物医院系统
java项目011-ssm 宠物医院系统 是一款基于springspringmvcmybatis的宠物系统, 包含界面布局、医生信息管理、客户信息管理、宠物管理、浏览管理、 诊断管理、医生管理、用户管理 其中医生管理、用户管理只能管理员有权限进行操作。 采用spingboot方式启动 运行截图...

避坑指南:Unity中AABB碰撞检测失效的5种常见原因及解决方法
Unity中AABB碰撞检测失效的深度排查与解决方案在Unity开发中,AABB(轴对齐包围盒)碰撞检测是基础但容易出问题的环节。许多开发者都遇到过这样的情况:明明逻辑正确,测试时却出现物体穿透、碰撞时有时无等诡异现象。本文…...

3分钟快速解决Windows热键冲突检测难题:Hotkey Detective终极指南
3分钟快速解决Windows热键冲突检测难题:Hotkey Detective终极指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...

AI专著生成必备工具,轻松撰写20万字专著,质量与效率双保障!
学术专著的写作是一个严谨的过程,其背后需要大量的资料和数据作为基础。搜集和整理这些资料与数据往往是写作过程中最繁琐且耗时的部分。研究人员需要广泛收集国内外的前沿文献,确保所用文献不仅具备权威性,还要与研究主题密切相关。同时&…...

如何用嘎嘎降AI处理金融学论文:金融学毕业论文降AI4.8元完整操作教程
如何用嘎嘎降AI处理金融学论文:金融学毕业论文降AI4.8元完整操作教程 第一次用降AI工具有很多不确定——传什么格式、选哪个模式、怎么验收。 这篇教程把金融学论文降AI教程的常见问题都覆盖了,主要基于嘎嘎降AI(www.aigcleaner.com&#x…...