Linux下的文件操作和文件管理
文章目录
- 应用编程
- 文件操作
- 文件描述符
- open函数
- write函数
- read函数
- close函数
- lseek函数
- 文件操作例子
- 文件管理
- 文件基本知识
- 文件类型
- 文件共享
- 空洞文件
- 错误处理
- 退出程序
- 原子操作
- fcntl和ioctl
- 截断文件
- stat函数
- 软链接和硬链接
应用编程
系统调用(system call)是Linux内核提供给应用层的应用编程接口(API),是Linux应用层进入内核的入口。内核提供了一系列的服务、资源、功能等,应用程序通过系统调用API函数来使用内核提供的服务、资源以及各种各样的功能,通过系统调用API,应用层可以实现与内核的交互。所有的操作系统都会向应用层提供系统调用,应用程序通过系统调用来使用操作系统提供的各种服务。通过系统调用,Linux应用程序可以请求内核以自己的名义执行某些事情,譬如打开磁盘中的文件、读写文件、关闭文件以及控制其它硬件外设。
裸机编程:把没有操作系统支持的编程环境称为裸机编程。比如单片机上的编程开发,编写直接在硬件上运行的程序,没有操作系统支持。
驱动编程:基于内核驱动框架开发驱动程序,编程人员通过调用Linux内核提供的接口完成设备驱动的注册,驱动程序负责底层硬件操作相关逻辑。
应用编程:也称系统编程,是基于Linux操作系统的,在应用程序中通过系统调用API完成应用程序的功能和逻辑,应用程序运行于操作系统之上。
通常在操作系统下有两种不同的状态,内核态和用户态,应用程序运行在用户态,内核则运行在内核态。
对同样一个操作,比如点亮LED,三种编程的代码框架如下。
裸机编程代码框架。
static void led_on(void);
static void led_off(void);
int main(void)
{while(1){led_on();delay();led_off();delay();}
}
裸机程序当中,LED的硬件操作代码与用户逻辑代码全部都是在同一个源文件中实现的,硬件操作代码与用户逻辑代码没有隔离,没有操作系统支持,代码编译之后直接在硬件平台上运行。
驱动编程代码框架。
static void led_on(void);
static void led_off(void);
static int led_open(struct inode *inode, struct file *filp);
static ssize_t led_write(struct file *filp, const char __user *buf, size_t size, loff_t *offt)
{int flag;if (copy_from_user(&flag, buf, size)) return -EFAULT;if (flag) led_on(); else led_off(); return 0;
}
static int led_release(struct inode *inode, struct file *filp);
static struct file_operations led_fops = { .owner = THIS_MODULE, .open = led_open, .write = led_write, .release = led_release,
};
static int led_probe(struct platform_device *pdev);
static int led_remove(struct platform_device *pdev);
static const struct of_device_id led_of_match[] = {{ .compatible = "led", }, { /* sentinel */ },
};
MODULE_DEVICE_TABLE(of, led_of_match);
static struct platform_driver led_driver = { .probe = led_probe, .remove = led_remove, .driver = { .owner = THIS_MODULE, .name = "led", .of_match_table = led_of_match, },
};
static int __init led_init(void);
static void __exit led_exit(void);
module_init(led_init);
module_exit(led_exit);
MODULE_LICENSE("GPL");
上面程序中,应用层通过write函数写入值,内核通过判断写入的值控制LED的亮灭。
应用编程代码框架。
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h> int main(int argc, char **argv)
{int fd,data; fd = open("/dev/led", O_WRONLY); //假定上面驱动加载后的文件是/dev/led if (fd < 0) return -1;while(1){data = 1;write(fd, &data, sizeof(data));sleep(1); data = 0;write(fd, &data, sizeof(data)); sleep(1); }close(fd); return 0;
}
上面代码中调用了open、write、close这三个系统调用API接口,open和close分别用于打开或关闭LED设备,write写入数据传给LED驱动,传入0熄灭LED,传入1点亮LED。
LED应用程序与LED驱动程序是分隔、分离的,它们单独编译,应用程序运行在操作系统之上,有操作系统支持,应用程序处于用户态,而驱动程序处于内核态,与纯粹的裸机程序存在着质的区别。
文件操作
文件描述符
调用open函数打开一个现有文件或创建一个新文件时,内核会向进程返回一个文件描述符(file descriptor),用于指代被打开的文件,所有执行IO操作的系统调用都是通过文件描述符来索引找到对应的文件。文件描述符会在读写操作或者关闭文件的时候传入。
可以使用下面的命令查看进程可以打开的最大文件数。
ulimit -n
最大值一般是1024,所以对一个进程来说,文件描述符是一种有限资源。文件描述符是从0开始分配的,如果打开文件的上限是1024的话,文件描述符的范围就是0-1023。每一个被打开的文件在同一个进程中都有一个唯一的文件描述符,不会重复,文件被关闭后,其对应的文件描述符也会被释放,释放的这个文件描述符可以再次分配给其它打开的文件,并与对应的文件绑定起来。
每次给打开的文件分配文件描述符都是从最小的没有被使用的文件描述符开始,我们在程序中调用open函数打开文件的时候,分配的文件描述符一般都是从3开始的,因为0、1、2分别分配给了系统标准输入、标准输出、标准错误。
文件描述符是可以进行复制的,而且可以复制多次,open()函数返回的文件描述符被复制后和原来的文件描述符有相同的权限。在Linux系统下,可以使用dup或dup2这两个系统调用对文件描述符进行复制,关闭文件时,旧的和新复制的描述符都要显示关闭。
使用 man 2 dup 命令打开dup和dup2函数的帮助信息如下图所示。

dup或dup2函数需要包含头文件<unistd.h>。
#include <unistd.h>
int dup(int oldfd);
int dup2(int oldfd, int newfd);
dup和dup2函数的不同之处在于,dup函数复制后的文件描述符是由系统分配的,遵循文件描述符分配原则,而dup2函数可以自己指定文件描述符。
后面会提到open函数使用O_APPEND标志可以完成文件的接续写,这里通过复制文件描述符也可以完成文件的接续写。
open函数
要操作一个文件,需要先打开该文件,得到文件描述符,然后对文件进行相应的读写操作,最后关闭该文件。open函数用于打开文件,除了打开已经存在的文件之外,还可以创建一个新的文件。
使用man命令可以查看帮助信息,一般格式是man 1/2/3 name,数字1表示查看Linux命令,数字2表示系统调用,数字3对应标准的C库函数。
使用man 2 open命令查看open函数的帮助信息如下图所示。

使用open函数需要包含<sys/types.h> 、<sys/stat.h> 和<fcntl.h>三个头文件,open函数可以带两个参数,也可以带三个参数。
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h> int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
第一个参数pathname是字符串类型,用于标识需要打开或创建的文件,可以是文件的绝对路径或相对路径,如果pathname是一个符号链接,会对其进行解引用。
第二个参数flags是调用open函数时需要提供的标志,包括文件访问模式标志以及其它文件相关标志,这些标志是使用宏定义描述的,都是常量。传入flags参数时既可以单独使用某一个标志,也可以通过位或运算“|”将多个标志进行组合。常见的标志有以下几个。
O_RDONLY(只读)、O_WRONLY(只写)、O_RDWR(读写)是文件访问权限标志,传入的flags参数中必须要包含其中一种标志,而且只能包含一种,打开的文件只能按照这种权限来操作,譬如使用了O_RDONLY标志,就只能对文件进行读取操作,不能写操作。
O_CREAT用于在pathname参数指向的文件不存在则创建此文件,使用此标志时,调用open函数需要传入第3个参数mode,参数mode用于指定新建文件的访问权限。
O_DIRECTORY:如果pathname参数指向的不是一个目录,则调用open失败。
O_EXCL标志一般结合O_CREAT标志一起使用,用于专门创建文件,在flags参数同时使用到了O_CREAT和O_EXCL标志的情况下,如果pathname参数指向的文件已经存在,则open函数返回错误。可以用于测试一个文件是否存在,如果不存在则创建此文件,如果存在则返回错误,这使得测试和创建两者成为一个原子操作。
O_NOFOLLOW:如果pathname参数指向的是一个符号链接,将不对其进行解引用,直接返回错误。不加此标志情况下,如果pathname参数是一个符号链接,会对其进行解引用。
O_TRUNC:在调用open函数打开文件的时候,将文件原本的内容全部丢弃,文件大小变为0。
O_APPEND:在调用open函数打开文件的时候,每次使用write()函数对文件进行写操作时,都会自动把文件当前位置偏移量移动到文件末尾,O_APPEND标志还涉及原子操作。
第三个参数mode用于指定新建文件的访问权限,只有当flags参数中包含O_CREAT或O_TMPFILE(用于创建一个临时文件)标志时才有效。mode参数的类型是mode_t,这是一个32位的无符号整形数据。从低位到高位分别是其他用户权限、同组用户权限、文件拥有者权限、特殊权限。
Linux中已经定义好了一些宏来描述不同的权限,S_IRUSR、S_IWUSR、S_IXUSR、S_IRWXU分别是文件所属者可读、可写、可执行、读写执行;S_IRGRP、S_IWGRP、S_IXGRP、S_IRWXG分别是同组用户可读、可写、可执行、读写执行;S_IROTH、S_IWOTH、S_IXOTH、S_IRWXO分别是其他用户可读、可写、可执行、读写执行;S_ISUID是set-user-ID特殊权限,S_ISGID是set-group-ID特殊权限,S_ISVTX是sticky特殊权限。这些宏可以通过位或运算“|”组合使用。
open函数O_RDONLY、O_WRONLY以及O_RDWR这三个标志表示以什么方式去打开文件,譬如以只写方式打开,open函数得到的文件描述符只能对文件进行写操作,不能读。只有用户对该文件具有相应权限时,才可以使用对应的标志去打开文件,否则会打开文件失败。
一个进程内多次使用open()函数打开同一个文件,那么会得到多个不同的文件描述符fd,在关闭文件的时候也需要调用close依次关闭各个文件描述符。
一个进程内多次使用open()函数打开同一个文件,在内存中并不会存在多份动态文件,而只有一份。
一个进程内多次使用open()函数打开同一个文件,不同文件描述符所对应的读写位置偏移量是相互独立的。
多次打开同一文件进行写操作,如果不加O_APPEND标志,那个各个文件之间就是各自写,最后一次写操作写的数据会从头覆盖前面写的数据,如果前面写的数据长与最后一次写的数据,那么没有被覆盖的数据会保留下来。总的来说,打开同一文件进行写操作,每个写操作都是从头开始写,后面写的会覆盖前面写的。加O_APPEND标志,那么所有写操作写的数据都会保留,先写的数据在前,后写的数据在后。
write函数
使用man 2 write命令查看write函数的帮助信息如下图所示。

write函数需要包含<unistd.h>头文件。
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);
fd就是通过open函数打开文件成功后得到的文件描述符;buf指定写入数据对应的缓冲区,写入的数据类型可根据具体要求定义;count是写入的字节数。如果写入成功将返回写入的字节数,如果函数返回的数字小于count,这不是错误,可能发生磁盘空间已满这种情况;如果写入出错,则返回-1。
read函数
使用man 2 read命令查看read函数的帮助信息如下图所示。

read函数也需要包含<unistd.h>头文件。
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
fd是文件描述符;buf是用于存储读取数据的缓冲区;count是需要读取的字节数。如果读取成功将返回读取到的字节数,实际读取到的字节数可能会小于count,也有可能为0。当前文件位置偏移量到文件末尾,读取到的字节数就为0。具体读到的字节数跟文件长度和偏移量有关。
close函数
使用man 2 close命令查看close函数的帮助信息如下图所示。

close函数需要包含<unistd.h>头文件。
#include <unistd.h>
int close(int fd);
close函数很简单,在操作完文件以后通过文件描述符关闭文件即可。关闭文件成功返回0,失败则返回-1。
除了使用close函数显式关闭文件之外,在Linux系统中,当一个进程终止时,内核会自动关闭它打开的所有文件。比如在程序中打开了文件,如果程序终止退出时没有关闭打开的文件,那么内核会自动将程序中打开的文件关闭。显式关闭不再需要的文件描述符往往是良好的编程习惯,会使代码在后续修改时更具有可读性,也更可靠。文件描述符是有限资源,当不再需要时要将其释放并归还于系统。
lseek函数
lseek函数也是很重要的一个函数,对于每个打开的文件,系统都会记录其读写位置偏移量,也把读写位置偏移量称为读写偏移量,记录了文件当前的读写位置,当调用read()或write()函数对文件进行读写操作时,就会从当前读写位置偏移量开始进行数据读写。读写偏移量用于指示read()或write()函数操作时文件的起始位置,会以相对于文件头部的位置偏移量来表示,文件第一个字节数据的位置偏移量为0。
使用man 2 lseek命令查看lseek函数的帮助信息如下图所示。

lseek函数需要包含<sys/types.h>和<unistd.h>两个头文件。
#include <sys/types.h>
#include <unistd.h>
off_t lseek(int fd, off_t offset, int whence);
fd是文件描述符;offset是偏移量,以字节为单位;whence用于定义参数offset偏移量对应的参考值,有以下三个宏定义。
SEEK_SET:读写偏移量将指向从文件头部开始算起的offset字节位置处;SEEK_CUR:读写偏移量将指向当前位置偏移量加上 offset字节位置处,offset可以为正也可以为负,如果是正数表示往后偏移,如果是负数则表示往前偏移;SEEK_END:读写偏移量将指向文件末尾加上offset字节位置处。
函数执行成功将返回从文件头部开始算起的位置偏移量,以字节为单位,即当前的读写位置,发生错误将返回-1。
以下是lseek使用的几个示例。
lseek(fd, 0, SEEK_SET); //将读写位置移动到文件开头处
lseek(fd, 0, SEEK_END); //将读写位置移动到文件末尾
lseek(fd, 100, SEEK_SET); //将读写位置移动到偏移文件开头100个字节处
lseek(fd, 0, SEEK_CUR); //获取当前读写位置偏移量
文件操作例子
示例一:使用只读方式打开一个当前目录下已经存在的文件aaa;然后再打开一个新建文件bbb,使用只写方式,新建文件的权限设置为:文件所属者拥有读、写、执行权限;同组用户与其他用户只有读权限。从aaa文件偏移头部10个字节位置开始读取20字节数据,然后将读取出来的数据写入到bbb文件中,从文件开头处开始写入,操作完成之后使用close显式关闭所有文件,然后退出程序。
上面例子的代码如下。
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>int main(int argc, char **argv)
{int fd1,fd2,ret;char buf[25];fd1 = open("./aaa",O_RDONLY); //使用只读方式打开一个当前目录下已经存在的文件aaaif(fd1 < 0){printf("open aaa file failed!\n");goto close_fd1;}elseprintf("open aaa successfully, the file descriptor is %d.\n",fd1);//打开一个新建文件bbb,使用只写方式,新建文件的权限设置为:文件所属者拥有读、写、执行权限;同组用户与其他用户只有读权限fd2 = open("./bbb",O_WRONLY|O_CREAT|O_EXCL,S_IRWXU|S_IRGRP|S_IROTH); if(fd2 < 0){printf("open bbb file failed!\n");goto close_fd2;}elseprintf("open bbb successfully, the file descriptor is %d.\n",fd2);lseek(fd1,10,SEEK_SET); //从aaa文件偏移头部10个字节ret = read(fd1,buf,20); //读取20字节数据if(ret < 0){printf("read data from aaa failed!\n");goto close_fd1;}elseprintf("read %d bytes : %s\n",ret,buf);ret = write(fd2,buf,20); //将读取出来的数据写入到bbb文件中if(ret < 0){printf("write data to bbb failed!\n");goto close_fd2;}elseprintf("write %d bytes : %s\n",ret,buf);close_fd2:close(fd2);
close_fd1:close(fd1);return 0;
}
执行结果如下图所示。
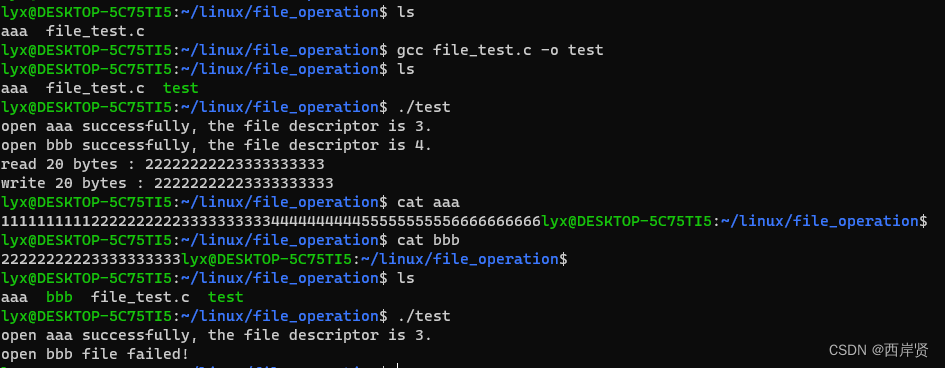
可以看到,文件的操作按照代码中写的那样执行了,写入bbb文件的内容确实是从aaa文件头部位置偏移10个字节后开始的。当bbb文件生成以后,再次执行可执行文件,因为在open函数中有O_CREAT和O_EXCL,所以如果文件已经存在,则open函数会返回错误。
示例二:通过open函数判断文件是否存在,并将判断结果显示出来。
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>int main(int argc, char **argv)
{int fd;fd = open("./aaa",O_WRONLY|O_CREAT|O_EXCL,S_IRWXU|S_IRGRP|S_IROTH);if(fd < 0){printf("The file aaa exists!\n");return fd;}else{printf("The file aaa doesn't exist, it has been created!\n");return fd;}
}
示例三:新建一个文件,权限设置为:文件所属者拥有读、写、执行权限;同组用户与其他用户只有读权限。使用只写方式打开文件,将文件前1Kbyte数据填充为0x00,将下1Kbyte数据填充为0xFF,操作完成之后显式关闭文件,退出程序。
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
#include <string.h>int main(int argc, char **argv)
{int fd;char buf1[1024];char buf2[1024];fd = open("./ccc",O_WRONLY|O_CREAT|O_EXCL,S_IRWXU|S_IRGRP|S_IROTH);if(fd < 0){printf("The file ccc exists!\n");return fd;}else{
/* for(int i=0; i<sizeof(buf1);i++){buf1[i] = 0x00; buf2[i] = 0xff;} */memset(buf1,0x00,sizeof(buf1)); //填充buf1为0x00memset(buf1,0xff,sizeof(buf1)); //填充buf2为0xffwrite(fd,buf1,1024);lseek(fd,1024,SEEK_SET);write(fd,buf2,1024);printf("Write done!\n");}close(fd);return fd;
}
示例四:打开一个已经存在的文件,通过lseek函数计算该文件的大小,并打印出来。
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>int main(int argc, char **argv)
{int fd;int ret=0;fd = open("./ccc",O_RDONLY);if(fd < 0){printf("open file ccc failed!\n");return fd;}ret = lseek(fd,0,SEEK_END);printf("File ccc has %d bytes.\n",ret); close(fd);return fd;
}
通过lseek函数将当前位置定位在文件尾,通过ret返回值得到文件的字节数。
文件管理
文件基本知识
文件在没有被打开的情况下一般都是存放在磁盘中的,并且以一种固定的形式进行存放,称为静态文件。
文件储存在硬盘上,硬盘的最小存储单位叫做扇区(sector),每个扇区储存512字节,即0.5KB,操作系统读取硬盘的时候,不会一个一个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个块(block)。由多个扇区组成的块是文件存取的最小单位,块的大小最常见的是4KB,即连续八个sector组成一个block。
静态文件对应的数据都是存储在磁盘设备不同的块中,open函数是如何找到对应的块的。其实磁盘在进行分区、格式化的时候会分为两个区域,一个是数据区,用于存储文件中的数据,另一个是inode区,用于存放inode table,inode table中存放的是一个一个的inode,不同的inode就可以表示不同的文件,每一个文件都必须对应一个inode。inode实质上是一个结构体,这个结构体中有很多的元素,不同的元素记录了文件了不同信息,譬如文件字节大小、文件所有者、文件对应的读/写/执行权限、文件时间戳
、文件类型、文件数据存储的块位置等信息。

在Linux中,可以通过 ls -i 命令查看文件的inode编号,如下图所示。

通过 stat filename 命令也可以查看文件的inode编号,如下图所示。

在格式化U盘的时候,快速格式化只是删除了U盘inode table,真正存储文件数据的区域并没有动,所以使用快速格式化的U盘,其中的数据是可以被找回来的。
所以打开一个文件,系统会先找到这个文件对应的inode编号,通过inode编号从inode table中找到对应的inode结构体,然后再
根据inode结构体中记录的信息,确定文件数据所在的block,并读出数据。
当调用open函数打开文件的时候,内核会申请一段内存/缓冲区,并且将静态文件的数据从磁盘等存储设备中读取到内存进行管理、缓存,把内存中的这份文件数据叫做动态文件、内核缓冲区。打开文件后,之后对这个文件的读写操作,都是针对内存中的这一份动态文件进行相关的操作,而并不是对磁盘中存放的静态文件进行操作的。内存的读写速率远比磁盘读写快得多。
对动态文件进行读写操作后,此时内存中的动态文件和磁盘设备中的静态文件就不同步了,数据的同步工作由内核完成,内核会在之后将内存这份动态文件更新到磁盘设备中。
文件类型
在Linux系统下,系统并不会通过文件后缀名来识别一个文件的类型,Linux系统下一共分为7种文件类型。可以使用stat或者ls命令查看文件的类型。 采用ls命令后第一个字符就是文件类型。’ - ‘是普通文件;’ d ‘是目录文件;’ c ‘是字符设备文件;’ b ‘是块设备文件;’ l ‘是符号链接文件;’ s ‘是套接字文件;’ p '是管道文件。
普通文件分为文本文件和二进制文件。文本文件的内容是由文本构成的,常见的.c、.h、.sh、.txt等这些都是文本文件,文本文件方便阅读、浏览以及编写。二进制文件比如可执行文件、C代码编译过后的.o文件、.bin文件等。
目录文件(directory)就是文件夹,文件夹在Linux系统中也是一种特殊文件,目录文件也可以使用vi命令打开,目录文件打开后有该目录文件的绝对路径和文件夹下包含的文件。
字符设备文件和块设备文件(character/block)对应的是硬件设备,在Linux系统中,硬件设备会对应一个设备文件,应用程序通过对设备文件的读写来操控、使用硬件设备。设备文件并不存在于磁盘中,而是由文件系统虚拟出来的,一般是由内存来维护,当系统关机时,设备文件都会消失,硬件设备文件一般存放在Linux系统/dev/目录下。
符号链接文件(link)类似于Windows系统中的快捷方式文件,是一种特殊文件,它的内容指向的是另一个文件路径,当对符号链接文件进行操作时,系统根据情况会对这个操作转移到它指向的文件上去,而不是对它本身进行操作,读取一个符号链接文件内容时,实际上读到的是它指向的文件的内容。
管道文件(pipe)主要用于进程间通信。
套接字文件(socket)也是一种进程间通信的方式,与管道文件不同的是,它们可以在不同主机上的进程间通信,实际上就是网络通信。
文件共享
文件共享多用于多进程或多线程编程环境中,可以通过文件共享的方式来实现多个线程同时操作同一个大文件,以减少文件读写时间、提升效率。
文件共享的核心是如何制造出多个不同的文件描述符来指向同一个文件,主要的方法有下面几种。
①同一个进程中多次调用open函数打开同一个文件。

多次调用open函数打开同一个文件会得到多个不同的文件描述符,并且多个文件描述符对应多个不同的文件表,所有的文件表都索引到了同一个inode节点,也就是磁盘上的同一个文件。
②不同进程中分别使用open函数打开同一个文件。

进程1和进程2分别是运行在Linux系统上两个独立的进程,它们在各自的程序中分别调用open函数打开同一个文件,进程1对应的文件描述符为fd1,进程2对应的文件描述符为fd2,fd1指向了进程1的文件表1,fd2指向了进程2的文件表2,各自的文件表都索引到了同一个inode节点,从而实现共享文件。
③同一个进程中通过dup/dup2函数对文件描述符进行复制。

空洞文件
lseek可以修改文件的当前读写位置偏移量,此函数不但可以改变位置偏移量,并且还允许文件偏移量超出文件长度。譬如有一个文件,该文件的大小是4KB,但是可以通过lseek系统调用将该文件的读写偏移量移动到超过偏移文件头部4096个字节处,比如偏移到6000字节处,这样是可以的。然后使用write()函数对文件进行写入操作,此时将从偏移文件头部6000个字节处开始写入数据,也就意味着4096-6000字节之间出现了一个空洞,这部分空间并没有写入任何数据,所以形成了空洞,这部分区域就被称为文件空洞,那么相应的该文件也被称为空洞文件。
文件空洞部分实际上并不会占用任何物理空间,直到在某个时刻对空洞部分进行写入数据时才会为它分配对应的空间,但是空洞文件形成时,逻辑上该文件的大小是包含了空洞部分的大小的。也就是说,空洞文件物理上不占内存空间,逻辑上占内存空间。
空洞文件对多线程共同操作文件是非常有用的,有时候创建一个很大的文件,如果单个线程从头开始依次构建该文件需要很长的时间,有一种思路就是将文件分为多段,然后使用多线程来操作,每个线程负责其中一段数据的写入。有点类似于施工队修路,比如说修建一条高速公路,单个施工队修筑会很慢,这个时候可以安排多个施工队,每一个施工队负责修建其中一段,最后将他们连接起来。
实际中空洞文件的应用场景:在使用迅雷下载文件时,还未下载完成,就发现该文件已经占据了全部文件大小的空间,这也是空洞文件,下载时如果没有空洞文件,多线程下载时文件就只能从一个地方写入,如果有了空洞文件,可以从不同的地址同时写入,就达到了多线程的优势;在创建虚拟机时,给虚拟机分配了100G的磁盘空间,但其实系统安装完成之后,开始也不过只用了3-4G的磁盘空间,如果一开始就把100G分配出去,资源是很大的浪费。
错误处理
当程序中调用函数发生错误的时候,操作系统内部会通过设置程序的errno变量来告知调用者究竟发生了什么错误。errno本质上是一个int类型的变量,用于存储错误编号,但是需要注意的是,并不是执行所有的系统调用或C库函数出错时,操作系统都会设置errno。
下图是open函数的返回值描述。

要使用errno,需要包含下面的头文件。
#include <errno.h>
errno仅仅只是一个错误编号,知道了这个编号还是不知道错误的原因,C库中有一个函数strerror(),该函数可以将对应的errno转换成出错的字符串信息。
通过 man 3 strerror 命令打开strerror()函数如下图所示。

函数strerror()需要包含下面的头文件。
#include <string.h>
char *strerror(int errnum);
参数errnum就是对应的errno。
在当前目录下打开一个不存在的文件,代码如下。
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
#include <errno.h>
#include <string.h>int main(int argc, char **argv)
{int fd;fd = open("./bbb", O_RDONLY);if(fd < 0){printf("Error : %s\n", strerror(errno));return fd;}close(fd);return 0;
}
运行后打印的信息如下。
Error : No such file or directory
上面的errno和strerror()的功能可以被perror函数代替,通过 man 3 perror 命令打开perror()函数如下图所示。

参数s表示在错误提示字符串信息之前加入自己的打印信息,也可以不加,不加则传入空字符串即可。
使用perror函数只需要加入<stdio.h>头文件。调用该函数不需要传入errno,函数内部会自己去获取errno变量的值,然后会将错误提示字符串打印出来,而不是返回字符串。
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>int main(int argc, char **argv)
{int fd;fd = open("./bbb", O_RDONLY);if(fd < 0){perror("Open error");return fd;}close(fd);return 0;
}
如果当前目录下不存在要打开的文件,上面的代码运行之后打印的信息如下。
Open error: No such file or directory
退出程序
当程序在执行某个函数出错的时候,如果此函数执行失败会导致后面的步骤不能在进行下去时,应该在出错时终止程序运行,一般情况是,程序执行正常退出return 0,而执行函数出错退出return -1。
在Linux系统下,进程退出除了使用return之外,还可以使用exit()、_exit()和_Exit()。
main函数中使用return后返回,return执行后把控制权交给调用函数,结束该进程。调用_exit()函数会清除其使用的内存空间,并销毁其在内核中的各种数据结构,关闭进程的所有文件描述符,并结束进程、将控制权交给操作系统。
使用 man 2 _exit 命令查看函数信息如下。

_exit函数需要包含<unistd.h>头文件,_Exit函数需要包含<stdlib.h>头文件。
#include <unistd.h>
void _exit(int status);#include <stdlib.h>
void _Exit(int status);
调用上面两个函数时需要传入status状态标志,0表示正常结束,其它值则表示程序执行过程中检测到错误。使用方法和return一样,用_exit(0)/_Exit(0)代替return 0,用_exit(-1)/_Exit(-1)代替return -1即可。
exit()函数和_exit()函数都是用来终止进程的,exit()是一个标准C库函数,而_exit()和_Exit()是系统调用,执行exit()会执行一些清理工作,最后调用_exit()函数。
使用 man 3 exit 命令查看函数信息如下。

exit()函数需要包含<stdlib.h>头文件。
#include <stdlib.h>
void exit(int status);
exit()函数的用法和上面的两个函数都一样。
退出程序的方法:main函数中使用return;Linux系统调用_exit()或_Exit();C标准库函数exit()。
原子操作
Linux是一个多任务、多进程操作系统,系统中往往运行着多个不同的进程或任务,多个不同的进程就有可能对同一个文件进行IO操作,此时该文件便是共享资源,它们共同操作着同一份文件,因此在多进程环境下可能会导致的竞争冒险。
操作共享资源的两个进程或线程,其操作之后的所得到的结果往往是不可预期的,因为每个进程或线程去操作文件的顺序是不可预期的,即这些进程获得CPU使用权的先后顺序是不可预期的,完全由操作系统调配,这就是竞争状态。这种情况下得到的结果很可能不是我们想要的。
原子操作是由多步操作组成的一个操作,原子操作要么一步也不执行,一旦执行,必须要执行完所有步骤,不可能只执行所有步骤中的一个子集。
在open函数的flags参数中包含O_APPEND标志就可以实现原子操作,每次执行write写入操作时都会将文件当前写位置偏移量移动到文件末尾,然后再写入数据,移动当前写位置偏移量到文件末尾和写入数据这两个操作就组成了一个原子操作,所以在加入O_APPEND标志后,不管怎么写入数据都是从文件末尾写,这样就不会出现进程A写入的数据覆盖了进程B写入的数据这种情况了。
移动当前写位置偏移量到文件末尾和写入数据这两个操作分别是lseek()和write()函数,在操作系统中,pwrite()是系统调用,它的功能就是lseek()和write()函数这个组合,同样地,还有pread()函数,使用 man 2 pread 命令打开帮助信息如下图所示。

pread()和pwrite()函数相比于read()和write()函数多了一个参数offset,表示当前需要进行读或写的位置偏移量。
#include <unistd.h>
ssize_t pread(int fd, void *buf, size_t count, off_t offset);
ssize_t pwrite(int fd, const void *buf, size_t count, off_t offset);
调用pread函数时,无法中断其定位和读操作,也就是原子操作,而且pread()和pwrite()函数的调用不更新文件表中的当前位置偏移量。也就是在调用pread()和pwrite()函数函数之前偏移在哪个位置,函数执行完之后还在哪个位置。
另外,前面提到的O_EXCL标志也涉及原子操作,判断文件是否存在和创建文件这两步操作就合成一个原子操作,如果文件不存在,就创建,如果存在,open()函数就返回错误。
fcntl和ioctl
fcntl()函数可以对一个已经打开的文件描述符执行一系列控制操作,比如复制一个文件描述符、获取/设置文件描述符标志、获取/设置文件状态标志等。
使用 man 2 fcntl 命令打开帮助信息如下图所示。

fcntl函数需要两个头文件。
#include <unistd.h>
#include <fcntl.h>
int fcntl(int fd, int cmd, ... /* arg */ );
fd是文件描述符,cmd是操作命令,此参数表示将要对fd进行什么操作,cmd参数支持很多操作命令,大致分为以下几种。
复制文件描述符(cmd=F_DUPFD或cmd=F_DUPFD_CLOEXEC);获取/设置文件描述符标志(cmd=F_GETFD或cmd=F_SETFD);获取/设置文件状态标志(cmd=F_GETFL或cmd=F_SETFL);获取/设置异步IO所有权(cmd=F_GETOWN或cmd=F_SETOWN);获取/设置记录锁(cmd=F_GETLK或cmd=F_SETLK)。
fcntl函数是一个可变参函数,第三个参数需要根据不同的cmd来传入对应的实参,配合cmd来使用。
执行失败返回值为-1,并设置errno,执行成功返回值根据cmd而定。
下面的代码就是使用fcntl复制文件描述符的,第三个参数0表示设置的文件描述符大于等于0且未被使用。
fd2 = fcntl(fd1, F_DUPFD, 0); //fd2返回复制后的文件描述符
cmd=F_GETFL可用于获取文件状态标志,不需要传入第三个参数,返回值成功表示获取到的文件状态标志;cmd=F_SETFL可用于设置文件状态标志,需要传入第三个参数,此参数表示需要设置的文件状态标志。这些标志指的就是在调用open函数时传入的flags标志,可以指定一个或多个,但是文件的读写权限标志以及文件创建标志(O_CREAT、O_EXCL、O_NOCTTY、O_TRUNC)等不能被设置,会被忽略。在Linux系统中,只有O_APPEND、O_ASYNC、O_DIRECT、O_NOATIME以及O_NONBLOCK这些标志可以被修改。
下面的代码就是使用fcntl函数来获取和设置文件状态标志的,flag也是整型。
flag = fcntl(fd, F_GETFL);
fcntl(fd, F_SETFL, flag | O_APPEND);
ioctl()可以认为是一个文件IO操作的杂物箱,可以处理的事情非常杂,一般用于操作特殊文件或硬件外设。
使用 man 2 ioctl 命令打开帮助信息如下图所示。

ioctl()需要包含<sys/ioctl.h>头文件。
#include <sys/ioctl.h>
int ioctl(int fd, unsigned long request, ...);
fd是文件描述符,request与具体要操作的对象有关,表示向文件描述符请求相应的操作,此函数是一个可变参函数,第三个参数需要根据request参数来决定,配合request来使用。成功返回0,失败返回-1。
截断文件
使用系统调用truncate()或ftruncate()可将普通文件截断为指定字节长度,使用 man 2 truncate 命令打开帮助信息如下图所示。

truncate()和ftruncate()函数需要包含两个头文件。
#include <unistd.h>
#include <sys/types.h>
int truncate(const char *path, off_t length);
int ftruncate(int fd, off_t length);
truncate()和ftruncate()函数的区别在于,truncate通过路径path指定目标文件,ftruncate通过文件描述符fd指定目标文件,所以使用ftruncate函数需要先通过open函数获得文件描述符,而且文件必须要有可写权限。
length参数就是要截断文件的大小,如果文件目前的大小大于参数length所指定的大小,则多余的数据将被丢失,如果文件目前的大小小于参数length所指定的大小,则将其进行扩展,对扩展部分进行读取将得到空字节"\0"。
truncate()和ftruncate()的运用如下图所示。
fd = open("./file1", O_RDWR);
ftruncate(fd, 0); //将当前目录下的文件file1截断为0truncate("./file2", 1024); //将当前目录下的文件file2截断为1024
stat函数
Linux下可以使用stat命令查看文件的属性,这个命令内部就是通过调用stat()函数来获取文件属性的,stat函数是Linux中的系统调用,通过 man 2 stat 命令查看帮助信息。
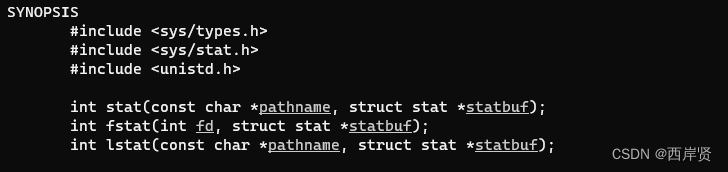
stat函数需要包含三个头文件。
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
int stat(const char *pathname, struct stat *statbuf);
int fstat(int fd, struct stat *statbuf);
int lstat(const char *pathname, struct stat *statbuf);
pathname是一个需要查看属性的文件路径;statbuf是struct stat类型指针,用于指向一个struct stat结构体变量,调用stat函数的时候需要传入一个struct stat变量的指针,获取到的文件属性信息就记录在struct stat结构体中。
stat函数直接通过文件路径得到文件信息。fstat函数需要文件描述符得到文件属性信息,所以使用fstat函数之前需要先打开文件得到文件描述符。lstat与stat、fstat的区别在于,对于符号链接文件,stat、fstat查阅的是符号链接文件所指向的文件对应的文件属性信息,而lstat查阅的是符号链接文件本身的属性信息。
struct stat是内核定义的一个结构体,在<sys/stat.h>头文件中申明,struct stat结构体内容如下所示。
struct stat { dev_t st_dev; /* 文件所在设备的ID */ ino_t st_ino; /* 文件对应inode节点编号 */ mode_t st_mode; /* 文件对应的模式 */ nlink_t st_nlink; /* 文件的链接数 */ uid_t st_uid; /* 文件所有者的用户ID */ gid_t st_gid; /* 文件所有者的组ID */ dev_t st_rdev; /* 设备号(指针对设备文件) */ off_t st_size; /* 文件大小(以字节为单位) */ blksize_t st_blksize; /* 文件内容存储的块大小 */ blkcnt_t st_blocks; /* 文件内容所占块数 */ struct timespec st_atim; /* 文件最后被访问的时间 */ struct timespec st_mtim; /* 文件内容最后被修改的时间 */struct timespec st_ctim; /* 文件状态最后被改变的时间 */
};
文件权限宏定义。
S_IRWXU 00700 owner has read, write, and execute permission
S_IRUSR 00400 owner has read permission
S_IWUSR 00200 owner has write permission
S_IXUSR 00100 owner has execute permission S_IRWXG 00070 group has read, write, and execute permission
S_IRGRP 00040 group has read permission
S_IWGRP 00020 group has write permission
S_IXGRP 00010 group has execute permission S_IRWXO 00007 others (not in group) have read, write, and execute permission
S_IROTH 00004 others have read permission
S_IWOTH 00002 others have write permission
S_IXOTH 00001 others have execute permission
如果要判断文件所有者对该文件是否具有可执行权限,可用下面的方法判断。
struct stat st;
stat("./file", &st);
if (st.st_mode & S_IXUSR)
{ //有权限
}
else
{ //无权限
}
文件类型宏定义。
S_IFSOCK 0140000 socket(套接字文件)
S_IFLNK 0120000 symbolic link(链接文件)
S_IFREG 0100000 regular file(普通文件)
S_IFBLK 0060000 block device(块设备文件)
S_IFDIR 0040000 directory(目录)
S_IFCHR 0020000 character device(字符设备文件)
S_IFIFO 0010000 FIFO(管道文件)S_IFMT 0170000 文件类型字段位掩码
通过st_mode变量判断文件类型。
struct stat st;
stat("./file", &st);
if ((st.st_mode & S_IFMT) == S_IFREG)
{ /* 是普通文件 */
}//判断文件类型的时候一般写成switch-case形式
switch (st.st_mode & S_IFMT)
{case S_IFSOCK: printf("socket file"); break; case S_IFLNK: printf("symbolic link file"); break; case S_IFREG: printf("regular file"); break; case S_IFBLK: printf("block device file"); break; case S_IFDIR: printf("directory file"); break; case S_IFCHR: printf("character device file"); break; case S_IFIFO: printf("pipe file"); break;
}
还可以使用Linux系统封装好的宏来进行判断,如下所示。
S_ISREG(m) #判断是不是普通文件,如果是返回true,否则返回false
S_ISDIR(m) #判断是不是目录
S_ISCHR(m) #判断是不是字符设备文件
S_ISBLK(m) #判断是不是块设备文件
S_ISFIFO(m) #判断是不是管道文件
S_ISLNK(m) #判断是不是链接文件
S_ISSOCK(m) #判断是不是套接字文件
# m是st_mode变量
if (S_ISREG(st.st_mode))
{ /* 是普通文件 */
}
写一个程序使用一下stat函数上面提到的。
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
#include <string.h>
#include <error.h>int main(int argc, char **argv)
{struct stat st; int ret; ret = stat("./aaa", &st); if (ret < 0) { perror("stat error"); return ret; } printf("file size: %ld bytes\ninode: %ld\n",st.st_size,st.st_ino); //打印文件大小和inodeprintf("file type : "); switch (st.st_mode & S_IFMT) //判断文件类型{case S_IFSOCK: printf("socket file\n"); break; case S_IFLNK: printf("symbolic link file\n"); break; case S_IFREG: printf("regular file\n"); break; case S_IFBLK: printf("block device file\n"); break; case S_IFDIR: printf("directory file\n"); break; case S_IFCHR: printf("character device file\n"); break; case S_IFIFO: printf("pipe file\n"); break; }if (st.st_mode & S_IRUSR) //读写执行属性判断{ printf("owner has read permission.\n"); }if (st.st_mode & S_IWUSR) {printf("owner has write permission.\n"); }if (st.st_mode & S_IXUSR) {printf("owner has execute permission.\n"); }return 0;;
}
执行结果如下图所示。

软链接和硬链接
在Linux系统中有两种链接文件,分为软链接文件和硬链接文件,软链接也叫符号链接,软链接文件是Linux系统下的七种文件类型之一,其作用类似于Windows下的快捷方式。
ln命令可以为一个文件创建软链接文件或硬链接文件,具体命令如下。
创建硬链接命令
ln 源文件 链接文件
硬链接文件与源文件拥有相同的inode号,意味着它们指向了物理硬盘的同一个区块,仅仅只是文件名字不同而已。删除硬链接文件或者源文件其中的一个,文件所对应的inode以及文件内容在磁盘中的数据块并不会被系统回收,因为inode数据结结构中会记录文件的链接数,这个链接数指的就是硬链接数,struct stat结构体中的st_nlink成员变量就记录了文件的链接数,源文件也算在链接数里面。
文件每创建一个硬链接,inode节点上的链接数就会加一,每删除一个硬链接,inode节点上的链接数就会减一,链接数减至0时,inode节点和对应的数据块会被文件系统所回收,也就意味着文件已经从文件系统中被删除了。
硬链接的操作如下图所示。

硬链接的情况下,对其中的一个硬链接文件修改,其他所有的硬链接文件内容都会被改动,修改是同步的。
创建软链接命令
ln -s 源文件 链接文件
软链接文件与源文件有着不同的inode号,意味着它们之间有着不同的数据块,软链接文件的数据块中存储的是源文件的路径名,链接文件可以通过这个路径找到被链接的源文件,它们之间类似于一种主从关系,当源文件被删除之后,软链接文件依然存在,但它指向的是一个无效的文件路径,这种链接文件被称为悬空链接。软链接inode节点上的链接数都是1,因为它们的inode号不同。
软链接的操作如下图所示。

同样地,软链接的情况下,对源文件或者软链接文件的修改,其他文件的内容也是同步被修改的。
对于硬链接,不能对目录创建硬链接,超级用户可以创建,但必须在底层文件系统支持的情况下;硬链接通常要求链接文件和源文件位于同一文件系统中。相反,可以对目录创建软链接;可以跨越不同文件系统;可以对不存在的文件创建软链接。
创建硬链接的函数。
#include <unistd.h>
int link(const char *oldpath, const char *newpath);
创建软链接的函数。
#include <unistd.h>
int symlink(const char *target, const char *linkpath);
软链接文件的数据块中存储的是源文件的路径名,因此其读取不能使用read函数,而要使用readlink函数。
#include <unistd.h>
ssize_t readlink(const char *pathname, char *buf, size_t bufsiz);
pathname是需要读取的软链接文件路径;buf是用于存放路径信息的缓冲区;bufsiz是读取大小,要大于链接文件数据块中存储的文件路径信息字节大小。
readlink读取软链接文件内容的代码如下。
#include <unistd.h>
#include <stdio.h>
#include <string.h>int main(int argc, char **argv)
{char buf[50]; int ret; memset(buf, 0x0, sizeof(buf)); ret = readlink("./b.c", buf, sizeof(buf)); if (ret < 0) { perror("readlink error"); return ret; } printf("%s\n", buf); return 0;;
}
普通文件由inode节点和数据块构成;目录由inode节点和目录块构成。
unlink()、remove()函数用于删除文件,如果删除的是软链接文件,其不会对软链接进行解引用操作,删除的是软链接文件本身,而不是其所指向的源文件。
软链接的一个应用就是Ubuntu的系统时间,使用 ls -l /etc/localtime 命令后如下图所示。

可以看到,/etc/localtime链接到了/usr/share/zoneinfo/Asia/Shanghai这个文件夹,如果要更改Ubuntu链接到某个地区的时间,只需要删除/etc目录下的localtime文件,然后新建一个软链接,软链接的源文件就是/usr/share/zoneinfo/下的某个地区,目标文件就是/etc/localtime。
使用下面的两条命令就可以完成。
sudo rm -rf localtime #删除原有链接文件
sudo ln -s /usr/share/zoneinfo/EST localtime #重新建立链接文件
参考资料:
I.MX6U嵌入式Linux C应用编程指南V1.4——正点原子
相关文章:
Linux下的文件操作和文件管理
文章目录 应用编程文件操作文件描述符open函数write函数read函数close函数lseek函数文件操作例子 文件管理文件基本知识文件类型文件共享空洞文件错误处理退出程序原子操作fcntl和ioctl截断文件stat函数软链接和硬链接 应用编程 系统调用(system call)是Linux内核提供给应用层…...

设计模式之桥梁模式
什么是桥梁模式 桥梁模式(Bridge Pattern)也称为桥接模式,属于结构型模式,它主要目的是通过组合的方式建立两个类之间的联系,而不是继承。桥梁模式将抽象部分与它的具体实现部分分离,使它们都可以独立地变…...
“从部署到优化,打造高效会议管理系统“
目录 引言一、部署单机项目 - 会议OA1.1 硬件和软件环境准备1.2 检查项目1.3 系统部署1.后端部署 二、部署前后端分离项目 - SPA项目后端部署2.前端部署 总结 引言 在现代化办公环境中,会议是组织沟通、决策和合作的重要方式之一。为了提高会议的效率和质量&#x…...
Facebook广告效果数据获取
一、背景 公司每年在Facebook和Google上投放了大量的广告,我总不能让老板登录Facebook广告投放平台上去看广告效果,其实老板只关注每天花了多少钱引来了多少客户,每个客户平均花费多少钱,其它的他才不关心,有Facebook…...

nlp之文本转向量
文章目录 代码代码解读 代码 from tensorflow.keras.preprocessing.text import Tokenizer # 标记器(每一个词,以我们的数值做映射,)words [LaoWang has a Wechat account., He is not a nice person., Be careful.] # 把这句话中每一个单词…...
【luckfox】添加压力传感器hx711
文章目录 前言一、参考资料二、电路图三、驱动四、makefile——添加驱动五、dts——使能gpio5.1 参考5.2 改动1—— hx117节点5.3 改动2——引脚节点5.4 已经被定义的引脚5.5 gpio源码 六、改动总结——使能hx711七、验证驱动添加八、编写测试文件8.1 测试代码8.2 配置编译环境…...

C++11的lambda表达式
lambda来源于函数式编程的概念。C11这次终于把lambda加进来了。 lambda表达式有如下优点: 1、声明式编程风格:就地匿名定义目标函数或函数对象,不需要额外写一个命名函数或者函数对象。以更直接的方式去写程序,好的可读性和可维护…...
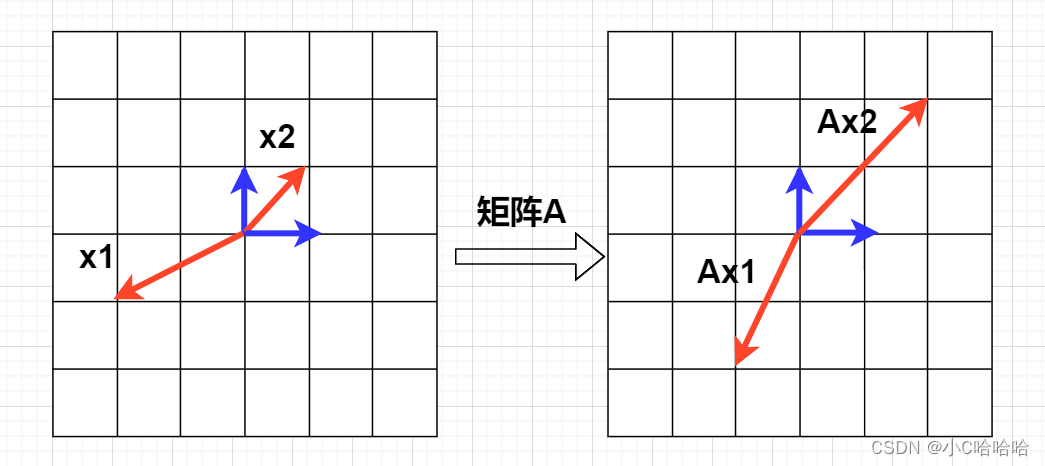
矩阵特征值与特征向量的理解
各位朋友大家好,我是小C哈哈哈,很高兴认识大家,在这里,我会将一些枯燥难懂的数学和算法知识以图片或动画的形式通俗易懂的展现给大家,希望大家喜欢。 线性代数中的矩阵特征值与特征向量这两个基本概念总是让很多人摸不…...

云原生安全:如何保护云上应用不受攻击
文章目录 云原生安全的概念1. 多层次的安全性2. 自动化安全3. 容器安全4. 持续监控5. 合规性 云原生安全的关键挑战1. 无边界的环境2. 动态性3. 多云环境4. 容器化应用程序5. API和微服务 如何保护云上应用不受攻击1. 身份验证和访问控制示例代码: 2. 数据加密示例代…...

如何在用pip配置文件设置HTTP爬虫IP
首先,定义问题:在 Pip 中设置HTTP爬虫IP服务器,以便在网络上进行访问和下载。 亲身经验:我曾经遇到过类似问题,通过设置HTTP爬虫IP服务器成功解决了网络访问问题。 数据和引证:根据 pip 官方文档ÿ…...

2023MathorCup高校数模挑战赛B题完整解题代码教程
赛道 B: 电商零售商家需求预测及库存优化问题 问题背景: 电商平台存在着上千个商家,他们会将商品货物放在电商配套的仓库, 电商平台会对这些货物进行统一管理。通过科学的管理手段和智能决策, 大数据智能驱动的供应链…...

《动手学深度学习 Pytorch版》 10.7 Transformer
自注意力同时具有并行计算和最短的最大路径长度这两个优势。Transformer 模型完全基于注意力机制,没有任何卷积层或循环神经网络层。尽管 Transformer 最初是应用于在文本数据上的序列到序列学习,但现在已经推广到各种现代的深度学习中,例如语…...

ORACLE-递归查询、树操作
1. 数据准备 -- 测试数据准备 DROP TABLE untifa_test;CREATE TABLE untifa_test(child_id NUMBER(10) NOT NULL, --子idtitle VARCHAR2(50), --标题relation_type VARCHAR(10) --关系,parent_id NUMBER(10) --父id );insert into untifa_test (CHILD_ID, TITLE, RELATION_TYP…...

MySQL篇---第四篇
系列文章目录 文章目录 系列文章目录一、并发事务带来哪些问题?二、事务隔离级别有哪些?MySQL的默认隔离级别是?三、大表如何优化?一、并发事务带来哪些问题? 在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对 同一数据进行操作…...

em/px/rem/vh/vw单位的区别
一、绝对长度单位 1.px 表示像素,显示器上每个像素点大小都是相同的 二、相对长度单位 2.em 相对于当前对象内文本的字体尺寸,如未设置对行内文本字体的尺寸,则相对于浏览器的默认字体(1em16px) em值不是固定的&…...
【C++】多态 ③ ( “ 多态 “ 实现需要满足的三个条件 | “ 多态 “ 的应用场景 | “ 多态 “ 的思想 | “ 多态 “ 代码示例 )
文章目录 一、" 多态 " 实现条件1、" 多态 " 实现需要满足的三个条件2、" 多态 " 的应用场景3、" 多态 " 的思想 二、" 多态 " 代码示例 一、" 多态 " 实现条件 1、" 多态 " 实现需要满足的三个条件 &q…...
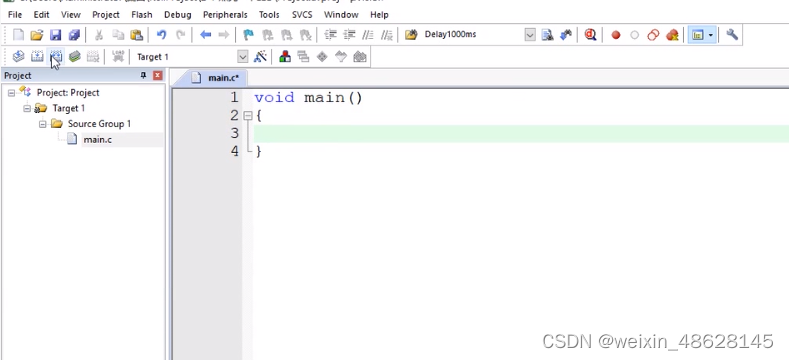
创建一个Keil项目
1、创建项目 2、选择存放的文件夹,还有设置项目名 3、选择型号(因为没有STC,用下面这个替代,功能差不多) 4、选择不用启动文件 5、就会得到下面这个,可以在Source Group 1下面编写代码了 6、右键source Group 1,添加c语…...
Xray的简单使用
xray 简介 xray 是一款功能强大的安全评估工具,由多名经验丰富的一线安全从业者呕心打造而成,主要特性有: 检测速度快。发包速度快; 漏洞检测算法效率高。支持范围广。大至 OWASP Top 10 通用漏洞检测,小至各种 CMS 框架 POC,均…...

Linux Ubunto Nginx安装
一 安装前 环境准备 gcc $ sudo apt-get install gcc zlib $ sudo apt-get install zlib1g-dev pcre $ sudo apt-get install libpcre3 libpcre3-dev openssl $ sudo apt-get install openssl libssl-dev‘ ubuntu 安装 libssl-dev失败的解决方案 1.安装aptitude sudo apt-g…...

深度学习中的epoch, batch 和 iteration
名词定义epoch使用训练集的全部数据进行一次完整的训练,称为“一代训练”batch使用训练集中的一小部分样本对模型权重进行一次反向传播的参数更新,这样的一部分样本称为:“一批数据”iteration使用一个batch的数据对模型进行一次参数更新的过…...

基于TESS光变曲线与深度学习的O型星物理参数预测研究
1. 项目概述与核心挑战在恒星天体物理研究中,大质量O型星扮演着至关重要的角色。它们不仅是宇宙中光度最高的天体之一,其强烈的辐射、恒星风和最终的超新星爆发,更是驱动星系化学演化和能量注入星际介质的关键引擎。然而,深入理解…...

AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸
AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸 【免费下载链接】AutoWall 🌌 Live wallpapers on Windows 7/8/10/11 using open-source wallpaper engine 项目地址: https://gitcode.com/gh_mirrors/au/AutoWall 厌倦了千篇一律的静态桌…...

Log4Shell漏洞深度解析:Spring Boot日志注入原理与四层修复方案
1. 这个漏洞不是“远程执行代码”那么简单——它是一次对Java生态信任链的系统性击穿Log4j CVE-2021-44228,业内常简称为“Log4Shell”,2021年12月爆发时,我正在给一家金融客户的Spring Boot微服务集群做灰度发布前的安全加固。凌晨三点收到告…...

如何扩展GASShooter:添加新武器、新能力与新游戏机制的终极指南
如何扩展GASShooter:添加新武器、新能力与新游戏机制的终极指南 【免费下载链接】GASShooter Advanced FPS/TPS Sample Project for Unreal Engine 4s GameplayAbilitySystem plugin 项目地址: https://gitcode.com/gh_mirrors/ga/GASShooter GASShooter是Un…...

手机也能玩转无人机仿真:用安卓QGC App连接同一WiFi下的PX4 JMAVSim模拟器
手机也能玩转无人机仿真:用安卓QGC App连接同一WiFi下的PX4 JMAVSim模拟器 无人机开发者和爱好者们,是否曾想过用手机就能完成整个无人机仿真测试流程?告别笨重的电脑束缚,只需一部安卓设备,就能在沙发上调试飞控算法。…...

京东自动购物终极指南:告别缺货烦恼,智能抢购神器
京东自动购物终极指南:告别缺货烦恼,智能抢购神器 【免费下载链接】Jd-Auto-Shopping 京东商品补货监控及自动下单 项目地址: https://gitcode.com/gh_mirrors/jd/Jd-Auto-Shopping 还在为心仪商品瞬间售罄而苦恼吗?还在熬夜等待补货却…...

如何用Untrunc拯救损坏视频?2025年终极MP4修复工具完全指南
如何用Untrunc拯救损坏视频?2025年终极MP4修复工具完全指南 【免费下载链接】untrunc Restore a damaged (truncated) mp4, m4v, mov, 3gp video. Provided you have a similar not broken video. 项目地址: https://gitcode.com/gh_mirrors/unt/untrunc 当你…...

终极Obsidian笔记模板指南:如何用kepano-obsidian构建你的第二大脑
终极Obsidian笔记模板指南:如何用kepano-obsidian构建你的第二大脑 【免费下载链接】kepano-obsidian My personal Obsidian vault template. A bottom-up approach to note-taking and organizing things I am interested in. 项目地址: https://gitcode.com/gh_…...

DRG存档编辑器终极指南:如何快速解锁《深岩银河》的全部游戏体验
DRG存档编辑器终极指南:如何快速解锁《深岩银河》的全部游戏体验 【免费下载链接】DRG-Save-Editor Rock and stone! 项目地址: https://gitcode.com/gh_mirrors/dr/DRG-Save-Editor 还在为《深岩银河》中无尽的资源收集和等级提升感到疲惫吗?DRG…...

ncmdumpGUI终极指南:3分钟搞定网易云音乐NCM文件转换
ncmdumpGUI终极指南:3分钟搞定网易云音乐NCM文件转换 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 还在为网易云音乐的NCM加密格式而烦恼吗&…...