《动手学深度学习 Pytorch版》 10.7 Transformer
自注意力同时具有并行计算和最短的最大路径长度这两个优势。Transformer 模型完全基于注意力机制,没有任何卷积层或循环神经网络层。尽管 Transformer 最初是应用于在文本数据上的序列到序列学习,但现在已经推广到各种现代的深度学习中,例如语言、视觉、语音和强化学习领域。
10.7.1 模型
Transformer 作为编码器-解码器架构的一个实例,其编码器和解码器是基于自注意力的模块叠加而成的,源(输入)序列和目标(输出)序列的嵌入(embedding)表示将加上位置编码(positional encoding),再分别输入到编码器和解码器中。

结构简介:
-
编码器:
-
由多个相同的层 叠加 而成,每个层有 两个子层(sublayer):
-
第一个子层为 多头自注意力(multi-head self-attention)汇聚
-
第二个子层为 基于位置的前馈网络(positionwise feed-forward network)
-
-
在计算编码器的自注意力时,查询、键和值都来自前一个编码器层的输出
-
每个子层都采用了残差连接(residual connection)
-
残差连接的加法计算之后紧接着应用层规范化(layer normalization)
-
-
解码器:
-
由多个相同的层 叠加 而成,除了编码器中描述的两个子层之外,解码器还在这两个子层之间插入了第三个子层:
- 编码器-解码器注意力(encoder-decoder attention)层
-
在解码器自注意力中,查询、键和值都来自上一个解码器层的输出
-
在第三个子层编码器-解码器注意力层中,查询来自前一个解码器层的输出,而键和值来自整个编码器的输出
-
import math
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
10.7.2 基于位置的前馈网络
基于位置的前馈网络对序列中的所有位置的表示进行变换时使用的是同一个多层感知机(MLP),这就是称前馈网络是基于位置的(positionwise)的原因。
名字很帅,其实就是全连接,但隐藏层的 MLP : )
输入X的形状(批量大小,时间步数或序列长度,隐单元数或特征维度)将被一个两层的感知机转换成形状为(批量大小,时间步数,ffn_num_outputs)的输出张量。
#@save
class PositionWiseFFN(nn.Module):"""基于位置的前馈网络"""def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs,**kwargs):super(PositionWiseFFN, self).__init__(**kwargs)self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)self.relu = nn.ReLU()self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)def forward(self, X):return self.dense2(self.relu(self.dense1(X)))
ffn = PositionWiseFFN(4, 4, 8)
ffn.eval()
ffn(torch.ones((2, 3, 4)))[0] # 把最后一个维度升上去
tensor([[-0.2199, 0.1357, -0.2216, 0.1659, 0.5388, -0.4541, 0.2121, -0.1025],[-0.2199, 0.1357, -0.2216, 0.1659, 0.5388, -0.4541, 0.2121, -0.1025],[-0.2199, 0.1357, -0.2216, 0.1659, 0.5388, -0.4541, 0.2121, -0.1025]],grad_fn=<SelectBackward0>)
10.7.3 残差连接和层规范化
批量归一化对每个特征/通道里的元素进行归一化,不适合序列长度会变的 NLP 应用。
层规范化和批量规范化的目标相同,但层规范化是基于特征维度进行规范化,即对每个样本里的元素进行归一化。

ln = nn.LayerNorm(2)
bn = nn.BatchNorm1d(2)
X = torch.tensor([[1, 2], [2, 3]], dtype=torch.float32)
# 在训练模式下计算X的均值和方差
print('layer norm:', ln(X), '\nbatch norm:', bn(X)) # layer norm 规范化的是每个样本(行) batch norm 规范化的是每个特征(列)
layer norm: tensor([[-1.0000, 1.0000],[-1.0000, 1.0000]], grad_fn=<NativeLayerNormBackward0>)
batch norm: tensor([[-1.0000, -1.0000],[ 1.0000, 1.0000]], grad_fn=<NativeBatchNormBackward0>)
#@save
class AddNorm(nn.Module):"""残差连接后进行层规范化"""def __init__(self, normalized_shape, dropout, **kwargs):super(AddNorm, self).__init__(**kwargs)self.dropout = nn.Dropout(dropout) # 暂退法也被作为正则化方法使用self.ln = nn.LayerNorm(normalized_shape) # 层规范化def forward(self, X, Y):return self.ln(self.dropout(Y) + X) # 残差连接
add_norm = AddNorm([3, 4], 0.5)
add_norm.eval()
add_norm(torch.ones((2, 3, 4)), torch.ones((2, 3, 4))).shape # 残差连接要求两个输入的形状相同
torch.Size([2, 3, 4])
10.7.4 编码器
EncoderBlock 类包含两个子层:多头自注意力和基于位置的前馈网络,这两个子层都使用了残差连接和紧随的层规范化。
#@save
class EncoderBlock(nn.Module):"""Transformer编码器块"""def __init__(self, key_size, query_size, value_size, num_hiddens, # 写的很多,实际都是一个数norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,dropout, use_bias=False, **kwargs):super(EncoderBlock, self).__init__(**kwargs)self.attention = d2l.MultiHeadAttention( # 第一层 多头注意力层key_size, query_size, value_size, num_hiddens, num_heads, dropout,use_bias)self.addnorm1 = AddNorm(norm_shape, dropout) # 第一个层规范化self.ffn = PositionWiseFFN( # 第二层 前馈网络层ffn_num_input, ffn_num_hiddens, num_hiddens)self.addnorm2 = AddNorm(norm_shape, dropout) # 第二个规范化层def forward(self, X, valid_lens):Y = self.addnorm1(X, self.attention(X, X, X, valid_lens)) # 第一层return self.addnorm2(Y, self.ffn(Y)) # 第二层
X = torch.ones((2, 100, 24))
valid_lens = torch.tensor([3, 2])
encoder_blk = EncoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5)
encoder_blk.eval()
encoder_blk(X, valid_lens).shape # Transformer编码器中的任何层都不会改变其输入的形状
torch.Size([2, 100, 24])
以下对 num_layers个EncoderBlock 类的实例进行了堆叠。
这里使用的是值范围在 -1 和 1 之间的固定位置编码,因此通过学习得到的输入的嵌入表示的值需要先乘以嵌入维度的平方根进行重新缩放,然后再与位置编码相加。
#@save
class TransformerEncoder(d2l.Encoder):"""Transformer编码器"""def __init__(self, vocab_size, key_size, query_size, value_size,num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, num_layers, dropout, use_bias=False, **kwargs):super(TransformerEncoder, self).__init__(**kwargs)self.num_hiddens = num_hiddensself.embedding = nn.Embedding(vocab_size, num_hiddens) # 嵌入层self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout) # 位置编码self.blks = nn.Sequential() # 编码器for i in range(num_layers):self.blks.add_module("block"+str(i), # 添加编码器的各层EncoderBlock(key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, dropout, use_bias))def forward(self, X, valid_lens, *args):# 因为位置编码值在-1和1之间,数值比较小,因此嵌入值乘以嵌入维度的平方根缩放到差不多大小,然后再与位置编码相加。X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))self.attention_weights = [None] * len(self.blks) # 存注意力汇聚权重用的for i, blk in enumerate(self.blks):X = blk(X, valid_lens) # 一层一层的丢进去进行 attentionself.attention_weights[ # 记录注意力汇聚权重i] = blk.attention.attention.attention_weightsreturn X
encoder = TransformerEncoder( # 创建一个两层的Transformer编码器200, 24, 24, 24, 24, [100, 24], 24, 48, 8, 2, 0.5)
encoder.eval()
encoder(torch.ones((2, 100), dtype=torch.long), valid_lens).shape # 输出的形状是(批量大小,时间步数目,num_hiddens)
torch.Size([2, 100, 24])
10.7.5 解码器
DecoderBlock 类中实现的每个层包含了三个子层:解码器自注意力、“编码器-解码器”注意力和基于位置的前馈网络。这些子层也都被残差连接和紧随的层规范化围绕。
class DecoderBlock(nn.Module):"""解码器中第i个块"""def __init__(self, key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,dropout, i, **kwargs):super(DecoderBlock, self).__init__(**kwargs)self.i = iself.attention1 = d2l.MultiHeadAttention( # 第一层 解码器的自注意力层key_size, query_size, value_size, num_hiddens, num_heads, dropout)self.addnorm1 = AddNorm(norm_shape, dropout) # 第一个层规范化self.attention2 = d2l.MultiHeadAttention( # 第二层 “编-解”注意力层key_size, query_size, value_size, num_hiddens, num_heads, dropout)self.addnorm2 = AddNorm(norm_shape, dropout) # 第二个层规范化self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, # 第三层 掐灭亏网络层num_hiddens)self.addnorm3 = AddNorm(norm_shape, dropout) # 第三个层规范化def forward(self, X, state):enc_outputs, enc_valid_lens = state[0], state[1]if state[2][self.i] is None: # 训练阶段,输出序列的所有词元都在同一时间处理,因此state[2][self.i]初始化为None。key_values = Xelse: # 预测阶段,输出序列是通过词元一个接着一个解码的,因此需要把直到当前时间步第i个块解码的输出在state[2][self.i]里面存着key_values = torch.cat((state[2][self.i], X), axis=1)state[2][self.i] = key_valuesif self.training:batch_size, num_steps, _ = X.shape# dec_valid_lens 的开头:(batch_size,num_steps),其中每一行是[1,2,...,num_steps]dec_valid_lens = torch.arange( # 只要训练状态下需要遮掉后面的内容1, num_steps + 1, device=X.device).repeat(batch_size, 1)else: # 预测模式后面空白的 不用管dec_valid_lens = NoneX2 = self.attention1(X, key_values, key_values, dec_valid_lens) # 自注意力Y = self.addnorm1(X, X2)Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens) # 编码器-解码器注意力。enc_outputs的开头:(batch_size,num_steps,num_hiddens)Z = self.addnorm2(Y, Y2)return self.addnorm3(Z, self.ffn(Z)), state
decoder_blk = DecoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5, 0)
decoder_blk.eval()
X = torch.ones((2, 100, 24))
state = [encoder_blk(X, valid_lens), valid_lens, [None]]
decoder_blk(X, state)[0].shape # 过一遍形状不变的
torch.Size([2, 100, 24])
class TransformerDecoder(d2l.AttentionDecoder):def __init__(self, vocab_size, key_size, query_size, value_size,num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, num_layers, dropout, **kwargs):super(TransformerDecoder, self).__init__(**kwargs)self.num_hiddens = num_hiddensself.num_layers = num_layersself.embedding = nn.Embedding(vocab_size, num_hiddens) # 词嵌入层self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout) # 位置编码self.blks = nn.Sequential() # 解码器for i in range(num_layers):self.blks.add_module("block"+str(i), # 添加解码器的各层DecoderBlock(key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, dropout, i))self.dense = nn.Linear(num_hiddens, vocab_size) # 最后的全连接层def init_state(self, enc_outputs, enc_valid_lens, *args):return [enc_outputs, enc_valid_lens, [None] * self.num_layers] # 最后那个是预测时存东西用的def forward(self, X, state):X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens)) # 叠加位置编码self._attention_weights = [[None] * len(self.blks) for _ in range (2)] # 存注意力汇聚权重用的for i, blk in enumerate(self.blks):X, state = blk(X, state)self._attention_weights[0][ # 存解码器自注意力权重i] = blk.attention1.attention.attention_weightsself._attention_weights[1][ # 存“编码器-解码器”自注意力权重i] = blk.attention2.attention.attention_weightsreturn self.dense(X), state@propertydef attention_weights(self):return self._attention_weights
10.7.6 训练
依照 Transformer 架构来实例化编码器-解码器模型。
num_hiddens, num_layers, dropout, batch_size, num_steps = 32, 2, 0.1, 64, 10 # 指定编码器和解码器都是2层
lr, num_epochs, device = 0.005, 200, d2l.try_gpu()
ffn_num_input, ffn_num_hiddens, num_heads = 32, 64, 4 # 都使用4头注意力
key_size, query_size, value_size = 32, 32, 32
norm_shape = [32]train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)encoder = TransformerEncoder( # 整一个编码器len(src_vocab), key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,num_layers, dropout)
decoder = TransformerDecoder( # 整一个解码器len(tgt_vocab), key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder) # 组网
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device) # 并行度应该挺高的 训起来不慢 1分9秒
loss 0.031, 6866.6 tokens/sec on cuda:0

训练结束后,使用 Transformer 模型将一些英语句子翻译成法语,并且计算它们的BLEU分数。
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):translation, dec_attention_weight_seq = d2l.predict_seq2seq(net, eng, src_vocab, tgt_vocab, num_steps, device, True)print(f'{eng} => {translation}, ',f'bleu {d2l.bleu(translation, fra, k=2):.3f}')
go . => va !, bleu 1.000
i lost . => j'ai perdu ., bleu 1.000
he's calm . => il est paresseux ., bleu 0.658
i'm home . => je suis chez moi ., bleu 1.000
可视化 Transformer 的注意力权重。
enc_attention_weights = torch.cat(net.encoder.attention_weights, 0).reshape((num_layers, num_heads,-1, num_steps))
enc_attention_weights.shape # 编码器自注意力权重的形状为(编码器层数,注意力头数,num_steps或查询的数目,num_steps或“键-值”对的数目)
torch.Size([2, 4, 10, 10])
d2l.show_heatmaps( # 逐行呈现编码器的两层多头注意力的权重enc_attention_weights.cpu(), xlabel='Key positions',ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)],figsize=(7, 3.5)) # 可以看到每个注意力头的注意力都不大一样。

用零填充被掩蔽住的注意力权重后,可视化解码器的自注意力权重和“编码器-解码器”的注意力权重。
解码器的自注意力权重和“编码器-解码器”的注意力权重都有相同的查询:即以序列开始词元(beginning-of-sequence,BOS)打头,再与后续输出的词元共同组成序列。
dec_attention_weights_2d = [head[0].tolist()for step in dec_attention_weight_seqfor attn in step for blk in attn for head in blk]
dec_attention_weights_filled = torch.tensor(pd.DataFrame(dec_attention_weights_2d).fillna(0.0).values) # 用零填充被掩蔽住的注意力权重
dec_attention_weights = dec_attention_weights_filled.reshape((-1, 2, num_layers, num_heads, num_steps))
dec_self_attention_weights, dec_inter_attention_weights = \dec_attention_weights.permute(1, 2, 3, 0, 4)
dec_self_attention_weights.shape, dec_inter_attention_weights.shape
(torch.Size([2, 4, 6, 10]), torch.Size([2, 4, 6, 10]))
由于解码器自注意力的自回归属性,查询不会对当前位置之后的“键-值”对进行注意力计算。
d2l.show_heatmaps( # 逐行呈现解码器的多头自注意力的权重dec_self_attention_weights[:, :, :, :len(translation.split()) + 1],xlabel='Key positions', ylabel='Query positions',titles=['Head %d' % i for i in range(1, 5)], figsize=(7, 3.5))

与编码器的自注意力的情况类似,通过指定输入序列的有效长度,输出序列的查询不会与输入序列中填充位置的词元进行注意力计算。
d2l.show_heatmaps( # 逐行呈现解码器的编-解多头自注意力的权重dec_inter_attention_weights, xlabel='Key positions',ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)],figsize=(7, 3.5))

练习
(1)在实验中训练更深的 Transformer 将如何影响训练速度和翻译效果?
更慢了,注意力越往后越浓重。
num_hiddens, num_layers_deeper, dropout, batch_size, num_steps = 32, 4, 0.1, 64, 10 # 加深到 4 层
lr, num_epochs, device = 0.005, 200, d2l.try_gpu()
ffn_num_input, ffn_num_hiddens, num_heads = 32, 64, 4 # 还是4头注意力
key_size, query_size, value_size = 32, 32, 32
norm_shape = [32]train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)encoder_deeper = TransformerEncoder(len(src_vocab), key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,num_layers_deeper, dropout)
decoder_deeper = TransformerDecoder(len(tgt_vocab), key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,num_layers_deeper, dropout)
net_deeper = d2l.EncoderDecoder(encoder_deeper, decoder_deeper)
d2l.train_seq2seq(net_deeper, train_iter, lr, num_epochs, tgt_vocab, device) # 时间慢到2分了 怎么精度跌了
loss 0.063, 4044.0 tokens/sec on cuda:0

engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):translation, dec_attention_weight_seq = d2l.predict_seq2seq(net_deeper, eng, src_vocab, tgt_vocab, num_steps, device, True)print(f'{eng} => {translation}, ',f'bleu {d2l.bleu(translation, fra, k=2):.3f}')
go . => va le chercher !, bleu 0.000
i lost . => je me suis tombé ., bleu 0.000
he's calm . => il est malade ., bleu 0.658
i'm home . => je suis sûr ., bleu 0.512
enc_attention_weights_deeper = torch.cat(net_deeper.encoder.attention_weights, 0).reshape((num_layers_deeper, num_heads,-1, num_steps))d2l.show_heatmaps(enc_attention_weights_deeper.cpu(), xlabel='Key positions',ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)],figsize=(10, 8))

dec_attention_weights_2d_deeper = [head[0].tolist()for step in dec_attention_weight_seqfor attn in step for blk in attn for head in blk]
dec_attention_weights_filled_deeper = torch.tensor(pd.DataFrame(dec_attention_weights_2d_deeper).fillna(0.0).values) # 用零填充被掩蔽住的注意力权重
dec_attention_weights_deeper = dec_attention_weights_filled_deeper.reshape((-1, 2, num_layers_deeper, num_heads, num_steps))
dec_self_attention_weights_deeper, dec_inter_attention_weights_deeper = \dec_attention_weights_deeper.permute(1, 2, 3, 0, 4)d2l.show_heatmaps( # 逐行呈现解码器的多头自注意力的权重dec_self_attention_weights_deeper[:, :, :, :len(translation.split()) + 1],xlabel='Key positions', ylabel='Query positions',titles=['Head %d' % i for i in range(1, 5)], figsize=(10, 8))

d2l.show_heatmaps(dec_inter_attention_weights_deeper, xlabel='Key positions',ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)],figsize=(10, 8))

(2)在 Transformer 中使用加性注意力取代缩放点积注意力是不是个好办法?为什么?
用加性的会慢点。
(3)对于语言模型,应该使用 Transformer 的编码器还是解码器,或者两者都用?如何设计?
我不道哇,还有半用半不用的?
(4)如果输入序列很长,Transformer 会面临什么挑战?为什么?
越长越不好算,太长了需要注意的就太多了。
(5)如何提高 Transformer 的计算速度和内存使用效率?提示:可以参考论文 (Tay et al., 2020)。
略。
(6)如果不使用卷积神经网络,如何设计基于 Transformer 模型的图像分类任务?提示:可以参考Vision Transformer (Dosovitskiy et al., 2021)。
图像切块。
相关文章:
《动手学深度学习 Pytorch版》 10.7 Transformer
自注意力同时具有并行计算和最短的最大路径长度这两个优势。Transformer 模型完全基于注意力机制,没有任何卷积层或循环神经网络层。尽管 Transformer 最初是应用于在文本数据上的序列到序列学习,但现在已经推广到各种现代的深度学习中,例如语…...

ORACLE-递归查询、树操作
1. 数据准备 -- 测试数据准备 DROP TABLE untifa_test;CREATE TABLE untifa_test(child_id NUMBER(10) NOT NULL, --子idtitle VARCHAR2(50), --标题relation_type VARCHAR(10) --关系,parent_id NUMBER(10) --父id );insert into untifa_test (CHILD_ID, TITLE, RELATION_TYP…...

MySQL篇---第四篇
系列文章目录 文章目录 系列文章目录一、并发事务带来哪些问题?二、事务隔离级别有哪些?MySQL的默认隔离级别是?三、大表如何优化?一、并发事务带来哪些问题? 在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对 同一数据进行操作…...

em/px/rem/vh/vw单位的区别
一、绝对长度单位 1.px 表示像素,显示器上每个像素点大小都是相同的 二、相对长度单位 2.em 相对于当前对象内文本的字体尺寸,如未设置对行内文本字体的尺寸,则相对于浏览器的默认字体(1em16px) em值不是固定的&…...
【C++】多态 ③ ( “ 多态 “ 实现需要满足的三个条件 | “ 多态 “ 的应用场景 | “ 多态 “ 的思想 | “ 多态 “ 代码示例 )
文章目录 一、" 多态 " 实现条件1、" 多态 " 实现需要满足的三个条件2、" 多态 " 的应用场景3、" 多态 " 的思想 二、" 多态 " 代码示例 一、" 多态 " 实现条件 1、" 多态 " 实现需要满足的三个条件 &q…...
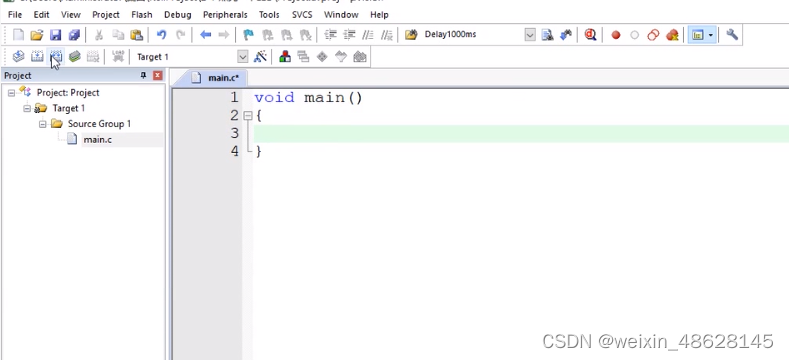
创建一个Keil项目
1、创建项目 2、选择存放的文件夹,还有设置项目名 3、选择型号(因为没有STC,用下面这个替代,功能差不多) 4、选择不用启动文件 5、就会得到下面这个,可以在Source Group 1下面编写代码了 6、右键source Group 1,添加c语…...
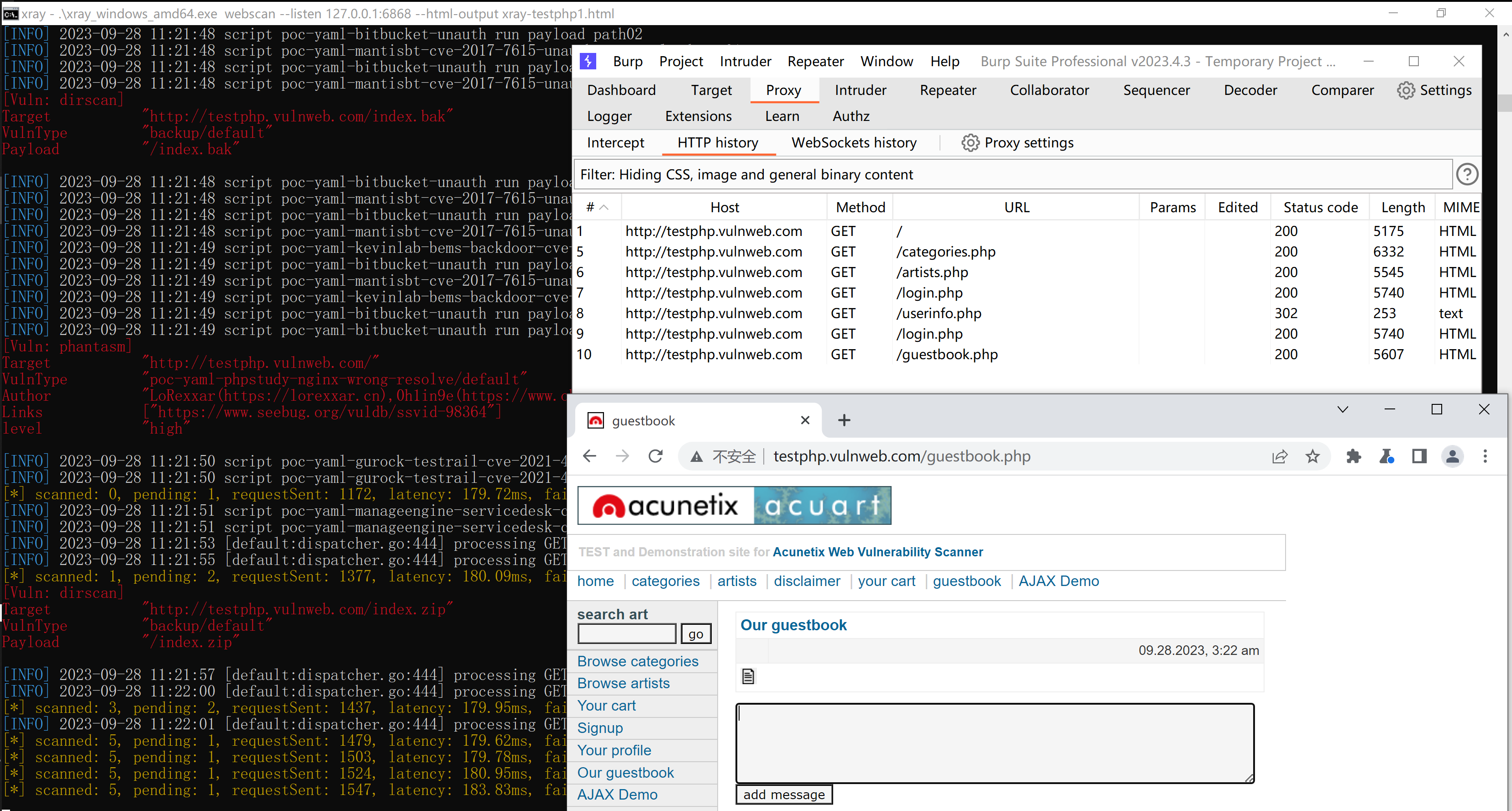
Xray的简单使用
xray 简介 xray 是一款功能强大的安全评估工具,由多名经验丰富的一线安全从业者呕心打造而成,主要特性有: 检测速度快。发包速度快; 漏洞检测算法效率高。支持范围广。大至 OWASP Top 10 通用漏洞检测,小至各种 CMS 框架 POC,均…...

Linux Ubunto Nginx安装
一 安装前 环境准备 gcc $ sudo apt-get install gcc zlib $ sudo apt-get install zlib1g-dev pcre $ sudo apt-get install libpcre3 libpcre3-dev openssl $ sudo apt-get install openssl libssl-dev‘ ubuntu 安装 libssl-dev失败的解决方案 1.安装aptitude sudo apt-g…...

深度学习中的epoch, batch 和 iteration
名词定义epoch使用训练集的全部数据进行一次完整的训练,称为“一代训练”batch使用训练集中的一小部分样本对模型权重进行一次反向传播的参数更新,这样的一部分样本称为:“一批数据”iteration使用一个batch的数据对模型进行一次参数更新的过…...

unity开发安卓视频文件适配手机和平板
using UnityEngine; using UnityEngine.UI;public class VideoResize : MonoBehaviour {private RawImage rawImage;private VideoPlayer videoPlayer;private void Start(){rawImage GetComponent<RawImage();videoPlayer GetComponent<VideoPlayer>();// 播放视频…...
)
NLP之RNN的原理讲解(python示例)
目录 代码示例代码解读知识点介绍 代码示例 import numpy as np import tensorflow as tf from tensorflow.keras.layers import SimpleRNNCell# 第t时刻要训练的数据 xt tf.Variable(np.random.randint(2, 3, size[1, 1]), dtypetf.float32) print(xt) # https://www.cnblog…...

yo!这里是进程间通信
目录 前言 进程间通信简介 目的 分类 匿名通道 介绍 举例(进程池) 命名管道 介绍 举例 共享内存 介绍 共享内存函数 1.shmget 2.shmat 3.shmdt 4.shmctl 举例 1.框架 2.通信逻辑 消息队列 信号量 同步与互斥 理解信号量 后记…...

使用docker安装MySQL,Redis,Nacos,Consul教程
文章目录 安装MySQL安装Redis安装Nacos安装Consul 如未安装docker,参考教程: https://blog.csdn.net/m0_63230155/article/details/134090090 安装MySQL #拉取镜像 sudo docker pull mysql:latestsudo docker run --name mysql \-p 3306:3306 \-e MYSQ…...

python和Springboot如何交互?
Python和Spring Boot可以通过RESTful API进行交互。Spring Boot通常用于后端开发,提供了快速构建RESTful API的工具,而Python则可以用于编写前端或与后端交互的代码。 要实现Python和Spring Boot的交互,可以按照以下步骤进行: 在…...

Qt实现json解析
前提要点 json文件,可通过键值的方式存储你所需要的数据,斌且支持多种类型存储,类似于一种结构化的数据库,在读取json文件时可通过相对应的关键字精准获取。他是一种树状结构,我们可以自己设定叶子的数量以及他所代表…...

Ajax、Json深入浅出,及原生Ajax及简化版Ajax
Ajax 1.路径介绍 1.1 JavaWeb中的路径 在JavaWeb中,路径分为相对路径和绝对路径两种: 相对路径: ./ 表示当前目录(可省略) ../ 表示当前文件所在目录的上一级目录 绝对路径: http://ip:port/工程名/资源路径 2.2 在JavaWeb中…...

前端第一阶段测试
前端第一阶段测试 选择问答 如果觉得有用请给我点个赞⑧~ 选择 1、【单选】下列哪个是子代选择器 A A、p>b B、p b C、pb D、p.b 2、【单选】下述有关css属性position的属性值的描述,说法错误的是?B A、static:没有定位,元素出…...

openlayers+vue的bug
使用addInteraction添加交互draw绘制,预期removeInteraction删除交互draw绘制时不再绘制,但是删除绘制不起作用,各种找原因,结果把data中的map变量注释掉即可,原因未知。 <template><div><div id"…...
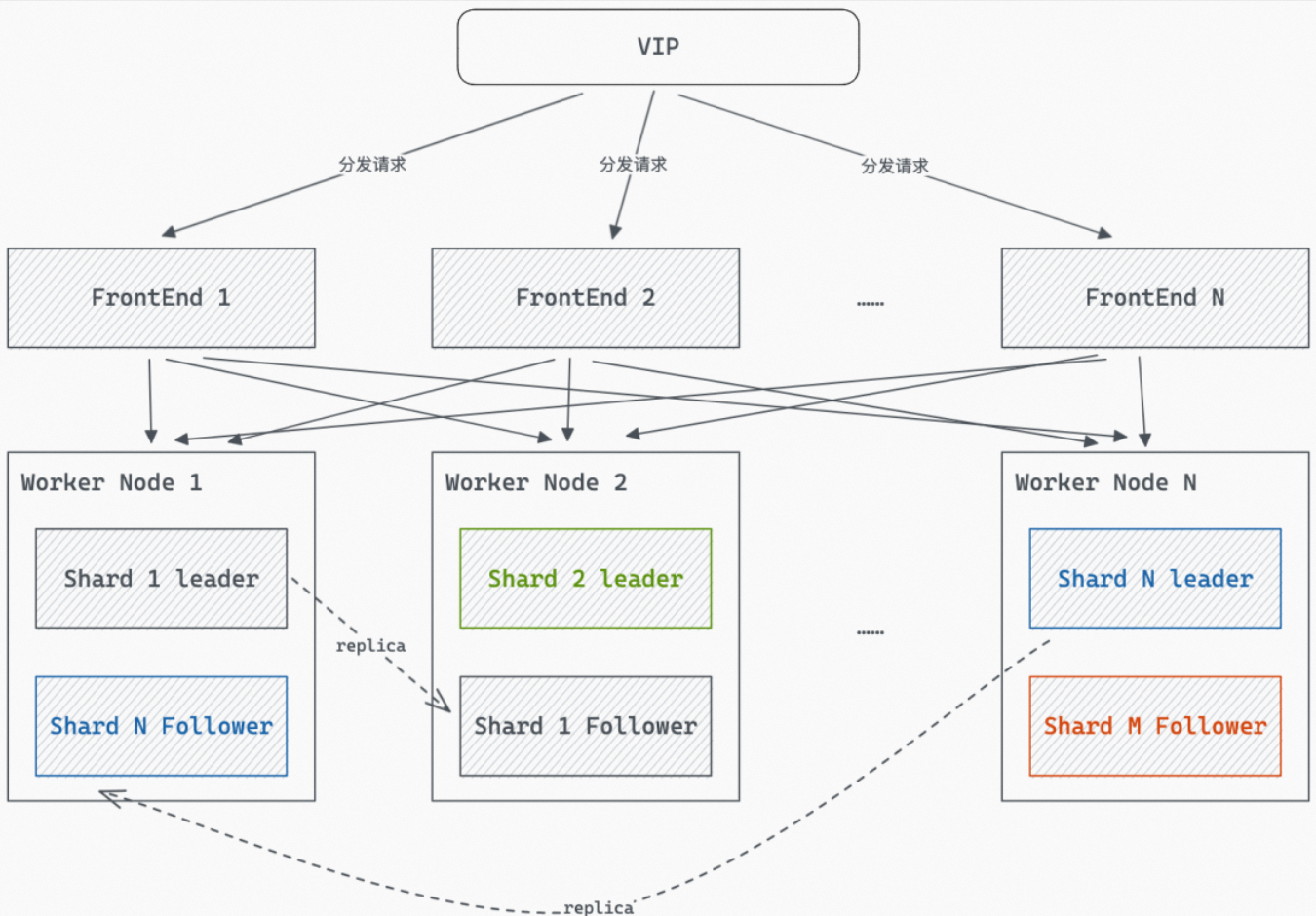
实时数仓-Hologres介绍与架构
本文是向大家介绍Hologres是一款实时HSAP产品,隶属阿里自研大数据品牌MaxCompute,兼容 PostgreSQL 生态、支持MaxCompute数据直接查询,支持实时写入实时查询,实时离线联邦分析,低成本、高时效、快速构筑企业实时数据仓…...
asp.net教务管理信息系统VS开发sqlserver数据库web结构c#编程Microsoft Visual Studio计算机毕业设计
一、源码特点 asp.net 教务管理信息系统是一套完善的web设计管理系统,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为vs2010,数据库为sqlserver2008,使用c#语言 开发 asp.net教务管理系统 应用技术&a…...

TVA注意力层INT8量化配置技巧
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

JS中forEach与普通for
for就不用说了,最普通的循环函数forEach1. 只写 1 个参数只接收当前遍历元素let arr [10,20,30] arr.forEach(item > {console.log(item) // 依次 10、20、30 })2. 写 2 个参数依次接收元素值、下标索引let arr [10,20,30] arr.forEach((item, index) > {co…...

基于晶体管逻辑的水箱自动控制器设计与实现
1. 项目概述:一个基于晶体管逻辑的自动水箱/湿度灌溉控制器 如果你也像我一样,曾经为家里的花园、阳台植物或者农村老家的储水塔手动开关水泵而烦恼,那么这个项目就是为你准备的。我设计并制作了一个完全自动化的水箱水位控制器,它…...
)
市面上有哪些是真正安全的降AIGC网站(轻松压低AI生成疑似率)
最崩溃的不是查重难题,而是查重达标却AI率超标亮红灯!很多工具只会简单同义词替换、浅层改字,根本洗不掉AI专属句式、行文逻辑和高频模板话术,学校AIGC检测一查一个准,论文直接凉凉。 本篇结合全网实测数据,…...

关于软件版本升级的故事
起因在群里有网友说软件的版本升级比较简单,俺就回了四个字母“PACS”,并补上了一个表情 然后看见开始细说了:一、PACS 属于哪一类?PACS 软件 第二类医疗器械(独立软件)国家药监局分类:Ⅱ 类 2…...

CANoe测试效率翻倍:手把手教你用XML Test Module搭建可复用的测试套件
CANoe测试效率翻倍:手把手教你用XML Test Module搭建可复用的测试套件在车载电子系统开发中,测试环节往往占据整个项目周期的40%以上时间。面对频繁的ECU软件迭代和多样化配置需求,传统逐个脚本执行测试的方式已经无法满足敏捷开发的要求。本…...

QuickDraw MediaPipe手势识别:无需画笔的手势控制绘画应用
QuickDraw MediaPipe手势识别:无需画笔的手势控制绘画应用 【免费下载链接】QuickDraw Implementation of Quickdraw - an online game developed by Google 项目地址: https://gitcode.com/gh_mirrors/qu/QuickDraw QuickDraw MediaPipe手势识别是一款创新…...

为Claude Code配置Taotoken解决账号封禁与Token不足难题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置Taotoken解决账号封禁与Token不足难题 对于依赖Claude Code进行日常编程辅助的开发者而言,直接使用官…...

League Akari:英雄联盟客户端智能自动化工具包实战指南
League Akari:英雄联盟客户端智能自动化工具包实战指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari是一款基于英雄…...

大学生零成本副业!SRC 漏洞挖掘入门教程,玩法收益一次性讲清
大学生零成本副业!SRC 漏洞挖掘入门教程,玩法收益一次性讲清 摘要:对大学生来说,找副业最核心的需求是“时间灵活、门槛低、能兼顾学习、有长期成长”,而SRC漏洞挖掘正是完美契合这些需求的选择——无需编程基础、无需…...