Pytorch代码入门学习之分类任务(二):定义数据集
一、导包
import torch
import torchvision
import torchvision.transforms as transforms二、下载数据集
2.1 代码展示
# 定义数据加载进来后的初始化操作:
transform = transforms.Compose([# 张量转换:transforms.ToTensor(),# 归一化操作:transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
])trainset = torchvision.datasets.CIFAR10(root='./data',train=True,download=True,transform=transform)
testset = torchvision.datasets.CIFAR10(root='./data',train=False,download=True,transform=transform)
trainloader = torch.utils.data.DataLoader(trainset,batch_size=4,shuffle=True,num_workers=0)
testloader = torch.utils.data.DataLoader(testset,batch_size=4,shuffle=False,num_workers=0)
2.2 数据集介绍与下载方式
(1)数据集介绍:
CIFAR10数据集共60000个样本,其中有50000个训练样本和10000个测试样本。每个样本都是一张32*32像素的RGB图像(彩色图像),每个图像分为3个通道(R通道、G通道与B通道)。
CIFAR10数据集用来进行监督学习训练,每个样本包含一个标签值,其中有10类物体,标签值按照0~9来区分,分别是飞机( airplane )、汽车( automobile )、鸟( bird )、猫( cat )、鹿( deer )、狗( dog )、青蛙( frog )、马( horse )、船( ship )和卡车( truck )。
CIFAR10数据集的内容,如下图所示。

官网介绍链接:CIFAR-10 and CIFAR-100 datasets (toronto.edu)
(2)下载方式:
①下载文件:下载地址:https://pan.baidu.com/s/1Nh28RyfwPNNfe_sS8NBNUA
提取码:1h4x
②将下载好的文件重命名为cifar-10-batches-py.tar.gz
③将文件保存至相应地址下即可
2.3 transforms.Compose
transforms.Compose:相当于将所有需要的操作进行打包;
transforms.ToTensor:完成张量转换,pytorch处理的都是tensor数据,需要将读入的图片转换为tensor,其中tensor比普通图片的三通道多了一个通道—batch;
transforms.Normalize:归一化操作,对这一批次的数据进行归一,可以加速网络的收敛、放置梯度消失与梯度爆炸。
2.4 Dataset
Dataset是指定义好数据的格式和数据变换的形式,完成一些初始化的变化,然后送给网络(相当于将数据读入进去)。
torchvision.datasets.CIFAR10(调用数据集):第一个参数为数据集加载的地址、第二个参数为是否是训练数据或测试数据(训练数据为True,测试数据为False)、第三个为download-指该数据集是否本地下载,最后一个参数为要做哪些变化(transform是指数据变换格式,torchvision会将我们需要的数据进行格式变换)。
2.4 Dataloader
Dataloader:负责用iterative迭代的方式不断读入批次数据,一批次一批次将数据进行打包,送入网络进行训练、学习、测试。
torch.utils.data.DataLoader:第一个参数为数据,第二个参数为batch_size(代表Dataloader一次从这么多数据中拿多少个数据走),第三个参数为是否将数据打乱(训练的时候将数据打乱会让数据变得复杂,测试的时候不需要变得复杂),第四个参数为需要几线程进行读取数据(对于windows,默认为0就可以)
三、定义元组
定义元组进行类别名的中文转换:
classes = ('airplane','automobile','bird','car','deer','dog','frog','horse','ship','truck')四、定义显示函数与运行数据加载器
4.1 代码展示
import matplotlib.pyplot as plt
import numpy as np # 用这个包中的根据将tensor数据转换成矩阵数据def imshow(img):img = img / 2 + 0.5# tensor数据转换为numpynpimg = img.numpy()# 使用transpose进行数据转换-通道转换plt.imshow(np.transpose(npimg,(1,2,0)))plt.show()dataiter = iter(trainloader)
images,labels = dataiter.next()imshow(torchvision.utils.make_grid(images))print(labels)
print(labels[0],classes[labels[0]])
print(' '.join(classes[labels[j]] for j in range(4)))
4.2 定义显示函数
tensor[batch,channel,H,W],而正常显示图片的顺序为H、W、channel,因此需要定义显示函数,通过反归一化才能变成正常的图片去显示。
4.3 定义迭代器
iter(trainloader) : 定义迭代器,读一次迭代的数据(batch_size=4,所以迭代器一次会读取四张图片);
torchvision.utils.make_grid:将多张图片拼接为一张图片。
参考:003 第一个分类任务1_哔哩哔哩_bilibili
相关文章:
Pytorch代码入门学习之分类任务(二):定义数据集
一、导包 import torch import torchvision import torchvision.transforms as transforms 二、下载数据集 2.1 代码展示 # 定义数据加载进来后的初始化操作: transform transforms.Compose([# 张量转换:transforms.ToTensor(),# 归一化操作&#x…...

oracle 里常用的一些 create insert update table
1、获得数据库里某个指定的库 SELECT COUNT(*) FROM ALL_TABLES ut WHERE ut.OWNERTJFX AND ut.TABLE_NAME CUR_TIME_BILL; 2、创建一个表,里面的数据可以从一个已存在的表里转移过来 CREATE TABLE temptable AS SELECT * FROM old_tbName //使用现有的表创建一…...

从Mysql架构看一条查询sql的执行过程
1. 通信协议 我们的程序或者工具要操作数据库,第一步要做什么事情? 跟数据库建立连接。 首先,MySQL必须要运行一个服务,监听默认的3306端口。在我们开发系统跟第三方对接的时候,必须要弄清楚的有两件事。 第一个就是通…...
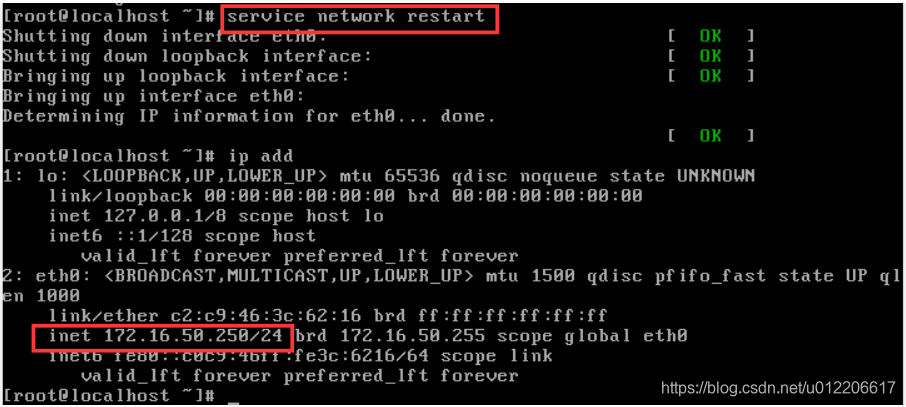
Linux系统下DHCP服务安装部署和使用实例详解(蜜罐)
目录 一、概述 二、具体配置如下: 一、概述 DHCP :动态主机设置协议(英语:Dynamic Host Configuration Protocol,DHCP)是一个局域网的网络协议,使用UDP协议工作,主要有两个用途&…...

模数转换器-ADC基础
文章目录 一、ADC是什么二、ADC处理采样保持量化编码三、ADC采样的重要参数:测量范围:分辨率(Resolution):精度:采样时间:采样率(Sampling Rate):信噪比(Signal-to-Noise Ratio, SNR):转换时间:一、ADC是什么 ADC(Analog-to-Digital Converter):模拟数字转换器…...

Linux:【1】Linux中的文件权限概念和相关命令
Linux:【1】Linux中的文件权限概念和相关命令 1、什么是文件权限?1.1、文件权限的表示方式 2、理解文件权限2.1、用户权限2.2、组权限2.3、其他权限 3、设置文件权限3.1、chmod 命令3.2、权限符号表示法3.3、权限数字表示法 4、查看文件权限4.1、ls 命令…...

JS实用小计
1.如何创建一个数组大小为100,每个值都为0的数组 // 方法一: Array(100).fill(0);// 方法二: // 注: 如果直接使用 map,会出现稀疏数组 Array.from(Array(100), (x) > 0);// 方法二变体: Array.from({ length: 100 }, (x) > 0); 2.如何逆序一个字…...
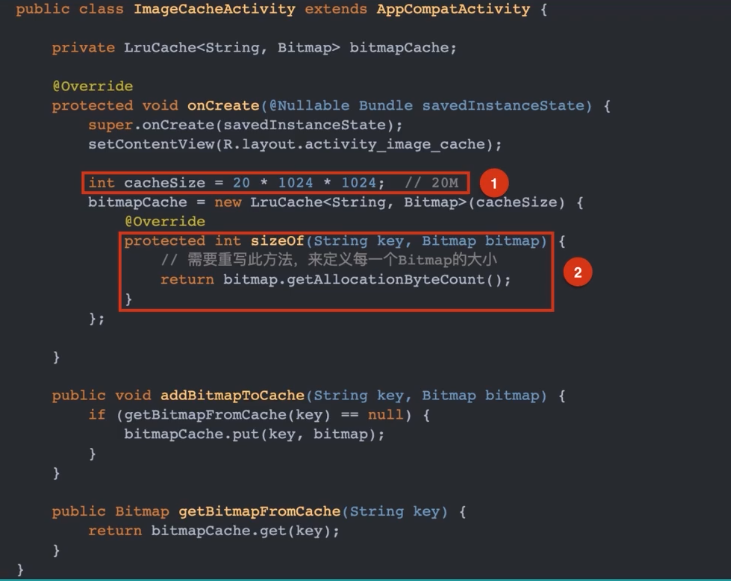
Android---Bitmap详解
每一个 Android App 中都会使用到 Bitmap,它也是程序中内存消耗的大户,当 Bitmap 使用内存超过可用空间,则会报 OOM。 Bitmap 占用内存分析 Bitmap 用来描述一张图片的长、宽、颜色等信息,可用使用 BitmapFactory 来将某一路径下…...

设计高信度和效度的问卷:关键要点与技巧
设计调查问卷是任何研究过程中至关重要的一部分,无论是出于学术目的还是商业目的。调查是用于收集数据的常用工具,它们可以为消费者行为、意见、客户满意度和其他重要因素提供有价值的见解。然而,调查的可靠性和有效性对于确保收集的数据准确…...

从工厂到社会:探索如何应用设计模式工厂模式
文章目录 🌟 将设计模式工厂模式运用到社会当中🍊 工厂模式在社会中的应用🎉 工厂🎉 餐厅🎉 运输 🍊 工厂模式的优势🎉 代码简洁🎉 扩展性强🎉 便于维护和管理 …...
和splice()用法)
slice()和splice()用法
前言: slice()和splice()都是JavaScript中数组的方法,但是它们的用法有所不同。接下来让我们详细分析一下他们的不同之处。 slice(): slice()方法返回一个数组的一部分,不会改变原始数组,而是返回一个新数组。 语法…...
基于windows10的pytorch环境部署及yolov8的安装及测试
第一章 pytorch环境部署留念 第一步:下载安装anaconda 官网地址 (也可以到清华大学开源软件镜像站下载:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/) 我安装的是下面这个,一通下一步就完事儿。 第二步…...
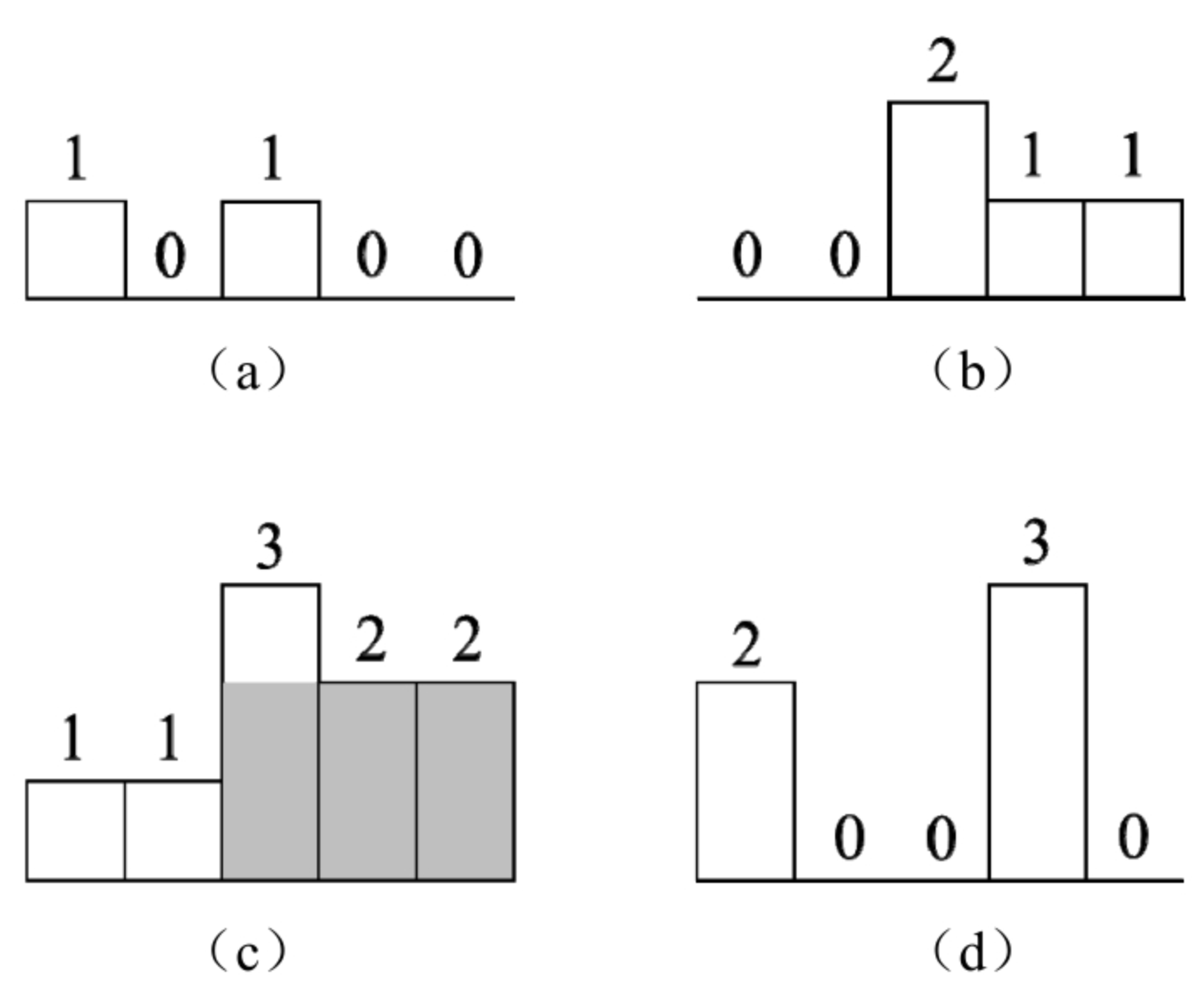
面试算法40:矩阵中的最大矩形
题目 请在一个由0、1组成的矩阵中找出最大的只包含1的矩形并输出它的面积。例如,在图6.6的矩阵中,最大的只包含1的矩阵如阴影部分所示,它的面积是6。 分析 直方图是由排列在同一基线上的相邻柱子组成的图形。由于题目要求矩形中只包含数字…...

was下log4j设置日志不输出问题
was下log4j设置日志不输出问题 WAS 也是用的 commons-logging 日志框架 commons-logging 确定 LogFactory 实现的顺序是 从应用的 META-INF/services/org.apache.commons.logging.LogFactory 中获得 LogFactory 实现从系统环境中获得 org.apache.commons.logging.LogFactory…...
小米14系列, OPPO Find N3安装谷歌服务框架,安装Play商店,Google
10月26号小米发布了新款手机小米14,那么很多大家需求问是否支持谷歌服务框架,是否支持Google Play商店gms。因为毕竟小米公司现在安装的系统是HyperOS澎湃OS。但是我拿到手机之后会发现还是开机初始界面会显示power by android,证明这一点他还是支持安装谷歌,包括最近一段时间发…...

Servlet 与Spring对比!
前言: Spring相关的框架知识,算是目前公司在用的前沿知识了,很重要!! 那么以Spring为基础的框架有几个? 以Spring为基础的框架包括若干模块,其中主要的有Spring Framework、Spring Boot、Spring…...
粤嵌实训医疗项目--day03(Vue + SpringBoot)
往期回顾 粤嵌实训医疗项目day02(Vue SpringBoot)-CSDN博客 粤嵌实训医疗项目--day01(VueSpringBoot)-CSDN博客 目录 一、SpringBoot AOP的使用 二、用户模块-注册功能(文件上传) 三、用户模块-注册实现…...

spark3.3.x处理excel数据
环境: spark3.3.x scala2.12.x 引用: spark-shell --jars spark-excel_2.12-3.3.1_0.18.5.jar 或项目里配置pom.xml <!-- https://mvnrepository.com/artifact/com.crealytics/spark-excel --> <dependency><groupId>com.crealytics</groupId><art…...

哪一个更好?Spring boot还是Node.js
前言 本篇文章有些与众不同,由于我自己手头有些关于这个主题的个人经验,受其启发写出此文。虽然SpringBoot和Node.js服务于很不一样的场景,但是这两个框架共性惊人。其实每种语言都有不计其数的框架,但仅仅一部分是真正卓越的。如…...

AD7321代码SPI接口模数转换连接DAC0832输出verilog
名称:AD7321代码12位ADC,SPI接口模数转换连接DAC0832输出 软件:QuartusII 语言:VHDL 代码功能: 使用VHDL语言编写代码,实现AD7321的控制,将模拟信号转换为数字信号,再经过处理后…...

Camoufox反检测浏览器:深度伪造Canvas/WebGL/Audio指纹
1. 这不是浏览器,而是一套“数字伪装系统”:Camoufox的本质定位很多人第一次看到“Camoufox反检测浏览器”时,下意识会把它当成一个“长得像Firefox的爬虫工具”,甚至有人直接把它和普通无头浏览器、SeleniumUser-Agent轮换方案划…...

RePKG:终极Wallpaper Engine资源提取与TEX转换完全指南
RePKG:终极Wallpaper Engine资源提取与TEX转换完全指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 你是否曾经想提取Wallpaper Engine壁纸中的精美音乐,…...

8051单片机端口操作:输入缓冲器与锁存器的区别与应用
1. C51端口输入与锁存器读取的本质区别在8051单片机开发中,端口操作有个容易被忽视但至关重要的细节:当你执行端口读写指令时,处理器实际访问的可能是两个不同的物理寄存器。以P1端口为例:输入缓冲器(Port Input&#…...

UFLUX v2.0:融合P模型与XGBoost的GPP估算混合建模框架
1. 项目概述与核心价值如果你正在从事全球变化生态学、碳循环研究或者遥感应用领域的工作,那么“如何更准确地估算陆地生态系统的总初级生产力”这个问题,大概率是你绕不开的挑战。总初级生产力,也就是我们常说的GPP,它衡量的是植…...

物联网安全新思路:轻量级机器学习算法实战评测与选型指南
1. 项目概述:当物联网遇上轻量级机器学习在物联网的世界里,安全从来不是一道选择题,而是一道生存题。想象一下,你家里的智能门锁、工厂里的传感器、街头的智能路灯,这些数以亿计的设备每时每刻都在产生和交换数据。它们…...

LiDAR增强信道估计:融合几何感知提升毫米波MIMO-OFDM系统性能
1. 项目概述与核心思路在毫米波大规模MIMO-OFDM系统中,尤其是在车联网这类高动态、低时延的应用场景里,获取精确的信道状态信息(CSI)是保障通信可靠性与高效性的基石。传统的信道估计方法,无论是基于最小二乘ÿ…...

Z变换与数字滤波器设计:从零极点分析到Python实战
1. 从理论到代码:Z变换如何成为数字信号处理的“瑞士军刀”如果你刚开始接触数字信号处理,可能会觉得Z变换是个有点抽象的数学工具。但在我十多年的音频算法和通信系统开发经历里,Z变换远不止是教科书上的公式——它是我们设计、分析和调试数…...

AI系统误差传播建模:从仿真数据生成到高效参数估计的完整方案
1. 项目概述:当AI系统出错时,误差是如何“传染”的?在自动驾驶汽车、工业机器人或者医疗影像诊断这类复杂的人工智能系统里,一个常见的架构是“流水线”式的多阶段处理。比如,一辆自动驾驶汽车先通过摄像头和激光雷达“…...

# 软考软件设计师 · 考前2天轻松复习与终极必背手册
软考软件设计师 考前2天轻松复习与终极必背手册📅 2026年5月21日 | 距考试仅剩2天 | D-2 轻松复习日 ⚠️ 今天的核心任务:翻看错题本 快速过一遍速记口诀 确认考场路线 心态放松 ❌ 不要学新内容!不要做难题!今天的任务只有一…...

量子电路生成式AI技术:原理、应用与挑战
1. 量子电路生成式AI技术概述量子计算正在经历一场由生成式人工智能技术驱动的变革。作为量子计算的基本构建块,量子电路的自动生成技术正在从理论探索快速转向实际应用。这项技术通过AI模型自动产生可执行的量子电路描述,包括Qiskit代码、OpenQASM程序和…...