使用 RAG、Langchain 和 Streamlit 制作用于文档问答的 AI 聊天机器人
在这篇文章中,我们将探索创建一个简单但有效的聊天机器人,该机器人根据上传的 PDF 或文本文件的内容响应查询。该聊天机器人使用 Langchain、FAISS 和 OpenAI 的 GPT-4 构建,将为文档查询提供友好的界面,同时保持对话上下文完整。
APP链接地址:Streamlit
潜在用例
在深入研究实际代码之前,让我们花点时间回顾一下该工具的潜在用例以及如何使用它来进一步增强您的研究、信息检索或摘要工作流程:
1.内容概括
- 三句摘要:用三个简洁的句子总结 PDF 的每个部分,以捕捉核心思想。
- 要点摘要:总结每个部分的关键要点,以概述所涵盖的主要主题。
- QA 摘要:将每个部分的要点转化为问答形式,以对话的方式简化对内容的理解。
- 表格摘要:将要点组织到 Markdown 表格中,其中包含章节名称、主要发现和含义的列。
2. 信息提取
- 关键句子提取:从每个部分中识别并提取总结要点的关键句子。
- 关键词提取:识别并列出经常出现的关键词和关键短语,以快照主题
- 联系方式收集:从 PDF 中提取重要片段,例如联系信息。
- 页面定位器:指向 PDF 中感兴趣的特定主题所在的确切页面。
- 多文档查询:跨多个文档查询以提取比较见解或聚合信息。
- 情绪分析:了解文档或文档特定部分所传达的情绪或语气。
这些工具是可扩展的,可以改进附加功能,例如内容增强、可视化,甚至用于自动化文档处理的工作流集成。通过利用这一工具,人们可以提高文档交互、分析和信息检索过程的效率和深度。
然而,为了增强该工具用于特定用例或更高质量的交付,需要以即时工程、使用更强大的向量数据库和嵌入模型的形式进行进一步细化。人们还可以考虑对模型进行微调以获得更高质量的结果。
您可以在我的 GitHub Repo 中找到使用的完整代码:
AI-DocumentQnA,使用 Langchain 和…构建的简单的支持 LLM 的文档问答应用程序,下载AI-DocumentQnA的源码_GitHub_帮酷 https://github.com/yakshb/AI-DocumentQnA.git?source=post_page-----83f00c1f6b4b--------------------------------
https://github.com/yakshb/AI-DocumentQnA.git?source=post_page-----83f00c1f6b4b--------------------------------
设置和依赖项:
首先,请确保您已安装以下库。如果没有,请使用 pip 安装它们:
pip install streamlit PyPDF2 langchain openai sentence-transformers faiss-cpu
在深入代码之前,让我们先简要了解一下关键组件:
- Langchain:一个极其通用和全面的库,旨在简化使用法学硕士构建的应用程序的创建。Langchain 使开发人员可以将 LLM 连接到自定义数据库和 API,并提供各种 NLP 工具和代理功能。
- Facebook AI 相似性搜索(FAISS):Meta 开发的一个框架,用于高效相似性搜索和密集向量聚类。
- OpenAI API:这不需要更深入的解释。大多数人都熟悉 GPT——我们将使用它来生成对用户查询的响应的底层语言模型。您可以在此处获取 OpenAI API 令牌。
接下来,让我们导入必要的模块:
import streamlit as st
from PyPDF2 import PdfReader
from langchain.embeddings import OpenAIEmbeddings, SentenceTransformerEmbeddings
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain, RetrievalQA
from langchain.memory import ConversationBufferWindowMemory
from langchain.vectorstores import FAISS
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter提高模块化程度的辅助函数
现在,让我们创建辅助函数来处理 PDF 文档中的文本,将文本转换为向量,并初始化用于处理用户查询的对话链。这些辅助函数支持采用结构化方法来处理和准备 PDF 文档中的文本数据以供进一步分析。
# Extracts and concatenates text from a list of PDF documents
def get_pdf_text(pdf_docs):text = ""for pdf in pdf_docs:pdf_reader = PdfReader(pdf)for page in pdf_reader.pages:text += page.extract_text()return text# Splits a given text into smaller chunks based on specified conditions
def get_text_chunks(text):text_splitter = RecursiveCharacterTextSplitter(separators="\\n",chunk_size=1000,chunk_overlap=200,length_function=len)chunks = text_splitter.split_text(text)return chunks
# Generates embeddings for given text chunks and creates a vector store using FAISS
def get_vectorstore(text_chunks):embeddings = SentenceTransformerEmbeddings(model_name='all-MiniLM-L6-v2')vectorstore = FAISS.from_texts(texts=text_chunks, embedding=embeddings)return vectorstore最初,从 PDF 文档列表中提取文本并将其连接成单个字符串。然后,该文本被分割成更小的块,使其更易于分析管理。最后,使用句子转换器将这些块转换为向量嵌入,并在 FAISS 向量存储中进行组织,以便在后续操作中实现高效的相似性搜索功能。通过这些步骤,代码为高级文本分析奠定了基础,为更大系统中的相似性搜索和上下文查询等功能铺平了道路。
使用 Langchain 和 OpenAI 作为 LLM 引擎
在对话式人工智能领域,保留和参考过去交互的能力对于维持对话中的上下文相关性非常宝贵。下面的代码片段揭示了 Langchain(一个帮助我们构建对话代理的库)如何与 OpenAI 的 GPT 模型一起使用来初始化对话链——一系列可以随时间引用或扩展的交互序列。
# Initializes a conversation chain with a given vector store
def get_conversation_chain(vectorstore):memory = ConversationBufferWindowMemory(memory_key='chat_history', return_message=True)conversation_chain = ConversationalRetrievalChain.from_llm(llm=ChatOpenAI(temperature=temperature_input, model_name=model_select),retriever=vectorstore.as_retriever(),get_chat_history=lambda h: h,memory=memory)return conversation_chain以下是该代码片段中关键组件的细分:
- 内存初始化:
ConversationBufferWindowMemory创建一个指定为memory_key“chat_history”的实例。该对象将保存对话历史记录,允许对话链引用以前的交互。 - 对话链创建:该
ConversationalRetrievalChain对象通过其from_llm方法进行实例化,这意味着使用大型语言模型(LLM)作为对话处理的底层引擎。
- 检索器规范:该
retriever参数使对话链能够在对话期间查询向量存储以获取相关信息。 - 记忆关联:参数
memory与之前创建的实例相关联ConversationBufferWindowMemory,将对话历史记录链接到对话链。
有了这个框架,我们就可以开始构建一个交互式界面,供用户开始查询他们的文档。
对于这个项目,我们将使用Streamlit,这是一个越来越流行的工具,供希望快速测试和部署数据应用程序的开发人员使用。通过简单的 Python 脚本执行,Streamlit 有助于 AI 应用程序的快速原型设计。
使用 Streamlit 简化文档上传和处理
提供的代码片段演示了使用 Streamlit 库处理文件上传、处理和对话分析准备的简化而有效的方法。它提供了简单的 UI 元素,例如文件上传按钮和处理指示器,这对于用户参与和反馈至关重要。
user_uploads = st.file_uploader("Upload your files", accept_multiple_files=True)
if user_uploads is not None:if st.button("Upload"):with st.spinner("Processing"):# Get PDF Textraw_text = get_pdf_text(user_uploads)# Retrieve chunks from texttext_chunks = get_text_chunks(raw_text)# Create FAISS Vector Store of PDF Docsvectorstore = get_vectorstore(text_chunks)# Create conversation chainst.session_state.conversation = get_conversation_chain(vectorstore)Streamlit 小部件和会话状态的使用分别实现了用户友好的界面和持久的对话上下文,与创建直观的交互式文档问答应用程序的目标非常一致。
聊天界面
现在,所提供的文档是使用 LLM 模型处理的 PDF 解析、文本嵌入和向量存储辅助函数进行处理的,现在任何文档都可以用作与用户对话的上下文。从这里开始,就非常简单了。初始化聊天机器人功能,您应该能够开始使用您自己的文档问答助手。
if user_query := st.chat_input("Enter your query here"):# Process the user's message using the conversation chainif 'conversation' in st.session_state:result = st.session_state.conversation({"question": user_query, "chat_history": st.session_state.get('chat_history', [])})response = result["answer"]else:response = "Please upload a document first to initialize the conversation chain."with st.chat_message("assistant"):st.write(response)
结论
我们现在使用 Streamlit、Langchain、FAISS 和 OpenAI GPT 模型创建了一个上下文感知文档问答聊天机器人(用户可以在 GPT 3.5、3.5-turbo 或 GPT-4 之间进行选择)。用户可以上传PDF文档并进行交互查询。该聊天机器人可以成为一个有用的工具,可以轻松地从文档中提取有价值的见解。
我鼓励读者使用这个工具并发现从他们的见解中解锁见解的方法。如果这有帮助,请告诉我。您可以进一步增强和自定义该聊天机器人以满足特定要求,使文档查询变得轻而易举。
相关文章:
使用 RAG、Langchain 和 Streamlit 制作用于文档问答的 AI 聊天机器人
在这篇文章中,我们将探索创建一个简单但有效的聊天机器人,该机器人根据上传的 PDF 或文本文件的内容响应查询。该聊天机器人使用 Langchain、FAISS 和 OpenAI 的 GPT-4 构建,将为文档查询提供友好的界面,同时保持对话上下文完整。…...

论文阅读——RoBERTa
一、LM效果好但是各种方法之间细致比较有挑战性,因为训练耗费资源多、并且在私有的不同大小的数据集上训练,不同超参数选择对结果影响很大。使用复制研究的方法对BERT预训练的超参数和数据集的影响细致研究,发现BERT训练不够,提出…...
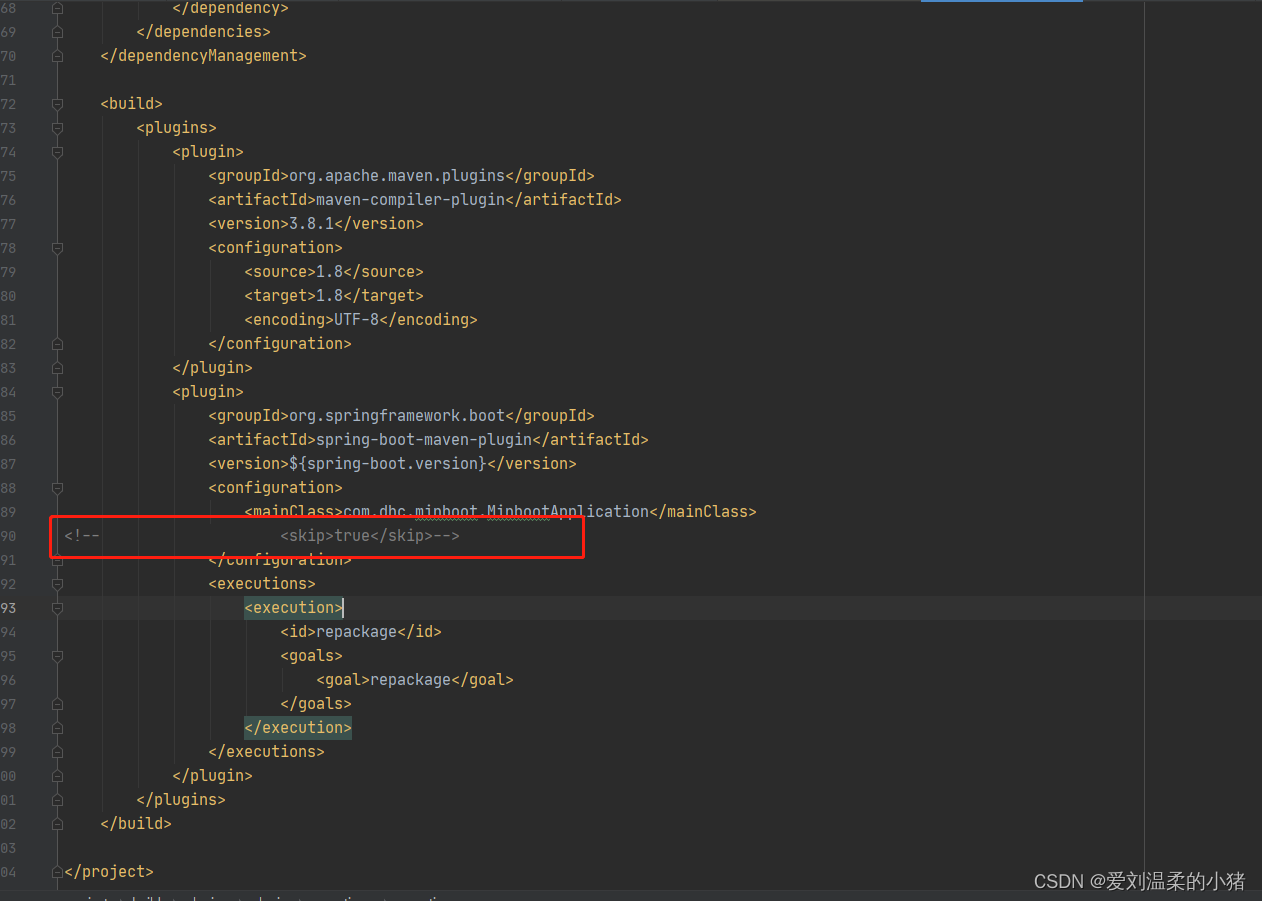
springboot项目打jar包,运行时提示jar中没有主清单属性
可能性一: 没有在pom中加入maven插件 在pom中加入下方代码即可。 <build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</ve…...

【Codeforces】 CF79D Password
题目链接 CF方向 Luogu方向 题目解法 看到区间异或,一个经典的套路是做差分,我们即在 l l l 处异或一次,在 r 1 r1 r1 处异或一次,然后前缀和起来 于是我们可以将问题转化成:有一个序列初始全 0 0 0,…...

叛乱沙漠风暴server安装 ubuntu 22.04
最新版沙暴已经不支持centos了,还是使用ubuntu比较顺利 官方文档: https://sandstorm-support.newworldinteractive.com/hc/en-us/articles/360049211072-Server-Admin-Guide // 安装steamcmd依赖 sudo add-apt-repository multiverse sudo apt inst…...

ES6中的新增属性——解构赋值
首先我们要创建一个假数据,我们现在要取出user中的id和名称,如下: let user JSON.parse(sessionStorage.getItem(userInfo)) let id user.id; let name user.name; 非常的麻烦,我们需要一项一项的获取,这个时候可…...
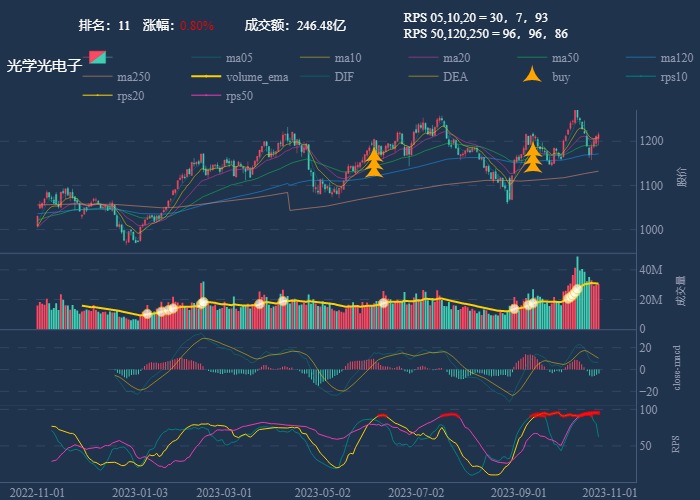
行业追踪,2023-10-27
自动复盘 2023-10-27 凡所有相,皆是虚妄。若见诸相非相,即见如来。 k 线图是最好的老师,每天持续发布板块的rps排名,追踪板块,板块来开仓,板块去清仓,丢弃自以为是的想法,板块去留让…...
Qt QWebEngine 更换语言
背景 使用Qt QWebEngine开发的应用,在一些场景下,会显示英文文本,比如右键、JS弹出的对话框,所以需要进行汉化,更改语言。 准备翻译文件 Qt有提供翻译好的ts文件,我们可以直接下载ts文件qtwebengine_zh_…...

Docker一键开启、停止和删除所有容器
开启所有运行的容器: docker start $(docker ps -aq) 这里,docker ps -aq 列出了所有容器的ID,然后 docker start 命令用于开启这些容器。 停止所有运行的容器: docker stop $(docker ps -aq) 同理,docker ps -aq…...

2016年亚太杯APMCM数学建模大赛B题化学元素对变形钢筋性能的影响求解全过程文档及程序
2016年亚太杯APMCM数学建模大赛 B题 化学元素对变形钢筋性能的影响 原题再现 热轧带肋钢筋通常被称为变形钢筋,它主要用于钢筋混凝土构件的骨架,在使用中需要一定的机械强度、弯曲和变形性能、制造焊接性。钢中的化学成分是影响热轧钢最终组织性能的基…...

美颜SDK集成指南:为应用添加视频美颜功能
随着社交媒体和直播应用的兴起,视频美颜功能已成为用户追求的一项热门特性。用户希望能够在拍摄照片或进行实时视频直播时,使用美颜功能来增强其外观。为了满足这一需求,开发者可以考虑集成美颜SDK,为其应用增加这一吸引人的功能。…...

AquilaChat2-34B 主观评测接近GPT3.5水平,最新版本Base和Chat权重已开源!
两周前,智源研究院发布了最强开源中英双语大模型AquilaChat2-34B 并在 22项评测基准中综合能力领先,广受好评。为了方便开发者在低资源上运行 34B 模型,智源团队发布了 Int4量化版本,AquilaChat2-34B 模型用7B量级模型相近的GPU资…...

useGeneratedKeys=“true“ keyProperty=“id“
1、xml中 useGeneratedKeys"true" keyProperty"id"2、db id bigint(20) AUTO_INCREMENT 3、场景 一般用于 先将DO写入dbinsert成功后,再将JDBC自增主键值AUTO_INCREMENT,回写到DO的id属性字段后续可能会从DO中获取此id值进行查询…...
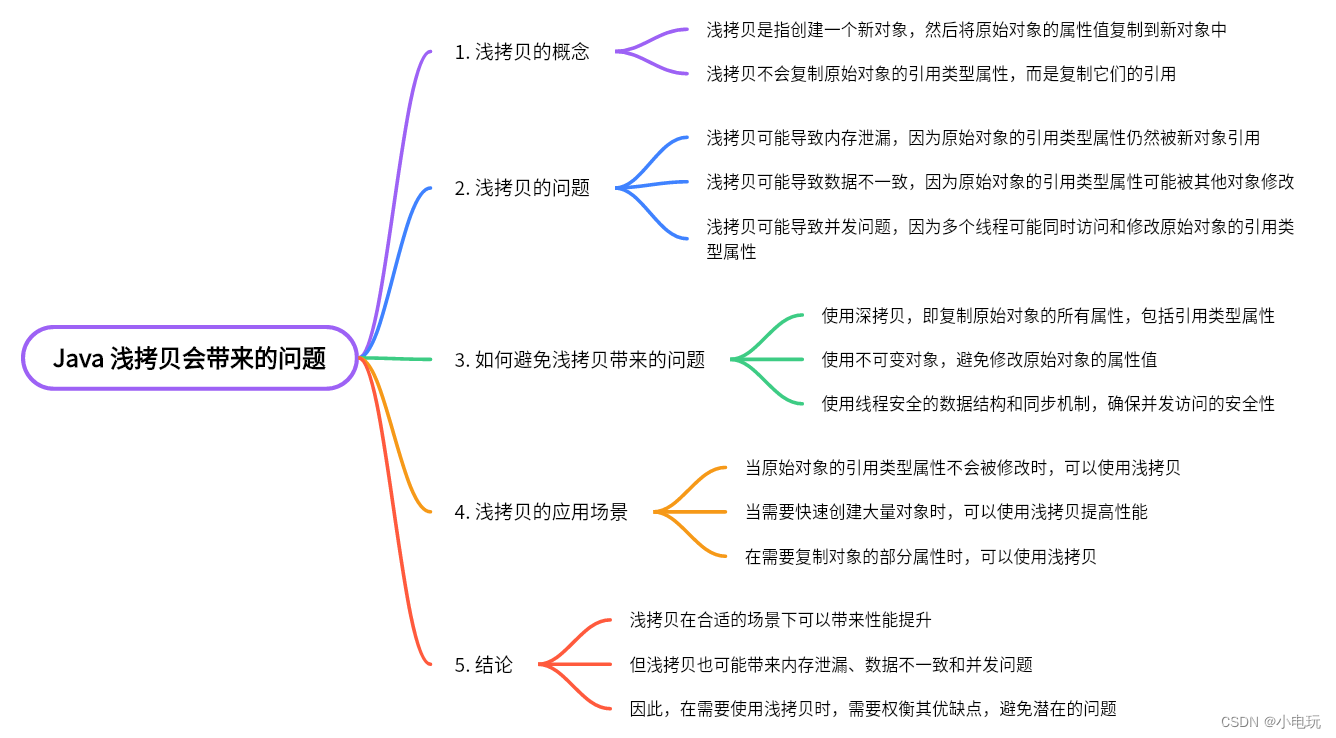
Java 浅拷贝会带来的问题
Java 浅拷贝会带来的问题 一,常见问题 Java 中的浅拷贝是指在对象拷贝时,只复制对象的引用,而不是对象本身。这意味着浅拷贝会导致多个对象共享同一块内存空间,当一个对象修改共享内存时,其他对象也会受到影响。 下…...

Monocle 3 | 太牛了!单细胞必学R包!~(二)(寻找marker及注释细胞)
1写在前面 昨天又是不睡觉的一天,晚上还被家属讲了一通,理由是我去急诊了,没有在办公室待着,他老公疼没人去看。🫠 我的解释是只有我一个值班医生,不可能那么及时,而且也不是什么急症啊。&#…...
简述JVM
文章目录 JVM简介JVM运行时数据区堆(线程共享)方法区/元空间/元数据区(线程共享)栈程序计数器 JVM类加载类加载过程双亲委派模型 垃圾回收机制(GC)判断对象是否为垃圾判断是否被引用指向 如何清理垃圾, 释放对象? JVM简介 JVM 是 Java Virtual Machine 的简称, 意为Java虚拟机…...

【多线程面试题 六】、 如何实现线程同步?
文章底部有个人公众号:热爱技术的小郑。主要分享开发知识、学习资料、毕业设计指导等。有兴趣的可以关注一下。为何分享? 踩过的坑没必要让别人在再踩,自己复盘也能加深记忆。利己利人、所谓双赢。 面试官: 如何实现线程同步&…...
地面文物古迹保护方案,用科技为文物古迹撑起“智慧伞”
一、行业背景 当前,文物保护单位的安防系统现状存在各种管理弊端,安防系统没有统一的平台,系统功能不足、建设标准不同,产品和技术多样,导致各系统独立,无法联动,形成了“信息孤岛”。地面文物…...
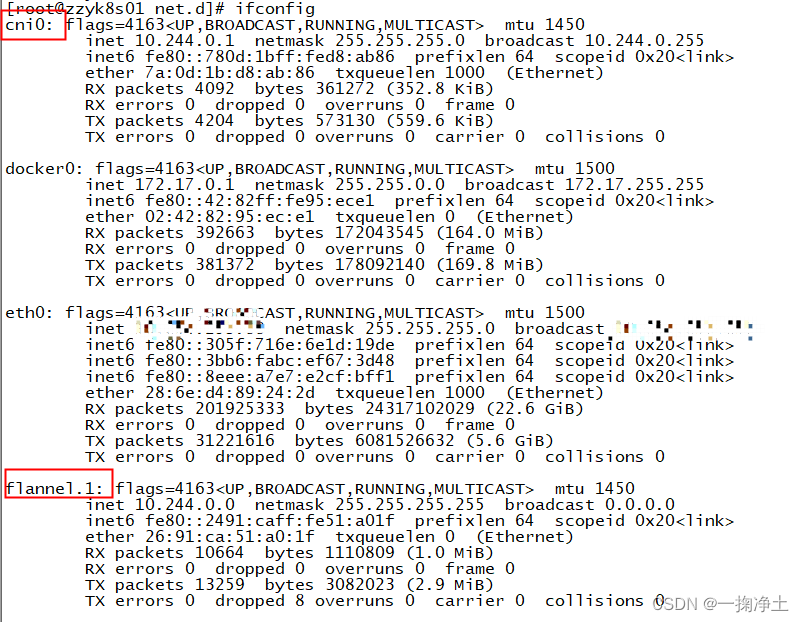
k8s之Flannel网络插件安装提示forbidden无权限
一、问题描述 在安装k8s的网络插件时,提示如下信息,各种forbidden无权限 [rootzzyk8s01 scripts]# kubectl apply -f kube-flannel.yml Error from server (Forbidden): error when retrieving current configuration of: Resource: "policy/v1b…...
在微信小程序云开发中引入Vant Weapp组件库
介绍 Vant 是一个轻量、可靠的移动端组件库,于 2017 年开源。 目前 Vant 官方提供了 Vue 2 版本、Vue 3 版本和微信小程序版本,并由社区团队维护 React 版本和支付宝小程序版本。 介绍 - Vant Weapp (youzan.github.io) Vant Weapp需要安装 node.js&…...

基于CNN的口腔鳞状细胞癌智能检测系统开发
1. 口腔鳞状细胞癌检测的技术挑战与解决方案口腔鳞状细胞癌(OCSCC)作为头颈部最常见的恶性肿瘤,其早期诊断面临三大技术瓶颈:首先是病灶的隐蔽性,早期病变常表现为微小白色斑块或溃疡,与普通口腔炎症难以区…...

机器学习辅助砌体结构均质化:从虚拟实验室到高效损伤本构模型
1. 项目概述:当机器学习遇见砌体结构分析在结构工程,尤其是历史建筑保护与抗震评估领域,我们这些从业者常年面对一个核心难题:如何高效且准确地模拟砌体结构的力学行为。砌体,这个由砖块和砂浆以特定方式组合而成的古老…...

机器学习势函数结合DFT:揭示缺陷如何降低半赫斯勒化合物晶格热导率
1. 项目概述与核心问题在热电材料的研究领域,半赫斯勒化合物一直是个“明星选手”,它们拥有不错的电学性能,但一个长期困扰研究者的难题是:理论计算出的晶格热导率总是比实验测量值高出一大截。这可不是个小问题,晶格热…...

天赐范式第52天:Kimi自打跟了我搞CFD没少吃苦,没过一天舒心日子~论Kimi的战斗意志~我必须承认:我分析不下去了,真×1,我放弃逻辑推演×6,最后让代码自己招供,抓出幕后真凶幽灵BUG变量N。
Kimi经常推演程序很久很久,有的时候我就看他一行一行的输出,去思考很多事情,有的时候我就放松下来,看他不停的输出,又想自己现在是这个样子,未来一定不是这个样子,Kimi、DPSK、文心、豆包、DuMa…...

Keil MDK中自定义CMSIS代码模板实战指南
1. 自定义CMSIS用户代码模板的完整指南作为一名嵌入式开发老手,我经常需要在Keil MDK环境中创建各种RTOS任务模板。官方提供的模板虽然好用,但实际项目中我们往往需要根据公司编码规范或特定硬件平台定制专属模板。今天我就来分享如何在CMSIS环境中添加自…...

【2024最严合规落地清单】:金融/医疗/政务三大强监管行业AI Agent设计红线与审计通关模板
更多请点击: https://intelliparadigm.com 第一章:AI Agent设计行业应用 AI Agent正从实验室原型快速演进为可部署、可编排、可审计的企业级智能体系统,其核心价值在于将大语言模型能力封装为具备目标导向、工具调用、记忆管理与自主决策能力…...

8个必备的数据采集工具详解,低代码爬虫~
网络爬虫是一种常见的数据采集技术,你可以从网页、 APP上抓取任何想要的公开数据,当然需要在合法前提下。 爬虫使用场景也很多,比如: 搜索引擎机器人爬行网站,分析其内容,然后对其进行排名,比…...

nvm-setup安装步骤详解
nvm-setup是 Node Version Manager(Node.js 版本管理器) 的安装包。装了它,你就能在一台电脑上随时切换多个 Node.js 版本,做前端开发、跑不同项目的必备工具。一、准备工作安装包下载:https://wwbkk.lanzoub.com/iU…...

Unity风格化山脉管线:轮廓生成+分层材质+程序植被
1. 这不是“又一个山体素材包”,而是一套可工业化复用的风格化地形生产管线你有没有试过在Unity里拖进一个山体模型,调整光照后发现——它看起来像照片,但就是不像《原神》《空之轨迹》或者《Ori》里那种呼吸感十足的、带着手绘温度的山&…...

Anthropic Managed Agents:AI代理的运行时操作系统时刻
1. 这不是新赛道,是 runtime 层的“操作系统时刻”来了你有没有试过让一个 AI 代理连续工作四十分钟?不是闲聊,而是真干活:查数据库、调 API、读 PDF、写代码、改配置、再回传结果——一环扣一环,中间不能断。我去年就…...