在全新ubuntu上用gpu训练paddleocr模型遇到的坑与解决办法
目录
- 一. 我的ubuntu版本
- 二.首先拉取paddleocr源代码
- 三.下载模型
- 四.训练前的准备
- 1.在源代码文件夹里创造一个自己放东西的文件
- 2.准备数据
- 2.1数据标注
- 2.2数据划分
- 3.改写yml配置文件
- 4.安装anaconda
- 五.开始训练
- 六.报错
- (1) libGL.so.1
- (2)Polygon
- (3) lanms
- (4)报错UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xbc in position 2: invalid start byt
- (5)Out of memory error on GPU 0. Cannot allocate xxxxMB memory on GPU 0, xxxxGB memory has been allocated and available memory is only 0.000000B.
一. 我的ubuntu版本
二.首先拉取paddleocr源代码
下载地址:https://gitee.com/paddlepaddle/PaddleOCR
三.下载模型
-
我要训练一个中文模型,看到该预训练模型泛化性能最优,于是下载这个模型
https://gitee.com/link?target=https%3A%2F%2Fpaddleocr.bj.bcebos.com%2FPP-OCRv3%2Fchinese%2Fch_PP-OCRv3_rec_train.tar -
其他模型地址:https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/models_list.md
四.训练前的准备
1.在源代码文件夹里创造一个自己放东西的文件
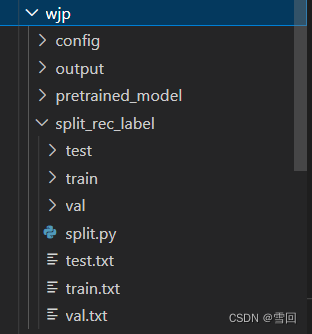
-
config文件夹用来装yml配置文件
pretrained_model用来装上一步下载的预训练模型
split_rec_label用来放数据集
output用来放训练出的模型 -
创建文件夹非强制,只是这样更方便管理自己文件,yml源文件地址就在
PaddleOCR-release-2.6/configs/rec/PP-OCRv3这个路径下
2.准备数据
2.1数据标注
参考博客:https://blog.csdn.net/qq_49627063/article/details/119134847
2.2数据划分
在训练之前,所有图片都在一个文件夹中,所有label信息都在同一个txt文件中,因此需要编写脚本,将其按照8:1:1的比例进行分割。
import os
import re
import shutil
import random
import argparsedef split_label(all_label, train_label, val_label, test_label):f = open(all_label, 'r')f_train = open(train_label, 'w')f_val = open(val_label, 'w')f_test = open(test_label, 'w')raw_list = f.readlines()num_train = int(len(raw_list) * 0.8)num_val = int(len(raw_list) * 0.1)num_test = int(len(raw_list) * 0.1)random.shuffle(raw_list)for i in range(num_train):f_train.writelines(raw_list[i])for i in range(num_train, num_train + num_val):f_val.writelines(raw_list[i])for i in range(num_train + num_val, num_train + num_val + num_test):f_test.writelines(raw_list[i])f.close()f_train.close()f_val.close()f_test.close()def split_img(all_imgs, train_label, train_imgs, val_label, val_imgs, test_label, test_imgs):f_train = open(train_label, 'r')f_val = open(val_label, 'r')f_test = open(test_label, 'r')train_list = f_train.readlines()val_list = f_val.readlines()test_list = f_test.readlines()for i in range(len(train_list)):img_path = os.path.join(all_imgs, re.split("[/\t]", train_list[i])[1])shutil.move(img_path, train_imgs)for i in range(len(val_list)):img_path = os.path.join(all_imgs, re.split("[/\t]", val_list[i])[1])shutil.move(img_path, val_imgs)for i in range(len(test_list)):img_path = os.path.join(all_imgs, re.split("[/\t]", test_list[i])[1])shutil.move(img_path, test_imgs)def get_args():parser = argparse.ArgumentParser()parser.add_argument("--all_label", default="../paddleocr/PaddleOCR/train_data/cls/cls_gt_train.txt")parser.add_argument("--all_imgs_dir", default="../paddleocr/PaddleOCR/train_data/cls/images/")parser.add_argument("--train_label", default="../paddleocr/PaddleOCR/train_data/cls/train.txt")parser.add_argument("--train_imgs_dir", default="../paddleocr/PaddleOCR/train_data/cls/train/")parser.add_argument("--val_label", default="../paddleocr/PaddleOCR/train_data/cls/val.txt")parser.add_argument("--val_imgs_dir", default="../paddleocr/PaddleOCR/train_data/cls/val/")parser.add_argument("--test_label", default="../paddleocr/PaddleOCR/train_data/cls/test.txt")parser.add_argument("--test_imgs_dir", default="../paddleocr/PaddleOCR/train_data/cls/test/")return parser.parse_args()def main(args):if not os.path.isdir(args.train_imgs_dir):os.makedirs(args.train_imgs_dir)if not os.path.isdir(args.val_imgs_dir):os.makedirs(args.val_imgs_dir)if not os.path.isdir(args.test_imgs_dir):os.makedirs(args.test_imgs_dir)split_label(args.all_label, args.train_label, args.val_label, args.test_label)split_img(args.all_imgs_dir, args.train_label, args.train_imgs_dir, args.val_label, args.val_imgs_dir, args.test_label, args.test_imgs_dir)if __name__ == "__main__":main(get_args())3.改写yml配置文件
- 源地址:https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.6/configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
Global:debug: falseuse_gpu: trueepoch_num: 800log_smooth_window: 20print_batch_step: 10save_model_dir: wjp/output/rec_ppocr_v3_distillationsave_epoch_step: 3eval_batch_step: [0, 2000]cal_metric_during_train: truepretrained_model:checkpoints:save_inference_dir:use_visualdl: falseinfer_img: doc/imgs_words/ch/word_1.jpgcharacter_dict_path: ppocr/utils/ppocr_keys_v1.txtmax_text_length: &max_text_length 25infer_mode: falseuse_space_char: truedistributed: truesave_res_path: wjp/output/rec/predicts_ppocrv3_distillation.txtOptimizer:name: Adambeta1: 0.9beta2: 0.999lr:name: Piecewisedecay_epochs : [700]values : [0.0005, 0.00005]warmup_epoch: 5regularizer:name: L2factor: 3.0e-05Architecture:model_type: &model_type "rec"name: DistillationModelalgorithm: DistillationModels:Teacher:pretrained:freeze_params: falsereturn_all_feats: truemodel_type: *model_typealgorithm: SVTRTransform:Backbone:name: MobileNetV1Enhancescale: 0.5last_conv_stride: [1, 2]last_pool_type: avgHead:name: MultiHeadhead_list:- CTCHead:Neck:name: svtrdims: 64depth: 2hidden_dims: 120use_guide: TrueHead:fc_decay: 0.00001- SARHead:enc_dim: 512max_text_length: *max_text_lengthStudent:pretrained:freeze_params: falsereturn_all_feats: truemodel_type: *model_typealgorithm: SVTRTransform:Backbone:name: MobileNetV1Enhancescale: 0.5last_conv_stride: [1, 2]last_pool_type: avgHead:name: MultiHeadhead_list:- CTCHead:Neck:name: svtrdims: 64depth: 2hidden_dims: 120use_guide: TrueHead:fc_decay: 0.00001- SARHead:enc_dim: 512max_text_length: *max_text_length
Loss:name: CombinedLossloss_config_list:- DistillationDMLLoss:weight: 1.0act: "softmax"use_log: truemodel_name_pairs:- ["Student", "Teacher"]key: head_outmulti_head: Truedis_head: ctcname: dml_ctc- DistillationDMLLoss:weight: 0.5act: "softmax"use_log: truemodel_name_pairs:- ["Student", "Teacher"]key: head_outmulti_head: Truedis_head: sarname: dml_sar- DistillationDistanceLoss:weight: 1.0mode: "l2"model_name_pairs:- ["Student", "Teacher"]key: backbone_out- DistillationCTCLoss:weight: 1.0model_name_list: ["Student", "Teacher"]key: head_outmulti_head: True- DistillationSARLoss:weight: 1.0model_name_list: ["Student", "Teacher"]key: head_outmulti_head: TruePostProcess:name: DistillationCTCLabelDecodemodel_name: ["Student", "Teacher"]key: head_outmulti_head: TrueMetric:name: DistillationMetricbase_metric_name: RecMetricmain_indicator: acckey: "Student"ignore_space: FalseTrain:dataset:name: SimpleDataSetdata_dir: wjp/split_rec_label/trainext_op_transform_idx: 1label_file_list:- wjp/split_rec_label/train.txttransforms:- DecodeImage:img_mode: BGRchannel_first: false- RecConAug:prob: 0.5ext_data_num: 2image_shape: [48, 320, 3]max_text_length: *max_text_length- RecAug:- MultiLabelEncode:- RecResizeImg:image_shape: [3, 48, 320]- KeepKeys:keep_keys:- image- label_ctc- label_sar- length- valid_ratioloader:shuffle: truebatch_size_per_card: 32drop_last: truenum_workers: 4
Eval:dataset:name: SimpleDataSetdata_dir: wjp/split_rec_label/vallabel_file_list:- wjp/split_rec_label/val.txttransforms:- DecodeImage:img_mode: BGRchannel_first: false- MultiLabelEncode:- RecResizeImg:image_shape: [3, 48, 320]- KeepKeys:keep_keys:- image- label_ctc- label_sar- length- valid_ratioloader:shuffle: falsedrop_last: falsebatch_size_per_card: 128num_workers: 44.安装anaconda
参考博客:https://blog.csdn.net/wyf2017/article/details/118676765
- 创建python虚拟环境
conda create -n ppocr
- 切换虚拟环境
source activate ppocr
五.开始训练
python tools/train.py -c wjp/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model=wjp/ch_PP-OCRv3_rec_train/best_accuracy
//-c参数放配置文件地址,-o参数放预训练模型地址pip install -i https://pypi.tuna.tsinghua.edu.cn/simple
六.报错
(1) libGL.so.1
ImportError: libGL.so.1: cannot open shared object file: No such file or directory
- 解决办法:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-python-headless
(2)Polygon
ModuleNotFoundError: No module named 'Polygon'
- 解决办法:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple Polygon3
(3) lanms
ModuleNotFoundError: No module named 'lanms'
源码下载地址:https://github.com/AndranikSargsyan/lanms-nova/tree/master
参考我这个教程编译:http://t.csdnimg.cn/BqOW6
- 将__init __.py文件替换
import numpy as npdef merge_quadrangle_n9(polys, thres=0.3, precision=10000):if len(polys) == 0:return np.array([], dtype='float32')p = polys.copy()p[:, :8] *= precisionret = np.array(merge_quadrangle_n9(p, thres), dtype='float32')ret[:, :8] /= precisionreturn ret- 找到linux种anaconda的包放在什么地方
pip show numpy
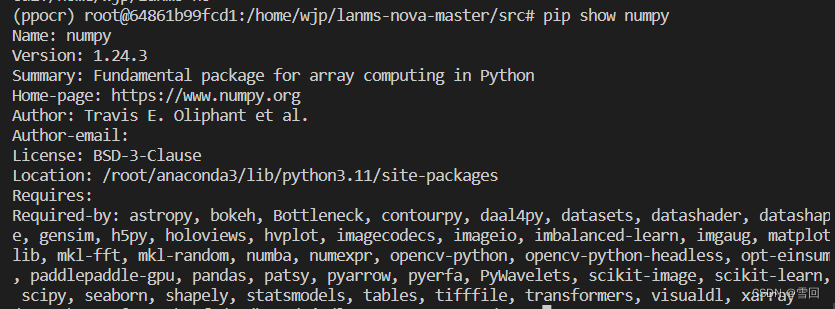
就知道该环境下的包安装地址
- 将编译好库的整个lanms文件夹移动到该地址去即可调用
(4)报错UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xbc in position 2: invalid start byt
f = open('txt01.txt',encoding='utf-8')
将 encoding=’utf-8’ 改为GB2312、gbk、ISO-8859-1,随便尝试一个均可以
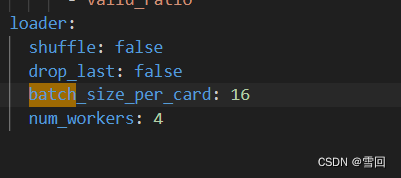
(5)Out of memory error on GPU 0. Cannot allocate xxxxMB memory on GPU 0, xxxxGB memory has been allocated and available memory is only 0.000000B.
将训练的配置yml文件中的batch_size_per_card参数不断改小(除以2),直到不再报这个错即可。
相关文章:
在全新ubuntu上用gpu训练paddleocr模型遇到的坑与解决办法
目录 一. 我的ubuntu版本二.首先拉取paddleocr源代码三.下载模型四.训练前的准备1.在源代码文件夹里创造一个自己放东西的文件2.准备数据2.1数据标注2.2数据划分 3.改写yml配置文件4.…...

React之服务端渲染
一、是什么 在SSR中 (opens new window),我们了解到Server-Side Rendering ,简称SSR,意为服务端渲染 指由服务侧完成页面的 HTML 结构拼接的页面处理技术,发送到浏览器,然后为其绑定状态与事件,成为完全可…...
jetson nano刷机更新Jetpack
只是记录个人在使用英伟达jetson Nano的经历,由于头一次尝试,所以特此记录需要的问题和经验。 一,英伟达刷机教程(jetson nano 版本) 本次我是直接刷机到TF卡,然后TF卡作为启动盘进行启动,我看网上有带EMMC版本的,好像可以直接把系统镜像安装到EMMC里面。但是有个问题…...
Android官方ShapeableImageView描边/圆形/圆角图,xml布局实现
Android官方ShapeableImageView描边/圆形/圆角图,xml布局实现 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas.android.com/apk/res/android"xmlns:app"http://schemas.android.…...

ubuntu扩大运行内存, 防止编译卡死
首先查看交换分区大小 grep SwapTotal /proc/meminfo 1、关闭交换空间 sudo swapoff -a 2、扩充交换空间大小,count64就是64G 1G x 64 sudo dd if/dev/zero of/swapfile bs1G count64 3、设置权限 sudo chmod 600 /swapfile 4、指定交换空间对应的设备文件 …...
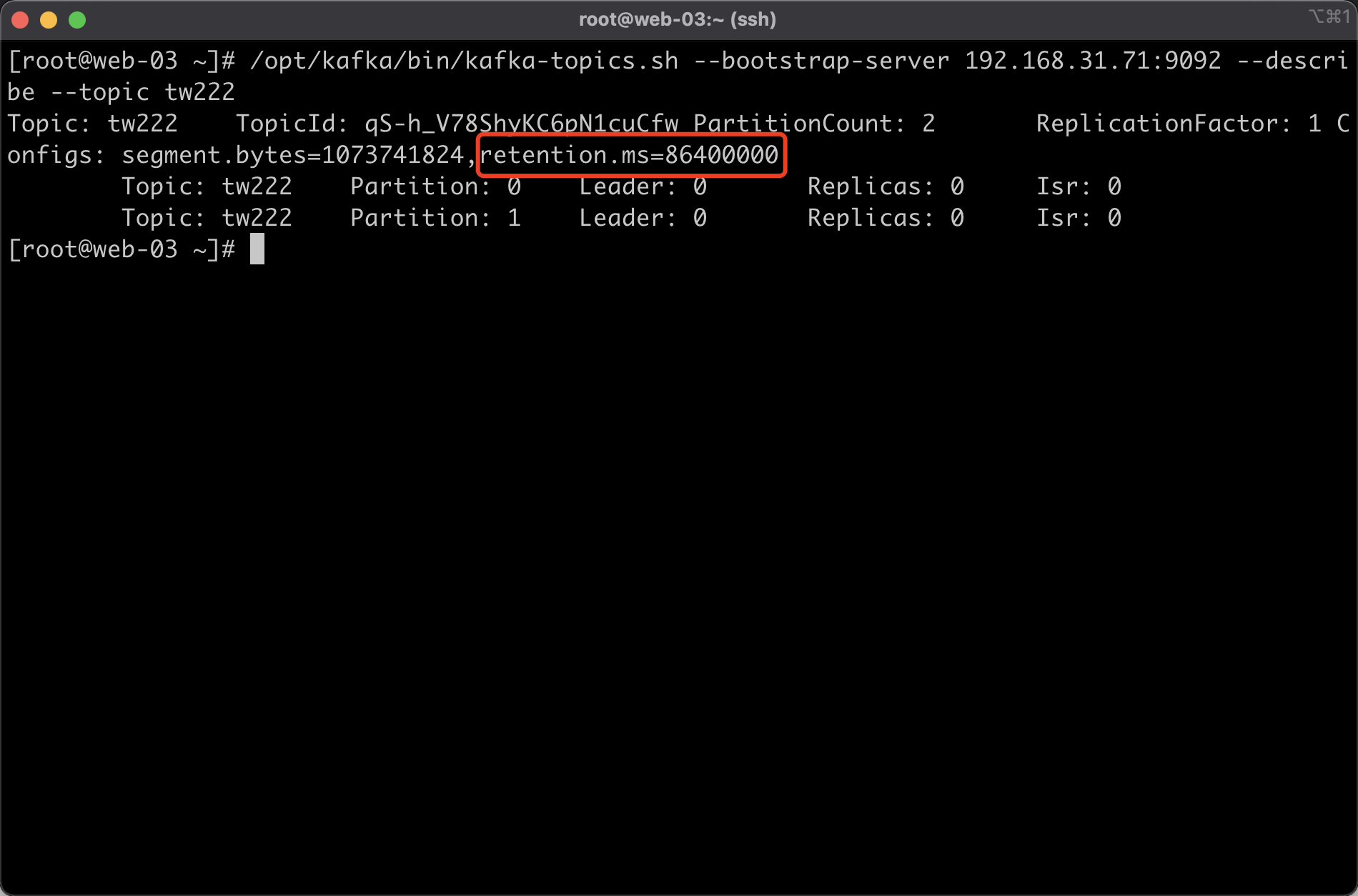
Kafka集群修改单个Topic数据保存周期
在大数据部门经常使用Kafka集群,有的时候大数据部门可能在Kafka中的Topic数据保存时间不需要很长,一旦被消费后就不需要一直保留。默认Topic存储时间为7day,个别的Topic或者某台Kafka集群需要修改Topic数据保存的一个周期,调整为3…...

selenium模拟登录无反应
在使用自动化工具selenium时对某些网站登录界面send_keys输入账号密码,运行时却没有自己想要的结果出现,这是因为你碰到前端二般的开发人员,他们用的是HTML嵌套,这对后端人员造成了一些麻烦,废话不多说,直接…...

指针变量未分配空间或者初始化为空指针使用问题
提示:关于指针 文章目录 前言一、指针的使用总结 前言 在看c书籍的时候,看到浅复制和深复制时,说到成员为指针的时候,会出异常。但是其实没有更多的感想,但是联想到上次考试指针没分配空间导致程序异常的情况…...

力扣第763题 划分字母区间 c++ 哈希 + 双指针 + 小小贪心
题目 763. 划分字母区间 中等 相关标签 贪心 哈希表 双指针 字符串 给你一个字符串 s 。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。 注意,划分结果需要满足:将所有划分结果按顺序连接,得…...

js 代码中的 “use strict“; 是什么意思 ?
use strict 是一种 ECMAscript5 添加的(严格)运行模式,这种模式使得 Javascript 在更严格的条件下运行。 设立"严格模式"的目的,主要有以下几个: 消除 Javascript 语法的一些不合理、不严谨之处,…...

用于读取验证码的 OCR 模型
介绍 此示例演示了使用功能 API 构建的简单 OCR 模型。除了结合 CNN 和 RNN 之外,它还说明了如何实例化新层并将其用作“端点层”来实现 CTC 损失。 设置 import os import numpy as np import matplotlib.pyplot as pltfrom pathlib import Path from collections import Co…...

Uniapp 跳转回上一页面并刷新页面数据
比如我从A页面跳转到B页面 然后再从B页面返回到A页面 顺带刷新一下A页面数据 let pages getCurrentPages(); // 当前页面 //获取当前页面栈let beforePage pages[pages.length - 3]; // //获取上一个页面实例对象beforePage.$vm.reloadList(); //调用它方法然后跳转…...
DeOldify 接口化改造 集成 Flask
类似的图片修复项目 GFPGAN 的改造见我另一篇文 https://blog.csdn.net/weixin_43074462/article/details/132497146 DeOldify 是一款开源软件,用于给黑白照片或视频上色,效果还不错。 安装部署教程请参考别的文章,本文基于你给项目跑通&…...

Vue 3响应式对象: ref和reactive
目录 什么是响应式对象? Ref Reactive Ref vs Reactive 适用场景: 访问方式: 引用传递: 性能开销: 响应式对象优点 响应式对象缺点 总结 Vue 3作为一种流行的JavaScript框架,提供了响应式编程的…...

Unity3D 如何用unity引擎然后用c#语言搭建自己的服务器
Unity3D是一款强大的游戏开发引擎,可以用于创建各种类型的游戏。在游戏开发过程中,经常需要与服务器进行通信来实现一些功能,比如保存和加载游戏数据、实现多人游戏等。本文将介绍如何使用Unity引擎和C#语言搭建自己的服务器,并给…...

带有 Vagrant 和 Virtualbox 的 Elasticsearch 集群
模拟分布式存储和计算环境的一种简单方法是使用 Virtualbox 作为 VM(“虚拟机”)的提供者,使用 Vagrant 作为前端脚本引擎来配置、启动和停止这些 VM。这篇文章的目标是构建一个集群虚拟设备,提供 Elasticsearch 作为可由主机使用…...

Cross Site Scripting (XSS)
攻击者会给网站发送可疑的脚本,可以获取浏览器保存的网站cookie, session tokens, 或者其他敏感的信息,甚至可以重写HTML页面的内容。 背景 XSS漏洞有不同类型,最开始发现的是存储型XSS和反射型XSS,2005,Am…...
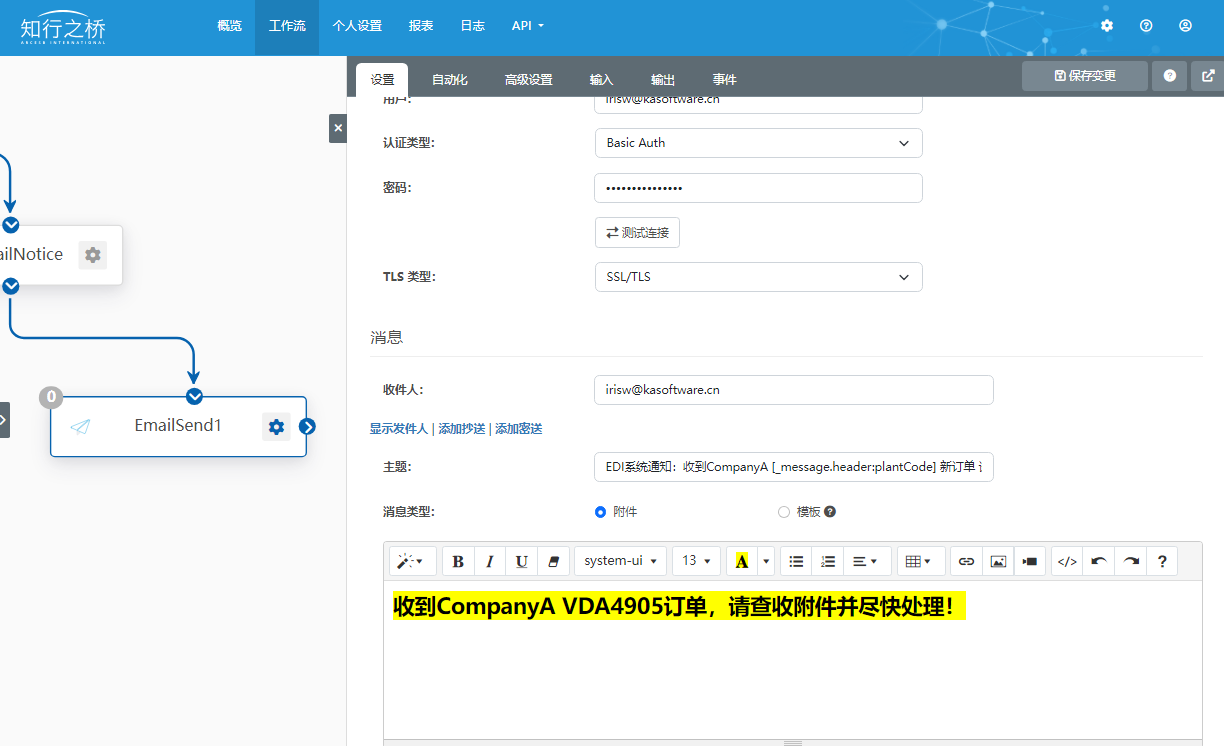
VDA到Excel方案介绍之自定义邮件接收主题
VDA标准是德国汽车工业协会(Verband der Automobilindustrie,简称VDA)制定的一系列汽车行业标准。这些标准包括了汽车生产、质量管理、供应链管理、环境保护、安全性能等方面的规范和指南。VDA标准通常被德国和国际上的汽车制造商采用&#x…...

【opencv】【CPU】windows10下opencv4.8.0-cuda C++版本源码编译教程
【opencv】【CPU】windows10下opencv4.8.0-cuda C版本源码编译教程 提示:博主取舍了很多大佬的博文并亲测有效,分享笔记邀大家共同学习讨论 文章目录 【opencv】【CPU】windows10下opencv4.8.0-cuda C版本源码编译教程前言准备工具cmakeopencv4.8.0opencv_contrib CMake编译VS2…...

多分类loss学习记录
这里简单的记录在人脸识别/声纹识别中常用的分类loss。详细原理可以参考其他博客。 扩展资料1 扩展资料2 L-softmax A-softmax AM-softmax L-softmax :基于softmax加入了margin, Wx 改写为||w||||x||cos(角度),将角度变为了m角度 A-softmax &…...

谁还在用机械音?顶伯接入微软 TTS,让你视频瞬间拥有大片质感!
谁还在用机械音?顶伯接入微软 TTS,让你视频瞬间拥有大片质感!视频配音还在用那种一听就出戏的机械音吗?🚫 顶伯正式接入微软 TTS 引擎,带来媲美真人的语音合成体验。无论你是短视频创作者、课程讲师&#x…...

终极音乐整合方案:用MusicFree插件打造你的专属音乐中心
终极音乐整合方案:用MusicFree插件打造你的专属音乐中心 【免费下载链接】MusicFreePlugins MusicFree播放插件 项目地址: https://gitcode.com/gh_mirrors/mu/MusicFreePlugins 还在为音乐平台会员费烦恼吗?还在忍受不同平台间的歌曲版权割裂吗&…...

别再只盯着人脸了!手把手教你用Python复现2023年最新的多模态情绪识别模型COGMEN
别再只盯着人脸了!手把手教你用Python复现2023年最新的多模态情绪识别模型COGMEN 情绪识别技术正在经历从单一模态到多模态融合的范式转变。传统基于面部表情的分析方法往往受限于光照条件、遮挡问题以及文化差异带来的表达偏差。2023年发布的COGMEN模型通过引入图…...
)
别再只记cat和空格了:一份给CTF新手的Linux命令执行绕过速查表(含通配符、编码、拼接)
CTF命令执行绕过实战手册:从基础技巧到高阶组合技 在CTF竞赛和安全测试中,命令执行漏洞是最常见的攻击面之一。许多新手面对各种过滤规则时,往往陷入"知道有绕过方法但记不住具体用法"的困境。本文将系统梳理Linux命令执行绕过的完…...

速学linux命令教程
概述:用户使用shell跟内核交互,Linux中有很多命令,不同的命令有不同的功能。多个命令合起来可以完成一个大的功能。命令很多我们不可能记得每条命令的用法。 所以,我们必须有一种方法来快速知道一个命令是如何使用的,…...

FTP明文传输风险与Wireshark抓包实证分析
1. 这不是危言耸听:FTP 的“裸奔”现状每天都在发生你有没有在公司内网用过 FTP 上传一份财务报表?有没有在校园网里用 FileZilla 向老师提交课程设计源码?有没有在运维后台用 ftp 命令同步过网站静态资源?如果答案是肯定的&#…...

零基础30天掌握渗透测试实战路径
1. 别被“渗透测试”四个字吓住:它本质是“合法授权的系统体检”很多人第一次看到“渗透测试”这个词,脑子里立刻浮现出黑客电影里飞速滚动的代码、黑底绿字的终端、戴着兜帽在咖啡馆敲键盘的神秘人——这种刻板印象害了不少想入门的朋友。我带过三十多个…...

生产级机器学习服务:容器化API与可观测性实战指南
1. 项目概述:当模型走出Jupyter,真正开始呼吸真实世界空气“From Notebook to Production: Running ML in the Real World (Part 4)”——这个标题里藏着一个被无数数据科学家反复咀嚼、又悄悄咽下的苦涩真相:我们花了80%的时间调参、画图、在…...

告别抢票焦虑:大麦网双端自动抢票系统深度解析与实战指南
告别抢票焦虑:大麦网双端自动抢票系统深度解析与实战指南 【免费下载链接】ticket-purchase 大麦自动抢票,支持人员、城市、日期场次、价格选择 项目地址: https://gitcode.com/GitHub_Trending/ti/ticket-purchase 你是否曾在心仪演出的开票瞬间…...

3个步骤掌握OBS多平台推流插件:告别重复操作,实现一键多平台直播同步
3个步骤掌握OBS多平台推流插件:告别重复操作,实现一键多平台直播同步 【免费下载链接】obs-multi-rtmp OBS複数サイト同時配信プラグイン 项目地址: https://gitcode.com/gh_mirrors/ob/obs-multi-rtmp OBS多平台推流插件(obs-multi-r…...