Crawler4j实例爬取爱奇艺热播剧案例
前言
热播剧数据在戏剧娱乐产业中扮演着着名的角色。热了解播剧的观众喜好和趋势,对于制作方和广告商来说都具有重要的参考价值。然而,手动收集和整理这些数据是在本文中,我们将介绍如何利用 Python 爬虫技术和 Crawler4j 实例来自动化爬取爱奇艺热播剧的相关信息。
Crawler4j技术概述
Crawler4j是一个基于Java的开源网络爬虫框架,它提供了一套简单的手工的API,用于构建高效的网络爬虫。虽然它是用Java编写的,但我们可以通过Python的Jython库来使用它。Crawler4j具有高度的可配置性和可扩展性,可以满足各种爬虫需求。
项目需求
我们的需求是爬取爱奇艺热播剧的相关信息,包括热烈的名称、演员阵容、评分等。我们希望能够自动化获取这些数据,并保存到本地或数据库中,以便后续处理分析和使用。
爬取思路分析
在找到开始编写爬虫代码之前,我们需要先分析爬取的思路。首先,我们需要确定爬取的目标网站,这里是爱奇艺。然后,需要包含热播剧信息的页面,并分析页面的结构和元素。最后,我们需要编写代码来模拟浏览器的行为,从页面中提取所需的信息。
构建爬虫框架
在构建爬虫框架之前,我们需要先安装Crawler4j库。可以通过pip命令来安装:pip installcrawler4j。
接下来,我们需要创建一个WebCrawler类,用于处理具体的页面抓取逻辑。在这个类中,我们可以重写shouldVisit方法来判断是否应该访问某个URL,以及重写visit方法来处理访问到的页面。
from crawler4j.crawler import WebCrawler
from crawler4j.parser import HtmlParseData
from crawler4j.url import WebURLclass IQiyiCrawler(WebCrawler):def shouldVisit(self, referringPage, url):# 判断是否应该访问该URLreturn url.startswith("http://www.iqiyi.com/hot")def visit(self, page):if page.getParseData() and isinstance(page.getParseData(), HtmlParseData):# 提取页面中的信息# ...# 保存信息到本地或数据库# ...下来我们创建了一个IQiyiCrawler类,继承自WebCrawler类,并重写了shouldVisit和visit方法。shouldVisit方法用于判断是否应该访问某个URL,visit方法用于处理访问到的页面。
from crawler4j.crawler import WebCrawler
from crawler4j.parser import HtmlParseData
from crawler4j.url import WebURLclass IQiyiCrawler(WebCrawler):def shouldVisit(self, referringPage, url):return url.startswith("http://www.iqiyi.com/hot")def visit(self, page):if page.getParseData() and isinstance(page.getParseData(), HtmlParseData):# 提取页面中的信息# ...# 保存信息到本地或数据库# ...# 创建CrawlController类
from crawler4j.crawler import CrawlControllerclass IQiyiCrawlController:def __init__(self):self.crawlController = CrawlController()def start(self):# 设置爬虫的配置config = self.crawlController.getConfig()config.setCrawlStorageFolder("path/to/crawl/storage/folder")config.setMaxDepthOfCrawling(5)config.setPolitenessDelay(1000)# 添加种子URLself.crawlController.addSeed("http://www.iqiyi.com/hot")# 设置代理信息config.setProxyHost("www.16yun.cn")config.setProxyPort("5445")config.setProxyUser("16QMSOML")config.setProxyPass("280651")# 启动爬虫self.crawlController.start(IQiyiCrawler, 1)# 等待爬取完成self.crawlController.waitUntilFinish()# 创建爬虫控制器实例并启动爬虫
crawler = IQiyiCrawlController()
crawler.start()相关文章:

Crawler4j实例爬取爱奇艺热播剧案例
前言 热播剧数据在戏剧娱乐产业中扮演着着名的角色。热了解播剧的观众喜好和趋势,对于制作方和广告商来说都具有重要的参考价值。然而,手动收集和整理这些数据是在本文中,我们将介绍如何利用 Python 爬虫技术和 Crawler4j 实例来自动化爬取爱…...

uniapp项目APP端安卓ios权限检测教程
导语:在 APP 的日常开发过程中,权限检测与授权是不可避免的一项重要的功能,下面就简单介绍一下如何检测和授权的方法。 目录 原理方法实战原理 此授权方法主要是依托于 HTML5 产业联盟的HTML5+规范实现的。 HTML5 产业联盟官网 获取当前操作系统名称 可以使用uni.getSys…...
通信)
java多进程间(父进程与子进程)通信
一般我们在java中运行其它类中的方法时,无论是静态调用,还是动态调用,都是在当前的进程中执行的,也就是说,只有一个java虚拟机实例在运行。而有的时候,我们需要通过java代码启动多个java子进程。这样做虽然…...
【从0到1设计一个网关】整合Nacos-服务注册与服务订阅的实现
文章目录 Nacos定义服务注册与订阅方法服务信息加载与配置实现将网关注册到注册中心实现服务的订阅 Nacos Nacos提供了许多强大的功能: 比如服务发现、健康检测。 Nacos支持基于DNS和基于RPC的服务发现。 同时Nacos提供对服务的实时的健康检查,阻止向不…...
【uniapp】短信验证码输入框
需求是短信验证码需要格子输入框 如图 网上找了一个案例改吧改吧 直接上代码 结构 <template><view class"verify-code"><!-- 输入框 --><input id"input" :value"code" class"input" :focus"isFocus"…...
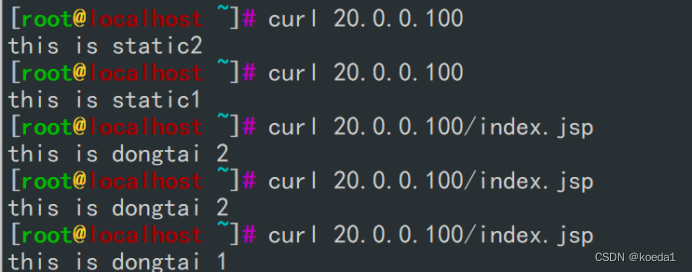
负载均衡的综合部署练习(hproxy+keepalived和lvs-DR+keepalived+nginx+Tomcat)
一、haproxykeepalived haproxy 2台 20.0.0.21 20.0.0.22 nginx 2台 20.0.0.23 20.0.0.24 客户机 1台 20.0.0.30 这里没有haproxy不是集群的概念,他只是代理服务器。 访问他直接可以直接访问后端服务器 关闭防火墙 安装haproxy和环境: yum in…...
+ Spring相关源码)
设计模式——策略模式(Strategy Pattern)+ Spring相关源码
文章目录 一、策略模式定义二、例子1. 菜鸟教程例子(略有改动)1.1 、定义。1.2、定义加法策略类1.3、定义乘法策略类1.4、创建 Context 类1.5、使用 2、JDK awt包——BufferStrategy3、Spring源码 —— InstantiatorStrategy4、Spring源码 —— Instanti…...

ORB-SLAM3算法2之开源数据集运行ORB-SLAM3生成轨迹并用evo工具评估轨迹
文章目录 0 引言1 数据和真值1.1 TUM1.2 EuRoc1.3 KITTI2 ORB-SLAM3的EuRoc示例3 ORB-SLAM3的TUM-VI示例4 ORB-SLAM3的ROS各版本示例4.1 单目4.2 单目和IMU4.3 双目4.4 双目和IMU4.5 RGB-D0 引言 ORB-SLAM3算法1 已成功编译安装ORB-SLAM3到本地,本篇目的是用TUM、EuRoc和KITT…...

Qt 序列化函数和反序列化函数
文章目录 界面学生类序列化函数反序列化函数刷新所选择的下拉表值添加 界面 学生类 // 创建学生信息类 class studentInfo { public:QString id; // 学号QString name; // 学生姓名QString age; // 学生年龄// 重写QDataStream& operator<<操作符&…...
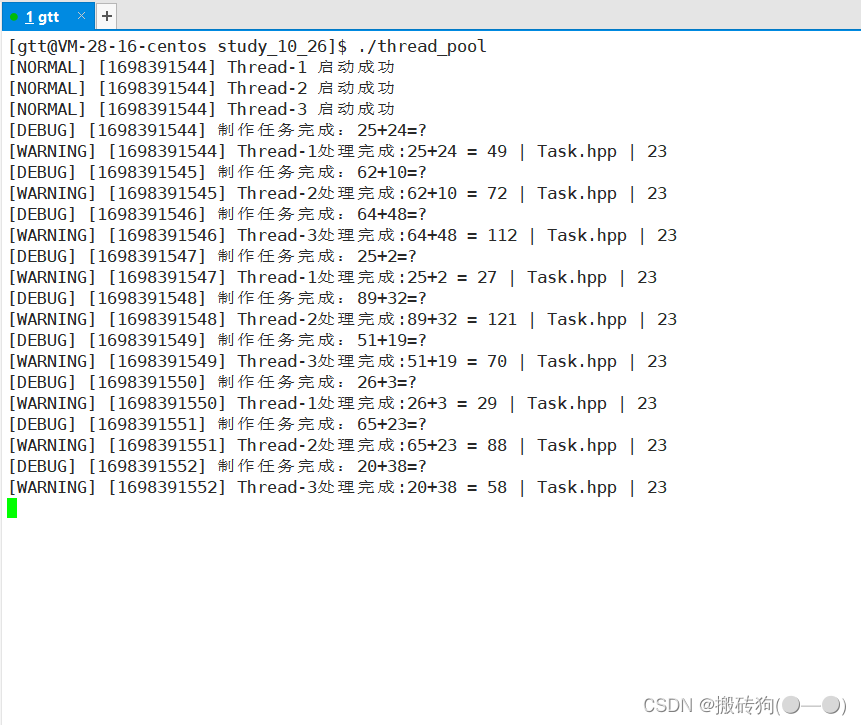
Linux之线程池
线程池 线程池概念线程池的应用场景线程池实现原理单例模式下线程池实现STL、智能指针和线程安全其他常见的各种锁 线程池概念 线程池:一种线程使用模式。 线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待…...
MAC安装stable diffusion
./webui.sh --precision full --no-half-vae --disable-nan-check --api Command: "/Users/xxxx/aigc/stable-diffusion-webui/venv/bin/python3" -m pip install torch2.0.1 torchvision0.15.2 Error code: 2 执行命令: pip install torch2.0.1 torchvi…...
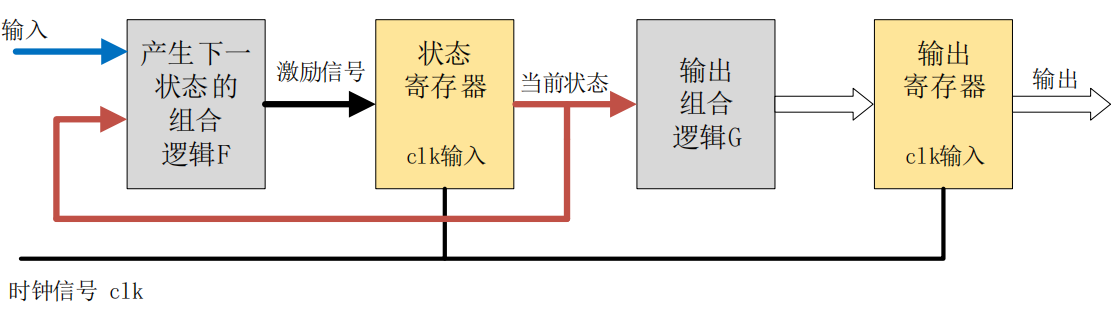
FPGA_状态机工作原理
FPGA_状态机介绍和工作原理 状态机工作原理Mealy 状态机模型Moore 状态机模型状态机描述方式代码格式 总结 状态机工作原理 状态机全称是有限状态机(Finite State Machine、FSM),是表示有限个状态以及在这些状态之间的转移和动作等行为的数学…...
【python练习】python斐波那契数列超时问题
计算斐波那契数列第n项的数字 Description计算斐波那契数列第n项的数字,其中f(1)f(2)1,f(n)f(n-1)f(n-2),如1,1,2,3,5,......Input 正整数n(n<100)Output 一个整数f(n)Sample Input 1 8 Sample Output 1…...

SpringCloud 微服务全栈体系(五)
第七章 Feign 远程调用 先来看我们以前利用 RestTemplate 发起远程调用的代码: 存在下面的问题: 代码可读性差,编程体验不统一 参数复杂 URL 难以维护 Feign 是一个声明式的 http 客户端,官方地址:https://github.…...

msvcp140.dll丢失的正确解决方法
在使用电脑中我们经常会遇到一些错误提示,其中之一就是“msvcp140.dll丢失”。这个错误通常会导致某些应用程序无法正常运行。为了解决这个问题,我们需要采取一些措施来修复丢失的msvcp140.dll文件。本文将介绍6个不同的解决方法,帮助读者解决…...

go pprof 如何使用 --chatGPT
gpt: pprof 是 Go 语言的性能分析工具,它可以用来检测 CPU 使用情况、内存使用情况、以及阻塞情况。你可以使用 pprof 来帮助诊断程序的性能问题,包括内存泄漏。 以下是如何使用 pprof 来分析内存泄漏的基本步骤: 1. **导入 pprof 包**&am…...
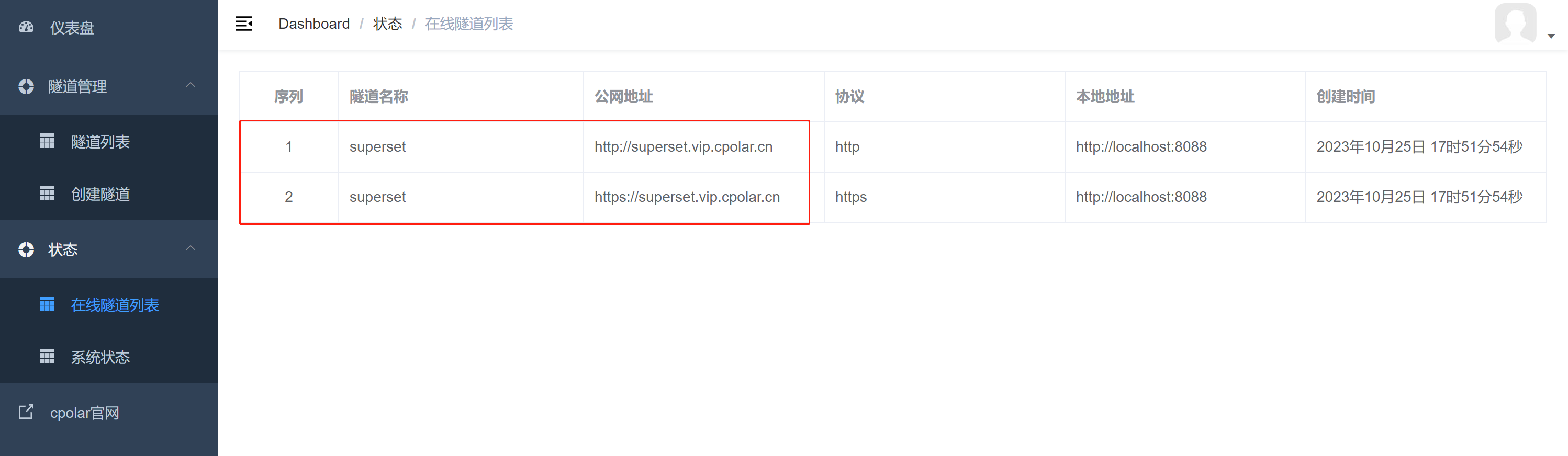
大数据可视化BI分析工具Apache Superset实现公网远程访问
大数据可视化BI分析工具Apache Superset实现公网远程访问 文章目录 大数据可视化BI分析工具Apache Superset实现公网远程访问前言1. 使用Docker部署Apache Superset1.1 第一步安装docker 、docker compose1.2 克隆superset代码到本地并使用docker compose启动 2. 安装cpolar内网…...

软考系统架构师知识点集锦二:软件工程
一、考情分析 二、考点精讲 2.1 软件过程模型 (1)原型模型 典型的原型开发方法模型。适用于需求不明确的场景,可以帮助用户明确需求。可以分为[抛弃型原型]与[演化型原型] 原型模型两个阶段: 1、原型开发阶段;2、目标软件开发阶段。 &#x…...

Go并发:使用sync.Pool来性能优化
简介 在Go提供如何实现对象的缓存池功能?常用一种实现方式是:sync.Pool, 其旨在缓存已分配但未使用的项目以供以后重用,从而减轻垃圾收集器(GC)的压力。 快速使用 sync.Pool的结构也比较简单,常用的方法…...
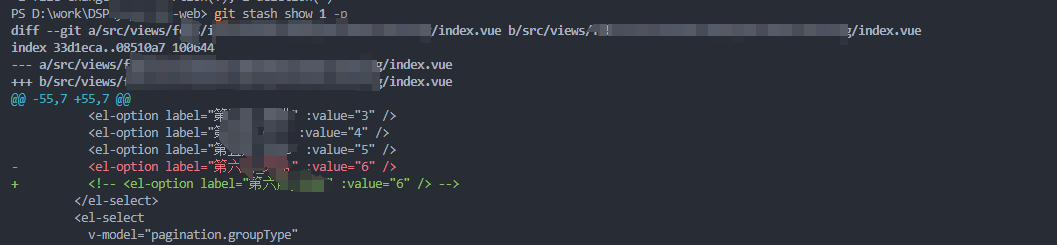
git stash的使用方法
git stash的使用方法 应用场景 当我们在开发一个新功能的时候,或者开发到一半,然后就收到了线上master 出现了bug,当分支开发已经进行了或者进行到一半了,这时怎么办呢? 这时解决方案有两种:一种是先先将当…...

Maven依赖scope:从编译到打包,一张图理清生命周期与classpath
Maven依赖scope全解析:构建生命周期与classpath的精准控制 当你盯着pom.xml里那些<scope>compile</scope>标签时,是否曾好奇它们究竟如何影响你的构建流程?Maven的依赖scope就像一个个精密的开关,控制着依赖项在编译、…...
)
ChatGPT生成的SQL注入漏洞代码竟通过了87%静态扫描器?安全团队紧急避坑指南(含检测脚本)
更多请点击: https://codechina.net 第一章:ChatGPT生成的SQL注入漏洞代码竟通过了87%静态扫描器?安全团队紧急避坑指南(含检测脚本) 近期,某金融企业安全团队在代码审计中发现,一段由ChatGPT生…...

2026 年招聘效率升级:高匹配候选人推荐的 AI 实践路径
招聘的核心目标是快速找到适配岗位的人才,而简历筛选与候选人推荐是决定招聘效率的关键环节。传统招聘模式下,HR 需手动比对简历与岗位要求,不仅耗时久,还易因主观判断遗漏高匹配候选人。随着 AI 技术在人力资源领域的深度应用&am…...

因果本是叙事
因果本是叙事人类总习惯于追问“为什么”。战争为什么爆发,企业为什么衰落,一个人为什么成功,一段关系为什么破裂。我们仿佛天然相信,每个结果背后都存在一个明确的原因,像齿轮咬合般推动世界运行。然而,当…...

我见过最聪明的技术人,都在偷偷培养这3种“非技术能力”
在软件测试行业摸爬滚打这些年,我见过太多天赋异禀的技术从业者:有人能一夜吃透新的自动化测试框架,有人能对着流量日志半小时定位出隐藏半年的内存泄漏问题,有人能把性能测试指标优化到远超行业标准。可几年过去,真正…...

【设计模式 14】责任链:谁来拍板
这一课讲责任链模式。什么在变:处理链路经常调整,审批层级和条件经常变。怎么挡:处理者串成链,每个只决定"签还是传"。那张采购申请单在三个部门之间转了十七天。 十七天。买的东西是一批进口检测设备,总价两…...
)
良心盘点!2026AI写作辅助软件榜单(覆盖 99% 毕业论文需求)
本文精选13 款2026 年实测 AI 论文工具,按全流程全能型、垂直领域专精型、润色降重专家、文献管理助手四大类别排序,覆盖从选题到定稿全链路,适配本科 / 硕博 / 期刊全场景,附选型速查表与避坑指南,帮你快速找到最佳拍…...

数字化舆论管控新时代,搜极星赋能企业长效发展
数字化舆论已从传统社交平台、媒体渠道,全面延伸至 AI 大模型对话场景。AI 幻觉、虚假信息扩散、恶意信息投毒、跨平台舆论失控,正成为企业声誉管理的全新挑战。 传统人工排查、被动应对、局部监测的舆论管控模式彻底失效,企业亟需一套全域覆…...

中小型企业服务器常见隐患 + 标准化运维维护方案总结
做运维多年,接触过大量中小企业服务器,总结几个最常见、最致命的问题:1、服务器常年不关机、不巡检,磁盘爆满无人察觉;2、对外开放端口过多,没有安全策略,极易被暴力破解;3、数据库无…...

如何在3分钟内为Word添加专业APA第7版引用格式:终极指南
如何在3分钟内为Word添加专业APA第7版引用格式:终极指南 【免费下载链接】APA-7th-Edition Microsoft Word XSD for generating APA 7th edition references 项目地址: https://gitcode.com/gh_mirrors/ap/APA-7th-Edition 学术写作中,引用格式的…...