【数据结构】Map和Set
⭐ 作者:小胡_不糊涂
🌱 作者主页:小胡_不糊涂的个人主页
📀 收录专栏:浅谈数据结构
💖 持续更文,关注博主少走弯路,谢谢大家支持 💖
Map、Set
- 1. 搜索树
- 1.1 概念
- 1.2 性能分析
- 2. 搜索
- 2.1 概念及场景
- 2.2 模型
- 3. Map的使用
- 3.1 关于Map.Entry<K, V>的说明
- 3.2 Map的常用方法说明
- 3.4 TreeMap的使用案例
- 4. Set的说明
- 4.1 常见方法说明
- 4.2 TreeSet的使用案例

1. 搜索树
1.1 概念
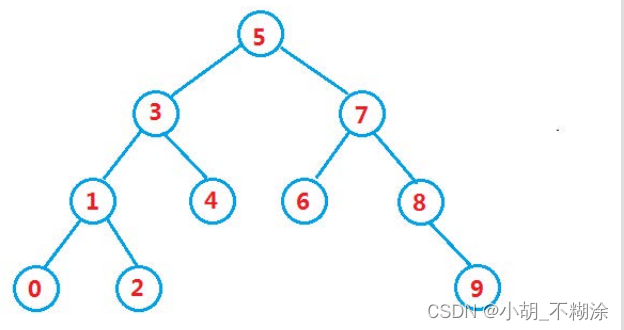
二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:
- 若它的左子树不为空,则左子树上所有节点的值都小于根节点的值
- 若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
- 它的左右子树也分别为二叉搜索树
下图就是一个二叉搜索树:
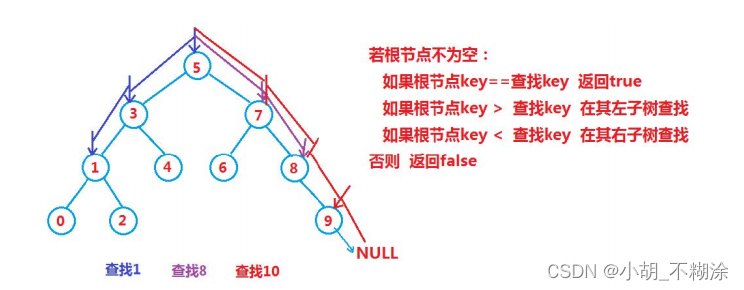
进行查找操作:
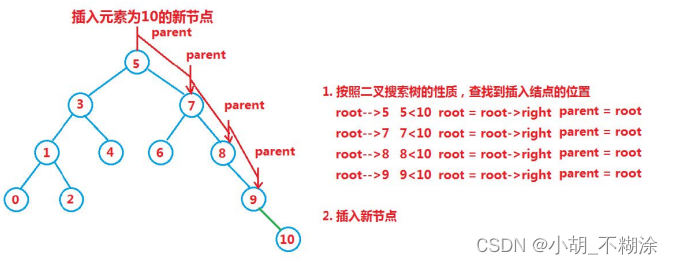
进行插入操作:
1. 树为空树

2. 如果树不是空树,按照查找逻辑确定插入位置,插入新结点
进行删除操作:
设待删除结点为 cur, 待删除结点的双亲结点为 parent
- cur.left == null
cur 是 root,则 root = cur.right
cur 不是 root,cur 是 parent.left,则 parent.left = cur.right
cur 不是 root,cur 是 parent.right,则 parent.right = cur.right - cur.right == null
cur 是 root,则 root = cur.left
cur 不是 root,cur 是 parent.left,则 parent.left = cur.left
cur 不是 root,cur 是 parent.right,则 parent.right = cur.left - cur.left != null && cur.right != null
需要使用替换法进行删除,即在它的右子树中寻找中序下的第一个结点(关键码最小),用它的值填补到被删除节点中,再来处理该结点的删除问题

代码实现:
public class BinarySearchTree {public static class TreeNode{int val;TreeNode left;TreeNode right;public TreeNode(int val){this.val=val;}}public TreeNode root;/*** 查找元素* 最好情况:完全二叉树 O(logN)* 最坏情况: 单分支的树 O(N)* @param key* @return*/public boolean search(int key){TreeNode cur=root;while(cur!=null){if(cur.val==key){return true;}else if(cur.val>key){cur=cur.left;}else{cur=cur.right;}}return false;}//插入元素public boolean insert(int key){if(root==null){root=new TreeNode(key);return true;}TreeNode cur=root;TreeNode parent=null;while(cur!=null){if(cur.val>key){parent=cur;cur=cur.left;}else if(cur.val<key){parent=cur;cur=cur.right;}else{return false;//树中不能有相等元素}}//若cur=null,判断key与父亲节点的大小if(parent.val>key){parent.left=new TreeNode(key);}if(parent.val<key){parent.right=new TreeNode(key);}return true;}//删除元素public void remove(int key){TreeNode cur = root;TreeNode parent = null;while (cur != null) {if(cur.val < key) {parent = cur;cur = cur.right;}else if(cur.val > key) {parent = cur;cur = cur.left;}else {//开始删除removeNode(cur,parent);}}}public void removeNode(TreeNode cur,TreeNode parent){//第一种情况if(cur.left==null){if(cur==root){root=cur.right;}if(cur==parent.left){parent.left=cur.right;}if(cur==parent.right){parent.right=cur.right;}}//第二种情况if(cur.right == null) {if(cur == root) {root = cur.left;}else if(cur == parent.left) {parent.left = cur.left;}else {parent.right = cur.left;}}//第三种情况if(cur.left!=null && cur.right!=null){TreeNode targetParent = cur;TreeNode target = cur.right;while (target.left != null) {targetParent = target;target = target.left;}cur.val = target.val;//删除targetif(targetParent.left == target) {targetParent.left = target.right;}else {targetParent.right = target.right;}}}
}
1.2 性能分析
插入和删除操作都必须先查找,查找效率代表了二叉搜索树中各个操作的性能。
对有n个结点的二叉搜索树,若每个元素查找的概率相等,则二叉搜索树平均查找长度是结点在二叉搜索树的深度的函数,即结点越深,则比较次数越多。
但对于同一个关键码集合,如果各关键码插入的次序不同,可能得到不同结构的二叉搜索树:
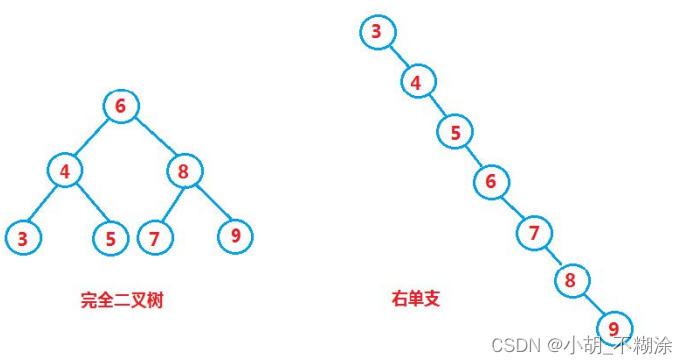
最优情况下,二叉搜索树为完全二叉树,其平均比较次数为:log2(N)
最差情况下,二叉搜索树退化为单支树,其平均比较次数为:N/2
2. 搜索
2.1 概念及场景
Map 和 Set 是一种专门用来进行搜索的容器或者数据结构,其搜索的效率与其具体的实例化子类有关。 以前常见的搜索方式有:
- 直接遍历,时间复杂度为O(N),元素如果比较多效率会非常慢
- 二分查找,时间复杂度为,但搜索前必须要求序列是有序的
上述排序比较适合静态类型的查找,即一般不会对区间进行插入和删除操作了,而现实中的查找比如:
- 根据姓名查询考试成绩
- 通讯录,即根据姓名查询联系方式
- 不重复集合,即需要先搜索关键字是否已经在集合中
可能在查找时进行一些插入和删除,即动态查找,那上述两种方式就不太适合了,而 Map 和 Set 则是一种适合动态查找的集合容器。
2.2 模型
一般把搜索的数据称为关键字(Key),和关键字对应的称为值(Value),将其称之为Key-value的键值对,所以模型会有两种:
- 纯 key 模型,比如:
- 有一个英文词典,快速查找一个单词是否在词典中
- 快速查找某个名字在不在通讯录中
- Key-Value 模型,比如:
- 统计文件中每个单词出现的次数,统计结果是每个单词都有与其对应的次数:<单词,单词出现的次数>
而Map中存储的就是key-value的键值对,Set中只存储了Key
3. Map的使用

Map是一个接口类,该类没有继承自Collection,该类中存储的是<K,V>结构的键值对,并且K一定是唯一的,不能重复。
3.1 关于Map.Entry<K, V>的说明
Map.Entry<K, V> 是Map内部实现的用来存放<key, value>键值对映射关系的内部类,该内部类中主要提供了<key, value>的获取,value的设置以及Key的比较方式。
| 方法 | 解释 |
|---|---|
| K getKey() | 返回 entry 中的 key |
| V getValue() | 返回 entry 中的 value |
| V setValue(V value) | 将键值对中的value替换为指定value |
Map.Entry<K,V>并没有提供设置Key的方法
3.2 Map的常用方法说明
| 方法 | 解释 |
|---|---|
| V get(Object key) | 返回 key 对应的 value |
| V getOrDefault(Object key, V defaultValue) | 返回 key 对应的 value,key 不存在,返回默认值 |
| V put(K key, V value) | 设置 key 对应的 value |
| V remove(Object key) | 删除 key 对应的映射关系 |
| Set keySet() | 返回所有 key 的不重复集合 |
| Collection values() | 返回所有 value 的可重复集合 |
| Set<Map.Entry<K, V>> entrySet() | 返回所有的 key-value 映射关系 |
| boolean containsKey(Object key) | 判断是否包含 key |
| boolean containsValue(Object value) | 判断是否包含 value |
注:
- Map是一个接口,不能直接实例化对象,如果要实例化对象只能实例化其实现类TreeMap或者HashMap
- Map中存放键值对的Key是唯一的,value是可以重复的
- 在TreeMap中插入键值对时,key不能为空,否则就会抛NullPointerException异常,value可以为空。但是HashMap的key和value都可以为空。
- Map中的Key可以全部分离出来,存储到Set中来进行访问(因为Key不能重复)。
- Map中的value可以全部分离出来,存储在Collection的任何一个子集合中(value可能有重复)。
- Map中键值对的Key不能直接修改,value可以修改,如果要修改key,只能先将该key删除掉,然后再来进行重新插入。
- TreeMap和HashMap的区别:
| Map底层结构 | TreeMap | HashMap |
|---|---|---|
| 底层结构 | 红黑树 | 哈希桶 |
| 插入/删除/查找时间复杂度 | O(log2(N)) | O(1) |
| 是否有序 | 关于Key有序 | 无序 |
| 线程安全 | 不安全 | 不安全 |
| 插入/删除/查找区别 | 需要进行元素比较 | 通过哈希函数计算哈希地址 |
| 比较与覆写 | key必须能够比较,否则会抛出ClassCastException异常 | 自定义类型需要覆写equals和hashCode方法 |
| 应用场景 | 需要Key有序场景下 | Key是否有序不关心,需要更高的时间性能 |
3.4 TreeMap的使用案例
public static void TestMap(){Map<String, String> m = new TreeMap<>();// put(key, value):插入key-value的键值对// 如果key不存在,会将key-value的键值对插入到map中,返回nullm.put("林冲", "豹子头");m.put("鲁智深", "花和尚");m.put("武松", "行者");m.put("宋江", "及时雨");String str = m.put("李逵", "黑旋风");System.out.println(m.size());//5System.out.println(m);//{宋江=及时雨, 李逵=黑旋风, 林冲=豹子头, 武松=行者, 鲁智深=花和尚}// put(key,value): 注意key不能为空,但是value可以为空// key如果为空,会抛出空指针异常//m.put(null, "花名");str = m.put("无名", null);System.out.println(m.size());//6// put(key, value):// 如果key存在,会使用value替换原来key所对应的value,返回旧valuestr = m.put("李逵", "铁牛");// get(key): 返回key所对应的value// 如果key存在,返回key所对应的value// 如果key不存在,返回nullSystem.out.println(m.get("鲁智深"));//花和尚System.out.println(m.get("史进"));//null//GetOrDefault(): 如果key存在,返回与key所对应的value,如果key不存在,返回一个默认值System.out.println(m.getOrDefault("李逵", "铁牛"));//铁牛System.out.println(m.getOrDefault("史进", "九纹龙"));//九纹龙System.out.println(m.size());//6//containKey(key):检测key是否包含在Map中,时间复杂度:O(logN)// 按照红黑树的性质来进行查找// 找到返回true,否则返回falseSystem.out.println(m.containsKey("林冲"));//trueSystem.out.println(m.containsKey("史进"));//false// containValue(value): 检测value是否包含在Map中,时间复杂度: O(N)// 找到返回true,否则返回falseSystem.out.println(m.containsValue("豹子头"));//trueSystem.out.println(m.containsValue("九纹龙"));//false// 打印所有的key// keySet是将map中的key防止在Set中返回的for(String s : m.keySet()){System.out.print(s + " ");//宋江 无名 李逵 林冲 武松 鲁智深 }System.out.println();// 打印所有的value// values()是将map中的value放在collect的一个集合中返回的for(String s : m.values()){System.out.print(s + " ");//及时雨 null 铁牛 豹子头 行者 花和尚}System.out.println();// 打印所有的键值对// entrySet(): 将Map中的键值对放在Set中返回了for(Map.Entry<String, String> entry : m.entrySet()){System.out.println(entry.getKey() + "--->" + entry.getValue());}System.out.println();//宋江--->及时雨//无名--->null//李逵--->铁牛//林冲--->豹子头//武松--->行者//鲁智深--->花和尚}
4. Set的说明
Set与Map主要的不同有两点:Set是继承自Collection的接口类,Set中只存储了Key。
4.1 常见方法说明
| 方法 | 解释 |
|---|---|
| boolean add(E e) | 添加元素,但重复元素不会被添加成功 |
| void clear() | 清空集合 |
| boolean contains(Object o) | 判断 o 是否在集合中 |
| Iterator iterator() | 返回迭代器 |
| boolean remove(Object o) | 删除集合中的 o |
| int size() | 返回set中元素的个数 |
| boolean isEmpty() | 检测set是否为空,空返回true,否则返回false |
| Object[] toArray() | 将set中的元素转换为数组返回 |
| boolean containsAll(Collection<?> c) | 集合c中的元素是否在set中全部存在,是返回true,否则返回false |
| boolean addAll(Collection<? extendsE> c) | 将集合c中的元素添加到set中,可以达到去重的效果 |
注意:
- Set是继承自Collection的一个接口类
- Set中只存储了key,并且要求key一定要唯一
- TreeSet的底层是使用Map来实现的,其使用key与Object的一个默认对象作为键值对插入到Map中的
- Set最大的功能就是对集合中的元素进行去重
- 实现Set接口的常用类有TreeSet和HashSet,还有一个LinkedHashSet,LinkedHashSet是在HashSet的基础上维护了一个双向链表来记录元素的插入次序。
- Set中的**Key不能修改,**如果要修改,先将原来的删除掉,然后再重新插入
- TreeSet中不能插入null的key,HashSet可以。
- TreeSet和HashSet的区别:
| Set底层结构 | TreeSet | HashSet |
|---|---|---|
| 底层结构 | 红黑树 | 哈希桶 |
| 插入/删除/查找时间复杂度 | O(log2(N) | O(1) |
| 是否有序 | 关于Key有序 | 不一定有序 |
| 线程安全 | 不安全 | 不安全 |
| 插入/删除/查找区别 | 按照红黑树的特性来进行插入和删除 | 1. 先计算key哈希地址 2. 然后进行 |
| 插入和删除 | ||
| 比较与覆写 | key必须能够比较,否则会抛出ClassCastException异常 | 自定义类型需要覆写equals和hashCode方法 |
| 应用场景需要 | Key有序场景 | Key是否有序不关心,需要更高的时间性能 |
4.2 TreeSet的使用案例
public static void TestSet(){Set<String> s = new TreeSet<>();// add(key): 如果key不存在,则插入,返回ture// 如果key存在,返回falseboolean isIn = s.add("apple");s.add("orange");s.add("peach");s.add("banana");System.out.println(s.size());//4System.out.println(s);//[apple, banana, orange, peach]isIn = s.add("apple");// add(key): key如果是空,抛出空指针异常//s.add(null);// contains(key): 如果key存在,返回true,否则返回falseSystem.out.println(s.contains("apple"));//trueSystem.out.println(s.contains("watermelen"));//false// remove(key): key存在,删除成功返回true// key不存在,删除失败返回false// key为空,抛出空指针异常s.remove("apple");System.out.println(s);//[banana, orange, peach]s.remove("watermelen");System.out.println(s);//[banana, orange, peach]Iterator<String> it = s.iterator();while(it.hasNext()){System.out.print(it.next() + " ");}System.out.println();//banana orange peach}
相关文章:
【数据结构】Map和Set
⭐ 作者:小胡_不糊涂 🌱 作者主页:小胡_不糊涂的个人主页 📀 收录专栏:浅谈数据结构 💖 持续更文,关注博主少走弯路,谢谢大家支持 💖 Map、Set 1. 搜索树1.1 概念1.2 性能…...

Python Flask
Python Flask是一个轻量级的web开发框架,用于快速地构建web应用程序。以下是Python Flask的基本使用步骤: 安装Flask:使用pip安装Flask包。在命令行中输入以下命令: pip install flask创建Flask对象:在Python文件中&am…...
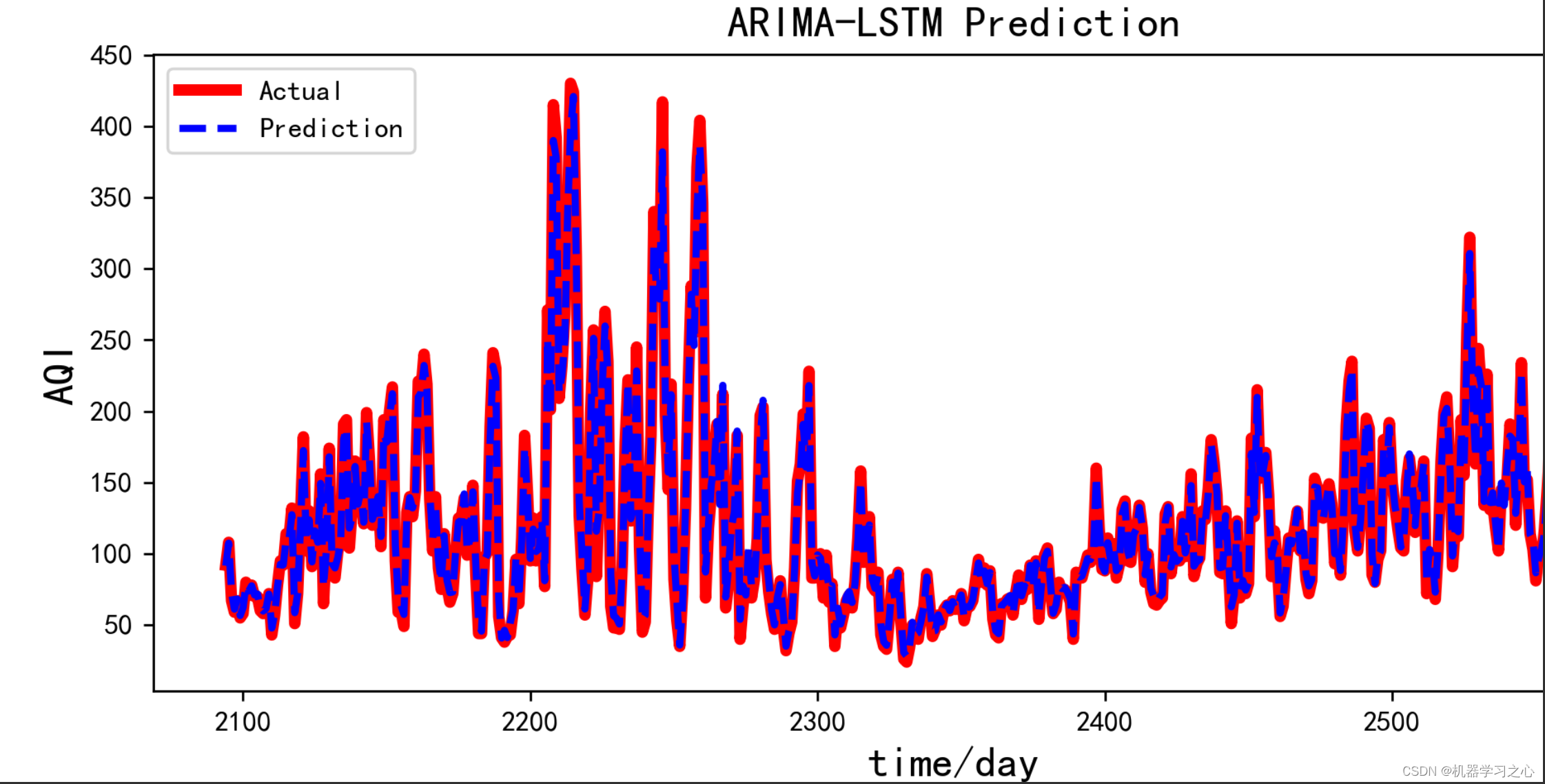
时序预测 | Python实现ARIMA-LSTM差分自回归移动平均模型结合长短期记忆神经网络时间序列预测
时序预测 | Python实现ARIMA-LSTM差分自回归移动平均模型结合长短期记忆神经网络时间序列预测 目录 时序预测 | Python实现ARIMA-LSTM差分自回归移动平均模型结合长短期记忆神经网络时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 时序预测 | Python实现ARIM…...
)
Redis快速上手篇八(redission完善分布式锁)
Redisson Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务,其中就包含了各种分布式锁的实现。简单说就是redis在分布式系统上工…...

Dataset文件下载以及使用,以nuswide为例
文章目录 文件夹结构如何使用继承torch.utils.data.Dataset构建新的class构建新的Dataloader 数据集要求以文章 multi-label learning from single positive label为例; 文件夹结构 我是这么放置的,其中含有obs的文件是通过运行文件夹preproc下的genera…...

ZYNQ连载02-开发环境
ZYNQ连载02-开发环境 1. 官方文档 ZYNQ开发使用的软件为Vivado/Vitis/PetaLinux,软件体积比较大,硬盘保留100G以上的空间,赛灵思提供详细的文档,链接如下: ZYNQ文档 2. Vivido和Vitis安装 赛灵思统一安装程序 3. PetaLinux安装…...
前端 :用HTML和css制作一个小米官网的静态页面
1.HTML: <body><div id "content"><div id "box"><div id "top"><div id "top-left"><span id "logo">MI</span><span id "text-logo">小米账…...

modelsim仿真报错:vlog-2388 ‘scl‘ already declared in this scope
问题背景: 1、使用vivado直接仿真的时候没有报错。 2、在vivado中调用modelsim的时候报错。 报错的代码: module iic_write(input clk,input rst,output scl,input en,inout sda);reg scl;……报错的意思是scl已经声明过了,mode…...
和EndInvoke()来实现异步)
C#中通过BeginInvoke()和EndInvoke()来实现异步
.NET Framework允许异步调用任何方法。定义与需要调用的方法具有相同签名的委托;公共语言运行库将自动为该委托定义具有适当签名的 BeginInvoke 和 EndInvoke 方法。以下介绍C#中,通过BeginInvoke()和EndInvoke()来实现异步。 1、异步编程 调用BeginInv…...

github中.gitignore不起作用啦
文章目录 前言两种方法解决清除本地缓存设置不需要 额外注意 前言 提示:人不是靠讲话来生活。每个人都应该靠行动。而行动,是需要时间来证明的。 --《自在独行》 两种方法解决 清除本地缓存 (.gitignore中已经表标明忽略的文件目录下的文件了…...
同步网盘推荐及挑选指南:便捷、安全、适用的选择
同步网盘是最近热门的文件协同工具之一,因其使用的便捷性受到了诸多用户的青睐。如今网盘市场产品众多,有什么好用的同步网盘?如何挑选同步网盘?是许多需求者关心的问题。 如何挑选同步网盘?在同步网盘挑选过程中要从…...

Java中的QName
javax.xml.namespace.QName代表XML规范中一个限定性名称(qualified name),它包含一个命名空间地址(Namespace URI)、一个本地部分、和一个前缀。QName可以用在xml的元素和属性中。 前缀提供了命名空间地址的前缀&#…...
汇编语言-div指令溢出问题
汇编语言-div指令溢出问题 8086CPU中被除数保存在ax(16位)或ax和dx(32位)中,如果被除数为16位,进行除法运算时al保存商,ah保存余数。如果被除数为32位时,进行除法运算时,ax保存商,d…...
)
koa搭建服务器(一)
最近有个需求需要使用到koa搭建服务器并编写接口对数据库进行增删改查,因此写一篇博客记录这段时间的收获。 一、新建koa项目 (一)安装koa及其相关依赖 npm i koa npm i koa-router// 中间件,用于匹配路由 npm i koa-bodyparse…...

qt-C++笔记之在两个标签页中按行读取两个不同的文件并且滚动条自适应滚动范围高度
qt-C笔记之在两个标签页中按行读取两个不同的文件并且滚动条自适应滚动范围高度 code review! 文章目录 qt-C笔记之在两个标签页中按行读取两个不同的文件并且滚动条自适应滚动范围高度1.运行2.文件结构3.main.cc4.main.pro5.a.txt6.b.txt7.上述代码中QVBoxLayout,…...
github搜索技巧探索
毕设涉及到推荐系统,那么就用搜索推荐系统相关资料来探索一下GitHub的搜搜技巧 文章目录 1. 基础搜索2. 限定在特定仓库搜索3. 按照语言搜索4. 按照star数量搜索5. 搜索特定用户/组织的仓库6. 查找特定文件或路径7. 按时间搜索8. 搜索不包含某个词的仓库9. 搜索特定…...
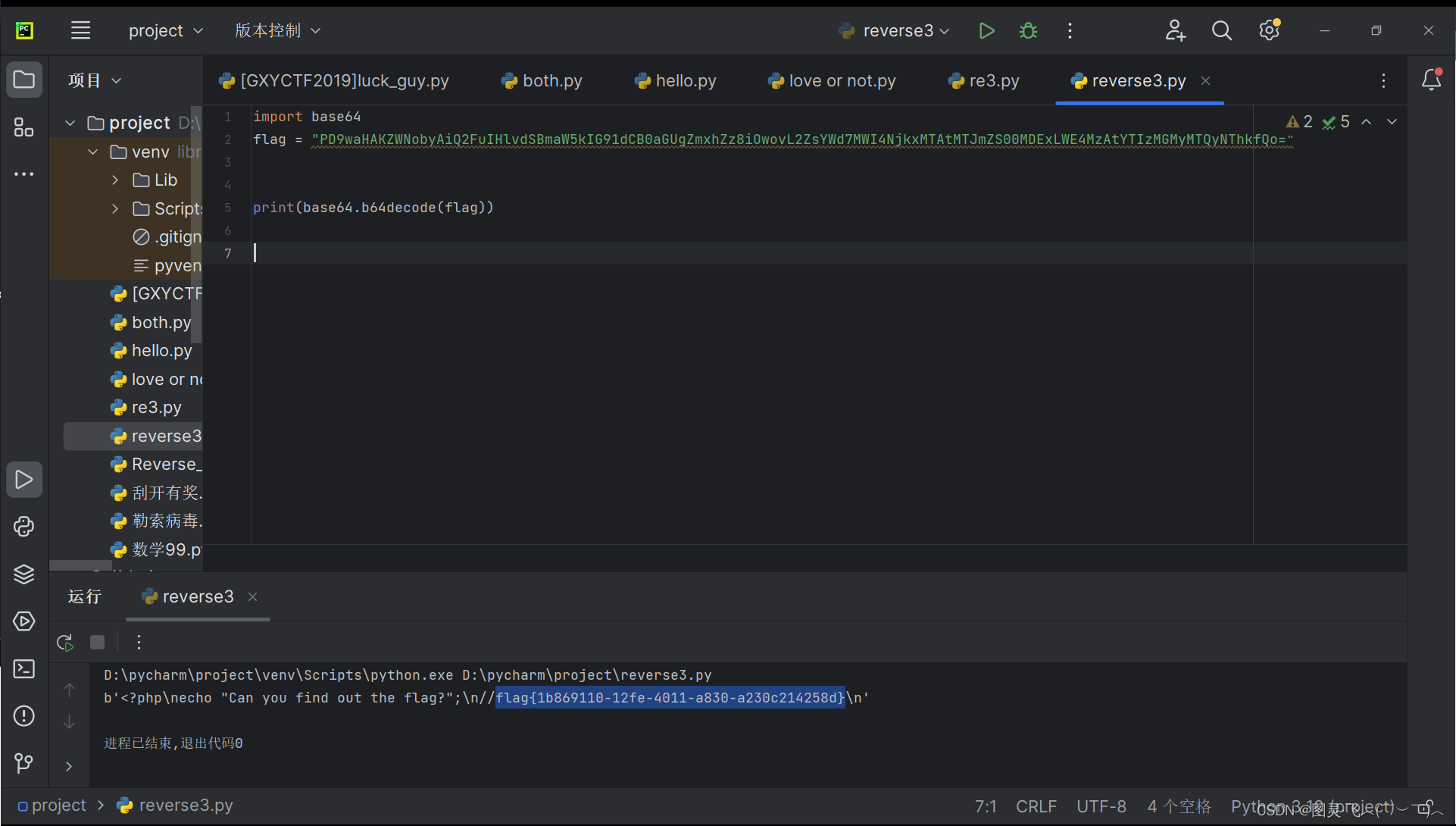
[ACTF2020 新生赛]Include
【解题思路】 1.打开链接 发现好东西,进一步分析。 2.分析页面 发现网页得到一个GET请求-->?fileflag.php 可以推断,要解答该题目需要获取 flag.php 的源代码. 将flag.php文件进行base64编码(将网页源代码转换为Base64编码ÿ…...
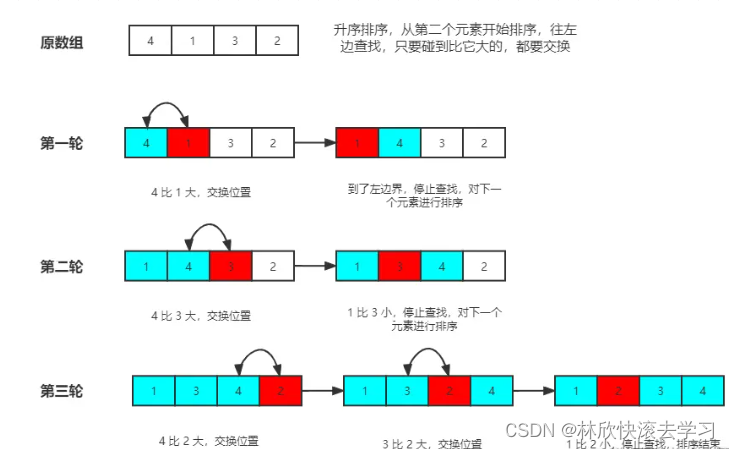
Go 实现插入排序算法及优化
插入排序 插入排序是一种简单的排序算法,以数组为例,我们可以把数组看成是多个数组组成。插入排序的基本思想是往前面已排好序的数组中插入一个元素,组成一个新的数组,此数组依然有序。光看文字可能不理解,让我们看看…...
--max30102 - 心率模块)
LuatOS-SOC接口文档(air780E)--max30102 - 心率模块
max30102.init(i2c_id,int)# 初始化MAX30102传感器 参数 传入值类型 解释 int 传感器所在的i2c总线id,默认为0 int int引脚 返回值 返回值类型 解释 bool 成功返回true, 否则返回nil或者false 例子 if max30102.init(0,pin.PC05) thenlog.info("max30102&q…...
设计模式(2)-创建型模式
1,创建型模式 4.1 单例设计模式 单例模式(Singleton Pattern)是 Java 中最简单的设计模式之一。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。 这种模式涉及到一个单一的类,该类负责创建自己…...

3分钟掌握加密压缩包密码破解:ArchivePasswordTestTool终极实战指南
3分钟掌握加密压缩包密码破解:ArchivePasswordTestTool终极实战指南 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经…...

2026网盘怎么选:别只盯“不限速”,更该看同步稳定性与数据安全
很多人换网盘的导火索是“限速”,但真正拉开体验差距的,往往是:同步是否稳定、复杂网络下是否容易失败、多人协作有没有权限与版本控制、数据安全与合规是否站得住脚。下面这篇不再只比较“快不快”,而是用更贴近长期使用的维度&a…...

终极RPG Maker MV/MZ游戏资源解密工具:三步搞定加密文件提取
终极RPG Maker MV/MZ游戏资源解密工具:三步搞定加密文件提取 【免费下载链接】RPG-Maker-MV-Decrypter You can decrypt RPG-Maker-MV Resource Files with this project ~ If you dont wanna download it, you can use the Script on my HP: 项目地址: https://g…...
)
Python爬虫实战:构建博物馆藏品数字档案(列表到详情深度采集)
㊗️本期内容已收录至专栏《Python爬虫实战》,持续完善知识体系与项目实战,建议先订阅收藏,后续查阅更方便~ ㊙️本期爬虫难度指数:⭐⭐⭐ (进阶) 🉐福利: 一次订阅后,专栏内的所有文…...

【测试】一文读懂软件测试:新手真正需要的测试认知
📌 相关专栏 【Linux专栏】【C语言专栏】【测试专栏】 📌 相关文章推荐 【Linux】网络基础2---Socket编程预备【Linux 】网络基础1 哈喽~欢迎来到千余的小天地 ❤ 我会分享很多干货/日常,点个关注不迷路哦~ 👍 点赞 ⭐ 收藏 &…...

如何三步完成QQ音乐加密音频的免费解密:解决音乐格式兼容性难题
如何三步完成QQ音乐加密音频的免费解密:解决音乐格式兼容性难题 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录…...

Appium环境搭建实战手册:解决JDK、Android SDK与Node.js兼容性问题
1. 为什么Appium环境搭建总让人卡在第一步?——不是工具不行,是路径没走对“Appium环境搭好了吗?”这句话我过去三年在测试团队晨会里至少听过27次。不是新人问的,是干了五年自动化测试的老同事皱着眉甩出来的。他刚重装系统&…...

XRF导向的土壤重金属定量分析方法与应用【附模型】
✨ 长期致力于X射线荧光、土壤重金属、本底扣除、重叠峰解析、光谱联用研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)非对称加权惩罚最小二乘本底扣…...

别再只用Selenium了!手把手教你用Python+UIAutomation+Unittest搭建Windows应用自动化测试框架
从Selenium到UIAutomation:Windows GUI自动化测试实战进阶指南 当Web自动化测试工程师首次接触Windows桌面应用测试时,往往会陷入工具选择的困境。传统基于坐标操作的自动化方案难以应对动态界面变化,而商业工具又存在学习成本高、灵活性不足…...

Midjourney景深模糊失效全解析,深度拆解--no参数干扰链、背景层剥离阈值及alpha通道注入技巧
更多请点击: https://intelliparadigm.com 第一章:Midjourney景深效果控制的底层逻辑与失效本质 Midjourney 并未提供原生的、参数化的景深(Depth of Field, DoF)控制机制。其所谓“景深效果”实为提示词引导下的隐式风格模仿&a…...