[读论文] On Joint Learning for Solving Placement and Routing in Chip Design
0. Abstract
由于 GPU 在加速计算方面的优势和对人类专家的依赖较少,机器学习已成为解决布局和布线问题的新兴工具,这是现代芯片设计流程中的两个关键步骤。它仍处于早期阶段,存在一些基本问题:可扩展性、奖励设计和端到端学习范式等。为了实现端到端放置学习,我们首先提出了一种由 DeepPlace 命名的联合学习方法,通过将强化学习与基于梯度的优化方案相结合,用于宏和标准单元的放置。为了进一步将布局与随后的布线任务连接起来,我们还开发了一种通过强化学习来同时完成宏布局和布线的联合学习方法,称为 DeepPR。我们的强化学习范例中的一个关键设计涉及一个多视图嵌入模型,用于编码输入宏的全局图级和局部节点级信息。此外,设计了随机网络蒸馏来鼓励探索。在公共芯片设计基准上的实验表明,经过几小时的训练,我们的方法可以有效地从经验中学习,并为标准单元放置后提供中间放置。
1. Introduction
2. Related Work
3. Methodology
3.1 Problem Formulation
首先,针对宏布局问题,其目标是确定宏在芯片画布上的位置,并且没有重叠和使线路长度最小。我们的 RL 代理将这些宏依次映射到布局上的有效位置。
- 当所有的宏都被放置后,我们要么固定它们的位置,要么采用基于梯度的放置优化,得到一个完整的布局方案,并有相应的评估指标,如线长和拥塞,如图 2(a) 所示。
- 或者,我们采用经典布线器或另一种 RL 代理来布局线路,并将确切的总长度作为布局和布线任务的奖励,如图 2(b) 所示。
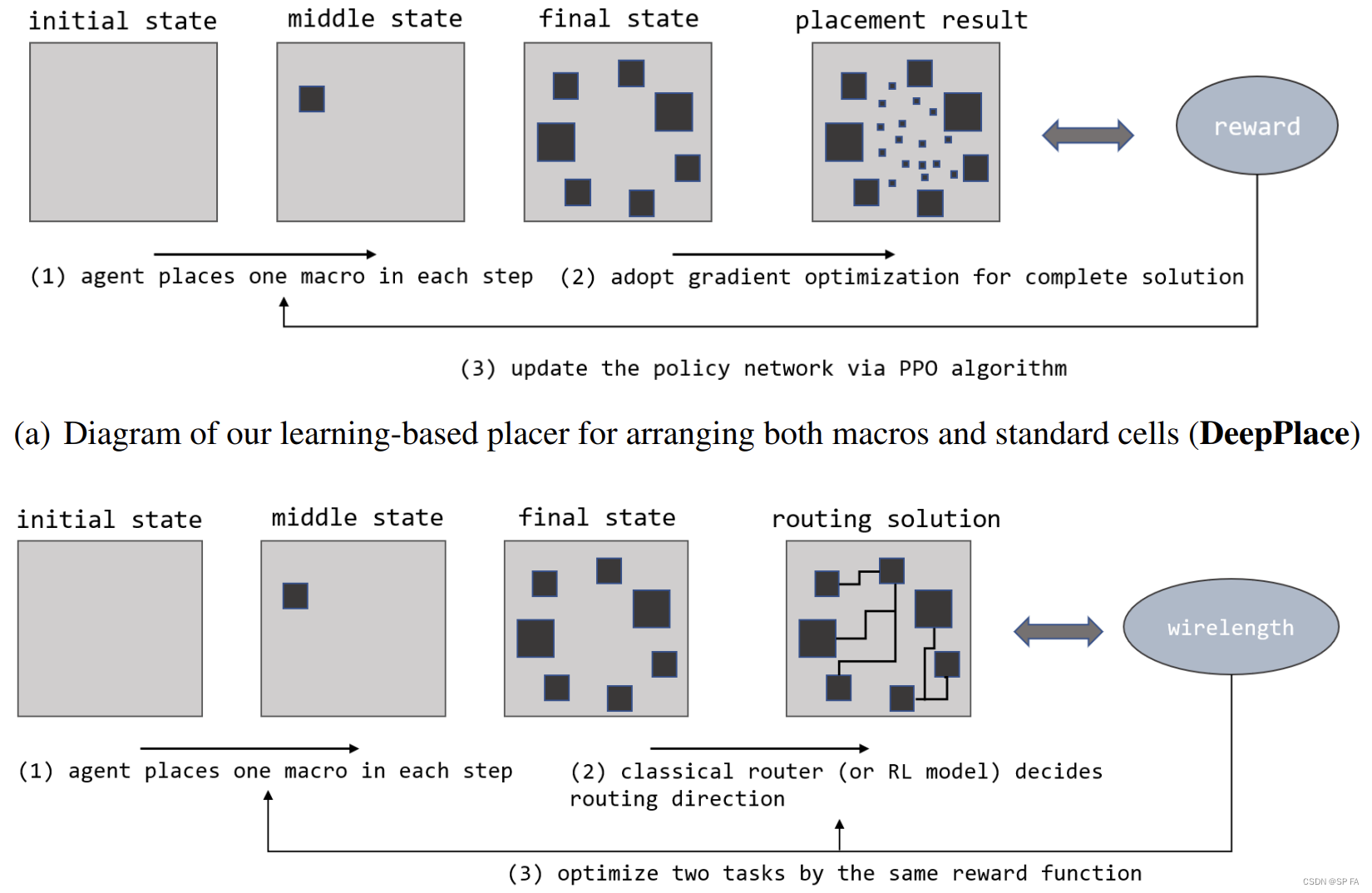
马尔可夫决策过程的关键要素定义如下:
- State s t s_t st: 状态表示由两部分组成,全局图 I I I 描绘了布局,网表图 H H H 包含了已放置的所有宏的详细位置。注意,布局问题类似于棋盘游戏,两者都需要确定棋子的位置。因此,我们将棋盘建模为二值图像 I I I,其中 1 表示已被占用的位置。此外,棋盘游戏的规则类似于网表图 H H H,与全局图像互补。
- Action a t a_t at: 动作空间包含时间 t t t 时 n × n n × n n×n 画布上的可用位置,其中 n n n 表示网格的大小。一旦当前宏选择了一个备用位置 ( x , y ) (x, y) (x,y),我们设置 I x y = 1 I_{xy}=1 Ixy=1 并从可用列表中删除该位置。
- Reward r t r_t rt: 最后的奖励是最终解决方案的线长和布线拥塞的负加权和。权重是主布线目标长度与布线拥塞之间的权衡,反映了路由任务的可达性。与其他深度强化学习放置器将之前所有动作的奖励设置为 0 不同,我们采用随机网络蒸馏(RND)来计算每个时间步的内在奖励。
策略网络学习通过放置先前的芯片来最大化预期回报,并通过近端策略优化(PPO)来提高放置质量。
3.2 The Structure of Policy Network
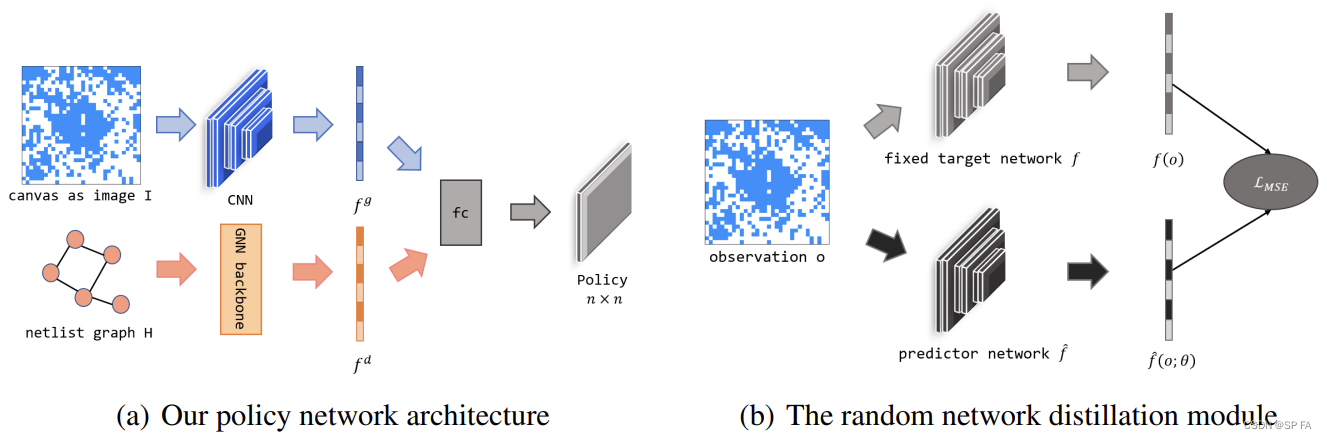
由于解决布局问题和玩棋盘游戏本质上都是以顺序的方式确定宏的位置,因此我们将当前状态建模为大小为 n × n n × n n×n 的图像 I I I。当先前的宏放置在位置 ( x , y ) (x, y) (x,y) 时, I x y = 1 I_{xy}=1 Ixy=1。此图像表示给出了部分布局的概述,但丢失了一些详细信息。我们进一步从 CNN 中得到全局嵌入。此外,作为关键输入信息的网表图隐含了奖励计算规则,对动作预测具有详细的指导作用。在这种情况下,我们开发了一个 GNN 架构,该架构可以为当前考虑的宏生成详细的节点嵌入。图神经网络的作用是探索网表的物理意义,并将节点的连通性信息提取成低维向量表示,用于后续的计算。在获得 CNN 的全局嵌入和 GNN 的详细节点嵌入后,我们将它们拼接融合,并将结果传递给全连接层以生成动作的概率分布。我们认为多视图嵌入模型能够综合挖掘全局和节点级信息。策略网络的整体结构如图 3(a) 所示。
3.3 Reward Design
3.3.1 Extrinsic Reward Design
尽管芯片布局的确切目标是最小化功耗、性能和面积,但它需要行业标准 EDA 工具花费数小时进行评估,这对于需要数千个示例来学习的 RL 代理来说是无法承受的,因此找到与真实奖励正相关的近似奖励函数是很自然的想法。我们定义了具有线长和拥塞的成本函数,试图同时优化性能和可达性: R E = − W i r e l e n g t h ( P , H ) − λ ⋅ C o n g e s t i o n ( P , H ) R_E=-Wirelength(P,H)-\lambda\cdot Congestion(P,H) RE=−Wirelength(P,H)−λ⋅Congestion(P,H)
其中 P P P 表示布局方案, H H H 表示网表, λ λ λ 是一个超参数,根据给定芯片的设置对相对重要性进行加权。
- Wirelength:使用经典的 HPWL 算法
- Congestion:我们采用矩形均匀线密度(RUDY)来近似布线拥塞。我们在实验中将线路拥塞的阈值设置为 0.1,否则会导致拥塞检查失败。
3.3.2 Intrinsic Reward Design
由于在完整流程结束之前不能提供有用的奖励信号,这使得布局成为一个稀疏奖励任务。情景奖励往往容易使算法在训练过程中陷入困境,导致算法性能低下,样本复杂度低下。受随机网络蒸馏(RND)思想的启发,我们在每个时间步中给予内在奖励以鼓励探索,如图 3(b) 所示。RND 中涉及两个网络:一个固定的和随机初始化的目标网络和一个根据代理收集的全局图像训练的预测网络。给定当前观测值 o o o (也指全局图像),目标网络和预测网络生成嵌入 f ( o ) f(o) f(o) 和 f ^ ( o ; θ ) \hat f(o;θ) f^(o;θ)。则内在奖励为: R T = ∣ ∣ f ^ ( o ; θ ) − f ( o ) ∣ ∣ 2 R_T=||\hat f(o;\theta)-f(o)||^2 RT=∣∣f^(o;θ)−f(o)∣∣2之后,由 SGD 训练的预测器网络用以最小化一个 MSE,该 MSE 将随机初始化的网络蒸馏为训练好的网络。这种蒸馏误差可以看作是预测不确定性的量化。当一个新的状态被期望与预测器所训练的不同时,内在奖励也会变得更高,以鼓励访问新的状态。
3.4 Combination with Gradient-based Placement Optimization
考虑到对宏布局的评估指标的影响,数百万个标准单元的布局与宏的布局同样重要。为了确保训练时每次迭代的运行时间能够承受,我们应用最先进的基于梯度的优化放置器 DREAMPlace 来安排奖励计算步骤中的标准单元。一方面,宏作为固定实例的位置会影响基于梯度的优化放置的解质量,这可以通过训练随着时间的推移而改善。另一方面,更好的近似度量(如长度)可以更好地指导智能体的训练。因此,RL agent 与基于梯度的优化放置器的组合将相互促进。此外,最先进的工具 DREAMPlace 实现了分析放置中的关键内核,例如,深度学习工具包的长度和密度计算,充分挖掘了 GPU 加速的潜力,并把运行时间减少到了不到一分钟。
3.5 Joint Learning of Placement and Routing
可达性是布局过程中需要考虑的最关键因素之一,因此拥塞是大多数方法中奖励函数的必要组成部分。然而,拥塞作为隐式可达性模型是粗糙的,并不总是准确的。同时,HPWL 作为线长的代表也会对真实目标产生偏差。这促使我们共同学习布局和布线任务,两者都试图在实践中最小化线长。我们可以在 DeepPR 中采用任何布线方法,包括 RL 模型和经典布线器,将从布局任务得到的网表分解为引脚到引脚的布线问题后确定方向。然后将总线长作为情景奖励,分别用于优化布局和布线代理的两个任务。这种联合学习模式的优势是双重的。一方面,布局方案为布线代理提供了丰富的训练数据,而不是以往工作中使用的随机生成数据,缺乏对真实领域数据分布的建模;另一方面,路径为分配代理提供了一个直接的优化目标,从而减轻了对中间成本模型的需求,减少了奖励信号的偏差。
相关文章:
[读论文] On Joint Learning for Solving Placement and Routing in Chip Design
0. Abstract 由于 GPU 在加速计算方面的优势和对人类专家的依赖较少,机器学习已成为解决布局和布线问题的新兴工具,这是现代芯片设计流程中的两个关键步骤。它仍处于早期阶段,存在一些基本问题:可扩展性、奖励设计和端到端学习范…...

L2-1 插松枝
L2-1 插松枝 分数 25 全屏浏览题目 切换布局 作者 陈越 单位 浙江大学 人造松枝加工场的工人需要将各种尺寸的塑料松针插到松枝干上,做成大大小小的松枝。他们的工作流程(并不)是这样的: 每人手边有一只小盒子,初始…...

Android 使用ContentObserver监听SettingsProvider值的变化
1、Settings原理 Settings 设置、保存的一些值,最终是存储到 SettingsProvider 的数据库 例如: Settings.Global.putInt(getContentResolver(), "SwitchLaunch", 0); Settings.System.putInt(getContentResolver(), "SwitchLaunch&quo…...
二进制安装部署k8s
概要 常见的K8S按照部署方式 minikube 是一个工具,可以在本地快速运行一个单节点微型K8S,仅用于学习,预习K8S的一些特性使用。 Kubeadmin kubeadmin也是一个工具,特工kubeadm init 和kubedm join,用于快速部署k8s…...
多输入多输出 | Matlab实现k-means-ELM(k均值聚类结合极限学习机)多输入多输出组合预测
多输入多输出 | Matlab实现k-means-ELM(k均值聚类结合极限学习机)多输入多输出组合预测 目录 多输入多输出 | Matlab实现k-means-ELM(k均值聚类结合极限学习机)多输入多输出组合预测预测效果基本描述程序设计参考资料 预测效果 基…...

ITSource 分享 第5期【校园信息墙系统】
项目介绍 本期给大家介绍一个 校园信息墙 系统,可以发布信息,表白墙,分享墙,校园二手买卖,咨询分享等墙信息。整个项目还是比较系统的,分为服务端,管理后台,用户Web端,小…...
记 : CTF2023羊城杯 - Reverse 方向 Blast 题目复现and学习记录
文章目录 前言题目分析and复习过程exp 前言 羊城杯题目复现: 第一题 知识点 :DES算法 : 链接:Ez加密器 第二题 知识点 :动态调试 : 链接:CSGO 这一题的查缺补漏: 虚假控制流的去除…...

【数据结构练习题】删除有序数组中的重复项
✨博客主页:小钱编程成长记 🎈博客专栏:数据结构练习题 🎈相关博文:消失的数字 — 三种解法超详解 删除有序数组中的重复项 1.🎈题目2. 🎈解题思路3. 🎈具体代码🎇总结 1…...
leetcode-链表
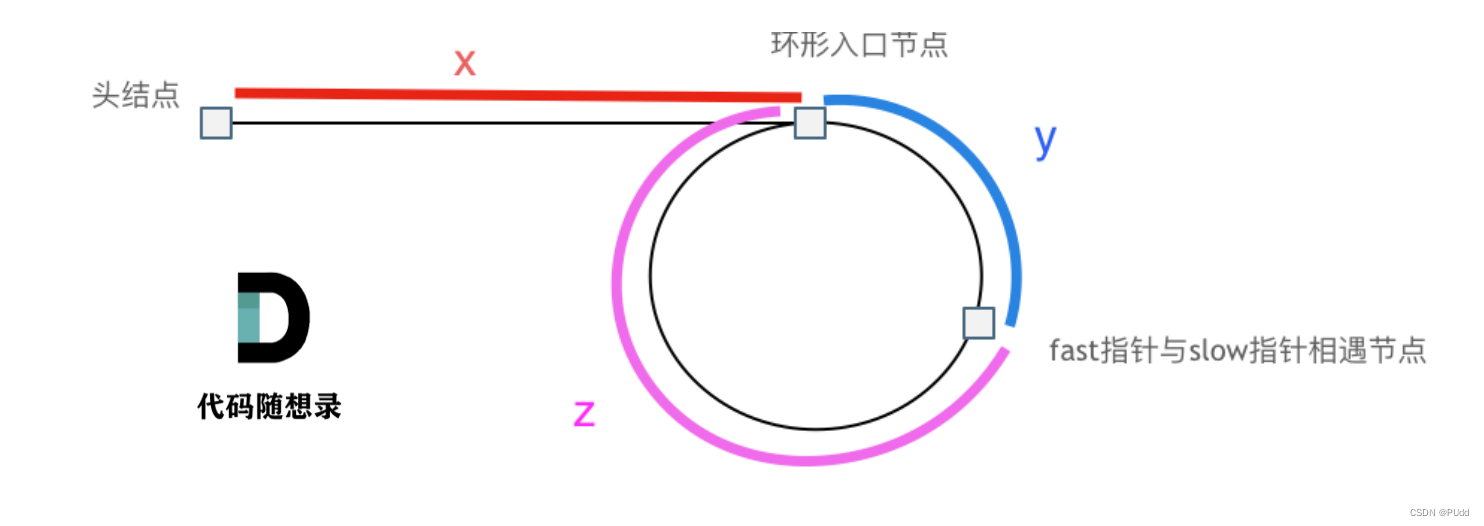
链表是一个用指针串联起来的线性结构,每个结点由数据域和指针域构成,指针域存放的是指向下一个节点的指针,最后一个节点指向NULL,第一个结点称为头节点head。 常见的链表有单链表、双向链表、循环链表。双向链表就是多了一个pre指…...
CV计算机视觉每日开源代码Paper with code速览-2023.10.27
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货 论文已打包,点击进入—>下载界面 点击加入—>CV计算机视觉交流群 1.【基础网络架构:Transformer】(Ne…...
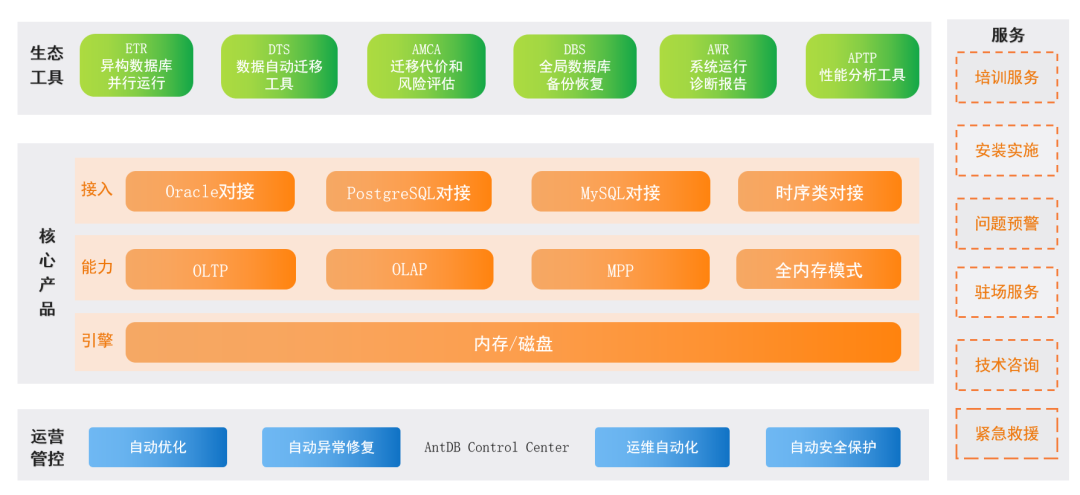
“赋能信创,物联未来” AntDB数据库携高可用解决方案亮相2023世界数字经济大会
10月14日,在2023世界数字经济大会暨京甬信创物联网产融对接会上,AntDB数据库技术总监北陌应邀发表《AntDB国产分布式数据库创新演进与高可用解决方案》主题演讲,就AntDB数据库助力客户数智化升级的高可用信创解决方案进行了详实、真挚地分享&…...
Kitex踩坑 [Error] KITEX: processing request error,i/o timeout
报错问题 2023/010/28 17:20:10.250768 default_server_handler.go:234: [Error] KITEX: processing request error, remoteService, remoteAddr127.0.0.1:65425, errordefault codec read failed: read tcp 127.0.0.1:8888->127.0.0.1:65425: i/o timeout 分析原因 Hert…...

前端移动web高级详细解析二
移动 Web 第二天 01-空间转换 空间转换简介 空间:是从坐标轴角度定义的 X 、Y 和 Z 三条坐标轴构成了一个立体空间,Z 轴位置与视线方向相同。 空间转换也叫 3D转换 属性:transform 平移 transform: translate3d(x, y, z); transform…...

Cesium 展示——对每段线、点、label做分组实体管理
文章目录 需求分析需求 对多组实体的管理,每组实体中包含多个点和一条线,并可对该组进行删除操作 分析 删除操作中用到了 viewer.entities.remove(radarEntity); 根据ID获取实体var radar = viewer.entities.getById(radar); viewer.entities.remove(radar );...

前端学习之Babel转码器
前言 Babel转码器可以将ES6转为ES5代码,从而在老版本的浏览器运行。这说明你可以用ES6的方式编码,又不用担心现有环境是否支持。 浏览器支持性查看:https://caniuse.com/ Babel官网:https://babeljs.io/ Babel安装流程 安装Babe…...

智能井盖监测系统功能,万宾科技传感器效果
智能井盖传感器的出现是高科技产品的更新换代,同时也是智慧城市建设中的需求。在智慧城市建设过程之中,高科技产品的应用数不胜数,智能井盖传感器的出现,解决了城市道路安全保护着城市地下生命线,改善着传统井盖带来的…...

LangChain+LLM实战---BERT主要的创新之处和注意力机制中的QKV
BERT主要的创新之处 BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer架构的预训练语言模型,由Google在2018年提出。它的创新之处主要包括以下几个方面: 双向性(Bidirectional&…...
)
使用 @antfu/eslint-config 配置 eslint (包含兼容uniapp方法)
安装 pnpm i -D eslint antfu/eslint-config创建 eslint.config.js 文件 // 如果没有在 page.json 配置 "type": "module" const antfu require(antfu/eslint-config).default module.exports antfu()// 配置了 "type": "module" …...
我的架构复盘
1、背景 我目前公司研发中心担任软件研发负责人,研发中心分为3组,总共有30多人。研发中心主要开发各类生产辅助工具,比如巡检、安全教育等系统。系统不对外,只在公司内部使用。 就我个人来说,作为研发负责人…...

LangChain+LLM实战---LangChain中的6大核心模块
模型(Models) LLMs 大型语言模型,将文本字符串作为输入,并返回文本字符串作为输出。 聊天模型 聊天模型通常由语言模型支持,但它们的API更加结构化。这些模型将聊天消息列表作为输入,并返回聊天消息。 文本…...

网页视频抓取终极指南:猫抓工具让你轻松收藏全网精彩内容
网页视频抓取终极指南:猫抓工具让你轻松收藏全网精彩内容 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 还在为网页上的精彩视频无法保…...

手机和电脑怎样换背景颜色?2026 年最全操作指南来了
想要轻松改变设备背景颜色却不知道从何下手?无论你用的是手机还是电脑,换背景颜色其实比你想象的要简单得多。本篇文章将为你详细介绍各种设备和软件上的背景颜色更换方法,帮你快速掌握这项基础操作技能。手机换背景颜色操作方法完全指南iOS …...

告别Excel人工统计!学生考勤自动分析系统搭建实录
实验背景 本实验基于“数智教育”大赛数据集,设计并实现学生多维度考勤统计转换流,目标是掌握ETL数据处理全过程,包括数据接入、数据清洗、多表关联、字段衍生、指标聚合以及结果落地等核心技能,完成学生考勤主题标签构建任务&am…...

预训练模型技术演进史:从Word2Vec到多模态大模型
1. 项目概述:这本“沙滩读物”到底在讲什么? “Beach Reading: a Short History of Pre-Trained Models”——光看标题,你可能会以为这是本躺在夏威夷躺椅上、椰子水还没喝完就能翻完的轻松小册子。但别被“Beach Reading”这个温柔前缀骗了。…...

解决VMware安装macOS后分辨率锁死的烦恼:手把手教你安装VMware Tools并自定义显示设置
突破VMware中macOS显示限制:从工具安装到完美适配的全流程指南 当你在VMware中成功安装macOS系统后,可能会立刻遇到一个令人沮丧的问题——屏幕分辨率被锁定在低分辨率状态,窗口无法自由缩放,操作体验大打折扣。这种显示限制不仅…...

ConstraintLayout的‘隐藏技巧’:用百分比、比例和GoneMargin搞定复杂UI适配
ConstraintLayout高级适配技巧:百分比、比例与动态隐藏视图的完美解决方案 在Android开发中,ConstraintLayout已经成为构建复杂界面的首选布局方式。但许多开发者仅仅停留在基础使用层面,未能充分发挥其强大的适配能力。本文将深入探讨三个关…...

如何在Windows上实现高效屏幕标注:gInk免费工具完全指南
如何在Windows上实现高效屏幕标注:gInk免费工具完全指南 【免费下载链接】gInk An easy to use on-screen annotation software inspired by Epic Pen. 项目地址: https://gitcode.com/gh_mirrors/gi/gInk 你是否需要在演示时快速圈出重点,或在线…...

观察Taotoken在不同网络环境下API调用的延迟表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在不同网络环境下API调用的延迟表现 在将大模型API集成到实际应用时,网络环境是影响开发者体验的关键因素…...

3分钟解锁你的QQ音乐:这款macOS工具让加密格式秒变通用音频
3分钟解锁你的QQ音乐:这款macOS工具让加密格式秒变通用音频 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,…...

官方证书+创作基金等你拿|“AI绘童趣·童心创科普”庆六一活动正式启动!
为庆祝六一国际儿童节,守护青少年纯真的好奇心与想象力,百度文心大模型携手海豚出版社、天津人民出版社,共同推出“文心创作周六一特辑”,面向全国青少年及社会创作者发起“AI绘童趣童心创科普”青少年科普绘本创作活动。活动以ER…...