scrapy-redis分布式爬虫(分布式爬虫简述+分布式爬虫实战)
一、分布式爬虫简述
(一)分布式爬虫优势
1.充分利用多台机器的带宽速度
2.充分利用多台机器的ip地址

 (二)Redis数据库
(二)Redis数据库
1.Redis是一个高性能的nosql数据库
2.Redis的所有操作都是原子性的
3.Redis的数据类型都是基于基本数据结构,无需额外的抽象
4.Redis五种数据类型:string、hash、list、set、zset(sorted set)
(三)python操作redis数据库
1.终端:pip install redis
2.代码如下
import redis
db = redis.Redis(host="localhost", port="6379", decode_responses=True)# 如果用到相同的key值,可以自动修改
db.set("name", "Sam")
db.set("name2", "张三")print(db.get("name2"))# 多个值
db.mset({"k1":"v1","k2":"v2"})
print(db.mget("k1","k2","name2"))# hash
db.hset("hash1","hkey1","hvalue1")
db.hset("hash1","hkey2","hvalue2")
db.hset("hash1","hkey3","hvalue3")print(db.hget("hash1","hkey2"))
print(db.hgetall("hash1"))db.lpush("list1",11,22,33)
print(db.llen("list1"))
print(db.lrange("list1",0,-1))db.sadd("set1", 55, 44 ,77)
print(db.scard("set1"))
print(db.smembers("set1"))db.zadd("zset1",{"item1":1,"item2":2,"item3":2})
print(db.zcard("zset1"))
print(db.zrange("zset1",0,-1))
print(db.zrange("zset1",0,-1,withscores=True))(四)Redis数据保存至mongodb数据库
import redis
import pymongo
import jsondb_redis = redis.Redis(host="localhost", port="6379", decode_responses=True)client_mongo = pymongo.MongoClient("mongodb://localhost:27017")
db_mongo = client_mongo["RedisToMongo"]
col_mongo = db_mongo["C1"]for i in db_redis.lrange("app:items", 0 -1):page = {"title":json.loads(i)["title"]}res = col_mongo.insert_one(page)print(res.inserted_id)二、分布式爬虫实战
实现一个简单的分布式:
1.创建爬虫项目和文件同scrapy一样的步骤
2.修改settings.py文件中的user-agent、robotstxt_obey、log_level、打开注释掉的item_piplines
3.终端安装scrapy-redis:pip install scrapy-redis
4.在app.py文件中修改如下代码:
import scrapy
from ..items import C07L07Item
from scrapy_redis.spiders import RedisSpiderclass AppSpider(RedisSpider):name = "app"redis_key = "app"# start_urls = ["http://127.0.0.1:5000/C07L07"]def __init__(self, *args, **kwargs):domain = kwargs.pop("domain","")self.allowed_domains = filter(None, domain.split(","))super(AppSpider, self).__init__(*args, **kwargs)def parse(self, response):links = response.xpath('//a/@href').getall()for link in links:link = "http://127.0.0.1:5000"+linkyield scrapy.Request(url=link,callback=self.parse_details, dont_filter=True)def parse_details(self, response):item = C07L07Item()item["title"] = response.textyield item在items.py文件中修改数据结构
import scrapyclass C07L07Item(scrapy.Item):title = scrapy.Field()在pipelines.py文件中修改代码
from itemdapter import ItemAdapterclass C07L07Pipeline:def process_item(self, item, spider):print(item["title"])return item5.在settings.py文件中添加如下代码,修改ITEM_PIPELINES
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = TrueREDIS_URL = "redis://127.0.0.1:6379"
DOWNLOAD_DELAY = 1ITEM_PIPELINES = {"C07LO7.pipelines.C07LO7Pipeline":300,"scrapy_redis.pipelines.RedisPipeline":400
}6.在终端链接redis数据库:redis-cli
lpush app http://127.0.0.1:5000/C07L07
7.运行爬虫代码:scrapy crawl app(可以开多进程)
相关文章:
scrapy-redis分布式爬虫(分布式爬虫简述+分布式爬虫实战)
一、分布式爬虫简述 (一)分布式爬虫优势 1.充分利用多台机器的带宽速度 2.充分利用多台机器的ip地址 (二)Redis数据库 1.Redis是一个高性能的nosql数据库 2.Redis的所有操作都是原子性的 3.Redis的数据类型都是基于基本数据…...

单目深度估计之图像重构原理解析
一、参考资料 浅析自监督深度估计中的光度损失(Photometric Loss) 二、图像重构原理 设输入位姿估计网络的3帧连续单目序列为 < I t − 1 , I t , I t 1 > <I_{t-1},I_{t},I_{t1}> <It−1,It,It1>,其中 t t t 为时间索引,…...
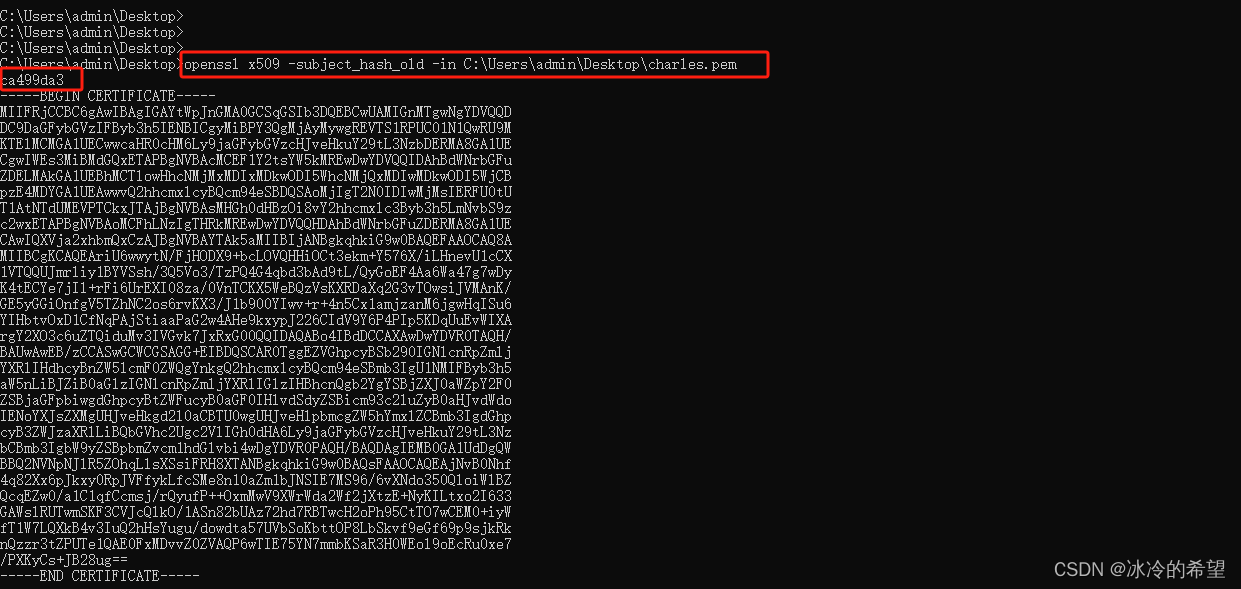
【爬虫】charles手机抓包环境设置(设置系统证书)
1.说明 想要对手机抓包,最关键的是需要设置好根证书,用户证书在安卓7.0之后就不受信任了,想要对手机app抓包,就需要把用户证书设置为系统证书(根证书) 注意,想要设置为根证书,你的…...

【flink sql table api】时间属性的指定与使用注意事项
文章目录 一. 时间属性介绍二. Table api指定时间属性三. 处理时间的指定1. 在创建表的 DDL 中定义2. 在 DataStream 到 Table 转换时定义3. 使用 TableSource 定义 四. 事件时间的指定1. 在 DDL 中定义2. 在 DataStream 到 Table 转换时定义3. 使用 TableSource 定义 五. 小结…...
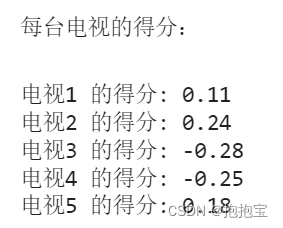
评价模型:CRITIC客观赋权法
目录 1.算法原理介绍2.算法步骤2.1 数据标准化2.2 计算信息承载量2.3 计算权重和得分 3.案例分析 1.算法原理介绍 CRITIC方法是一种客观权重赋权法,其基本思路是确定指标的客观权数以两个基本概念为基础。一是对比强度,它表示同一指标各个评价方案取值差…...

两个Tomcat插件配置不同端口,session冲突,同时登录被挤下线问题的解决
如果是配置了两个Tomcat的插件,在同一ip有两个需要同时登录的项目,可以在其中一个web项目的web.xml文件里添加session命名的配置,如下: <!--配置不同的session,避免管理端和手机端两个同时登录被挤下线--><se…...

Mybatis中执行Sql的执行过程
MyBatis中执行SQL的过程可以分为以下几个步骤: 解析配置文件:在运行时,MyBatis会加载并解析配置文件(通常为mybatis-config.xml),获取数据库连接信息、映射文件等。 创建SqlSessionFactory:MyB…...

IEEE Standard for SystemVerilog—Chapter 25.7 Tasks and functions in interfaces
子例程(任务和函数)可以在接口中定义,也可以在连接的一个或多个模块中定义。这允许更抽象的建模级别。例如,“读”和“写”可以定义为任务,而不需要引用任何连线,主模块只能调用这些任务。在modport中&…...

一台服务器最大能支持多少条 TCP 连接
文章目录 1. 一台服务器最大能打开的文件数1.1 限制参数1.2 调整服务器能打开的最大文件数示例 2. 一台服务器最大能支持多少连接3. 一台客户端机器最多能发起多少条连接4. 其他5. 相关实际问题5.1 "too many open files" 报错是怎么回事,该如何解决5.2 一…...

Qt重定向QDebug,Qt/C++开源作品39-日志输出增强版V2022
Qt重定向QDebug,自定义一个简易的日志管理类 Chapter1 Qt重定向QDebug,自定义一个简易的日志管理类0.前言1.最简单的操作运行结果2.实现一个简易的日志管理类 Chapter2 Qt::Qt Log日志模块Qt Log日志模块官方解释官方Demo思路 Chapter3 QT日志模块的个性…...

linux入门---多线程的控制
目录标题 线程库pthread_create如何一次性创建多个线程线程的终止线程的等待线程取消分离线程如何看待其他语言支持的多线程线程id的本质线程的局部存储线程的封装 线程库 要想控制线程就得使用原生线程库也可以将其称为pthread库,这个库是遵守posix标准的…...
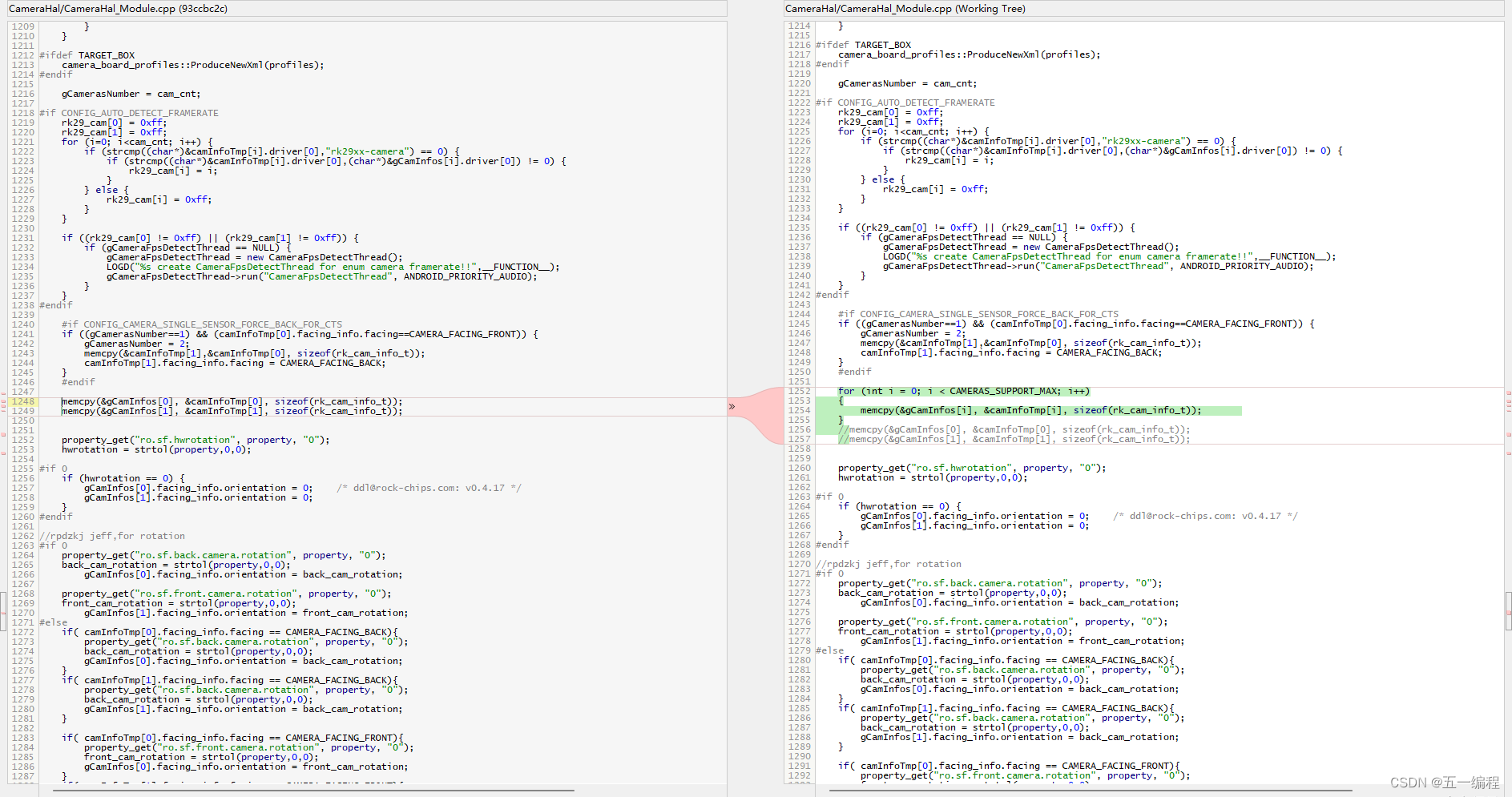
基于android的 rk3399 同时支持多个USB摄像头
基于android的 rk3399 同时支持多个USB摄像头 一、前文二、CameraHal_Module.h三、CameraHal_Module.cpp四、编译&烧录Image五、App验证 一、前文 Android系统默认支持2个摄像头,一个前置摄像头,一个后置摄像头 需要支持数量更多的摄像头࿰…...
【Qt之控件QTreeView】设置单元格高度、设置图标尺寸
设置列宽 设置高度 自定义代理 继承QItemDelegate,实现sizeHint ()方法,设置自定义委托。 class itemDelegate : public QItemDelegate {Q_OBJECTpublic:explicit itemDelegate(QObject *parent 0) : QItemDelegate(parent){}~itemDelegate(){}virtua…...
)
力扣42.接雨水(java,暴力法、前缀和解法)
Problem: 42. 接雨水 文章目录 思路解题方法复杂度Code 思路 要能接住雨水,感性的认知就是要形成一个“下凹区域”,则此时我们就要比较当前柱子和其左右柱子高度的关系,易得一个关键的式子:当前小区域的积水 min(当前…...
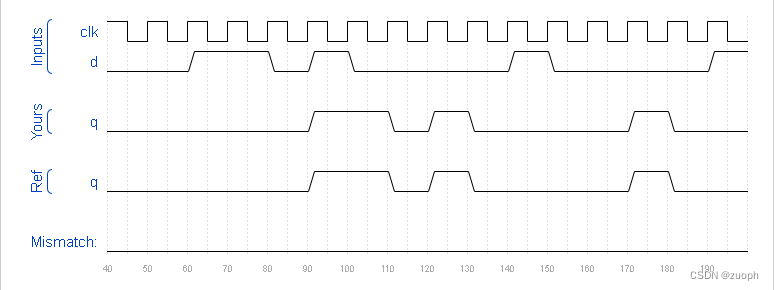
hdlbits系列verilog解答(移位寄存器)-23
文章目录 一、问题描述二、verilog源码三、仿真结果 一、问题描述 您将获得一个具有两个输入和一个输出的模块 my_dff (实现 D 触发器)。实例化其中的三个,然后将它们链接在一起以形成长度为 3 的移位寄存器。端口 clk 需要连接到所有实例。…...

Linux命令记载
服务器基本操作 SSH登录服务器 ssh -p 端口号 用户名服务器IP 输入密码SFTP上传文件 #输入密码 #使用get命令下载远程服务器的文件,比如/usr/test.txt sftp>get /usr/test.txt#使用put命令上传本地文件到服务器,比如/usr/test1.txt sftp> put /…...
Flume 快速入门【概述、安装、拦截器】
文章目录 什么是 Flume?Flume 组成Flume 安装Flume 配置任务文件应用示例启动 Flume 采集任务 Flume 拦截器编写 Flume 拦截器拦截器应用 什么是 Flume? Flume 是一个开源的数据采集工具,最初由 Apache 软件基金会开发和维护。它的主要目的是…...
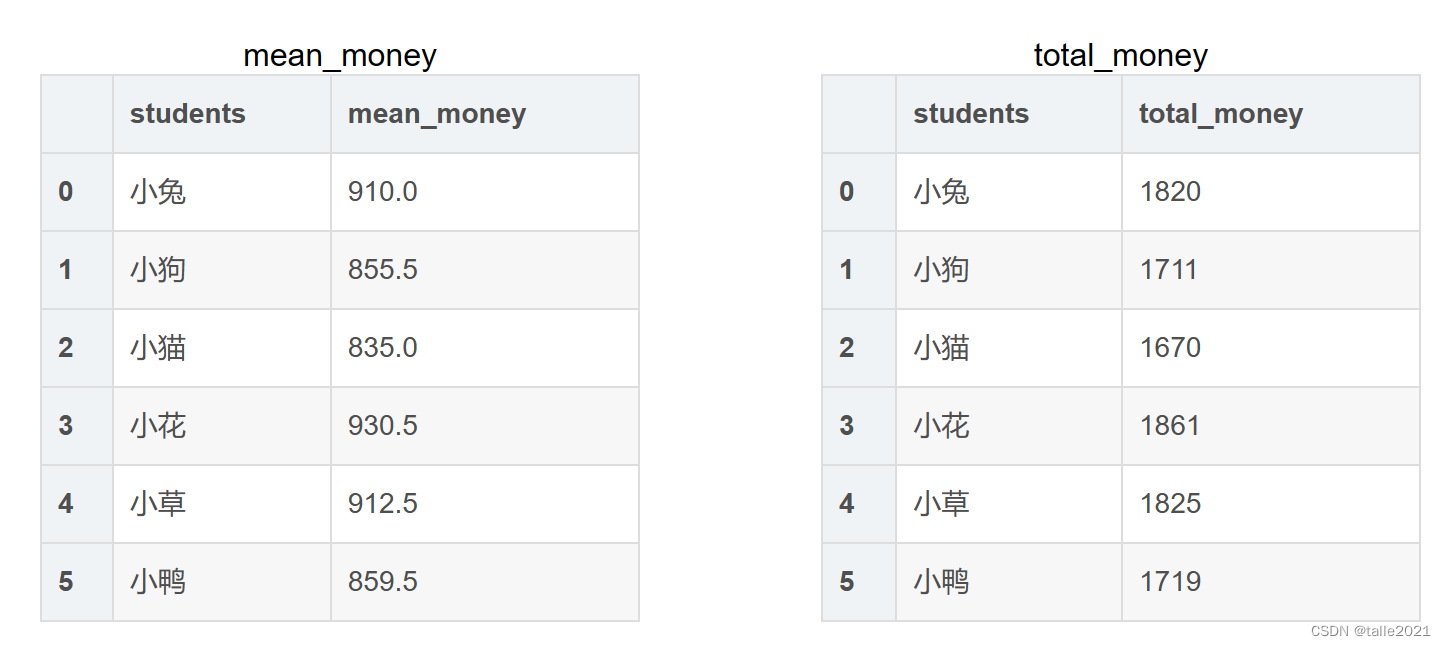
【pandas技巧】group by+agg+transform函数
目录 1. group by单个字段单个聚合 2. group by单个字段多个聚合 3. group by多个字段单个聚合 4. group by多个字段多个聚合 5. transform函数 studentsgradesexscoremoney0小狗小学部female958441小猫小学部male938362小鸭初中部male838543小兔小学部female909314小花小…...
一文解读WordPress网站的各类缓存-老白博客
缓存是一种重要的WordPress优化手段,用于提高网站的性能和加载速度。减少计算量,有效提升响应速度,让有限的资源服务更多的用户。本文老白博客便从自己的使用简单给大家介绍下WordPress的缓存,包括 站点缓存(Page Cach…...

从零开始:开发直播商城APP的技术指南
时下,直播商城APP已经成了线上购物、电子商务的核心组成,本文将为您提供一个全面的技术指南,帮助您从零开始开发一个直播商城APP。我们将涵盖所有关键方面,包括技术堆栈、功能模块、用户体验和安全性。 第一部分:技术…...

终极指南:三阶加速法让BT下载速度提升300%的完整方案
终极指南:三阶加速法让BT下载速度提升300%的完整方案 【免费下载链接】trackerslist Updated list of public BitTorrent trackers 项目地址: https://gitcode.com/GitHub_Trending/tr/trackerslist 你是否曾面对BT下载时缓慢如蜗牛、连接时断时续的困境&…...

防爆控制柜制造:从危险区域适配到电气安全的完整解析
一、什么是防爆控制柜制造?防爆控制柜制造,是指根据化工厂、石油化工、制药车间、喷涂车间、粉尘车间、油漆房、燃气站、危化品仓库、煤化工、粮食加工、木粉加工、新能源材料、电子化学品等存在爆炸性气体、蒸气或粉尘环境的场所需求,对防爆…...

终极指南:5分钟让Switch手柄在Windows上完美运行
终极指南:5分钟让Switch手柄在Windows上完美运行 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.com/gh_mi…...

Hello-Agents 第二部分-第九章总结:上下文工程
作者:逆境不可逃 技术永无止境 希望我的内容可以帮助到你!!!!! 大家吼 ! 我是 逆境不可逃 今天给大家带来文章《Hello-Agents 第二部分-第九章总结:上下文工程》. Hello-Agents 官方地址:data…...

【与我学 ClaudeCode】规划与协调篇 之 Skills:按需加载的领域知识框架
作者:逆境不可逃 技术永无止境 希望我的内容可以帮助到你!!!!! 大家吼 ! 我是 逆境不可逃 今天给大家带来文章《【与我学 ClaudeCode】规划与协调篇 之 Skills:按需加载的领域知识框架》. Lea…...

论文AI率90%熬夜怎么办?2026年5招实测,一次过知网维普AIGC
2025 年 12 月 25 日知网 AIGC 检测系统升级,2026 年 4 月 27 日维普 AI 率检测平台升级…2026 毕业季,各大主流 AIGC 检测软件陆续升级系统,识别 AI 痕迹更加精准。 临近毕业,同学们看者飘红的 AIGC 检测报告、纷繁复杂的降 AI 系…...

Bpmn Process Designer性能优化指南:大型流程图的渲染与交互优化
Bpmn Process Designer性能优化指南:大型流程图的渲染与交互优化 【免费下载链接】bpmn-process-designer bpmn-js 工具库 项目地址: https://gitcode.com/gh_mirrors/bp/bpmn-process-designer Bpmn Process Designer是一款基于bpmn-js的强大流程设计器工具…...

脉冲神经网络SNN工程落地全链路指南:从LIF建模到边缘部署
1. 这不是又一本“神经网络入门”——它是一份面向真实研究与工程落地的脉冲神经网络实操手记“Spiking Neural Networks”(SNN)这个词,过去十年里在学术会议海报上出现的频率,几乎和咖啡渍在论文草稿边缘的扩散速度一样快。但如果…...

实战指南:5个关键技术揭秘PUBG罗技鼠标宏后坐力控制脚本
实战指南:5个关键技术揭秘PUBG罗技鼠标宏后坐力控制脚本 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg logitech-pubg是一个针对《绝…...
ascend-transformer-boost:Transformer加速库架构原理剖析
前言 我第一次在昇腾NPU上跑Llama-2-7B推理时,用的是PyTorch原生实现,跑出来的吞吐是18 tokens/s,跟官方宣称的29 tokens/s差了快一倍。翻了一圈文档,发现昇腾CANN其实自带了一个Transformer加速库——ascend-transformer-boost&a…...