SQL SERVER 表分区
1. 概要说明
SQL SERVER的表分区功能是为了将一个大表(表中含有非常多条数据)的数据根据某条件(仅限该表的主键)拆分成多个文件存放,以提高查询数据时的效率。创建表分区的主要步骤是
1、确定需要以哪一个字段作为分区条件;
2、拆分成多少个文件保存该表;
3、分区函数(拆分条件);
4、分区方案(按拆分函数拆分后需要对应到哪些文件组中去)。
不是企业版的sql server不支持分区;
参考:SQL SERVER 表分区实施步骤_sqlserver表分区步骤_Henry_Wu001的博客-CSDN博客
sql server 分区表 性能 sqlserver分区表实战_mob6454cc77db30的技术博客_51CTO博客
(0.1)SQL Server分区介绍
在SQL Server中,数据库的所有表和索引都视为已分区表和索引,默认这些表和索引值包含一个分区;也就是说表或索引至少包含一个分区。SQL Server中数据是按水平方式分区,是多行数据映射到单个分区。已经分区的表或者索引,在执行查询或者更新时,将被看作为单个逻辑实体;简单说来利用分区将一个表数据分多个表来存储,对于大数据量的表,将表分成多块查询,若只查询某个分区数据将降低消耗提高效率。需要注意的是单个索引或者表的分区必须位于一个数据库中。在使用大量数据管理时,SQL Server使用分区可以快速访问数据子集,减少io提高效率。
同时不同分区可以存放在不同文件组里,文件组若能存放在不同逻辑磁盘上,则可以实现io的并发使用以提高效率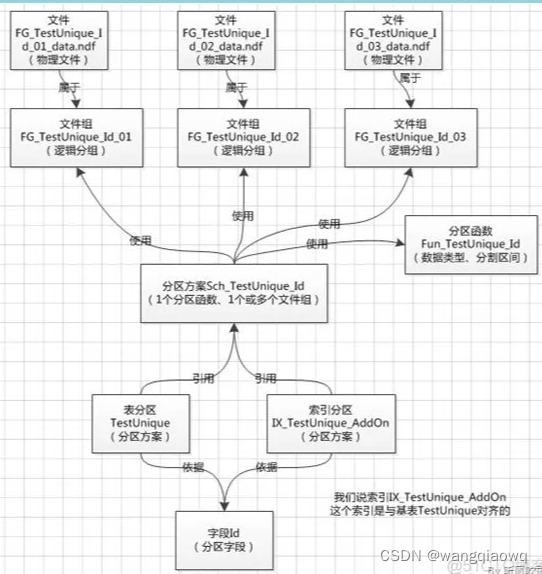
(0.2)SQL Server分区创建概述
创建分区函数:确定分区方式和界点
创建分区架构:将分区函数指定的分区映射到文件组
新建分区表
索引分区知识详解
(0.3)SQL Server分区管理概述
拆分分区(split)
合并分区(merge)
切换分区(switch)
$PARTION
【1】创建表分区
未分区的表,相当于只有一个分区,只能存储在一个FileGroup中;对表进行分区后,每一个分区都存储在一个FileGroup,或分布式存储在不同的FileGroup中。对表进行分区的过程,实际上是将逻辑上完整的一个表,按照特定的字段拆分成多个分区,分散到相同或不同的FileGroup中,每一个部分叫做表的一个分区(Partition),一个分区实际上是一个独立的,内部的物理表。也就是说,分区表在逻辑上是一个表,而在物理上是多个完全独立的表。
分区(Partition)的特性是:
每一个Partition在FileGroup中都独立存储,分区之间是相互独立的
每一个parititon都属于唯一的表对象,
每一个Partition 都有唯一的ID,
每一个Partition都有一个编号(Partition Number),同一个表的分区编号是唯一的,从1开始递增;
Step0,准备工作:构建文件组和文件
登录后复制
--添加文件组
alter database testSplit add filegroup db_fg1
--添加文件到文件组
alter database testSplit add file
(name=N'ById1',filename=N'J:\Work\数据库\data\ById1.ndf',size=5Mb,filegrowth=5mb)
to filegroup db_fg1
一,新建分区表分为三步
Step1, 创建分区函数
要先创建函数
分区函数的作用是提供分区字段的类型和分区的边界值,进而决定分区的数量
CREATE PARTITION FUNCTION [pf_int](int)
AS RANGE LEFT
FOR VALUES (10, 20)
分区函数pf_int 的含义是按照int类型分区,分区的边界值是10,20,left表示边界值属于左边界。两个边界值能够分成三个分区,别是(-infinite,10],(10,20],(20,+infinite)。
Step2,创建分区架构(Scheme)
再创建架构、应用函数
分区架构的作用是为Parition分配FileGroup,在逻辑上,Partition Scheme和FileGroup是等价的,都是数据存储的逻辑空间,只不过Partition Scheme指定的是多个FileGroup。
CREATE PARTITION SCHEME [ps_int]
AS PARTITION [pf_int]
TO ([PRIMARY], [db_fg1], [db_fg1])
不管是在不同的FileGroup中,还是在相同的FileGroup中,分区都是独立存储的。
分区scheme的所有分区都存储到相同的文件组中:
CREATE PARTITION SCHEME [ps_int]
AS PARTITION [pf_int]
ALL TO ([PRIMARY])
Step3,新建分区表
新建分区表,实际上是在创建Table时,使用on子句指定数据存储的逻辑位置是分区架构(Partition Scheme)
create table dbo.dt_test
(
ID int,
code int
)
on [ps_int] (id)
查看分区编号(Partition Number)
分区编号(Partition Number) 从1开始,从最左边的分区向右依次递增+1,边界值最小的分区编号是1,
例如,对于以下分区函数:
CREATE PARTITION FUNCTION pf_int_Left (int)
AS
RANGE LEFT
FOR VALUES (10,20);
分区的边界值(Boundary Value)是10,20, 边界值属于左边界(Range Left),该分区函数 pf_int_Left 划分了三个分区(Partition),范围区间是:(-infinite,10], (10,20], (20,+infinite),(小括号表示不包括边界值,中括号表示包括边界值),系统分配的分区编号分别是:1,2,3。用户可以通过使用$Partition函数 查看分区编号,调用语法格式是:
$Partition.Partition_Function(Partition_Column_Value)
例如,通过$Partition函数 查看分区列值为21时,该行数据所在的分区编号:
select $Partition.pf_int_left(21)
由于分区列值是21, 属于范围(20,+infinite),因此分区编号是:3。
【2】对现有表分区
在SQL Server中,普通表可以转化为分区表,而分区表不能转化为普通表,普通表转化成分区表的过程是不可逆的,将普通表转化为分区表的方法是:
在分区架构(Partition Scheme)上创建聚集索引,就是说,将聚集索引分区。
数据库中已有分区函数(partition function) 和分区架构(Partition scheme):
-- create parition function
CREATE PARTITION FUNCTION pf_int_Left (int)
AS RANGE LEFT
FOR VALUES (10,20);
--determine partition number
select $Partition.pf_int_left(21)
CREATE PARTITION SCHEME PS_int_Left
AS PARTITION pf_int_Left
TO ([primary], [primary], [primary]);
如果在普通表上存在聚集索引,并且聚集索引列是分区列,那么重建聚集索引,就能使表转化成分区表。聚集索引的创建有两种方式:使用clustered 约束(primary key 或 unique约束)创建,使用 create clustered index 创建。
【2.1】在分区架构(Partition Scheme)上,创建聚集索引
如果聚集索引是使用 create clustered index 创建的,并且聚集索引列就是分区列,使普通表转换成分区表的方法是:删除所有的 nonclustered index,在partition scheme上重建clustered index
1,表dbo.dt_partition的聚集索引是使用 create clustered index 创建的,
create table dbo.dt_partition
(
ID int,
Code int
)
create clustered index cix_dt_partition_ID
on dbo.dt_partition(ID)
2,从系统表Partition中,查看该表的分区只有一个
select *
from sys.partitions p
where p.object_id=object_id(N'dbo.dt_partition',N'U')
3,使用partition scheme,重建表的聚集索引
create clustered index cix_dt_partition_ID
on dbo.dt_partition(ID)
with(drop_existing=on)
on PS_int_Left(ID)
4,重建聚集索引之后,表的分区有三个
select *
from sys.partitions p
where p.object_id=object_id(N'dbo.dt_partition',N'U')
【2.4】普通表=》分区表,不可逆
普通表转化成分区表的过程是不可逆的,普通表能够转化成分区表,而分区表不能转化成普通表。
普通表存储的Location是FileGroup,分区表存储的Location是Partition Scheme,在SQL Server中,存储表数据的Location叫做Data Space。
通过在Partition Scheme上创建Clustered Index ,能够将已经存在的普通表转化成partition table,但是,将Clustered index删除,表仍然是分区表,转化过程(将普通表转换成分区表)是不可逆的;
一个Partition Table 是不能转化成普通表的,即使通过合并分区,使Partiton Table 只存在一个Partition,这个表的仍然是Partition Table,这个Table的Data Space 是Partition Scheme,而不会转化成File Group。
从 sys.data_spaces 中查看Data Space ,共有两种类型,分别是FG 和 PS。
FG是File Group,意味着数据表的数据存储在File Group分配的存储空间,一个Table 只能存在于一个FileGroup中。PS 是Partition Scheme,意味着将数据分布式存储在不同的File Groups中,存储数据的File Group是根据Partition column值的范围来分配的。对于分区表,SQL Server从指定的File Group分配存储空间,虽然一个Table只能指定一个Partition Scheme,但是其数据却分布在多个File Groups中,这些File Groups由Partition Scheme指定,可以相同,也可以不同。
【3】分区切换
在SQL Server中,对超级大表做数据归档,使用select和delete命令是十分耗费CPU时间和Disk空间的;
SQL Server必须记录相应数量的事务日志,而使用switch操作归档分区表的老数据,十分高效,switch操作不会移动数据,只是做元数据的置换;
因此,执行分区切换操作的时间是非常短暂的,几乎是瞬间完成,但是,在做分区切换时,源表和靶表必须满足一定的条件:
表的结构相同:列的数据类型,可空性(nullability)相同;
索引结构必须相同:索引键的结构,聚集性,唯一性,列的可空性必须相同;
主键约束:如果源表存在主键约束,那么靶表必须创建等价的主键约束;
唯一约束:唯一约束可以使用唯一索引来实现;
索引键的结构:索引键的顺序,包含列,唯一性,聚集性都必须相同;
存储的数据空间(data space)相同:源表和靶表必须创建在相同的FileGroup或Partition Scheme上;
分区切换是将源表中的一个分区,切换到靶表(target_table)中,靶表可以是分区表,也可以不是分区表,switch操作的语法是:
ALTER TABLE schema_name . table_name
SWITCH [ PARTITION source_partition_number_expression ]
TO target_table [ PARTITION target_partition_number_expression ]
【3.2】源表和目标表的结构必须相同
1,数据列的可空性必须相同(nullability)
2,数据列的数据类型必须相同
1,数据列的可空性必须相同(nullability)
【3.5】交换分区:总结
在执行分区操作时,要求源表和靶表必须满足:
表的结构相同:列的数据类型,可空性(nullability)相同;
索引结构必须相同:索引键的结构,聚集性,唯一性,列的可空性必须相同;
主键约束:如果源表存在主键约束,那么靶表必须创建等价的主键约束;
唯一约束:唯一约束可以使用唯一索引来实现;
索引键的结构:索引键的顺序,包含列,唯一性,聚集性都必须相同;
存储的数据空间(data space)相同:源表和靶表必须创建在相同的FileGroup或Partition Scheme上;
(1)时间分区
代码:现有表转成分区表
-- 创建测试数据,测试表 part_test
use test1;
if object_id('part_test' ) is not null
drop table part_test;
;with t1 as (
select 1 as id,1 as num ,cast('2021-01-01 00:01:01' as datetime) as day_info
union all
select id+1 ,num+1 ,dateadd(day,1,day_info) from t1
where id<=1000000
)
select * into part_test from t1 option(maxrecursion 0)
-- 分区函数
CREATE PARTITION FUNCTION [pf_datetime](datetime)
AS RANGE LEFT for values(
'2021-01-01' ,
'2022-01-01' ,
'2023-01-01' ,
'2024-01-01' ,
'2025-01-01' ,
'2026-01-01' ,
'2027-01-01' ,
'2028-01-01' ,
'2029-01-01' ,
'2030-01-01' ,
'2031-01-01' ,
'2032-01-01' ,
'2033-01-01' ,
'2034-01-01' ,
'2035-01-01' ,
'2036-01-01' ,
'2037-01-01' ,
'2038-01-01' ,
'2039-01-01' ,
'2040-01-01' ,
'2041-01-01' ,
'2042-01-01' ,
'2043-01-01' ,
'2044-01-01' ,
'2045-01-01' ,
'2046-01-01' ,
'2047-01-01' ,
'2048-01-01'
);
-- 分区架构
CREATE PARTITION SCHEME [ps_datetime]
AS PARTITION [pf_datetime]
ALL TO ([PRIMARY])
-- 创建聚集索引和耳机索引
create clustered index PIX_id on part_test(id)
create index ix_dayinfo on part_test(day_info)
-- 查看是否还有二级索引
-- sp_help part_test
-- 删掉二级索引,重建聚集索引并应用分区架构
drop index ix_dayinfo on part_test
-- 重建聚集索引=》现有表改成分区表,分区列必须是在主键内,比如这里的 day_info 就必须在主键内
create clustered index PIX_id
on dbo.part_test(ID,day_info)
with(drop_existing=on)
on [ps_datetime](day_info)
--创建索引对齐分区索引
create index id_p_num on part_test(num) on [ps_datetime](day_info)
create index id_p_dayinfo on part_test(day_info) on [ps_datetime](day_info)
select * from part_test where day_info='2021-01-11 00:01:01.000'
-- 拆分分区(最末尾)
-- 在分区函数中新增一个边界值,即可将一个分区变为2个。一般边界值默认是 left ;放到最前或者最后来拆分就是新增分区
alter partition function pf_datetime()
split range('2049-01-01') --将第二个分区拆为2个分区
-- 归档到历史表
alter table bigorder switch partition 1 to <同表结构、默认值、null约束一致的表>
相关文章:
SQL SERVER 表分区
1. 概要说明 SQL SERVER的表分区功能是为了将一个大表(表中含有非常多条数据)的数据根据某条件(仅限该表的主键)拆分成多个文件存放,以提高查询数据时的效率。创建表分区的主要步骤是 1、确定需要以哪一个字段作为分…...
从零开始学习PX4源码0(固件下载及编译)
目录 文章目录目录摘要1.重点学习网址2.固件下载1.下载最新版本固件2.下载之前版本固件 摘要 本节主要记录从零开始学习PX4源码1(固件下载)的过程,欢迎批评指正!!! 下载固件主要分为两个版本,之前稳定版本和最新官网发布版本,为什么要下载两个版本,主要是说明两个版本有…...

centos格式化硬盘/u盘的分区为NTFS格式
centos7好像不支持ntfs? 对报这个,ntfs not configured in kernel。 安装了ntfs-3g就可以访问了。 插上u盘查看u盘设备 #查看硬件设备及挂载目录 df -h #查看硬件设备(包括未挂载的) fdisk -l卸载外部设备 umount /dev/sdbxxx …...

【工具】FreePic2PDF+PdgCntEditor|PDF批量添加书签(Windows)
这俩软件都不大,比较便携。 FreePic2PDF: 我下载的来源:https://www.52pojie.cn/thread-1317140-1-1.html(包含下载链接https://www.lanzoui.com/it4x6j4hbvc)下载的结果:https://pan.baidu.com/s/1r8n5G42…...
中移链浏览器简介
(1)简介 生活中,常用的互联网浏览器,是用来检索、展示以及传递Web信息资源的应用程序。用浏览器进行搜索,可以快速查找到目标信息。而对于区块链而言,也有区块链浏览器。 区块链浏览器,是指为用…...
深入浅出排序算法之计数排序
目录 1. 原理 2. 代码实现 3. 性能分析 1. 原理 首先看一个题目,有n个数,取值范围是 0~n,写出一个排序算法,要求时间复杂度和空间复杂度都是O(n)的。 为了达到这种效果,这一篇将会介绍一种不基于比较的排序方法。这…...

大坝水库安全监测终端MCU,智能化管理的新篇章!
我国目前拥有超过9.8万座水库大坝,其中超过95%为土石坝,这些大坝主要是在上世纪80年代以前建造的。这些水库大坝在保障防洪、发电、供水、灌溉等方面发挥了巨大的作用,但是同时也存在一定的安全风险,比如坝体结构破损、坝基渗漏、…...

LeetCode 面试题 16.09. 运算
文章目录 一、题目二、C# 题解 一、题目 请实现整数数字的乘法、减法和除法运算,运算结果均为整数数字,程序中只允许使用加法运算符和逻辑运算符,允许程序中出现正负常数,不允许使用位运算。 你的实现应该支持如下操作:…...
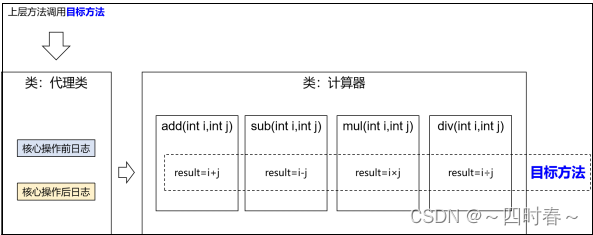
spring-代理模式
代理模式 一、概念1.静态代理2.动态代理 一、概念 ①介绍 二十三种设计模式中的一种,属于结构型模式。它的作用就是通过提供一个代理类,让我们在调用目标 方法的时候,不再是直接对目标方法进行调用,而是通过代理类间接调用。让不…...
我用好说 AI 做二次元人设
你有没有想过自己做一部原创作品? 就像开发《星露谷物语》那样,自己把控作品的 角色、故事、载体、宣传 等方方面面,让 idea 不再只是灵光一闪。 以前是 “万事开头难”,可能第一步都举步维艰。但现在有了 AI 就不同了ÿ…...

付费阅读微信小程序源码/小程序和公众号双版本-多种付费模式前后端+独立源码
源码简介: 付费阅读微信小程序源码,这个是小程序和公众号双版本,它支持多种付费模式前后端独立源码。能够支持免费观看部分文字、视频和音频内容,而其他部分则需要付费才能继续观看。这样更方便变现。 这是付费阅读微信小程序合…...

ref、reactive、toRef、toRefs
ref 作用:定义一个响应式数据 语法:const xxx ref(initValue) 创建一个包含响应式数据的引用对象 js中操作数据:xxx.value 模板中读取数据:不需要.value,直接<div>{{xxx}}</div> 接收的数据:基本类型、对…...

GPT实战系列-如何用自己数据微调ChatGLM2模型训练
GPT实战系列-如何用自己数据微调ChatGLM2模型训练 目录 GPT实战系列-如何用自己数据微调ChatGLM2模型训练1、训练数据广告文案生成模型训练和测试数据组织: 2、训练脚本3、执行训练调整运行 4、问题解决问题一问题二问题三问题四 1、训练数据 广告文案生成模型 输…...
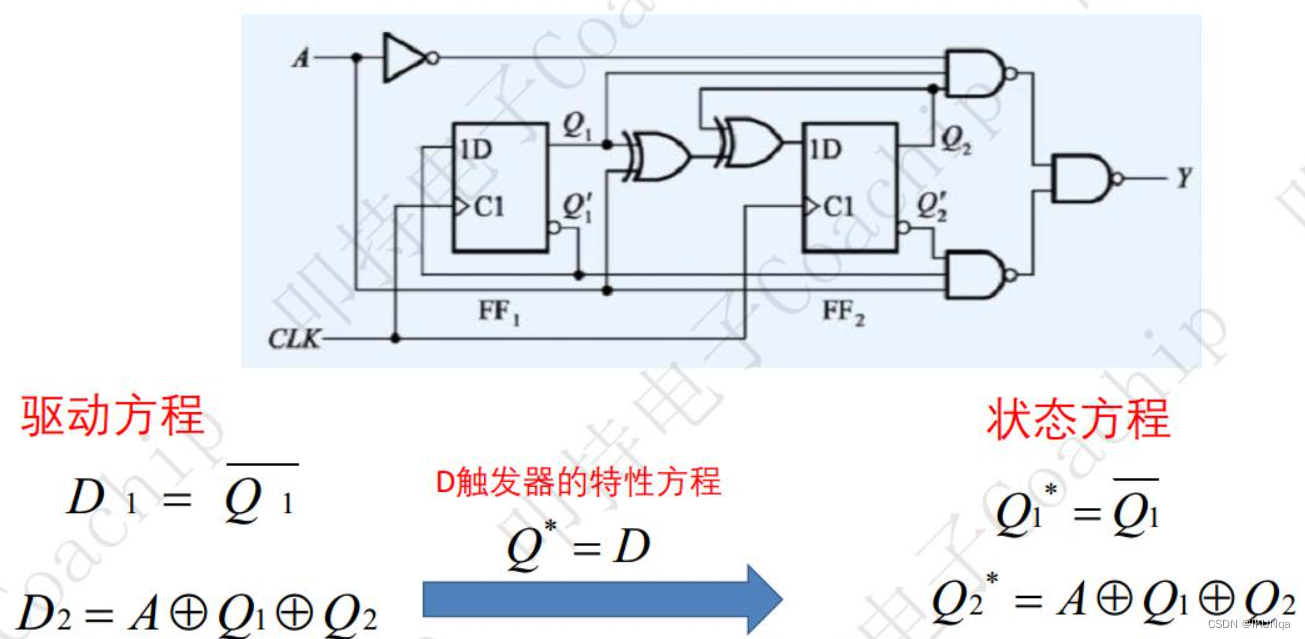
【数电知识点_2023.10.28】
数制与码制 十进制转二进制 8 bits 1 Byte 2|12 //121100自下而上 商为0为止 2|_ 6_…0 2|_ 3_…0 2|1…1 0…1 0.375 //0.3750.011自上而下 小数点为0为止 x 2 ———— 0.75…0 x 2 ———— 1.5…1 x 2 ———— 1…1 BCD码:每4位二进制表示一位十进制 8421…...
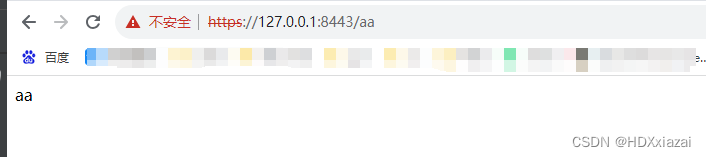
spring boot配置ssl(多cer格式)保姆级教程
1. 准备cer格式的证书; 2. 合并cer证书并转化成jks格式的证书 为啥有这一步,因为cer证书配置在spring boot项目中,项目启动不起来。如果有大佬想指导一下可以给我留言,在此先谢过大佬。 1)先创建一个jks格式的证…...
第2篇 机器学习基础 —(4)k-means聚类算法
前言:Hello大家好,我是小哥谈。聚类算法是一种无监督学习方法,它将数据集中的对象分成若干个组或者簇,使得同一组内的对象相似度较高,不同组之间的对象相似度较低。聚类算法可以用于数据挖掘、图像分割、文本分类等领域…...

【Python爬虫+可视化】解析小破站热门视频,看看播放量为啥会这么高!评论、弹幕主要围绕什么展开
大家早好、午好、晚好吖 ❤ ~欢迎光临本文章 如果有什么疑惑/资料需要的可以点击文章末尾名片领取源码 环境使用 Python 3.8 Pycharm 模块使用 import requests import csv import datetime import hashlib import time 一. 数据来源分析 明确需求 明确采集网站以及数…...

Mac电脑专业三维模型展UV贴图编辑工具RizomUV RS + VS 2023有哪些特点
RizomUV RS VS是一款功能强大的UV展开软件,用于在三维模型上创建和编辑UV贴图。它具有直观的用户界面和丰富的功能,能够帮助艺术家和设计师更高效地进行UV展开工作。 RizomUV RS VS支持多种模型格式,包括OBJ、FBX、DAE和3DS等,使…...

Linux文件描述符和文件指针互转
本文研究的主要是Linux中文件描述符fd与文件指针FILE*互相转换的相关内容,具体介绍如下。 简介 1.文件描述符fd的定义: 文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当…...
C++11线程
C11线程 创建线程 创建线程需要包含头文件<thread>,使用线程类std::thread 构造函数 默认构造函数 thread() noexcept; 默认构造函数,构造一个线程对象,但它不会启动任何实际的线程执行。 任务函数构造函数 template< class Fun…...

MySQL 8.3远程连接踩坑记:Navicat提示caching_sha2_password错误的完整修复流程
MySQL 8.3远程连接认证插件问题深度解析与实战修复指南 1. 问题现象与背景分析 那天下午,当我正尝试用Navicat Premium 16连接新部署的MySQL 8.3数据库时,屏幕上突然弹出的红色错误框让我的咖啡杯悬在了半空: Authentication plugin caching_…...

嵌入式软件定时器原理与实现:从硬件限制到多任务调度
1. 软件定时器:从硬件限制到软件自由的桥梁在嵌入式开发里,定时器是个绕不开的话题。无论是让LED灯定时闪烁,还是需要周期性地采集传感器数据,甚至是实现一个简单的按键消抖,都离不开定时功能。硬件定时器(…...

GNSS数据处理避坑指南:为什么你的PPP精度总上不去?可能是SP3和CLK文件用错了
GNSS数据处理避坑指南:为什么你的PPP精度总上不去?可能是SP3和CLK文件用错了 当你花费数小时运行PPP解算,却发现定位结果始终达不到预期精度时,那种挫败感我深有体会。作为从事高精度GNSS数据处理多年的工程师,我见过太…...
)
大模型查询质量评估新范式(Perplexity算法底层逻辑首次公开)
更多请点击: https://codechina.net 第一章:大模型查询质量评估新范式(Perplexity算法底层逻辑首次公开) Perplexity(困惑度)并非仅是语言模型训练阶段的监控指标,而是当前大模型查询质量评估中…...

3分钟高效掌握Python手机号查QQ号实用技巧
3分钟高效掌握Python手机号查QQ号实用技巧 【免费下载链接】phone2qq 项目地址: https://gitcode.com/gh_mirrors/ph/phone2qq 手机号查QQ号是现代社交网络管理中的一项实用技能,通过Python工具可以快速实现手机号与QQ号的关联查询。这个开源项目提供了一个…...

财务RPA只能自动执行吗?它还能结合大模型,进化成财务分析助手
提到财务RPA,多数人对它的认知还停留在“自动化工具”层面,能724小时不间断处理发票录入、凭证生成、银行对账等重复性财务工作,替代人工完成机械操作,实现“降本增效”。但事实上,随着大模型技术与财务场景的深度融合…...

使用 TaoToken CLI 工具一键配置多开发环境接入参数
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 TaoToken CLI 工具一键配置多开发环境接入参数 在团队协作或个人多项目开发中,为不同的 AI 应用工具配置 API 密钥…...

终极免费Windows音频调校指南:用Equalizer APO解锁专业音质
终极免费Windows音频调校指南:用Equalizer APO解锁专业音质 【免费下载链接】equalizerapo Equalizer APO mirror 项目地址: https://gitcode.com/gh_mirrors/eq/equalizerapo 你是否对电脑的音质总是不满意?无论是听音乐、看电影还是玩游戏&…...

从QRegExp迁移到QRegularExpression避坑全记录:我们项目踩过的雷和最佳实践
从QRegExp迁移到QRegularExpression避坑全记录:我们项目踩过的雷和最佳实践 当团队决定将代码库从Qt4/Qt5升级到Qt6时,正则表达式模块的迁移往往是最容易被低估的挑战之一。我们项目组在重构过程中,曾因QRegExp到QRegularExpression的语法差异…...

终极指南:3步解锁B站缓存视频播放自由
终极指南:3步解锁B站缓存视频播放自由 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 还在为B站缓存的m4s视频无法在其他播放器打开而…...