竞赛选题 深度学习图像修复算法 - opencv python 机器视觉
文章目录
- 0 前言
- 2 什么是图像内容填充修复
- 3 原理分析
- 3.1 第一步:将图像理解为一个概率分布的样本
- 3.2 补全图像
- 3.3 快速生成假图像
- 3.4 生成对抗网络(Generative Adversarial Net, GAN) 的架构
- 3.5 使用G(z)生成伪图像
- 4 在Tensorflow上构建DCGANs
- 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 深度学图像修复算法
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
2 什么是图像内容填充修复
内容识别填充(译注: Content-aware fill ,是 photoshop
的一个功能)是一个强大的工具,设计师和摄影师可以用它来填充图片中不想要的部分或者缺失的部分。在填充图片的缺失或损坏的部分时,图像补全和修复是两种密切相关的技术。有很多方法可以实现内容识别填充,图像补全和修复。
- 首先我们将图像理解为一个概率分布的样本。
- 基于这种理解,学*如何生成伪图片。
- 然后我们找到最适合填充回去的伪图片。

自动删除不需要的部分(海滩上的人)

最经典的人脸补充
补充前:

补充后:

3 原理分析
3.1 第一步:将图像理解为一个概率分布的样本
你是怎样补全缺失信息的呢?
在上面的例子中,想象你正在构造一个可以填充缺失部分的系统。你会怎么做呢?你觉得人类大脑是怎么做的呢?你使用了什么样的信息呢?
在博文中,我们会关注两种信息:
语境信息:你可以通过周围的像素来推测缺失像素的信息。
感知信息:你会用“正常”的部分来填充,比如你在现实生活中或其它图片上看到的样子。
两者都很重要。没有语境信息,你怎么知道填充哪一个进去?没有感知信息,通过同样的上下文可以生成无数种可能。有些机器学*系统看起来“正常”的图片,人类看起来可能不太正常。
如果有一种确切的、直观的算法,可以捕获前文图像补全步骤介绍中提到的两种属性,那就再好不过了。对于特定的情况,构造这样的算法是可行的。但是没有一般的方法。目前最好的解决方案是通过统计和机器学习来得到一个类似的技术。
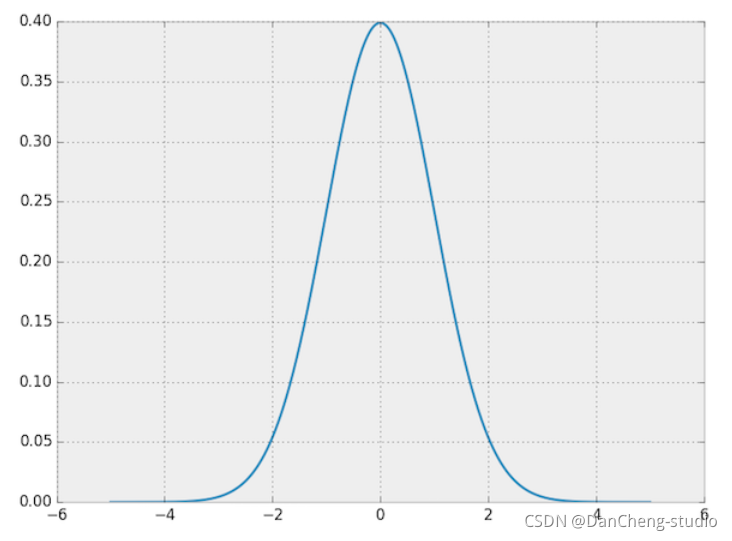
从这个分布中采样,就可以得到一些数据。需要搞清楚的是PDF和样本之间的联系。
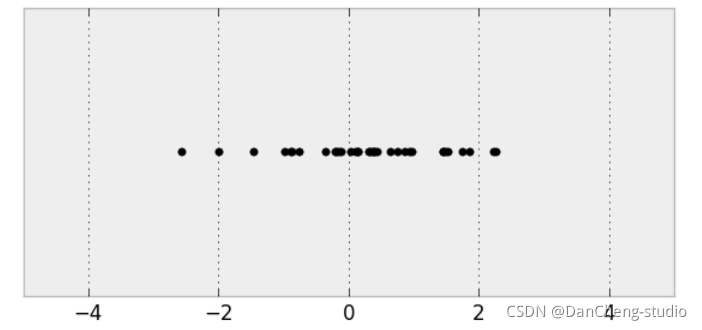
从正态分布中的采样
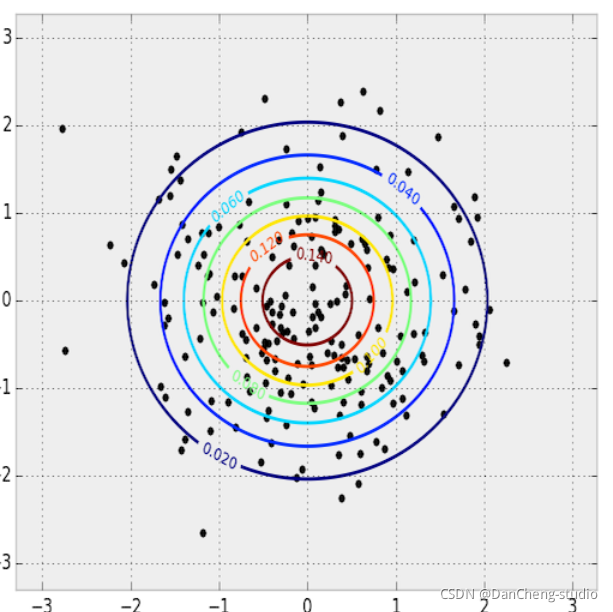
2维图像的PDF和采样。 PDF 用等高线图表示,样本点画在上面。
3.2 补全图像
首先考虑多变量正态分布, 以求得到一些启发。给定 x=1 , 那么 y 最可能的值是什么?我们可以固定x的值,然后找到使PDF最大的 y。
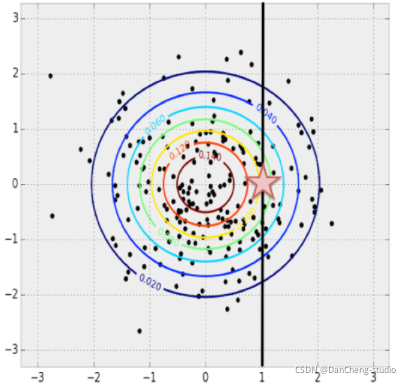
在多维正态分布中,给定x,得到最大可能的y
这个概念可以很自然地推广到图像概率分布。我们已知一些值,希望补全缺失值。这可以简单理解成一个最大化问题。我们搜索所有可能的缺失值,用于补全的图像就是可能性最大的值。
从正态分布的样本来看,只通过样本,我们就可以得出PDF。只需挑选你喜欢的 统计模型, 然后拟合数据即可。
然而,我们实际上并没有使用这种方法。对于简单分布来说,PDF很容易得出来。但是对于更复杂的图像分布来说,就十分困难,难以处理。之所以复杂,一部分原因是复杂的条件依赖:一个像素的值依赖于图像中其它像素的值。另外,最大化一个一般的PDF是一个非常困难和棘手的非凸优化问题。
3.3 快速生成假图像
在未知概率分布情况下,学习生成新样本
除了学 如何计算PDF之外,统计学中另一个成熟的想法是学 怎样用 生成模型
生成新的(随机)样本。生成模型一般很难训练和处理,但是后来深度学*社区在这个领域有了一个惊人的突破。Yann LeCun 在这篇 Quora
回答中对如何进行生成模型的训练进行了一番精彩的论述,并将它称为机器学习领域10年来最有意思的想法。
3.4 生成对抗网络(Generative Adversarial Net, GAN) 的架构
使用微步长卷积,对图像进行上采样
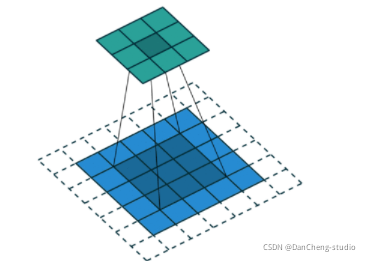
现在我们有了微步长卷积结构,可以得到G(z)的表达,以一个向量z∼pz 作为输入,输出一张 64x64x3 的RGB图像。
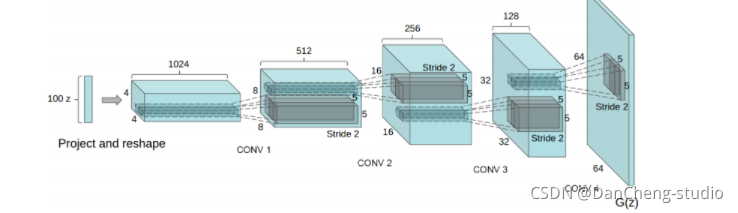
3.5 使用G(z)生成伪图像
基于DCGAN的人脸代数运算 DCGAN论文 。

4 在Tensorflow上构建DCGANs
部分代码:
def generator(self, z):self.z_, self.h0_w, self.h0_b = linear(z, self.gf_dim*8*4*4, 'g_h0_lin', with_w=True)self.h0 = tf.reshape(self.z_, [-1, 4, 4, self.gf_dim * 8])h0 = tf.nn.relu(self.g_bn0(self.h0))self.h1, self.h1_w, self.h1_b = conv2d_transpose(h0,[self.batch_size, 8, 8, self.gf_dim*4], name='g_h1', with_w=True)h1 = tf.nn.relu(self.g_bn1(self.h1))h2, self.h2_w, self.h2_b = conv2d_transpose(h1,[self.batch_size, 16, 16, self.gf_dim*2], name='g_h2', with_w=True)h2 = tf.nn.relu(self.g_bn2(h2))h3, self.h3_w, self.h3_b = conv2d_transpose(h2,[self.batch_size, 32, 32, self.gf_dim*1], name='g_h3', with_w=True)h3 = tf.nn.relu(self.g_bn3(h3))h4, self.h4_w, self.h4_b = conv2d_transpose(h3,[self.batch_size, 64, 64, 3], name='g_h4', with_w=True)return tf.nn.tanh(h4)def discriminator(self, image, reuse=False):if reuse:tf.get_variable_scope().reuse_variables()h0 = lrelu(conv2d(image, self.df_dim, name='d_h0_conv'))h1 = lrelu(self.d_bn1(conv2d(h0, self.df_dim*2, name='d_h1_conv')))h2 = lrelu(self.d_bn2(conv2d(h1, self.df_dim*4, name='d_h2_conv')))h3 = lrelu(self.d_bn3(conv2d(h2, self.df_dim*8, name='d_h3_conv')))h4 = linear(tf.reshape(h3, [-1, 8192]), 1, 'd_h3_lin')return tf.nn.sigmoid(h4), h4
当我们初始化这个类的时候,将要用到这两个函数来构建模型。我们需要两个判别器,它们共享(复用)参数。一个用于来自数据分布的小批图像,另一个用于生成器生成的小批图像。
self.G = self.generator(self.z)
self.D, self.D_logits = self.discriminator(self.images)
self.D_, self.D_logits_ = self.discriminator(self.G, reuse=True)
接下来,我们定义损失函数。这里我们不用求和,而是用D的预测值和真实值之间的交叉熵(cross
entropy),因为它更好用。判别器希望对所有“真”数据的预测都是1,对所有生成器生成的“伪”数据的预测都是0。生成器希望判别器对两者的预测都是1 。
self.d_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(self.D_logits,tf.ones_like(self.D)))
self.d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(self.D_logits_,tf.zeros_like(self.D_)))
self.g_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(self.D_logits_,tf.ones_like(self.D_)))
self.d_loss = self.d_loss_real + self.d_loss_fake
下面我们遍历数据。每一次迭代,我们采样一个小批数据,然后使用优化器来更新网络。有趣的是,如果G只更新一次,鉴别器的损失不会变成0。另外,我认为最后调用
d_loss_fake 和 d_loss_real 进行了一些不必要的计算, 因为这些值在 d_optim 和 g_optim 中已经计算过了。
作为Tensorflow 的一个联系,你可以试着优化这一部分,并发送PR到原始的repo。
for epoch in xrange(config.epoch):...for idx in xrange(0, batch_idxs):batch_images = ...batch_z = np.random.uniform(-1, 1, [config.batch_size, self.z_dim]) \.astype(np.float32)# Update D network_, summary_str = self.sess.run([d_optim, self.d_sum],feed_dict={ self.images: batch_images, self.z: batch_z })# Update G network_, summary_str = self.sess.run([g_optim, self.g_sum],feed_dict={ self.z: batch_z })# Run g_optim twice to make sure that d_loss does not go to zero (different from paper)_, summary_str = self.sess.run([g_optim, self.g_sum],feed_dict={ self.z: batch_z })errD_fake = self.d_loss_fake.eval({self.z: batch_z})errD_real = self.d_loss_real.eval({self.images: batch_images})errG = self.g_loss.eval({self.z: batch_z})最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
竞赛选题 深度学习图像修复算法 - opencv python 机器视觉
文章目录 0 前言2 什么是图像内容填充修复3 原理分析3.1 第一步:将图像理解为一个概率分布的样本3.2 补全图像 3.3 快速生成假图像3.4 生成对抗网络(Generative Adversarial Net, GAN) 的架构3.5 使用G(z)生成伪图像 4 在Tensorflow上构建DCGANs最后 0 前言 &#…...

基于深度学习网络的美食检测系统matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3.部分核心程序 % 图像大小 image_size [224 224 3]; num_classes size(VD,2)-1;% 目标类别数量…...

人工智能基础_机器学习006_有监督机器学习_正规方程的公式推导_最小二乘法_凸函数的判定---人工智能工作笔记0046
我们来看一下公式的推导这部分比较难一些, 首先要记住公式,这个公式,不用自己理解,知道怎么用就行, 比如这个(mA)T 这个转置的关系要知道 然后我们看这个符号就是求X的导数,X导数的转置除以X的导数,就得到单位矩阵, 可以看到下面也是,各种X的导数,然后计算,得到对应的矩阵结…...
【MongoDB】Windows 安装MongoDB 6.0
一、下载安装包 安装包下载地址https://www.mongodb.com/try/download/community这里我选择的是 二、解压并安装 1、解压 这里我将压缩包解压到了D盘,并重命名成了mongodb,解压后的目录如下: 2、创建配置文件 在D:\mongodb下新建conf目录…...

DM8 Dokcer镜像更新后远程无法jdbc连接问题
背景:原来官网下的dm8docker镜像有效期只有两个星期,问他们商务申请了新的dm8镜像,准备简单升级一下镜像再引入原来的database 先说结论:jdbc驱动要更新 官网dm8驱动链接地址 原来的tag镜像 dm8_single:v8.1.2.128_ent_x86_64…...

AI:39-基于深度学习的车牌识别检测
🚀 本文选自专栏:AI领域专栏 从基础到实践,深入了解算法、案例和最新趋势。无论你是初学者还是经验丰富的数据科学家,通过案例和项目实践,掌握核心概念和实用技能。每篇案例都包含代码实例,详细讲解供大家学习。 📌📌📌本专栏包含以下学习方向: 机器学习、深度学…...
)
软考 系统架构设计师系列知识点之系统架构评估(1)
所属章节: 第8章. 系统质量属性与架构评估 第2节. 系统架构评估 1. 概述 系统架构评估是在对架构分析、评估的基础上,对架构策略的选取进行决策。它利用数学或逻辑分析技术,针对系统的一致性、正确性、质量属性、规划结果等不同方面&#x…...

Spark UI中Shuffle dataSize 和shuffle bytes written 指标区别
背景 本文基于Spark 3.1.1 目前在做一些知识回顾的时候,发现了一些很有意思的事情,就是Spark UI中ShuffleExchangeExec 的dataSize和shuffle bytes written指标是不一样的, 那么在AQE阶段的时候,是以哪个指标来作为每个Task分区大…...

Java——Map.getOrDefault方法详解
Java——Map.getOrDefault方法详解 Map.getOrDefault(Object key, V defaultValue)是Java中Map接口的一个方法,用于获取指定键对应的值,如果键不存在,则返回一个默认值。 该方法的签名如下: V getOrDefault(Object key, V defau…...

银河集团香港优才计划95分获批案例展示!看看是如何申请的?
银河集团香港优才计划95分获批案例展示!看看是如何申请的? 今天来分享一则银河集团香港优才计划获批案例!客户本科学历非名校、从事业务支援及人力资源行业,优才打分95分,这个条件可能在很多人的印象里,会觉…...

Python class中以`_`开头的类特殊方法
在学基础的时候没学到过(可能见过但是又忘了),在学习深度学习项目的时候遇见了很多; 以论文Multi-label learning from single positive label为例; 这些方法都是程序自行调用的,不需要(也不可以…...

2023云栖大会开幕:全球数万开发者参会,展现AI时代的云计算创新
10月31日,2023云栖大会在杭州开幕,大会吸引全球数万开发者参会。阿里巴巴集团董事会主席蔡崇信在致辞中表示,今年云栖大会主题回归“计算,为了无法计算的价值”,这也是2015年云栖大会的主题,当时云计算支撑…...

[量化投资-学习笔记004]Python+TDengine从零开始搭建量化分析平台-EMA均线
在之前的文章中用 Python 直接计算的 MA 均线,但面对 EMA 我认怂了。 PythonTDengine从零开始搭建量化分析平台-MA均线的多种实现方式 高数是我们在大学唯一挂过的科。这次直接使用 Pandas 库的 DataFrame.ewm 函数,便捷又省事。 并且用 Pandas 直接对之…...

KaiwuDB 获山东省工信厅“信息化应用创新优秀解决方案”奖
10月23日,山东省工信厅正式公示《2023年山东省信息化应用创新典型应用案例及优秀解决方案名单》,面向全省、全国重点推荐山东省技术水平先进、应用示范效果突出、产业带动性强的信息化解决方案及应用实践,对于进一步激发山东省信息技术产业创…...

Python-常用的量化交易代码片段
算法交易正在彻底改变金融世界。通过基于预定义标准的自动化交易,交易者可以以闪电般的速度和比以往更精确的方式执行订单。如果您热衷于深入了解算法交易的世界,本指南提供了帮助您入门的基本代码片段。从获取股票数据到回溯测试策略,我们都能满足您的需求! 1. 使用 YFina…...

Netty优化-rpc
Netty优化-rpc 1.3 RPC 框架1)准备工作 1.3 RPC 框架 1)准备工作 这些代码可以认为是现成的,无需从头编写练习 为了简化起见,在原来聊天项目的基础上新增 Rpc 请求和响应消息 Data public abstract class Message implements …...
:概念、作用、术语)
【Docker 内核详解】cgroups 资源限制(一):概念、作用、术语
cgroups 资源限制(一):概念、作用、术语 1.cgroups 是什么2.cgroups 的作用3.cgroups 术语表 当谈论 Docker 时,常常会聊到 Docker 的实现方式。很多开发者都知道,Docker 容器本质上是宿主机上的进程(容器所…...
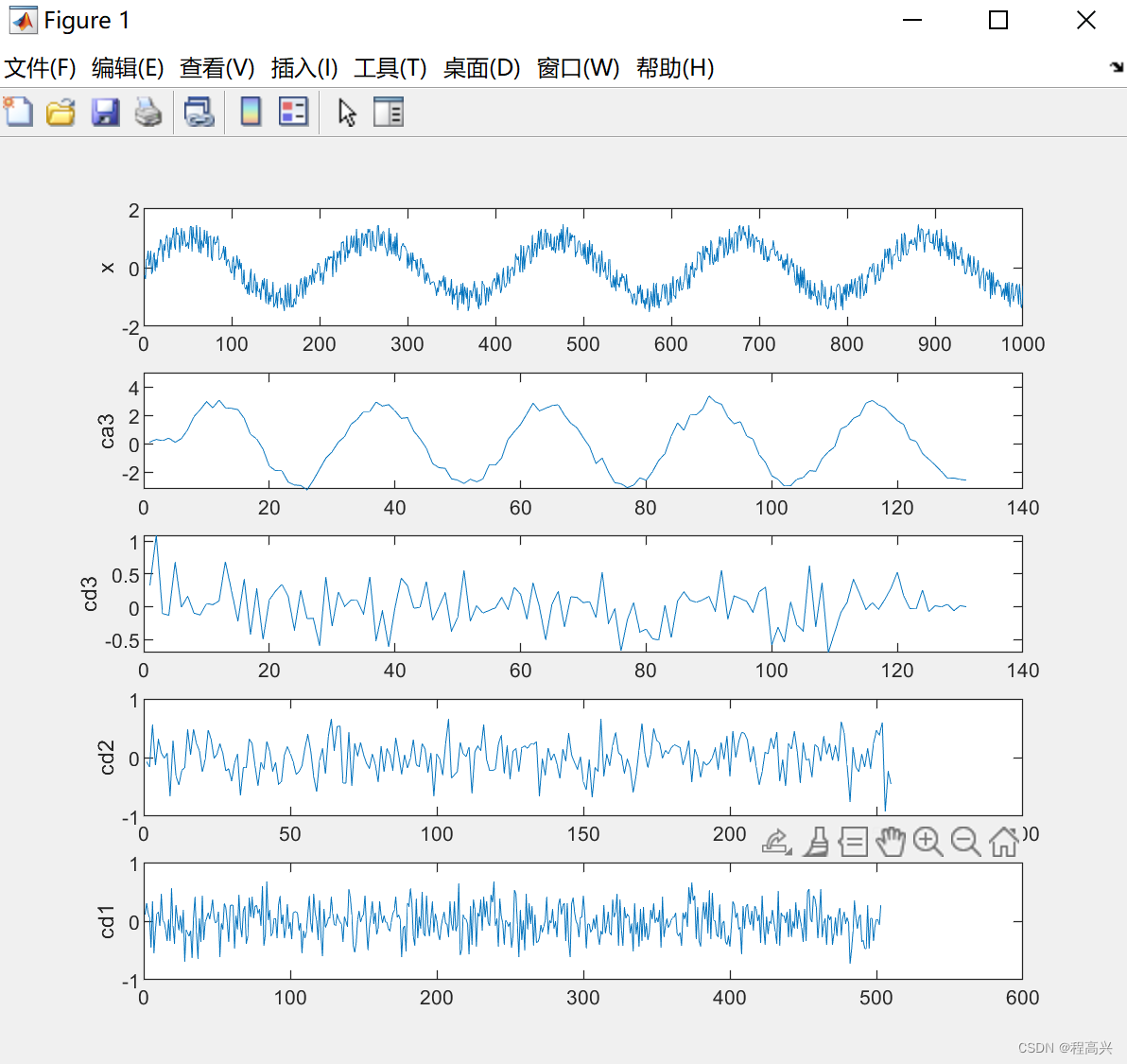
MATLAB——一维小波的多层分解
%% 学习目标:一维小波的多层分解 clear all; close all; load noissin.mat; xnoissin; [C,L]wavedec(x,3,db4); % 3层分解,使用db4小波 [cd1,cd2,cd3]detcoef(C,L,[1,2,3]); % 使用detcoef函数获取细节系数 ca3appcoef(C,L,db4,3); …...
C++的拷贝构造函数
目录 拷贝构造函数一、为什么用拷贝构造二、拷贝构造函数1、概念2、特征1. 拷贝构造函数是构造函数的一个重载形式。2. 拷贝构造函数的参数3. 若未显式定义,编译器会生成默认的拷贝构造函数。4. 拷贝构造函数典型调用场景 拷贝构造函数 一、为什么用拷贝构造 日期…...
【手机端远程连接服务器】安装和配置cpolar+JuiceSSH:实现手机端远程连接服务器
文章目录 1. Linux安装cpolar2. 创建公网SSH连接地址3. JuiceSSH公网远程连接4. 固定连接SSH公网地址5. SSH固定地址连接测试 处于内网的虚拟机如何被外网访问呢?如何手机就能访问虚拟机呢? cpolarJuiceSSH 实现手机端远程连接Linux虚拟机(内网穿透,手机端连接Linux虚拟机) …...

告别跑飞!S32K3xx Standby模式唤醒后程序复位?手把手教你用WKPU和RTC保留关键数据
S32K3xx低功耗实战:WKPU与RTC协同解决Standby模式数据丢失难题 引言 在嵌入式系统设计中,低功耗优化一直是工程师们面临的永恒挑战。S32K3xx系列微控制器凭借其出色的电源管理能力,成为汽车电子、工业控制等领域的热门选择。然而,…...

ExploitDB二进制漏洞库使用教程:快速查找和利用漏洞的简单方法
ExploitDB二进制漏洞库使用教程:快速查找和利用漏洞的简单方法 【免费下载链接】exploitdb-bin-sploits The legacy Exploit Database repository - New repo located at https://gitlab.com/exploit-database/exploitdb-bin-sploits 项目地址: https://gitcode.c…...

深圳清关代理口碑爆棚,不找它你就亏大啦!
事件经过某外贸公司近期有一批从国外进口的电子产品要在深圳口岸清关。该公司原本以为按照常规流程操作即可顺利完成清关,便自行准备了相关单证资料。然而,当货物到达深圳口岸进行报关时,却遭遇了清关受阻的情况。海关在合规审核过程中发现&a…...

2026年八大上门服务预约小程序:解锁高效生活新体验
本文围绕上门服务预约小程序展开系统性梳理,聚焦2026年市场上主流的八家服务商,包括好赞科技、厦门亿点通科技、福州启帆数字科技等。内容覆盖核心功能解析、场景适配性、用户体验及服务效率等关键维度,旨在帮助用户理解不同平台的差异化优势…...

别再手动改参数了!用Fluent 2023R1的Parametric模块,5分钟搞定N个工况的批量仿真
Fluent 2023R1参数化模块实战:从单点仿真到智能设计空间探索 在计算流体动力学(CFD)领域,工程师们常常需要面对一个现实困境:如何高效完成数十种工况的参数扫描?传统手动修改边界条件的方式不仅耗时费力&am…...

量子退火与模拟退火:工业优化算法对比与应用
1. 量子优化算法概述在工业优化领域,寻找复杂问题的最优解一直是个巨大挑战。量子计算的出现为解决这类问题提供了全新思路。量子退火(Quantum Annealing)和模拟退火(Simulated Annealing)作为两种核心优化方法&#x…...

ZYNQ启动太慢?从FSBL到U-Boot的完整性能分析与优化实战
ZYNQ启动太慢?从FSBL到U-Boot的完整性能分析与优化实战 在嵌入式系统开发中,启动时间往往是衡量产品性能的关键指标之一。对于基于Xilinx ZYNQ平台的产品,从按下电源键到系统完全就绪,这中间经历的毫秒级延迟可能决定着一个工业控…...

ARM NEON SIMD指令集:VMAX与VMIN向量运算详解
1. ARM SIMD指令集基础与向量运算概述在移动计算和嵌入式系统领域,ARM架构凭借其出色的能效比占据了主导地位。随着应用对计算性能需求的不断提升,SIMD(单指令多数据)技术成为提升处理器并行计算能力的关键手段。ARM的Advanced SI…...

DLSS版本切换终极指南:掌控游戏性能优化的核心技术
DLSS版本切换终极指南:掌控游戏性能优化的核心技术 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 想要在《赛博朋克2077》中体验更流畅的光追效果?或是让《艾尔登法环》的画面表现更上一层楼&a…...

如何快速打造专业直播画面:OBS StreamFX插件终极指南
如何快速打造专业直播画面:OBS StreamFX插件终极指南 【免费下载链接】obs-StreamFX StreamFX is a plugin for OBS Studio which adds many new effects, filters, sources, transitions and encoders! Be it 3D Transform, Blur, complex Masking, or even custom…...