Spark On Hive原理和配置
目录
一、Spark On Hive原理
(1)为什么要让Spark On Hive?
二、MySQL安装配置(root用户)
(1)安装MySQL
(2)启动MySQL设置开机启动
(3)修改MySQL密码
三、Hive安装配置
(1)修改Hadoop的core-site.xml
(2)创建hive-site.xml
(3)修改配置文件hive-env.sh
(4)上传mysql连接驱动
(5)初始化元数据 (Hadoop集群启动后)
(6)创建logs目录,启动元数据服务
(7)启动Hive shell
四、Spark On Hive配置
(1)创建hive-site.xml(spark/conf目录)
(2)放置MySQL驱动包
(3)查看hive的hive-site.xml配置
(4)启动hive的MetaStore服务
(5)Spark On Hive测试
(6)Pycharm-spark代码连接测试
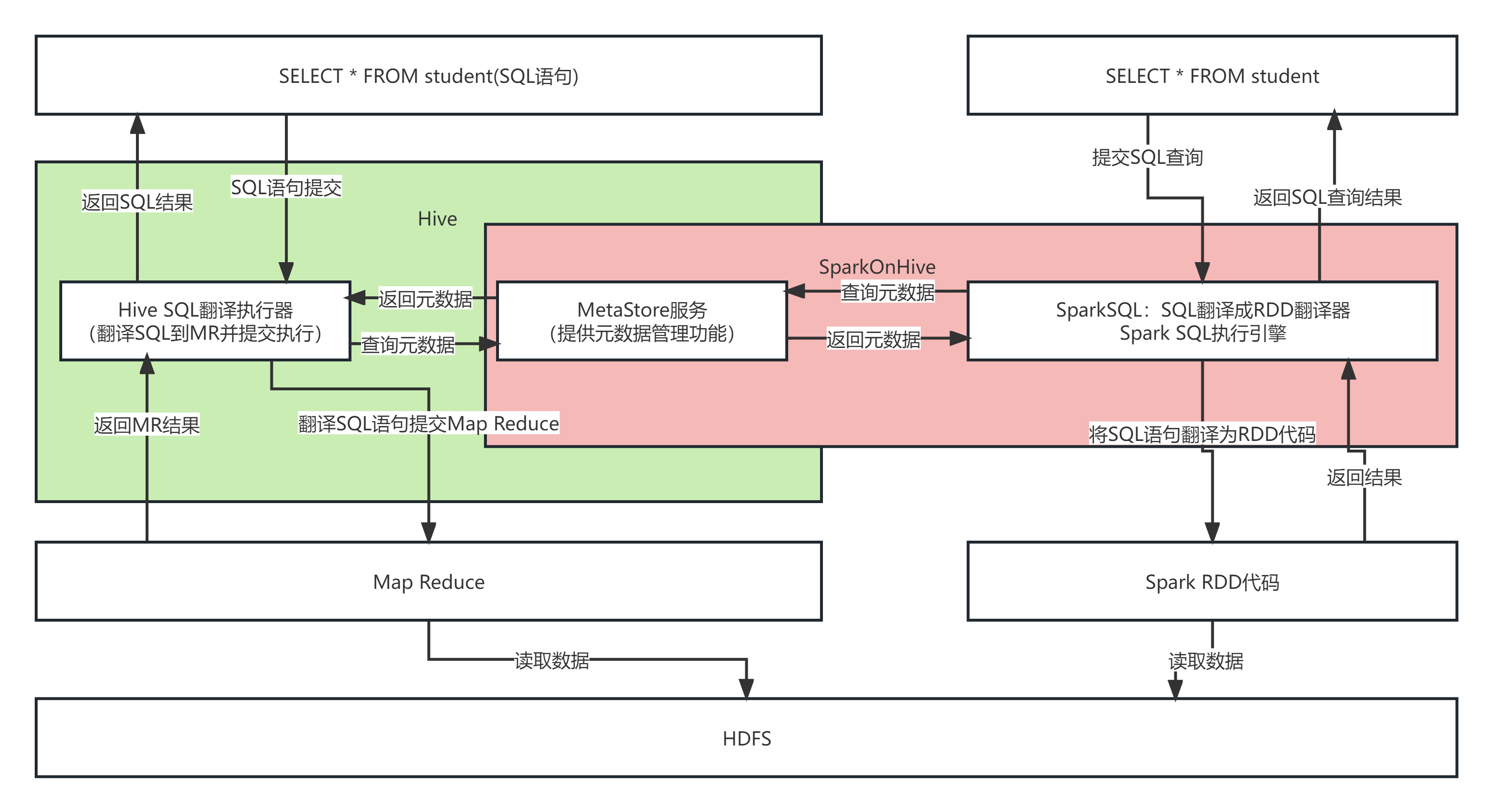
一、Spark On Hive原理
(1)为什么要让Spark On Hive?
对于Spark来说,自身是一个执行引擎。但是Spark自己没有元数据管理功能,当我们执行: SELECT * FROM person WHERE age > 10的时候, Spark完全有能力将SQL变成RDD提交。
但是问题是,Person的数据在哪? Person有哪些字段?字段啥类型? Spark完全不知道了。不知道这些东西,如何翻译RDD运行。在SparkSQL代码中可以写SQL那是因为,表是来自DataFrame注册的。 DataFrame中有数据,有字段,有类型,足够Spark用来翻译RDD用.。如果以不写代码的角度来看,SELECT * FROM person WHERE age > 10 spark无法翻译,因为没有元数据。
解决方案:
Spark提高执行引擎能力,Hive的MetaStore提供元数据管理功能。选择Hive的原因是使用Hive的用户数量多。
二、MySQL安装配置(root用户)
(1)安装MySQL
命令:
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
rpm -Uvh https://repo.mysql.com//mysql57-community-release-el7-7.noarch.rpm
yum -y install mysql-community-server


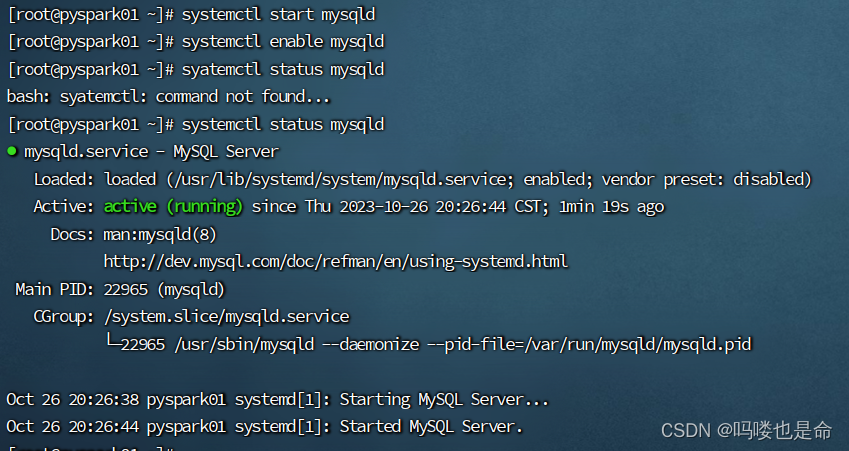
(2)启动MySQL设置开机启动
命令:
systemctl start mysqld
systemctl enable mysqld
(3)修改MySQL密码
命令:
查看密码:grep 'temporary password' /var/log/mysqld.log
修改密码:
mysql -uroot -p #登录MySQL,密码是刚刚查看的临时密码set global validate_password_policy=LOW; #密码安全级别低set global validate_password_length=4; #密码长度最低四位ALTER USER 'root'@'localhost' IDENTIFIED BY '密码'; # 设置用户和密码
# 配置远程登陆用户以及密码
grant all privileges on *.* to root@"%" identified by 'root' with grant option;flush privileges;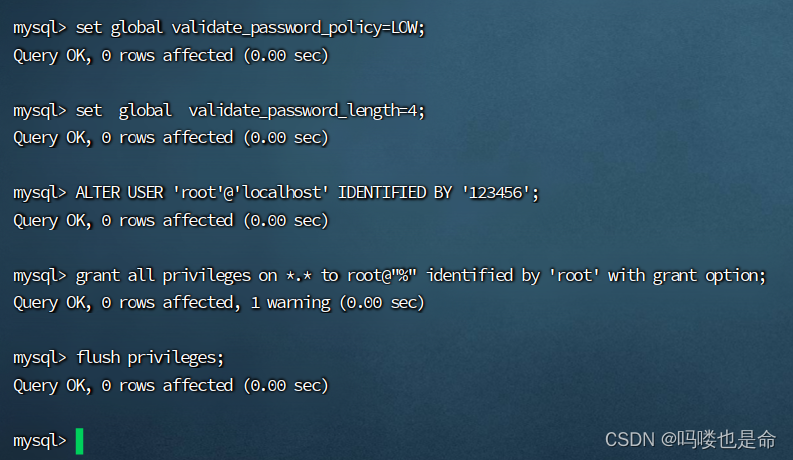
三、Hive安装配置
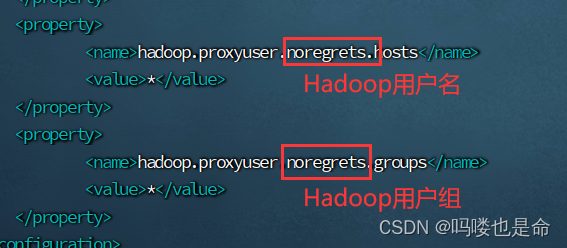
(1)修改Hadoop的core-site.xml
添加内容如下:
<property>
<name>hadoop.proxyuser.noregrets.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.noregrets.groups</name>
<value>*</value>
</property>
上传解压安装Hive压缩包并构建软连接
命令:
解压:tar -zvxf apache-hive-3.1.3-bin-tar-gz -C /export/servers
构建软连接:ln -s /export/servers/apache-hive-3.1.3-bin/ /export/servers/hive

(2)创建hive-site.xml
命令:
cd /export/servers/hive/conf
vim hive-site.xml
添加内容如下:
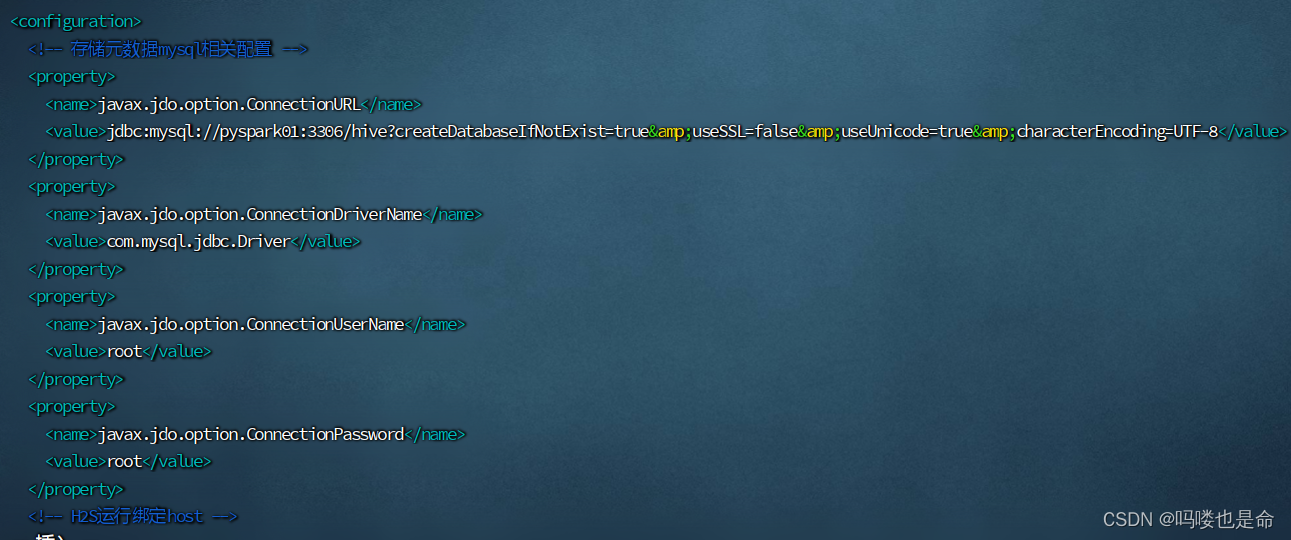
<configuration>
<!-- 存储元数据mysql相关配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://pyspark01:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
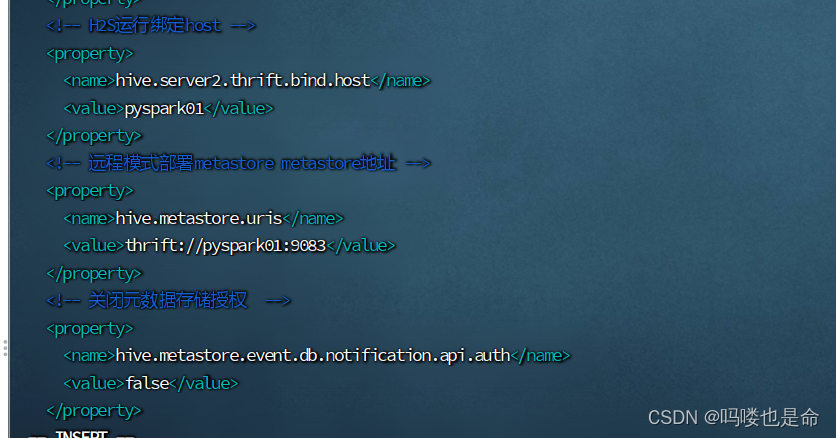
<!-- H2S运行绑定host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>pyspark01</value>
</property>
<!-- 远程模式部署metastore metastore地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://pyspark01:9083</value>
</property>
<!-- 关闭元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>
(3)修改配置文件hive-env.sh
命令:
cd /export/servers/hive/conf
cp hive-env.sh.template hive-env.sh
vim hive-env.sh(修改第48行内容)
内容如下:
export HADOOP_HOME=/export/servers/hadoop
export HIVE_CONF_DIR=/export/servers/hive/conf
export HIVE_AUX_JARS_PATH=/export/servers/hive/lib

(4)上传mysql连接驱动
链接:https://pan.baidu.com/s/1MJ9QBsE3h1FAxuB3a4iyVw?pwd=1111
提取码:1111
MySQL5使用5的连接版本,MySQL8使用8的连接版本。
(5)初始化元数据 (Hadoop集群启动后)
命令:
登录数据库:
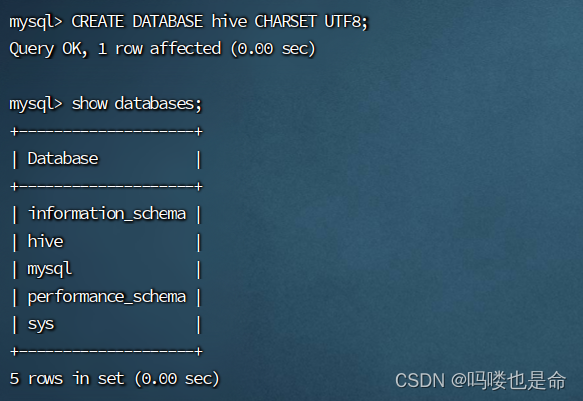
mysql -uroot -p
CREATE DATABASE hive CHARSET UTF8; #建表

cd /export/server/hive/
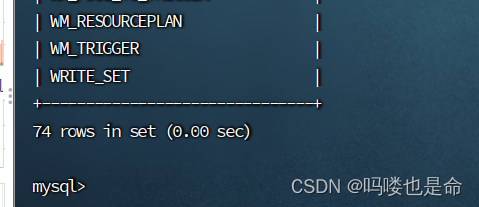
bin/schematool -initSchema -dbType mysql -verbos
#初始化成功会在mysql中创建74张表

(6)创建logs目录,启动元数据服务
命令:
创建文件夹:mkdir logs
启动元数据服务:nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &

(7)启动Hive shell
命令:bin/hive(配置环境变量可直接使用hive)

四、Spark On Hive配置
(1)创建hive-site.xml(spark/conf目录)
添加内容如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--告知Spark创建表存到哪里-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<!--告知Spark Hive的MetaStore在哪-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://pyspark01:9083</value>
</property>
</configuration>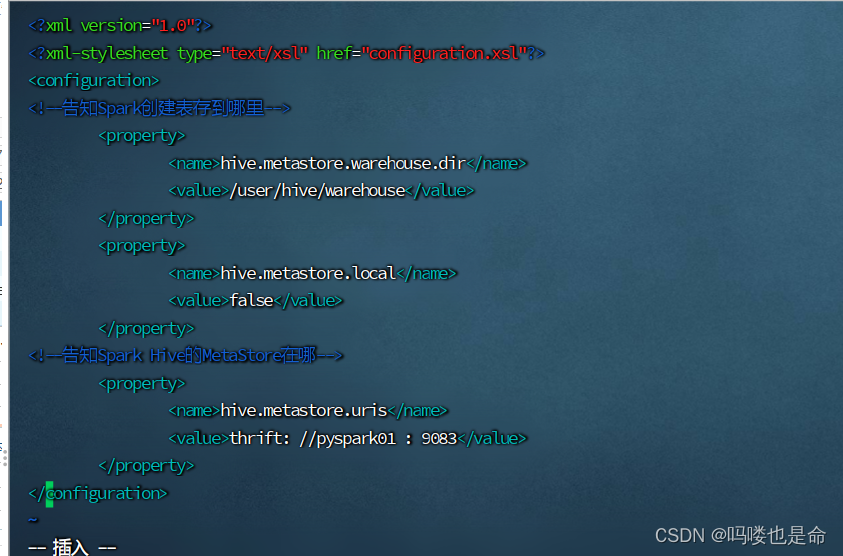
(2)放置MySQL驱动包

(3)查看hive的hive-site.xml配置
确保有如下配置:

(4)启动hive的MetaStore服务
命令:
nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
(5)Spark On Hive测试
①创建表sparkonhive
命令:
在spark目录下:
bin/spark
spark.sql('create table sparkonhive(id int)' )

②进入查看查看
命令:
hive目录:
bin/hive(配置过环境变量可直接使用hive)

(6)Pycharm-spark代码连接测试
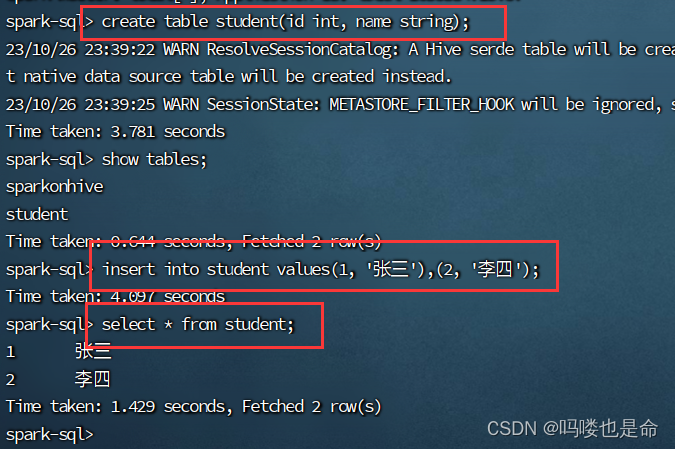
在Linux的sparkSQl终端或者hive终端创建学生表,然后使用spark代码查询。
命令:
create table student(id int, name string);
insert into student values(1,'张三'),(2, '李四');
使用spark代码查询
在Spark代码中加上如下内容

# cording:utf8
import string
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
from pyspark.sql.types import IntegerType, StringType, StructType, ArrayType
if __name__ == '__main__':spark = SparkSession.builder.\appName('udf_define').\master('local[*]').\config('spark.sql.shuffle.partitions', 2).\config('spark.sql.warehouse.dir', 'hdfs://pyspark01:8020/user/hive/warehouse').\config('hive.metastore.uris', 'thrift://pyspark01:9083').\enableHiveSupport().\getOrCreate()sc = spark.sparkContextspark.sql('''SELECT * FROM student''').show()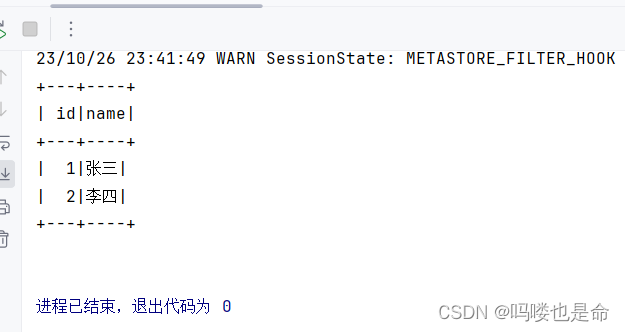
相关文章:
Spark On Hive原理和配置
目录 一、Spark On Hive原理 (1)为什么要让Spark On Hive? 二、MySQL安装配置(root用户) (1)安装MySQL (2)启动MySQL设置开机启动 (3)修改MySQL…...

驱动第十天
...

工作中常用的git命令,千万不能忘
1、设置当前分支为默认分支: git branch –set-upstream-toorigin/master 2、To push the current branch and set the remote as upstream, use: git push --set-upstream origin eds_enhancement 3、同步远程分支 git remote update --prune [remote] 4、Remo…...

计组之存储系统
存储器概述 分类 1.按在计算机中的作用(层次)分类 主存储器。CPU可以直接随机地对其进行访问,也可以和高速缓冲存储器(Cache)及辅助存储器交换数据。辅助存储器。辅存的内容需要调入主存后才能被CPU访问。高速缓冲存储器。位于…...

【Jenkins】新建任务FAQ
问题1. 源码管理处填入Repository URL,报错:无法连接仓库:Error performing git command: ls-remote -h https://github.com/txy2023/GolangLearning.git HEAD 原因: jenkins全局工具配置里默认没有添加git的路径,如果…...
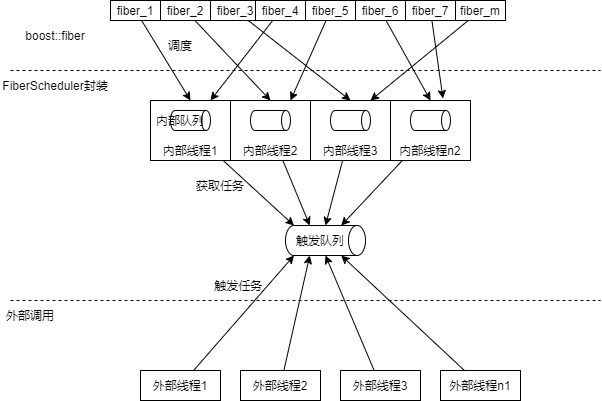
生产环境使用boost::fiber
简介 boost::fiber是一类用户级线程,也就是纤程。其提供的例子与实际生产环境相距较远,本文将对其进行一定的改造,将其能够投入到生产环境。 同时由于纤程是具有传染性的,使用纤程的代码里也全部要用纤程封装,本文将对…...

TSINGSEE青犀AI视频识别技术+危化安全生产智慧监管方案
一、背景分析 石油与化学工业生产过程复杂多样,涉及的物料易燃易爆、有毒有害,生产条件多高温高压、低温负压,现场危险化学品存储量大、危险源集中,重特大安全事故多发。打造基于工业互联网的安全生产新型能力,提高危…...
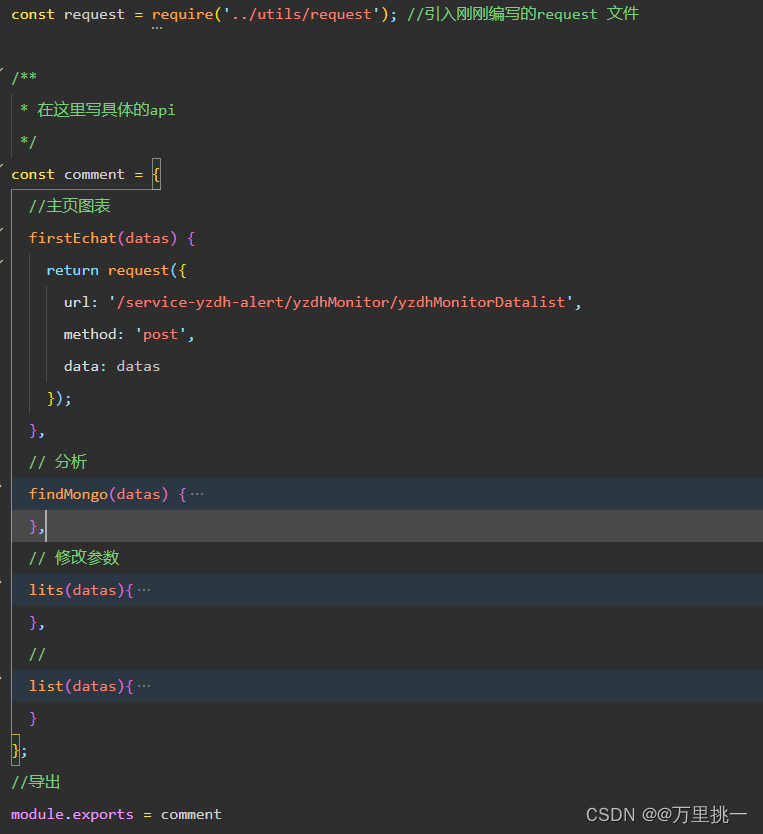
小程序request请求封装
以上为本人的项目目录 1.首先在utils中创建request.js文件封装request请求,此封装带上了token,每次请求都会自带token,需要你从后端获取后利用wx.setStorageSync(token,返回的token),不使用的话就是空。 直接复制即可,需要改一下…...
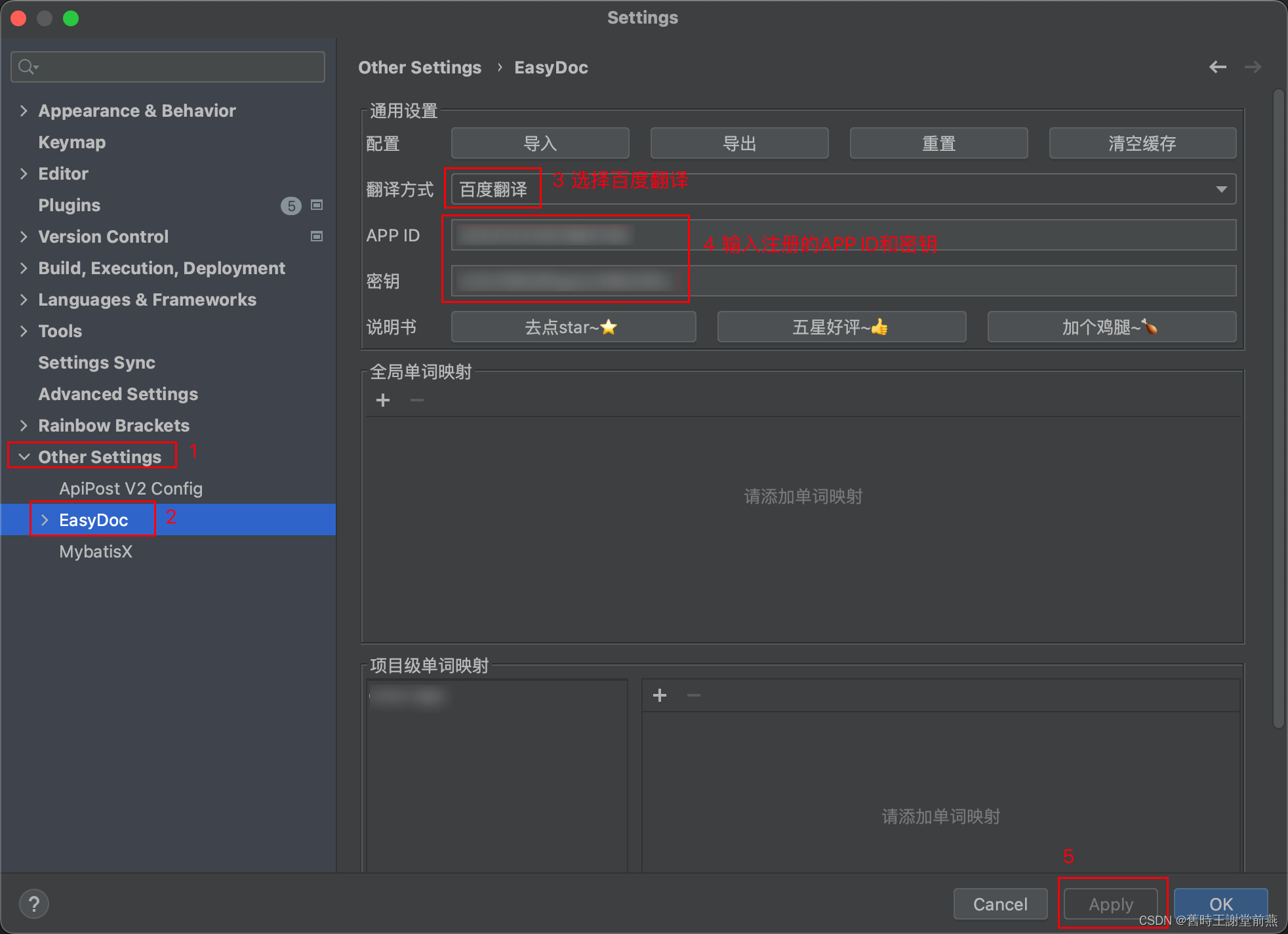
Easy Javadoc插件的使用教程
目录 一、安装Easy Javadoc插件 二、配置注释模板 三、配置翻译 一、安装Easy Javadoc插件 在idea的File-Settings-Plugins中搜索Easy Javadoc插件,点击install进行安装,安装完成后需要restart IDE,重启后插件生效。 二、配置注释模板 …...
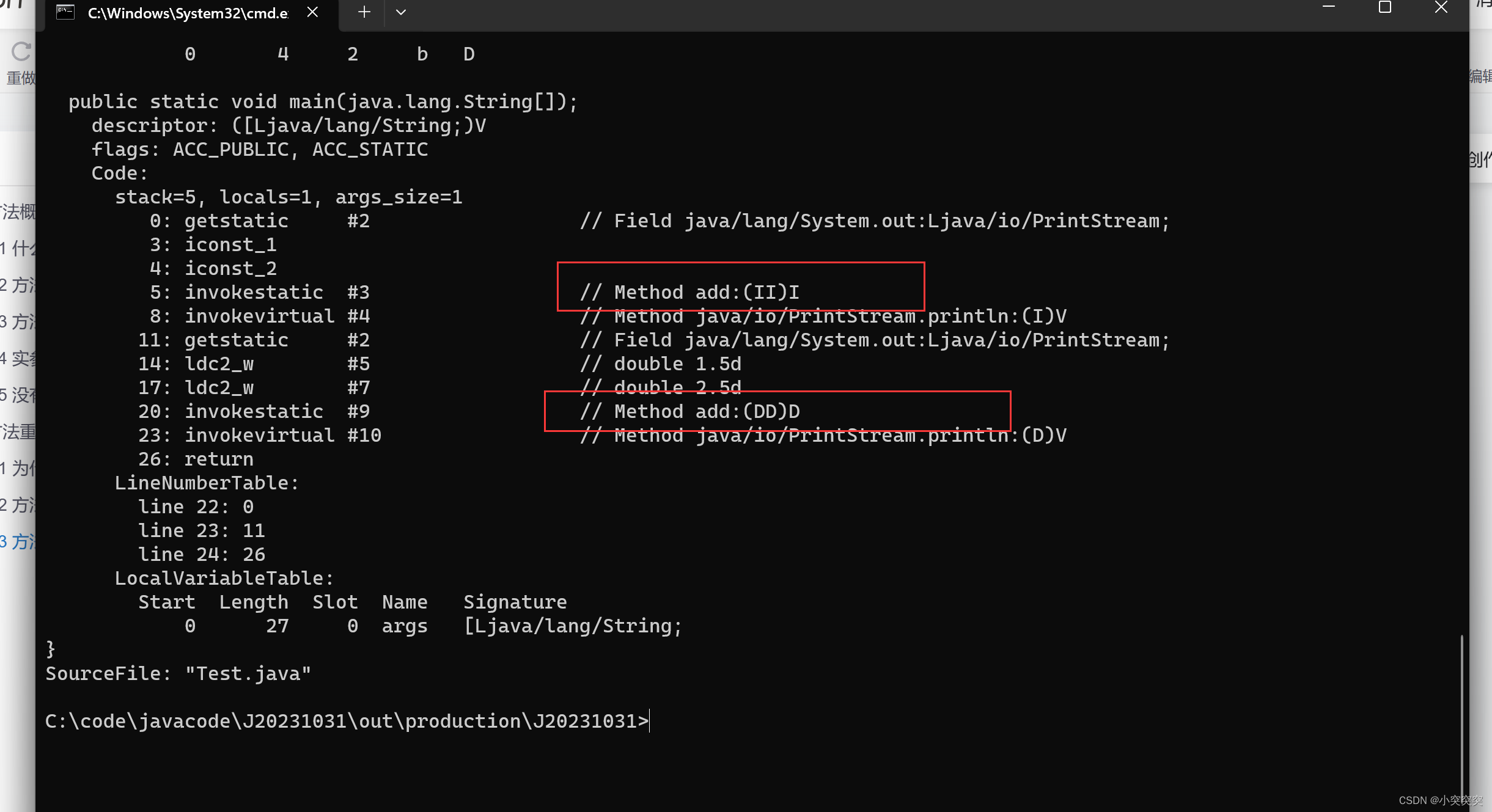
一篇文章让你弄懂Java中的方法
目录 1. 方法概念及使用 1.1 什么是方法(method) 1.2 方法定义 1.3 方法调用的执行过程 1.4 实参和形参的关系 1.5 没有返回值的方法 2. 方法重载 2.1 为什么需要方法重载 2.2 方法重载概念 2.3 方法签名 1. 方法概念及使用 1.1 什么是方法(method) 方法就是一…...

SAP MM学习笔记39 - MRP(资材所要量计划)
这一章开始,离开请求书,学点儿新知识啦。 MRP ( Material Requirement Planning ) - 资材所要量计划。 它的位置在下面的调达周期图上来看,就是右上角的 所要量决定那块儿。 1,MRP(资材所要量计划) 的概要 MRP 的主要目的就是 确…...
总线类设备驱动——IIC
目录 一、本章目标 二、IIC设备驱动 2.1 I2C协议简介 2.2 LinuxI2C驱动 2.3 I2C 设备驱动实例 一、本章目标 一条总线可以将多个设备连接在一起,提高了系统的可扩展性能。这个互联的系统通常由三部分组成:总线控制器、物理总线(一组信号线) 和设备。总线控制器…...
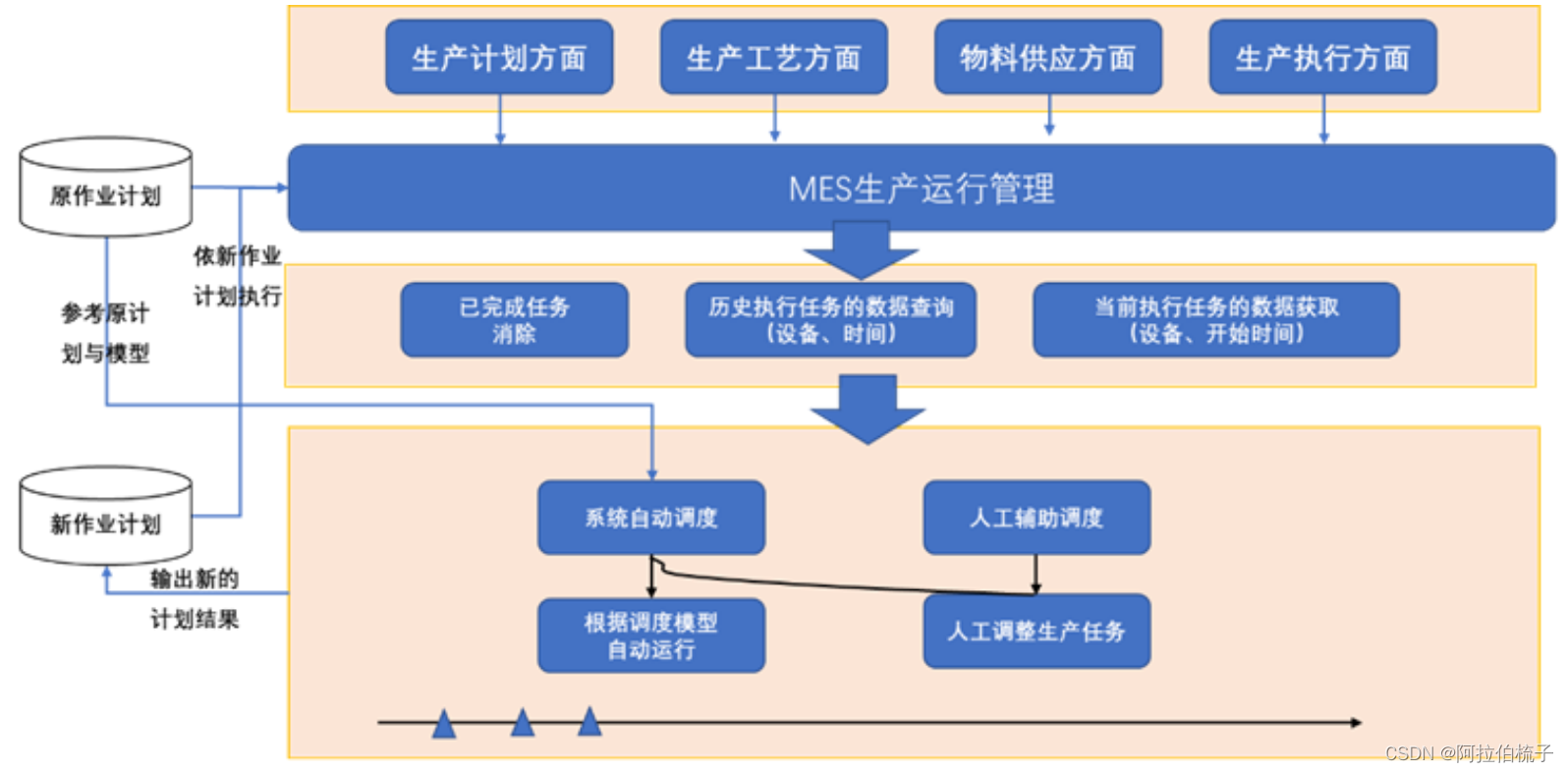
MES 的价值点之动态调度
随着数字化技术的发展,为制造企业的生产计划提供了更多的便利。但在实际生产管理过程中,企业的生产计划不管做的多么理想,还是可能会因诸多的扰动因素造成执行与计划差异,这时就需要通过一些动态调整方案去适应新的生产要求与环境…...

dfs序及相关例题
常用的三种dfs序 欧拉序 每经过一次该点记录一次的序列。 dfs序 记录入栈和出栈的序列。 dfn序 只记录入栈的序列。 dfs序 DFS 序列是指 DFS 调用过程中访问的节点编号的序列。 如何求dfs序?可以用以下代码来找dfs序。 vector<vector<int>> g(n…...
python入门实战:爬取图片到本地
简单记录一下爬取网站图片保存到本地指定目录过程,希望对刚入门的小伙伴有所帮助! 目标网站就是下图所示页面: 实现步骤: 1.爬取每页的图片地址集合 2.下载图片到本地 3. 获取指定页数的页面路径 以下是实现代码: import bs4 import requests import os # 下…...

day02 矩阵 2023.10.26
1.矩阵 2.矩阵乘法 3.特殊矩阵 4.逆矩阵 5.正交矩阵 6.几何意义 7.齐次坐标 8.平移矩阵 9.旋转矩阵 10.缩放矩阵 11.复合运算...
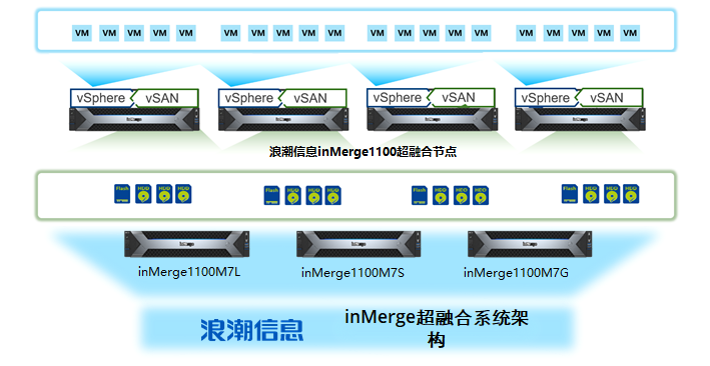
浪潮信息inMerge超融合 刷新全球vSAN架构虚拟化VMmark最佳成绩
近日,在国际权威的VMmark测试中,浪潮信息inMerge1100超融合产品搭载NF5280M7服务器,满载运行44Tiles取得40.95分的成绩,刷新了vSAN架构(Intel双路最新平台)虚拟化性能测试纪录。该测试结果证明inMerge1100可…...
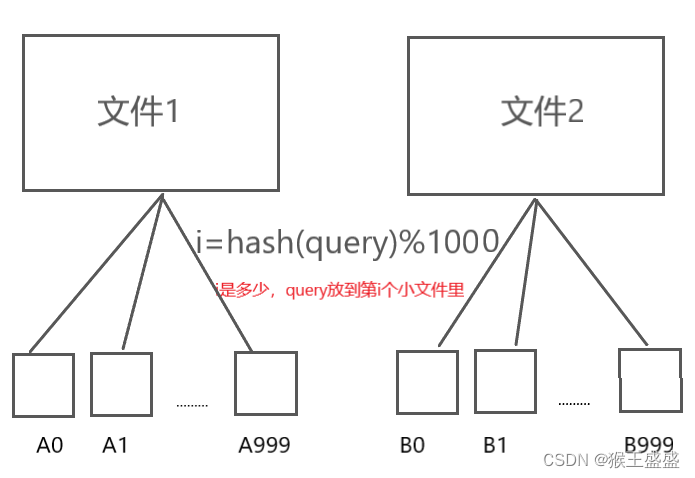
【【哈希应用】位图/布隆过滤器】
位图/布隆过滤器 位图位图概念位图的使用位图模拟实现 布隆过滤器布隆过滤器概念布隆过滤器的使用布隆过滤器模拟实现 位图/布隆过滤器应用:海量数据处理哈希切分 位图 位图概念 计算机中通常以位bit为数据最小存储单位,只有0、1两种二进制状态&#x…...
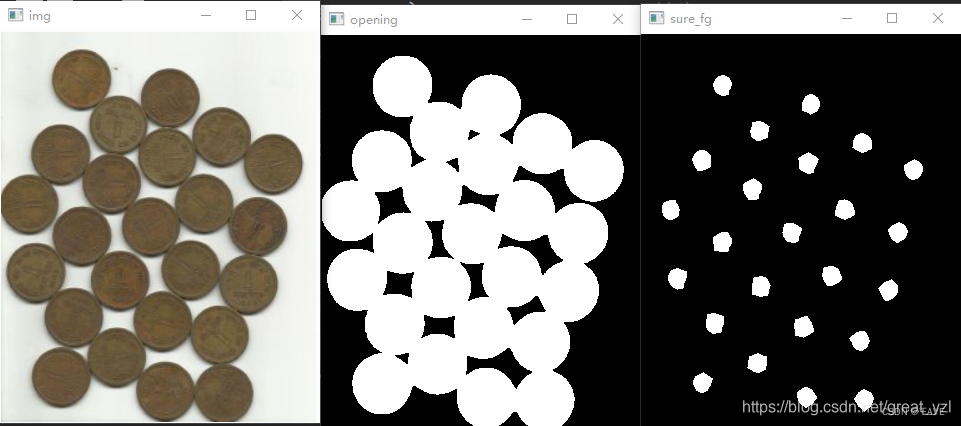
OpenCV学习笔记
一、OpenCV基础 (一)图像的读取、显示、创建 https://mp.weixin.qq.com/s?__bizMzA4MTA1NjM5NQ&mid2247485202&idx1&sn05d0b4cd25675a99357910a5f2694508&chksm9f9b80f6a8ec09e03ab2bb518ea6aad83db007c9cdd602c7459ed75c737e380ac9c3…...
idea 一键部署jar包
上传成功...

【免费下载】 QQ空间说说批量删除插件:2023年最新版推荐
QQ空间说说批量删除插件:2023年最新版推荐 【下载地址】QQ空间说说批量删除插件-2023年最新版 本仓库提供了一个2023年最新版的QQ空间说说批量删除插件。该插件可以帮助用户快速批量删除QQ空间中的说说,节省大量手动操作的时间 项目地址: https://gitc…...

使用 curl 命令直接测试 Taotoken 聊天补全接口连通性与返回
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 curl 命令直接测试 Taotoken 聊天补全接口连通性与返回 在开发或调试过程中,有时你可能需要绕过高级 SDK…...

基于Adafruit Trinket与旋转编码器制作USB物理音量旋钮
1. 项目概述与核心价值作为一个常年泡在电脑前,需要频繁切换音乐、会议和视频的开发者,我发现自己每天点击系统音量图标的次数多得离谱。那种在关键时刻需要快速调低音量,却不得不移动鼠标、寻找小图标的操作,不仅打断了工作流&am…...

别再只调API了!深入XXL-Job时间轮源码,手把手带你搞懂任务触发与调度过期的那些坑
深入XXL-Job时间轮:从源码解析任务调度与过期处理的实战指南 在分布式任务调度领域,XXL-Job以其轻量级、易扩展的特性成为众多Java项目的首选方案。但当我们从简单的API调用者转变为架构设计者时,仅满足于配置层面的理解显然不够。本文将带您…...

开源阅读鸿蒙版:打造您的个性化无广告数字图书馆
开源阅读鸿蒙版:打造您的个性化无广告数字图书馆 【免费下载链接】legado-Harmony 开源阅读鸿蒙版仓库 项目地址: https://gitcode.com/gh_mirrors/le/legado-Harmony legado-Harmony是一款专为鸿蒙系统设计的开源电子书阅读器,它为您提供纯净的阅…...

长期使用Taotoken聚合服务对开发效率的实际提升感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken聚合服务对开发效率的实际提升感受 作为一名在多个项目中集成大模型能力的开发者,我过去需要为不同的…...
)
【网安-Web渗透测试-内网渗透】内网信息收集(工具)
目录1. 内网基础知识1.1 局域网1.1.1 局域网简介1.1.2 局域网的网络结构1.2 工作组1.3 域1.4 内网渗透2. 环境说明2.1 DC2.2 WebServer2.3 Marry2.4 Jack3. Cobalt Strike工具:用户凭据(密码)收集4. Metasploit信息收集5. BloodHound工具6. 内…...

峡谷焕新:用R3nzSkin解锁英雄联盟个性化游戏体验
峡谷焕新:用R3nzSkin解锁英雄联盟个性化游戏体验 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 在英雄联盟的召唤师峡谷中,每一…...

【技术解析】从点测量到全场感知:DIC三维应变测量如何革新传统应变片测试范式
1. 从点到面的技术革命:为什么我们需要全场应变测量? 记得我第一次接触材料力学测试时,导师让我用传统应变片测量一块铝合金板的拉伸变形。我花了整整三天时间,在试样上贴了二十多个应变片,结果数据还是支离破碎。那时…...

支付系统架构设计:从交易核心到资金核算的稳定性实践
1. 支付系统总览:从业务到资金的桥梁但凡涉及在线交易的公司,支付系统都是其技术架构中当之无愧的“心脏”。它远不止是调用一个第三方支付接口那么简单,而是一套连接用户、业务、资金渠道和内部账务的复杂工程体系。一个设计得当的支付系统&…...