数据结构——树
深度优先/广度优先遍历
深度优先:
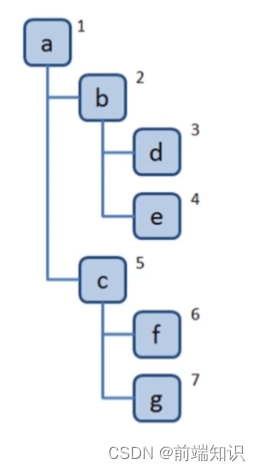
访问根节点
对根节点的 children 挨个进行深度优先遍历
const tree = {val: "a",children: [{val: "b",children: [{val: "d",children: [],},{val: "e",children: [],},],},{val: "c",children: [{val: "f",children: [],},{val: "g",children: [],},],},],
};const dfs = (root) => {console.log(root.val);root.children.forEach((child) => {dfs(child);});
};dfs(tree);广度优先:
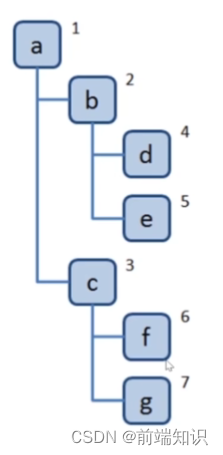
新建立一个队列,根节点入队
对头出队并访问
把对头的children挨个入队
重复2,3,直到队列为空
const tree = {val: "a",children: [{val: "b",children: [{val: "d",children: [],},{val: "e",children: [],},],},{val: "c",children: [{val: "f",children: [],},{val: "g",children: [],},],},],
};const bfs = (root) => {const q = [root];while (q.length > 0) {const n = q.shift();console.log(n.val);n.children.forEach((child) => {q.push(child);});}
};bfs(tree);二叉树的先中后序遍历
二叉树:每个节点最多只能有两个节点
先序遍历(根、左、右):
访问根节点
对根节点的左子树进行先序遍历
对根节点的右子树进行先序遍历
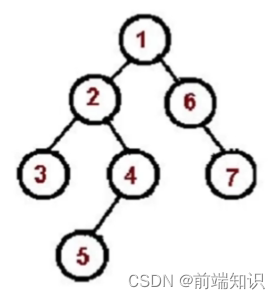
1、2、3、4、5、6、7
const tree = {val: "1",left: {val: "2",left: {val: "3",left: null,right: null,},right: {val: "4",left: {val: "5",},right: null,},},right: {val: "6",left: null,right: {val: "7",right: null,left: null,},},
};const preorder = (root) => {if (!root) return;console.log(root.val);preorder(root.left);preorder(root.right);
};
preorder(tree);中序遍历(左、中、右):
对根节点左子树遍历
访问根节点
对根节点右子树遍历
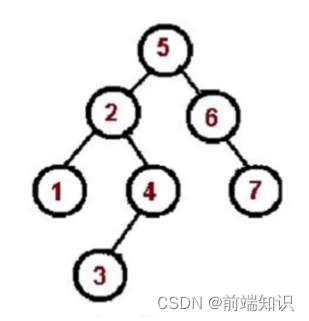
1、2、3、4、5、6、7
const tree = {val: "5",left: {val: "2",left: {val: "1",left: null,right: null,},right: {val: "4",left: {val: "3",},right: null,},},right: {val: "6",left: null,right: {val: "7",right: null,left: null,},},
};const inorder = (root) => {if (!root) return;inorder(root.left);console.log(root.val);inorder(root.right);
};
inorder(tree);后序遍历(左、右、根):
对根节点左子树遍历
对根节点右子树遍历
访问根节点
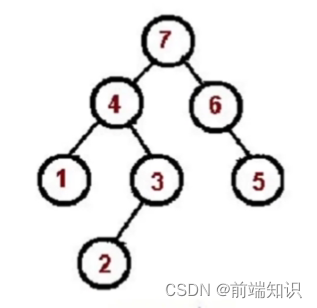
1、2、3、4、5、6、7
const tree = {val: "7",left: {val: "4",left: {val: "1",left: null,right: null,},right: {val: "3",left: {val: "2",},right: null,},},right: {val: "6",left: null,right: {val: "5",right: null,left: null,},},
};const postorder = (root) => {if (!root) return;postorder(root.left);postorder(root.right);console.log(root.val);
};
postorder(tree);非递归写法
递归调用函数,会不断的入栈出栈,所以考虑用栈实现。
先序遍历:
// 递归
const preorder = (root) => {if (!root) return;console.log(root.val);preorder(root.left);preorder(root.right);
};// 非递归
const preorder = (root) => {if (!root) return;const stack = [root]while(stack.length){const n = stack.pop()console.log(n.val)// 栈后进先出,先右后左if(n.right) stack.push(n.right)if(n.left) stack.push(n.left)}
}中序遍历:
// 递归
const inorder = (root) => {if (!root) return;inorder(root.left);console.log(root.val);inorder(root.right);
};
// 非递归
const inorder = (root) => {if (!root) return;const stack = [];let p = root;while (stack.length || p) {// 所有的左子树进栈while (p) {stack.push(p);p = p.left;}//最尽头的左子树出栈const n = stack.pop();console.log(n.val);p = n.right;}
};后续遍历:
const postorder = (root) => {if (!root) return;postorder(root.left);postorder(root.right);console.log(root.val);
};
// 先序遍历是 根、左、右,后续遍历时:左、右、根,倒过来是根、右、左,只需要把先序遍历的后面两个颠倒顺序const postorder = (root) => {if (!root) return;const outputStack = [];const stack = [root];while (stack.length) {const n = stack.pop();outputStack.push(n);if (n.left) stack.push(n.left);if (n.right) stack.push(n.right);}while (outputStack.length) {const n = outputStack.pop();console.log(n.val);}
};相关文章:
数据结构——树
深度优先/广度优先遍历深度优先:访问根节点对根节点的 children 挨个进行深度优先遍历const tree {val: "a",children: [{val: "b",children: [{val: "d",children: [],},{val: "e",children: [],},],},{val: "c&quo…...

【华为OD机试模拟题】用 C++ 实现 - 找到它(2023.Q1)
最近更新的博客 【华为OD机试模拟题】用 C++ 实现 - 去重求和(2023.Q1) 文章目录 最近更新的博客使用说明找到它题目输入输出示例一输入输出示例二输入输出说明Code使用说明 参加华为od机试,一定要注意不要完全背诵代码,需要理解之后模仿写出,通过率才会高。 华为 OD …...

python中yield的使用
在 Python 中,yield 是一个关键字,它用于定义生成器函数。生成器函数是一个特殊的函数,可以返回一个迭代器,当生成器函数被调用时,它不会立即执行,而是返回一个生成器对象,通过迭代生成器对象可…...
GO进阶(4) 深入Go的内存管理
Go语言成为高生产力语言的原因之一自己管理内存:Go抛弃了C/C中的开发者管理内存的方式,实现了主动申请与主动释放管理,增加了逃逸分析和GC,将开发者从内存管理中释放出来,让开发者有更多的精力去关注软件设计ÿ…...
【C++】类与对象理解和学习(下)
放在专栏【C知识总结】,会持续更新,期待支持🌹建议先看完【C】类与对象理解和学习(上)【C】类与对象理解和学习(中)本章知识点概括Ⅰ本章知识点概括Ⅱ初始化列表前言在上一篇文章中,…...

【Neo4j】Spring Data Neo4j APi阅读随笔
引言 关于Spring boot整合Neo4j的官方api翻译&学习随笔 (TOC) 一、准备工作 1.注入依赖 <dependency><groupId>org.springframework.data</groupId><artifactId>spring-data-jpa</artifactId></dependency>2.配置yml文件 这里是本…...

JVM内存模型简介
1 程序计数器 程序计数器是一块较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器。字节码解释器工作时通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等功能都需要依赖这个计数器来完。 ja…...

k8s如何给node添加标签
一、为什么需要标签? k8s集群如果由大量节点组成,可将节点打上对应的标签,然后通过标签进行筛选及查看,更好的进行资源对象的相关选择与匹配 二、怎么查看目前node上具有的标签 [rootmaster01 ~]# kubectl get node --show-labels NAME …...
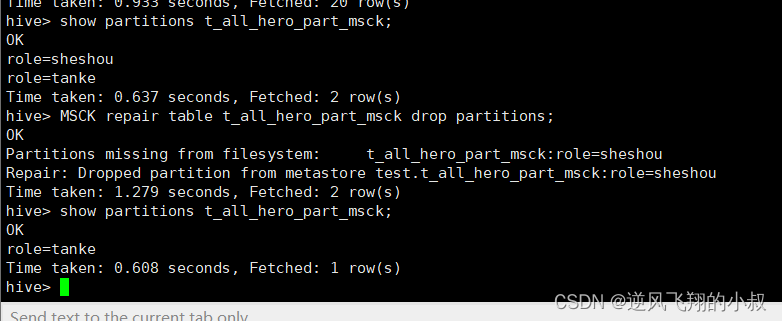
【大数据Hive】Hive ddl语法使用详解
一、前言 使用过关系型数据库mysql的同学对mysql的ddl语法应该不陌生,使用ddl语言来创建数据库中的表、索引、视图、存储过程、触发器等,hive中也提供了类似ddl的语法。本篇将详细讲述hive中ddl的使用。 二、hive - ddl 整体概述 在Hive中,DA…...
)
Connext DDS录制服务 Recording Service(2)
2.4 远程管理 控制客户端(如RTI管理控制台)可以使用此接口远程控制录制服务。 注:记录服务远程管理基于第10.3节中描述的RTI远程管理平台。有关录制服务中远程管理工作的详细讨论,请参阅该手册 下面是所有支持操作的API引用。 2.4.1 启用远程管理 默认情况下,在录制服务中…...

mysql数据类型选择
数据类型选择 完整性约束 是完整性约束是为保证数据库中数据的正确性和相容性,对关系模型提出的某种约束条件或规则。 通常包括:实体完整性约束、参照完整性约束、域完整性约束、用户自定义完整性约束。 实体完整性(Entity integrity)是指主键必须非空…...

【Java】Spring Boot 配置文件
文章目录SpringBoot 配置文件1. 配置文件的作用2. 配置文件的格式3. properties配置文件说明3.1 properties基本语法3.2 读取配置文件3.3 properties缺点分析4. yml配置文件说明4.1 yml基本语法4.2 yml使用进阶4.2.1 yml配置不同的数据类型及null4.2.1 yml配置的读取4.2.2 配置…...
AtCoder Beginner Contest 290 G. Edge Elimination(思维题 枚举+贪心)
题目 T(T<100)组样例,每次给出一棵深度为d的k叉树, 其中,第i层深的节点个数为 保证k叉树的所有节点个数tot不超过1e18, 求在k叉树上构建一棵大小恰为x的连通块,所需要断开的最少的树边的条数(x<tot<1e18)…...
数据挖掘概述
目录1、数据挖掘概述2、数据挖掘常用库3、模型介绍3.1 分类3.2 聚类3.3 回归3.4 关联3.5 模型集成4、模型评估ROC 曲线5、模型应用1、数据挖掘概述 数据挖掘:寻找数据中隐含的知识并用于产生商业价值 数据挖掘产生原因:海量数据、维度众多、问题复杂 数…...

linux kernel iio 架构
linux kernel iio 架构讲解Linux IIO(Industrial I/O)架构是Linux内核提供的一种用于支持各种类型传感器和数据采集设备的子系统,包括温度、压力、湿度、加速度、光度等多种传感器。IIO架构的核心是一个通用的IIO子系统,它提供了一…...

Socket通信详解
Socket通信详解 文章目录Socket通信详解Socket流程介绍函数介绍编程实例Socket流程介绍 socket通信类似于电话通信,其服务器基本流程就是 Created with Raphal 2.3.0安装电话socket()分配电话号码bind()连接电话线listen()拿起话筒accept()函数介绍 socket() 其中…...
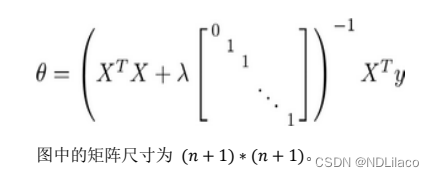
多分类、正则化问题
多分类问题 利用逻辑回归解决多分类问题,假如有一个训练集,有 3 个类别,分别为三角形 𝑦 1,方框𝑦 2,圆圈 𝑦 3。我们下面要做的就是使用一个训练集,将其分成 3 个二…...

史上最全面的软件测试面试题总结(接口、自动化、性能全都有)
目录 思维发散 Linux 测试概念和模型 测试计划与工具 测试用例设计 Web项目 Python基础 算法 逻辑 接口测试 性能测试 总结感谢每一个认真阅读我文章的人!!! 重点:配套学习资料和视频教学 思维发散 一个球ÿ…...

速来~与 Werner Vogels 博士一起探索敏捷性与创新速度一起提升的秘方
Amazon Web Services 的现代应用程序创新一直是 Amazon 公司坚持追求的核心目标。约20年前,我们经历了一次彻底的转型,旨在建立起“发明、发布、再发明、再发布、重新开始、洗牌、再重复”的快速迭代流程。正是此番探索,彻底改变了我们构建应…...

Apache Hadoop、HDFS介绍
目录Hadoop介绍Hadoop集群HDFS分布式文件系统基础文件系统与分布式文件系统HDFS简介HDFS shell命令行HDFS工作流程与机制HDFS集群角色与职责HDFS写数据流程(上传文件)HDFS读数据流程(下载文件)Hadoop介绍 用Java语言实现开源 允许…...

基于MCP协议构建阿里云SLS日志AI查询助手:原理、部署与实战
1. 项目概述:当阿里云SLS遇上MCP如果你正在用阿里云日志服务(SLS)做日志分析,同时又想用上像Claude、Cursor这类AI编程助手来帮你写查询、分析数据,那你可能已经感受到了一个痛点:如何在AI助手和你的日志数…...

Chrome for Testing 终极指南:5个实战技巧让自动化测试更稳定高效
Chrome for Testing 终极指南:5个实战技巧让自动化测试更稳定高效 【免费下载链接】chrome-for-testing 项目地址: https://gitcode.com/gh_mirrors/ch/chrome-for-testing Chrome for Testing 是 Google Chrome Labs 团队专门为浏览器自动化测试设计的 Chr…...

御坂翻译器:5分钟快速上手,让Galgame翻译不再困扰你
御坂翻译器:5分钟快速上手,让Galgame翻译不再困扰你 【免费下载链接】MisakaTranslator 御坂翻译器—Galgame/文字游戏/漫画多语种实时机翻工具 项目地址: https://gitcode.com/gh_mirrors/mi/MisakaTranslator 你是否曾因语言障碍而错过精彩的Ga…...

GAIA-DataSet:如何构建下一代AIOps智能运维的黄金基准?
GAIA-DataSet:如何构建下一代AIOps智能运维的黄金基准? 【免费下载链接】GAIA-DataSet GAIA, with the full name Generic AIOps Atlas, is an overall dataset for analyzing operation problems such as anomaly detection, log analysis, fault local…...

微信网页版访问终极指南:如何用wechat-need-web插件轻松解锁微信网页版
微信网页版访问终极指南:如何用wechat-need-web插件轻松解锁微信网页版 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 还在为微信网页版无…...

量子生成分类技术:原理、优势与应用解析
1. 量子生成分类技术概述量子生成分类(Quantum Generative Classification, QGC)是一种基于量子计算原理的新型机器学习范式,它从根本上改变了传统分类任务的实现方式。与常见的判别式学习方法不同,QGC采用生成式学习策略…...

React Native Navigation终极指南:构建原生移动应用导航的完整解决方案 [特殊字符]
React Native Navigation终极指南:构建原生移动应用导航的完整解决方案 🚀 【免费下载链接】react-native-navigation A complete native navigation solution for React Native 项目地址: https://gitcode.com/gh_mirrors/re/react-native-navigation…...

AI驱动个人网站生成器:基于Next.js与OpenAI的配置化数字名片
1. 项目概述:一个AI驱动的个人数字名片最近在折腾个人品牌和在线展示,发现了一个挺有意思的开源项目:zachlagden/iamjarvis.xyz。这本质上是一个基于AI的个人网站生成器,或者说,是一个高度定制化的“数字名片”。它的核…...

电气噪声抑制实战:从原理到电磁屏蔽的电子系统稳定性设计
1. 项目概述:无处不在的“隐形杀手”——电气噪声作为一名在电子硬件开发一线摸爬滚打了十多年的工程师,我处理过无数稀奇古怪的故障。很多时候,问题不是出在核心算法或主控芯片上,而是一个看不见摸不着的“隐形杀手”——电气噪声…...

Revelation光影包:物理渲染与启发式算法的视觉革命
Revelation光影包:物理渲染与启发式算法的视觉革命 【免费下载链接】Revelation An explorative shaderpack for Minecraft: Java Edition 项目地址: https://gitcode.com/gh_mirrors/re/Revelation Revelation不仅仅是一个Minecraft光影包——它是基于物理渲…...