Python爬取读书网的图片链接和书名并保存在数据库中
一个比较基础且常见的爬虫,写下来用于记录和巩固相关知识。
一、前置条件
本项目采用scrapy框架进行爬取,需要提前安装
pip install scrapy# 国内镜像
pip install scrapy -i https://pypi.douban.com/simple由于需要保存数据到数据库,因此需要下载pymysql进行数据库相关的操作
pip install pymysql# 国内镜像
pip install pymysql -i https://pypi.douban.com/simple同时在数据库中创立对应的表
create database spider01 charset utf8;use spider01;# 这里简单创建name和src
create table book(id int primary key auto_increment,name varchar(188),src varchar(188)
);二、项目创建
在终端进入准备存放项目的文件夹中
1、创建项目
scrapy startproject scrapy_book创建成功后,结构如下:
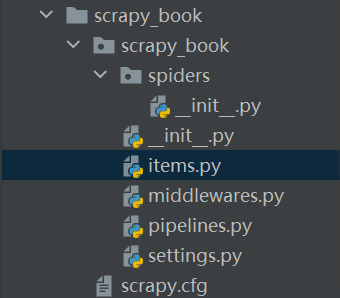
2、跳转到spiders路径
cd scrapy_book\scrapy_book\spiders3、生成爬虫文件
由于涉及链接的提取,这里生成CrawlSpider文件
scrapy genspider -t crawl read Www.dushu.com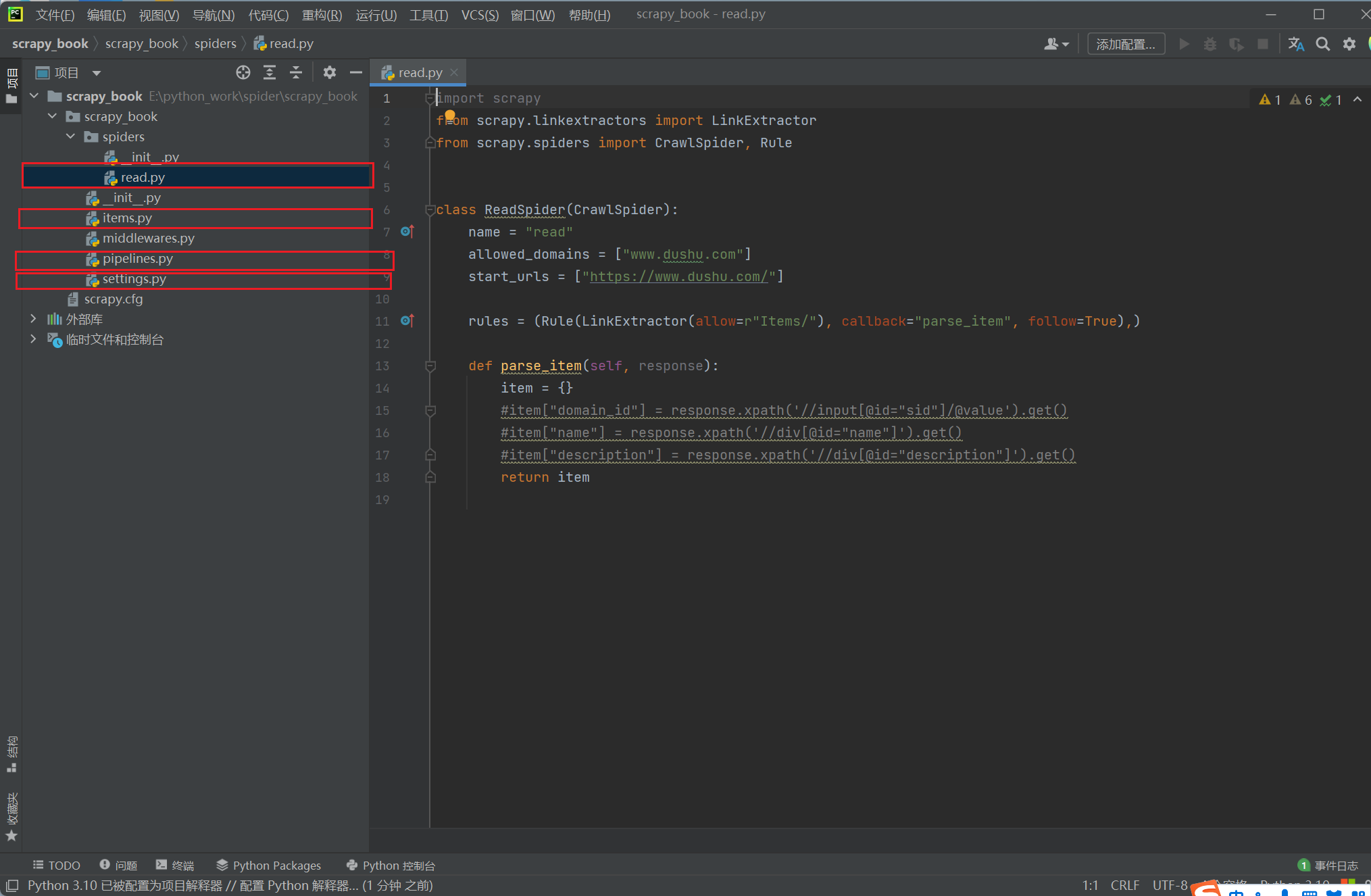
注意:先将第11行中follow的值改为False,否则会跟随从当前页面提取的链接继续爬取,避免过度下载
4、项目结构说明
接下来我们一共要修改4个文件完成爬取功能:
- read.py: 自定义的爬虫文件,完成爬取的功能
- items.py: 定义数据结构的地方,是一个继承自scrapy.Item的类
- pipelines.py: 管道文件,里面只有一个类,用于处理下载数据的后续处理
- setings.py: 配置文件 比如:是否遵循robots协议,User-Agent协议
三、网页分析
1、图书分析
读书网主页:

在读书网中,随便选取一个分类,这里以外国小说为例进行分析
这里我们简单爬取它的图片和书名,当然也可扩展

使用xpath语法对第一页的图片进行分析

由上图可以知道
书名://div[@class="bookslist"]//img/@alt
书图片地址://div[@class="bookslist"]//img/@data-original 不是src属性是因为页面图片使用懒加载
2、页码分析
第一页:外国小说 - 读书网|dushu.com 或 https://www.dushu.com/book/1176_1.html
第二页:外国小说 - 读书网|dushu.com
第三页:外国小说 - 读书网|dushu.com




发现规律,满足表达式:r"/book/1176_\d+\.html"
四、项目完成
1、修改items.py文件
自己定义下载数据的结构
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass ScrapyBookItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# 书名name = scrapy.Field()# 图片地址src = scrapy.Field()2、修改settings.py文件
将第65行的ITEM_PIPELINES的注释去掉,并在下面新增自己数据库的相关配置

3、修改pipnelines.py文件
进行下载数据的相关处理
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapter# 加载settings文件
from scrapy.utils.project import get_project_settings
import pymysqlclass ScrapyBookPipeline:# 最开始执行def open_spider(self,spider):settings = get_project_settings()# 获取配置信息self.host = settings['DB_HOST']self.port = settings['DB_PORT']self.user = settings['DB_USER']self.password = settings['DB_PASSWROD']self.name = settings['DB_NAME']self.charset = settings['DB_CHARSET']self.connect()def connect(self):self.conn = pymysql.connect(host=self.host,port=self.port,user=self.user,password=self.password,db=self.name,charset=self.charset)self.cursor = self.conn.cursor()# 执行中def process_item(self, item, spider):# 根据自己的表结构进行修改,我的是book表sql = 'insert into book(name,src) values("{}","{}")'.format(item['name'], item['src'])# 执行sql语句self.cursor.execute(sql)# 提交self.conn.commit()# 结尾执行def close_spider(self, spider):self.cursor.close()self.conn.close()4、修改read.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule# 导入时可能有下划线报错,是编译器问题,可以正常使用
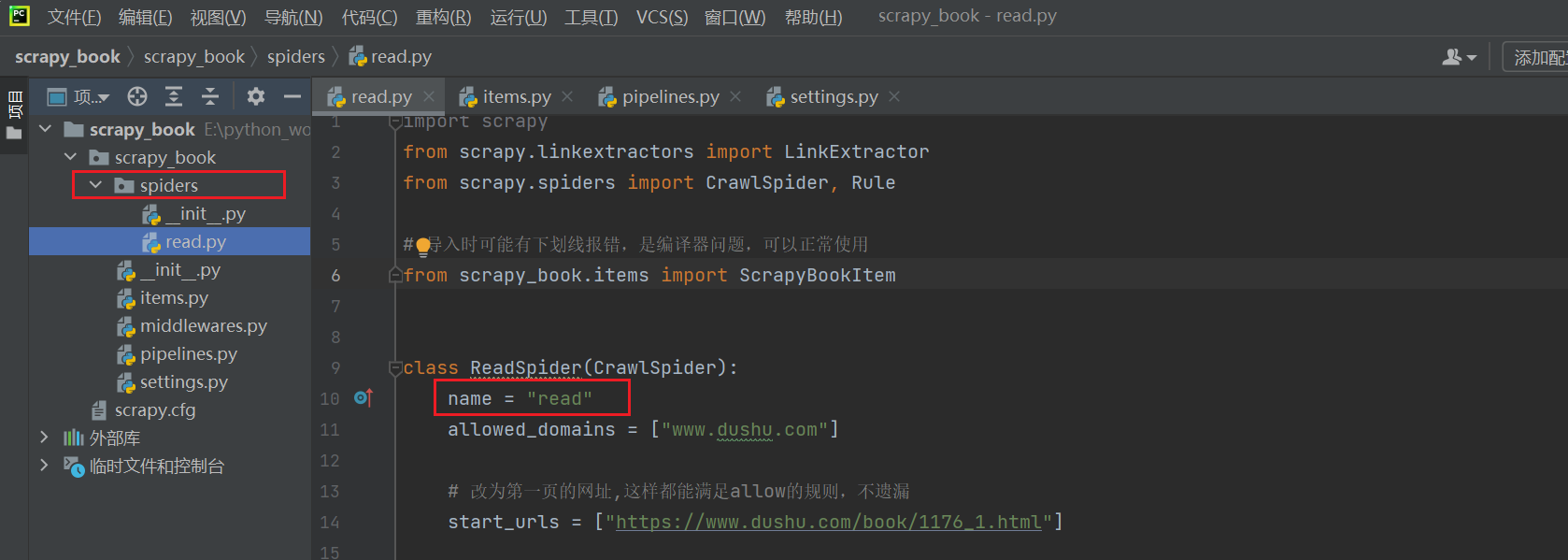
from scrapy_book.items import ScrapyBookItemclass ReadSpider(CrawlSpider):name = "read"allowed_domains = ["www.dushu.com"]# 改为第一页的网址,这样都能满足allow的规则,不遗漏start_urls = ["https://www.dushu.com/book/1176_1.html"]# allow属性提取指定链接,下面是正则表达式 callback回调函数 follow是否跟进就是按照提取连接规则进行提取这里选择Falserules = (Rule(LinkExtractor(allow=r"/book/1176_\d+\.html"), callback="parse_item", follow=False),)def parse_item(self, response):item = {}# item["domain_id"] = response.xpath('//input[@id="sid"]/@value').get()# item["name"] = response.xpath('//div[@id="name"]').get()# item["description"] = response.xpath('//div[@id="description"]').get()# 获取当前页面的所有图片img_list = response.xpath('//div[@class="bookslist"]//img')for img in img_list:name = img.xpath('./@alt').extract_first()src = img.xpath('./@data-original').extract_first()book = ScrapyBookItem(name=name, src=src)# 进入pipelines管道进行下载yield book
5、下载
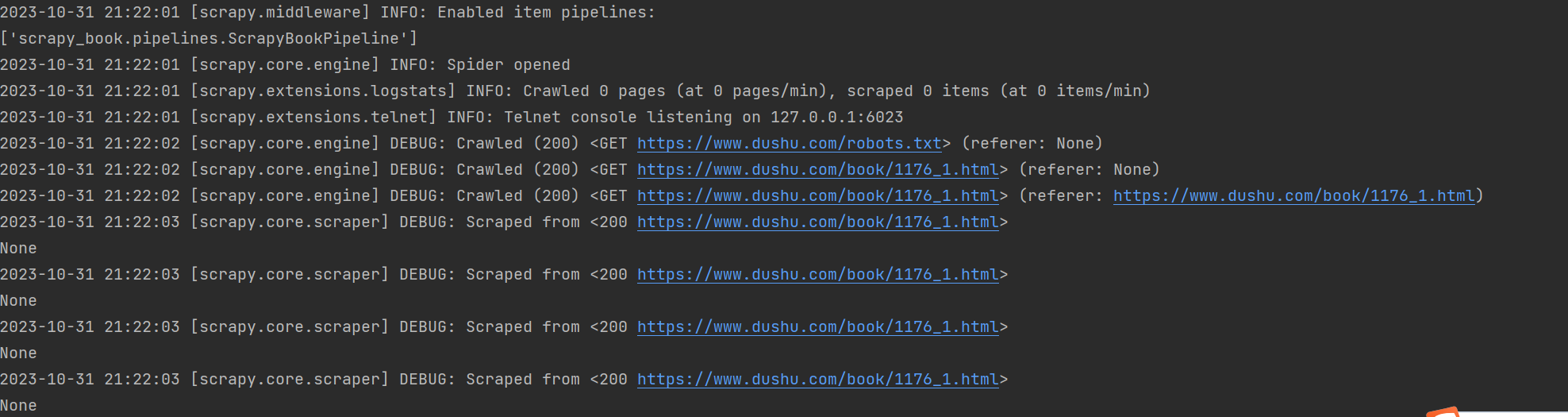
终端进入spiders文件夹,运行命令:scrapy crawl read
其中read是spiders文件夹下read.py中name的值

6、结果



一共下载了40(每一页的数据) * 13(页) = 520条数据
将read.py中的follow改为True即可下载该类书籍的全部数据,总共有100页,如果用流量的话谨慎下载,预防话费不足。

5、结语
这个爬虫项目应该可以适用于挺多场景的,不是特别多, 跟着写一下也没啥坏处。如果有代码的需求的话,日后会把项目的代码地址给出。因为自己学爬虫没多久,记录一下梳理下思路,也可以为以后有需要的时候做参考。
相关文章:
Python爬取读书网的图片链接和书名并保存在数据库中
一个比较基础且常见的爬虫,写下来用于记录和巩固相关知识。 一、前置条件 本项目采用scrapy框架进行爬取,需要提前安装 pip install scrapy# 国内镜像 pip install scrapy -i https://pypi.douban.com/simple 由于需要保存数据到数据库,因…...

js解决加油站
在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。 你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。 给定两个整数数组 gas 和 cost &…...
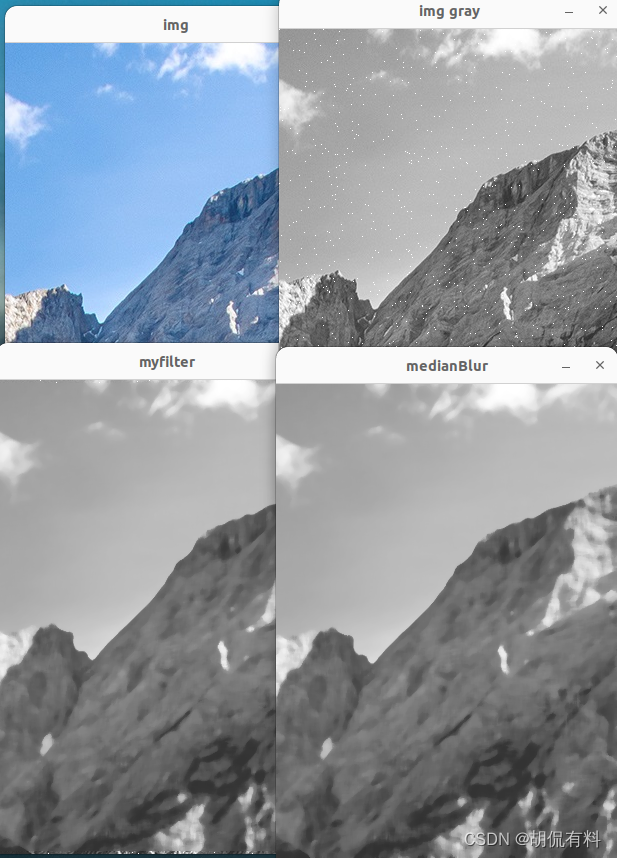
【c++|opencv】二、灰度变换和空间滤波---5.中值滤波
every blog every motto: You can do more than you think. https://blog.csdn.net/weixin_39190382?typeblog 0. 前言 1. 中值滤波 #include<iostream> #include<opencv2/opencv.hpp> #include"Salt.h"using namespace cv; using namespace std;voi…...

python之pytorch多进程
目录 1、创建并运行并行进程 2、使用队列(Queue)来共享数据 3、进程池 4、进程锁 5、比较使用多进程和使用单进程执行一段代码的时间消耗 6、共享变量 多进程是计算机科学中的一个术语,它是指同时运行多个进程,这些进程可以…...

sqoop 抽数报错com.mysql.cj.exceptions.WrongArgumentException: HOUR_OF_DAY: 2 -> 3
文章目录 1.sqoop 抽数报错: Caused by: com.mysql.cj.exceptions.WrongArgumentException: HOUR_OF_DAY: 2 -> 3 at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructor…...
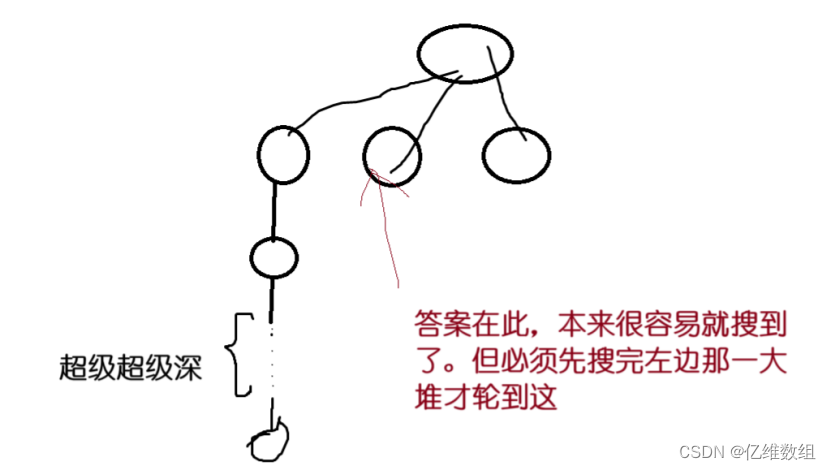
【Acwing170】加成序列(dfs+迭代加深+剪枝)题解和一点感想
本思路来自acwing算法提高课 题目描述 看本文需要准备的知识 1.dfs算法基本思想 2.对剪枝这个词有个简单的认识 迭代加深思想和此题分析 首先,什么是迭代加深呢?当一个问题的解有很大概率出现在递归树很浅的层,但是这个问题的解本身存在…...
Android开发知识学习——Kotlin进阶
文章目录 次级构造主构造器init 代码块构造属性data class相等性解构Elvis 操作符when 操作符operatorLambdainfix 函数嵌套函数注解使用处目标函数简化函数参数默认值扩展函数类型内联函数部分禁用用内联具体化的类型参数抽象属性委托属性委托类委托 Kotlin 标准函数课后题 次…...

iOS使用AVCaptureSession实现音视频采集
AVCaptureSession配置采集行为并协调从输入设备到采集输出的数据流。要执行实时音视频采集,需要实例化采集会话并添加适当的输入和输出。 AVCaptureSession:管理输入输出音视频流AVCaptureDevice:相机硬件的接口,用于控制硬件特性…...

springboot和flask整合nacos,使用openfeign实现服务调用,使用gateway实现网关的搭建(附带jwt续约的实现)
环境准备: 插件版本jdk21springboot 3.0.11 springcloud 2022.0.4 springcloudalibaba 2022.0.0.0 nacos2.2.3(稳定版)python3.8 nacos部署(docker) 先创建目录,分别创建config,logs…...
深入浅出排序算法之基数排序
目录 1. 前言 1.1 什么是基数排序⭐⭐⭐ 1.2 执行流程⭐⭐⭐⭐⭐ 2. 代码实现⭐⭐⭐ 3. 性能分析⭐⭐ 3.1 时间复杂度 3.2 空间复杂度 1. 前言 一个算法,只有理解算法的思路才是真正地认识该算法,不能单纯记住某个算法的实现代码! 1.…...
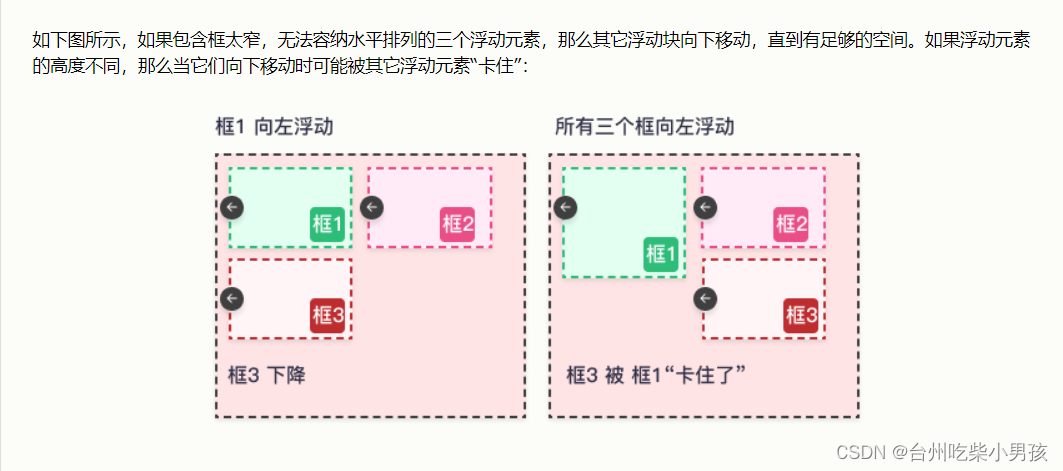
CSS选择器、CSS属性相关
CSS选择器 CSS属性选择器 通过标签的属性来查找标签,标签都有属性 <div class"c1" id"d1"></div>id值和class值是每个标签都自带的属性,还有另外一种:自定义属性 <div class"c1" id"d1&…...
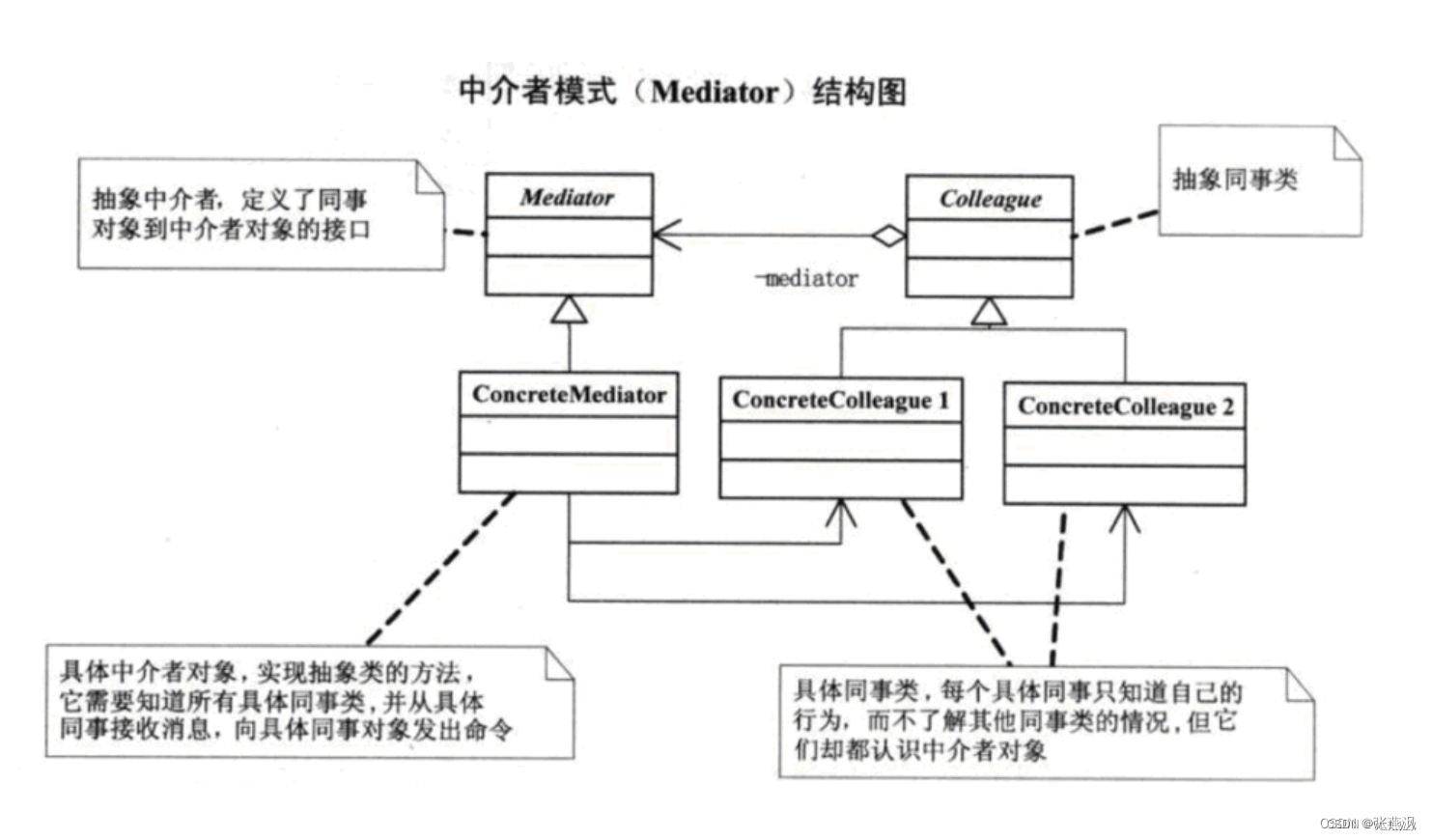
设计模式(21)中介者模式
一、介绍: 1、定义:中介者模式(Mediator Pattern)是一种行为型设计模式,它通过引入一个中介者对象来降低多个对象之间的耦合度。在中介者模式中,各个对象之间不直接进行通信,而是通过中介者对象…...

JVM虚拟机:通过一个例子解释JVM中栈结构的使用
代码 代码解析 main方法执行,创建栈帧并压栈。 int d8,d为局部变量,是基础类型,它位于虚拟机栈的局部变量表中 然后创建了一个TestDemo的对象,这个对象在堆中,并且这个对象的成员变量(day&am…...
会自动写代码的AI大模型来了!阿里云推出智能编码助手通义灵码
用大模型写代码是什么样的体验?10月31日,杭州云栖大会上,阿里云对外展示了一款可自动编写代码的 AI 助手,在编码软件的对话窗口输入“帮我用 python 写一个飞机游戏”,短短几秒,这款名为“通义灵码”的 AI …...

如何公网远程访问本地WebSocket服务端
本地websocket服务端暴露至公网访问【cpolar内网穿透】 文章目录 本地websocket服务端暴露至公网访问【cpolar内网穿透】1. Java 服务端demo环境2. 在pom文件引入第三包封装的netty框架maven坐标3. 创建服务端,以接口模式调用,方便外部调用4. 启动服务,出现以下信息表示启动成功…...

python 练习 在列表元素中合适的位置插入 输入值
目的: 有一列从小到大排好的数字元素列表, 现在想往其插入一个值,要求: 大于右边数字小于左边数字 列表元素: [1,4,6,13,16,19,28,40,100] # 方法: 往列表中添加一个数值,其目的方便元素位置往后…...
企业级JAVA、数据库等编程规范之命名风格 —— 超详细准确无误
🧸欢迎来到dream_ready的博客,📜相信你对这两篇博客也感兴趣o (ˉ▽ˉ;) 📜 表白墙/留言墙 —— 初级SpringBoot项目,练手项目前后端开发(带完整源码) 全方位全步骤手把手教学 📜 用户登录前后端…...
有什么可以自动保存微信收到的图片和视频的方法么
8-1 在一些有外勤工作的公司里,经常会需要在外面工作的同事把工作情况的图片发到指定微信或者指定的微信群里,以记录工作进展等,或者打卡等,对于外勤人员来说,也就发个图片的事,但是对于在公司里收图片的人…...
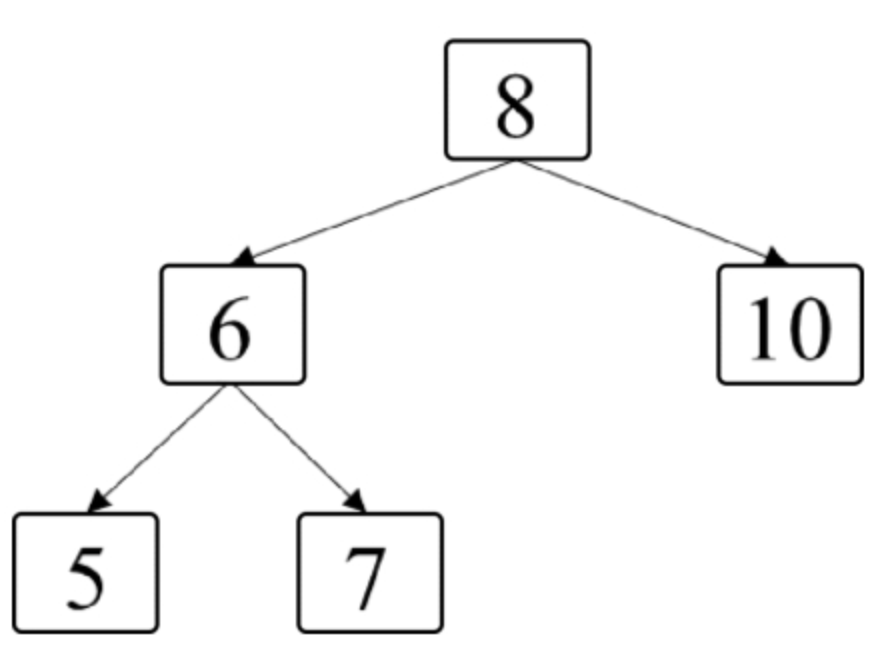
面试算法46:二叉树的右侧视图
题目 给定一棵二叉树,如果站在该二叉树的右侧,那么从上到下看到的节点构成二叉树的右侧视图。例如,图7.6中二叉树的右侧视图包含节点8、节点10和节点7。请写一个函数返回二叉树的右侧视图节点的值。 分析 既然这个题目和二叉树的层相关&a…...

ncmdumpGUI:3分钟掌握网易云音乐ncm格式转换的终极方案
ncmdumpGUI:3分钟掌握网易云音乐ncm格式转换的终极方案 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经在网易云音乐下载了心爱的歌曲&a…...

Taotoken用量看板如何帮助个人开发者管理月度预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助个人开发者管理月度预算 对于独立工作的个人开发者而言,项目预算往往是决定技术选型与使用策…...

ncmdumpGUI:3步解决网易云音乐ncm格式播放限制的终极方案
ncmdumpGUI:3步解决网易云音乐ncm格式播放限制的终极方案 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经在网易云音乐下载了心爱的歌曲…...

多维子集和问题:NP难问题的算法与应用解析
1. 多维子集和问题概述多维子集和问题(Multi-dimensional Subset Sum Problem)是计算复杂度理论中的经典NP难问题。简单来说,它要求在给定的n维向量集合中,找出一个子集,使得该子集中所有向量在每一维上的和恰好等于目标向量对应的分量。这个…...

数据流编排与异步任务调度中间件kelivo部署与实战指南
1. 项目概述与核心价值最近在折腾一个挺有意思的项目,叫“Chevey339/kelivo”。乍一看这个标题,可能有点摸不着头脑,它不像那些直接告诉你“XX管理系统”或“XX工具库”的项目名那么直白。但恰恰是这种看似神秘的命名,背后往往隐藏…...

从仿生结构到步态算法:8自由度并联腿机器狗行走全解析
1. 8自由度并联腿机器狗的结构奥秘 第一次拆解机器狗时,我对着那些复杂的连杆结构发了半小时呆。直到发现它的腿部运动原理和公园里的跷跷板惊人相似——这个发现让我瞬间理解了8自由度并联腿的精妙之处。这种结构就像给机器人装上了"机械肌腱"࿰…...

从零构建现代化工作流引擎:架构、实战与生产级部署指南
1. 项目概述:一个为专业开发者打造的现代化工作流引擎最近在GitHub上看到一个挺有意思的项目,叫rohitg00/pro-workflow。光看名字,你可能觉得这又是一个“工作流”工具,市面上这类工具已经多如牛毛了。但当我深入去研究它的源码、…...

免费开源鼠标连点器终极指南:5分钟掌握高效自动化技巧
免费开源鼠标连点器终极指南:5分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,…...

MCP服务器自动发现与管理工具mcpfinder详解
1. 项目概述:一个用于发现与管理MCP服务器的工具如果你正在构建或使用基于模型上下文协议(Model Context Protocol, 简称MCP)的应用,那么你很可能遇到过这样的困扰:手头有几个不同功能的MCP服务器ÿ…...

VR头显立体视觉姿态估计技术解析
1. 自我中心姿态估计的技术挑战与创新思路在虚拟现实和增强现实应用中,准确估计用户在三维空间中的身体姿态是实现自然交互的基础。传统基于外部摄像头的动作捕捉系统虽然精度较高,但存在设备复杂、使用场景受限等问题。相比之下,基于头戴设备…...