#集成学习#:bagging、boosting、stacking和blending
集成学习是一种机器学习方法,旨在提高单个模型的性能和鲁棒性。它基于这样一个假设:通过结合多个模型的预测结果,可以获得更好的预测性能,因为每个模型都可能从数据中提取不同的信息,因此他们的错误也可能是不同的,通过整合他们的预测结果可以减少这种错误的影响。
集成学习可以分为两类:bagging和boosting。
Bagging:是bootstrap aggregating的缩写,即自举汇聚法。它通过从原始数据集中进行有放回的随机抽样来创建多个训练集,每个训练集都用于训练一个独立的模型。这些模型的预测结果被组合起来,例如通过平均,以生成最终的集成模型的预测结果。Bagging可以用于降低模型方差,因为通过使用不同的训练集训练多个模型,我们可以减少模型对特定训练集的敏感性。
-
Boosting:是一种迭代算法,它通过逐步改善模型的预测能力来构建一个强大的集成模型。每个迭代的模型都是在先前模型的基础上构建的,即每个模型都尝试学习之前模型的错误。通过这种方式,Boosting可以减少模型偏差,因为它们能够逐步拟合训练数据中更复杂的模式。
-
除了Bagging和Boosting,还有其他类型的集成学习方法,例如Stacking和Blending。Stacking通过训练多个不同类型的基本模型,并使用第二个元模型(或叫做“超级学习器”)来组合它们的预测结果。Blending是一种类似于Stacking的技术,它在训练数据集上训练多个不同的模型,并使用一个加权平均来组合它们的预测结果。
集成学习可以提高预测性能和鲁棒性,但需要更多的计算资源和时间。它适用于大型数据集和需要高度精确的预测的情况。
使用pytorch分别实现bagging、boosting、stacking和blending
下面是使用PyTorch实现集成学习的例子:
首先,我们需要准备数据。这里我们使用PyTorch的MNIST数据集作为例子。我们将训练集和测试集分别加载进来:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.transforms as transforms# 定义数据转换
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))
])# 加载数据集
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)# 定义数据加载器
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False)接下来,我们可以定义基本模型,这里使用简单的卷积神经网络:
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.conv1 = nn.Conv2d(1, 10, kernel_size=5)self.conv2 = nn.Conv2d(10, 20, kernel_size=5)self.dropout = nn.Dropout2d()self.fc1 = nn.Linear(320, 50)self.fc2 = nn.Linear(50, 10)def forward(self, x):x = self.conv1(x)x = nn.functional.relu(nn.functional.max_pool2d(x, 2))x = self.conv2(x)x = nn.functional.relu(nn.functional.max_pool2d(self.dropout(x), 2))x = x.view(-1, 320)x = nn.functional.relu(self.fc1(x))x = self.dropout(x)x = self.fc2(x)return nn.functional.log_softmax(x, dim=1)现在,我们可以使用这个基本模型来构建集成学习模型。
bagging
首先是Bagging。在Bagging中,我们通过随机抽样训练集数据来构建多个基本模型。每个模型都是独立训练的,我们可以将它们的预测结果平均得到集成模型的输出。
# Bagging
n_models = 5
models = []
for i in range(n_models):model = CNN()optimizer = optim.Adam(model.parameters(), lr=0.01)criterion = nn.CrossEntropyLoss()for epoch in range(10):for batch_idx, (data, target) in enumerate(train_loader):optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()models.append(model)# 预测
def bagging_predict(models, data):outputs = torch.zeros(data.shape[0], 10)for model in models:output = torch.exp(model(data))outputs += outputreturn outputs.argmax(dim=1)# 评估
correct = 0
total = 0
with torch.no_grad():for data, target in test_loader:outputs = bagging_predict(models, data)total += target.size(0)correct += (outputs == target).sum().item()
print(f"Accuracy: {100 * correct / total:.2f}%")boosting
下一步是Boosting。在Boosting中,我们构建多个基本模型,每个模型都在前一个模型训练的基础上进行训练。每个模型的训练都会依据之前模型的预测结果进行加权,以便更好地捕获错误分类的样本。
# Boosting
n_models = 5
models = []
train_dataset_boost = list(train_dataset)
for i in range(n_models):model = CNN()optimizer = optim.Adam(model.parameters(), lr=0.01)criterion = nn.CrossEntropyLoss()for epoch in range(10):for batch_idx, (data, target) in enumerate(train_loader):if i == 0:weights = torch.ones(len(train_dataset))else:outputs = torch.exp(models[-1](data))weights = torch.zeros(len(train_dataset))for j, (d, t) in enumerate(train_dataset_boost):if t == outputs.argmax(dim=1)[j]:weights[j] = 1 / (outputs[j][t] + 1e-6)weights = weights / weights.sum()sampler = torch.utils.data.sampler.WeightedRandomSampler(weights, len(weights), replacement=True)train_loader_boost = torch.utils.data.DataLoader(train_dataset_boost, batch_size=64, sampler=sampler)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()models.append(model)# 更新训练集权重outputs = torch.exp(model(torch.stack([d for d, t in train_dataset_boost])))weights = torch.zeros(len(train_dataset))for j, (d, t) in enumerate(train_dataset_boost):if t == outputs.argmax(dim=1)[j]:weights[j] = 1 / (outputs[j][t] + 1e-6)weights = weights / weights.sum()train_dataset_boost = list(zip(train_dataset, weights))train_dataset_boost = [(d, t, w) for (d, t), w in train_dataset_boost]# 预测
def boosting_predict(models, data):outputs = torch.zeros(data.shape[0], 10)for model in models:output = torch.exp(model(data))outputs += outputreturn outputs.argmax(dim=1)# 评估
correct = 0
total = 0
with torch.no_grad():for data, target in test_loader:outputs = boosting_predict(models, data)total += target.size(0)correct += (outputs == target).sum().item()
print(f"Accuracy: {100 * correct / total:.2f}%")stacking
下一个集成方法是Stacking。在Stacking中,我们首先将训练集分成两部分,第一部分用于训练一组基本模型,第二部分用于为最终模型生成预测。对于第一部分,我们使用多个基本模型对其进行训练。对于第二部分,我们使用第一部分的基本模型的预测结果来训练一个最终的元模型,该元模型将基本模型的预测结果作为输入,并输出最终的预测结果。
# Stacking
n_models = 5
models = []
train_dataset_base, train_dataset_meta = torch.utils.data.random_split(train_dataset, [50000, 10000])
for i in range(n_models):model = CNN()optimizer = optim.Adam(model.parameters(), lr=0.01)criterion = nn.CrossEntropyLoss()for epoch in range(10):for batch_idx, (data, target) in enumerate(train_loader):optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()models.append(model)# 构建元数据集
meta_data = []
with torch.no_grad():for data, target in train_loader:outputs = []for model in models:outputs.append(model(data))outputs = torch.stack(outputs, dim=1)meta_data.append((outputs, target))# 构建元模型
class MetaModel(nn.Module):def __init__(self):super().__init__()self.fc1 = nn.Linear(5*10, 100)self.fc2 = nn.Linear(100, 10)def forward(self, x):x = x.view(x.shape[0], -1)x = F.relu(self.fc1(x))x = self.fc2(x)return xmeta_model = MetaModel()
optimizer = optim.Adam(meta_model.parameters(), lr=0.01)
criterion = nn.CrossEntropyLoss()# 元训练
for epoch in range(10):for data, target in meta_data:optimizer.zero_grad()output = meta_model(data.view(data.shape[0], -1))loss = criterion(output, target)loss.backward()optimizer.step()# 预测
def stacking_predict(models, meta_model, data):outputs = []with torch.no_grad():for model in models:output = model(data)outputs.append(output)outputs = torch.stack(outputs, dim=1)meta_output = meta_model(outputs.view(outputs.shape[0], -1))return meta_output.argmax(dim=1)# 评估
correct = 0
total = 0
with torch.no_grad():for data, target in test_loader:outputs = stacking_predict(models, meta_model, data)total += target.size(0)correct += (outputs == target).sum().item()
print(f"Accuracy: {100 * correct / total:.2f}%")blending
最后一个集成方法是Blending。Blending类似于Stacking,但它只使用一部分训练数据进行元模型的训练,而不是使用训练集的全部数据。在Blending中,我们首先将训练集分成两部分,第一部分用于训练多个基本模型,第二部分用于为最终模型生成预测。对于第二部分,我们使用第一部分的基本模型的预测结果来训练一个最终的元模型,该元模型将基本模型的预测结果作为输入,并输出最终的预测结果。
# Blending
n_models = 5
models = []
train_dataset_base, train_dataset_blend = torch.utils.data.random_split(train_dataset, [50000, 10000])
for i in range(n_models):model = CNN()optimizer = optim.Adam(model.parameters(), lr=0.01)criterion = nn.CrossEntropyLoss()for epoch in range(10):for batch_idx, (data, target) in enumerate(train_loader):if batch_idx < len(train_loader) // 2:optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()else:breakmodels.append(model)# 生成元数据
meta_data = []
with torch.no_grad():for data, target in train_loader:outputs = []for model in models:output = model(data)outputs.append(output)meta_data.append((torch.cat(outputs, dim=1), target))# 构建元模型
class MetaModel(nn.Module):def __init__(self):super().__init__()self.fc1 = nn.Linear(5*10, 100)self.fc2 = nn.Linear(100, 10)def forward(self, x):x = x.view(x.shape[0], -1)x = F.relu(self.fc1(x))x = self.fc2(x)return xmeta_model = MetaModel()
optimizer = optim.Adam(meta_model.parameters(), lr=0.01)
criterion = nn.CrossEntropyLoss()# 元训练
for epoch in range(10):for data, target in meta_data:optimizer.zero_grad()output = meta_model(data.view(data.shape[0], -1))loss = criterion(output, target)loss.backward()optimizer.step()# 预测
def blending_predict(models, meta_model, data):outputs = []with torch.no_grad():for model in models:output = model(data)outputs.append(output)meta_output = meta_model(torch.cat(outputs, dim=1))return meta_output.argmax(dim=1)# 评估
correct = 0
total = 0
with torch.no_grad():for data, target in test_loader:outputs = blending_predict(models, meta_model, data)total += target.size(0)correct += (outputs == target).sum().item()
print(f"Accuracy: {100 * correct / total:.2f}%")
这就是如何使用PyTorch实现Bagging、Boosting、Stacking和Blending的代码示例。这些集成方法是机器学习中非常有用的工具,可以帮助我们提高模型的准确性和稳健性,尤其是在处理大规模、高维度数据时。
相关文章:

#集成学习#:bagging、boosting、stacking和blending
集成学习是一种机器学习方法,旨在提高单个模型的性能和鲁棒性。它基于这样一个假设:通过结合多个模型的预测结果,可以获得更好的预测性能,因为每个模型都可能从数据中提取不同的信息,因此他们的错误也可能是不同的&…...

NCRE计算机等级考试Python真题(一)
第一套试题1、关于数据的存储结构,以下选项描述正确的是A.数据所占的存储空间量B.数据在计算机中的顺序存储方式C.数据的逻辑结构在计算机中的表示D.存储在外存中的数据正确答案: C2、关于线性链表的描述,以下选项中正确的是A.存储空间不一定…...

C#协变逆变
文章目录协变协变接口的实现逆变里氏替换原则协变 协变概念令人费解,多半是取名或者翻译的锅,其实是很容易理解的。 比如大街上有一只狗,我说大家快看,这有一只动物!这个非常自然,虽然动物并不严格等于狗…...

算法设计与分析期末考试复习(四)
贪心算法(Greedy Algorithm) 找零钱问题 假设有4种硬币,面值分别为:二角五分、一角、五分和一分,现在要找给顾客六角三分钱,如何找使得给出的硬币个数最少? 首先选出1个面值不超过六角三分的最…...
)
qsort函数排序数据 and 模拟实现qosrt函数(详解)
前言:内容包括使用库函数qsort排序任意类型的数据,模拟实现qsort函数(冒泡排序的逻辑) 我们先了解qsort函数的语法:qsort函数默认按照升序排序数据 void qsort (void* base, size_t num, size_t size,int (*compar)(…...

Mysql视图,存储过程,触发器,函数以及Mysql架构
一,视图视图是基于查询的一个虚拟表 , 也就是将sql语句封装起来, 要用的时候直接调用视图即可, select语句查询的表称为基表, 查询的结果集称为虚拟表, 基本表数据发生了改变, 那么视图也会发生改变, 使用视图就是为了简化查询语句.1.CREATE VIEW view_admin AS SELECT * FROM…...
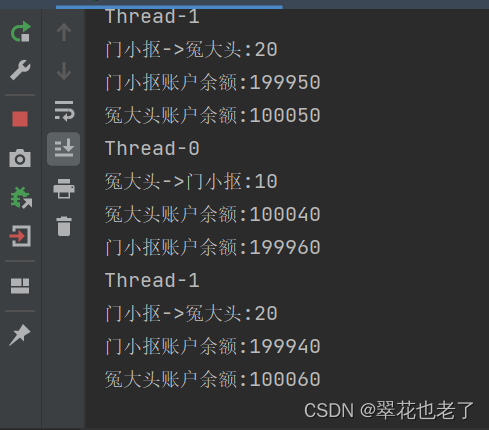
什么是线程死锁?如何解决死锁问题
死锁,一组互相竞争的资源的线程之间相互等待,导致永久阻塞的现象。 如下图所示: 与死锁对应的,还有活锁,是指线程没有出现阻塞,但是无限循环。 有一个经典的银行转账例子如下: 我们有个账户类…...
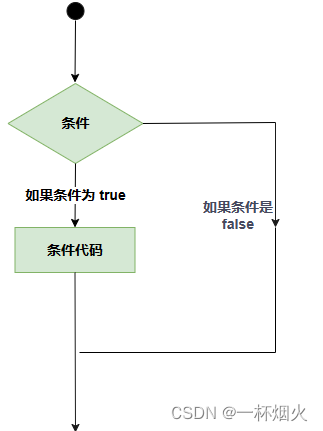
C语言几种判断语句简述
C 判断 判断结构要求程序员指定一个或多个要评估或测试的条件,以及条件为真时要执行的语句(必需的)和条件为假时要执行的语句(可选的)。 C 语言把任何非零和非空的值假定为 true,把零或 null 假定为 fals…...

【python学习笔记】:SQL常用脚本(二)
11、四舍五入ROUND函数 ROUND ( numeric_expression , length [ ,function ] ) function 必须为 tinyint、smallint 或 int。 如果省略 function 或其值为 0(默认值),则将舍入 numeric_expression。 如果指定了0以外的值,则将截…...

【Linux】进程地址空间
文章目录🎪 进程地址空间🚀1.写时拷贝与虚拟地址🚀2.地址空间引入🚀3.地址空间的意义⭐3.1 虚拟地址寻址⭐3.2 虚拟地址意义🎪 进程地址空间 地址空间(address space)表示任何一个计算机实体所…...

Qt音视频开发17-vlc内核回调拿图片进行绘制
一、前言 在众多播放器中,支持的种类格式众多,并支持DVD影音光盘,VCD影音光盘及各类流式协议,提供了sdk进行开发,这点是至关重要的,尽管很多优秀的播放器很牛逼,由于没有提供sdk第三方开发&…...

安装配置DHCP
本次实验采用CentOS71.检查在安装DHCP之前先使用rpm命令查看系统中已有的DHCP软件包rpm -qa | grep dhcp由此可知,系统中尚未安装DHCP软件包2.安装我们可以使用yum命令为系统安装DHCP软件包yum -y install dhcp安装完成后再次检查可以看到DHCP软件包3.配置dhcp配置文…...

MarkDown中写UML图的方法
目录序UML图之顺序图顺序图的四个要素关于消息箭头的语法Mermaid中顺序图的简单例子样例用小人表示对象为对象设置别名激活对象UML图之类图类图中常见的关系关于不同类型关系的语法Mermaid中类图的简单例子样例类定义的两种方式为类定义成员双向关系的表示多重性关系的表示UML之…...

Axure8设计—动态仪表盘
本次分享的的案例是Axure8制作的动态仪表盘,根据设置的数值,仪表盘指针旋转到相应的值位置 预览地址:https://2qiuwg.axshare.com 下载地址:https://download.csdn.net/download/weixin_43516258/87502161 一、制作原型 1、首先创建空白页…...
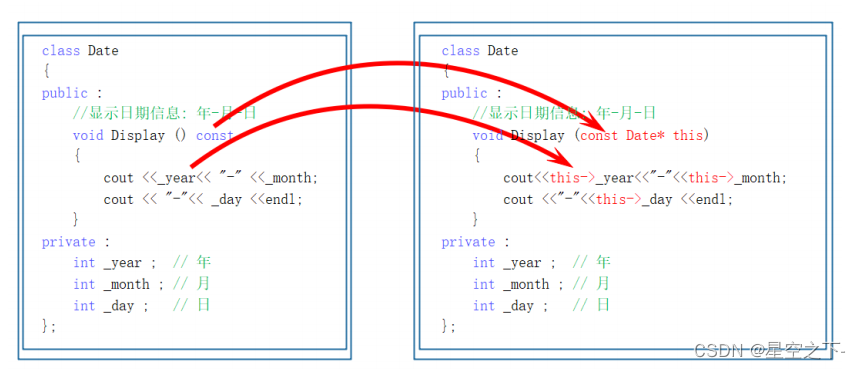
【C++】类和对象的六个默认成员函数
类的6个默认成员函数构造函数概念特性析构函数概念特性拷贝构造函数概念特征拷贝构造函数典型调用场景:赋值运算符重载运算符重载赋值运算符重载取地址及const取地址操作符重载类的6个默认成员函数 到底什么是类的6个默认成员函数呢?相信大家一定对此怀…...
4、算法MATLAB---认识矩阵
认识矩阵1、矩阵定义和基本运算1.1 赋值运算符:1.2 等号运算符:1.3 空矩阵1.4 一行一列矩阵1.5 行矩阵(元素用空格或逗号分隔)1.6 列矩阵(分号表示换行)1.7 m行n列的矩阵:行值用逗号间隔&#x…...
vue3+rust个人博客建站日记2-确定需求
反思 有人说过我们正在临近代码的终结点。很快,代码就会自动产生出来,不需要再人工编写。程序员完全没用了,因为商务人士可以从规约直接生成程序。 扯淡!我们永远抛不掉代码,因为代码呈现了需求的细节。在某些层面上&a…...

Linux安装云原生网关Kong/KongA
目录1 概述2 创建服务器3 安装postgres4 安装kong5 安装node6 安装KONGA1 概述 Kong Kong是一款基于OpenResty(NginxLua模块)编写的高可用、易扩展的开源API网关,专为云原生和云混合架构而建,并针对微服务和分布式架构进行了特别…...
)
Vue学习笔记(2)
2.1 事件处理 2.1.1 事件监听器 JavaScript:通过获取DOM对象再往DOM对象上使用addEventListener注册监听事件 const btn document.querySelector(#my-button) btn.addEventListener(click, function() {alert(点击事件!) })jQuery:通过$选择器绑定对象…...

2023年三月份图形化四级打卡试题
活动时间 从2023年3月1日至3月21日,每天一道编程题。 本次打卡的规则如下: 小朋友每天利用10~15分钟做一道编程题,遇到问题就来群内讨论,我来给大家答疑。 小朋友做完题目后,截图到朋友圈打卡并把打卡的截图发到活动群…...

自动驾驶人机交接:DMS与安全验证如何破解控制权转移困局
1. 自动驾驶人机交接的核心困境与行业分野最近几年,自动驾驶(AV)和高级驾驶辅助系统(ADAS)无疑是汽车科技领域最炙手可热的话题。无论是传统车企的“新四化”转型,还是科技公司的颠覆性入局,大家…...

Laravel RSS聚合器larafeed:现代化内容聚合后端解决方案
1. 项目概述:一个为Laravel打造的现代化RSS聚合器如果你正在用Laravel构建一个内容聚合平台、新闻阅读器,或者只是想为自己的个人博客添加一个“我最近在读什么”的订阅墙,那么你很可能需要处理RSS或Atom源。手动解析这些XML格式的源、处理缓…...

文献阅读 260511-Wildfire damages and the cost-effective role of forest fuel treatments
Wildfire damages and the cost-effective role of forest fuel treatments 来自 <https://www.science.org/doi/10.1126/science.aea6463> ## Abstract: Gave the core question: Wildfires are among the most pressing environmental challenges of the 21st century,…...

41《CAN总线报文周期、抖动与实时性分析》
CAN总线基础:从物理层到数据链路层的核心概念 一、一个让我熬夜的CAN问题 去年调试某款车载ECU时遇到个诡异现象:同一批次的控制器,有的在-20℃低温下CAN通信完全正常,有的却频繁丢帧。示波器挂上去一看,显性电平的下降沿斜率明显变缓,从正常的15ns拖到了40ns。查了三天…...
)
NotebookLM深度绑定Google Drive的终极方案(含OAuth2作用域最小化清单+服务账号部署模板)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM深度绑定Google Drive的终极方案(含OAuth2作用域最小化清单服务账号部署模板) NotebookLM 本地知识增强能力依赖于安全、稳定且权限精确的 Google Drive 数据接入。直…...

DICOM文件里除了图像,还藏了哪些信息?一份给开发者的隐私与元数据解析指南
DICOM文件里除了图像,还藏了哪些信息?一份给开发者的隐私与元数据解析指南 医疗影像数据是AI模型训练和医疗信息系统开发的重要基础,但许多开发者往往只关注图像像素本身,忽略了DICOM文件中蕴含的丰富元数据。这些元数据不仅包含关…...

从F103到F407:老STM32玩家升级指南,详解性能差异与项目移植实战
从F103到F407:老STM32玩家升级指南,详解性能差异与项目移植实战 对于熟悉STM32F1系列开发的工程师来说,升级到F407系列既是一次性能跃迁的机会,也伴随着学习曲线和移植挑战。本文将深入剖析两款芯片的差异,并提供可落地…...

MyBatis如何实现动态数据源切换?
MyBatis如何实现动态数据源切换 在现代应用中,特别是微服务架构中,使用多个数据库的情况越来越常见。MyBatis是一个流行的Java持久层框架,它允许我们方便地与多种数据库进行交互。在某些情况下,我们可能需要动态切换数据源&#x…...
)
QCustomPlot之颜色图实战:从静态数据到动态刷新的可视化(十四)
1. 认识QCPColorMap:从静态热力图开始 第一次接触QCustomPlot的颜色图功能时,我正需要可视化一组服务器CPU温度分布数据。当时尝试了多种图表类型,最终发现QCPColorMap简直是二维矩阵数据可视化的"神器"。这个类专门用于绘制热力图…...

智能开关总是断连?7 个行之有效的解决方法
三星智能切换(Samsung Smart Switch)是一款官方且易于使用的工具,专为三星用户设计,用于在移动设备之间或手机与电脑之间传输照片、联系人、应用程序、短信和其他数据。它支持无线 Wi-Fi 连接和有线 USB 连接,为数据迁…...