多模态对比语言图像预训练CLIP:打破语言与视觉的界限

项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域):汇总有意义的项目设计集合,助力新人快速实战掌握技能,助力用户更好利用 CSDN 平台,自主完成项目设计升级,提升自身的硬实力。

-
专栏订阅:项目大全提升自身的硬实力
-
[专栏详细介绍:项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域)
多模态对比语言图像预训练CLIP:打破语言与视觉的界限
一种基于多模态(图像、文本)对比训练的神经网络。它可以在给定图像的情况下,使用自然语言来预测最相关的文本片段,而无需为特定任务进行优化。CLIP的设计类似于GPT-2和GPT-3,具备出色的零射击能力,可以应用于多种多模态任务。
-
多模态对比语言图像预训练(CLIP)是一种神经网络模型,它通过多模态对比训练来学习图像和文本之间的关联。与传统的单模态预训练模型不同,CLIP能够同时处理图像和文本,从而更好地理解它们之间的语义关系。
-
CLIP的设计类似于GPT-2和GPT-3,是一种自回归语言模型。它通过对比学习来学习图像和文本之间的映射关系。在训练过程中,CLIP会接收一张图像和一个与之相关的文本片段,并学习如何将这两个模态的信息进行关联。通过这种方式,CLIP可以学会将图像与相应的文本片段进行匹配,从而在给定图像的情况下,使用自然语言来预测最相关的文本片段。
-
由于CLIP采用了对比学习的方法,它可以在无需为特定任务进行优化的前提下,表现出色地完成多种多模态任务。这使得CLIP成为了一种通用的多模态预训练模型,可以广泛应用于图像标注、视觉问答、图像生成等领域。
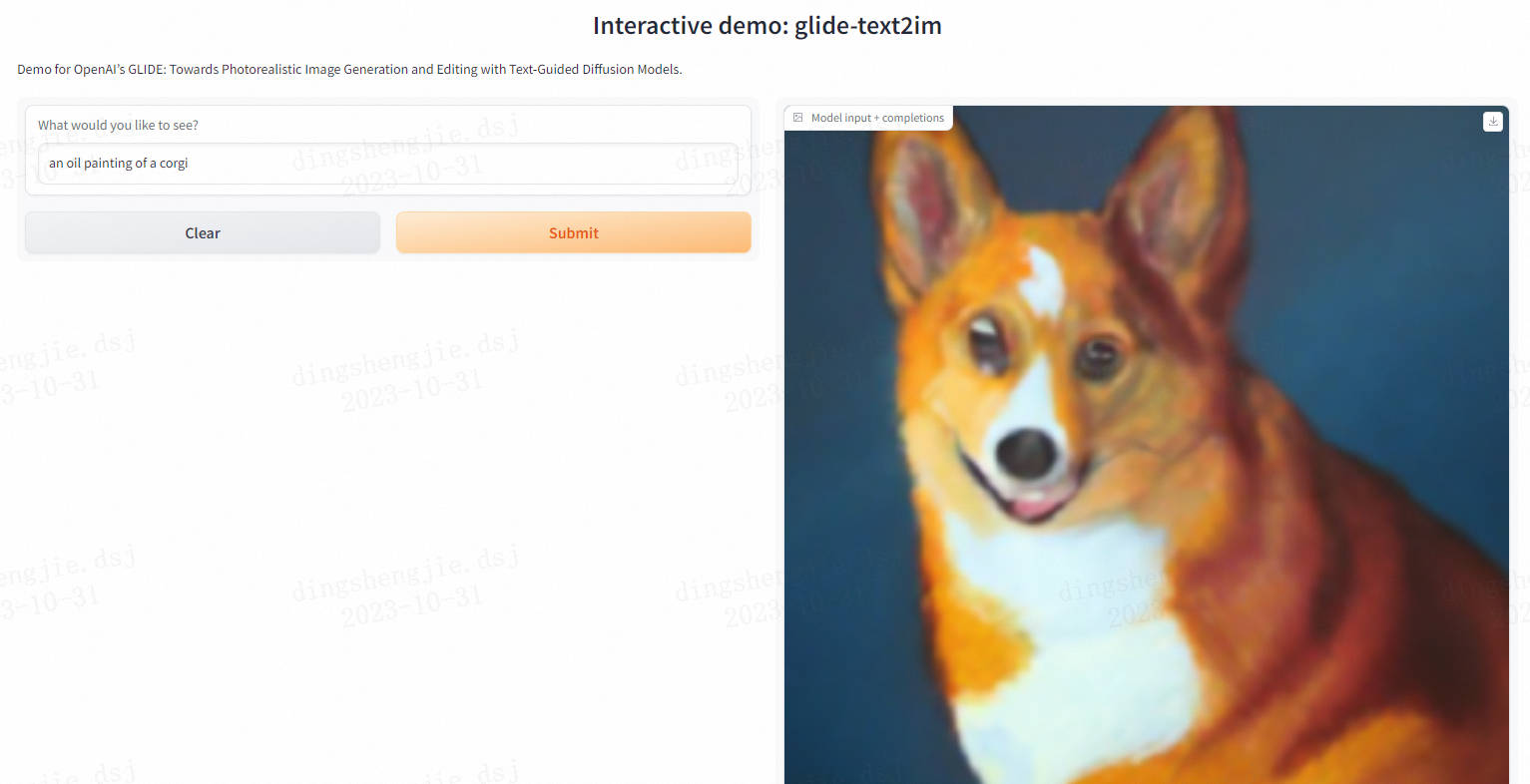
CLIP(对比语言图像预训练)是一种基于多种(图像、文本)对进行训练的神经网络。在给定图像的情况下,它可以用自然语言来预测最相关的文本片段,而无需直接针对任务进行优化,类似于GPT-2和gpt - 3的零射击能力。我们发现CLIP在不使用任何原始的1.28M标记示例的情况下,在ImageNet“零射击”上匹配原始ResNet50的性能,克服了计算机视觉中的几个主要挑战。
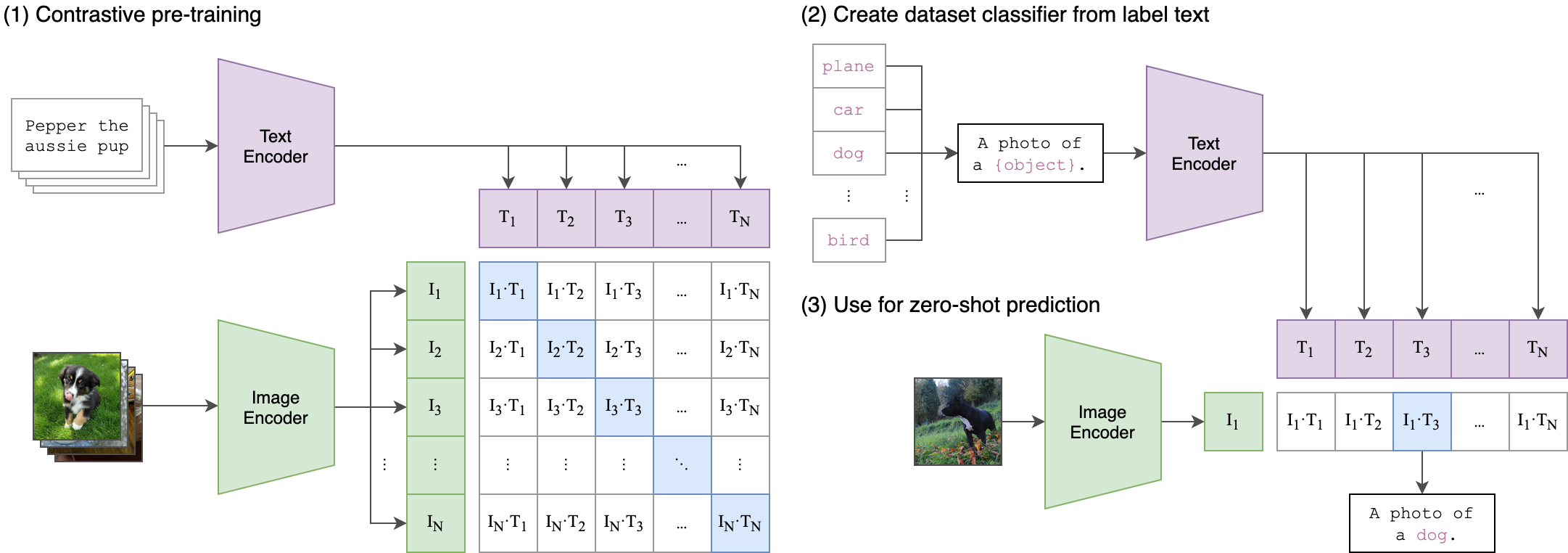
1.安装
ftfy
regex
tqdm
torch
torchvision$ conda install --yes -c pytorch pytorch=1.7.1 torchvision cudatoolkit=11.0
$ pip install ftfy regex tqdm
$ pip install git+https://github.com/openai/CLIP.git
Replace cudatoolkit=11.0 above with the appropriate CUDA version on your machine or cpuonly when installing on a machine without a GPU.
import torch
import clip
from PIL import Imagedevice = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)image = preprocess(Image.open("CLIP.png")).unsqueeze(0).to(device)
text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)with torch.no_grad():image_features = model.encode_image(image)text_features = model.encode_text(text)logits_per_image, logits_per_text = model(image, text)probs = logits_per_image.softmax(dim=-1).cpu().numpy()print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]]
- API
The CLIP module clip provides the following methods:
clip.available_models()
Returns the names of the available CLIP models.
clip.load(name, device=..., jit=False)
返回模型和模型所需的TorchVision转换,由’ clip.available_models() ‘返回的模型名指定。它将根据需要下载模型。’ name '参数也可以是本地检查点的路径。
可以选择性地指定运行模型的设备,默认是使用第一个CUDA设备(如果有的话),否则使用CPU。当’ jit ‘为’ False '时,将加载模型的非jit版本。
clip.tokenize(text: Union[str, List[str]], context_length=77)
返回一个LongTensor,其中包含给定文本输入的标记化序列。这可以用作模型的输入
’ clip.load() '返回的模型支持以下方法:
model.encode_image(image: Tensor)
给定一批图像,返回由CLIP模型的视觉部分编码的图像特征。
model.encode_text(text: Tensor)
给定一批文本tokens,返回由CLIP模型的语言部分编码的文本特征。
model(image: Tensor, text: Tensor)
给定一批图像和一批文本标记,返回两个张量,包含对应于每个图像和文本输入的logit分数。其值是对应图像和文本特征之间的相似度的余弦值,乘以100。
2.案例介绍
2.1 零样本能力
下面的代码使用CLIP执行零样本预测,如本文附录B所示。本例从CIFAR-100数据集获取图像,并在数据集的100个文本标签中预测最可能的标签。
import os
import clip
import torch
from torchvision.datasets import CIFAR100#Load the model
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load('ViT-B/32', device)#Download the dataset
cifar100 = CIFAR100(root=os.path.expanduser("~/.cache"), download=True, train=False)#Prepare the inputs
image, class_id = cifar100[3637]
image_input = preprocess(image).unsqueeze(0).to(device)
text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device)#Calculate features
with torch.no_grad():image_features = model.encode_image(image_input)text_features = model.encode_text(text_inputs)#Pick the top 5 most similar labels for the image
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)
values, indices = similarity[0].topk(5)#Print the result
print("\nTop predictions:\n")
for value, index in zip(values, indices):print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")
输出将如下所示(具体数字可能因计算设备的不同而略有不同):
Top predictions:snake: 65.31%turtle: 12.29%sweet_pepper: 3.83%lizard: 1.88%crocodile: 1.75%
Note that this example uses the encode_image() and encode_text() methods that return the encoded features of given inputs.
2.2 Linear-probe 评估
The example below uses scikit-learn to perform logistic regression on image features.
import os
import clip
import torchimport numpy as np
from sklearn.linear_model import LogisticRegression
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR100
from tqdm import tqdm#Load the model
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load('ViT-B/32', device)#Load the dataset
root = os.path.expanduser("~/.cache")
train = CIFAR100(root, download=True, train=True, transform=preprocess)
test = CIFAR100(root, download=True, train=False, transform=preprocess)def get_features(dataset):all_features = []all_labels = []with torch.no_grad():for images, labels in tqdm(DataLoader(dataset, batch_size=100)):features = model.encode_image(images.to(device))all_features.append(features)all_labels.append(labels)return torch.cat(all_features).cpu().numpy(), torch.cat(all_labels).cpu().numpy()#Calculate the image features
train_features, train_labels = get_features(train)
test_features, test_labels = get_features(test)#Perform logistic regression
classifier = LogisticRegression(random_state=0, C=0.316, max_iter=1000, verbose=1)
classifier.fit(train_features, train_labels)#Evaluate using the logistic regression classifier
predictions = classifier.predict(test_features)
accuracy = np.mean((test_labels == predictions).astype(float)) * 100.
print(f"Accuracy = {accuracy:.3f}")
Note that the C value should be determined via a hyperparameter sweep using a validation split.
3.更多资料参考:
- OpenCLIP: includes larger and independently trained CLIP models up to ViT-G/14
- Hugging Face implementation of CLIP: for easier integration with the HF ecosystem
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
相关文章:
多模态对比语言图像预训练CLIP:打破语言与视觉的界限
项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域):汇总有意义的项目设计集合,助力新人快速实…...

使用s3cmd访问S3存储 -【真实案例】
背景 项目中使用到了 S3 存储(基于华为云 OBS),并且在应用服务器上开通了到 S3 存储的防火墙。 👉 目标:在应用服务器上验证 S3 存储是否通畅可用。 👉 选型:经过分析,发现在 Linux 下可以使用 s3cmd 来访问 S3 存储。 s3cmd 简介 s3cmd 是一个开源免费的、基于 P…...
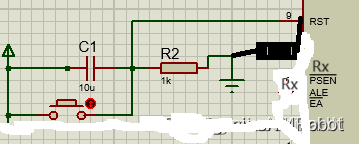
51单片机复位电容计算与分析(附带Proteus电路图)
因为iC x (dU/dt).在上电瞬间,U从0变化到U,所以这一瞬间就是通的,然后这就是一个直流回路,因为电容C直流中是断路的,所以就不通了。 然后来分析一下这个电容的电压到底是能不能达到单片机需要的复位电压。 这是一个线性电容&…...

前端性能瓶颈崩溃项目?Webpack助力解决!
🎬 江城开朗的豌豆:个人主页 🔥 个人专栏 :《 VUE 》 《 javaScript 》 📝 个人网站 :《 江城开朗的豌豆🫛 》 ⛺️ 生活的理想,就是为了理想的生活 ! 目录 ⭐ 专栏简介 📘 文章引言 一、背…...

纷享销客BI,助力企业激活数据价值,科学企业决策
10月25日上午,国家数据局正式挂牌成立,这标志着我国数字经济发展将进入新的发展阶段,也将有力促进数据要素技术创新、开发利用和有效治理,以数据强国支撑数字中国的建设。伴随数据作为企业新的生产要素的意义不断凸显,…...
SpringBoot整合阿里云OSS对象存储
文章目录 1、OSS介绍及开通1.1、阿里云OSS简介1.2、开通OSS 2、创建存储空间bucket及密钥获取2.1、创建存储空间2.2、获取密钥 3、OSS快速入门案例4、在springboot项目中整合4.1、将oss配置放到yml文件中4.2、创建Oss属性类,接收yml文件中的属性4.3、封装文件上传功…...
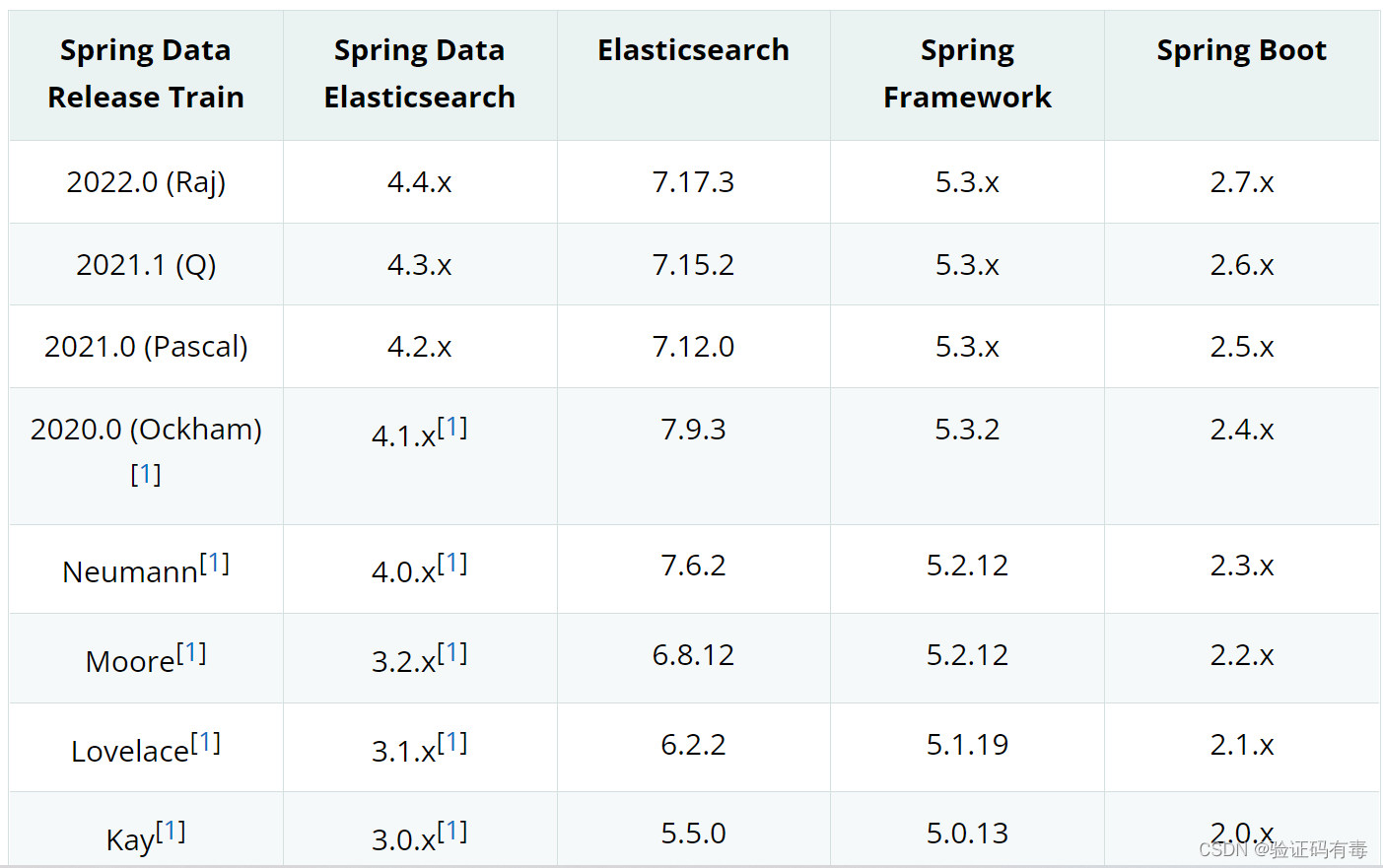
【ES专题】ElasticSearch快速入门
目录 前言从一个【搜索】说起 阅读对象阅读导航笔记正文一、全文检索1.1 什么是【全文检索】1.2 【全文检索】原理1.3 什么是倒排索引 二、ElasticSearch简介2.1 ElasticSearch介绍2.2 ElasticSearch应用场景2.3 数据库横向对比 三、ElasticSearch环境搭建3.1 Windows下安装3.2…...

案例分析真题-质量属性
案例分析真题-质量属性 2009 年真题 【问题1】 【问题2】 2011 年真题 【问题1】 骚戴理解:首先要知道这样的题目没有可靠性,只有可用性,更没有容错性,这里我(3)写成了i,而不是f,仔…...

微信小程序面试题之理论篇
本文内容,来源于极客学院的分享,这里只做引用。 说说你对微信小程序的理解?优缺点? 背景 小程序与H5 优缺点 优点:缺点: 说说微信小程序的生命周期函数有哪些? 应用的生命周期页面的生命期组件的生命周期执行过程 应…...

C++前缀和算法的应用:统计上升四元组
C前缀和算法的应用:统计上升四元组 本文涉及的基础知识点 C算法:前缀和、前缀乘积、前缀异或的原理、源码及测试用例 包括课程视频 题目 给你一个长度为 n 下标从 0 开始的整数数组 nums ,它包含 1 到 n 的所有数字,请你返回上…...

华泰证券:新奥能源:零售气待恢复,泛能与智家仍是亮点
来源:猛兽财经 作者:猛兽财经 猛兽财经获悉,由于新奥能源(02688)发布三季度经营数据: 1-3Q23:天然气零售量yoy-4.7%,燃气批发量yoy17.6%,综合能源销量yoy34.2%ÿ…...
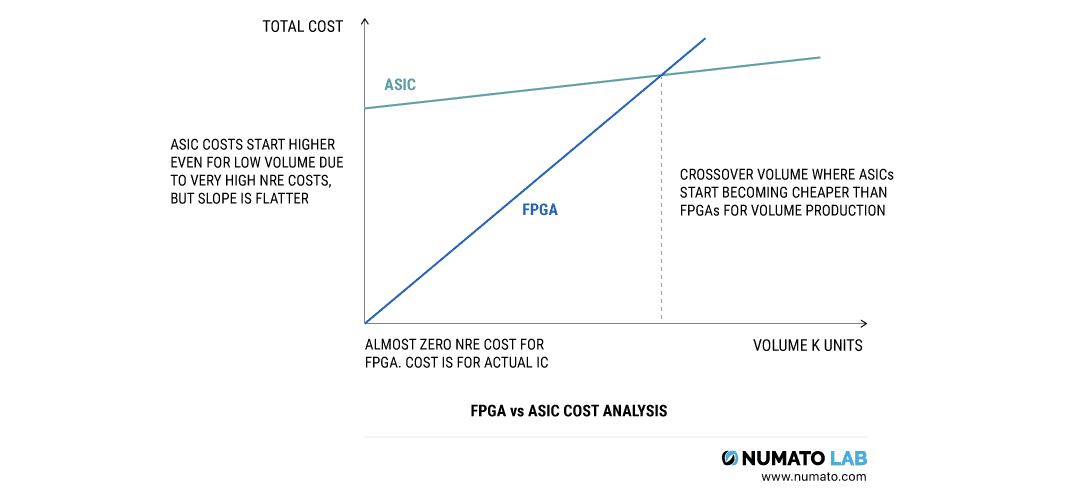
FPGA与ASIC有什么差异?二者该如何选用?
前言 对于一个数字电路的新手来说,这可能是会经常遇到的一个问题:FPGA和ASIC之间的区别是什么? 接下来本文将尝试讲解 “什么是FPGA?” 和 “什么是ASIC?”,然后讲述一些关于FPGA和ASIC的问题,例如它们之间…...

Kotlin run 用法
Kotlin 中的 .run 函数可以用于不同的场景,下面是一些常见的用法: 执行代码块并返回结果: val result run {// 在这里编写一些代码逻辑// 返回最后一个表达式的结果"Hello, Kotlin" }println(result) // 输出:Hello, …...
iZotope RX 10(音频修复和增强工具)
iZotope RX 10是一款音频修复和增强软件,主要特点包括: 声音修复:iZotope RX 10可以去除不良噪音、杂音、吱吱声等,使音频变得更加清晰干净。音频增强:iZotope RX 10支持对音频进行音量调节、均衡器、压缩器、限制器等…...
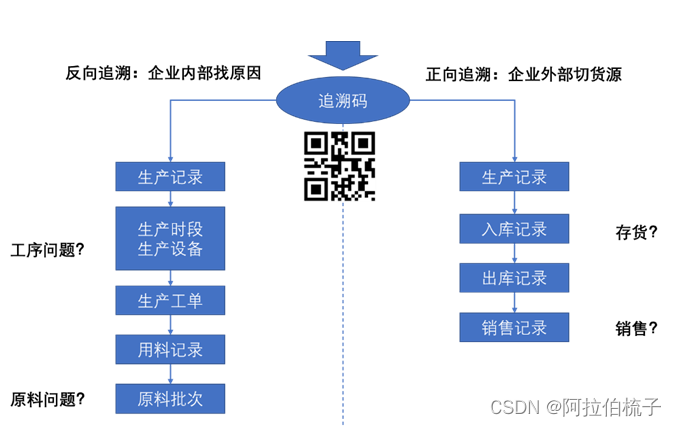
MES 价值点之数据追随
在现代制造业中,数据追溯已经越来越得到重视,特别是那些推行精益生产的企业重要性就更加突出了,而制造执行系统(MES)作为一种关键的生产管理工具,是能很好的为制造企业提供数据追溯功能。今天,和…...

yolo8制作自己的数据集训练和预测分割
一、训练coco128-seg数据集,增加一个类别 coco128-seg数据集下载: github链接 csdn链接 1、修改两个配置文件 (1)、修改"E:\python\ultralytics-main\ultralytics\cfg\datasets\coco128-seg.yaml"路径下的coco128-seg.yaml数据集配置文件,可以拷贝出来 修改数…...
分享一下怎么做一个同城配送小程序
如何制作一个同城配送小程序:功能特点、使用指南及未来展望 一、引言 随着互联网的快速发展,人们对于生活服务的需求越来越高。同城配送作为连接消费者与商家的桥梁,越来越受到人们的关注。本文将详细介绍如何制作一个同城配送小程序&#…...
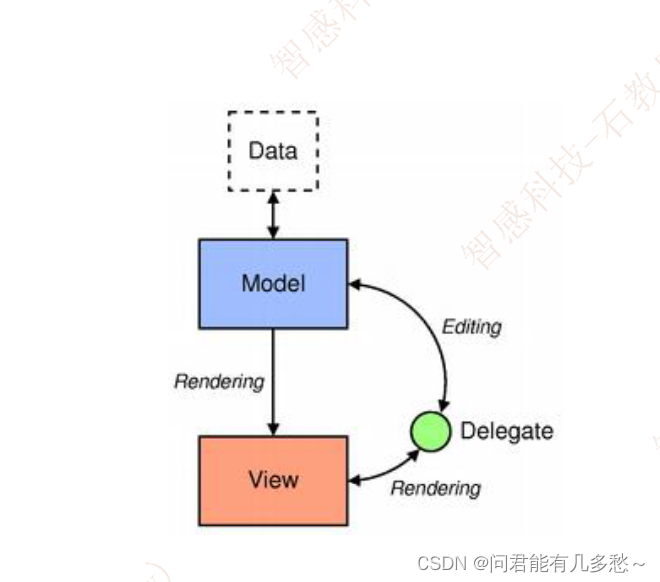
Qt 中model/View 架构 详解,以及案例实现相薄功能
model/View 架构 导读 我们的系统需要显示大量数据,比如从数据库中读取数据,以自己的方式显示在自己的应用程序的界面中。早期的 Qt 要实现这个功能,需要定义一个组件,在这个组件中保存一个数据对象,比如一个列表。我们对这个列表进行查找、插入等的操作,或者把修改…...

提高微星笔记本Linux下散热性能,MSI-EC 驱动新补丁发布
导读近日消息,今年早些时候,Linux 6.4 中添加了 MSI-EC 驱动程序,允许对 Linux 系统微星笔记本电脑进行更多控制。 MSI-EC 驱动程序近日迎来新补丁,为微星笔记本带来 Cooler Boost 功能。该功能允许提高笔记本电脑的风扇转速&…...

Apache Doris (五十): Doris表结构变更-动态分区(2)
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频 目录...

PostgreSQL CASE语句深度解析:性能、类型与NULL安全实战指南
1. 为什么你必须真正吃透 PostgreSQL 的 CASE 语句——它远不止是 SQL 里的“if-else”翻译器在 PostgreSQL 实战中,我见过太多人把CASE当成一个语法糖:写几个WHEN...THEN,加个ELSE,再套个END,就以为搞定了。结果呢&am…...

别再死记硬背了!用Multisim仿真+图解,5分钟搞懂三极管共射放大电路工作原理
用Multisim仿真图解5分钟掌握三极管共射放大电路三极管共射放大电路是电子技术中最基础也最关键的电路之一,但传统教材中复杂的公式推导和静态图解往往让初学者望而生畏。本文将带你用Multisim仿真软件,通过可视化的方式直观理解电路工作原理,…...
)
Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析)
更多请点击: https://intelliparadigm.com 第一章:Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析) 自2024年V6.2版本起,大量用户反馈 --stylize 与 --sharp 参数组合下图像边缘锐化效果显著弱化&am…...

全链路压测实战:双十一级别的流量,我是这样扛住的
作为一名在质量保障领域摸爬滚打多年的测试工程师,我深知传统的单接口压测在如今分布式架构下的无力感。当业务流量达到双十一这种脉冲式、高并发的级别时,任何一个非核心链路上的“短板”都可能引发系统性的雪崩。全链路压测不再是选择题,而…...

基于可解释机器学习的城市人口流动空间降尺度分析实践
1. 项目概述:从宏观到微观,解码城市脉搏在城市的肌理中,人口的流动如同血液的循环,承载着经济活力、社会互动与空间结构的全部信息。无论是城市规划师优化公交线路,还是商业分析师评估店铺选址,亦或是公共卫…...

翻译 GDB 官方文档
翻译 GDB 官方文档项目地址官方文档地址下载源码包编译html运行翻译程序项目地址 https://github.com/shootercheng/gdb-translate.git 项目结构 $ tree -L 1 . ├── cmd ├── go.mod ├── input ├── internal ├── LICENSE ├── output ├── README.md ├─…...

ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南
ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 核心关键词:ZTE光猫工厂模式解锁 长尾关键词: ZT…...

HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器
HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III地图编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hiv…...

告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南
告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南第一次点击"打包项目"按钮时,进度条仿佛被冻结的场景,每个UE5开发者都经历过。尤其当项目规模达到数十GB时,等待时间可能超过一小时——这背后隐藏着引擎底…...

三步破解百度网盘限速:免费获取真实下载链接的终极指南
三步破解百度网盘限速:免费获取真实下载链接的终极指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘几十KB的龟速下载而苦恼吗?想要彻…...