自动化测试如何解析excel文件?
前言
自动化测试中我们存放数据无非是使用文件或者数据库,那么文件可以是csv,xlsx,xml,甚至是txt文件,通常excel文件往往是我们的首选,无论是编写测试用例还是存放测试数据,excel都是很方便的。那么今天我们就把不同模块处理excel文件的方法做个总结,直接做封装,方便我们以后直接使用,增加工作效率。
openpyxl
openpyxl是个第三方库,首先我们使用命令 pip install openpyxl 直接安装
注:openpyxl操作excel时,行号和列号都是从1开始计算的
封装代码
"""
------------------------------------
@Time : 2019/5/13 18:00
@Auth : linux超
@File : ParseExcel.py
@IDE : PyCharm
@Motto: Real warriors,dare to face the bleak warning,dare to face the incisive error!
------------------------------------
"""
from openpyxl import load_workbook
from openpyxl.styles import Font
from openpyxl.styles.colors import BLACK
from collections import namedtupleclass ParseExcel(object):"""解析excel文件"""def __init__(self, filename, sheet_name=None):try:self.filename = filenameself.sheet_name = sheet_nameself.wb = load_workbook(self.filename)if self.sheet_name is None:self.work_sheet = self.wb.activeelse:self.work_sheet = self.wb[self.sheet_name]except FileNotFoundError as e:raise edef get_max_row_num(self):"""获取最大行号"""max_row_num = self.work_sheet.max_rowreturn max_row_numdef get_max_column_num(self):"""获取最大列号"""max_column = self.work_sheet.max_columnreturn max_columndef get_cell_value(self, coordinate=None, row=None, column=None):"""获取指定单元格的数据"""if coordinate is not None:try:return self.work_sheet[coordinate].valueexcept Exception as e:raise eelif coordinate is None and row is not None and column is not None:if isinstance(row, int) and isinstance(column, int):return self.work_sheet.cell(row=row, column=column).valueelse:raise TypeError('row and column must be type int')else:raise Exception("Insufficient Coordinate of cell!")def get_row_value(self, row):"""获取某一行的数据"""column_num = self.get_max_column_num()row_value = []if isinstance(row, int):for column in range(1, column_num + 1):values_row = self.work_sheet.cell(row, column).valuerow_value.append(values_row)return row_valueelse:raise TypeError('row must be type int')def get_column_value(self, column):"""获取某一列数据"""row_num = self.get_max_column_num()column_value = []if isinstance(column, int):for row in range(1, row_num + 1):values_column = self.work_sheet.cell(row, column).valuecolumn_value.append(values_column)return column_valueelse:raise TypeError('column must be type int')def get_all_value_1(self):"""获取指定表单的所有数据(除去表头)"""max_row_num = self.get_max_row_num()max_column = self.get_max_column_num()values = []for row in range(2, max_row_num + 1):value_list = []for column in range(1, max_column + 1):value = self.work_sheet.cell(row, column).valuevalue_list.append(value)values.append(value_list)return valuesdef get_all_value_2(self):"""获取指定表单的所有数据(除去表头)"""rows_obj = self.work_sheet.iter_rows(min_row=2, max_row=self.work_sheet.max_row,values_only=True) # 指定values_only 会直接提取数据不需要再使用cell().valuevalues = []for row_tuple in rows_obj:value_list = []for value in row_tuple:value_list.append(value)values.append(value_list)return valuesdef get_excel_title(self):"""获取sheet表头"""title_key = tuple(self.work_sheet.iter_rows(max_row=1, values_only=True))[0]return title_keydef get_listdict_all_value(self):"""获取所有数据,返回嵌套字典的列表"""sheet_title = self.get_excel_title()all_values = self.get_all_value_2()value_list = []for value in all_values:value_list.append(dict(zip(sheet_title, value)))return value_listdef get_list_nametuple_all_value(self):"""获取所有数据,返回嵌套命名元组的列表"""sheet_title = self.get_excel_title()values = self.get_all_value_2()excel = namedtuple('excel', sheet_title)value_list = []for value in values:e = excel(*value)value_list.append(e)return value_listdef write_cell(self, row, column, value=None, bold=True, color=BLACK):"""指定单元格写入数据:param work_sheet::param row: 行号:param column: 列号:param value: 待写入数据:param bold: 加粗, 默认加粗:param color: 字体颜色,默认黑色:return:"""try:if isinstance(row, int) and isinstance(column, int):cell_obj = self.work_sheet.cell(row, column)cell_obj.font = Font(color=color, bold=bold)cell_obj.value = valueself.wb.save(self.filename)else:raise TypeError('row and column must be type int')except Exception as e:raise eif __name__ == '__main__':pe = ParseExcel('testdata.xlsx')# sheet = pe.get_sheet_object('testcase')column_row = pe.get_max_column_num()print('最大列号:', column_row)max_row = pe.get_max_row_num()print('最大行号:', max_row)#cell_value_1 = pe.get_cell_value(row=2, column=3)print('第%d行, 第%d列的数据为: %s' % (2, 3, cell_value_1))cell_value_2 = pe.get_cell_value(coordinate='A5')print('A5单元格的数据为: {}'.format(cell_value_2))value_row = pe.get_row_value(3)print('第{}行的数据为:{}'.format(3, value_row))value_column = pe.get_column_value(2)print('第{}列的数据为:{}'.format(2, value_column))#values_1 = pe.get_all_value_1()print('第一种方式获取所有数据\n', values_1)values_2 = pe.get_all_value_2()print('第二种方式获取所有数据\n', values_2)title = pe.get_excel_title()print('表头为\n{}'.format(title))dict_value = pe.get_listdict_all_value()print('所有数据组成的嵌套字典的列表:\n', dict_value)#namedtuple_value = pe.get_list_nametuple_all_value()print('所有数据组成的嵌套命名元组的列表:\n', namedtuple_value)pe.write_cell(1, 2, 'Tc_title')
# add by linux超 at 2019/05/22 15:58
上面这个封装如如果用来同时操作同一个excel文件的两个sheet写入数据时,会有点小bug(写完后你会发现两个表单有一个是没有数据的)
其实原因很简单:不同对象拥有自己独立的属性, 当你写操作的时候其实每个对象只针对自己的表单做了保存,所以最后一个对象写完数据后,只保存了自己的表单,其他的对象的表单实际是没有保存的。针对这个问题,对上面封装的代码进行了轻微改动
"""
------------------------------------
@Time : 2019/5/22 9:11
@Auth : linux超
@File : ParseExcel.py
@IDE : PyCharm
@Motto: Real warriors,dare to face the bleak warning,dare to face the incisive error!
------------------------------------
"""
from openpyxl import load_workbook
from openpyxl.styles import Font
from openpyxl.styles.colors import BLACK
from collections import namedtupleclass ParseExcel(object):"""解析excel文件"""def __init__(self, filename):try:self.filename = filenameself.__wb = load_workbook(self.filename)except FileNotFoundError as e:raise edef get_max_row_num(self, sheet_name):"""获取最大行号"""max_row_num = self.__wb[sheet_name].max_rowreturn max_row_numdef get_max_column_num(self, sheet_name):"""获取最大列号"""max_column = self.__wb[sheet_name].max_columnreturn max_columndef get_cell_value(self, sheet_name, coordinate=None, row=None, column=None):"""获取指定单元格的数据"""if coordinate is not None:try:return self.__wb[sheet_name][coordinate].valueexcept Exception as e:raise eelif coordinate is None and row is not None and column is not None:if isinstance(row, int) and isinstance(column, int):return self.__wb[sheet_name].cell(row=row, column=column).valueelse:raise TypeError('row and column must be type int')else:raise Exception("Insufficient Coordinate of cell!")def get_row_value(self, sheet_name, row):"""获取某一行的数据"""column_num = self.get_max_column_num(sheet_name)row_value = []if isinstance(row, int):for column in range(1, column_num + 1):values_row = self.__wb[sheet_name].cell(row, column).valuerow_value.append(values_row)return row_valueelse:raise TypeError('row must be type int')def get_column_value(self, sheet_name, column):"""获取某一列数据"""row_num = self.get_max_column_num(sheet_name)column_value = []if isinstance(column, int):for row in range(1, row_num + 1):values_column = self.__wb[sheet_name].cell(row, column).valuecolumn_value.append(values_column)return column_valueelse:raise TypeError('column must be type int')def get_all_value_1(self, sheet_name):"""获取指定表单的所有数据(除去表头)"""max_row_num = self.get_max_row_num(sheet_name)max_column = self.get_max_column_num(sheet_name)values = []for row in range(2, max_row_num + 1):value_list = []for column in range(1, max_column + 1):value = self.__wb[sheet_name].cell(row, column).valuevalue_list.append(value)values.append(value_list)return valuesdef get_all_value_2(self, sheet_name):"""获取指定表单的所有数据(除去表头)"""rows_obj = self.__wb[sheet_name].iter_rows(min_row=2, max_row=self.__wb[sheet_name].max_row, values_only=True)values = []for row_tuple in rows_obj:value_list = []for value in row_tuple:value_list.append(value)values.append(value_list)return valuesdef get_excel_title(self, sheet_name):"""获取sheet表头"""title_key = tuple(self.__wb[sheet_name].iter_rows(max_row=1, values_only=True))[0]return title_keydef get_listdict_all_value(self, sheet_name):"""获取所有数据,返回嵌套字典的列表"""sheet_title = self.get_excel_title(sheet_name)all_values = self.get_all_value_2(sheet_name)value_list = []for value in all_values:value_list.append(dict(zip(sheet_title, value)))return value_listdef get_list_nametuple_all_value(self, sheet_name):"""获取所有数据,返回嵌套命名元组的列表"""sheet_title = self.get_excel_title(sheet_name)values = self.get_all_value_2(sheet_name)excel = namedtuple('excel', sheet_title)value_list = []for value in values:e = excel(*value)value_list.append(e)return value_listdef write_cell(self, sheet_name, row, column, value=None, bold=True, color=BLACK):if isinstance(row, int) and isinstance(column, int):try:cell_obj = self.__wb[sheet_name].cell(row, column)cell_obj.font = Font(color=color, bold=bold)cell_obj.value = valueself.__wb.save(self.filename)except Exception as e:raise eelse:raise TypeError('row and column must be type int')if __name__ == '__main__':pe = ParseExcel('testdata.xlsx')print(pe.get_all_value_2('division'))print(pe.get_list_nametuple_all_value('division'))column_row = pe.get_max_column_num('division')print('最大列号:', column_row)max_row = pe.get_max_row_num('division')print('最大行号:', max_row)cell_value_1 = pe.get_cell_value('division', row=2, column=3)print('第%d行, 第%d列的数据为: %s' % (2, 3, cell_value_1))cell_value_2 = pe.get_cell_value('division', coordinate='A5')print('A5单元格的数据为: {}'.format(cell_value_2))value_row = pe.get_row_value('division', 3)print('第{}行的数据为:{}'.format(3, value_row))value_column = pe.get_column_value('division', 2)print('第{}列的数据为:{}'.format(2, value_column))values_1 = pe.get_all_value_1('division')print('第一种方式获取所有数据\n', values_1)values_2 = pe.get_all_value_2('division')print('第二种方式获取所有数据\n', values_2)title = pe.get_excel_title('division')print('表头为\n{}'.format(title))dict_value = pe.get_listdict_all_value('division')print('所有数据组成的嵌套字典的列表:\n', dict_value)namedtuple_value = pe.get_list_nametuple_all_value('division')print('所有数据组成的嵌套命名元组的列表:\n', namedtuple_value)pe.write_cell('division', 1, 2, 'Tc_title')
xlrd
安装xlrd,此模块只支持读操作, 如果要写需要使用xlwt或者使用xlutils配合xlrd, 但是使用xlwt只能对新的excel文件进行写操作,无法对原有文件进行写, 所以这里选择是用xlutils
但是还有一个问题就是,如果使用xlutils, 那么我们的excel文件需要以.xls 为后缀。因为以xlsx为后缀无法实现写,会报错(亲测,因为formatting_info参数还没有对新版本的xlsx的格式完成兼容)
注:xlrd操作excel时,行号和列号都是从0开始计算的
封装代码
"""
------------------------------------
@Time : 2019/5/13 21:22
@Auth : linux超
@File : ParseExcel_xlrd.py
@IDE : PyCharm
@Motto: Real warriors,dare to face the bleak warning,dare to face the incisive error!
------------------------------------
"""
import xlrd
from xlutils import copy
from collections import namedtupleclass ParseExcel(object):# xlrd 解析excel, 行号和列号都是从0开始的def __init__(self, filename, sheet):try:self.filename = filenameself.sheet = sheetself.wb = xlrd.open_workbook(self.filename, formatting_info=True)if isinstance(sheet, str):self.sheet = self.wb.sheet_by_name(sheet)elif isinstance(sheet, int):self.sheet = self.wb.sheet_by_index(sheet)else:raise TypeError('sheet must be int or str')except Exception as e:raise edef get_max_row(self):"""获取表单的最大行号"""max_row_num = self.sheet.nrowsreturn max_row_numdef get_max_column(self):"""获取表单的最大列号"""min_row_num = self.sheet.ncolsreturn min_row_numdef get_cell_value(self, row, column):"""获取某个单元格的数据"""if isinstance(row, int) and isinstance(column, int):values = self.sheet.cell(row-1, column-1).valuereturn valueselse:raise TypeError('row and column must be type int')def get_row_values(self, row):"""获取某一行的数据"""if isinstance(row, int):values = self.sheet.row_values(row-1)return valueselse:raise TypeError('row must be type int')def get_column_values(self, column):"""获取某一列的数据"""if isinstance(column, int):values = self.sheet.col_values(column-1)return valueselse:raise TypeError('column must be type int')def get_table_title(self):"""获取表头"""table_title = self.get_row_values(1)return table_titledef get_all_values_dict(self):"""获取所有的数据,不包括表头,返回一个嵌套字典的列表"""max_row = self.get_max_row()table_title = self.get_table_title()value_list = []for row in range(2, max_row):values = self.get_row_values(row)value_list.append(dict(zip(table_title, values)))return value_listdef get_all_values_nametuple(self):"""获取所有的数据,不包括表头,返回一个嵌套命名元组的列表"""table_title = self.get_table_title()max_row = self.get_max_row()excel = namedtuple('excel', table_title)value_list = []for row in range(2, max_row):values = self.get_row_values(row)e = excel(*values)value_list.append(e)return value_listdef write_value(self, sheet_index, row, column, value):"""写入某个单元格数据"""if isinstance(row, int) and isinstance(column, int):if isinstance(sheet_index, int):wb = copy.copy(self.wb)worksheet = wb.get_sheet(sheet_index)worksheet.write(row-1, column-1, value)wb.save(self.filename)else:raise TypeError('{} must be int'.format(sheet_index))else:raise TypeError('{} and {} must be int'.format(row, column))if __name__ == '__main__':pe = ParseExcel('testdata.xls', 'testcase')print('最大行号:', pe.get_max_row())print('最大列号:', pe.get_max_column())print('第2行第3列数据:', pe.get_cell_value(2, 3))print('第2行数据', pe.get_row_values(2))print('第3列数据', pe.get_column_values(3))print('表头:', pe.get_table_title())print('所有的数据返回嵌套字典的列表:', pe.get_all_values_dict())print('所有的数据返回嵌套命名元组的列表:', pe.get_all_values_nametuple())pe.write_value(0, 1, 3, 'test')
pandas
pandas是一个做数据分析的库, 总是感觉在自动化测试中使用pandas解析excel文件读取数据有点大材小用,不论怎样吧,还是把pandas解析excel文件写一下把
我这里只封装了读,写的话我这有点小问题,后面改好再追加代码吧。
请先pip install pandas安装pandas
封装代码
"""
------------------------------------
@Time : 2019/5/13 14:00
@Auth : linux超
@File : ParseExcel_pandas.py
@IDE : PyCharm
@Motto: Real warriors,dare to face the bleak warning,dare to face the incisive error!
------------------------------------
"""
import pandas as pdclass ParseExcel(object):def __init__(self, filename, sheet_name=None):try:self.filename = filenameself.sheet_name = sheet_nameself.df = pd.read_excel(self.filename, self.sheet_name)except Exception as e:raise edef get_row_num(self):"""获取行号组成的列表, 从0开始的"""row_num_list = self.df.index.valuesreturn row_num_listdef get_cell_value(self, row, column):"""获取某一个单元格的数据"""try:if isinstance(row, int) and isinstance(column, int):cell_value = self.df.ix[row-2, column-1] # ix的行参数是按照有效数据行,且从0开始return cell_valueelse:raise TypeError('row and column must be type int')except Exception as e:raise edef get_table_title(self):"""获取表头, 返回列表"""table_title = self.df.columns.valuesreturn table_titledef get_row_value(self, row):"""获取某一行的数据, 行号从1开始"""try:if isinstance(row, int):row_data = self.df.ix[row-2].valuesreturn row_dataelse:raise TypeError('row must be type int')except Exception as e:raise edef get_column_value(self, col_name):"""获取某一列数据"""try:if isinstance(col_name, str):col_data = self.df[col_name].valuesreturn col_dataelse:raise TypeError('col_name must be type str')except Exception as e:raise edef get_all_value(self):"""获取所有的数据,不包括表头, 返回嵌套字典的列表"""rows_num = self.get_row_num()table_title = self.get_table_title()values_list = []for i in rows_num:row_data = self.df.ix[i, table_title].to_dict()values_list.append(row_data)return values_listif __name__ == '__main__':pe = ParseExcel('testdata.xlsx', 'testcase')print(pe.get_row_num())print(pe.get_table_title())print(pe.get_all_value())print(pe.get_row_value(2))print(pe.get_cell_value(2, 3))print(pe.get_column_value('Tc_title'))
总结
使用了3种方法,4个库 xlrd,openpyxl,xlwt,pandas 操作excel文件,个人感觉还是使用openpyxl比较适合在自动化中使用,当然不同人有不同选择,用哪个区别也不是很大。
以上3种方法,都可以拿来直接使用,不需要再做封装了 !
Python接口自动化测试零基础入门到精通(2023最新版)
相关文章:

自动化测试如何解析excel文件?
前言 自动化测试中我们存放数据无非是使用文件或者数据库,那么文件可以是csv,xlsx,xml,甚至是txt文件,通常excel文件往往是我们的首选,无论是编写测试用例还是存放测试数据,excel都是很方便的。…...

职场好物:乐歌M9S升降办公电脑台,告别久坐办公,升职加薪就选它
办公是现代生活不可避免的组成部分,科技的快速发展,给了我们更多新的生活方式,促使我们更加关注自己的身体状况,我们挨过了饭都吃不饱的年代,随着办公人群的不断扩张,不知道你有没有发现身边人或多或少都有…...
springboot+vue基于Hadoop短视频流量数据分析与可视化系统的设计与实现【内含源码+文档+部署教程】
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ 🍅由于篇幅限制,想要获取完整文章或者源码,或者代做&am…...

审核 Microsoft SQL Server 日志
手动审核数据库活动是一项艰巨的任务,有效完成审计的最佳方法是使用简化和自动化数据库监控的综合解决方案,该解决方案还应使数据库管理员能够监控、跟踪和即时识别任何操作问题的根本原因,并实时检测对机密数据的未经授权的访问。 什么是 S…...
【NLP】什么是语义搜索以及如何实现 [Python、BERT、Elasticsearch]
语义搜索是一种先进的信息检索技术,旨在通过理解搜索查询和搜索内容的上下文和含义来提高搜索结果的准确性和相关性。与依赖于匹配特定单词或短语的传统基于关键字的搜索不同,语义搜索会考虑查询的意图、上下文和语义。 语义搜索在搜索结果的精度和相关…...

【JavaScript】JS基础语法
1 JavaScript 的书写形式 1.1 行内式 直接嵌入到 html 元素内部 <input type"button" value"按钮" onclick"alert(hello JavaScript)" >1.2 内嵌式 写在script标签内 <script>alert("haha")</script>1.3 外部式…...

06-云计算概览及问题关注
容器生态系统 容器生态系统包含核心技术、平台技术和支持技术。 1-1 容器核心技术 其中容器核心技术指的是能让容器在主机服务器上运行的技术,包含容器规范、容器 runtime、容器管理工具、容器生态工具、registries、容器 OS。 容器规范: 容器除了常…...
怎么监控钉钉聊天记录内容(监控钉钉聊天记录的3种形式)
企业沟通工具的普及,越来越多的企业开始使用钉钉作为内部沟通工具。然而,对于企业管理者来说,如何监控钉钉聊天记录内容成为了一个重要的问题。本文将介绍几种方法,帮助企业管理者实现监控钉钉聊天记录内容的目的。 一、钉钉自带功…...

深入理解强化学习——强化学习的历史:时序差分学习
分类目录:《深入理解强化学习》总目录 相关文章: 强化学习的历史:最优控制 强化学习的历史:试错学习 强化学习的历史:试错学习的发展 强化学习的历史:K臂赌博机、统计学习理论和自适应系统 强化学习的…...

OpenCloudOS9操作系统搭建Confluence8.0.4企业WIKI
OpenCloudOS9操作系统搭建Confluence8.0.4企业WIKI 1. 概要2. 系统基础环境配置3. 安装并配置MySQL3.1. 安装MySQL3.2. MySQL基本配置3.3. 创建Confluence数据库4. 安装并配置Confluence5. 破解Confluence6. 优化配置Confluence7. confluence对接Windows AD域环境1. 概要 Atlas…...

03-Vue中的常用指令的使用,事件及其修饰符
常用指令 指令语法和插值语法 Vue框架中的所有指令的名字都以v-开始,完整语法格式<HTML标签 v-指令名:参数"javascript表达式(表达式的结果是一个值)"></HTML标签>: 指令的职责是当表达式的值改变时,将其产生的连带影响,响应式地作用于DOM元素不是所有…...

ScrapeKit库中Swift爬虫程序写一段代码
以下是一个使用ScrapeKit库的Swift爬虫程序,用于爬取网页视频的代码: import ScrapeKit// 创建一个配置对象,用于指定爬虫ip服务器信息 let config Configuration(proxyHost: "duoip", proxyPort: 8000)// 创建一个爬虫对象 let s…...
总感觉戴助听器耳朵又闷又堵怎么办?
随着助听器技术的进步发展,这些问题都有了一定程度的改善。例如,现在的助听器变得越来越小巧,外形更加美观和隐蔽;各种降噪技术和验配技巧也提升了助听器的音质和清晰度。 但是,还有一个问题困扰着很多助听器用户&…...
编程助手DevChat:让开发更轻松
#AI编程助手哪家好?DevChat“真”好用 # 目录 前言一、安装Vscode1、下载链接2、安装 二、注册DevChat1、打开注册页2、验证成功完成邮箱绑定3、绑定微信可获得8元 三、安装插件四、配置Access Key1、获取Access Key2、设置Access Key①、点击左下角管理(…...

稳定扩散的高分辨率图像合成
推荐稳定扩散AI自动纹理工具:DreamTexture.js自动纹理化开发包 1、稳定扩散介绍 通过将图像形成过程分解为去噪自动编码器的顺序应用,扩散模型 (DM) 在图像数据及其他数据上实现了最先进的合成结果。此外,它们的配方…...
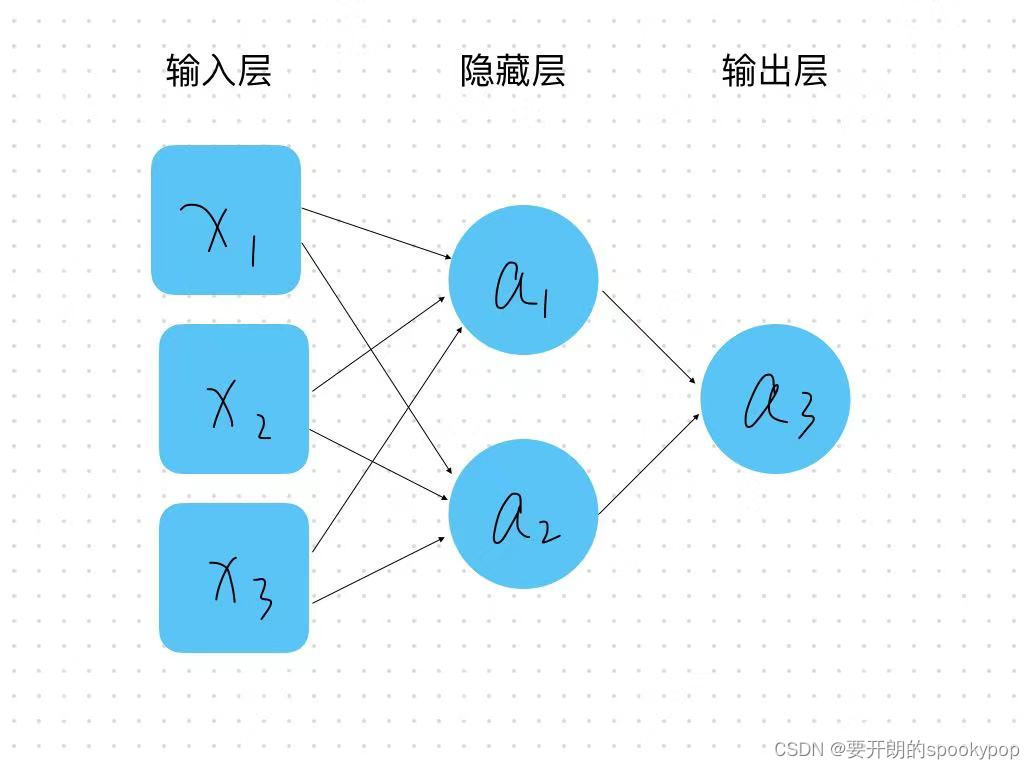
3 Tensorflow构建模型详解
上一篇:2 用TensorFlow构建一个简单的神经网络-CSDN博客 本篇目标是介绍如何构建一个简单的线性回归模型,要点如下: 了解神经网络原理构建模型的一般步骤模型重要参数介绍 1、神经网络概念 接上一篇,用tensorflow写了一个猜测西…...
智慧农场牧场小程序源码 智慧农业认养系统源码
智慧农场牧场小程序源码 智慧农业认养系统源码 要了解源码的,看文末。 随着科技的进步和人们对绿色食品的需求增加,智慧农场正成为未来农业发展的方向。智慧农场是指运用先进的技术手段,如物联网、云计算、智能控制技术、大数据分析等&…...

3D数据过滤为2D数据集并渲染
开发环境: Windows 11 家庭中文版Microsoft Visual Studio Community 2019VTK-9.3.0.rc0vtk-example参考代码 代码逻辑:初始化数据集points -> 添加数据集到polydata -> 通过vtkVertexGlyphFilter过滤(带顶点、单元数据)po…...
)
第十一章 ObjectScript 系统宏(二)
文章目录 第十一章 ObjectScript 系统宏(二) 宏引用FormatText(text, arg1, arg2, ...)FormatTextHTML(text, arg1, arg2, ...)FormatTextJS(text, arg1, arg2, ...)GETERRORCODE(sc)GETERRORMESSAGE(sc,num)ISERR(sc)ISOK(sc)Text(text, domain, langua…...

跨境电商大作战:2023黑色星期五准备指南
黑色星期五,作为全球购物狂欢的象征,已经成为了电商业务的一年一度的重要节点。尤其对于跨境电商来说,这一天意味着巨大的商机和挑战。为了在这个竞争激烈的时刻脱颖而出,跨境电商必须做好充分的准备。Nox聚星在这里给大家分享几个…...

Stitches项目架构分析:RequireJS模块化设计与Grunt构建流程完全指南 [特殊字符]
Stitches项目架构分析:RequireJS模块化设计与Grunt构建流程完全指南 🚀 【免费下载链接】stitches HTML5 Sprite Sheet Generator 项目地址: https://gitcode.com/gh_mirrors/sti/stitches Stitches是一个基于HTML5的雪碧图生成器,它采…...

告别道路预测老套路:用ParkPredict+模型思路,解决停车场里的‘鬼探头’难题
破解泊车场景预测困局:ParkPredict模型的技术革新与实践停车场里的每一次转向、倒车和避让,都是对自动驾驶系统预测能力的极限挑战。与开放道路的规则明确不同,这里没有清晰的车道线指引,没有统一的行驶方向,只有随时可…...

解决Claude Code访问不稳定与Token不足的痛点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code访问不稳定与Token不足的痛点 许多开发者将Claude Code作为日常编程的得力助手,用于代码生成、问题调试…...
 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南)
SAP-ABAP:变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南
变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南如果把内表比作一张内存中的“数据库表”,那么键就是这张表的索引甚至主键。键的设计直接决定了数据的唯一性…...

打不开JupyterLab
因为安装某些依赖导致JupyterLab的依赖被动升级或降级,从而影响了JupyterLab的运行,此时可以SSH登录到实例,然后输入jupyter-lab命令进行确认,如果执行命令报错则说明是此问题,那么可以通过pip install jupyterlab再次…...

深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南
深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 在当今网络设备管理领域,获取设备完整控制…...

网飞成立 AI 动画工作室,开启流媒体“原生 AI 制片时代”,中外布局逻辑有何不同?
1. Netflix“偷跑”在影视巨头关于 AIGC 的军备竞赛中,Netflix 再次加速。据外媒 TheVerge 报道,网飞于今年 3 月成立了名为 "INKubator" 的工作室,这是全球流媒体巨头中首个以生成式人工智能为核心的动画制作部门。此动作引发全球…...

PrivacyGuard实战:基于实证差分隐私的机器学习模型隐私审计框架
1. 项目概述与核心价值在过去的几年里,我亲眼见证了机器学习模型从实验室走向银行、医疗、社交网络等各个敏感领域的全过程。模型性能的每一次飞跃都令人兴奋,但随之而来的隐私泄露事件也一次次为我们敲响警钟。一个在医疗数据上训练出的诊断模型&#x…...

3步快速上手Whisper-WebUI:轻松实现语音转字幕的完整指南
3步快速上手Whisper-WebUI:轻松实现语音转字幕的完整指南 【免费下载链接】Whisper-WebUI A Web UI for easy subtitle using whisper model. 项目地址: https://gitcode.com/gh_mirrors/wh/Whisper-WebUI 还在为视频制作繁琐的字幕而烦恼吗?Whis…...

终极虚拟显示器解决方案:ParsecVDisplay完整使用指南
终极虚拟显示器解决方案:ParsecVDisplay完整使用指南 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd ParsecVDisplay是一个基于Parsec虚拟显示驱动(VDD)的独立应用程序…...