Hadoop、Hive安装
一、 工具
Linux系统:Centos,版本7.0及以上
JDK:jdk1.8
Hadoop:3.1.3
Hive:3.1.2
虚拟机:VMware
mysql:5.7.11
工具下载地址: https://pan.baidu.com/s/1JYtUVf2aYl5–i7xO6LOAQ
提取码: xavd
提示:以下是本篇文章正文内容,下面案例可供参考
二、JDK安装
下载jdk-8u181-linux-x64.tar.gz包,将此包上传至/opt 目录下。
cd /opt
解压安装包 tar zxvf jdk-8u181-linux-x64.tar.gz
删除安装包 rm -f jdk-8u181-linux-x64.tar.gz
使用root权限编辑profile文件设置环境变量
vi/etc/profile
export JAVA_HOME= /usr/java/jdk1.8.0_181
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
让修改的文件生效
source /etc/profile
三、安装mysql
下载mysql-5.7.11-linux-glibc2.5-x86_64.tar.gz包,将此包上传至/opt目录下,并改名mysql。
cd /opttar -xzvf mysql-5.7.11-linux-glibc2.5-x86_64.tar.gz mv mysql-5.7.11-linux-glibc2.5-x86_64 mysql
先查询是否存在用户组
groups mysql
创建用户组和用户名
groupadd mysql && useradd -r -g mysql mysql
授予文件数据目录权限
chown mysql:mysql -R /opt/mysql/data
修改/etc/my.cnf配置文件,没有得到话就创建
vi /etc/my.cnf
[mysqld]
port = 3306
user=mysql
basedir=/opt/mysql/
datadir=/opt/mysql/data
socket=/tmp/mysql.sock
symbolic-links=0[mysqld_safe]
log-error=/opt/mysql/data/mysql.log
pid-file=/opt/mysql/data/mysql.pid[client]
port=3306
default-character-set=utf8
初始化mysql服务
cd /opt/mysql/bin
执行命令,然后会有一个默认密码,有的人这里会报错是因为没有安装libaio,这里就先安装一遍
yum install libaio -y
./mysqld --defaults-file=/etc/my.cnf --user=mysql --initialize

启动mysql
cp /opt/mysql/support-files/mysql.server /etc/init.d/mysql
service mysql start
进入目录
cd /opt/mysql/bin
登录,输入刚才的临时密码就可以了(直接复制粘贴)
./mysql -u root -p
修改密码,我设置的密码是root,在最后面,根据自己需要进行设置
alter user 'root'@'localhost' identified with mysql_native_password BY 'root';
刷新,使操作生效
flush privileges;
更改数据库连接权限
use mysql;
update user set host='%' where user = 'root';
flush privileges;
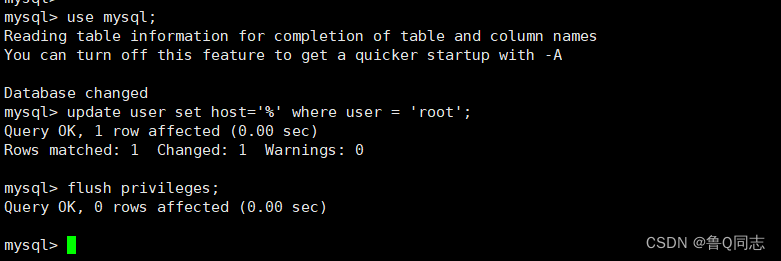
退出
exit
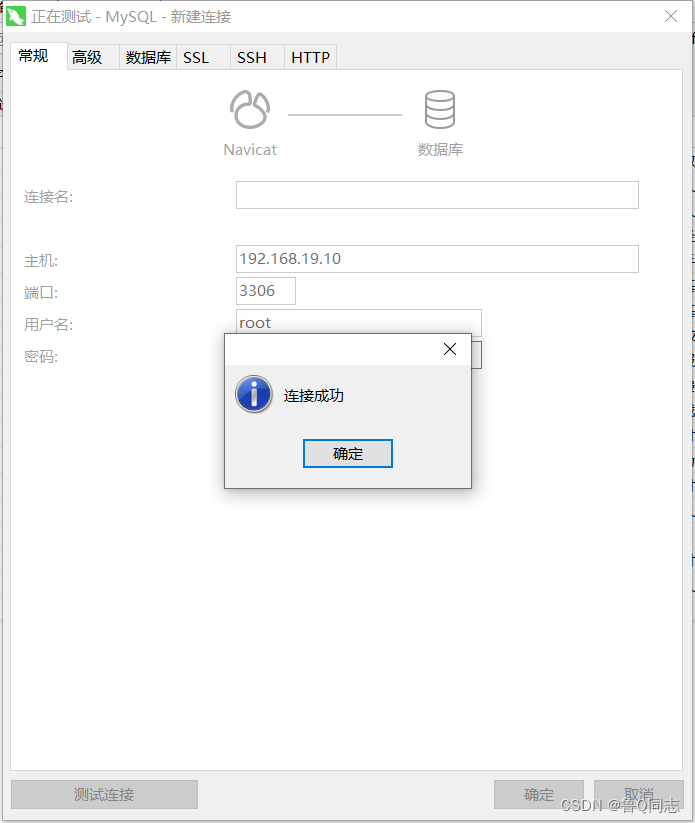
测试
我虚拟机的ip为192.168.19.10

有的人会连接不成功,是因为发防火墙没有放开端口,这里有两种方法,关闭防火墙或者开放端口
关闭防火墙
systemctl stop firewalld
开放端口
firewall-cmd --zone=public --add-port=3306/tcp --permanent
开放完端口后需要重启防火墙才能生效
firewall-cmd --reload
设置开机自启
添加到服务列表
chkconfig --add mysql
查看列表
chkconfig --list
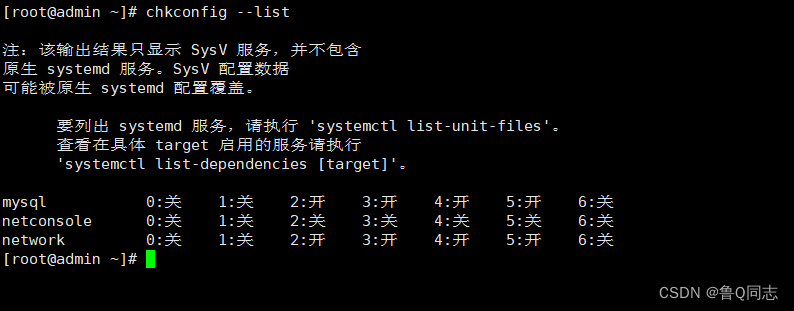
一般2345都是开或者on的,如果不是执行命令
chkconfig --level 2345 mysql on
添加系统路径
vi /etc/profile
export PATH=/opt/mysql/bin:$PATH
source /etc/profile
四、hadoop安装
安装步骤和jdk的完全一样,存在/opt ,然后把下载解压的hadoop放到该文件夹下面。最主要的也还是配置文件,如果配置文件里面的路径正确那就可以。配置代码如下:
vi/etc/profile
export HADOOP_HOME=/opt/hadoop-3.1.3
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
安装完之后可以在终端输入hadoop version命令查看:

Hadoop分布式配置
终端输入mkdir /opt/hadoop-3.1.3/tmp创建tmp文件夹
终端输入mkdir /opt/hadoop-3.1.3/data/namenode创建namenode文件夹
终端输入mkdir /opt/hadoop-3.1.3/data/datanode创建datanode文件夹
在终端输入cd /opt/hadoop-3.1.3/etc/hadoop/ 注意自己的路径,后面需要修改的文件都在这个目录下面,这里先进入该目录
进入/opt/hadoop-3.1.3/etc/hadoop
cd /opt/hadoop-3.1.3/etc/hadoop
配置core-site.xml:输入vi core-site.xml 打开文件后添加
(全分布式中我使用三台虚拟机,KingSSM是我的主机名,还有两台分别是Slave1和Slave2)
<configuration><property><name>fs.defaultFS</name><value>hdfs://kingssm:9000</value></property><property><name>hadoop.tmp.dir</name><value>/opt/hadoop-3.1.3/tmp</value></property>
</configuration>
配置hdfs-site.xml:输入vi hdfs-site.xml 打开文件后添加
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>/opt/hadoop-3.1.3/data/namenode</value></property><property><name>dfs.datanode.data.dir</name><value>/opt/hadoop-3.1.3/data/datanode</value></property><property><name>dfs.permissions</name><value>false</value></property>
</configuration>配置mapred.site.xml:输入vi mapred-site.xml 打开文件后添加
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapred.job.tracker</name><value>kingssm:9001</value></property>
</configuration>
配置yarn-site.xml:输入yarn-site.xml打开文件后添加
<configuration>
<!-- Site specific YARN configuration properties --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.hostname</name><value>kingssm</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property>
</configuration>配置hadoop-env.sh:输入vi hadoop-env.sh 打开文件后添加
export JAVA_HOME=/opt/jdk1.8.0_181
export HADOOP_HOME=/opt/hadoop-3.1.3
export PATH=$PATH:/opt/hadoop-3.1.3/bin
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
export HADOOP_PID_DIR=/opt/hadoop-3.1.3/pids
配置yarn-env.sh:输入vi yarn-env.sh 打开文件后添加
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
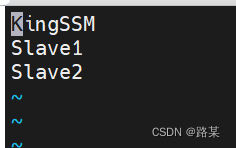
配置workers:输入vi workers 打开文件后添加,这里换成你的主机名和IP地址(KingSSM是当前正在操作的虚拟机主机名,其他两个是等下要克隆的两台虚拟机的主机名,IP地址要在虚拟机中修改)
在终端输入cd /opt/hadoop-3.1.3/sbin/ 进入新的目录
配置start-dfs.sh:输入vi start-dfs.sh打开文件后添加
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
配置stop-dfs.sh:输入vi stop-dfs.sh打开文件后添加
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
修改主机名
# 查看主机名称
hostname# 修改主机名
hostnamectl --static set-hostname kingssm
设置静态IP
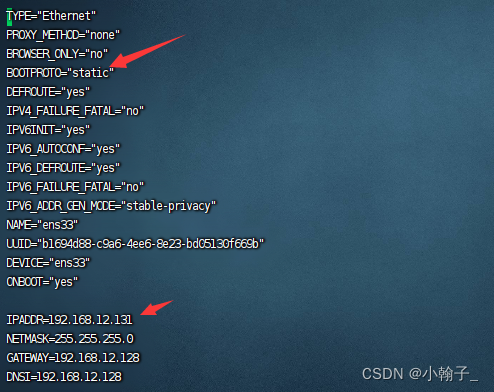
终端输入ip route查看网关

输入vi /etc/sysconfig/network-scripts/ifcfg-ens33修改文件:修改或添加下面的内容,IP地址自己选择,但是注意要和网关对应,如网关是192.168.12.128,那IP地址前面就得是192.168.12,后面那部分自己随意,NDS1和网关一样,子网掩码是255.255.255.0
添加虚拟机之间的映射
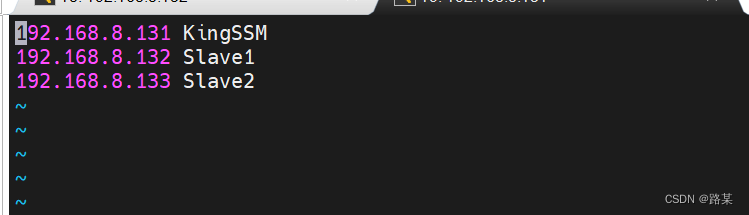
终端输入vi /etc/hosts,添加
SSH免密登录
首先运行
ssh localhost
正常情况下是免密登录的,如果你还要输入密码的话,那就是你ssh没有配置好。这里要说一下的是ssh7.0之后就关闭了dsa的密码验证方式,如果你的秘钥是通过dsa生成的话,需要改用rsa来生成秘钥
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
再次运行
ssh localhost
如果不需要输入密码,说明ssh配置好了。接下来运行
ssh-keygen -t rsa 然后一直回车;
等可以再次输入时输入下面命令将公钥发布出去:
ssh-copy-id kingssm
ssh-copy-id slave1
ssh-copy-id slave2
五、克隆虚拟机,启动集群
把当前正在使用的kingssm虚拟机关闭,然后克隆两台虚拟机。
点击虚拟机------>右键------>管理------>克隆------>完全克隆
等克隆完之后,三台虚拟机都打开,然后对克隆出来的两台分别设置主机名slave1和slave2,并修改IP地址
启动集群
三台虚拟机都需要先格式化
打开终端,以root身份操作,三台都要输入hadoop namenode -format进行格式化
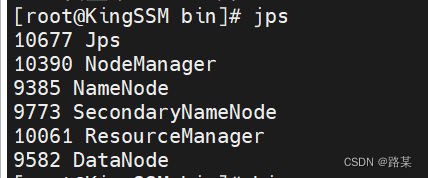
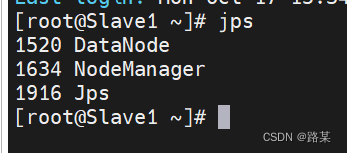
格式化完成后,在kingssm中启动集群,输入start-all.sh启动集群,(如果关闭,输入stop-all.sh)
启动完后输入jps查看启动状态,kingssm和slave应该有以下信息
访问网页查看结果:kingssm:9870
访问网页查看结果:kingssm:8088

六、hive安装
修改hadoop的 core-site.xml中, 添加以下内容:
修改hadoop 配置文件 /opt/hadoop-3.1.3/core-site.xml,加入如下配置项:
<property><name>hadoop.proxyuser.root.hosts</name><value>*</value>
</property>
<property><name>hadoop.proxyuser.root.groups</name><value>*</value>
</property>
软件包下载 apache-hive-3.1.2-bin.tar.gz,上传/usr目录下并解压重命名hive
cd /opt
tar -xzvf apache-hive-3.1.2-bin.tar.gz
mv apache-hive-3.1.2-bin
修改 hive的环境配置文件: hive-env.sh
cd /export/server/hive-3.1.2/conf
cp hive-env.sh.template hive-env.sh
vim hive-env.sh
修改一下内容:
# 配置hadoop的家目录
HADOOP_HOME=/opt/hadoop-3.1.3/
# 配置hive的配置文件的路径
export HIVE_CONF_DIR=/opt/hive/conf/
# 配置hive的lib目录
export HIVE_AUX_JARS_PATH=/opt/hive/lib/
创建配置文件
cd /opt/conf/
vi hive-site.xml
将以下内容复制配置文件中
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://kingssm:3306/metastore?createDatabaseIfNotExist=true&useSSL=false</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value></property><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property><property><name>hive.metastore.schema.verification</name><value>false</value></property><property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value></property><property><name>hive.cli.print.current.db</name><value>true</value></property><!-- 远程模式部署metastore 服务地址 --><property><name>hive.metastore.uris</name><value>thrift://kingssm:9083</value></property><property><name>hive.cli.print.header</name><value>true</value></property><property><name>hive.server2.thrift.bind.host</name><value>kingssm</value></property><property><name>hive.server2.thrift.port</name><value>10000</value></property>
</configuration>vi /etc/profile
export HIVE_HOME=/opt/hive
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile
连接MySQL, 用户名root, 密码root
mysql -uroot -proot
创建hive元数据, 需要和hive-site.xml中配置的一致sql
创建数据库, 数据库名为: metastore
create database metastore;
show databases;
初始化元数据库
schematool -initSchema -dbType mysql -verbose
看到schemaTool completed 表示初始化成功
验证安装
hive
退出
quit;
如遇以下错误及解决方法:

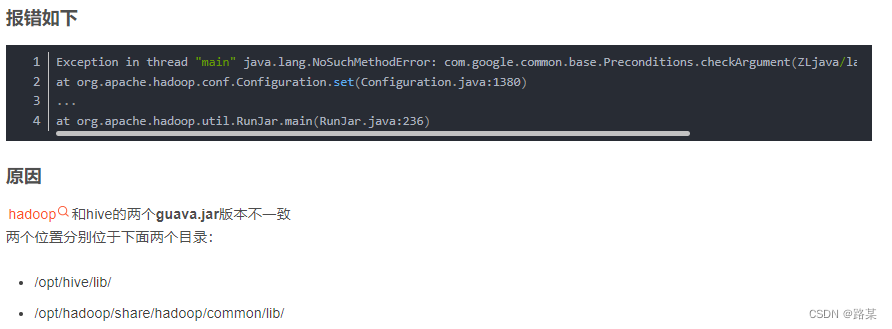
hadoo的slf4j和hive两个slf4j冲突
删除 /opt/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar

hadoop和hive的两个guava.jar版本不一致
将高版本的替换到底版本的
创建HDFS的hive相关的目录
hadoop fs -mkdir /tmp
hadoop fs -mkdir -p /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
启动 hive的服务: metastore
先启动metastore服务项:
前台启动:
cd /opt/hive/bin
hive --service metastore
注意: 前台启动后, 会一直占用前台界面, 无法进行操作
好处: 一般先通过前台启动, 观察metastore服务是否启动良好
前台退出: ctrl + c
后台启动:
当前台启动没有任何问题的时候, 可以将其退出, 然后通过后台启动, 挂载后台服务即可
cd /opt/hive/bin
nohup hive --service metastore &
启动后, 通过 jps查看, 是否出现一个runjar 如果出现 说明没有问题(建议搁一分钟左右, 进行二次校验)
注意: 如果失败了, 通过前台启动, 观察启动日志, 看一下是什么问题, 尝试解决
后台如何退出:
通过 jps 查看进程id 然后采用 kill -9
启动hive的服务: hiveserver2服务
接着启动hiveserver2服务项:
前台启动:
cd /opt/hive/bin
hive --service hiveserver2
注意: 前台启动后, 会一直占用前台界面, 无法进行操作
好处: 一般先通过前台启动, 观察hiveserver2服务是否启动良好
前台退出: ctrl + c
后台启动:
当前台启动没有任何问题的时候, 可以将其退出, 然后通过后台启动, 挂载后台服务即可
cd /opt/hive/bin
nohup hive --service hiveserver2 &
启动后, 通过 jps查看, 是否出现一个runjar 如果出现 说明没有问题(建议搁一分钟左右, 进行二次校验)
注意: 如果失败了, 通过前台启动, 观察启动日志, 看一下是什么问题, 尝试解决
后台如何退出:
通过 jps 查看进程id 然后采用 kill -9
基于beeline的连接方式
cd /opt/hive/bin
beeline --进入beeline客户端
连接hive:
!connect jdbc:hive2://kingssm:10000
接着输入用户名: root
最后输入密码: 无所谓(一般写的都是虚拟机的登录密码)
可能出现问题
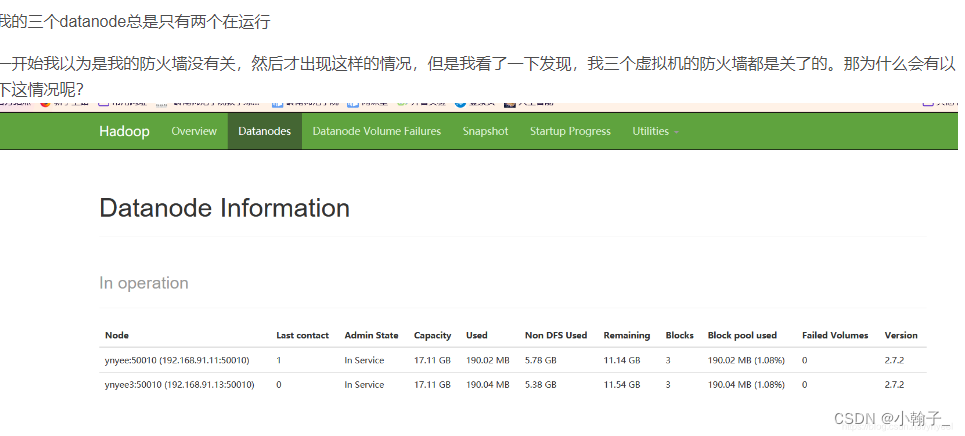
到我们hadoop下的/opt/hadoop-3.1.3/data/datanode/current下去修改VERSION文件,把datanodeUuid改成两个不同的id就可以了,随便改都可以~
相关文章:
Hadoop、Hive安装
一、 工具 Linux系统:Centos,版本7.0及以上 JDK:jdk1.8 Hadoop:3.1.3 Hive:3.1.2 虚拟机:VMware mysql:5.7.11 工具下载地址: https://pan.baidu.com/s/1JYtUVf2aYl5–i7xO6LOAQ 提取码: xavd…...

PHP自定义函数--输入起始日期和解算日期返回日期差几天和 上一个周期的起始结束日期
/** 日期差几天* param beginDate:2018-01-26 endDatee:2018-01-26* return int days* */ function dateDiff($beginDate, $endDate) {$diff date_diff(date_create($beginDate), date_create($endDate))->format(%R%a);return (int)$diff; }/** 返回上一周期的起始和结束日…...

.net 7 上传文件踩坑
(Name “file”) 没加上这个传不进文件 /// <summary>/// 上传单个文件/// </summary>/// <param name"formFile"></param>/// <returns></returns>[HttpPost("UploadFiles")][FunctionAttribute(MuType.Btn, "…...
C++基础算法④——排序算法(快速、归并附完整代码)
快速排序 快速排序是对冒泡排序的一种改进。 它的基本思想是:通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行快速排序,以达到整个序列有序。 假设我们现在对 …...

高防CDN如何在防护cc上大显神通
高级防御CDN(Content Delivery Network)在对抗CC(HTTP Flood)攻击方面扮演着关键的角色,具备以下重要职能和作用: 流量分散:CC攻击的目标是通过大规模的HTTP请求使服务器过载,从而导…...

解决CSS中height:100%失效的问题
出现BUG的场景,点击退出到登录页面,发现高度不对 上面出现了一种只是占了内容的高度,没有占满100%,为什么会出现这种情况呐? 让div的height"100%",执行网页时,css先执行到࿰…...

小红书穿搭类种草营销怎么做?纯干货
在众多营销方式中,穿搭类种草营销以其独特的优势在小红书平台上崭露头角。穿搭类种草营销,以其独特的优势,成为了品牌和商家推广产品的重要方式。其优势主要体现在以下几个方面: 1. 高度相关性:小红书平台的用户主要是…...

什么是ARFF文件,以.arff结尾
关于arff,主要涉及三个输入类:概念、实例和属性。 1.概念简单而言就是需要被处理的东西, 2. 实例这个词有些陌生,但是可以大致认为其为样本, 3. 属性就是数据表中的一列。 为什么要用arff?(arff介绍&#x…...

华为OD机考算法题:计算疫情扩散时间
题目部分 题目计算疫情扩散时间难度难题目说明在一个地图中(地图由 n * n 个区域组成)有部分区域被感染病菌感染区域每天都会把周围(上下左右)的4个区域感染。 请根据给定的地图计算多少天以后,全部区域都会被感染。 如果初始地图上所有区域全部都被感染࿰…...
29岁从事功能测试5年被辞,面试4个月还没到工作......
最近一个32岁的老同学因为被公司辞退,聊天过程中找我倾诉,所以写下了这篇文章。 他是15年二本毕业,学的园林专业,人属于比较懒的那种,不爱学习,专业学的也一般。实习期间通过校招找到了一份对口的工作。但…...

再记【fatal error C1001: 内部编译器错误】的一个原因
平台:Windows 11、Visual Studio 2022 报错信息 已启动生成... 1>------ 已启动生成: 项目: PointMatchingModel, 配置: Debug x64 ------ 1>PointMatchingModel.cpp 1>C:\tools\vcpkg\installed\x64-windows\include\pcl\registration\impl\ia_fpcs.hpp…...

数据分析、大数据分析和人工智能之间的区别
数据分析、大数据分析和人工智能近年来十分热门,三者之间看起来有相似之处,也有不同之处。今天就来谈谈三者间的区别。 数据分析 数据分析是指对数据进行分析,从中提取有价值的信息,以支持企业或组织的决策制定。数据分析可以针对…...
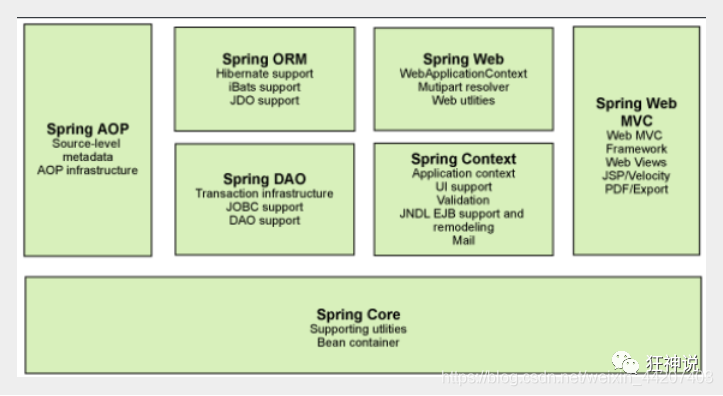
Spring系列之基础
目录 Spring概述 Spring的优点 Spring Framework的组成 总结 Spring概述 Spring 是目前主流的 Java Web 开发框架,是 Java 世界最为成功的框架。该框架是一个轻量级的开源框架,具有很高的凝聚力和吸引力。它以Ioc(控制反转)和…...
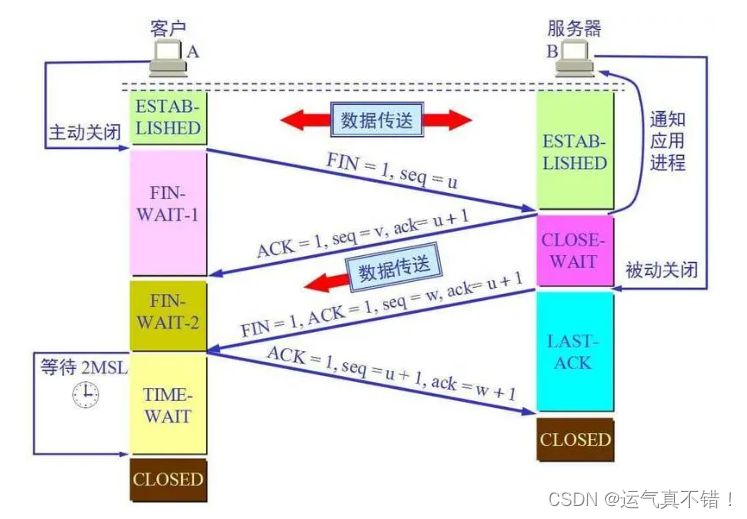
Android开发知识学习——TCP / IP 协议族
文章目录 学习资源来自:扔物线TCP / IP 协议族TCP连接TCP 连接的建立与关闭TCP 连接的建立为什么要三次握手? TCP 连接的关闭为什么要四次挥手? 为什么要⻓连接? 常见面试题课后题 学习资源来自:扔物线 TCP / IP 协议…...

思维训练 第四课 省略句
系列文章目录 文章目录 系列文章目录前言一、省略的十五种情况1.并列复合句中某些相同成分的省略2.在用when, while, if, as if, though, although, as ,until, whether等连词引导的状语从句中,如果谓语有be,而主语又跟主句的主语相同或是(从句主语是&am…...
soul协议算法
逆向工程技术是指对软件或应用程序进行逆向分析以了解其内部机制和功能的过程。虽然我无法详细介绍"Soul App"的逆向工程技术,但以下是一些常见的逆向工程技术,可能与你的研究相关: 1. 反汇编(Disassembly)…...

电子产品的认证体系
一、国内认证体系 1、CNAS认可:对认证机构的认可 CNAS全称是China National Accreditation Service for Conformity Assessment,中国合格评定国家认可委员会,由国家认证认可监督管理委员会(CNCA)批准设立并授权的唯一…...

大厂面试题-网络四元组
四元组,简单理解就是在TCP协议中,去确定一个客户端连接的组成要素,它包括源 IP地址、目标IP地址、源端口号、目标端口号。 正常情况下,我们对于网络通信的认识可能是这样(如图)。 服务端通过Server Socket建立一个对指定端口号…...

【通义千问“助力用户运营,无代码开发实现API连接广告推广和CRM】
通义千问:阿里云推出的超大规模语言模型 通义千问,是阿里云推出的一个超大规模的语言模型,功能包括多轮对话、文案创作、逻辑推理、多模态理解、多语言支持。这款产品的主要目标是帮助用户在无需编程的情况下,通过API连接广告推广…...
数据结构第一课-----------数据结构的介绍
作者前言 🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂 🎂 作者介绍: 🎂🎂 🎂 🎉🎉🎉…...

Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度
Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否在激烈的游戏对抗中经历过这样的挫败:同时按下左右方向键时角色卡…...

百考通智能任务书:贴合你的选题,拒绝空话假大空
毕业设计任务书是高校教学管理中的关键环节,它不仅标志着研究工作的正式启动,更是后续开题、实施、论文撰写和答辩全过程的行动依据。然而,许多学生在撰写时常常因不熟悉本专业写作规范、技术表达能力有限,或缺乏权威模板参考而陷…...

Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取
Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取微信小程序作为轻量级应用的代表,已经渗透到电商、社交、工具等各个领域。随着小程序功能的日益复杂,自动化测试成为保障产品质量的重要手段。本文将带你快速搭建微信小程序…...

深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案
深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是否曾因Honey Select 2的原版体验受…...

模拟电路实现自主循线机器人:无MCU的硬件逻辑设计
1. 项目概述:用最纯粹的模拟电路,造一台会“思考”的机器人每次看到那些在赛道上灵巧穿梭的循线小车,你是不是也手痒,想自己动手做一个?但一听到“单片机”、“编程”、“Arduino”这些词,又觉得门槛太高&a…...

抖音批量下载助手:一键构建你的专属视频素材库
抖音批量下载助手:一键构建你的专属视频素材库 【免费下载链接】douyinhelper 抖音批量下载助手 项目地址: https://gitcode.com/gh_mirrors/do/douyinhelper 还在为手动保存抖音视频而烦恼吗?想要批量获取心仪创作者的精彩内容却无从下手&#x…...

从脚本到系统:设计一个支持插件、限流、重试与监控的 Python 异步爬虫框架
从脚本到系统:设计一个支持插件、限流、重试与监控的 Python 异步爬虫框架 很多人第一次写 Python 爬虫,都是从几十行脚本开始的:requests.get()、BeautifulSoup、for 循环、保存 CSV。它很快,也很有成就感。但真实项目往往不是“…...

3步精通WaveTools:鸣潮全场景性能优化终极指南
3步精通WaveTools:鸣潮全场景性能优化终极指南 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 开源优化工具WaveTools作为《鸣潮》玩家必备的性能调校助手,通过深度配置优化实现画质…...

从Figma设计到Python GUI:Tkinter-Designer如何重塑可视化开发范式
从Figma设计到Python GUI:Tkinter-Designer如何重塑可视化开发范式 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发领域&am…...

量子机器学习:平衡数据复杂度与电路表达力的核心策略
1. 项目概述:量子机器学习中的核心平衡艺术在量子机器学习这个前沿交叉领域摸爬滚打了几年,我越来越深刻地意识到,决定一个模型成败的,往往不是最炫酷的量子门设计,而是一个看似基础却极易被忽视的平衡问题:…...