pytorch笔记:PackedSequence对象送入RNN
pytorch 笔记:PAD_PACKED_SEQUENCE 和PACK_PADDED_SEQUENCE-CSDN博客
- 当使用
pack_padded_sequence得到一个PackedSequence对象并将其送入RNN(如LSTM或GRU)时,RNN内部会进行特定的操作来处理这种特殊的输入形式。 -
使用
PackedSequence的主要好处是提高效率和计算速度。因为通过跳过填充部分,RNN不需要在这些部分进行无用的计算。这特别对于处理长度差异很大的批量序列时很有帮助。
1 PackedSequence对象
PackedSequence是一个命名元组,其中主要的两个属性是data和batch_sizes。data是一个1D张量,包含所有非零长度序列的元素,按照其在批次中的顺序排列。batch_sizes是一个1D张量,表示每个时间步的批次大小
-
PackedSequence(data=tensor([6, 5, 1, 8, 7, 9]),batch_sizes=tensor([3, 2, 1]), sorted_indices=None, unsorted_indices=None)
2 处理PackedSequence
- 当RNN遇到
PackedSequence作为输入时,它会按照batch_sizes中指定的方式对data进行迭代 - 举例来说,上面例子中
batch_sizes是[3,2,1],那么RNN首先处理前3个元素,然后是接下来的2个元素,最后是最后一个元素。 - 这允许RNN仅处理有效的序列部分,而跳过填充
3 输出
- 当RNN完成对
PackedSequence的处理后,它的输出同样是一个PackedSequence对象 - 可以使用
pad_packed_sequence将其转换回常规的填充张量格式,以进行后续操作或损失计算 - 隐藏状态和单元状态(对于LSTM)也会被返回,这些状态与未打包的序列的处理方式相同
4 举例
- 假设我们有以下3个句子,我们想要用RNN进行处理:
I love AI
Hello
PyTorch is great- 为了送入RNN,我们首先需要将这些句子转换为整数形式,并进行填充以保证它们在同一个批次中有相同的长度。
{'PAD': 0,'I': 1,'love': 2,'AI': 3,'Hello': 4,'PyTorch': 5,'is': 6,'great': 7
}
- 句子转换为整数后(id):
I love AI->[1, 2, 3]Hello->[4]PyTorch is great->[5, 6, 7]
- 为了将它们放入同一个批次,我们进行填充:
[1, 2, 3]
[4, 0, 0]
[5, 6, 7]
- 假设每个单词的id 对应的embedding就是自己:
[[1], [2], [3]]
[[4], [0], [0]]
[[5], [6], [7]]
- 使用pack_padded_sequence进行处理
import torch
from torch.nn.utils.rnn import pack_padded_sequence# 输入序列
input_seq = torch.tensor([[1,2,3], [4, 0, 0], [5,6,7]])
input_seq=input_seq.reshape(data.shape[0],input_seq.shape[1],1)
#每个单词id的embedding就是他自己
input_seq=input_seq.float()
#变成float是为了喂入RNN所需# 序列的实际长度
lengths = [3, 1, 3]# 使用pack_padded_sequence
packed = pack_padded_sequence(input_seq, lengths, batch_first=True,enforce_sorted=False)packed
'''
PackedSequence(data=tensor([[1.],[5.],[4.],[2.],[6.],[3.],[7.]]), batch_sizes=tensor([3, 2, 2]), sorted_indices=tensor([0, 2, 1]), unsorted_indices=tensor([0, 2, 1]))
'''- 现在,当我们将此
PackedSequence送入RNN时,RNN首先处理前3个元素,因为batch_sizes的第一个元素是3。然后,它处理接下来的2个元素,最后处理剩下的2个元素。-
具体来说,RNN会如下处理:
- 时间步1:根据
batch_sizes[0] = 3,RNN同时处理三个句子的第一个元素。具体地说,它处理句子1的"I",句子2的"PyTorch",和句子3的"Hello"。 - 时间步2:根据
batch_sizes[1] = 2,RNN处理接下来两个句子的第二个元素,即句子1的"love"和句子2的"is"。 - 时间步3:根据
batch_sizes[2] = 2,RNN处理接下来两个句子的第三个元素,即句子1的"AI"和句子2的"great"。
- 时间步1:根据
-
- 喂入RNN
import torch.nn as nnclass SimpleRNN(nn.Module):def __init__(self,input_size,hidden_size,num_layer=1):super(SimpleRNN,self).__init__()self.rnn=nn.RNN(input_size,hidden_size,num_layer,batch_first=True)def forward(self,x,hidden=None):packed_output,h_n=self.rnn(x,hidden)return packed_output,h_n
#单层的RNNSrnn=SimpleRNN(1,3)
Srnn(packed_data)
'''
(PackedSequence(data=tensor([[-0.1207, -0.0247, 0.4188],[-0.3173, -0.0499, 0.6838],[-0.4900, -0.0751, 0.8415],[-0.7051, -0.1611, 0.9610],[-0.7497, -0.2117, 0.9829],[-0.3361, -0.1660, 0.9329],[ 0.4608, -0.0492, 0.1138]], grad_fn=<CatBackward0>), batch_sizes=tensor([3, 2, 2]), sorted_indices=None, unsorted_indices=None),tensor([[[-0.3361, -0.1660, 0.9329],[ 0.4608, -0.0492, 0.1138],[-0.4900, -0.0751, 0.8415]]], grad_fn=<StackBackward0>))
'''- 得到的RNN输出是pack的,hidden state没有变化
-
Srnn=SimpleRNN(1,3) Srnn(packed_data) ''' (PackedSequence(data=tensor([[-0.1207, -0.0247, 0.4188],[-0.3173, -0.0499, 0.6838],[-0.4900, -0.0751, 0.8415],[-0.7051, -0.1611, 0.9610],[-0.7497, -0.2117, 0.9829],[-0.3361, -0.1660, 0.9329],[ 0.4608, -0.0492, 0.1138]], grad_fn=<CatBackward0>), batch_sizes=tensor([3, 2, 2]), sorted_indices=None, unsorted_indices=None),tensor([[[-0.3361, -0.1660, 0.9329],[ 0.4608, -0.0492, 0.1138],[-0.4900, -0.0751, 0.8415]]], grad_fn=<StackBackward0>)) '''pad_packed_sequence(Srnn(packed_data)[0],batch_first=True) ''' (tensor([[[-0.1207, -0.0247, 0.4188],[-0.7051, -0.1611, 0.9610],[-0.3361, -0.1660, 0.9329]],[[-0.3173, -0.0499, 0.6838],[-0.7497, -0.2117, 0.9829],[ 0.4608, -0.0492, 0.1138]],[[-0.4900, -0.0751, 0.8415],[ 0.0000, 0.0000, 0.0000],[ 0.0000, 0.0000, 0.0000]]], grad_fn=<TransposeBackward0>),tensor([3, 3, 1])) '''
-
相关文章:

pytorch笔记:PackedSequence对象送入RNN
pytorch 笔记:PAD_PACKED_SEQUENCE 和PACK_PADDED_SEQUENCE-CSDN博客 当使用pack_padded_sequence得到一个PackedSequence对象并将其送入RNN(如LSTM或GRU)时,RNN内部会进行特定的操作来处理这种特殊的输入形式。 使用PackedSequ…...
实例)
C#WPF工具提示(ToolTip)实例
本文演示C#WPF工具提示(ToolTip)实例 ToolTip ToolTip是当鼠标移到某个控件上后可以弹出提示的控件 属性说明 1、HasDropShadow 决定工具提示是否具有扩散的黑色阴影,使其和背后的窗口区别开来 2、Placement 使用PlacementMode枚举值决定如何放置工具提示。默认值是M…...

智慧矿山系统中的猴车安全监测与识别
智慧矿山是近年来兴起的一种采用人工智能(AI)技术的矿山管理方式,它通过利用智能传感设备和先进算法来实现对矿山环境和设备进行监测和管理,从而提高矿山的安全性和效率。在智慧矿山的AI算法系列中,猴车不安全行为识别…...

网络协议--TCP连接的建立与终止
18.1 引言 TCP是一个面向连接的协议。无论哪一方向另一方发送数据之前,都必须先在双方之间建立一条连接。本章将详细讨论一个TCP连接是如何建立的以及通信结束后是如何终止的。 这种两端间连接的建立与无连接协议如UDP不同。我们在第11章看到一端使用UDP向另一端发…...

react条件渲染
目录 前言 1. 使用if语句 2. 使用三元表达式 3. 使用逻辑与操作符 列表渲染 最佳实践和注意事项 1. 使用合适的条件判断 2. 提取重复的逻辑 3. 使用适当的key属性 总结 前言 在React中,条件渲染指的是根据某个条件来决定是否渲染特定的组件或元素。这在构…...

Docker中Failed to initialize NVML: Unknown Error
参考资料 Docker 中无法使用 GPU 时该怎么办(无法初始化 NVML:未知错误) SOLVED Docker with GPU: “Failed to initialize NVML: Unknown Error” 解决方案需要的条件: 需要在服务器上docker的admin list之中. 不需要服务器整体的admin权限.…...

学习笔记|单样本秩和检验|假设检验摘要|Wilcoxon符号检验|规范表达|《小白爱上SPSS》课程:SPSS第十一讲 | 单样本秩和检验如何做?很轻松!
目录 学习目的软件版本原始文档单样本秩和检验一、实战案例二、统计策略三、SPSS操作1、正态性检验2.单样本秩和检验 四、结果解读第一,假设检验摘要第二,Wilcoxon符号检验结果摘要。第三,Wilcoxon符号秩检验图第四,数…...

ttkefu在线客服在客户联络领域的价值
随着互联网的快速发展,越来越多的企业开始注重在线客服的应用。ttkefu作为一款智能在线客服系统,在客户联络领域中展现出了巨大的价值。本文将详细介绍ttkefu在线客服在客户联络领域的应用优势、专家分析以及未来发展趋势。 一、ttkefu在线客服简介 tt…...

创新方案|2023如何用5种新形式重塑疫后实体门店体验
在电商盛行的当下,线上购物已成为新零售的重要组成部分,实体零售业正处于两难境地。一方面,实体零售是绝对有必要的:美国约 85% 的销售额来自实体商店。 另一方面,尽管增长放缓,但电商收入占销售总额的比例…...
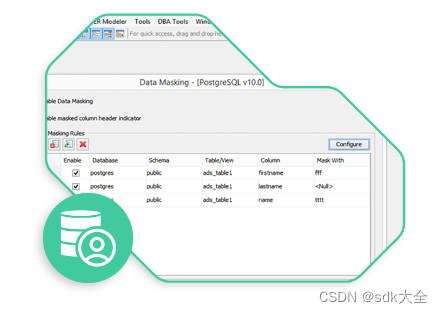
Aqua Data Studio 2023.1
为什么选择 Aqua Data Studio? 随着数据在业务中的作用不断发展,组织需要一种有效的方法来简化复杂的技术任务并缩小 IT 和业务团队之间的差距。 使用多个数据库平台不再复杂。使用 Aqua Data Studio 简化您的所有数据管理流程和任务:这是一…...
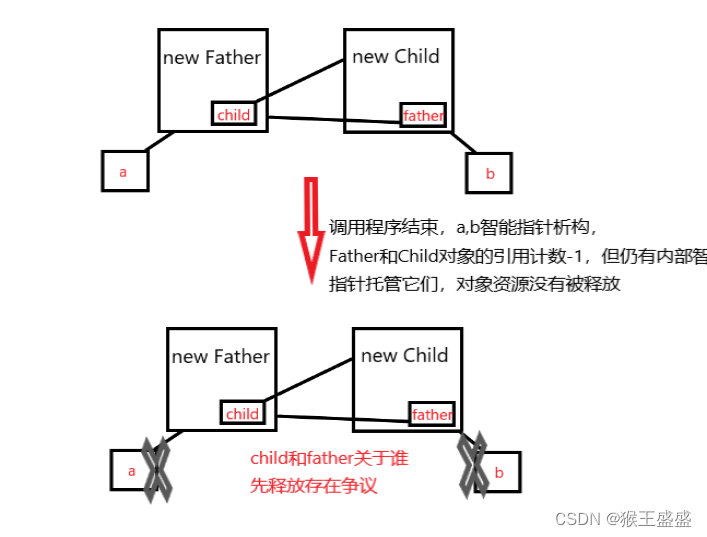
【C++智能指针】
智能指针 为什么使用智能指针?概念分类auto_ptrunique_ptrshared_ptr循环引用weak_ptr 为什么使用智能指针? 考虑以下场景: void div() {int a, b;cin >> a >> b;if (b 0)throw invalid_argument("除0错误");return…...

gcc/g++使用格式+各种选项,预处理/编译(分析树,编译优化,生成目标代码)/汇编/链接过程(函数库,动态链接)
目录 gcc/g--编译器 介绍 使用格式 通用选项 编译选项 链接选项 程序编译过程 预处理(宏替换) 编译 (生成汇编) 分析树(parse tree) 编译优化 删除死代码 寄存器分配和调度 强度削弱 内联函数 生成目标代码 汇编 (生成二进制代码) 链接(生成可执行文件) 函…...

OSPF复习(2)
目录 一、LSA的头部 二、6种类型的LSA(课堂演示) 1、type1-LSA:----重要且复杂 2、type2-LSA: 3、type3-LSA: 4、type4-LSA: 5、type5-LSA: 6、type7-LSA: 三、OSPF的网络类…...
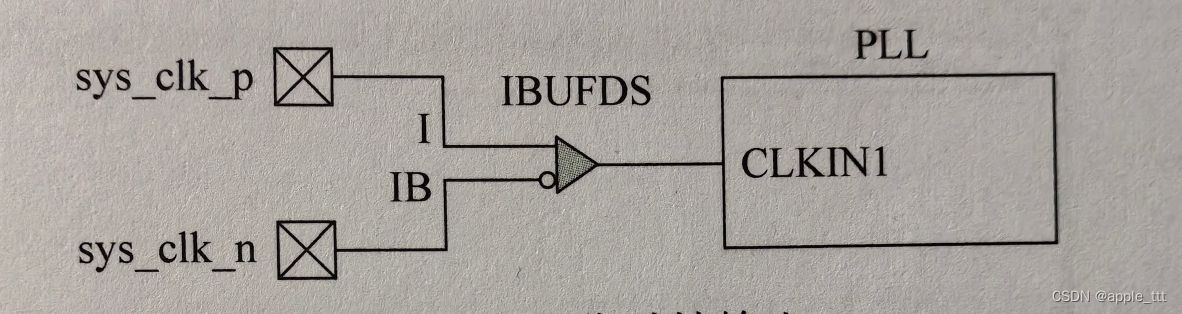
FPGA时序分析与约束(9)——主时钟约束
一、时序约束 时序引擎能够正确分析4种时序路径的前提是,用户已经进行了正确的时序约束。时序约束本质上就是告知时序引擎一些进行时序分析所必要的信息,这些信息只能由用户主动告知,时序引擎对有些信息可以自动推断,但是推断得到…...

sqlite3 关系型数据库语言 SQL 语言
SQL(Structured Query Language)语言是一种结构化查询语言,是一个通用的,功能强大的关系型数据库操作语言. 包含 6 个部分: 1.数据查询语言(DQL:Data Query Language) 从数据库的二维表格中查询数据,保留字 SELECT 是 DQL 中用的最多的语句 2.数据操作语言(DML) 最主要的关…...

spring boot中的多环境配置
1.切换环境 spring:profiles:include: devactive: dev的作用是为了启动某个环境,两个作用基本一致, 环境定义如下: spring:profiles: dev或者是查找application-dev.yml这个文件的所有配置 2.加载文件 spring:config:import:- optional:f…...

python3 阿里云api进行巡检发送邮件
python3 脚本爬取阿里云进行巡检 不确定pip能不能安装上,使用时候可以百度一下,脚本是可以使用的,没有问题的 太长时间了,pip安装依赖忘记那些了,使用科大星火询问了下,给了下面的,看看能不能使…...
【Linux】安装使用Nginx负载均衡,并且部署前端项目
目录 一、Nginx概述 1. 什么 2. 背景 3. 作用 二、Nginx负载均衡 1. 讲述 2. 使用 1. 下载 2. 安装 3. 负载均衡 三、前端部署 1. 准备 2. 部署 一、Nginx概述 1. 什么 Nginx是一个高性能的开源Web服务器和反向代理服务器。它具有轻量级、高并发、低内存消耗的…...

k8s中 pod 或节点的资源利用率监控
pod 或节点的资源利用率监控 1 简介2 Kubectl Top介绍3 生效kubectl top命令3.1 下载配置components.yaml3.2 修改配置components.yaml参数3 kubectl top 应用3.1 查看node节点的资源占⽤率3.2 查看pod的资源占⽤率1 简介 通过Kubectl Top命令,可以查看你k8snode节点或者pod的…...
订水商城实战教程07-搜索
目录 1 创建数据源2 首页搜索功能3 创建搜索页面4 搭建搜索结果页面总结 上一篇我们讲解了店铺信息的展示功能,本篇讲解一下搜索功能。通常小程序在首页都配置了搜索的功能,输入关键词进行检索,可以在结果页上进行选购。同时还记录了用户的搜…...

想深耕网络安全行业,这些必备条件缺一不可
网络空间的攻防对抗日益激烈,网络安全已成为企业生存和国家安全的命脉,它负责构筑数字世界的坚固防线,保护核心资产与用户隐私免受侵害。 想要成为一名优秀的网络安全专家,除了敏锐的安全意识和高度的责任感,更需要锤…...

告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南
告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南你是否已经厌倦了Windows系统越来越慢的启动速度、频繁的后台更新和资源占用?当你的电脑开始频繁卡顿,或许该考虑给系统来一次"减负"了。Kubuntu 22.04 L…...

收藏|2026年大模型算法岗崛起!程序员小白入门高薪赛道全攻略
前些年,算法岗位一直稳居技术圈高薪行列,无数程序员争相入局,也成为计算机专业毕业生求职首选方向。 伴随大模型技术飞速迭代落地,行业就业格局迎来重大变革。如今含金量最高、人才缺口最大、长期发展潜力顶尖的岗位,已…...

JMeter实现RSA签名验签全流程实战
1. 为什么RSA加密接口测试总卡在“连通但失败”这一步? 你有没有遇到过这种情况:接口文档写得清清楚楚,Postman里填好URL、Header、Body,一发请求——返回 {"code":4001,"msg":"签名验证失败"} …...

Godot 4.3随机地图性能优化:避开TileMap与RNG陷阱
1. 为什么刚写完第一版随机地图就崩溃?——从“能跑”到“能用”的真实断层你兴冲冲地照着教程敲完几十行GDScript,RandomNumberGenerator初始化了,for x in range(width)循环也套好了,甚至还在_draw()里用draw_rect()把每个格子都…...

为内部知识库问答机器人集成taotoken多模型能力的架构设计
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答机器人集成taotoken多模型能力的架构设计 应用场景类,探讨为企业内部知识库构建智能问答机器人时&…...

茉莉花插件:如何让中文文献管理效率提升300%
茉莉花插件:如何让中文文献管理效率提升300% 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 还在为中文文献的元数据抓…...

3步掌握OpenSpeedy:免费开源游戏加速工具使用指南
3步掌握OpenSpeedy:免费开源游戏加速工具使用指南 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否曾为游戏卡顿而烦恼?是否希望在单机游戏中加快…...

C++的单例模式及其作用
什么是单例模式?无论是在面向对象编程还是软件架构中,单例模式都扮演着至关重要的角色。它不仅能够确保一个类只有一个实例存在,还能够提供全局访问点,使得我们可以方便地在程序的任何地方使用该实例。但有几个设计模式并非解决抽…...

工业级SCADA革命:FUXA零代码可视化平台如何重塑工业监控决策
工业级SCADA革命:FUXA零代码可视化平台如何重塑工业监控决策 【免费下载链接】FUXA Web-based Process Visualization (SCADA/HMI/Dashboard) software 项目地址: https://gitcode.com/gh_mirrors/fu/FUXA 在工业4.0和数字化转型浪潮中,传统SCADA…...