Hadoop相关知识点
文章目录
- 一、主要命令
- 二、配置虚拟机
- 2.1 设置静态ip
- 2.2 修改主机名及映射
- 2.3 修改映射
- 2.4 单机模式
- 2.5 伪分布式
- 2.6 完全分布式
- 三、初识Hadoop
- 四、三种模式的区别
- 4.1、单机模式与伪分布式模式的区别
- 4.2、特点
- 4.3、配置文件的差异
- 4.3.1、单机模式
- 4.3.2、伪分布式模式
- 4.3.3、完全分布式模式
- 五、问答题
- 六、shell访问hdfs(通过HDFS*Shell命令)
- 6.1、问答题
- 6.2、注意
一、主要命令
- 开启防火墙 sudo ufw enable
- 关闭防火墙 sudo ufw disable
- 查看防火墙状态 sudo ufw status
- 修改主机名 sudo vi /etc/hostname
- 修改映射 sudo vi /etc/hosts (考题)
- 建立文件夹 mkdir 文件夹名字
- 删除文件夹 rm -rf 递归删除文件夹向下穿透,其下所有文件、文件夹都会被删除 rm -f 强制删除文件 rm -r 递归删除文件
- 解压文件夹 tar -zxvf 文件名 -C ~/解压到的文件路径
- 文件重命名 mv 旧文件名 新文件名
- 修改主机名的文件位置 /etc/hostname
- 使配置环境变量生效 source ~/.bashrc
- 修改环境变量的 vi ~/.bashrc
- 查看具体的某个文件用cat
- 查看目录用 ls
- 重启ssh服务器 service sshd restart
- 启动ssh sudo service ssh start
- sudo是必须执行的命令
- -i 表示覆盖的意思
二、配置虚拟机
2.1 设置静态ip
查看当前ip:ifconfig
进入到netplan文件夹 cd /etc/netplan
查看文件目录,找到需要修改的文件 ls
进行修改ip sudo vi 00-installer-config.yaml
将设置的网络应用 sudo netplan apply
再次查看ip ip已经更换
2.2 修改主机名及映射
修改主机名 sudo vi /etc/hostname 修改后记得重启
修改映射 sudo vi /etc/hosts (考题)
2.3 修改映射
sudo vi /etc/hosts 将ip地址和主机名的映射添加到文件中192.168.xx.xxx single
使用文本编辑器打开 C:\Windows\System32\drivers\etc\host 文件并在文件末尾添加以下配置并保存退出 192.168.xx.xxx single
2.4 单机模式
- 没有HDFS
- 只能测试MapReduce程序
- MapReduce处理的是本地的Linux的文件数据
- 只需要修改hadoop-env.sh配置文件
2.5 伪分布式
- 格式化HDFS的命令: hdfs namenode -format
启动hadoop集群的命令
- start-all.sh或
- 启动dfs命令: start-dfs.sh
- 启动yarn命令: start-yarn.sh
- 启动yarn之后会有哪些服务?
ResourceManage(8088)、NodeManager(8042)
- 启动hdfs之后会有哪些服务?
Namenode 、 DataNode、 SecondaryNamenode
- 启动所有服务的命令: start-all.sh
- 查看yarn、web页面的端口号
查看yarn的端口号:8088
查看hdfs端口号:50070(通过web看)
-
查看集群启动进程
jps
yarn的中文名(Yet Another Resource Negotiator):资源调度与分配框架 -
控制从节点运行的服务器:workers(3.0hadoop)slaves(2.0hadoop)
-
NameNode(名称结点)的职责
A. 维护HDFS集群的目录树结构:NameNode负责存储和管理文件系统的命名空间,包括目录、文件和其属性等信息。
B. 维护HDFS集群的所有数据块的分布、副本数和负载均衡:NameNode记录每个数据块的位置和副本信息,并负责管理数据块的复制和迁移,以实现数据的可靠性和负载均衡。
C. 响应客户端的所有读写数据请求:NameNode接收客户端的读写请求,并将请求转发到适当的DataNode进行数据读取或写入操作。
D.NameNode负责管理数据块和处理元数据。
- Namenode无法访问时:
- 默认数据块大小:64mb 128mb 128mb
- 要存下700m需要6块数据块:一块为128
- namenode保存的两个文件:edits文件(文件的更新操作,记录操作日志)fsimage文件(修改信息 时间 控制访问权限 hdfs的元信息)
- DataNode(数据结点)职责
1.存储数据块block
2.根据namenode的指令对block进行创建、复制、删除等操作
3.datanode和namenode进行心跳通信,接受namenode指令
4.定期向namenode汇报自身存储的block列表及健康状态
5.负责为客户端发起的读写请求提供服务
- block是hdfs文件系统中最小的存储单位
SSH免密登录原理
非对称加密算法(rsa)、公钥加密(给别人)、私钥解密(给自己)
生成密钥对:ssh-keygen -t
将公钥copy给serverB:ssh-copy-id -i
在主机上登录子机:ssh 子机名
2.6 完全分布式
- 分发命令:scp -r /home/hadoop/hadoop-2.7.4 node2:/home/hadoop
三、初识Hadoop
- 大数据的特征:大量、真实、多样、低价值密度、高速
- hadoop起源的三篇论文:NDFS、MapReduce(分而治之,并行计算)、HDFS(分布式文件系统)->源于谷歌的GFS论文
- hadoop处理的是离线数据!
- 元数据(MetaData):记录hdfs文件系统的相关信息,包括文件系统的目录结构 文件名 文件路径 文件大小等。
- Hadoop的优缺点(简答题):
高扩展性: 增加集群的存储和计算能力
低成本: 利用多台廉价计算机,分布式系统处理
高效性: 离线并行动态计算,提高计算效率
高可靠性: 维护数据副本(3个),可有效防止数据丢失
高容错性:可转移到其他计算机上运行
缺点
不适合处理小文件:为了解决大型数据集的处理问题
无法实时计算:核心是执行离线计算的引擎
安全性较低存储和网络传输方面缺乏对数据的加密
场景:
适合:大数据分析、离线分析
不适合:少量数据、复杂数据、在线分析
- HDFS是Hadoop生态圈的基石,主要负责hadoop集群数据的存储和读取
- 大数据处理的意义:对未来事物发展规律做出预测,对之前的数据进行归纳和总结。
- 第二名称节点的作用:辅助namenode合并fsimage文件和edits文件 将合并结果发送给namenode,帮助主节点namenode进行元数据备份和恢复
四、三种模式的区别
4.1、单机模式与伪分布式模式的区别
单机模式
运行在单个计算机中
所有Hadoop组件(如HDFS和YARN)都在本地运行,并且没有网络通信
在单机模式下,Hadoop使用本地文件系统来存储数据。
伪分布式模式
Hadoop在一台计算机上模拟了一个分布式环境。
Hadoop服务(如HDFS和YARN)运行在单个计算机上,但它们通过网络进行通信和协作。
文件系统被配置为HDFS,而不是本地文件系统,数据被存储在HDFS中。
4.2、特点

4.3、配置文件的差异
4.3.1、单机模式

4.3.2、伪分布式模式

4.3.3、完全分布式模式

五、问答题

(1)ifconfig
(2)scp -r /home/hadoop/hadoop-2.7.4 node2:/home/hadoop
(3)hdfs namenode -format
(4)start-dfs.sh 和 start-yarn.sh

(1)hdfs dfs -mkdir /hd123
(2)hdfs dfs -touch data.txt
(3)hdfs dfs -ls /hd123
(4)hdfs dfs -appendToFile test.txt /hd123/data.txt
(5)hdfs dfs -cat /hd2112054139/data.txt
(6)hdfs dfs -get /hd2112054139/data.txt
根据HDFS的块大小为128MB,存储300MB的文件需要多少个数据块。
计算方法如下:
文件大小 / 块大小 = 数据块数量
300MB / 128MB ≈ 2.34
根据向上取整规则,需要3个数据块来存储300MB的文件。
所以,需要3个数据块来存储300MB的文件。
六、shell访问hdfs(通过HDFS*Shell命令)
- 格式化HDFS
hdfs namenode -format - 创建目录
hdfs -dfs -mkdir /hd2112054139 - 级联的创建目录
hdfs dfs -mkdir -p /hd2112054139/a/b/c 使用-p时,如果父目录不存在,会自动创建 - 查看目录
hdfs dfs -ls /hd211205139 - 级联的查看目录
hdfs dfs -ls -R /hd2112054139 - 将本地文件上传到HDFS中:hdfs dfs -put 文件名 文件目录 或 hdfs dfs -copyFromLocal b.txt /usr/opt/data
- 将本地文件下载(复制):hdfs dfs -get 文件目录 本地文件目录
- 追加数据
-appendToFile命令:将所有给定本地文件的内容追加到hdfs文件,hdf文件不存在,则创建该文件
hdfs dfs -appendToFile d.txt /usr/opt/data/a.txt
- 在hdfs中文件复制到同一个目录下:hdfs dfs -cp /data1.txt /data2.txt
- 查看文件夹大小:hdfs dfs -du -s 文件夹名
- 查看文件大小:hdfs dfs -du 文件名
- hdfs中删除文件:hdfs dfs -rm -r 文件路径名
- hdfs中统计文件:hdfs dfs -count 文件路径名(显示:目录个数、文件个数、文件总计大小、输入路径)
- 合并目录下的文件并下载到本地:hdfs dfs -getmerge /hd123 ~/input/merge.txt,
并在本地查看内容:cd 本地文件名 cat merge.txt - 查看文件内容:
#-cat命令:将文件内容显示出来(适合小文件)
hdfs dfs -cat /usr/opt/data/a.txt
#-haed命令:查看文件前1KB的内容
hdfs dfs -head /usr/opt/data/a.txt
#-tail命令:查看文件最后1KB的内容
hdfs dfs -tail /usr/opt/data/a.txt
#-tail -f命令:可以动态显示文件中追加的内容
#在Linux系统中
tail -f 1.txt
#hdfs
hdfs dfs -tail -f /usr/opt/data/a.txt
- HDFS中block默认保存3份
- 一个datanode上只有一个数据块的备份
6.1、问答题
1.根据要求写出HDFS shell命令
- 在HDFS上创建名为test的目录(此目录在主目录下)
hdfs dfs -mkdir ~/test - 将本地的文件file上传至test目录下
hdfs dfs -put /input/file.txt /test - 将本地的文件file内容追加至test目录下的file1.txt中
hdfs dfs -appendToFile file.txt /test/file1.txt - 查看test的目录信息.
hdfs dfs -ls /test
2.这三台操作系统为Ubutun 18.04机器(机器名分别是master(192.168.22.101)、slave(192.168.30.102)、slave2(192.168.22.103))部署Hadoop完全分布式环境,master上位Namenode节点,三台机器已经实现免密登录。实现下面功能需要输入什么Linux命令或者操作进行什么操作?
- 在主机master生成密钥的命令是什么?
ssh-keygen -t - 从master,通过ssh登录到slave2
ssh slave2 - 在master上,格式化HDFS
hdfs namenode -format’ - 启动YARN
start-yarn.sh - 该Hadoop集群运行时,使用哪儿个命令查看集群启动进程
jps
6.2、注意
hdfs dfs -put ~/input/file.txt /test 和 hdfs dfs -put /input/file.txt /test 的区别在于文件的来源路径。
hdfs dfs -put ~/input/file.txt /test 中的/input/file.txt表示当前用户的主目录下的input/file.txt文件。波浪号()在这里代表当前用户的主目录。
hdfs dfs -put /input/file.txt /test中的/input/file.txt表示根目录下的input/file.txt文件。
所以,两个命令的主要区别在于文件来源的路径。第一个命令将从当前用户的主目录下复制file.txt文件到HDFS中的/test目录,而第二个命令将从根目录下的/input目录中复制file.txt文件到HDFS中的/test目录。
相关文章:
Hadoop相关知识点
文章目录 一、主要命令二、配置虚拟机2.1 设置静态ip2.2 修改主机名及映射2.3 修改映射2.4 单机模式2.5 伪分布式2.6 完全分布式 三、初识Hadoop四、三种模式的区别4.1、单机模式与伪分布式模式的区别4.2、特点4.3、配置文件的差异4.3.1、单机模式4.3.2、伪分布式模式4.3.3、完…...
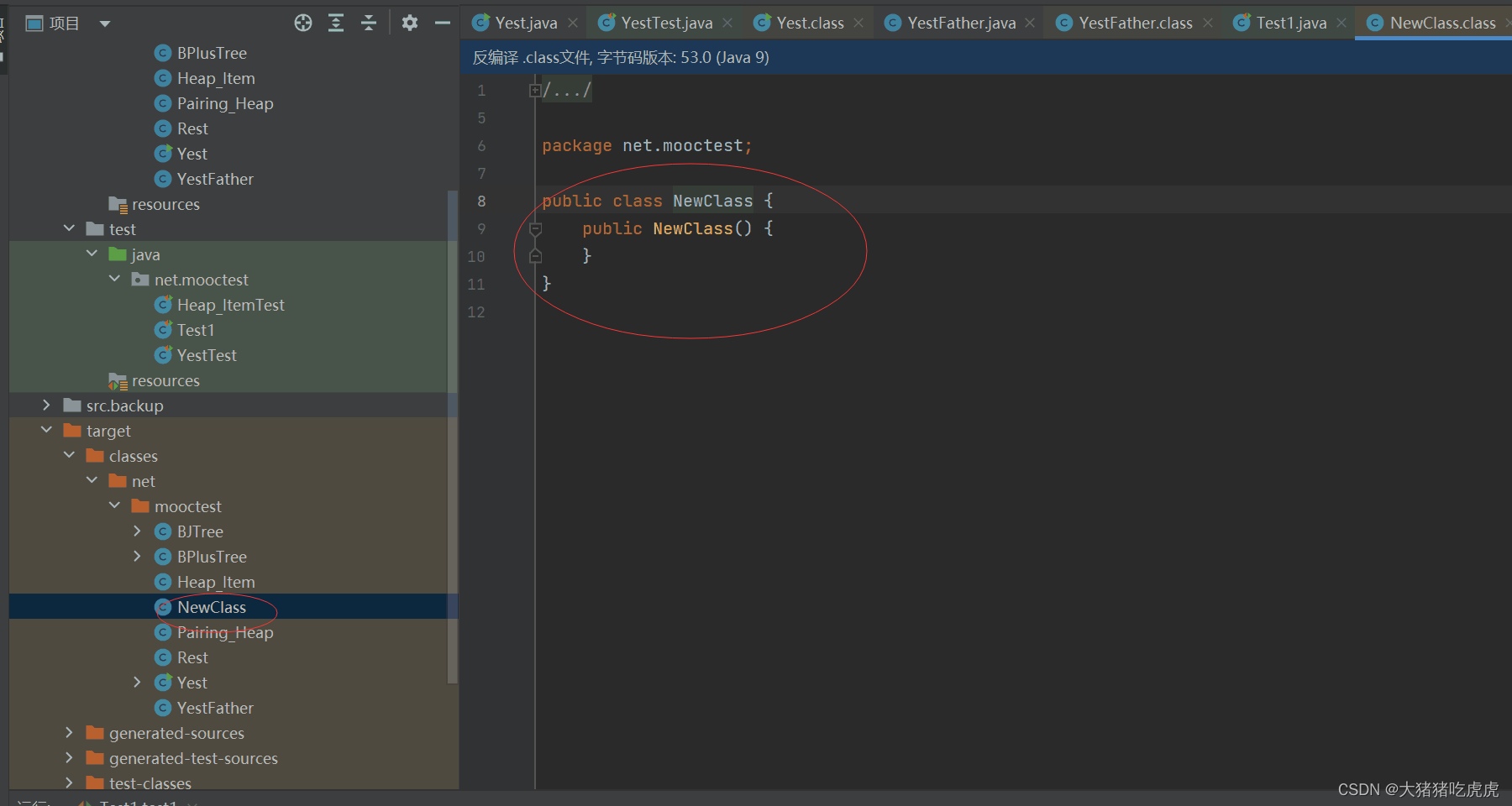
Javassist讲解1(介绍,读写字节码)
Javassist讲解1(介绍,读写字节码) 介绍一、读写字节码1.如何创建新的类2.类冻结 介绍 javassist 使Java字节码操作变得简单,它是一个用于在Java中编辑字节码的类库; 它使Java程序能够在运行时定义一个新类,…...

【Linux】常见指令以及具体其使用场景
君兮_的个人主页 即使走的再远,也勿忘启程时的初心 C/C 游戏开发 Hello,米娜桑们,这里是君兮_,随着博主的学习,博主掌握的技能也越来越多,今天又根据最近的学习开设一个新的专栏——Linux,相信Linux操作系…...
)
后台管理(二)
1、权限控制 如果没有权限控制,系统的功能完全不设防,全部暴露在所有用户面前。用户登录以后可以使用系统中的所有功能。这是实际运行中不能接受的,所以权限控制系统的目标就是管理用户行为,保护系统功能。 1.1、 定义资源 资源就…...

反转链表II(C++解法)
题目 给你单链表的头指针 head 和两个整数 left 和 right ,其中 left < right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。 示例 1: 输入:head [1,2,3,4,5], left 2, right 4 输出:[1…...
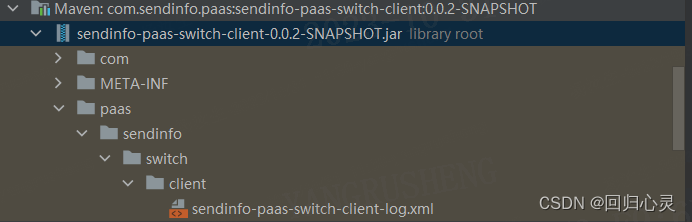
记一次 logback 没有生成独立日志文件问题
背景 在新项目发布后发现日志文件并没有按照期望的方式独立开来,而是都写在了 application.log 文件中。 问题展示 日志文件: 项目引入展示: <include resource"paas/sendinfo/switch/client/sendinfo-paas-switch-client-log.…...
)
数据库强化(1.视图)
1.什么是视图 视图是指计算机数据库中的视图,是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。但是,视图并不在数据库中以存储的数据值集形式存在。行和列数据来自由定义视图的查询所引用的…...

Mysql与SeaweedFS数据不同步问题产生原因及解决办法
文章目录 Mysql与SeaweedFS数据不同步问题的探究与解决问题背景原因探究不一致的写操作缺乏事务管理 解决方案引入分布式事务处理使用消息队列 实践演示(python代码)结论 Mysql与SeaweedFS数据不同步问题的探究与解决 问题背景 在数据库和文件存储系统…...

Kotlin apply和with用法和区别
apply apply 是 Kotlin 标准库中的一个函数,它允许你在对象上执行一系列操作,然后返回该对象自身。它的语法结构如下: fun <T> T.apply(block: T.() -> Unit): T这个函数接受一个 lambda 表达式作为参数,该 lambda 表达…...
springboot通过aop自定义注解@Log实现日志打印
springboot通过aop自定义注解Log实现日志打印 文章目录 效果图实操步骤1.引入依赖2.自定义日志注解3.编写日志切面类4.UserController5.运行 效果图 实操步骤 注意,本代码在springboot环境下运行,jdk1.8 1.引入依赖 <dependency><groupId>…...

k8spod详解其二
一,资源限制 当定义 Pod 时可以选择性地为每个容器设定所需要的资源数量。 最常见的可设定资源是 CPU 和内存大小,以及其他类型的资源。 当为 Pod 中的容器指定了 request 资源时,调度器就使用该信息来决定将 Pod 调度到哪个节点上。当还为…...

golang包的管理
Go语言中包的使用 Go语言使用包(package)这种语法元素来组织源码,所有语法可见性均定义在package这个级别,与Java 、python等语言相比,这算不上什么创新,但与C传统的include相比,则是显得“先进…...

Windows10安装Anaconda与Pytorch的记录
这是一篇关于安装Anaconda和Pytorch的记录与复盘,写的原因是我电脑恢复系统之后东西全没了,再装Pytorch的时候一脸懵逼忘了怎么弄了,写篇记录以备我下一次安装。 1、Anaconda的安装 1.1、Anaconda安装包下载 下载链接: Free Download | An…...
图解Kafka高性能之谜(五)
高性能的多分区、冗余副本集群架构 高性能网络模型NIO 简单架构设计: 详细架构设计: 高性能的磁盘写技术 高性能的消息查找设计 索引文件定位使用跳表的设计 偏移量定位消息时使用稀疏索引: 高响应的磁盘拷贝技术 kafka采用sendFile()的…...

opencv在linux上调用usb摄像头进行拍照
功能 1.按照指定的文件名创建文件夹,创建之前判断该文件夹是否存在 2.调用摄像头按可调整窗口大小的方式显示 3.按esc退出摄像头画面 4.按p保存当前摄像头的画面,并按当前时间为照片的名字进行保存打开终端查看是否有摄像头 ls /dev/video*一般video1就…...

软考之知识产品+例题
知识产权 保护期限 公民作品 没有限制 署名权、修改权、保护作品完整权 作者终生及其死亡后的第 50 年的 12月31日 发表权、使用权、获得报酬权 单位作品 首次发表后的第 50 年的 12月31 日,若未发表则不受保护 发表权、使用权、获得报酬权 公民软件作品 没…...
玩了一下 Jenkins,最新版本 + JDK11
背景 今年五月的时候玩了一下 Jenkins,最新版本 2.414.3 ,JDK 11 。本机有两个 JDK,只放到 Tomcat 里面了,看到了一个启动页面,后面有其他事情就忘记了。最近又想起来,觉得还是应该玩一下这么有技术含量的…...
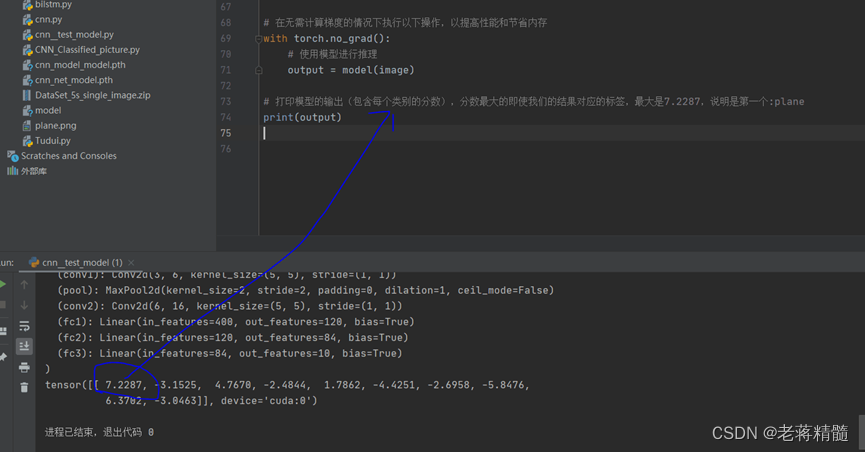
自定义的卷积神经网络模型CNN,对图片进行分类并使用图片进行测试模型-适合入门,从模型到训练再到测试,开源项目
自定义的卷积神经网络模型CNN,对图片进行分类并使用图片进行测试模型-适合入门,从模型到训练再到测试:开源项目 开源项目完整代码及基础教程: https://mbd.pub/o/bread/ZZWclp5x CNN模型: 1.导入必要的库和模块&…...

C# 使用.NET的SocketAsyncEventArgs实现高效能多并发TCPSocket通信
简介: SocketAsyncEventArgs是一个套接字操作得类,主要作用是实现socket消息的异步接收和发送,跟Socket的BeginSend和BeginReceive方法异步处理没有多大区别,它的优势在于完成端口的实现来处理大数据的并发情况。 BufferManager类…...
+ Spring相关源码)
设计模式——观察者模式(Observer Pattern)+ Spring相关源码
文章目录 一、观察者模式定义二、例子2.1 菜鸟教程例子2.1.1 定义观察者2.1.2 定义被观察对象2.1.3 使用 2.2 JDK源码 —— Observable2.2.1 观察者接口Observer2.2.1 被观察者对象Observable 2.3 Spring源码 —— AbstractApplicationContext2.3.1 观察者2.3.2 被观察者 2.3 G…...

AWVS深度调优指南:从安装卡死到WAF绕过实战
1. 这不是“点几下就完事”的玩具,而是渗透测试中真正扛压的扫描引擎很多人第一次听说AWVS(Acunetix Web Vulnerability Scanner),是在某篇标题写着“三分钟上手”“一键扫出100个漏洞”的公众号推文里。结果装完发现:…...

OpenSSH协议层隐藏版本号实战指南
1. 为什么连OpenSSH版本号都要藏?这不是小题大做很多人第一次听说“要隐藏SSH版本号”,第一反应是:这玩意儿不就是个登录提示吗?又不是密码,至于这么紧张?我刚入行那会儿也这么想。直到有次在客户现场做渗透…...

终极解密:如何使用unluac工具实现Lua字节码逆向工程
终极解密:如何使用unluac工具实现Lua字节码逆向工程 【免费下载链接】unluac fork from http://hg.code.sf.net/p/unluac/hgcode 项目地址: https://gitcode.com/gh_mirrors/un/unluac unluac是一款专业的Lua 5.x字节码反编译工具,能够将编译后的…...

量子机器学习优化微波脉冲:从量子门到物理控制的降噪增效实践
1. 项目概述与核心价值在量子计算这个充满潜力但也布满荆棘的领域里,我们每天都在和两个“天敌”作斗争:噪声和退相干。你辛辛苦苦制备的量子态,可能还没来得及完成一次完整的计算,就已经被环境噪声“污染”得面目全非。传统的纠错…...

如何在Windows电脑上安装安卓应用:APK安装器完整教程
如何在Windows电脑上安装安卓应用:APK安装器完整教程 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer APK安装器是一款专为Windows系统设计的安卓应用安装工…...

微信小程序抓包实战:安卓模拟器+BurpSuite无Root稳定方案
1. 为什么微信小程序抓包成了“玄学”,而这条路径能绕过所有坑做移动安全测试或前端调试的同行,大概率都经历过这种场景:想看看微信小程序发了什么请求、带了哪些参数、响应体里有没有敏感字段,结果一上手就卡在第一步——连包都抓…...
)
手把手教你为Ubuntu 22.04服务器安装Tesla V100s驱动与CUDA 12.2(保姆级避坑指南)
手把手教你为Ubuntu 22.04服务器安装Tesla V100s驱动与CUDA 12.2(保姆级避坑指南) 在AI模型训练和推理领域,Tesla V100s显卡凭借其强大的计算能力和高效的Tensor Core架构,成为许多企业和研究机构的首选。然而,为Ubunt…...

基于高斯过程与多源数据融合的金属增材制造工艺优化
1. 项目概述与核心挑战在激光粉末床熔融这类金属增材制造工艺里,我们这些一线的工程师和研究员最头疼的问题之一,就是工艺参数和最终零件性能之间那“剪不断、理还乱”的复杂关系。你手头有激光功率、扫描速度、扫描间距、铺粉层厚、扫描旋转角度等一大堆…...

TrafficMonitor插件终极指南:5分钟打造你的个性化Windows桌面监控中心
TrafficMonitor插件终极指南:5分钟打造你的个性化Windows桌面监控中心 【免费下载链接】TrafficMonitorPlugins 用于TrafficMonitor的插件 项目地址: https://gitcode.com/gh_mirrors/tr/TrafficMonitorPlugins 你是否厌倦了在多个应用程序之间频繁切换来查看…...

终极解决方案:如何用qmc-decoder快速解锁QQ音乐加密格式
终极解决方案:如何用qmc-decoder快速解锁QQ音乐加密格式 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 你是否曾经下载了QQ音乐,却发现那些.qmc3、…...