二叉查找树的应用 —— K模型和KV模型
文章目录
- 前言
- 1. K模型
- 2. KV模型
- 🍑 构建KV模型的树
- 🍑 英汉词典
- 🍑 统计水果出现的次数
- 3. 总结
前言
在上一篇文章中,我们进行了二叉查找树的实现(文章链接),那么今天主要探讨一下二叉查找树的应用
1. K模型
K 模型即只有 key 作为关键码,结构中只需要存储 Key 即可,关键码即为需要搜索到的值。
比如:给一个单词 word,判断该单词是否拼写正确,具体方式如下:
- 以单词集合中的每个单词作为 key,构建一棵二叉查找树
- 在二叉查找树中检索该单词是否存在,存在则拼写正确,不存在则拼写错误。
其实这个 K 模型就是上一篇文章中,我们实现的二叉查找树。
2. KV模型
所谓 KV 模型就是每一个关键码 key,都有与之对应的值 Value,即 <Key, Value> 的键值对。
这种方式在现实生活中非常常见:比如英汉词典就是英文与中文的对应关系,通过英文可以快速找到与其对应的中文,英文单词与其对应的中文 <word, chinese>就构成一种键值对;
再比如统计单词次数,统计成功后,给定单词就可快速找到其出现的次数,单词与其出现次数就是 <word, count> 就构成一种键值对。
下面我们就构造一个 KV 模型的二叉查找树,然后用这棵树来做一些应用。
🍑 构建KV模型的树
我这里直接用递归的方式实现整颗树,需要添加一个模板参数 Value,另外对于查找函数 Find 的返回值就不能写成 bool 类型了,而是需要写成 Node* 类型,因为 Key 不能被修改,但是我们可以通过返回的节点类型来修改 Key 对应的 Value。
代码实现
// KV模型
namespace key_value
{ // 节点类template<class K, class V>struct BSTreeNode{BSTreeNode<K, V>* _left; // 左指针BSTreeNode<K, V>* _right; // 右指针K _key; // 关键码V _value; // 对应的值// 构造函数BSTreeNode(const K& key, const V& value):_left(nullptr), _right(nullptr), _key(key), _value(value){}};// 二叉查找树类template<class K, class V>class BSTree{typedef BSTreeNode<K, V> Node;public:// 中序遍历void InOrder(){_InOrder(_root);cout << endl;}// 查找函数Node* FindR(const K& key){return _FindR(_root, key);}// 插入函数// 注意:这里除了要插入key,还要插入对应的valuebool InsertR(const K& key, const V& value){return _InsertR(_root, key, value);}// 删除函数(只需要删除key即可)bool EraseR(const K& key){return _EraseR(_root, key);}private:// 删除函数(递归删除子函数)bool _EraseR(Node*& root, const K& key){if (root == nullptr)return false;if (root->_key < key){return _EraseR(root->_right, key);}else if (root->_key > key){return _EraseR(root->_left, key);}else{Node* del = root;// 删除if (root->_left == nullptr){root = root->_right;}else if (root->_right == nullptr){root = root->_left;}else{Node* minRight = root->_right;while (minRight->_left){minRight = minRight->_left;}swap(root->_key, minRight->_key);return _EraseR(root->_right, key);}delete del;return true;}}// 插入函数(递归插入子函数)bool _InsertR(Node*& root, const K& key, const V& value){if (root == nullptr){root = new Node(key, value);return true;}if (root->_key < key)return _InsertR(root->_right, key, value);else if (root->_key > key)return _InsertR(root->_left, key, value);elsereturn false;}// 查找函数(递归查找子函数)Node* _FindR(Node* root, const K& key){if (root == nullptr)return nullptr;if (root->_key < key){return _FindR(root->_right, key);}else if (root->_key > key){return _FindR(root->_left, key);}else{return root;}}// 中序遍历(递归遍历子函数)void _InOrder(Node* root){if (root == nullptr)return;_InOrder(root->_left);cout << root->_key << ":" << root->_value << endl;_InOrder(root->_right);}private:Node* _root = nullptr;};
}
🍑 英汉词典
用这棵树实现一个简单的英汉词典 dict,可以通过英文找到与其对应的中文。
以 <单词, 中文含义> 为键值对构造二叉查找树时,二叉查找树需要进行键值对的比较,并且只需要比较 Key,查询英文单词时,只需给出英文单词,就可快速找到与其对应的 key。
代码实现
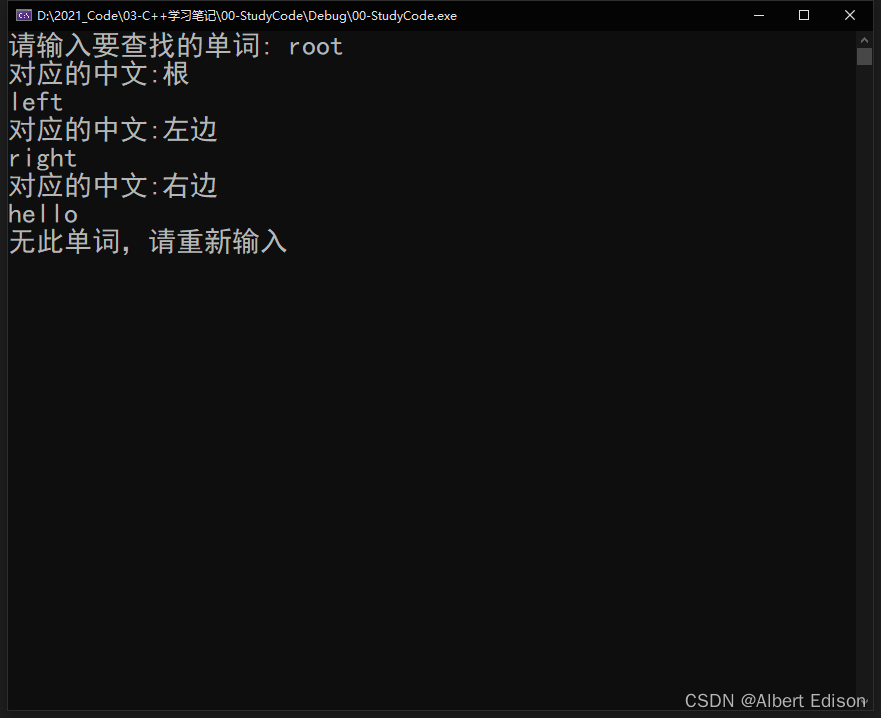
void TestBSTree1()
{BSTree<string, string> ECDict;ECDict.InsertR("root", "根");ECDict.InsertR("string", "字符串");ECDict.InsertR("left", "左边");ECDict.InsertR("insert", "插入");ECDict.InsertR("erase", "删除");ECDict.InsertR("right", "右边");cout << "请输入要查找的单词: ";string str; // 输入要查找的单词while (cin >> str){auto ret = ECDict.FindR(str);if (ret != nullptr){cout << "对应的中文:" << ret->_value << endl; // 如果单词存在,输出对应的中文}else{cout << "无此单词,请重新输入" << endl; // 如果单词不存在}}
}
可以看到,当我们输入树中存在的单词时,就会显示对应的中文,如果单词不存在,就不会显示。
如果我们要修改某个单词的中文也是可以的,只需要修改节点指向的 Value 即可。
🍑 统计水果出现的次数
KV 模型的二叉树还可以用来统计某个元素出现的次数。
比如下面有一组水果,现在我需要统计水果出现的次数,并输出。
代码实现
void TestBSTree2()
{string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };// 水果出现的次数BSTree<string, int> countTree; // key是字符串; value是次数for (const auto& str : arr){auto ret = countTree.FindR(str); // 查找该水果是否存在if (ret == nullptr) // 如果该水果不存在{countTree.InsertR(str, 1); // 就插入到树中,并把次数置为1(出现了一次)}else // 如果该水果存在{ret->_value++; // 就修改value}}// 打印结果countTree.InOrder();
}
可以看到水果的次数已经被统计出来了

3. 总结
对于 K 模型的二叉查找树上节课我们已经说过了,它有很多缺点,后面的 AVL树 就是在它的基础上进行优化的,那么与之对应的就是 STL 当中的 set 容器,它的底层就是一颗 K 模型的二叉查找树。
对于 KV 模型的二叉查找树,它与之对应的是 STL 当中的 map 容器,它的底层是一颗 KV 模型的二叉查找树。
相关文章:
二叉查找树的应用 —— K模型和KV模型
文章目录前言1. K模型2. KV模型🍑 构建KV模型的树🍑 英汉词典🍑 统计水果出现的次数3. 总结前言 在上一篇文章中,我们进行了二叉查找树的实现(文章链接),那么今天主要探讨一下二叉查找树的应用…...

深度学习实战(11):使用多层感知器分类器对手写数字进行分类
使用多层感知器分类器对手写数字进行分类 1.简介 1.1 什么是多层感知器(MLP)? MLP 是一种监督机器学习 (ML) 算法,属于前馈人工神经网络 [1] 类。该算法本质上是在数据上进行训练以学习函数。给定一组特征和一个目标变量&#x…...

ThingsBoard-警报
1、使用 IoT 设备警报 ThingsBoard 提供了创建和管理与您的实体相关的警报的能力:设备、资产、客户等。例如,您可以将 ThingsBoard 配置为在温度传感器读数高于某个阈值时自动创建警报。当然,这是一个非常简化的案例,实际场景可能要复杂得多。 2、主要概念 下面让我们回…...
如何去阅读源码,我总结了18条心法
在聊如何去阅读源码之前,先来简单说一下为什么要去阅读源码,大致可分为以下几点原因:最直接的原因,就是面试需要,面试喜欢问源码,读完源码才可以跟面试官battle提升自己的编程水平,学习编程思想…...
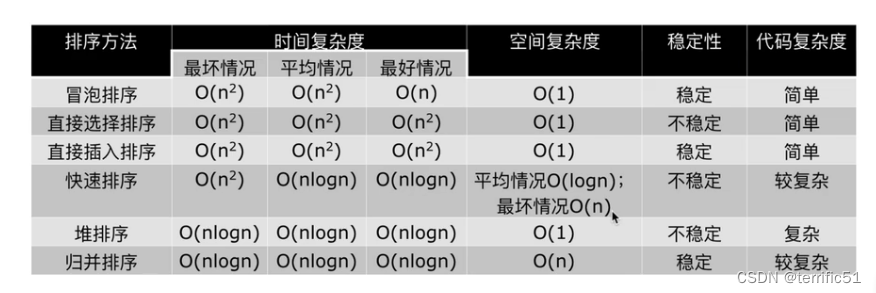
排序:归并排序
一、归并 li[2,4,5,7,//1,3,6,8]#归并的前提是必须两部分排好序 def merge(li,low,mid,high):ilowjmid1ltmp[]while i<mid and j<high: #只要左右两边都有数if li[i]<li[j]:ltmp.append(li[i])i1else:ltmp.append(li[j])j1#while执行完,肯定有一部分没数…...
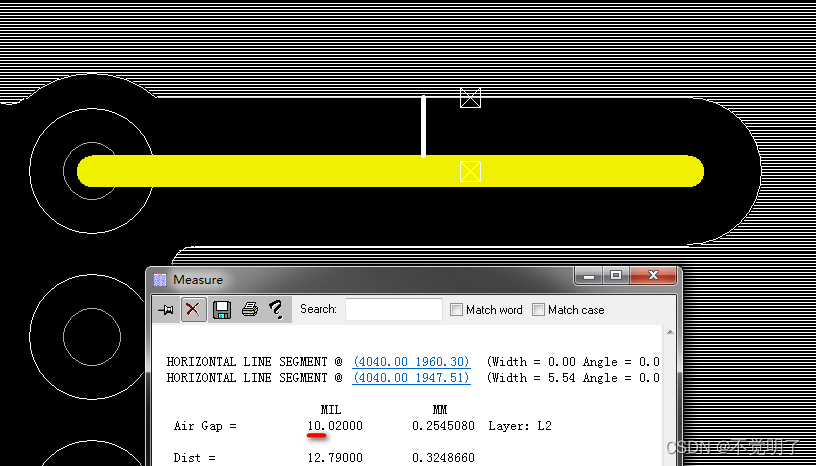
Allegro172版本线到铜皮不按照设定值避让的原因和解决办法
Allegro172版本线到铜皮不按照设定值避让的原因和解决办法 用Allegro做PCB设计的时候,有时会单独给某块铜皮附上线到铜皮额外再增加一个数值,如下图 在规则的基础上,额外再避让10mil 规则避让line到铜皮10.02mil 额外设置多避让10mil,避让的结果却是30.02mil,正确的是20.…...

小白该从哪方面入手学习大数据
大数据本质上是海量数据。 以往的数据开发,需要一定的Java基础和工作经验,门槛高,入门难。 如果零基础入门数据开发行业的小伙伴,可以从Python语言入手。 Python语言简单易懂,适合零基础入门,在编程语言…...
尚医通(十)数据字典加Redis缓存 | MongoDB
目录一、Redis介绍二、数据字典模块添加Redis缓存1、service_cmn模块,添加redis依赖2、service_cmn模块,添加Redis配置类3、在service_cmn模块,配置文件添加redis配置4、通过注解添加redis缓存5、查询数据字典列表添加Redis缓存6、bug&#x…...

为什么我们不再发明编程语言了?
上个世纪,数百种编程语言被发明出来,但是进入21世纪,当我们都进入互联网时代时,只剩那么寥寥几个了。 如果你翻一下TIOBE得编程语言排行榜,就会发现20年来,上蹿下跳的就是那几张老面孔:C , Java…...

预处理指令详解
预处理指令详解**1.预定义符号****2.#define****2.1 #define 定义标识符****2.2 #define 定义宏****2.3 #define 替换规则****2.4 #和##****#的作用****##的作用****2.5 带副作用的宏参数****2.6 宏和函数的对比****宏和函数对比图****2.7 命名约定****3.#undef**4.条件编译4.1…...
Redis
一.认识NoSQL 1.SQL 关系型数据库 结构化: 定义主键,无符号型数据等关联的:结构化表和表之间的关系通过外键进行关联,节省存储空间SQL查询:语法固定 SELECT id,name,age FROM tb_user WHERE id1 ACID 2.NoSQL 非关系型数据库 Re…...
Elasticsearch5.5.1 自定义评分插件开发
文本相似度插件开发,本文基于Elasticsearch5.5.1,Kibana5.5.1 下载地址为: Past Releases of Elastic Stack Software | Elastic 本地启动两个服务后,localhost:5601打开Kibana界面,点击devTools,效果图…...
4.4 序列化与反序列化
文章目录1.概述2.特点/应用场景3.涉及到的流对象4.代码实现序列化与反序列化4.1 步骤1:创建学生类Student24.2 步骤2:创建序列化测试类5.测试案例中常见的几种编译错误类型6.为什么反序列化版本号需要与序列化版本号一致?7.自动提示 生成UID …...

647. 回文子串 516. 最长回文子序列
647. 回文子串 方法一:动态规划 dp[i][j]:[i,j]范围的下标字符串s是否为回文子串 遍历字符串,每次判断s[i]与s[j]是否相等 ①若相等,j-i0 即单个字符串s[i],那么一定为回文子串,赋值为1 ②若相等,j-i1…...

实用小妙招
记录一些实用小妙招,都是收藏夹里收藏的各种文章,总结在一起,持续更新 实用小妙招LinuxUbuntu修改终端语言安装 Node.js (nvm)git 记住账号密码WSL迁移默认用户修改Linux Ubuntu 修改终端语言 apt update apt install -y language-pack-zh…...

别让猴子跳回背上
1.管理者的贡献来自于他们的判断力与影响力,而非他们所投入的个人时间与埋头苦干 2.管理者的绩效表现则是许多人群策群力的结果 3.管理者的时间管理: 老板占用的时间;组织占用的时间;自己占用的时间;外界占用的时间; 4.管理者的策略在于增加自己的时间,…...
数据结构 | 线性表
🔥Go for it!🔥 📝个人主页:按键难防 📫 如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀 📖系列专栏:数据结构与算法 ὒ…...

Deepwalk深度游走算法
主要思想 Deepwalk是一种将随机游走和word2vec两种算法相结合的图结构数据的挖掘算法。该算法可以学习网络的隐藏信息,能够将图中的节点表示为一个包含潜在信息的向量, Deepwalk算法 该算法主要分为随机游走和生成表示向量两个部分,首先…...
微服务项目【服务调用分布式session共享】
nginx动静分离 第1步:通过SwitchHosts新增二级域名:images.zmall.com 第2步:将本次项目的所有静态资源js/css/images复制到nginx中的html目录下 第3步:在nginx的核心配置文件nginx.conf中新增二级域名images.zmall.com访问映射…...

神经网络的万能逼近定理
这是我见过的讨论神经网络万有逼近问题的最好的文章。在文章中,给出了最清晰,简洁的构造性证明。揭示了它的本质。 三十年前,我们接触到神经网络的万有逼近问题。发表了几篇文章。这些文章把神经网络能力的来历、优点、缺点,都已…...

Spring Boot项目SQL执行监控实战:手把手集成P6spy,自定义日志格式并输出到文件
Spring Boot生产环境SQL监控全方案:P6spy高阶配置与日志持久化实战 当你负责的电商系统在促销活动期间突然出现响应迟缓,或是金融交易系统在月末结算时频繁超时,数据库查询性能往往是首要怀疑对象。但生产环境的数据库通常不允许直接连接进行…...

告别手动操作!用Word宏/VBA实现doc批量转docx的隐藏技巧
职场效率革命:Word宏/VBA零代码实现文档格式批量升级 每天面对堆积如山的.doc文件,行政文员小张总要手动打开每个文件另存为.docx格式——这个机械操作不仅耗时费力,还容易遗漏文件。其实微软Office内置的自动化工具能完美解决这个问题&#…...

别再瞎找了!AI论文软件2026最新测评与推荐
2026年真正好用的AI论文软件,核心看生成的论文质量、低AI味、格式正确、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 一、…...

JeecgBoot低代码开发平台终极实战指南:从零开始构建企业级应用
JeecgBoot低代码开发平台终极实战指南:从零开始构建企业级应用 【免费下载链接】jeecg-boot jeecgboot/jeecg-boot 是一个基于 Spring Boot 的 Java 框架,用于快速开发企业级应用。适合在 Java 应用开发中使用,提高开发效率和代码质量。特点是…...

OpenClaw+Qwen3.5-4B-Claude:个人知识库自动更新系统
OpenClawQwen3.5-4B-Claude:个人知识库自动更新系统 1. 为什么需要自动化知识管理 作为一个技术从业者,我每天都会接触到大量信息——技术博客、论文摘要、行业动态、代码库更新等等。过去三年里,我尝试过各种笔记工具和知识管理方法&#…...
)
别再纠结了!用SpringBoot实战告诉你,图片上传选FastDFS还是MinIO(附完整代码)
SpringBoot实战:FastDFS与MinIO文件存储方案深度对比与选型指南 在当今数据驱动的互联网应用中,文件存储系统如同数字世界的基础设施,支撑着从用户头像到高清视频的各种数据存取需求。作为Java开发者,当我们面对"选择困难症&…...

企业级流程引擎如何重塑低代码开发?基于Vite+Vue3的可视化建模实践
企业级流程引擎如何重塑低代码开发?基于ViteVue3的可视化建模实践 【免费下载链接】vite-vue-bpmn-process 基于 Vite TypeScript Vue3 NaiveUI Bpmn.js 的流程编辑器(前端部分)。支持高度自定义🚀🚀🚀。…...

基于spring和vue的企业原材料库存盘点食品厂管理系统
目录技术选型与架构设计核心功能模块划分数据库设计要点关键技术实现前端交互优化系统安全措施测试与部署方案扩展性设计项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作技术选型与架构设计 后端采用Spring Boot框架࿰…...

OpCore-Simplify:智能化解构OpenCore EFI配置难题,让黑苹果安装不再复杂
OpCore-Simplify:智能化解构OpenCore EFI配置难题,让黑苹果安装不再复杂 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为…...

aircrack-ng使用教程
aircrack-ng是一款用于无线网络安全评估的工具套件,主要用于破解WEP和WPA/WPA2-PSK加密的无线网络密码。它通过分析捕获的数据包,利用密码破解技术来获取网络密钥,是网络安全测试和渗透测试中常用的工具之一。该工具支持多种攻击模式和优化选…...