深度学习实战(11):使用多层感知器分类器对手写数字进行分类
使用多层感知器分类器对手写数字进行分类

1.简介
1.1 什么是多层感知器(MLP)?
MLP 是一种监督机器学习 (ML) 算法,属于前馈人工神经网络 [1] 类。该算法本质上是在数据上进行训练以学习函数。给定一组特征和一个目标变量(例如标签),它会学习一个用于分类或回归的非线性函数。在本文中,我们将只关注分类案例。
1.2 MLP和逻辑回归有什么相似之处吗?
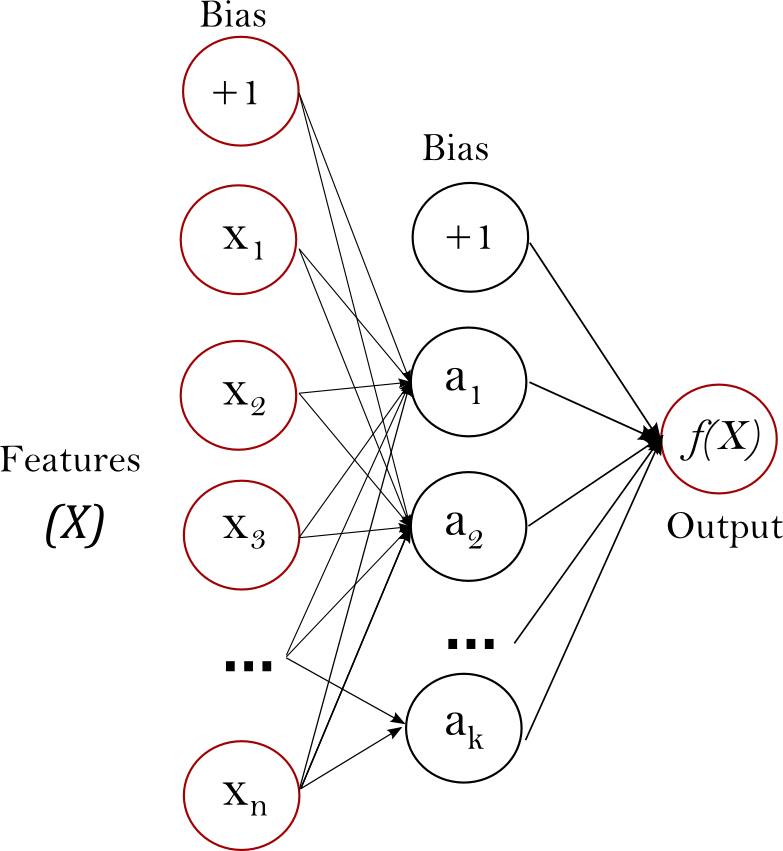
有!逻辑回归只有两层,即输入和输出,但是,在 MLP 模型的情况下,唯一的区别是我们可以有额外的中间非线性层。这些被称为隐藏层。除了输入节点(属于输入层的节点)之外,每个节点都是一个使用非线性激活函数的神经元[1]。由于这种非线性性质,MLP 可以学习复杂的非线性函数,从而区分不可线性分离的数据!请参见下面的图 2,了解具有一个隐藏层的 MLP 分类器的可视化表示。
1.3 MLP 是如何训练的?
MLP 使用反向传播进行训练。
1.4 MLP的主要优缺点.
优点:
- 可以学习非线性函数,从而分离不可线性分离的数据 。
缺点: - 隐藏层的损失函数导致非凸优化问题,因此存在局部最小值。
- 不同的权重初始化可能会导致不同的输出/权重/结果。
- MLP 有一些超参数,例如隐藏神经元的数量,需要调整的层数(时间和功耗)。
- MLP 可能对特征缩放敏感 。
2.使用scikit-learn的Python动手实例
2.1 数据集
对于这个实践示例,我们将使用 MNIST 数据集。 MNIST 数据库是一个著名的手写数字数据库,用于训练多个 ML 模型 。有 10 个不同数字的手写图像,因此类别数为 10 (参见图 3)。
注意:由于我们处理图像,因此这些由二维数组表示,并且数据的初始维度是每个图像的 28 by 28 ( 28x28 pixels )。然后二维图像被展平,因此在最后由矢量表示。每个 2D 图像都被转换为维度为 [1, 28x28] = [1, 784] 的 1D 向量。最后,我们的数据集有 784 个特征/变量/列。

2.2 数据导入与准备
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_openml
from sklearn.neural_network import MLPClassifier
# Load data
X, y = fetch_openml("mnist_784", version=1, return_X_y=True)
# Normalize intensity of images to make it in the range [0,1] since 255 is the max (white).
X = X / 255.0
请记住,每个 2D 图像现在都转换为维度为 [1, 28x28] = [1, 784] 的 1D 矢量。我们现在来验证一下。
print(X.shape)
这将返回: (70000, 784) 。我们有 70k 个扁平图像(样本),每个图像包含 784 个像素(28*28=784)(变量/特征)。
因此,输入层权重矩阵的形状为
784 x #neurons_in_1st_hidden_layer.
输出层权重矩阵的形状为
#neurons_in_3rd_hidden_layer x #number_of_classes
2.3 模型训练
现在让我们构建模型、训练它并执行分类。我们将分别使用 3 个隐藏层和 50,20 and 10 个神经元。此外,我们将设置最大迭代次数 100 ,并将学习率设置为 0.1 。这些是我在简介中提到的超参数。我们不会在这里微调它们。
# Split the data into train/test sets
X_train, X_test = X[:60000], X[60000:]
y_train, y_test = y[:60000], y[60000:]
classifier = MLPClassifier(hidden_layer_sizes=(50,20,10),max_iter=100,alpha=1e-4,solver="sgd",verbose=10,random_state=1,learning_rate_init=0.1,
)
# fit the model on the training data
classifier.fit(X_train, y_train)
2.4 模型评估
现在,让我们评估模型。我们将估计训练和测试数据和标签的平均准确度。
print("Training set score: %f" % classifier.score(X_train, y_train))
print("Test set score: %f" % classifier.score(X_test, y_test))
训练集分数:
0.998633
测试集分数:
0.970300
2.5 成本函数演变的可视化
训练期间损失减少的速度有多快?让我们制作一个漂亮的图表看一看!
fig, axes = plt.subplots(1, 1)
axes.plot(classifier.loss_curve_, 'o-')
axes.set_xlabel("number of iteration")
axes.set_ylabel("loss")
plt.show()
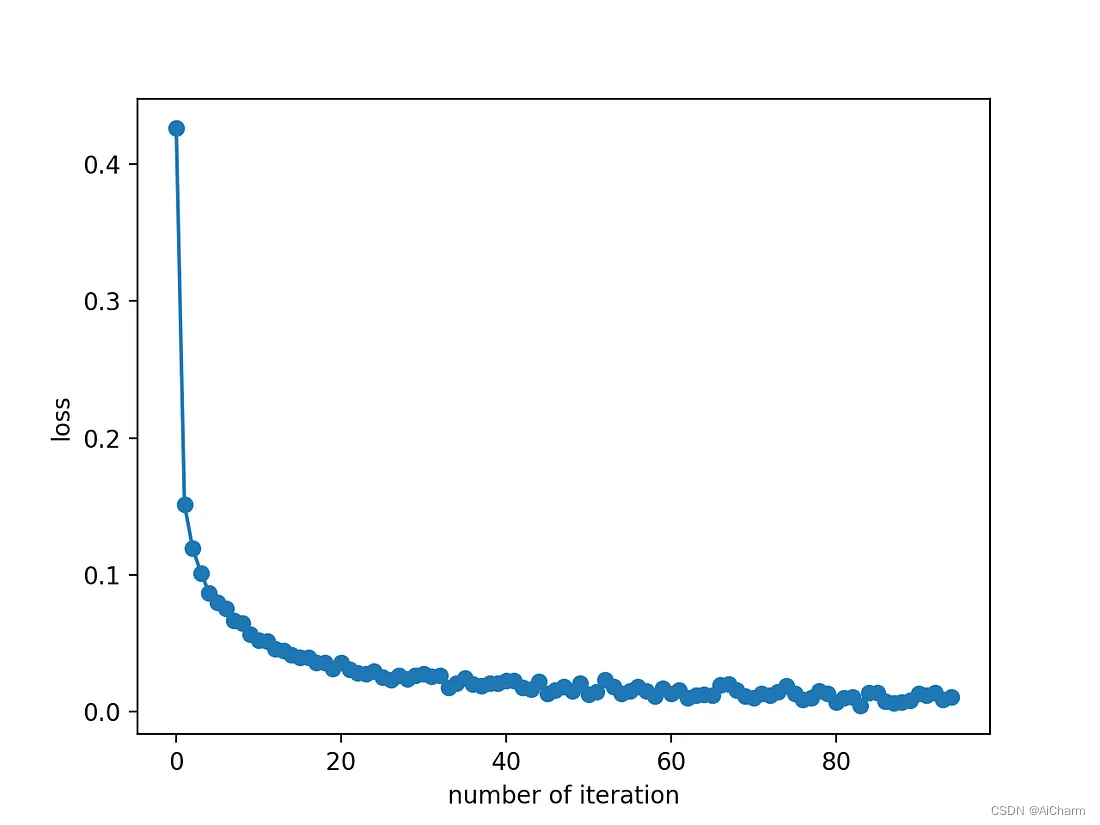
在这里,我们看到损失在训练期间下降得非常快,并且在 40th 迭代后饱和(请记住,我们将最大 100 次迭代定义为超参数)。
2.6 可视化学习到的权重
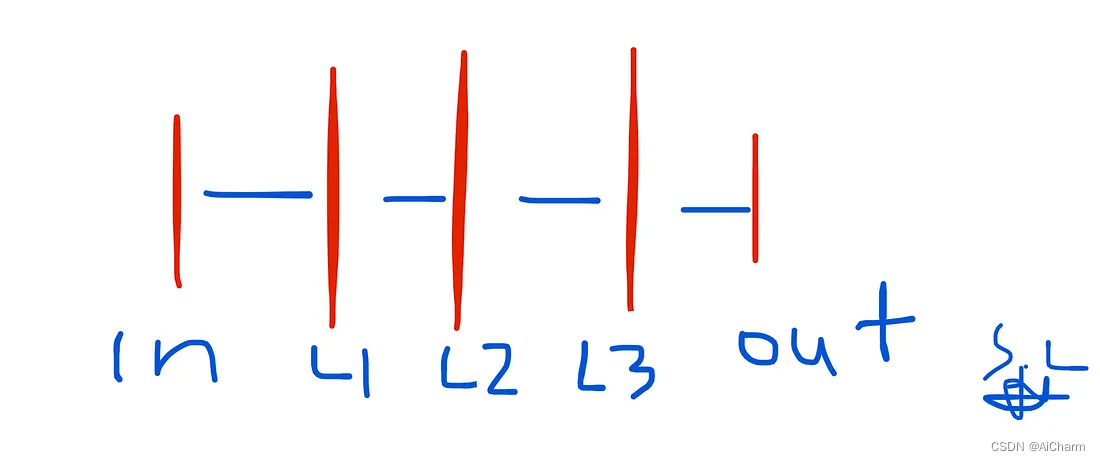
这里我们首先需要了解权重(每一层的学习模型参数)是如何存储的。
根据文档,属性 classifier.coefs_ 是形状为 (n_layers-1, ) 的权重数组的列表,其中索引 i 处的权重矩阵表示层 i 和层 i+1 之间的权重。在这个例子中,我们定义了 3 个隐藏层,我们还有输入层和输出层。因此,我们希望层间权重有 4 个权重数组(图 5 中的 in-L1, L1-L2, L2-L3 和 L2-out )。
类似地, classifier.intercepts_ 是偏置向量列表,其中索引 i 处的向量表示添加到层 i+1 的偏置值。
让我们验证一下:
len(classifier.intercepts_) == len(classifier.coefs_) == 4
正确返回 True 。
输入层权重矩阵的形状为
784 x #neurons_in_1st_hidden_layer.
输出层权重矩阵的形状为
#neurons_in_3rd_hidden_layer x #number_of_classes.
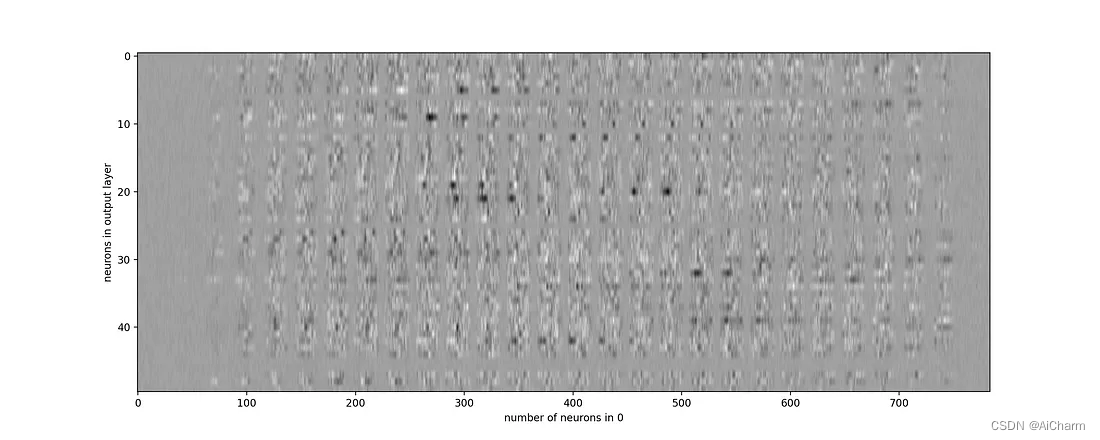
2.7 可视化输入层的学习权重
target_layer = 0 #0 is input, 1 is 1st hidden etc
fig, axes = plt.subplots(1, 1, figsize=(15,6))
axes.imshow(np.transpose(classifier.coefs_[target_layer]), cmap=plt.get_cmap("gray"), aspect="auto")
axes.set_xlabel(f"number of neurons in {target_layer}")
axes.set_ylabel("neurons in output layer")
plt.show()
将它们重新整形并绘制为 2D 图像。
# choose layer to plot
target_layer = 0 #0 is input, 1 is 1st hidden etc
fig, axes = plt.subplots(4, 4)
vmin, vmax = classifier.coefs_[0].min(), classifier.coefs_[target_layer].max()
for coef, ax in zip(classifier.coefs_[0].T, axes.ravel()):ax.matshow(coef.reshape(28, 28), cmap=plt.cm.gray, vmin=0.5 * vmin, vmax=0.5 * vmax)ax.set_xticks(())ax.set_yticks(())
plt.show()
3.总结
MLP 分类器是一种非常强大的神经网络模型,可以学习复杂数据的非线性函数。该方法使用前向传播来构建权重,然后计算损失。接下来,反向传播用于更新权重,从而减少损失。这是以迭代方式完成的,迭代次数是一个输入超参数,正如我在简介中所解释的那样。其他重要的超参数是每个隐藏层中的神经元数量和隐藏层总数。这些都需要微调。
更多Ai资讯:公主号AiCharm

相关文章:
深度学习实战(11):使用多层感知器分类器对手写数字进行分类
使用多层感知器分类器对手写数字进行分类 1.简介 1.1 什么是多层感知器(MLP)? MLP 是一种监督机器学习 (ML) 算法,属于前馈人工神经网络 [1] 类。该算法本质上是在数据上进行训练以学习函数。给定一组特征和一个目标变量&#x…...

ThingsBoard-警报
1、使用 IoT 设备警报 ThingsBoard 提供了创建和管理与您的实体相关的警报的能力:设备、资产、客户等。例如,您可以将 ThingsBoard 配置为在温度传感器读数高于某个阈值时自动创建警报。当然,这是一个非常简化的案例,实际场景可能要复杂得多。 2、主要概念 下面让我们回…...
如何去阅读源码,我总结了18条心法
在聊如何去阅读源码之前,先来简单说一下为什么要去阅读源码,大致可分为以下几点原因:最直接的原因,就是面试需要,面试喜欢问源码,读完源码才可以跟面试官battle提升自己的编程水平,学习编程思想…...
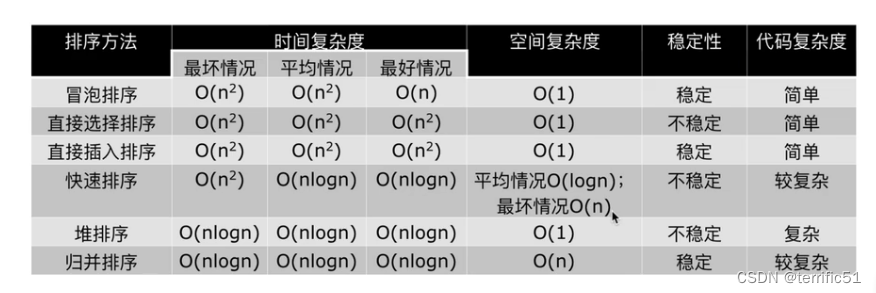
排序:归并排序
一、归并 li[2,4,5,7,//1,3,6,8]#归并的前提是必须两部分排好序 def merge(li,low,mid,high):ilowjmid1ltmp[]while i<mid and j<high: #只要左右两边都有数if li[i]<li[j]:ltmp.append(li[i])i1else:ltmp.append(li[j])j1#while执行完,肯定有一部分没数…...
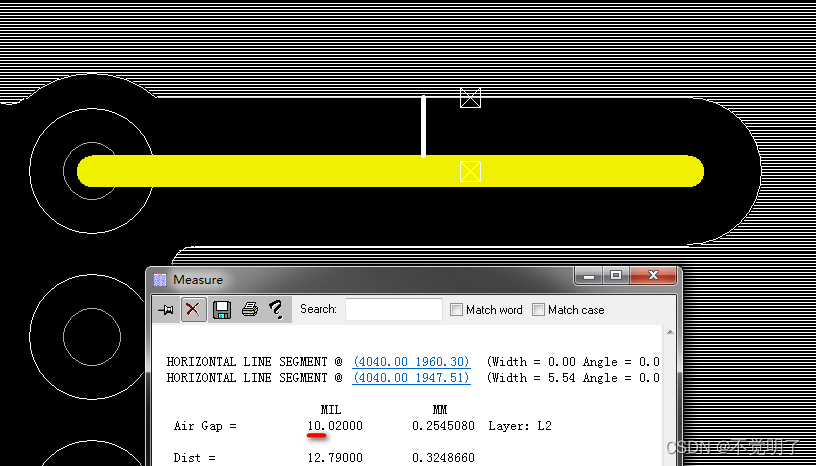
Allegro172版本线到铜皮不按照设定值避让的原因和解决办法
Allegro172版本线到铜皮不按照设定值避让的原因和解决办法 用Allegro做PCB设计的时候,有时会单独给某块铜皮附上线到铜皮额外再增加一个数值,如下图 在规则的基础上,额外再避让10mil 规则避让line到铜皮10.02mil 额外设置多避让10mil,避让的结果却是30.02mil,正确的是20.…...

小白该从哪方面入手学习大数据
大数据本质上是海量数据。 以往的数据开发,需要一定的Java基础和工作经验,门槛高,入门难。 如果零基础入门数据开发行业的小伙伴,可以从Python语言入手。 Python语言简单易懂,适合零基础入门,在编程语言…...
尚医通(十)数据字典加Redis缓存 | MongoDB
目录一、Redis介绍二、数据字典模块添加Redis缓存1、service_cmn模块,添加redis依赖2、service_cmn模块,添加Redis配置类3、在service_cmn模块,配置文件添加redis配置4、通过注解添加redis缓存5、查询数据字典列表添加Redis缓存6、bug&#x…...

为什么我们不再发明编程语言了?
上个世纪,数百种编程语言被发明出来,但是进入21世纪,当我们都进入互联网时代时,只剩那么寥寥几个了。 如果你翻一下TIOBE得编程语言排行榜,就会发现20年来,上蹿下跳的就是那几张老面孔:C , Java…...

预处理指令详解
预处理指令详解**1.预定义符号****2.#define****2.1 #define 定义标识符****2.2 #define 定义宏****2.3 #define 替换规则****2.4 #和##****#的作用****##的作用****2.5 带副作用的宏参数****2.6 宏和函数的对比****宏和函数对比图****2.7 命名约定****3.#undef**4.条件编译4.1…...
Redis
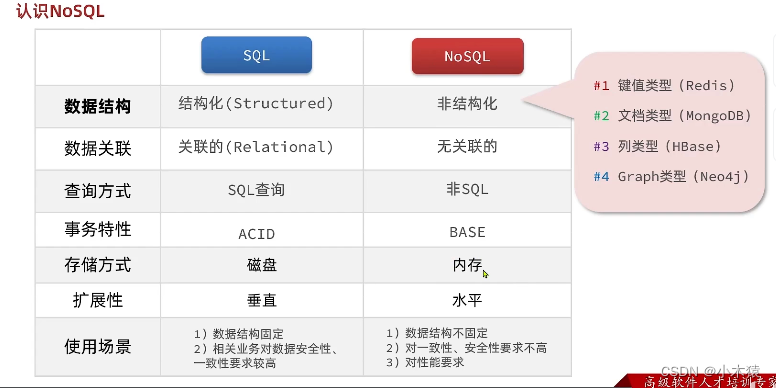
一.认识NoSQL 1.SQL 关系型数据库 结构化: 定义主键,无符号型数据等关联的:结构化表和表之间的关系通过外键进行关联,节省存储空间SQL查询:语法固定 SELECT id,name,age FROM tb_user WHERE id1 ACID 2.NoSQL 非关系型数据库 Re…...
Elasticsearch5.5.1 自定义评分插件开发
文本相似度插件开发,本文基于Elasticsearch5.5.1,Kibana5.5.1 下载地址为: Past Releases of Elastic Stack Software | Elastic 本地启动两个服务后,localhost:5601打开Kibana界面,点击devTools,效果图…...
4.4 序列化与反序列化
文章目录1.概述2.特点/应用场景3.涉及到的流对象4.代码实现序列化与反序列化4.1 步骤1:创建学生类Student24.2 步骤2:创建序列化测试类5.测试案例中常见的几种编译错误类型6.为什么反序列化版本号需要与序列化版本号一致?7.自动提示 生成UID …...

647. 回文子串 516. 最长回文子序列
647. 回文子串 方法一:动态规划 dp[i][j]:[i,j]范围的下标字符串s是否为回文子串 遍历字符串,每次判断s[i]与s[j]是否相等 ①若相等,j-i0 即单个字符串s[i],那么一定为回文子串,赋值为1 ②若相等,j-i1…...

实用小妙招
记录一些实用小妙招,都是收藏夹里收藏的各种文章,总结在一起,持续更新 实用小妙招LinuxUbuntu修改终端语言安装 Node.js (nvm)git 记住账号密码WSL迁移默认用户修改Linux Ubuntu 修改终端语言 apt update apt install -y language-pack-zh…...

别让猴子跳回背上
1.管理者的贡献来自于他们的判断力与影响力,而非他们所投入的个人时间与埋头苦干 2.管理者的绩效表现则是许多人群策群力的结果 3.管理者的时间管理: 老板占用的时间;组织占用的时间;自己占用的时间;外界占用的时间; 4.管理者的策略在于增加自己的时间,…...
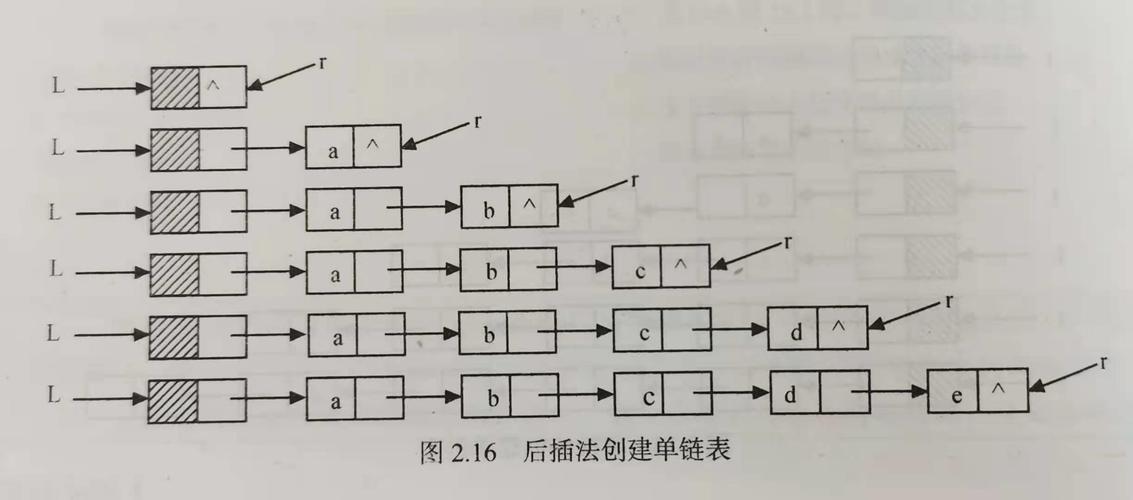
数据结构 | 线性表
🔥Go for it!🔥 📝个人主页:按键难防 📫 如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀 📖系列专栏:数据结构与算法 ὒ…...

Deepwalk深度游走算法
主要思想 Deepwalk是一种将随机游走和word2vec两种算法相结合的图结构数据的挖掘算法。该算法可以学习网络的隐藏信息,能够将图中的节点表示为一个包含潜在信息的向量, Deepwalk算法 该算法主要分为随机游走和生成表示向量两个部分,首先…...
微服务项目【服务调用分布式session共享】
nginx动静分离 第1步:通过SwitchHosts新增二级域名:images.zmall.com 第2步:将本次项目的所有静态资源js/css/images复制到nginx中的html目录下 第3步:在nginx的核心配置文件nginx.conf中新增二级域名images.zmall.com访问映射…...

神经网络的万能逼近定理
这是我见过的讨论神经网络万有逼近问题的最好的文章。在文章中,给出了最清晰,简洁的构造性证明。揭示了它的本质。 三十年前,我们接触到神经网络的万有逼近问题。发表了几篇文章。这些文章把神经网络能力的来历、优点、缺点,都已…...

【信息系统项目管理师】项目管理过程的三万字大论文
【信息系统项目管理师】项目管理过程的三万字大论文 【信息系统项目管理师】项目管理过程的三万字大论文 【信息系统项目管理师】项目管理过程的三万字大论文1.制定项目章程2.识别干系人3.制定范围管理计划4.制定进度管理计划5.制定成本管理计划6.制定质量管理计划7.编制人力资…...

AtlasOS系统性能优化指南:从诊断到维护的全流程解决方案
AtlasOS系统性能优化指南:从诊断到维护的全流程解决方案 【免费下载链接】Atlas 🚀 An open and lightweight modification to Windows, designed to optimize performance, privacy and security. 项目地址: https://gitcode.com/GitHub_Trending/atl…...

如何快速掌握扩散模型:PyTorch实现的终极指南
如何快速掌握扩散模型:PyTorch实现的终极指南 【免费下载链接】Diffusion-Models-pytorch Pytorch implementation of Diffusion Models (https://arxiv.org/pdf/2006.11239.pdf) 项目地址: https://gitcode.com/gh_mirrors/di/Diffusion-Models-pytorch 想要…...

OpenClaw人人养虾:接入iMessage
此方案为旧版 iMessage 接入方式,仅适用于 macOS 且配置复杂。新用户请优先使用 BlueBubbles 方案,它更稳定且功能更丰富。 前置要求 macOS 12 Monterey 或更高版本(仅支持 macOS)已登录 Apple ID 并激活 iMessageHomebrew 包管…...

Windows下OpenClaw实战:30分钟接入Qwen3.5-4B-Claude模型
Windows下OpenClaw实战:30分钟接入Qwen3.5-4B-Claude模型 1. 为什么选择WindowsOpenClaw组合 去年我在尝试自动化办公流程时,发现很多AI工具对Windows支持并不友好。直到遇到OpenClaw,这个开源的智能体框架让我眼前一亮——它不仅能像人类一…...
)
Windows 11下保姆级安装Isaac Sim 4.5.0与Isaac Lab避坑全记录(含CUDA 12.8配置)
Windows 11下Isaac Sim 4.5.0与Isaac Lab全流程部署指南(RTX 4090实测版) 对于机器人仿真和AI开发领域的从业者来说,NVIDIA Isaac Sim和Isaac Lab无疑是当前最强大的工具组合之一。然而,当我在自己的RTX 4090显卡上首次尝试部署这…...

luci-app-unblockneteasemusic技术指南:解决网易云音乐播放限制问题
luci-app-unblockneteasemusic技术指南:解决网易云音乐播放限制问题 【免费下载链接】luci-app-unblockneteasemusic [OpenWrt] 解除网易云音乐播放限制 项目地址: https://gitcode.com/gh_mirrors/lu/luci-app-unblockneteasemusic 一、问题导向:…...

南北阁 4.1-3B 开源镜像实战:Streamlit轻量化UI+CoT折叠展示一文详解
南北阁 4.1-3B 开源镜像实战:Streamlit轻量化UICoT折叠展示一文详解 想快速体验一个能在本地流畅运行、还能“看见”模型思考过程的智能对话工具吗?今天要介绍的,就是基于南北阁(Nanbeige)4.1-3B模型打造的轻量化流式…...
)
HFSS建模进阶:如何高效使用布尔运算和局部坐标系(实战案例解析)
HFSS建模进阶:布尔运算与局部坐标系的高效实战指南 在微波器件和天线设计的数字世界里,精确的三维建模往往是成功仿真的第一步。当您已经掌握了HFSS的基础建模操作后,如何将建模效率提升到专业水平?本文将带您深入探索两个常被忽视…...

避开这5个坑!VS2019+Doxygen注释实战:从代码规范到HTML文档生成
VS2019Doxygen注释实战:5个典型陷阱与高效解决方案 在C项目开发中,良好的代码文档是团队协作的基石。Visual Studio 2019与Doxygen的组合为开发者提供了强大的自动化文档生成能力,但许多团队在实际应用中常陷入一些看似简单却影响深远的陷阱。…...

LingBot-Depth部署避坑指南:常见问题与解决方案汇总
LingBot-Depth部署避坑指南:常见问题与解决方案汇总 1. 引言:为什么需要这份指南 当你第一次尝试部署LingBot-Depth时,可能会遇到各种意想不到的问题——从模型下载失败到GPU内存不足,从端口冲突到奇怪的输出结果。这些问题往往…...