pytorch复现3_GoogLenet
背景:
GoogLeNeta是2014年提出的一种全新的深度学习结构,在这之前的AlexNet、VGG等结构都是通过增大网络的深度(层数)来获得更好的训练效果,但层数的增加会带来很多负作用,比如overfit、梯度消失、梯度爆炸等。GoogLeNet通过引入inception从另一种角度来提升训练结果:能更高效的利用计算资源,在相同的计算量下能提取到更多的特征,从而提升训练结果。
因此GoogLeNet在专注于加深网络结构的同时,引入了新的基本结构——Inception模块,以增加网络的宽度。
网络结构图:
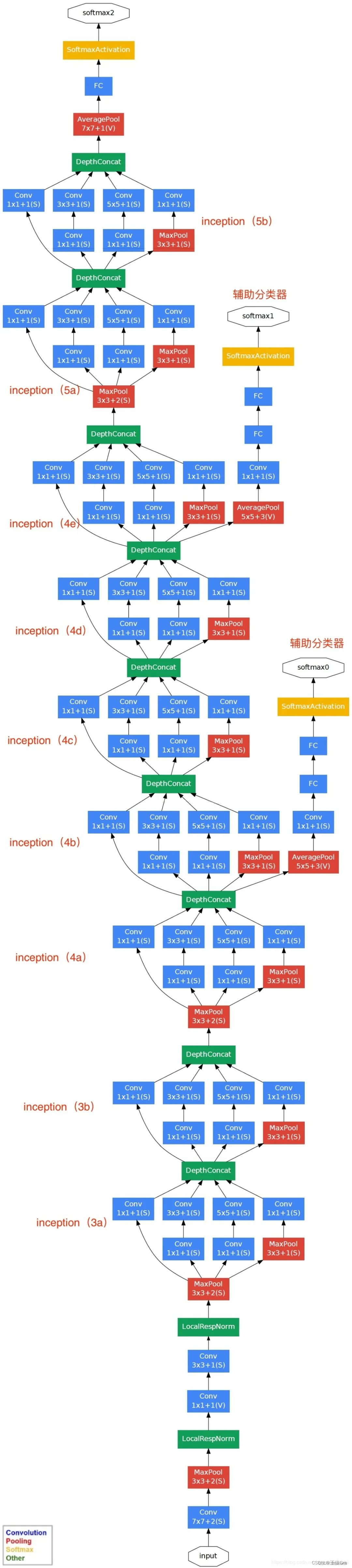
1、Inception模块
Inception就是把多个卷积或池化操作,放在一起组装成一个网络模块
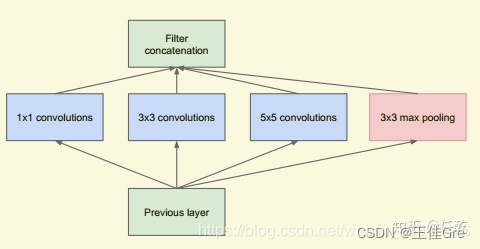
实际中需要什么样的Inception
我们在上面提供了一种Inception的结构,但是这个结构存在很多问题,是不能够直接使用的。首要问题就是参数太多,导致特征图厚度太大。为了解决这个问题,作者在其中加入了1X1的卷积核,改进后的Inception结构如下图:
代码:
定义BasicConv2d
class BasicConv2d(nn.Module):def __init__(self, in_channels, out_channels, **kwargs):super(BasicConv2d, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)self.relu = nn.ReLU(inplace=True)def forward(self, x):x = self.conv(x)x = self.relu(x)return x
定义Inception
class Inception(nn.Module):def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):super(Inception, self).__init__()self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)self.branch2 = nn.Sequential(BasicConv2d(in_channels, ch3x3red, kernel_size=1),BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小)self.branch3 = nn.Sequential(BasicConv2d(in_channels, ch5x5red, kernel_size=1),BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2) # 保证输出大小等于输入大小)self.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),BasicConv2d(in_channels, pool_proj, kernel_size=1))
定义分类器
class InceptionAux(nn.Module):def __init__(self, in_channels, num_classes):super(InceptionAux, self).__init__()self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4]self.fc1 = nn.Linear(2048, 1024)self.fc2 = nn.Linear(1024, num_classes)def forward(self, x):# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14x = self.averagePool(x)# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4x = self.conv(x)# N x 128 x 4 x 4x = torch.flatten(x, 1)x = F.dropout(x, 0.5, training=self.training)# N x 2048x = F.relu(self.fc1(x), inplace=True)x = F.dropout(x, 0.5, training=self.training)# N x 1024x = self.fc2(x)# N x num_classesreturn xmodel完整代码:
import torch.nn as nn
import torch
import torch.nn.functional as Fclass GoogLeNet(nn.Module):def __init__(self, num_classes=1000, aux_logits=True, init_weights=False):super(GoogLeNet, self).__init__()self.aux_logits = aux_logitsself.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)self.conv2 = BasicConv2d(64, 64, kernel_size=1)self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)self.maxpool4 = nn.MaxPool2d(3, stride=2, ceil_mode=True)self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)if self.aux_logits:self.aux1 = InceptionAux(512, num_classes)self.aux2 = InceptionAux(528, num_classes)self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.dropout = nn.Dropout(0.4)self.fc = nn.Linear(1024, num_classes)if init_weights:self._initialize_weights()def forward(self, x):# N x 3 x 224 x 224x = self.conv1(x)# N x 64 x 112 x 112x = self.maxpool1(x)# N x 64 x 56 x 56x = self.conv2(x)# N x 64 x 56 x 56x = self.conv3(x)# N x 192 x 56 x 56x = self.maxpool2(x)# N x 192 x 28 x 28x = self.inception3a(x)# N x 256 x 28 x 28x = self.inception3b(x)# N x 480 x 28 x 28x = self.maxpool3(x)# N x 480 x 14 x 14x = self.inception4a(x)# N x 512 x 14 x 14if self.training and self.aux_logits: # eval model lose this layeraux1 = self.aux1(x)x = self.inception4b(x)# N x 512 x 14 x 14x = self.inception4c(x)# N x 512 x 14 x 14x = self.inception4d(x)# N x 528 x 14 x 14if self.training and self.aux_logits: # eval model lose this layeraux2 = self.aux2(x)x = self.inception4e(x)# N x 832 x 14 x 14x = self.maxpool4(x)# N x 832 x 7 x 7x = self.inception5a(x)# N x 832 x 7 x 7x = self.inception5b(x)# N x 1024 x 7 x 7x = self.avgpool(x)# N x 1024 x 1 x 1x = torch.flatten(x, 1)# N x 1024x = self.dropout(x)x = self.fc(x)# N x 1000 (num_classes)if self.training and self.aux_logits: # eval model lose this layerreturn x, aux2, aux1return xdef _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)nn.init.constant_(m.bias, 0)class Inception(nn.Module):def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):super(Inception, self).__init__()self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)self.branch2 = nn.Sequential(BasicConv2d(in_channels, ch3x3red, kernel_size=1),BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小)self.branch3 = nn.Sequential(BasicConv2d(in_channels, ch5x5red, kernel_size=1),BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2) # 保证输出大小等于输入大小)self.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),BasicConv2d(in_channels, pool_proj, kernel_size=1))def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(x)outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1)class InceptionAux(nn.Module):def __init__(self, in_channels, num_classes):super(InceptionAux, self).__init__()self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4]self.fc1 = nn.Linear(2048, 1024)self.fc2 = nn.Linear(1024, num_classes)def forward(self, x):# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14x = self.averagePool(x)# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4x = self.conv(x)# N x 128 x 4 x 4x = torch.flatten(x, 1)x = F.dropout(x, 0.5, training=self.training)# N x 2048x = F.relu(self.fc1(x), inplace=True)x = F.dropout(x, 0.5, training=self.training)# N x 1024x = self.fc2(x)# N x num_classesreturn xclass BasicConv2d(nn.Module):def __init__(self, in_channels, out_channels, **kwargs):super(BasicConv2d, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)self.relu = nn.ReLU(inplace=True)def forward(self, x):x = self.conv(x)x = self.relu(x)return x
相关文章:
pytorch复现3_GoogLenet
背景: GoogLeNeta是2014年提出的一种全新的深度学习结构,在这之前的AlexNet、VGG等结构都是通过增大网络的深度(层数)来获得更好的训练效果,但层数的增加会带来很多负作用,比如overfit、梯度消失、梯度爆炸等。GoogLeNet通过引入i…...

CH09_重新组织数据
拆分变量(Split Variable) 曾用名:移除对参数的赋值(Remove Assignments to Parameters) 曾用名:分解临时变量(Split Temp) let temp 2 * (height width); console.log(temp); t…...

最新 IntelliJ IDEA 旗舰版和社区版下载安装教程(图解)
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...
优化 FPGA HLS 设计
优化 FPGA HLS 设计 用工具用 C 生成 RTL 的代码基本不可读。以下是如何在不更改任何 RTL 的情况下提高设计性能。 介绍 高级设计能够以简洁的方式捕获设计,从而减少错误并更容易调试。然而,经常出现的问题是性能权衡。在高度复杂的 FPGA 设计中实现高性…...

LVGL库入门 01 - 样式
一、LVGL样式概述 1、创建样式 在 LVGL 中,样式都是以对象的方式存在,一个对象可以描述一种样式。每个控件都可以独立添加样式,创建的样式之间互不影响。 可以使用 lv_style_t 类型创建一个样式并初始化: static lv_style_t s…...

酷克数据出席永洪科技用户大会 携手驱动商业智能升级
10月27日,第7届永洪科技全国用户大会在北京召开。酷克数据作为国内云原生数仓代表企业,受邀出席本次大会,全面展示了云数仓领域最新前沿技术,并进行主题演讲。 携手合作 助力企业释放数据价值 数据仓库是商业智能(BI…...

英语教育目标转变:更加注重实际应用能力培养
今年九月份,北京市教委发布了《关于深入推进高中阶段学校考试招生改革的实施意见》。按照该意见,北京市2024年初三年级学生的初中学业水平考试英语科目听力口语考试与笔试将分离,首次计算机考试将于2023年12月17日进行。 根据《意见》规定,听力口语计算机考试共有两次考试机会…...

Java中的继承和多态
目录 1. 继承 1.1 为什么需要继承 1.2 继承概念 1.3 继承的语法 1.4 父类成员访问 1.4.1 子类中访问父类的成员变量 1.4.2 子类中访问父类的成员方法 1.5 super关键字 1.6 子类构造方法 1.7 super和this 1.8 再谈初始化 1.9 protected 关键字 1.10 继承方式…...

海外问卷调查现在还可以做吗?
可以做,海外问卷调查是一个稳定长期的互联网创业项目。 大家好,我是橙河,这篇文章讲一讲海外问卷调查现在还可以做吗? 海外问卷调查,简单来说,就是外国的商业公司对外发放的付费调查问卷,按照…...

CA证书与服务器证书
服务器证书和CA证书是网络通信中使用的两种重要的证书。服务器证书是用于验证服务器身份的证书,而CA证书是用于验证证书颁发机构(Certificate Authority)身份的证书。 服务器证书是由网站服务器申请并由CA机构颁发的。它包含了服务器的公钥和其他相关信息ÿ…...

AI智能语音识别模块(二)——基于Arduino的语音控制MP3播放器
文章目录 简介离线语音控制模块Mini MP3模块0.96寸 OLED模块实验准备安装库接线定义主要程序实验效果注意事项总结 简介 在前面一篇文章里我们对AI智能语音识别模块进行了介绍,并对离线语音模组下载固件的过程进行了一个简单描述,不知道大家还记不记得&…...

CentOS部署Minikube
基本介绍 Minikube是本地的Kubernetes,专注于使其易于为Kubernete学习和开发。 官方地址:https://minikube.sigs.k8s.io/docs/start/ 部署安装 # CentOS 7.6# 前置条件:安装好Docker或其他容器引擎或虚拟机 参见《CentOS一键部署Docker》…...

第5章_排序与分页
文章目录 1 排序数据1.1 排序规则1.2 单列排序1.3 多列排序排序演示代码 2 分页2.1 背景2.2 实现规则2.3 拓展分页演示代码 3 课后练习 1 排序数据 1.1 排序规则 使用 ORDER BY 子句排序 ASC(ascend): 升序DESC(descend):降序 …...

Elasticsearch实战:常见错误及详细解决方案
Elasticsearch实战:常见错误及详细解决方案 1.read_only_allow_delete":“true” 当我们在向某个索引添加一条数据的时候,可能(极少情况)会碰到下面的报错: {"error": {"root_cause": [{&…...

C#添加缓存,删除缓存,修改缓存
在C#中,可以使用内置的缓存功能或者使用第三方缓存库来管理缓存。下面分别介绍使用内置缓存功能和使用第三方缓存库的方法。 使用内置缓存功能: 添加缓存: 在C#中,可以使用MemoryCache类来添加缓存。以下是一个简单的示例&…...

PADS Router的操作页面及鼠标指令介绍
PADS Router的用户界面由菜单栏,工作界面,一般工具栏,状态栏,项目浏览器组,输出窗口,电子表格组成(图1): 图1 注意:如果你的界面没有显示项目浏览器ÿ…...
Android studio进入手机调试状态
首先usb插入电脑手机打开开发者模式进入点击就会在你的页面显示了...

《Pytorch新手入门》第二节-动手搭建神经网络
《Pytorch新手入门》第二节-动手搭建神经网络 一、神经网络介绍二、使用torch.nn搭建神经网络2.1 定义网络2.2 torch.autograd.Variable2.3 损失函数与反向传播2.4 优化器torch.optim 三、实战-实现图像分类(CIFAR-10数据集)3.1 CIFAR-10数据集加载与预处理3.2 定义网络结构3.3…...

C++ 模板学习笔记
C另外一种编程成为 泛型编程 ,主要利用的技术就是模板 C提供两种模板机制:函数模板和类模板 C11中,函数模板和类模板都可以设定默认参数,传送门 函数模板 一般 typename 和 class 没有区别,typename 还有个作用是使…...

1、Flink基础概念
1、基础知识 (1)、数据流上的有状态计算 (2)、框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。 (3)、事件驱动型应用,有数据流就进行处理,无数据流就不…...

Invoke-Obfuscation深度解析:PowerShell混淆技术的实战指南与防御策略
Invoke-Obfuscation深度解析:PowerShell混淆技术的实战指南与防御策略 【免费下载链接】Invoke-Obfuscation PowerShell Obfuscator 项目地址: https://gitcode.com/gh_mirrors/in/Invoke-Obfuscation Invoke-Obfuscation是一款专业的PowerShell脚本混淆框架…...

GPS测速仪SpeedView 3.2.0汉化版 精准速度 实时测速工具
一款实时测速应用程序,英文名为“SpeedView”,安装到手机上就能够在开车的时候查看仪表盘车辆的速度是否准确 实时测速:通过GPS精准定位,实时显示当前速度、平均速度和最高速度,支持多种单位切换(km/h、mp…...

从实战出发:聊聊Serial口静态路由在老旧网络设备迁移中的那些事儿
从实战出发:聊聊Serial口静态路由在老旧网络设备迁移中的那些事儿 第一次在机房里见到那台积满灰尘的Cisco 1841时,我差点以为这是个博物馆展品。但客户坚持说这台服役超过15年的老伙计承载着他们最重要的生产线控制数据,任何闪失都可能造成六…...

关于fiddler报错“The system proxy was changed. click to reenable capturing”的解决办法
背景:第一次下载安装fiddler,安装过程没有任何问题,但启动即报错 参考了很多帖子,一个一个排查后,发现是sslvpn的问题(因为访问校园网需要安装了 EasyConnect 深信服SSLVPN客户端),把…...

联发科MT6833与MT6853 5G核心板:规格对比与产品选型实战指南
1. 项目概述:两款5G安卓核心板的定位与价值在当前的移动设备开发领域,尤其是面向中高端市场的智能手机、平板电脑以及各类智能终端,选择一颗性能强劲、功能集成度高且成本可控的核心处理器平台,是决定产品成败的关键。联发科&…...

2025年AI数字人行业现状:全国超99万家企业涌入,真正能落地的不到一成
当生成式AI的浪潮席卷各行各业,AI数字人成为最先跑出商业化落地速度的细分赛道。然而,在全国超99万家相关企业蜂拥而入的热闹背后,一个残酷的现实正在显现:绝大多数所谓的"AI数字人"不过是披着科技外衣的"会动的照…...

2026年外贸管理软件怎么选?B2B与跨境B2C实用选型指南
在外贸行业数字化升级过程中,企业挑选管理软件,首要理清自身业务赛道。目前行业主流分为传统外贸B2B、跨境电商B2C两大模式。结合企业实际经营需求,传统B2B可划分为获客拓客类工具、内部业务管理类系统;跨境B2C可划分为前端店铺运…...

告别PyTorch依赖:手把手教你用C++ CUDA实现LeNet推理,从Python模型导出到C++部署全流程
从PyTorch到C CUDA:工业级LeNet模型部署全流程实战 在深度学习模型开发中,Python生态提供了丰富的训练工具,但生产环境往往需要高性能的C实现。本文将完整演示如何将PyTorch训练的LeNet模型部署到C CUDA环境,涵盖模型导出、内存管…...

Geist字体实战手册:现代数字产品的瑞士设计解决方案
Geist字体实战手册:现代数字产品的瑞士设计解决方案 【免费下载链接】geist-font 项目地址: https://gitcode.com/gh_mirrors/ge/geist-font 在数字产品界面中,字体选择往往成为视觉体验的瓶颈。Geist字体家族以其瑞士设计理念,为开发…...

微生物网络分析终极指南:如何用NetCoMi轻松解锁微生物互作密码
微生物网络分析终极指南:如何用NetCoMi轻松解锁微生物互作密码 【免费下载链接】NetCoMi Network construction, analysis, and comparison for microbial compositional data 项目地址: https://gitcode.com/gh_mirrors/ne/NetCoMi 还在为复杂的微生物组数据…...