Elasticsearch实战:常见错误及详细解决方案
Elasticsearch实战:常见错误及详细解决方案
1.read_only_allow_delete":“true”
当我们在向某个索引添加一条数据的时候,可能(极少情况)会碰到下面的报错:
{"error": {"root_cause": [{"type": "cluster_block_exception","reason": "blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"}],"type": "cluster_block_exception","reason": "blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"},"status": 403
}上述报错是说索引现在的状态是只读模式(read-only),如果查看该索引此时的状态:
GET z1/_settings
#结果如下
{"z1" : {"settings" : {"index" : {"number_of_shards" : "5","blocks" : {"read_only_allow_delete" : "true"},"provided_name" : "z1","creation_date" : "1556204559161","number_of_replicas" : "1","uuid" : "3PEevS9xSm-r3tw54p0o9w","version" : {"created" : "6050499"}}}}
}可以看到"read_only_allow_delete" : "true",说明此时无法插入数据,当然,我们也可以模拟出来这个错误:
PUT z1
{"mappings": {"doc": {"properties": {"title": {"type":"text"}}}},"settings": {"index.blocks.read_only_allow_delete": true}
}PUT z1/doc/1
{"title": "es真难学"
}现在我们如果执行插入数据,就会报开始的错误。那么怎么解决呢?
- 清理磁盘,使占用率低于 85%。
- 手动调整该项,具体参考官网
这里介绍一种,我们将该字段重新设置为:
PUT z1/_settings
{"index.blocks.read_only_allow_delete": null
}现在再查看该索引就正常了,也可以正常的插入数据和查询了。
2. illegal_argument_exception
有时候,在聚合中,我们会发现如下报错:
{"error": {"root_cause": [{"type": "illegal_argument_exception","reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [age] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead."}],"type": "search_phase_execution_exception","reason": "all shards failed","phase": "query","grouped": true,"failed_shards": [{"shard": 0,"index": "z2","node": "NRwiP9PLRFCTJA7w3H9eqA","reason": {"type": "illegal_argument_exception","reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [age] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead."}}],"caused_by": {"type": "illegal_argument_exception","reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [age] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.","caused_by": {"type": "illegal_argument_exception","reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [age] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead."}}},"status": 400
}这是怎么回事呢?是因为,聚合查询时,指定字段不能是text类型。比如下列示例:
PUT z2/doc/1
{"age":"18"
}
PUT z2/doc/2
{"age":20
}GET z2/doc/_search
{"query": {"match_all": {}},"aggs": {"my_sum": {"sum": {"field": "age"}}}
}当我们向elasticsearch中,添加一条数据时(此时,如果索引存在则直接新增或者更新文档,不存在则先创建索引),首先检查该age字段的映射类型。如上示例中,我们添加第一篇文档时(z1索引不存在),elasticsearch会自动的创建索引,然后为age字段创建映射关系(es 就猜此时age字段的值是什么类型,如果发现是text类型,那么存储该字段的映射类型就是text),此时age字段的值是text类型,所以,第二条插入数据,age的值也是text类型,而不是我们看到的long类型。我们可以查看一下该索引的mappings信息:
GET z2/_mapping
#mapping信息如下
{"z2" : {"mappings" : {"doc" : {"properties" : {"age" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}}}}}}
}上述返回结果发现,age类型是text。而该类型又不支持聚合,所以,就会报错了。解决办法就是:
- 如果选择动态创建一篇文档,映射关系取决于你添加的第一条文档的各字段都对应什么类型。而不是我们看到的那样,第一次是
text,第二次不加引号,就是long类型了不是这样的。 - 如果嫌弃上面的解决办法麻烦,那就选择手动创建映射关系。首先指定好各字段对应什么类型。后续才不至于出错。
3.Result window is too large
很多时候,我们在查询文档时,一次查询结果很可能会有很多,而 elasticsearch 一次返回多少条结果,由size参数决定:
GET e2/doc/_search
{"size": 100000,"query": {"match_all": {}}
}而默认是最多范围一万条,那么当我们的请求超过一万条时(比如有十万条),就会报:
Result window is too large, from + size must be less than or equal to: [10000] but was [100000]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting.意思是一次请求返回的结果太大,可以另行参考 scroll API或者设置index.max_result_window参数手动调整size的最大默认值:
#kibana中设置
PUT e2/_settings
{"index": {"max_result_window": "100000"}
}
#Python中设置
from elasticsearch import Elasticsearch
es = Elasticsearch()
es.indices.put_settings(index='e2', body={"index": {"max_result_window": 100000}})如上例,我们手动调整索引e2的size参数最大默认值到十万,这时,一次查询结果只要不超过 10 万就都会一次返回。 注意,这个设置对于索引es的size参数是永久生效的。
4.持续更新中
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
相关文章:

Elasticsearch实战:常见错误及详细解决方案
Elasticsearch实战:常见错误及详细解决方案 1.read_only_allow_delete":“true” 当我们在向某个索引添加一条数据的时候,可能(极少情况)会碰到下面的报错: {"error": {"root_cause": [{&…...

C#添加缓存,删除缓存,修改缓存
在C#中,可以使用内置的缓存功能或者使用第三方缓存库来管理缓存。下面分别介绍使用内置缓存功能和使用第三方缓存库的方法。 使用内置缓存功能: 添加缓存: 在C#中,可以使用MemoryCache类来添加缓存。以下是一个简单的示例&…...

PADS Router的操作页面及鼠标指令介绍
PADS Router的用户界面由菜单栏,工作界面,一般工具栏,状态栏,项目浏览器组,输出窗口,电子表格组成(图1): 图1 注意:如果你的界面没有显示项目浏览器ÿ…...
Android studio进入手机调试状态
首先usb插入电脑手机打开开发者模式进入点击就会在你的页面显示了...

《Pytorch新手入门》第二节-动手搭建神经网络
《Pytorch新手入门》第二节-动手搭建神经网络 一、神经网络介绍二、使用torch.nn搭建神经网络2.1 定义网络2.2 torch.autograd.Variable2.3 损失函数与反向传播2.4 优化器torch.optim 三、实战-实现图像分类(CIFAR-10数据集)3.1 CIFAR-10数据集加载与预处理3.2 定义网络结构3.3…...

C++ 模板学习笔记
C另外一种编程成为 泛型编程 ,主要利用的技术就是模板 C提供两种模板机制:函数模板和类模板 C11中,函数模板和类模板都可以设定默认参数,传送门 函数模板 一般 typename 和 class 没有区别,typename 还有个作用是使…...

1、Flink基础概念
1、基础知识 (1)、数据流上的有状态计算 (2)、框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。 (3)、事件驱动型应用,有数据流就进行处理,无数据流就不…...

分享一下怎么做小程序营销活动
小程序营销活动已经成为现代营销的必备利器,它能够帮助企业提高品牌知名度、促进产品销售,以及加强与用户的互动。然而,要想成功地策划和执行一个小程序营销活动,需要精心设计和全面规划。本文将为您介绍小程序营销活动的策划和执…...

Laravel 后台管理 Dcat Admin 使用记录
Laravel Dcat Admin 安装配置修改配置表格操作 Ajax 结合 Pjax 更新数据状态表格 链接表单设置页面(通常修改更新在同一页面)表单 安装配置 安装文档地址 框架版本 Laravel 8.* 修改配置 修改 admin.php 文件 return [// 后台名称name > DAD后台管理,// 标题title > 后台…...

c语言基础:L1-070 吃火锅
以上图片来自微信朋友圈:这种天气你有什么破事打电话给我基本没用。但是如果你说“吃火锅”,那就厉害了,我们的故事就开始了。 本题要求你实现一个程序,自动检查你朋友给你发来的信息里有没有 chi1 huo3 guo1。 输入格式&#x…...

java spring boot 注解、接口和问题解决方法(持续更新)
注解 RestController 是SpringMVC框架中的一个注解,它结合了Controller和ResponseBody两个注解的功能,用于标记一个类或者方法,表示该类或方法用于处理HTTP请求,并将响应的结果直接返回给客户端,而不需要进行视图渲染…...

HMAC_SHA1加密算法和SHA1加密算法的区别
HMAC_SHA1加密算法和SHA1加密算法的区别 应用场景:SHA1目前主要用于政府部门和私营业主处理敏感信息,被视为最先进的加密技术。而HMAC_SHA1主要用于基于密钥的消息认证码(HMAC)运算,需要一个密钥作为输入。密钥需求&a…...
Ubuntu连不上WiFi 或者虽然能连上校园网,但是浏览器打不开登录页面
写在前面 自己的电脑环境: Ubuntu20.04 一、问题描述 自己的 Ubuntu 遇到连接不上 除校园网之外的其他WiFi, 或者 虽然能连上校园网,但是浏览器打不开登录页面的问题。 二、解决方法 出现这种问题的原因可能是 之前开过VPN, 导致系统的网络设置出现…...

Maven第八章:如何解决Maven的jar版本冲突
Maven第八章:如何解决Maven的jar版本冲突 前言 本文重点讲解Maven依赖冲突原因,maven依赖原则以及如何利用idea Maven Helper插件分析解决问题。 背景 开发过程中引入第三方jar遇到依赖冲突的,非常影响开发,甚至大部分时间都在调试版本兼容。 Caused by:java.lang.NoSuch…...

c# 读写内存映射文件
在C#中,可以使用System.IO.MemoryMappedFiles命名空间中的MemoryMappedFile类来操作内存映射文件。可以创建不固定大小的内存映射文件,具体步骤如下: 1. 先创建一个初始大小为0的内存映射文件,使用MemoryMappedFile.CreateNew方法…...

行业揭秘:腾讯共享wifi码推广零加盟费是真的吗?
近年来,“共享经济”概念在商业领域取得了巨大成功。共享WiFi贴码成为共享经济的一种典型案例,被越来越多的人看作是一种低风险、高回报的投资方式。而在这个市场中,腾讯WiFi码推广以“零加盟费”而备受关注。本文将探讨腾讯WiFi码推广零加盟…...

E4980A 精密型 LCR 表,20 Hz 至 2 MHz
E4980A 精密型 LCR 表 20 Hz 至 2 MHz E4980A 精密型 LCR 表实现了测量准确度、速度与通用性的理想结合,适用于各种元器件测量。 E4980A 精密型 LCR 表实现了测量准确度、速度与通用性的理想结合,适用于各种元器件测量。 无论是在低阻抗量程还是在高阻…...

【前端工作提效】关于工作提效的一点实践与思考
1、测试提的BUG是一个一个提的,如果顺着测试提供的BUG单去一个一个解决问题,那么很容易管中窥豹,就像打补丁一样,缝缝补补,没有办法从根源去解决问题。所以我们需要尽量去了解代码的业务情况,并尽可能将一些…...
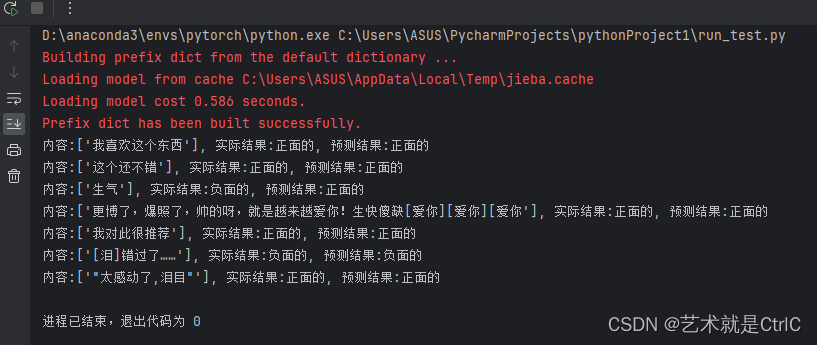
Pytorch 文本情感分类案例
一共六个脚本,分别是: ①generateDictionary.py用于生成词典 ②datasets.py定义了数据集加载的方法 ③models.py定义了网络模型 ④configs.py配置一些参数 ⑤run_train.py训练模型 ⑥run_test.py测试模型 数据集https://download.csdn.net/download/Victor_Li_/88486959?spm1…...

Flutter之GetX controller tag使用详解
本文主要介绍 GetX 依赖注入中 tag 的作用和使用详解。 作用 前面几篇文章介绍了 GetX 依赖注入的使用以及通过源码剖析了依赖注入的原理: •《Flutter应用框架搭建(一)GetX集成及使用详解》•《Flutter 通过源码一步一步剖析 Getx 依赖管理的实现》•《Flutter之…...
)
保姆级教程:用USM的PE和分区助手,把旧硬盘数据无损搬到新硬盘(附Win11引导修复)
Win11系统硬盘无损迁移全指南:USM PE与分区助手实战详解当你面对一块崭新的固态硬盘,既想享受飞速读写体验,又担心重装系统后那些精心调试的设置和重要数据丢失,这种纠结我太熟悉了。去年我的主力机升级时,整整3TB的工…...

Debian Bullseye定制Live ISO避坑指南:从debootstrap到xorriso的完整流程解析
Debian Bullseye定制Live ISO避坑指南:从debootstrap到xorriso的完整流程解析当我们需要快速部署一套标准化的Debian环境时,定制Live ISO无疑是最优雅的解决方案之一。不同于传统的系统安装方式,Live ISO允许我们将预先配置好的系统环境打包成…...

Harness与Agent SDK的边界划分:最佳实践
Harness与Agent SDK的边界划分:最佳实践 引言 在云原生软件交付的下半场,企业面临的核心矛盾已经从「有没有工具链」变成了「能不能把工具链用出价值」。作为全球领先的软件交付平台(SDP),Harness凭借开箱即用的CI/CD、Feature Flag、混沌工程、合规治理等能力,已经成为…...

AI医疗Agent如何72小时通过NMPA二类证审批:附2024最新审评问答清单与材料模板
更多请点击: https://intelliparadigm.com 第一章:AI医疗Agent的监管合规本质与NMPA二类证核心逻辑 AI医疗Agent并非通用大模型的简单应用延伸,而是以临床决策支持、病灶识别、报告生成等具体医疗器械功能为边界的技术实体。其监管合规本质在…...

Meta裁了8000人,员工拖着行李箱抢可乐
昨天凌晨4点,Meta很多员工的邮箱同时响了。是裁员邮件。这一次,Meta裁掉了全球约10%的员工,规模大约8000人。分手大礼包:16周基础薪资 每满1年工龄额外2周薪资 18个月全家医保。真正让硅谷炸锅的,反而是裁员前几天&a…...

工业AI落地:从数据冷启动到高质数据工程实战
1. 为什么“数据为中心”不是口号,而是工程现场的真实压力去年冬天,我帮一家做工业缺陷检测的初创公司做模型交付。他们拿来的数据集只有237张标注图,全是产线停机时人工拍的——光照不均、角度单一、连螺丝孔都只拍正面。当时团队信心满满&a…...

加拿大AI治理实战:风险分级、监管沙盒与可信AI工程化落地
1. 项目概述:这不是一场技术秀,而是一场制度设计的实战演练“Canada’s AI Ambitions: Navigating the Future of AI Governance”——这个标题里没有一行代码,不提一个模型参数,却直指当前全球AI发展最棘手、最易被忽视的底层命题…...

踩坑实录:Seatunnel同步Hive到StarRocks时,数据量翻倍和中文乱码怎么破?
Seatunnel数据同步实战:破解Hive到StarRocks的三大典型问题 在数据仓库迁移和ETL流程中,Seatunnel作为一款高效的数据同步工具,已经成为许多企业技术栈中的关键组件。但当我们将Hive数据同步到StarRocks时,往往会遇到一些令人头疼…...

深度学习的缺失数据革命:使用MIDAS实现高效多重插补
深度学习的缺失数据革命:使用MIDAS实现高效多重插补 【免费下载链接】MIDAS Multiple imputation utilising denoising autoencoder for approximate Bayesian inference 项目地址: https://gitcode.com/gh_mirrors/midas3/MIDAS 在数据科学和机器学习领域&a…...

新业务新项目的缺陷密度解析
对于新业务、新项目,业界并没有一个放之四海而皆准的“标准答案”。但通过参考行业研究数据,从四个渐进的项目阶段来设定基准,是更务实的做法。📈 测量差异与高层级数据使用KLOC(千行代码)和功能点这两种度…...