Pytorch 文本情感分类案例
一共六个脚本,分别是:
①generateDictionary.py用于生成词典
②datasets.py定义了数据集加载的方法
③models.py定义了网络模型
④configs.py配置一些参数
⑤run_train.py训练模型
⑥run_test.py测试模型
数据集![]() https://download.csdn.net/download/Victor_Li_/88486959?spm=1001.2014.3001.5501停用词表
https://download.csdn.net/download/Victor_Li_/88486959?spm=1001.2014.3001.5501停用词表![]() https://download.csdn.net/download/Victor_Li_/88486973?spm=1001.2014.3001.5501
https://download.csdn.net/download/Victor_Li_/88486973?spm=1001.2014.3001.5501
generateDictionary.py如下
import jiebadata_path = "./weibo_senti_100k.csv"
data_stop_path = "./hit_stopwords.txt"
data_list = open(data_path,encoding='utf-8').readlines()[1:]
stops_word = open(data_stop_path,encoding='utf-8').readlines()
stops_word = [line.strip() for line in stops_word]
stops_word.append(" ")
stops_word.append("\n")voc_dict = {}
min_seq = 1
top_n = 1000
UNK = "UNK"
PAD = "PAD"
for item in data_list:label = item[0]content = item[2:].strip()seg_list = jieba.cut(content,cut_all=False)seg_res = []for seg_item in seg_list:if seg_item in stops_word:continueseg_res.append(seg_item)if seg_item in voc_dict.keys():voc_dict[seg_item] += 1else:voc_dict[seg_item] = 1# print(content)# print(seg_res)voc_list = sorted([_ for _ in voc_dict.items() if _[1] > min_seq],key=lambda x:x[1],reverse=True)[:top_n]voc_dict = {word_count[0]:idx for idx,word_count in enumerate(voc_list)}voc_dict.update({UNK:len(voc_dict),PAD:len(voc_dict)+1})ff = open("./dict","w")
for item in voc_dict.keys():ff.writelines("{},{}\n".format(item,voc_dict[item]))
ff.close()datasets.py如下
from torch.utils.data import Dataset, DataLoader
import jieba
import numpy as npdef read_dict(voc_dict_path):voc_dict = {}with open(voc_dict_path, 'r') as f:for line in f:line = line.strip()if line == '':continueword, index = line.split(",")voc_dict[word] = int(index)return voc_dictdef load_data(data_path, data_stop_path,isTest):data_list = open(data_path, encoding='utf-8').readlines()[1:]stops_word = open(data_stop_path, encoding='utf-8').readlines()stops_word = [line.strip() for line in stops_word]stops_word.append(" ")stops_word.append("\n")voc_dict = {}data = []max_len_seq = 0for item in data_list:label = item[0]content = item[2:].strip()seg_list = jieba.cut(content, cut_all=False)seg_res = []for seg_item in seg_list:if seg_item in stops_word:continueseg_res.append(seg_item)if seg_item in voc_dict.keys():voc_dict[seg_item] += 1else:voc_dict[seg_item] = 1if len(seg_res) > max_len_seq:max_len_seq = len(seg_res)if isTest:data.append([label, seg_res,content])else:data.append([label, seg_res])return data, max_len_seqclass text_ClS(Dataset):def __init__(self, data_path, data_stop_path,voc_dict_path,isTest=False):self.isTest = isTestself.data_path = data_pathself.data_stop_path = data_stop_pathself.voc_dict = read_dict(voc_dict_path)self.data, self.max_len_seq = load_data(self.data_path, self.data_stop_path,isTest)np.random.shuffle(self.data)def __len__(self):return len(self.data)def __getitem__(self, item):data = self.data[item]label = int(data[0])word_list = data[1]if self.isTest:content = data[2]input_idx = []for word in word_list:if word in self.voc_dict.keys():input_idx.append(self.voc_dict[word])else:input_idx.append(self.voc_dict["UNK"])if len(input_idx) < self.max_len_seq:input_idx += [self.voc_dict["PAD"] for _ in range(self.max_len_seq - len(input_idx))]data = np.array(input_idx)if self.isTest:return label,data,contentelse:return label, datadef data_loader(dataset,config):return DataLoader(dataset,batch_size=config.batch_size,shuffle=config.is_shuffle,num_workers=4,pin_memory=True)models.py如下
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as npclass Model(nn.Module):def __init__(self,config):super(Model,self).__init__()self.embeding = nn.Embedding(config.n_vocab,config.embed_size,padding_idx=config.n_vocab - 1)self.lstm = nn.LSTM(config.embed_size,config.hidden_size,config.num_layers,batch_first=True,bidirectional=True,dropout=config.dropout)self.maxpool = nn.MaxPool1d(config.pad_size)self.fc = nn.Linear(config.hidden_size * 2 + config.embed_size,config.num_classes)self.softmax = nn.Softmax(dim=1)def forward(self,x):embed = self.embeding(x)out, _ = self.lstm(embed)out = torch.cat((embed, out), 2)out = F.relu(out)out = out.permute(0, 2, 1)out = self.maxpool(out).reshape(out.size()[0],-1)out = self.fc(out)out = self.softmax(out)return out
configs.py如下
import torch.typesclass Config():def __init__(self):self.n_vocab = 1002self.embed_size = 256self.hidden_size = 256self.num_layers = 5self.dropout = 0.8self.num_classes = 2self.pad_size = 32self.batch_size = 32self.is_shuffle = Trueself.learning_rate = 0.001self.num_epochs = 100self.devices = torch.device('cuda' if torch.cuda.is_available() else 'cpu')run_train.py如下
import torch
import torch.nn as nn
from torch import optim
from models import Model
from datasets import data_loader,text_ClS
from configs import Config
import time
import torch.multiprocessing as mpif __name__ == '__main__':mp.freeze_support()cfg = Config()data_path = "./weibo_senti_100k.csv"data_stop_path = "./hit_stopwords.txt"dict_path = "./dict"dataset = text_ClS(data_path, data_stop_path, dict_path)train_dataloader = data_loader(dataset,cfg)cfg.pad_size = dataset.max_len_seqmodel_text_cls = Model(cfg)model_text_cls.to(cfg.devices)loss_func = nn.CrossEntropyLoss()optimizer = optim.Adam(model_text_cls.parameters(), lr=cfg.learning_rate)scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.9)for epoch in range(cfg.num_epochs):running_loss = 0correct = 0total = 0epoch_start_time = time.time()for i,(labels,datas) in enumerate(train_dataloader):datas = datas.to(cfg.devices)labels = labels.to(cfg.devices)pred = model_text_cls.forward(datas)loss_val = loss_func(pred,labels)running_loss += loss_val.item()loss_val.backward()if ((i + 1) % 4 == 0) or (i + 1 == len(train_dataloader)):optimizer.step()optimizer.zero_grad()_, predicted = torch.max(pred.data, 1)correct += (predicted == labels).sum().item()total += labels.size(0)scheduler.step()accuracy_train = 100 * correct / totalepoch_end_time = time.time()epoch_time = epoch_end_time - epoch_start_timetain_loss = running_loss / len(train_dataloader)print("Epoch [{}/{}],Time: {:.4f}s,Loss: {:.4f},Acc: {:.2f}%".format(epoch + 1, cfg.num_epochs, epoch_time, tain_loss,accuracy_train))torch.save(model_text_cls.state_dict(),"./text_cls_model/text_cls_model{}.pth".format(epoch))run_test.py如下
import torch
import torch.nn as nn
from torch import optim
from models import Model
from datasets import data_loader,text_ClS
from configs import Config
import time
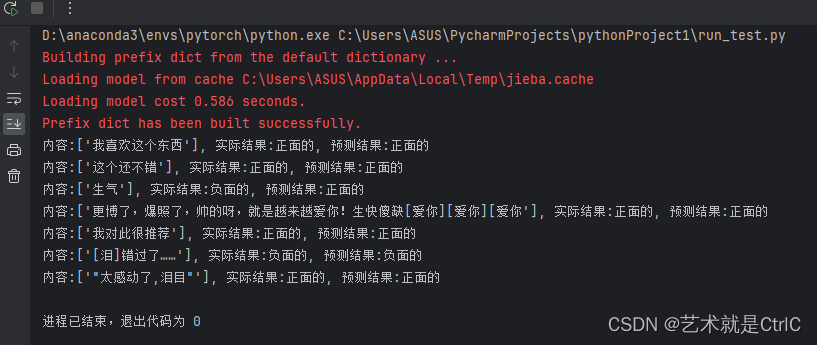
import torch.multiprocessing as mpif __name__ == '__main__':mp.freeze_support()cfg = Config()data_path = "./test.csv"data_stop_path = "./hit_stopwords.txt"dict_path = "./dict"cfg.batch_size = 1dataset = text_ClS(data_path, data_stop_path, dict_path,isTest=True)dataloader = data_loader(dataset,cfg)cfg.pad_size = dataset.max_len_seqmodel_text_cls = Model(cfg)model_text_cls.load_state_dict(torch.load('./text_cls_model/text_cls_model0.pth'))model_text_cls.to(cfg.devices)classes_name = ['负面的','正面的']for i,(label,input,content) in enumerate(dataloader):label = label.to(cfg.devices)input = input.to(cfg.devices)pred = model_text_cls.forward(input)_, predicted = torch.max(pred.data, 1)print("内容:{}, 实际结果:{}, 预测结果:{}".format(content,classes_name[label],classes_name[predicted[0]]))
测试结果如下
相关文章:
Pytorch 文本情感分类案例
一共六个脚本,分别是: ①generateDictionary.py用于生成词典 ②datasets.py定义了数据集加载的方法 ③models.py定义了网络模型 ④configs.py配置一些参数 ⑤run_train.py训练模型 ⑥run_test.py测试模型 数据集https://download.csdn.net/download/Victor_Li_/88486959?spm1…...

Flutter之GetX controller tag使用详解
本文主要介绍 GetX 依赖注入中 tag 的作用和使用详解。 作用 前面几篇文章介绍了 GetX 依赖注入的使用以及通过源码剖析了依赖注入的原理: •《Flutter应用框架搭建(一)GetX集成及使用详解》•《Flutter 通过源码一步一步剖析 Getx 依赖管理的实现》•《Flutter之…...

Kubernetes群集调度
调度约束 Kubernetes 是通过 List-Watch 的机制进行每个组件的协作,保持数据同步的,每个组件之间的设计实现了解耦。 用户是通过 kubectl 根据配置文件,向 APIServer 发送命令,在 Node 节点上面建立 Pod 和 Container。 APIServ…...

【总结】linux centos 7 开启网络白名单访问策略
目录 linux开启网络端口白名单访问策略开启白名单步骤补充说明 linux开启网络端口白名单访问策略 安全需要,被检测各种3306、9200、9300端口没有设置访问策略。需要整改。 对于linux来说,有两种方式可以开启防火墙 开启白名单步骤 场景一:…...

2023-2024-1高级语言程序设计第1次月考
7-1-1 计算摄氏温度 给定一个华氏温度F,本题要求编写程序,计算对应的摄氏温度C。计算公式:C5(F−32)/9。题目保证输入与输出均在整型范围内。 输入格式: 输入在一行中给出一个华氏温度。 输出格式: 在一行中按照格式“Celsius C”输出对…...
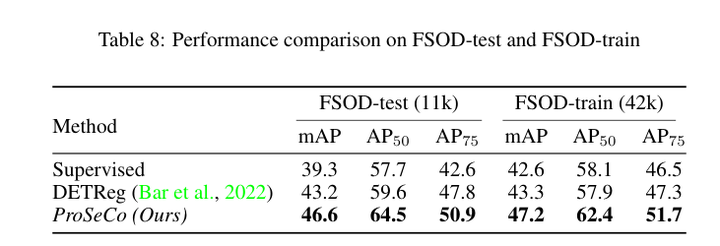
目标检测:Proposal-Contrastive Pretraining for Object Detection from Fewer Data
论文作者:Quentin Bouniot,Romaric Audigier,Anglique Loesch,Amaury Habrard 作者单位:Universit Paris-Saclay; Universit Jean Monnet Saint-Etienne; Universitaire de France (IUF) 论文链接:http://arxiv.org/abs/2310.16835v1 内容…...
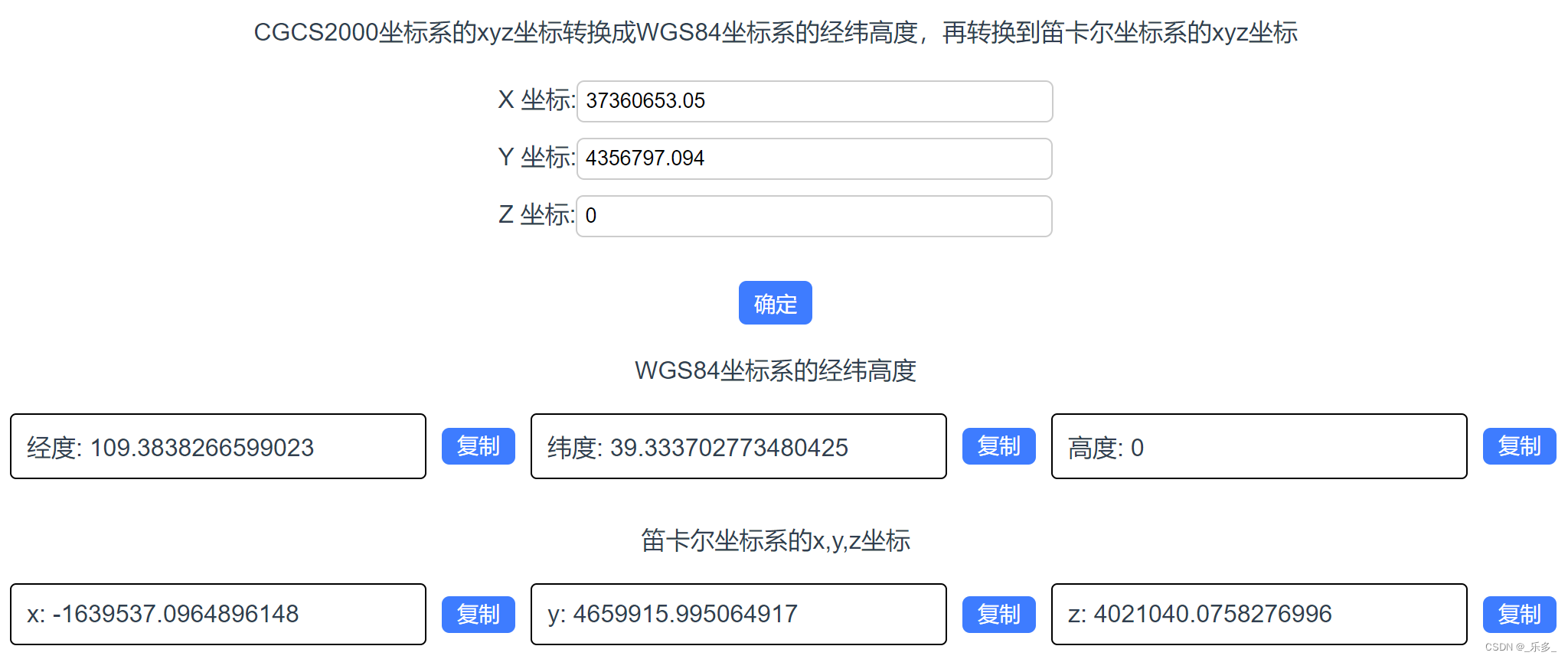
Cesium:CGCS2000坐标系的xyz坐标转换成WGS84坐标系的经纬高度,再转换到笛卡尔坐标系的xyz坐标
作者:CSDN @ _乐多_ 本文将介绍使用 Vue 、cesium、proj4 框架,实现将CGCS2000坐标系的xyz坐标转换成WGS84坐标系的经纬高度,再将WGS84坐标系的经纬高度转换到笛卡尔坐标系的xyz坐标的代码。并将输入和输出使用 Vue 前端框架展示了出来。代码即插即用。 网页效果如下图所示…...
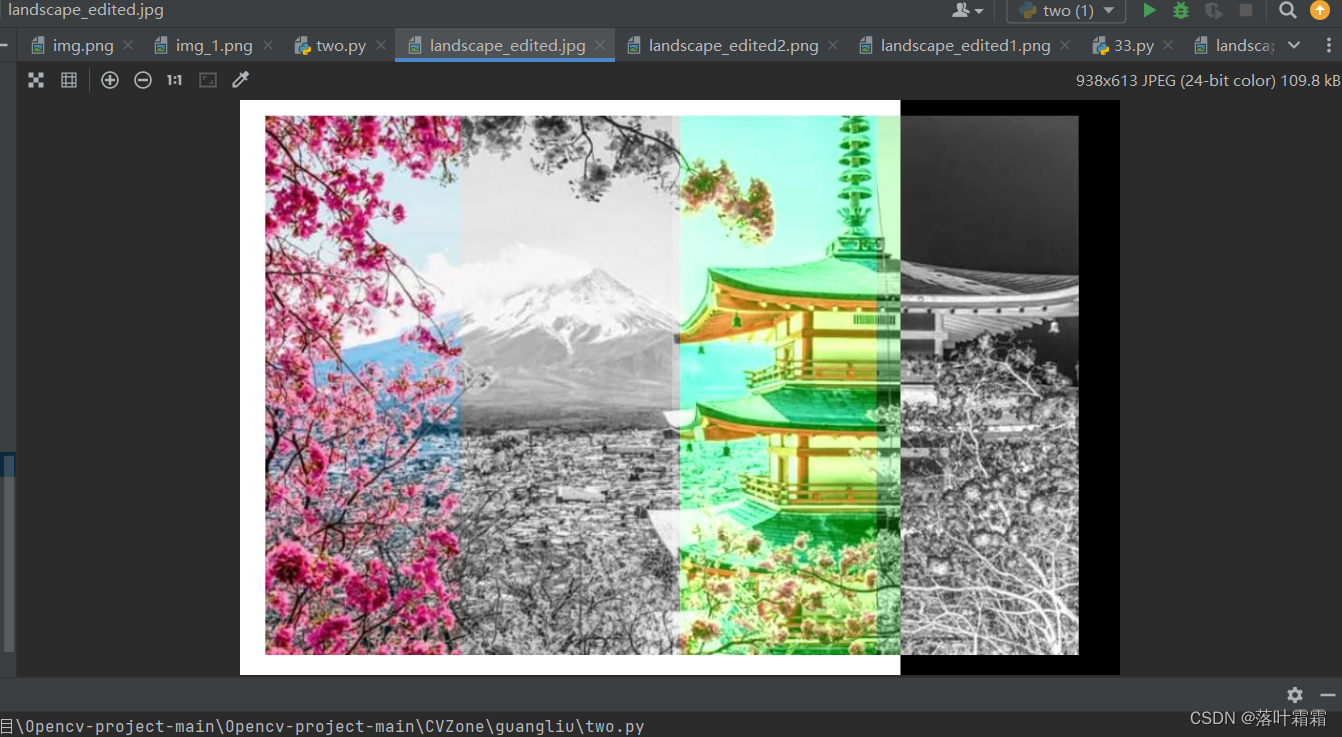
【OpenCV实现图像:用Python生成图像特效,报错ValueError: too many values to unpack (expected 3)】
文章目录 概要读入图像改变单个通道黑白特效颜色反转将图像拆分成四个子部分 概要 Python是一种功能强大的编程语言,也是图像处理领域中常用的工具之一。通过使用Python的图像处理库(例如Pillow、OpenCV等),开发者可以实现各种各…...

875. 爱吃香蕉的珂珂
题目描述 珂珂喜欢吃香蕉。这里有 n 堆香蕉,第 i 堆中有 piles[i] 根香蕉。警卫已经离开了,将在 h 小时后回来。 珂珂可以决定她吃香蕉的速度 k (单位:根/小时)。每个小时,她将会选择一堆香蕉,…...

台灯太亮会导致近视吗?精选高品质的台灯
台灯相信很多家庭都会备上一台,用于办公、休闲或者给孩子学习使用,如果使用的台灯亮度过高的话,可能会对视力造成一定的影响,尤其是夜晚的时候。建议是选择带有亮度调节功能的台灯会比较好一点,可以自行根据周围环境的…...

Scala函数和闭包
1. 函数 1.1 函数与方法 Scala 中函数与方法的区别非常小,如果函数作为某个对象的成员,这样的函数被称为方法,否则就是一个正常的函数。 // 定义方法 def multi1(x:Int) {x * x} // 定义函数 val multi2 (x: Int) > {x * x}println(mult…...

LeetCode----1935. 可以输入的最大单词数
题目 键盘出现了一些故障,有些字母键无法正常工作。而键盘上所有其他键都能够正常工作。 给你一个由若干单词组成的字符串 text ,单词间由单个空格组成(不含前导和尾随空格);另有一个字符串 brokenLetters ,由所有已损坏的不同字母键组成,返回你可以使用此键盘完全输入…...

学习笔记三十:K8S配置管理中心Secret实现加密数据配置管理
K8S配置管理中心Secret实现加密数据配置管理 Secret概述secret三种可选参数:Secret类型 使用Secret通过环境变量引入Secret通过volume挂载Secret创建Secret创建yaml文件将Secret挂载到Volume中 Secret概述 Configmap一般是用来存放明文数据的,如配置文件࿰…...

关于uviewui修改主题及在uniapp中的应用
在uview使用过程中遇到很多不方便的地方,记录下来 修改主题颜色 给UI框架换个主题色基础方法是覆盖原有色(但这个方法比较笨,处理起来也不干净利索),所以换个思路改变基础色值变量,步骤主要分为2部分&…...
使用QEMU模拟启动uboot
uboot的相关知识,可以参考:uboot基本概念。 一、环境配置 WSL: ubutu20.04 模拟开发板:vexpress-a9 uboot版本:u-boot-2023.10 二、安装QEMU 2.1、安装sudo apt install qemu2.2、查看支持哪些开发板qemu-system-arm -M help结…...

学习数据结构和算法之前,你需要知道什么?
最快的学习方法是什么?计算机基础支持有哪些?学习数据结构和算法应该如何思考?如何成长?为什么要学习数据结构和算法? 最快的学习方法是什么? 实践。 计算机基础支持有哪些? 数据结构和算法。…...
16. 机器学习 - 决策树
Hi,你好。我是茶桁。 在上一节课讲SVM之后,再给大家将一个新的分类模型「决策树」。我们直接开始正题。 决策树 我们从一个例子开始,来看下面这张图: 假设我们的x1 ~ x4是特征,y是最终的决定,打比方说是…...

将多余的内存,当作虚拟内存。修改edge缓存路径到虚拟内存中
一、下载工具,把内存映射成硬盘 软媒内存盘 v1.1.3.0 软媒内存盘下载-软媒内存盘 v1.1.3.0 - 下载吧 (xiazaiba.com) 二、映射edge的缓存路径 到新建的虚拟硬盘中 mklink /D "C:\Users\Administrator\AppData\Local\Microsoft\Edge\User Data" "V:\…...

【从0到1设计一个网关】过滤器链的实现---实现负载均衡过滤器
文章目录 什么是过滤器?编写负载均衡过滤器负载均衡的定义与实现负载均衡算法设计实现效果演示链接 自研网关整合Nacos,实现服务注册和配置变更 源码链接 什么是过滤器? 再前面的几个章节中我们已经实现了将我们的网关服务注册到注册中心,并且成功的从配置中心拉取了配置…...

科技云报道:打造生成式AI应用,什么才是关键?
科技云报道原创。 生成式AI作为当前人工智能的前沿领域,全球多家科技企业都在加大生成式AI的研发投入力度。 随着技术、产品及应用等方面不断推出重要成果,如今有更多的行业用户在思考该如何将生成式AI应用落地。 但开发生成式AI应用是一个充满挑战的…...

GParted实战:从虚拟机沙盒到实体机,安全演练Linux分区合并与扩容全流程
GParted实战:从虚拟机沙盒到实体机,安全演练Linux分区合并与扩容全流程在虚拟机的安全环境中练习Linux分区操作,就像飞行员在模拟器中训练紧急情况处理一样重要。GParted作为Linux系统管理员的"瑞士军刀",其强大功能背后…...
)
手把手教你用Python+OpenBMI复现运动想象BCI实验(附完整代码与数据集)
Python实战:从OpenBMI到运动想象脑机接口的全流程复现指南在认知科学与脑机接口(BCI)研究领域,运动想象(Motor Imagery)实验一直是经典范式。传统上,这类实验多依赖Matlab生态完成,但随着Python在科学计算领域的崛起,越…...

水纹真实度提升300%的关键技巧,深度拆解--style raw、--chaos 45与自定义tile texture协同机制
更多请点击: https://kaifayun.com 第一章:水纹真实度提升300%的关键技巧,深度拆解--style raw、--chaos 45与自定义tile texture协同机制 水纹渲染的真实感跃升并非依赖单一参数调优,而是三重机制在纹理生成管线中的精准耦合&am…...

proj-agones:知识点:helm
helm install之后的log be like:(base) savilahaobogon ~ % helm install prometheus prometheus-community/kube-prometheus-stack -n monitoring --create-namespace NAME: prometheus LAST DEPLOYED: Wed May 20 14:54:39 2026 NAMESPACE: monitoring STATUS: de…...

Seraphine:你的英雄联盟智能助手,3大核心功能提升游戏决策力
Seraphine:你的英雄联盟智能助手,3大核心功能提升游戏决策力 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 想象一下这样的场景:你刚刚进入英雄联盟的排位赛BP阶段&#x…...

抖音无水印下载器:5分钟掌握高效批量下载的完整指南
抖音无水印下载器:5分钟掌握高效批量下载的完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support…...
bug修改)
找不到测试(No tests were found)bug修改
解决办法 两个地方有时候改一个地方就好了改成在in whole project或者Across module dependencies...

使用Node.js和Taotoken快速构建一个智能客服聊天接口
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Node.js和Taotoken快速构建一个智能客服聊天接口 本教程面向具备Node.js基础的后端开发者,旨在指导你如何使用Open…...

如何高效下载B站视频:Python开源工具bilibili-downloader完全指南
如何高效下载B站视频:Python开源工具bilibili-downloader完全指南 【免费下载链接】bilibili-downloader B站视频下载,支持下载大会员清晰度4K,持续更新中 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-downloader B站视频…...

打造梦幻岛屿的5个秘诀:免费在线规划工具完整指南
打造梦幻岛屿的5个秘诀:免费在线规划工具完整指南 【免费下载链接】HappyIslandDesigner "Happy Island Designer (Alpha)",是一个在线工具,它允许用户设计和定制自己的岛屿。这个工具是受游戏《动物森友会》(Animal Crossing)启发…...