第5章_排序与分页
文章目录
- 1 排序数据
- 1.1 排序规则
- 1.2 单列排序
- 1.3 多列排序
- 排序演示代码
- 2 分页
- 2.1 背景
- 2.2 实现规则
- 2.3 拓展
- 分页演示代码
- 3 课后练习
1 排序数据
1.1 排序规则
使用 ORDER BY 子句排序
- ASC(ascend): 升序
- DESC(descend):降序
ORDER BY 子句在SELECT语句的结尾(默认升序)。
1.2 单列排序
SELECT last_name, job_id, department_id, hire_date
FROM employees
ORDER BY hire_date ;
/*部分输出:
+-------------+------------+---------------+------------+
| last_name | job_id | department_id | hire_date |
+-------------+------------+---------------+------------+
| King | AD_PRES | 90 | 1987-06-17 |
| Whalen | AD_ASST | 10 | 1987-09-17 |
| Kochhar | AD_VP | 90 | 1989-09-21 |
| Hunold | IT_PROG | 60 | 1990-01-03 |
| Ernst | IT_PROG | 60 | 1991-05-21 |
| De Haan | AD_VP | 90 | 1993-01-13 |
*/SELECT last_name, job_id, department_id, hire_date
FROM employees
ORDER BY hire_date DESC ;
/*部分输出:
+-------------+------------+---------------+------------+
| last_name | job_id | department_id | hire_date |
+-------------+------------+---------------+------------+
| Banda | SA_REP | 80 | 2000-04-21 |
| Kumar | SA_REP | 80 | 2000-04-21 |
| Ande | SA_REP | 80 | 2000-03-24 |
| Markle | ST_CLERK | 50 | 2000-03-08 |
| Lee | SA_REP | 80 | 2000-02-23 |
| Philtanker | ST_CLERK | 50 | 2000-02-06 |
*/
SELECT employee_id, last_name, salary*12 annsal
FROM employees
ORDER BY annsal;
/*部分输出:
+-------------+-------------+-----------+
| employee_id | last_name | annsal |
+-------------+-------------+-----------+
| 132 | Olson | 25200.00 |
| 128 | Markle | 26400.00 |
| 136 | Philtanker | 26400.00 |
| 127 | Landry | 28800.00 |
| 135 | Gee | 28800.00 |
| 119 | Colmenares | 30000.00 |
*/
1.3 多列排序
-
可以使用不在SELECT列表中的列排序。
-
在对多列进行排序的时候,首先排序的第一列必须有相同的列值,才会对第二列进行排序。如果第一列数据中所有值都是唯一的,将不再对第二列进行排序。
SELECT last_name, department_id, salary
FROM employees
ORDER BY department_id, salary DESC;
/*部分输出
+-------------+---------------+----------+
| last_name | department_id | salary |
+-------------+---------------+----------+
| Grant | NULL | 7000.00 |
| Whalen | 10 | 4400.00 |
| Hartstein | 20 | 13000.00 |
| Fay | 20 | 6000.00 |
| Raphaely | 30 | 11000.00 |
| Khoo | 30 | 3100.00 |
| Baida | 30 | 2900.00 |
| Tobias | 30 | 2800.00 |
*/
排序演示代码
#1. 排序# 如果没有使用排序操作,默认情况下查询返回的数据是按照添加数据的顺序显示的。
SELECT * FROM employees;# 1.1 基本使用
# 使用 ORDER BY 对查询到的数据进行排序操作。
# 升序:ASC (ascend)
# 降序:DESC (descend)# 练习:按照salary从高到低的顺序显示员工信息
SELECT employee_id,last_name,salary
FROM employees
ORDER BY salary DESC;
/*部分输出:
+-------------+-------------+----------+
| employee_id | last_name | salary |
+-------------+-------------+----------+
| 100 | King | 24000.00 |
| 101 | Kochhar | 17000.00 |
| 102 | De Haan | 17000.00 |
| 145 | Russell | 14000.00 |
| 146 | Partners | 13500.00 |
*/# 练习:按照salary从低到高的顺序显示员工信息
SELECT employee_id,last_name,salary
FROM employees
ORDER BY salary ASC;
/*部分输出:
+-------------+-------------+----------+
| employee_id | last_name | salary |
+-------------+-------------+----------+
| 132 | Olson | 2100.00 |
| 128 | Markle | 2200.00 |
| 136 | Philtanker | 2200.00 |
| 127 | Landry | 2400.00 |
| 135 | Gee | 2400.00 |
| 119 | Colmenares | 2500.00 |
| 131 | Marlow | 2500.00 |
*/# 如果在ORDER BY 后没有显式指名排序的方式的话,则默认按照升序排列。
SELECT employee_id,last_name,salary
FROM employees
ORDER BY salary;
/*部分输出
+-------------+-------------+----------+
| employee_id | last_name | salary |
+-------------+-------------+----------+
| 132 | Olson | 2100.00 |
| 128 | Markle | 2200.00 |
| 136 | Philtanker | 2200.00 |
| 127 | Landry | 2400.00 |
| 135 | Gee | 2400.00 |
| 119 | Colmenares | 2500.00 |
| 131 | Marlow | 2500.00 |
*/#2. 我们可以使用列的别名,进行排序
SELECT employee_id,salary,salary * 12 annual_sal
FROM employees
ORDER BY annual_sal;
/*部分输出
+-------------+----------+------------+
| employee_id | salary | annual_sal |
+-------------+----------+------------+
| 132 | 2100.00 | 25200.00 |
| 128 | 2200.00 | 26400.00 |
| 136 | 2200.00 | 26400.00 |
| 127 | 2400.00 | 28800.00 |
| 135 | 2400.00 | 28800.00 |
*/#列的别名只能在 ORDER BY 中使用,不能在WHERE中使用。
#如下操作报错!
SELECT employee_id,salary,salary * 12 annual_sal
FROM employees
WHERE annual_sal > 81600;#3. 强调格式:WHERE 需要声明在FROM后,ORDER BY之前。
#先用where过滤,再用ORDER BY排序
SELECT employee_id,salary
FROM employees
WHERE department_id IN (50,60,70)
ORDER BY department_id DESC;
/*部分输出:
+-------------+----------+
| employee_id | salary |
+-------------+----------+
| 204 | 10000.00 |
| 103 | 9000.00 |
| 104 | 6000.00 |
| 105 | 4800.00 |
| 106 | 4800.00 |
| 107 | 4200.00 |
*/#4. 二级排序
#1.可以使用不在SELECT列表中的列排序。
#2.在对多列进行排序的时候,首先排序的第一列必须有相同的列值,才会对第二列
#3.进行排序。如果第一列数据中所有值都是唯一的,将不再对第二列进行排序。#练习:显示员工信息,先按照department_id的降序排列,
#再salary的升序排列
SELECT employee_id,salary,department_id
FROM employees
ORDER BY department_id DESC,salary ASC;
/*部分输出:
+-------------+----------+---------------+
| employee_id | salary | department_id |
+-------------+----------+---------------+
| 206 | 8300.00 | 110 |
| 205 | 12000.00 | 110 |
| 113 | 6900.00 | 100 |
| 111 | 7700.00 | 100 |
| 112 | 7800.00 | 100 |
| 110 | 8200.00 | 100 |
| 109 | 9000.00 | 100 |
*/
2 分页
2.1 背景
- 背景1:查询返回的记录太多了,查看起来很不方便,怎么样能够实现分页查询呢?
- 背景2:表里有 4 条数据,我们只想要显示第 2、3 条数据怎么办呢?
2.2 实现规则
分页原理
所谓分页显示,就是将数据库中的结果集,一段一段显示出来需要的条件。
MySQL中使用 LIMIT 实现分页
格式:
LIMIT 位置偏移量, 行数
第一个“位置偏移量”参数指示MySQL从哪一行开始显示,是一个可选参数,如果不指定“位置偏移量”,将会从表中的第一条记录开始(第一条记录的位置偏移量是0,第二条记录的位置偏移量是1,以此类推);第二个参数“行数”指示返回的记录条数。
举例
–前10条记录:
SELECT * FROM 表名 LIMIT 0,10;
或者
SELECT * FROM 表名 LIMIT 10;
–第11至20条记录:
SELECT * FROM 表名 LIMIT 10,10;
–第21至30条记录:
SELECT * FROM 表名 LIMIT 20,10;
MySQL 8.0中可以使用“LIMIT 3 OFFSET 4”,意思是获取从
第5条记录开始后面的3条记录,和“LIMIT4,3;”返回的结果相同。
分页显式公式:(当前页数-1)*每页条数,每页条数:
SELECT * FROM table
LIMIT(PageNo - 1)*PageSize,PageSize;
- 注意:LIMIT 子句必须放在整个SELECT语句的最后!
- 使用 LIMIT 的好处:
约束返回结果的数量可以 减少数据表的网络传输量 ,也可以 提升查询效率 。如果我们知道返回结果只有1 条,就可以使用 LIMIT 1 ,告诉 SELECT 语句只需要返回一条记录即可。这样的好处就是 SELECT 不需要扫描完整的表,只需要检索到一条符合条件的记录即可返回。
2.3 拓展
在不同的 DBMS 中使用的关键字可能不同。在 MySQL、PostgreSQL、MariaDB 和 SQLite 中使用 LIMIT 关键字,而且需要放到 SELECT 语句的最后面。
- 如果是 SQL Server 和 Access,需要使用 TOP 关键字,比如:
SELECT TOP 5 name, hp_max FROM heros
ORDER BY hp_max DESC
- 如果是 DB2,使用 FETCH FIRST 5 ROWS ONLY 这样的关键字:
SELECT name, hp_max
FROM heros
ORDER BY hp_max DESC FETCH FIRST 5 ROWS ONLY
- 如果是 Oracle,你需要基于 ROWNUM 来统计行数:
SELECT rownum,last_name,salary
FROM employees
WHERE rownum < 5 ORDER BY salary DESC;
#需要说明的是,这条语句是先取出来前 5 条数据行,然后再按照 hp_max
#从高到低的顺序进行排序。但这样产生的结果和上述方法的并不一样。
#在后面讲到子查询,你可以使用SELECT last_name,salary
FROM employees
ORDER BY salary DESC)
WHERE rownum < 10;
#得到与上述方法一致的结果。
分页演示代码
#2. 分页
#2.1 mysql使用limit实现数据的分页显示# 需求1:每页显示20条记录,此时显示第1页
SELECT employee_id,last_name
FROM employees
LIMIT 0,20;#0是偏移量,20是显示的条目数
/*输出:
+-------------+------------+
| employee_id | last_name |
+-------------+------------+
| 100 | King |
| 101 | Kochhar |
| 102 | De Haan |
| 103 | Hunold |
| 104 | Ernst |
| 105 | Austin |
| 106 | Pataballa |
| 107 | Lorentz |
| 108 | Greenberg |
| 109 | Faviet |
| 110 | Chen |
| 111 | Sciarra |
| 112 | Urman |
| 113 | Popp |
| 114 | Raphaely |
| 115 | Khoo |
| 116 | Baida |
| 117 | Tobias |
| 118 | Himuro |
| 119 | Colmenares |
+-------------+------------+
20 rows in set (0.00 sec)
*/# 需求2:每页显示20条记录,此时显示第2页
SELECT employee_id,last_name
FROM employees
LIMIT 20,20;#偏移量是20,显示条目数是20
/*输出
+-------------+-------------+
| employee_id | last_name |
+-------------+-------------+
| 120 | Weiss |
| 121 | Fripp |
| 122 | Kaufling |
| 123 | Vollman |
| 124 | Mourgos |
| 125 | Nayer |
| 126 | Mikkilineni |
| 127 | Landry |
| 128 | Markle |
| 129 | Bissot |
| 130 | Atkinson |
| 131 | Marlow |
| 132 | Olson |
| 133 | Mallin |
| 134 | Rogers |
| 135 | Gee |
| 136 | Philtanker |
| 137 | Ladwig |
| 138 | Stiles |
| 139 | Seo |
+-------------+-------------+
20 rows in set (0.00 sec)
*/# 需求3:每页显示20条记录,此时显示第3页
SELECT employee_id,last_name
FROM employees
LIMIT 40,20;#需求:每页显示pageSize条记录,此时显示第pageNo页:
#公式:LIMIT (pageNo-1) * pageSize,pageSize;#2.2 WHERE ... ORDER BY ...LIMIT 声明顺序如下:
# LIMIT的格式: 严格来说:LIMIT 位置偏移量,条目数
# 结构"LIMIT 0,条目数" 等价于 "LIMIT 条目数"
SELECT employee_id,last_name,salary
FROM employees
WHERE salary > 6000
ORDER BY salary DESC
#limit 0,10;
LIMIT 10;
/*输出:
+-------------+-----------+----------+
| employee_id | last_name | salary |
+-------------+-----------+----------+
| 100 | King | 24000.00 |
| 101 | Kochhar | 17000.00 |
| 102 | De Haan | 17000.00 |
| 145 | Russell | 14000.00 |
| 146 | Partners | 13500.00 |
| 201 | Hartstein | 13000.00 |
| 108 | Greenberg | 12000.00 |
| 147 | Errazuriz | 12000.00 |
| 205 | Higgins | 12000.00 |
| 168 | Ozer | 11500.00 |
+-------------+-----------+----------+
10 rows in set (0.00 sec)
*/#练习:表里有107条数据,我们只想要显示第 32、33 条数据怎么办呢?
SELECT employee_id,last_name
FROM employees
LIMIT 31,2;
/*输出:
+-------------+-----------+
| employee_id | last_name |
+-------------+-----------+
| 131 | Marlow |
| 132 | Olson |
+-------------+-----------+
2 rows in set (0.00 sec)
*/#2.3 MySQL8.0新特性:LIMIT ... OFFSET ...#练习:表里有107条数据,我们只想要显示第 32、33 条数据怎么办呢?
SELECT employee_id,last_name
FROM employees
LIMIT 2 OFFSET 31;#偏移量是31,显示条目为2条
/*输出
+-------------+-----------+
| employee_id | last_name |
+-------------+-----------+
| 131 | Marlow |
| 132 | Olson |
+-------------+-----------+
*/#练习:查询员工表中工资最高的员工信息
SELECT employee_id,last_name,salary
FROM employees
ORDER BY salary DESC
#limit 0,1
LIMIT 1;
/*输出
+-------------+-----------+----------+
| employee_id | last_name | salary |
+-------------+-----------+----------+
| 100 | King | 24000.00 |
+-------------+-----------+----------+
*/#2.4 LIMIT 可以使用在MySQL、PGSQL、MariaDB、SQLite 等数据库中使用,表示分页。
# 不能使用在SQL Server、DB2、Oracle!
3 课后练习
#第05章_排序与分页的课后练习#1. 查询员工的姓名和部门号和年薪,按年薪降序,按姓名升序显示 SELECT last_name,department_id,salary * 12 annual_salary
FROM employees
ORDER BY annual_salary DESC,last_name ASC;
/*部分输出
+-------------+---------------+---------------+
| last_name | department_id | annual_salary |
+-------------+---------------+---------------+
| King | 90 | 288000.00 |
| De Haan | 90 | 204000.00 |
| Kochhar | 90 | 204000.00 |
| Russell | 80 | 168000.00 |
| Partners | 80 | 162000.00 |
| Hartstein | 20 | 156000.00 |
| Errazuriz | 80 | 144000.00 |
*/#2. 选择工资不在 8000 到 17000 的员工的姓名和工资,按工资降序,显示第21到40位置的数据 SELECT last_name,salary
FROM employees
WHERE salary NOT BETWEEN 8000 AND 17000
ORDER BY salary DESC
LIMIT 20,20;
/*输出
+-----------+---------+
| last_name | salary |
+-----------+---------+
| Ernst | 6000.00 |
| Fay | 6000.00 |
| Mourgos | 5800.00 |
| Austin | 4800.00 |
| Pataballa | 4800.00 |
| Whalen | 4400.00 |
| Lorentz | 4200.00 |
| Sarchand | 4200.00 |
| Bull | 4100.00 |
| Bell | 4000.00 |
| Everett | 3900.00 |
| Chung | 3800.00 |
| Dilly | 3600.00 |
| Ladwig | 3600.00 |
| Rajs | 3500.00 |
| Dellinger | 3400.00 |
| Mallin | 3300.00 |
| Bissot | 3300.00 |
| Taylor | 3200.00 |
| Stiles | 3200.00 |
+-----------+---------+
*/#3. 查询邮箱中包含 e 的员工信息,并先按邮箱的字节数降序,
# 再按部门号升序SELECT employee_id,last_name,email,department_id
FROM employees
#where email like '%e%'
WHERE email REGEXP '[e]'
ORDER BY LENGTH(email) DESC,department_id;
/*部分输出
+-------------+------------+----------+---------------+
| employee_id | last_name | email | department_id |
+-------------+------------+----------+---------------+
| 201 | Hartstein | MHARTSTE | 20 |
| 114 | Raphaely | DRAPHEAL | 30 |
| 119 | Colmenares | KCOLMENA | 30 |
| 186 | Dellinger | JDELLING | 50 |
| 191 | Perkins | RPERKINS | 50 |
| 193 | Everett | BEVERETT | 50 |
| 198 | OConnell | DOCONNEL | 50 |
*/
相关文章:

第5章_排序与分页
文章目录 1 排序数据1.1 排序规则1.2 单列排序1.3 多列排序排序演示代码 2 分页2.1 背景2.2 实现规则2.3 拓展分页演示代码 3 课后练习 1 排序数据 1.1 排序规则 使用 ORDER BY 子句排序 ASC(ascend): 升序DESC(descend):降序 …...

Elasticsearch实战:常见错误及详细解决方案
Elasticsearch实战:常见错误及详细解决方案 1.read_only_allow_delete":“true” 当我们在向某个索引添加一条数据的时候,可能(极少情况)会碰到下面的报错: {"error": {"root_cause": [{&…...

C#添加缓存,删除缓存,修改缓存
在C#中,可以使用内置的缓存功能或者使用第三方缓存库来管理缓存。下面分别介绍使用内置缓存功能和使用第三方缓存库的方法。 使用内置缓存功能: 添加缓存: 在C#中,可以使用MemoryCache类来添加缓存。以下是一个简单的示例&…...

PADS Router的操作页面及鼠标指令介绍
PADS Router的用户界面由菜单栏,工作界面,一般工具栏,状态栏,项目浏览器组,输出窗口,电子表格组成(图1): 图1 注意:如果你的界面没有显示项目浏览器ÿ…...
Android studio进入手机调试状态
首先usb插入电脑手机打开开发者模式进入点击就会在你的页面显示了...

《Pytorch新手入门》第二节-动手搭建神经网络
《Pytorch新手入门》第二节-动手搭建神经网络 一、神经网络介绍二、使用torch.nn搭建神经网络2.1 定义网络2.2 torch.autograd.Variable2.3 损失函数与反向传播2.4 优化器torch.optim 三、实战-实现图像分类(CIFAR-10数据集)3.1 CIFAR-10数据集加载与预处理3.2 定义网络结构3.3…...

C++ 模板学习笔记
C另外一种编程成为 泛型编程 ,主要利用的技术就是模板 C提供两种模板机制:函数模板和类模板 C11中,函数模板和类模板都可以设定默认参数,传送门 函数模板 一般 typename 和 class 没有区别,typename 还有个作用是使…...

1、Flink基础概念
1、基础知识 (1)、数据流上的有状态计算 (2)、框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。 (3)、事件驱动型应用,有数据流就进行处理,无数据流就不…...

分享一下怎么做小程序营销活动
小程序营销活动已经成为现代营销的必备利器,它能够帮助企业提高品牌知名度、促进产品销售,以及加强与用户的互动。然而,要想成功地策划和执行一个小程序营销活动,需要精心设计和全面规划。本文将为您介绍小程序营销活动的策划和执…...

Laravel 后台管理 Dcat Admin 使用记录
Laravel Dcat Admin 安装配置修改配置表格操作 Ajax 结合 Pjax 更新数据状态表格 链接表单设置页面(通常修改更新在同一页面)表单 安装配置 安装文档地址 框架版本 Laravel 8.* 修改配置 修改 admin.php 文件 return [// 后台名称name > DAD后台管理,// 标题title > 后台…...

c语言基础:L1-070 吃火锅
以上图片来自微信朋友圈:这种天气你有什么破事打电话给我基本没用。但是如果你说“吃火锅”,那就厉害了,我们的故事就开始了。 本题要求你实现一个程序,自动检查你朋友给你发来的信息里有没有 chi1 huo3 guo1。 输入格式&#x…...

java spring boot 注解、接口和问题解决方法(持续更新)
注解 RestController 是SpringMVC框架中的一个注解,它结合了Controller和ResponseBody两个注解的功能,用于标记一个类或者方法,表示该类或方法用于处理HTTP请求,并将响应的结果直接返回给客户端,而不需要进行视图渲染…...

HMAC_SHA1加密算法和SHA1加密算法的区别
HMAC_SHA1加密算法和SHA1加密算法的区别 应用场景:SHA1目前主要用于政府部门和私营业主处理敏感信息,被视为最先进的加密技术。而HMAC_SHA1主要用于基于密钥的消息认证码(HMAC)运算,需要一个密钥作为输入。密钥需求&a…...
Ubuntu连不上WiFi 或者虽然能连上校园网,但是浏览器打不开登录页面
写在前面 自己的电脑环境: Ubuntu20.04 一、问题描述 自己的 Ubuntu 遇到连接不上 除校园网之外的其他WiFi, 或者 虽然能连上校园网,但是浏览器打不开登录页面的问题。 二、解决方法 出现这种问题的原因可能是 之前开过VPN, 导致系统的网络设置出现…...

Maven第八章:如何解决Maven的jar版本冲突
Maven第八章:如何解决Maven的jar版本冲突 前言 本文重点讲解Maven依赖冲突原因,maven依赖原则以及如何利用idea Maven Helper插件分析解决问题。 背景 开发过程中引入第三方jar遇到依赖冲突的,非常影响开发,甚至大部分时间都在调试版本兼容。 Caused by:java.lang.NoSuch…...

c# 读写内存映射文件
在C#中,可以使用System.IO.MemoryMappedFiles命名空间中的MemoryMappedFile类来操作内存映射文件。可以创建不固定大小的内存映射文件,具体步骤如下: 1. 先创建一个初始大小为0的内存映射文件,使用MemoryMappedFile.CreateNew方法…...

行业揭秘:腾讯共享wifi码推广零加盟费是真的吗?
近年来,“共享经济”概念在商业领域取得了巨大成功。共享WiFi贴码成为共享经济的一种典型案例,被越来越多的人看作是一种低风险、高回报的投资方式。而在这个市场中,腾讯WiFi码推广以“零加盟费”而备受关注。本文将探讨腾讯WiFi码推广零加盟…...

E4980A 精密型 LCR 表,20 Hz 至 2 MHz
E4980A 精密型 LCR 表 20 Hz 至 2 MHz E4980A 精密型 LCR 表实现了测量准确度、速度与通用性的理想结合,适用于各种元器件测量。 E4980A 精密型 LCR 表实现了测量准确度、速度与通用性的理想结合,适用于各种元器件测量。 无论是在低阻抗量程还是在高阻…...

【前端工作提效】关于工作提效的一点实践与思考
1、测试提的BUG是一个一个提的,如果顺着测试提供的BUG单去一个一个解决问题,那么很容易管中窥豹,就像打补丁一样,缝缝补补,没有办法从根源去解决问题。所以我们需要尽量去了解代码的业务情况,并尽可能将一些…...
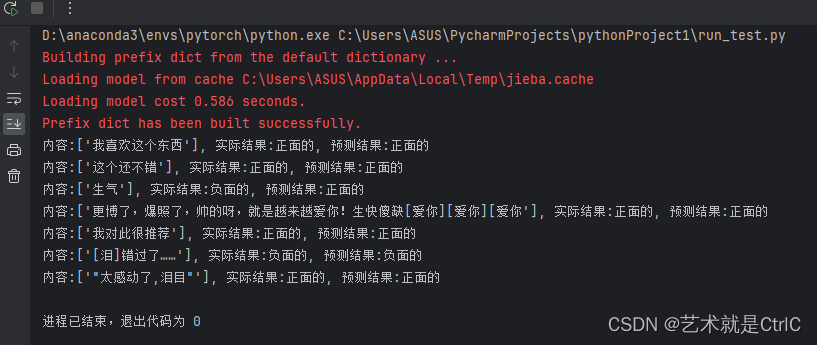
Pytorch 文本情感分类案例
一共六个脚本,分别是: ①generateDictionary.py用于生成词典 ②datasets.py定义了数据集加载的方法 ③models.py定义了网络模型 ④configs.py配置一些参数 ⑤run_train.py训练模型 ⑥run_test.py测试模型 数据集https://download.csdn.net/download/Victor_Li_/88486959?spm1…...

电脑‘假关机’真烦人!深入聊聊Windows电源管理里的‘快速启动’到底是个啥
Windows快速启动技术揭秘:高效与兼容性的博弈深夜加班结束,你点击关机按钮准备休息,却发现显示器刚暗下去又突然亮起——这不是灵异事件,而是Windows的快速启动功能在"作祟"。这种介于关机和休眠之间的混合状态…...

Kubernetes多租户管理:实现资源隔离与安全的完整指南
Kubernetes多租户管理:实现资源隔离与安全的完整指南 引言 在企业环境中,多租户管理是Kubernetes的重要功能。通过多租户管理,可以实现不同团队或客户之间的资源隔离和安全控制。这对于共享Kubernetes集群的场景尤为重要。 作为一名资深的Dev…...

昇腾CANN cann-spack-package:Spack 包管理器的 CANN 集成实战
HPC(高性能计算)圈子里不用 pip 和 conda——用 Spack。Spack 是一个专为科学计算设计的包管理器,能同时管理一个软件包的多个版本(不同编译器、不同依赖版本、不同架构),每个变体独立安装在 spack/opt/ 下…...

多云安全态势:管理多个云环境的安全状态
多云安全态势:管理多个云环境的安全状态 一、多云安全态势概述 1.1 多云安全态势的定义 多云安全态势是指在多个云环境中评估和管理安全状态的过程。它通过统一的安全策略和监控,确保多个云平台的安全性和合规性。 1.2 多云安全态势的价值 统一安全&…...

2026年腾讯云OpenClaw/Hermes Agent配置Token Plan怎么安装看这
2026年腾讯云OpenClaw/Hermes Agent配置Token Plan怎么安装看这。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具&…...

Midjourney V6调色板设置失效的5大隐性原因:从--sref误用到色域压缩陷阱,一文终结色彩失真
更多请点击: https://codechina.net 第一章:Midjourney V6调色板设置失效的全局认知 Midjourney V6 引入了更严格的色彩语义解析机制,导致此前在 V5.x 中广泛使用的 --palette 参数(如 --palette vibrant 或 --palette muted&…...

pycryptodome导入失败的四大底层原因与诊断方案
1. 这不是pycryptodome的问题,而是你没看清它真正依赖的底层逻辑“ImportError: No module named Crypto”、“AttributeError: module Crypto.Cipher has no attribute AES”、“ModuleNotFoundError: No module named Cryptography_cffi...”——这些报错我过去三…...

STM32F4电池电量监测实战:用HAL库和ADC DMA,从硬件分压到软件滤波全流程解析
STM32F4电池电量监测实战:从硬件设计到软件滤波的工程化实现 在物联网设备和便携式电子产品的开发中,精确监测电池电量是一个看似简单却暗藏玄机的关键技术点。许多开发者都曾遇到过这样的困境:实验室测试时电量显示精准稳定,一旦…...

抖音无水印下载器:5分钟掌握高效批量下载的完整指南
抖音无水印下载器:5分钟掌握高效批量下载的完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support…...

ShiroAttack2实战指南:从漏洞检测到内存马注入的完整揭秘
ShiroAttack2实战指南:从漏洞检测到内存马注入的完整揭秘 【免费下载链接】ShiroAttack2 shiro反序列化漏洞综合利用,包含(回显执行命令/注入内存马)修复原版中NoCC的问题 https://github.com/j1anFen/shiro_attack 项目地址: https://gitc…...