CoCa论文笔记
摘要
计算机视觉任务中,探索大规模预训练基础模型具有重要意义,因为这些模型可以可以极快地迁移到下游任务中。本文提出的CoCa(Contrastive Captioner),一个极简设计,结合对比损失和captioning损失预训练一个image-text encoder-decoder基础模型,该模型包含对比方法,如CLIP,和生成方法,如SimVLM,的学习能力。与基本的encoder-decoder transformer使用所有的decoder层来编码输出不同,CoCa在上半部分的decoder中舍去cross-attention来编码unimodel单模态文本表示,然后级联剩下的decoder结合image encoder用于multimodel图文对表示。在单模态的图像和文本表示之间使用对比损失函数,对多模态decoder的输出应用captioning损失来自动预测文本tokens。通过共享相同的计算图,两个训练目标以最小的开销有效地训练。CoCa在网络文本数据和带注释的图像数据上进行预训练,图像的标签被简单视为文本来学习特征表示。此外,CoCa在零样本迁移和各种特定的下游任务上都取得了最好的效果,包含视觉识别(ImageNet,Kinetics-400/600/700,Moments-in-Time),检索,多模型理解和图像字幕。在图像分类任务上,CoCa的zero-shot取得86.3%的top-1准确率,linear probe取得90.6%,微调上取得91.0%的精度。
Introduction
深度学习最近已经见证了基础语言模型的兴起,例如BERT,T5,GPT-3,该模型使用大规模数据进行预训练,并通过零样本、少样本或迁移学习展示通用多任务处理能力。与专用模型相比,针对大量下游任务的预训练基础模型可以摊销训练成本。
对于视觉和视觉-语言问题,几个基础模型已经进行探究过:
- Single-encoder model:之前的工作验证了single-encoder模型的有效性,该模型在图像分类数据集,如ImageNet,上使用交叉熵损失函数进行预训练。模型的编码器提供通用的视觉特征表示,可以在各种图像和视频理解的下游任务上进行微调。但是这些模型非常依赖于图像的标注,同时不涉及任何自然语言知识,阻碍其在视觉和语言多模态的下游任务上的应用。

- Dual-encoder model:指的是CLIP这一条线上的研究。利用海量从网络上采集的图文对,以对比损失函数优化两个encoder,即image encoder和text encoder分别对图像和文本进行独立编码。CLIP模型在zero-shot图像分类任务和图像-文本检索上都取得出色的成绩,但是由于CLIP是图像和文本独立编码,且编码过程中没有任何图像和文本侧的交叉,只在最后计算余弦相似度,缺少图像和文本的融合表示,因此不适用于VQA等需要对图像和文本联合理解的任务。

- Encoder-Decoder model:这种模型使用encoder-decoder的结构,encoder侧对图像进行编码,decoder侧学习一个跨模态的语言模型,预测图像对应的文本。这种生成式方法天然适用于看图说话任务,并且图像和文本在encoder-decoder的attention交互有助于多模态信息融合,适用于多模态理解相关任务。缺点在于,没有像CLIP一样生成单独的文本表示,不能灵活应用到图文匹配任务中。

CoCa统一上面三种范式,训练一个图像-文本模型既可以生成图像侧和文本侧的单独表示,又能进行更深层次的图像、文本信息融合,适用于更广泛的任务。
模型结构
介绍CoCa网络结构之前,首先回顾一下之前三种基础模型的不同之处。
- Single-Encoder Classification:该方法使用一个大型图像标注数据集,如ImageNet、Instagram、JFT,来训练一个视觉encoder。这些图像标签通常使用交叉熵损失函数来映射到固定的类别空间分布中,公式如下。
L c l s = − p ( y ) l o g q θ ( x ) L_{cls}=-p(y)logq_{\theta}(x) Lcls=−p(y)logqθ(x)
- Dual-Encoder Contrastive Learning:该方法使用海量从网络上采集的图像对进行训练,以对比损失函数优化image和text encoder,公式如下:
L c o n = − 1 N ( ∑ i N l o g e x p ( x i T y i / σ ) ∑ j = 1 N e x p ( x i T y i / σ ) + e x p ( y i T x i / σ ) ∑ j = 1 N e x p ( y i T x i / σ ) ) L_{con}=-\frac{1}{N}(\sum_i^Nlog\frac{exp(x_i^Ty_i/\sigma)}{\sum_{j=1}^Nexp(x_i^Ty_i/\sigma)}+\frac{exp(y_i^Tx_i/\sigma)}{\sum_{j=1}^Nexp(y_i^Tx_i/\sigma)}) Lcon=−N1(i∑Nlog∑j=1Nexp(xiTyi/σ)exp(xiTyi/σ)+∑j=1Nexp(yiTxi/σ)exp(yiTxi/σ))
其中 x i x_i xi和 y j y_j yj分布为图像和文本的归一化编码。 σ \sigma σ为温度系数来缩放逻辑值。
- Encoder-Decoder Captioning:encoder侧对图像进行编码,decoder侧学习一个跨模态的语言模型,预测图像对应的文本,损失函数如下:
L c a p = − ∑ t = 1 T l o g P θ ( y t ∣ y < t , x ) L_{cap}=-\sum_{t=1}^TlogP_{\theta}(y_t|y_{<t},x) Lcap=−t=1∑TlogPθ(yt∣y<t,x)
如下图所示,CoCa模型的整体框架包含3个部分:一个encoder(image encoder)和两个decoder(Unimodel Text Decoder和Multimodel Text Decoder)。Image Encoder采用图像模型对图像进行编码,例如ViT等。Unimodel Text Decoder和CLIP中的text encoder类似,用于提取文本的特征,是一个不和图像侧进行信息交互的文本解码器。Unimodel Text Decoder和Image Encoder之间没有cross attention,而MultiMode Text Decoder建立在Unimodel Text Decoder之上,和Image Encoder进行交互,生成图像和文本交互信息,并解码还原对应文本。

整个模型的损失包括对比学习和看图说话两部分。损失函数如下:
L C o C a = λ c o n ∗ L c o n + λ c a p ∗ L c a p L_{CoCa}=\lambda_{con}*L_{con}+\lambda_{cap}*L_{cap} LCoCa=λcon∗Lcon+λcap∗Lcap
单模态文本decoder生成文本编码,末尾的cls token包含文本统一表示,和图像侧编码进行对比学习。多模态文本编码部分和图像侧编码输出进行更深入交互,生成文本预测结果。
此外,CoCa采用attention pooling的方式融合图像侧信息。对于图像识别任务,使用单个图像编码获取全局表示效果更好,而对于多模态理解任务需要更多视觉tokens获取局部特征。因此CoCa在图像侧使用attention pooling既可以提取一个统一的编码,也可以提取每个token的表示。对于生成式任务会用一个维度为256的query进行attention,而对比学习则采用维度为1的query提取全局信息。
实验结果
预训练设置
Data:CoCa使用JFT-3B和ALIGN两个数据集从头开始训练模型,不同于之前的模型首先使用交叉熵损失函数预训练一个图像编码器,CoCa直接从头开始训练所有参数。
Optimization:batch size设置为65536,其中每个batch中的数据来自JFT和ALIGN数据集各一半。训练步数为500k,大约是JFT训练5个epoch,ALIGN训练10个epoch。优化函数采用Adafactor, β 1 = 0.9 , β 2 = 0.999 \beta_1=0.9,\beta_2=0.999 β1=0.9,β2=0.999,权重衰减率为0.01。CoCa预训练的输入大小为288×288,patch size为18×18,之后又以576×576的分辨率训练了一个epoch。
实验结果
CoCa在图像分类、图文检索、看图说话等多个任务上都取得非常亮眼的效果。下图为CoCa在多个任务上的效果对比,可以看到CoCa在多个任务和数据集上都达到SOTA,在ImageNet上达到91%的效果。

视觉识别任务
CoCa分别在图像分类数据集ImageNet和视频数据集Kinetics-400, 600, 700上进行实验验证其有效性。实验过程中的超参数设置如下。

冻结CoCa的预训练权重,然后在数据集上进行训练,在相同的设置下,与其他模型进行对比,效果如下,可以看到CoCa已经取得较好的Top-1精度,同时在视频任务上超过之前的SOTA方法。进一步微调CoCa的encoder,在所有数据集上效果都有提升,在ImageNet上取得新的SOTA达到91%的Top-1值。

跨模式对齐任务
在该任务中,CoCa的所有参数冻结直接用来提取特征进行zero-shot,在这部分多模态decoder没有被使用。
零样本图文检索
CoCa在MSCOCO和Flickr30K两个基础的图文检索数据集上进行测试。按照CLIP的测试方法,首先分别输入图像/文本到对应的encoder中得到测试集中所有的图像/文本embeddings,然后通过余弦相似度召回。如下图所示,CoCa在所有评价指标上都超过之前方法很多。结果显示CoCa可以学习到很好的单模态表示并且跨膜态对齐它们。

零样本图像分类
如下图所示,CoCa在ImageNet上取得一个新的SOTA零样本图像分类结果。此外,通过对比平均值可以知道CoCa具有较好的泛化性。

零样本视频检索
CoCa在MSR-VTT数据集上测试视频-文本检索效果。如下图所示CoCa在text-to-video和video-to-text召回上都取得最好的效果。

多模态理解任务
CoCa一个关键的优势在于其可以像encoder-decoder模型一样处理多模态embeddings,因此CoCa可以进行看图描述和多模态理解任务。
多模态理解
CoCa分别在VQA、SNLI-VE、NLVR2上进行多模态理解任务测试,如下图所示,CoCa效果超过最强的视觉语言预训练模型,同时在这三个任务上都取得了SOTA。

看图说话
除了多模态分类任务,CoCa同样可以直接应用到看图说话任务中。使用captioning损失函数在MSCOCO数据集上微调CoCa,然后进行MSCOCO的Karpathy-test子集测试,同时在线测试NoCaps数据集。如下图所示,Coca在MSCOCO数据集上超越使用交叉熵损失训练的最强模型。在NoCaps测试上,CoCa分别在测试和验证子集上取得SOTA。

结论
本文提出了一个新的图像文本基础模型CoCa,融合了已有的图像预训练范式。CoCa可以使用图像文本对进行端到端训练,并在encoder-decoder范式中有效地对比和caption损失。最重要的是CoCa在一系列下游任务中都取得了最好的效果。
相关文章:
CoCa论文笔记
摘要 计算机视觉任务中,探索大规模预训练基础模型具有重要意义,因为这些模型可以可以极快地迁移到下游任务中。本文提出的CoCa(Contrastive Captioner),一个极简设计,结合对比损失和captioning损失预训练一…...

uniapp 微信小程ios端键盘弹起后导致页面无法滚动
项目业务逻辑和出现的问题整理 新增页面 用户可以主动添加输入文本框 添加多了就会导致当前页面出现滚动条,这就导致ios端滚动页面的时候去点击输入框键盘抬起再关闭的时候去滚动页面发现页面滚动不了(偶尔出现),经过多次测试发现是键盘抬起的时候 主动向上滑动 100%出现这种问…...
三维模型优势在哪里?如何提升产品自身商业价值?
不少企业、商家都开始使用VR全景展示来宣传推广自己的产品、活动等,虽说VR全景的沉浸式体验,相比于图片、视频而言有着无法取代的优势,但是也不能忘了VR全景另一个大优势,那就是丰富多样的互动性。3D模型展示让产品展示和体验不再…...
WheatA 轻量级生态数据软件
无论是在工作还是上学期间,大家想要做一个科研项目或者市场调查时,往往需要大量的数据用于分析总结,这时获得优质的数据就显得额外重要,数据的优劣往往决定了项目结果的好坏。数据来源的主要渠道主要有两种:无非是去数…...
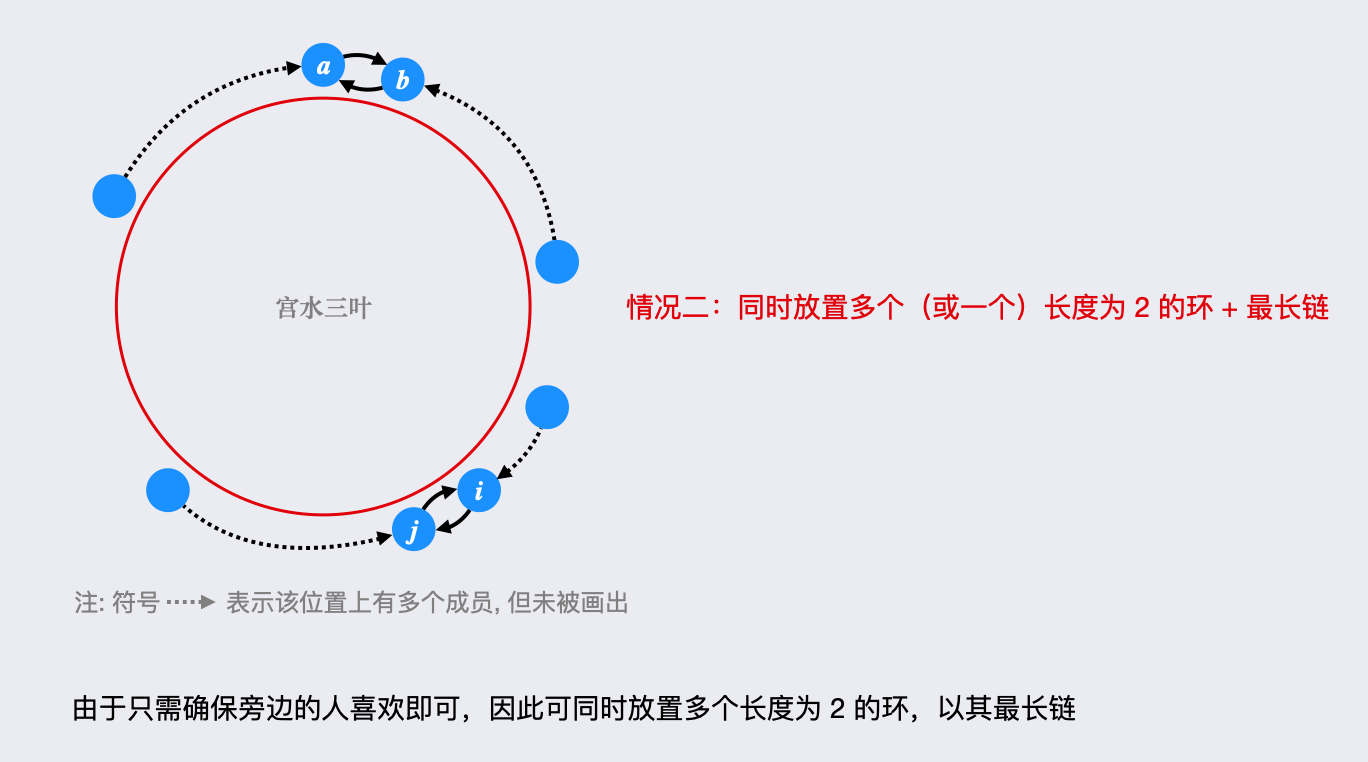
2127. 参加会议的最多员工数 : 啥是内向/外向基环树(拓扑排序)
题目描述 这是 LeetCode 上的 「2127. 参加会议的最多员工数」 ,难度为 「困难」。 Tag : 「拓扑排序」、「内向基环树」、「图」 一个公司准备组织一场会议,邀请名单上有 n 位员工。 公司准备了一张圆形的桌子,可以坐下任意数目的员工。 员工…...

Qt入门日记1
目录 1.Qt简介和案例 2.第一个Qt程序 3.学会查看帮助文档 4.创建一个按钮 5.对象树简介 6.Qt的坐标系 7. 信号和槽 7.1自定义信号和槽 7.2信号连接信号 7.3拓展 7.4Qt4版本以前的connect 1.Qt简介和案例 Qt是一个跨平台的C图形用户界面应用程序框架(就是一个库吧…...

SpringBoot_第七章(读写分离)
这里列举了三种读写分离实现方案,分别是如下三种 1:MybatisPlus(读写分离) 1.1:首先创建三个数据库1主2从 表名是user表 1.2:代码实例 1:导入pom <!--MybatisPlus的jar 3.0基于jdk8--><depend…...
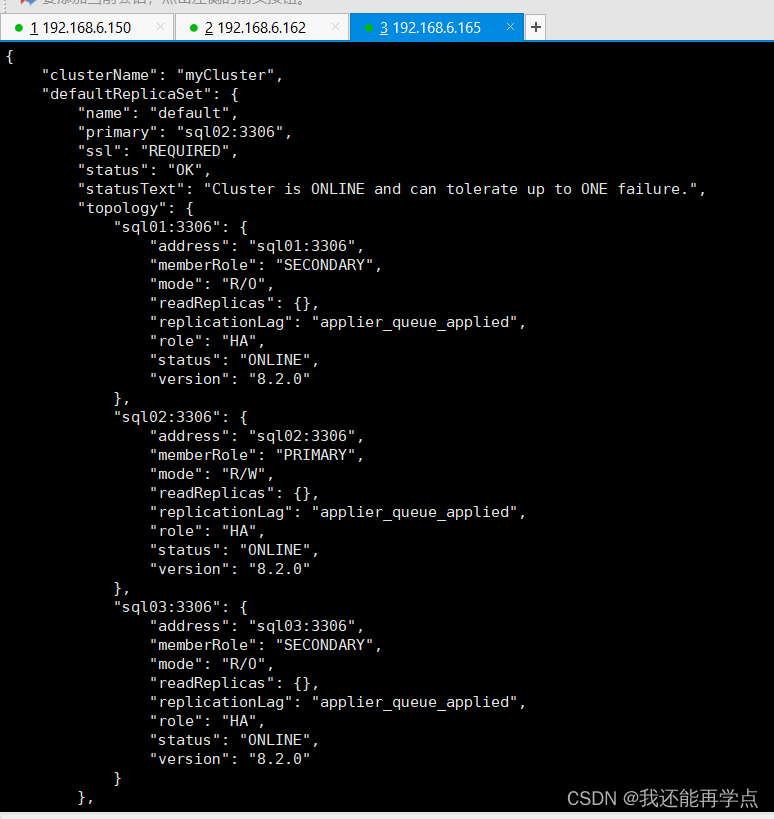
linux下mysql-8.2.0集群部署(python版本要在2.7以上)
目录 一、三台主机准备工作 1、mysql官方下载地址:https://dev.mysql.com/downloads/ 2、修改/etc/hosts 3、关闭防火墙 二、三台主机安装mysql-8.2.0 1、解压 2、下载相应配置 3、初始化mysql,启动myslq,设置开机自启 4、查看初始密…...

40 深度学习(四):卷积神经网络|深度可分离卷积|colab和kaggle的基础使用
文章目录 卷积神经网络为什么要卷积卷积的具体流程池化tensorflow代码 深度可分离卷积原理介绍计算量对比代码参数计算例子 colab 和 kagglecolabkaggle如何在colab上使用kaggle的数据 卷积神经网络 卷积神经网络的基本结构 1: (卷积层(可选)池化层) * N全连接层 *…...

Spring Boot面向切面加注解
一.项目pom.xml文件引入切面依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-aop</artifactId> </dependency>二.定义注解类 import java.lang.annotation.*;/*** desc 错误日志注解* au…...

uniapp小程序授权统一处理
1.使用 1.将工具代码引入到utils中 const authorize (scope, isOne false, isMust false) > {if (!scope || !authorizeObj[scope]) {return console.error(请传输需要获取权限的 scope,详见,https://uniapp.dcloud.net.cn/api/other/authorize.html#scope-…...

光学仿真|优化汽车内部照明体验
当我们谈论优化人类感知的内部照明时,我们实际上指的是两个重点领域:安全性和驾驶员体验。如果内部照明可以提供尽可能最佳的体验,驾驶员则能够更好地应对颇具挑战性或意外的驾驶状况,并且减轻疲劳感。除了功能优势外,…...

Spring XML使用CASE WHEN处理SELECT字段
在日常开发中,经常会碰到需要导出的情况。而一些枚举值或者状态一般是定义成整型,这个时候需要对数据进行转换,转换成对应的文本再导出。 在XML中用CASE WHEN来根据不同的查询结果做不同的处理。 比如 SELECT name AS 姓名, age AS 年龄 C…...

关于C#中使用多线程的讨论
关于C#中使用多线程的讨论 C# 中 Thread 调用的函数有返回值 没有输入应该如何解决 如果你想在一个新的线程中调用一个带返回值但没有输入参数的函数,可以使用 Thread 类的委托 ThreadStart 来创建一个新的线程,并在其中调用该函数。然后,你可以使用 Thread 类的 Join 方法…...

工程机械数字孪生可视化平台建设,推动大型装备智能化数字化转型升级
随着信息技术的迅猛发展,数字孪生技术作为一项新兴技术应运而生。数字孪生是指通过数学模型和仿真技术,将实际物理对象与其数字化虚拟模型相互关联,实现对物理对象的全生命周期管理和智能优化。在工程机械领域,巨蟹数科从数字孪生…...
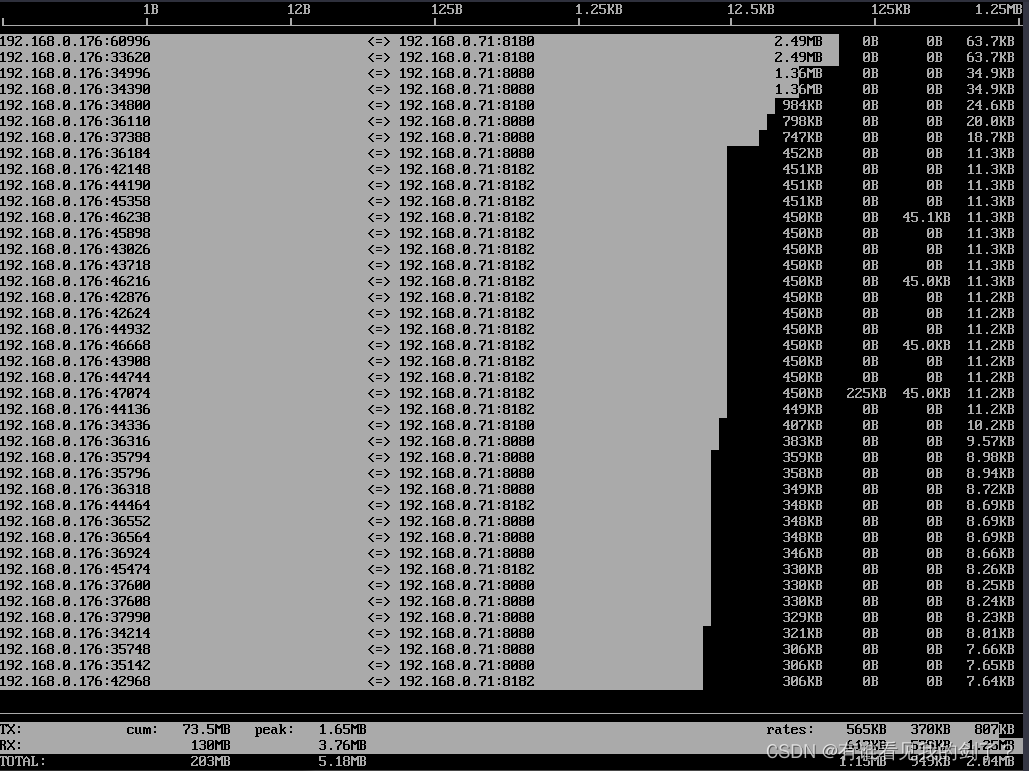
Linux 网络流量监控利器 iftop命令详解及实战
简介 iftop 是什么 在 Linux 系统下即时监控服务器的网络带宽使用情况,有很多工具,比如 iptraf、nethogs 等等,但是推荐使用小巧但功能很强大的 iftop 工具。 iftop 是 Linux 系统一个免费的网卡实时流量监控工具,类似于 top 命令…...
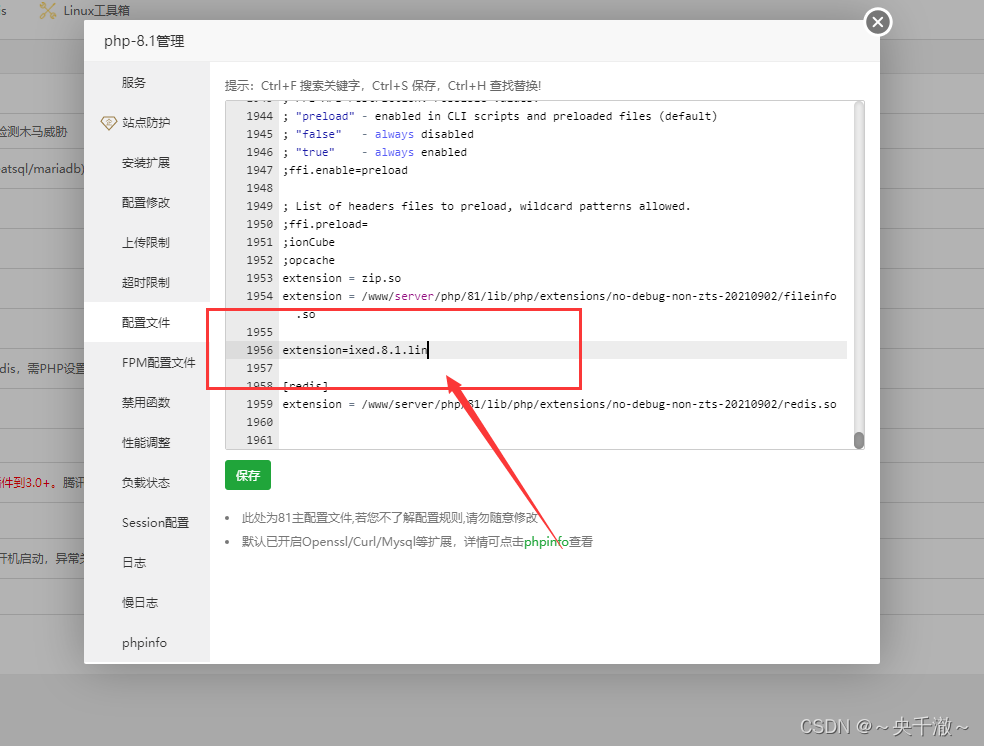
protected by SourceGuardian and requires a SourceGuardian loader ‘ixed.8解决方案
php相关问题 安装程序提示以下内容 遇到某些php程序的安装提示: PHP script ‘/www/wwwroot/zhengban.youyacao.com/install/index.php’ is protected by SourceGuardian and requires a SourceGuardian loader ‘ixed.8.1.lin’ to be installed. 1) Click her…...
)
KWin、libdrm、DRM从上到下全过程 —— drmModeAddFBxxx(14)
接前一篇文章:KWin、libdrm、DRM从上到下全过程 —— drmModeAddFBxxx(13) 上一回讲完了drivers/gpu/drm/drm_framebuffer.c中的framebuffer_check函数中的第一个for循环,本回继续讲解framebuffer_check()接下来的代码。为了便于理解,再次贴出其源码,如下所示: static …...
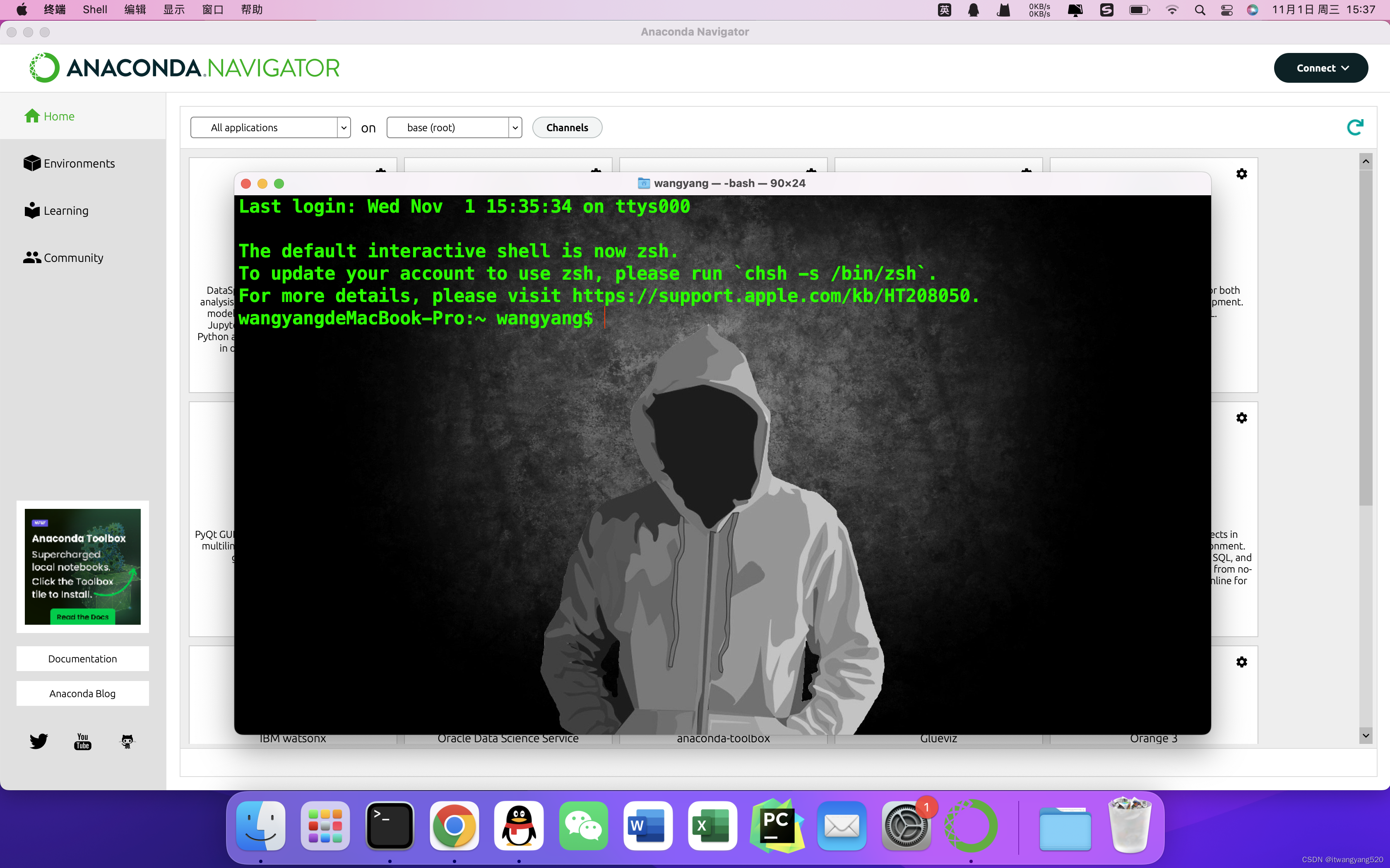
2023-macOS下安装anaconda,终端自动会出现(base)字样,如何取消
2023-macOS下安装anaconda,终端自动会出现(base)字样,如何取消 安装后,我们再打开终端,就会自动出现了(base) 就会出现这样子的,让人头大, 所以我们要解决它 具体原因是 安装了anac…...
Nginx搭载负载均衡及前端项目部署
目录 编辑 一.Nginx安装 1.安装所需依赖 2.下载并解压Nginx安装包 3.安装nginx 4.启动Nginx服务 二.Tomcat负载均衡 1.准备环境 1.1 准备两个Tomcat 1.2 修改端口号 1.3 配置Nginx服务器集群 2.效果展示 编辑三.前端项目打包 编辑四.前端项目部署 1.上传项目…...

优化缺陷密度,核心是从“事后救火”转向“全程预防”
优化缺陷密度,核心是从“事后救火”转向“全程预防”,通过系统化的流程和工具,在生产代码中构建 “计划-执行-检查-改进”的持续优化闭环。📈 第一步:测量与评估,建立基线测量缺陷密度:按质量阶…...

终极网站性能优化指南:publiccode.asia 加载速度提升10个技巧
终极网站性能优化指南:publiccode.asia 加载速度提升10个技巧 【免费下载链接】publiccode.asia-legacy Website of https://publiccode.asia 项目地址: https://gitcode.com/gh_mirrors/pu/publiccode.asia-legacy 想要让你的网站像闪电一样快速加载吗&…...

FlashAttention 在昇腾NPU上的极致优化
刚接触 FlashAttention 那会,我被一个困惑砸懵了:明明 Attention 机制的计算量已经是 O(n) 了,业界还在拼命优化它,图什么? 直到我看见一组数据才明白——训练一个 1750 亿参数的 GPT-3,光是 Attention 计…...

5分钟掌握OpenTracks:隐私优先的开源运动跟踪应用全面指南
5分钟掌握OpenTracks:隐私优先的开源运动跟踪应用全面指南 【免费下载链接】OpenTracks Repository moved to: https://codeberg.org/OpenTracksApp/OpenTracks 项目地址: https://gitcode.com/gh_mirrors/op/OpenTracks 你是否厌倦了那些不断要求网络权限、…...

对比直接使用厂商api体验taotoken在延迟与可用性上的差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商 API 体验 Taotoken 在延迟与可用性上的差异 在构建依赖大模型能力的应用时,开发者通常会直接调用特定…...

微服务限流实战:Nginx 漏桶与网关令牌桶
限流不是为了让系统“变慢”,而是为了让系统在突发流量、恶意请求或超过承载能力时,仍然能保住核心服务。 一句话概括:限流是在入口处控制请求速度或并发数量,Nginx 常用漏桶算法控制请求流出速率,Spring Cloud Gatewa…...

CharacterAI Python API终极指南:如何快速构建AI对话机器人
CharacterAI Python API终极指南:如何快速构建AI对话机器人 【免费下载链接】CharacterAI Unofficial Python API for character.ai 项目地址: https://gitcode.com/gh_mirrors/ch/CharacterAI 你是否想在自己的Python应用中集成CharacterAI的强大对话功能&a…...

Coq终极实践指南:深入解析形式化证明系统架构与应用
Coq终极实践指南:深入解析形式化证明系统架构与应用 【免费下载链接】coq The Rocq Prover is an interactive theorem prover, or proof assistant. It provides a formal language to write mathematical definitions, executable algorithms and theorems togeth…...

Mi-Create:让每个人都能成为小米手表表盘设计师的免费开源工具
Mi-Create:让每个人都能成为小米手表表盘设计师的免费开源工具 【免费下载链接】Mi-Create Unofficial watchface creator for Xiaomi wearables ~2021 and above 项目地址: https://gitcode.com/gh_mirrors/mi/Mi-Create 你是否曾经看着小米手表上那些千篇一…...

3步实现AI动作复制:如何用ComfyUI-MimicMotionWrapper让普通人拥有专业舞者动作
3步实现AI动作复制:如何用ComfyUI-MimicMotionWrapper让普通人拥有专业舞者动作 【免费下载链接】ComfyUI-MimicMotionWrapper 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-MimicMotionWrapper 你是否想过让照片中的人物动起来,赋予静…...