Es中出现unassigned shards问题解决
1、一般后台会报primary shard is not active Timeout: …
出现这种问题表示该索引是只读了,没办法进行shard及存储操作,优先排除是系统存储盘满了
2、通过监控工具查看(cerebro)
发现该索引shard 1 损坏

也可以通过命令进行查看
GET _cluster/allocation/explain?pretty

3、问题原因
1. Shard allocation 过程中的延迟机制2. nodes 数小于分片副本数3. 检查是否开启 cluster.routing.allocation.enable 参数4. 分片的历史数据丢失了5. 磁盘不够用了6. es 的版本问题
4、 问题解决
4.1、 简单粗暴方式解决(删索引)
如果该索引数据是日志记录,非必要数据可进行删除该索引即可解决,如:监控数据,丢了就丢了,因为你只关注当前的
4.2、Shard allocation 过程中的延迟机制
当一个 点从集群中下线了, es 有一个延迟拷贝机制, 默认是等一分钟之后再开始处理 unassigned 的分片, 该做 rebalance的去 rebalance,只所以这样, 是因为es担心如果一个点只是中断了片刻, 或者临时下线某台机器,就立马大动干戈,就尴尬了,比如下面这种情形
Node(节点) 19 在网络中失联了(某个家伙踢到了电源线)
Master 立即注意到了这个节点的离线,它决定在集群内提拔其他拥有 Node 19 上面的主分片对应的副本分片为主分片
在副本被提拔为主分片以后,master 节点开始执行恢复操作来重建缺失的副本。集群中的节点之间互相拷贝分片数据,网卡压力剧增,集群状态尝试变绿。
由于目前集群处于非平衡状态,这个过程还有可能会触发小规模的分片移动。其他不相关的分片将在节点间迁移来达到一个最佳的平衡状态
与此同时,那个踢到电源线的倒霉管理员,把服务器插好电源线进行了重启,现在节点 Node 19 又重新加入到了集群。不幸的是,这个节点被告知当前的数据已经没有用了, 数据已经在其他节点上重新分配了。所以 Node 19 把本地的数据进行删除,然后重新开始恢复集群的其他分片(然后这又导致了一个新的再平衡)
如果这一切听起来是不必要的且开销极大,那就对了。是的,不过前提是你知道这个节点会很快回来。如果节点 Node 19 真的丢了,上面的流程确实正是我们想要发生的。
这个默认的延迟分配分片的实际是1分钟, 当然你可以设置这个时间
curl -XPUT 'localhost:9200/<INDEX_NAME>/_settings' -d '
{"settings": {"index.unassigned.node_left.delayed_timeout": "30s"}
}'
4.3、nodes 数小于分片副本数
当一个nodes 被下掉之后, master 节点会重新 reassigns 这台nodes上的所有分片, 尽可能的把同一个分片的不同副本分片和主分片分配到不同的node上,但是如果你设置的一个分片的 副本数目太多, 导致根本没法一个 node上分配一个,就会出现问题, 会导致 es 没法进行 reassign, 这样就会出现 unassigned 的分片。
从一开始创建index 的时候就要保证N >= R + 1这里 N 代表 node的个数, R代表你index 的副本数目。
这种情况要么增加 nodes 个数要么减少副本数
curl -XPUT 'localhost:9200/<INDEX_NAME>/_settings' -d '{"number_of_replicas": 2}'
我们上个例子中,就把 副本数目减少到 2个, 问题解决。
注释:目前我就是属于单节点,但没办法调整分片数与节点数关系达到平衡,所以我这里直接删了索引
4.4检查是否开启 cluster.routing.allocation.enable 参数
Shard allocation 功能默认都是开启的, 但是如果你在某个时刻关闭了,这个功能(比如滚动重启的情形, https://www.elastic.co/guide/en/elasticsearch/guide/current/_rolling_restarts.html ), 后面忘了开启了,也会导致问题, 你可以使用下面这个命令开开启下
curl -XPUT 'localhost:9200/_cluster/settings' -d
'{ "transient":{ "cluster.routing.allocation.enable" : "all" }
}'
恢复之后, 你可以从监控上,看到 unassigned shards 逐渐恢复
看监控中,几个index都恢复了,好像还有constant-updates这个index 没有好,我们看下是否还有其他原因
分片的历史数据丢失了
我们现在的问题是这样, constant-updates 这个index 的第 0个分片处于 unassigned 状态, 创建这个index 的时候 每个分片只有 一个 主分片,没有其他副本, 数据没有副本, 集群检测到这个分片的 全局状态文件,但是没有找到原始数据, 就没法进行恢复。
还有一种可能是这样, 当一个node 重启的时候, 会重新连接集群, 然后把自己的 disk 文件信息汇报上去, 这时候进行恢复,如果这个过程出现了问题,比如存储坏掉了,那么当前分片还是没法恢复正常。
这个时候,你可以考虑下,是继续等待原来的那台机器恢复然后加入集群,还是重新强制分配 这些 unassigned 的分片, 重新分配的时候也可以使用备份数据。
如果你打算重新强制分配主分片,可以使用下面的命令 , 记得带上"allow_primary": “true”
curl -XPOST 'localhost:9200/_cluster/reroute' -d '{ "commands" :[ { "allocate" : { "index" : "constant-updates", "shard" : 0, "node": "<NODE_NAME>", "allow_primary": "true" }}]
}'
如果你没有带上"allow_primary": “true”, 就会报错
{"error":{"root_cause":[{"type":"remote_transport_exception","reason":"[NODE_NAME][127.0.0.1:9301][cluster:admin/reroute]"}],
"type":"illegal_argument_exception","reason":"[allocate] trying to allocate a primary shard [constant-updates][0], which is disabled"},
"status":400}
因为没有当前分配的分片是没有主分片了。
当然你在重新强制分配主分片的时候,可以创建一个 empty 的主分片,也就是老数据我不要了, 这个时候,如果失联的 node 重新加入集群后, 就把自己降级了, 分片的数据也会使用 这个 empty 的主分片覆盖, 因为它已经变成过时的版本了。
POST _cluster/reroute
{"commands" : [ {"allocate_empty_primary" :{"index" : "constant-updates", "shard" : 0, "node" : "<NODE_NAME>", "accept_data_loss" : true}}]
}
这个命令就可以创建一个 empty 的主分片。
4.5、磁盘不够情况解决
4.5.1、先进行查询
curl -s 'localhost:9200/_cat/allocation?v'
4.5.2、如果磁盘空间比较有剩余可以调整low disk watermark的磁盘使用比例也是可以设置的
curl -XPUT 'localhost:9200/_cluster/settings' -d
'{"transient": { "cluster.routing.allocation.disk.watermark.low": "90%" }
}'
4.5.3、可通过扩容物理磁盘并更改es配置
可以修改配置文件opensearch.yml或elasticsearch.yml进行配置在新的磁盘用逗号隔开,重启es
path.data:/test/data1,/test/data2
4.6、es 的版本问题
还有一种极端情况, 就是你升级了某个node的版本, master node 会不认这个跟它版本不同的的node, 也不会在上面分配分片。
如果你手动强制往上面分配分片,会报错。
[NO(target node version [XXX] is older than source node version [XXX])]
大体就这几种情况,你可以根据自己的观察到的现象去判断。
总结
针对不同情况需要进行不同的处理,能不删数据尽量不删数据,如果有更好的解决方案,或者没有解决你的问题欢迎留言一起讨论
原文链接:
https://www.cnblogs.com/lvzhenjiang/p/14196973.html
https://blog.csdn.net/syc000666/article/details/94910375
相关文章:
Es中出现unassigned shards问题解决
1、一般后台会报primary shard is not active Timeout: … 出现这种问题表示该索引是只读了,没办法进行shard及存储操作,优先排除是系统存储盘满了 2、通过监控工具查看(cerebro) 发现该索引shard 1 损坏 也可以通过命令进行查看 GET _cluster/allo…...
RT-DERT:在实时目标检测上,DETRs打败了yolo
文章目录 摘要1、简介2. 相关研究2.1、实时目标检测器2.2、端到端目标检测器2.3、用于目标检测的多尺度特征 3、检测器的端到端速度3.1、 NMS分析3.2、端到端速度基准测试 4、实时DETR4.1、模型概述4.2、高效的混合编码器4.3、IoU-aware查询选择4.4、RT-DETR的缩放 5、实验5.1、…...

uniapp/H5富文本复制文本功能
代码实现: copy() {let replacedContent this.form.resTaskBaseInfoDetail.content;let text readHtml(replacedContent)// #ifdef H5let textarea document.createElement("textarea")textarea.value texttextarea.readOnly "readOnly"d…...

通付盾Web3专题 | 智能账户:数字时代基础单元
2008年10月31日,中本聪(Satoshi Nakamoto)在P2P foundation 网站发布比特币白皮书《比特币:一种点对点的电子现金系统》。转眼距比特币白皮书发布已过去15年。2009年1月比特币网络正式推出,当时每个比特币的价格仅为0.…...
java网上阅读网站系统eclipse定制开发mysql数据库BS模式java编程jdbc
一、源码特点 JSP 网上阅读网站系统是一套完善的web设计系统,对理解JSP java SSM框架 mvc编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为 TOMCAT7.0,eclipse开发,数据库为Mysql5.0&a…...

人工智能基础_机器学习007_高斯分布_概率计算_最小二乘法推导_得出损失函数---人工智能工作笔记0047
这个不分也是挺难的,但是之前有详细的,解释了,之前的文章中有, 那么这里会简单提一下,然后,继续向下学习 首先我们要知道高斯分布,也就是,正太分布, 这个可以预测x在多少的时候,概率最大 要知道在概率分布这个,高斯分布公式中,u代表平均值,然后西格玛代表标准差,知道了 这两个…...
开源播放器GSYVideoPlayer的简单介绍及播放rtsp流的优化
开源播放器GSYVideoPlayer的简单介绍及播放rtsp流的优化 前言一、GSYVideoPlayer🔥🔥🔥是什么?二、简单使用1.First、在project下的build.gradle添加2.按需导入3. 常用代码 rtsp流的优化大功告成 总结 前言 本文介绍,…...
安卓手机数据恢复工具 DiskDigger Pro 中文版-适用于已获得 root 权限的设备!可以从您的存储卡或内存恢复数据
可以从您的存储卡或内存中取消删除和恢复丢失的照片、文档、视频、音乐等。 无论您是不小心删除了文件,还是重新格式化了存储卡,DiskDigger 强大的数据恢复功能都可以找到您丢失的文件并让您恢复它们。 注意:如果您的设备未获得 root 权限&a…...
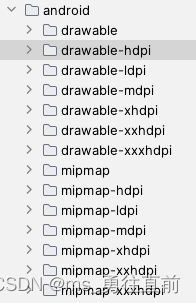
Python 生成Android不同尺寸的图标
源代码 # -*- coding: utf-8 -*- import sys import os import shutil from PIL import Imagedef generateAndroidIcons():imageSource icon.pngicon Image.open(imageSource)sizes [(android/drawable,512),(android/drawable-hdpi,72),(android/drawable-ldpi,36),(andro…...

PHP使用GuzzleHttp进行HTTP请求
1,composer安装 composer require guzzlehttp/guzzle:~7.0 2,设置过期时间和跳过ssl验证 use GuzzleHttp\Client;$clientnew Client([timeout > 5, verify > false]);2,get请求 use GuzzleHttp\Client;$clientnew Client([timeout > 5, verif…...

pytorch笔记:allclose,isclose,eq,equal
1 allclose 1.1介绍 torch.allclose是一个PyTorch函数,用于检查两个张量是否在某个容忍度范围内近似相等 torch.allclose(input, other, rtol1e-05, atol1e-08, equal_nanFalse)input (Tensor) – 第一个输入张量other (Tensor) – 第二个输入张量rtol (float) –…...

YoloV8修改检测框为中心点
代码实现参考: https://github.com/computervisioneng/train-yolov8-custom-dataset-step-by-step-guide/blob/master/local_env/predict_video.py from ultralytics import YOLO from PIL import Image import cv2 import numpy as npmodel YOLO("/home/ps…...
文言一心中将C语言归类为低级语言,这对么?
文言一心中将C语言归类为低级语言,这对么? 以下是文言一心中的回答:C语言属于低级语言。低级语言通常指的是接近于机器语言的编程语言,它们与计算机硬件的交互更加直接,能够更高效地利用计算机资源。最近很多小伙伴找我ÿ…...
[补题记录] Codeforces Round 906 (Div. 2)(A~D)
URL:https://codeforces.com/contest/1890 目录 A Problem/题意 Thought/思路 Code/代码 B Problem/题意 Thought/思路 Code/代码 C Problem/题意 Thought/思路 Code/代码 D Problem/题意 Thought/思路 Code/代码 A Problem/题意 给出一个数组 A…...

Kubernetes yaml文件
目录 yaml文件 Pod yaml文件详解 deployment.yaml文件详解 Service yaml文件详解 文件 Kubernetes 支持 YAML 和 JSON 格式管理资源对象 JSON 格式:主要用于 api 接口之间消息的传递 YAML 格式:用于配置和管理,YAML 是一种简洁的非标记性…...
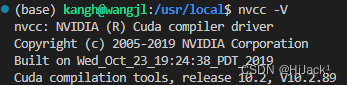
Linux——切换CUDA版本
一、查看本地cuda版本 cd /usr/local/ ls当前cuda为软连接,指向指定的cuda版本 stat cuda # 查看当前cuda状态信息二、切换CUDA版本 # 删除原有软连接 sudo rm -rf /usr/local/cuda # 建立需要切换的cuda软连接版本 sudo ln -s /usr/local/cuda-**.* /usr/l…...

利用云计算和微服务架构开发可扩展的同城外卖APP
如今,同城外卖APP已经成为了人们点餐的主要方式之一。然而,要构建一款成功的同城外卖APP,不仅需要满足用户的需求,还需要具备可扩展性,以适应快速增长的用户和订单量。 一、了解同城外卖APP的需求 在着手开发同城外卖…...
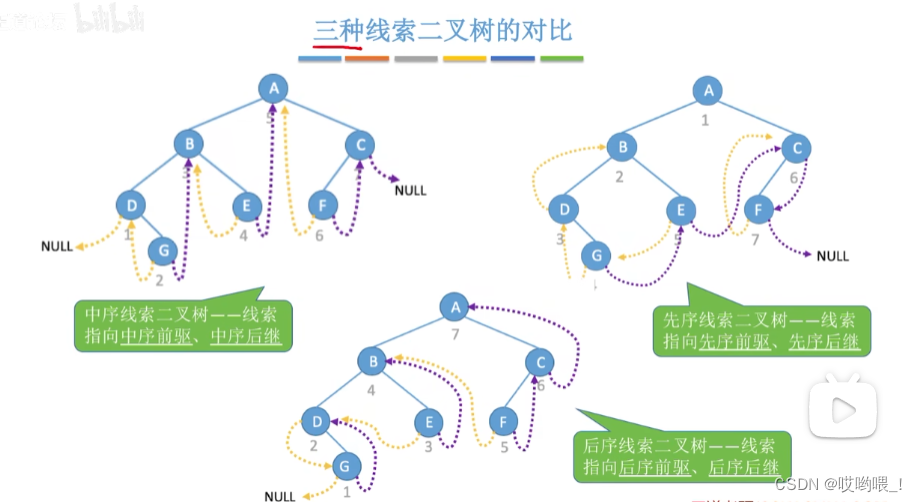
数据结构详细笔记——二叉树
文章目录 二叉树的定义和基本术语特殊的二叉树满二叉树完全二叉树二叉排序树平衡二叉树 二叉树的常考性质完全二叉树的常考性质二叉树的存储结构顺序存储链式存储 二叉树的先中后序遍历先序遍历(空间复杂度:O(h))中序遍…...
react实现列表增删改查的小demo(class组件版)
前言 react的语法上就是比vue麻烦不少,既然要开手动挡,那就开吧,一个基础的demo 效果图 列表 新增弹窗 编辑弹框 新增一条数据后的效果 代码 根组件 index.jsx import React, { Component,createRef} from react import withRouter from ../../utils/withRouter import G…...
运行批处理文件,Windows 10至少提供了三种方法,有的可以设置定时运行
Windows 10至少有三种写入批处理文件的方法。你可以使用命令提示符或文件资源管理器按需运行它们。你可以使用任务计划程序配置脚本,以便按计划运行。或者,你可以将批处理文件保存在“启动”文件夹中,让系统在你登录帐户后立即运行它们。 如果要按需运行脚本,可以使用文件…...

3步高效启用Windows Insider预览计划:免登录离线方案终极指南
3步高效启用Windows Insider预览计划:免登录离线方案终极指南 【免费下载链接】offlineinsiderenroll OfflineInsiderEnroll - A script to enable access to the Windows Insider Program on machines not signed in with Microsoft Account 项目地址: https://g…...

你的EEPROM数据丢了吗?基于STM32和AT24CXX的I2C通信稳定性实战调优指南
EEPROM数据可靠性实战:STM32与AT24CXX的I2C通信深度优化 在工业控制、医疗设备和消费电子等领域,EEPROM作为非易失性存储器承担着关键参数存储的重任。但当系统突然断电或遭遇电磁干扰时,工程师们常会遇到数据丢失、校验失败等棘手问题。本文…...

如何实现IT资产管理系统的全面智能化提升?
如何利用物联网提升IT资产管理效率 物联网的应用为IT资产管理带来了颠覆性的变化。借助设备间的互联互通,企业能够取得实时数据,进而进行更为精准的决策。利用在每项设备上安装传感器,企业可实时追踪资产的使用情况与状态。这种系统利用数据采…...

微软Windows拆分:云AI战略转型下的业务重构与行业影响
1. 从“巨无霸”到“手术台”:微软拆分的深层逻辑与行业变局最近几年,关于微软可能进行业务拆分的讨论,就像科技行业的“月经帖”,每隔一段时间就会冒出来。但这一次,市场的风声似乎比以往任何时候都要紧。从“拆分Win…...

在电脑上免费畅玩Switch游戏:Ryujinx模拟器终极完整指南
在电脑上免费畅玩Switch游戏:Ryujinx模拟器终极完整指南 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx 你是否曾梦想在电脑上体验《塞尔达传说:王国之泪》的壮…...

毕业答辩PPT救星:百考通AI如何用30分钟搞定高质量学术汇报
又到一年毕业季,相信不少同学在论文定稿后,突然发现自己卡在了最后一关——毕业答辩PPT的制作上。这份看似简单的PPT,却是评审老师对你研究成果形成第一印象的关键载体,甚至直接影响答辩的通过率。 然而现实是,许多同…...

从零到精通:3分钟掌握gdown,让Google Drive下载不再是噩梦
从零到精通:3分钟掌握gdown,让Google Drive下载不再是噩梦 【免费下载链接】gdown Google Drive public file downloader when curl/wget fails. 项目地址: https://gitcode.com/gh_mirrors/gd/gdown 还在为Google Drive大文件下载失败而烦恼吗&a…...
)
用正点原子Nano开发板,5分钟搞定RT-Thread Nano的MDK5工程配置(附串口调试技巧)
正点原子Nano开发板极速上手RT-Thread实战指南 1. 开箱即用的开发环境搭建 刚拿到正点原子Nano开发板时,最令人兴奋的莫过于快速验证硬件是否正常工作。这款基于STM32F103RBT6的开发板,以其72MHz主频和丰富的外设资源,成为嵌入式入门学习的…...

LLM 本地部署框架 vLLM 和 LMDeploy
1. 安装vLLM的环境 1.1 安装要求 1. vLLM 包含预编译的 C 和 CUDA (12.8) 二进制文件。 2. 要求: 操作系统: LinuxPython: 3.9 -- 3.12 # (实测:推荐安装3.10以上版本)GPU: 计算能力 7.0 或更高 (例如, V100, T4, RTX20xx, A100, L4, H100 等…...

Proteus 8.17安装超详细教程 保姆级教程【附安装包】
电子设计小伙伴们!今天我给大家带来一篇超详细的Proteus 8.17专业版安装教程 !这可是电子工程师和学生党的福音啊!作为PCB设计和单片机仿真的神器,Proteus绝对是你玩转电子设计必备的利器!不会安装?别担心&…...