【MySQL索引与优化篇】数据库调优策略
数据库调优策略
文章目录
- 数据库调优策略
- 1. 数据库调优的措施
- 1.1 调优目标
- 1.2 如何定位调优问题
- 1.3 调优的维度和步骤
- 第1步:选择合适的DBMS
- 第2步:优化表设计
- 第3步:优化逻辑查询
- 第4步:优化物理查询
- 第5步:使用 Redis 或 Memcached 作为缓存
- 第6步:库级优化
- 2. 优化MySQL服务器
- 2.1 优化服务器硬件
- 2.2 优化MySQL的参数
- 3. 优化数据库结构
- 3.1 拆分表:冷热数据分离
- 3.2 中间表
- 3.3 增加冗余字段
- 3.4 优化数据类型
- 3.5 优化插入记录的速度
- 3.6 使用非空约束
- 3.7 分析表、检查表与优化表
- 1. 分析表
- 2. 检查表
- 3. 优化表
- 3.8 小结
- 4. 大表优化
- 5. 其它调优策略
- 5.1 服务器语句超时处理
- 5.2 创建全局通用表空间
1. 数据库调优的措施
1.1 调优目标
- 尽可能
节省系统资源,以便系统可以提供更大负荷的服务。(吞吐量更大) - 合理的结构设计和参数调整,以提高用户操作
响应的速度。(响应速度更快) - 减少系统的瓶颈,提高MySQL数据库整体的性能
1.2 如何定位调优问题
- 用户的反馈 (主要)
- 日志分析 (主要)
- 服务器资源使用监控
- 数据库内部状况监控,
活动会话(Active Session)监控是一个重要的指标。通过它,可以了解数据库当前是否处于非常繁忙的状态,是否存在 SQL 堆积等 - 其它,除了活动会话监控以外,我们也可以对
事务、锁等待等进行监控,这些都可以帮助我们对数据库的运行状态有更全面的认识。
1.3 调优的维度和步骤
第1步:选择合适的DBMS
如果对 事务性处理 以及 安全性要求高 的话,可以选择商业的数据库产品。这些数据库在事务处理和查询性能上都比较强,比如采用 SQL Server、Oracle,那么 单表存储上亿条据 是没有问题的。如果数据表设计得好,即使不采用 分库分表 的方式,查询效率也不差
除此以外,还可以采用开源的 MySQL 进行存储,它有很多存储引擎可以选择,如果进行事务处理的话可以选择 InnoDB,非事务处理可以选择 MyISAM。
NOSQL 阵营包括 键值型数据库、 文档型数据库、搜索引擎、列式存储和 图形数据库。这些数据库的优缺点和使用场景各有不同,比如列式存储数据库可以大幅度降低系统的 I/O,适合于分布式文件系统,但如果数据需要频繁地增删改,那么列式存储就不太适用了。
第2步:优化表设计
选择了 DBMS 之后,我们就需要进行表设计了。数据表的设计方式也直接影响了后续的 SQL 查询语句。如果用的是 MySQL,可以根据不同表的使用需求,选择不同的存储引擎。除此以外,还有一些优化的原则可以参考:
- 表结构要尽量
遵循三范式的原则 - 如果
查询应用比较多,尤其是需要进行多表联查的时候,可以采用反范式进行优化 表字段的数据类型选择,一般来说,如果字段可以采用数值类型就不要采用字符类型;字符长度要尽可能设计得短一些,字符型固定长度用char
第3步:优化逻辑查询
SQL 查询优化,可以分为 逻辑查询优化 和 物理查询优化。逻辑查询优化就是通过改变 SQL 语句的内容让 SQL 执行效率更高效,采用的方式是对 SQL 语句进行等价变换,对查询进行重写。SQL 的查询重写包括了子查询优化、等价谓词重写、视图重写、条件简化、连接消除和嵌套连接消除等
比如在 EXISTS 子查询和 IN 子查询的时候,会根据 小表驱动大表 的原则选择适合的子查询。
第4步:优化物理查询
物理查询优化是在确定了逻辑查询优化之后,采用物理优化技术(比如索引等),通过计算代价模型对各种可能的访问路径进行估算,从而找到执行方式中代价最小的作为执行计划。在这个部分中,需要掌握的重点是对索引的创建和使用,在前几篇文章中已经进行了细致的剖析。
第5步:使用 Redis 或 Memcached 作为缓存
通常我们对于常用的数据以及查询响应要求高的场景(响应时间短,吞吐量大) ,可以考虑内存数据库,毕竟术业有专攻。
第6步:库级优化
库级优化是站在数据库的维度上进行的优化策略,比如控制一个库中的数据表数量。另外,单一的数据库总会遇到各种限制,不如取长补短,利用"外援"的方式。通过 主从架构 优化我们的读写策略,通过对数据库进行垂直或者水平切分,突破单一数据库或数据表的访问限制,提升查询的性能。
- 读写分离,主从架构,读写分离
- 数据分片,分库分表
2. 优化MySQL服务器
优化MySQL服务器主要从两个方面来优化,一方面是对 硬件 进行优化;另一方面是对MySQL 服务的参数 进行优化。这部分的内容需要较全面的知识,一般只有 专业的数据库管理员 才能进行这一类的优化。对于可以定制参数的操作系统,也可以针对MySQL进行操作系统优化
2.1 优化服务器硬件
服务器的硬件性能直接决定着MySQL数据库的性能。
- 配置较大的内存
- 配置高速磁盘系统
- 合理分布磁盘I/O,把磁盘I/O分散在多个设备上,以减少资源竞争,提高并行操作能力
- 配置多处理器,MySQL是多线程的数据库,多处理器可同时执行多个线程
2.2 优化MySQL的参数
MySQL服务的配置参数都在 my.cnf 或者 my.ini 文件的[mysqld]组中。配置完参数以后,,需要重新启动MySQL服务才会生效,下面对几个对性能影响比较大的参数进行详细介绍:
-
innodb_buffer_pool_size:表示lnnoDB类型的表和索引的最大缓存,默认128MB。它不仅仅缓存
索引数据,还会缓存表的数据。这个值越大,查询的速度就会越快。但是这个值太大会影响操作系统的性能。 -
key_buffer_size:表示索引缓冲区的大小。索引缓冲区是所有的
线程共享。它的大小取决于内存的大小。如果这个值大大,就会导致操作系统频繁换页,也会降低系统性能。对于内存在4GB左右的服务器该参数可设置为256M或384M。 -
table_cache:表示
同时打开的表的个数。这个值越大,能够同时打开的表的个数越多。物理内存越大,设置就越大。默认为2402,调到512-1024最佳。这个值不是越大越好,因为同时打开的表太多会影响操作系统的性能。 -
sort_buffer_size:表示
每个需要进行排序的线程分配的缓冲区的大小。增加这个参数的值可以提高 ORDER BY 或 GROUP BY 操作的速度。默认数值是2 097 144字节(约2MB)。对于内存在4GB左右的服务器推荐设置为6-8M,如果有100个连接,那么实际分配的总共排序缓冲区大小为100 * 6 = 600MB。 -
join_buffer_size:表示联合查询所能使用的缓冲区大小,默认8M,和sort_buffer_size一样,该参数对应的分配内存也是每个连接独享
-
read_buffer_size:表示
每个线程连续扫描时为扫描的每个表分配的缓冲区的大小(字节)。当线程从表中连续读取记录时需要用到这个缓冲区。SET SESSION read_buffer_size可以临时设置该参数的值。默认为64K,可以设置为4M。 -
innodb_flush_log_at_trx_commit:表示
何时将缓冲区的数据写入日志文件,并目将日志文件写入磁盘中。该参数对于innoDB引擎非常重要。默认1- 值为0时,表示
每秒1次的频率将数据写入日志文件并将志文件写入磁盘。每个事务的commit并不会触发前面的任何操作。该模式速度最快,但不太安全,mysqld进程的崩溃会导致上一秒钟所有事务数据的丢失 - 值为1时,表示
每次提交事务时将数据写入日志文件并将日志文件写入磁盘进行同步。该模式是最安全的,但也是最慢的一种方式。因为每次事务提交或事务外的指令都需要把日志写入 (flush) 硬盘 - 值为2 时,表示
每次提交事务时将数据写入日志文件,每隔1秒将日志文件写入磁盘。该模式速度较快也比0安全,只有在操作系统崩溃或者系统断电的情况下,上一秒钟所有事务数据才可能丢失
- 值为0时,表示
-
innodb_log_buffer_size :这是 InnoDB 存储引擎的 事务日志所使用的缓冲区 。为了提高性能,也是先将信息写入 Innodb Log Buffer 中,当满足 innodb_flush_log_trx_commit 参数所设置的相应条件(或者日志缓冲区写满)之后,才会将日志写到文件(或者同步到磁盘)中。
-
max_connections :表示
允许连接到MySQL数据库的最大数量,默认值是 151 。如果状态变量connection_errors_max_connections 不为零,并且一直增长,则说明不断有连接请求因数据库连接数已达到允许最大值而失败,这是可以考虑增大max_connections 的值。在Linux 平台下,性能好的服务器,支持 500-1000 个连接不是难事,需要根据服务器性能进行评估设定。这个连接数不是越大越好,因为这些连接会浪费内存的资源。过多的连接可能会导致MySQL服务器僵死。 -
back_log :用于
控制MySQL监听TCP端口时设置的积压请求栈大小。如果MySql的连接数达到max_connections时,新来的请求将会被存在堆栈中,以等待某一连接释放资源,该堆栈的数量即back_log,如果等待连接的数量超过back_log,将不被授予连接资源,将会报错。5.6.6 版本之前默认值为 50 , 之后的版本默认为 50 + (max_connections / 5), 对于Linux系统推荐设置为小于512的整数,但最大不超过900。如果需要数据库在较短的时间内处理大量连接请求, 可以考虑适当增大back_log 的值。
-
thread_cache_size : 线程池缓存线程数量的大小 ,当客户端断开连接后将当前线程缓存起来,当在接到新的连接请求时快速响应无需创建新的线程 。这尤其对那些使用短连接的应用程序来说可以极大的提高创建连接的效率。那么为了提高性能可以增大该参数的值。默认为60,可以设置为120。
可以通过如下几个MySQL状态值来适当调整线程池的大小:
mysql> show global status like 'Thread%'; +-------------------+-------+ | Variable_name | Value | +-------------------+-------+ | Threads_cached | 2 | | Threads_connected | 1 | | Threads_created | 3 | | Threads_running | 2 | +-------------------+-------+ 4 rows in set (0.01 sec)当 Threads_cached 越来越少,但 Threads_connected 始终不降,且 Threads_created 持续升高,可适当增加 thread_cache_size 的大小。
-
wait_timeout:指定 一个请求的最大连接时间 ,默认28800,对于4GB左右内存的服务器可以设置为5-10。
-
interactive_timeout:表示服务器在关闭连接前等待行动的秒数
-
innodb_buffer_pool_instances:默认为1,这个参数可以将lnnoDB 的缓存区分成几个部分,这样可以提高系统的
并行处理能力,因为可以允许多个进程同时处理不同部分的缓存区。
这里给出一份my.cnf的参考配置,注意只是参考配置,实际情况还需具体情况具体分析:
[mysqld]
port = 3306
serverid = 1
socket = /tmp/mysql.sock skip-locking #避免MySQL的外部锁定,减少出错几率增强稳定性。
skip-name-resolve #禁止MySQL对外部连接进行DNS解析,使用这一选项可以消除MySQL进行DNS解析的时间。但需要注意,如果开启该选项,则所有远程主机连接授权都要使用IP地址方式,否则MySQL将无法正常处理连接请求!
back_log = 384
key_buffer_size = 256M
max_allowed_packet = 4M
thread_stack = 256K
table_cache = 128K
sort_buffer_size = 6M
read_buffer_size = 4M
read_rnd_buffer_size=16M
join_buffer_size = 8M
myisam_sort_buffer_size =64M
table_cache = 512
thread_cache_size = 64
query_cache_size = 64M
tmp_table_size = 256M
max_connections = 768
max_connect_errors = 10000000
wait_timeout = 10
thread_concurrency = 8 #该参数取值为服务器逻辑CPU数量*2,在本例中,服务器有2颗物理CPU,而每颗物理CPU又支持H.T超线程,所以实际取值为4*2=8
skipnetworking #开启该选项可以彻底关闭MySQL的TCP/IP连接方式,如果WEB服务器是以远程连接的方式访问MySQL数据库服务器则不要开启该选项!否则将无法正常连接! table_cache=1024
innodb_additional_mem_pool_size=4M #默认为2M
innodb_flush_log_at_trx_commit=1
innodb_log_buffer_size=2M #默认为1M
innodb_thread_concurrency=8 #你的服务器CPU有几个就设置为几。建议用默认一般为8
tmp_table_size=64M #默认为16M,调到64-256最挂
thread_cache_size=120
query_cache_size=32M
3. 优化数据库结构
一个好的 数据库设计方案 对于数据库的性能常常会起到 事半功倍 的效果。合理的数据库结构不仅可以使数据库占用更小的磁盘空间,而且能够使查询速度更快。数据库结构的设计需要考虑 数据冗余、 查询和更新的速度、字段的数据类型 是否合理等多方面的内容
3.1 拆分表:冷热数据分离
拆分表的思路是,把 1个包含很多字段的表拆分成 2个或者多个相对较小的表。原因是,这些表中某些字段的操作频率很高(热数据),经常要进行查询或者更新操作,而另外一些字段的使用频率却很低(冷数据),冷热数据分离,可以减小表的宽度。如果放在一个表里面,每次查询都要读取大记录,会消耗较多的资源
MySQL限制每个表最多存储 4096 列,并且每一行数据的大小不能超过 65535 字节。表越宽,把表装载进内存缓冲池时所占用的内存也就越大,也会消耗更多的IO。 冷热数据分离的目的 是:
- 减少磁盘IO,保证热数据的内存缓存命中率
- 更有效的利用缓存,避免读入无用的冷数据
3.2 中间表
对于需要经常联合查询的表,可以建立中间表以提高查询效率。通过建立中间表把需要经常联合查询的数据插入中间表中,然后将原来的联合查询改为对中间表的查询,以此来提高查询效率。该方式仅限于不经常变化的数据使用,因为很容易导致数据不一致的问题
注意:如果其中表信息有修改,可能会导致 数据不一致 的问题,可通过以下方式进行数据同步
方式1:清空数据->重新添加数据
3.3 增加冗余字段
参考前面文章反范式化
3.4 优化数据类型
优先选择符合存储需要的最小的数据类型
-
情况一:整形数据类型优化
- 在不清楚使用哪种整形类型的情况下,考虑使用
int; - 对于非负型数据,考虑使用
unsigend
- 在不清楚使用哪种整形类型的情况下,考虑使用
-
情况二:既可以使用文本类型,又可以使用整形类型的字段,优先选择使用整形类型
-
情况三:避免使用TEXT、BLOB数据类型
-
MysQL
内存临时表不支持TEXT、BLOB这样的大数据类型,如果查询中包含这样的数据,在排序等操作时,就不能使用内存临时表,必须使用磁盘临时表进行。并且对于这种数据,MySQL还是要进行 二次查询,会使SQL性能变得很差,但不是说一定不能使用这样的数据类型如果一定要使用,建议把BLOB或是TEXT列
分离到单独的扩展表中,查询时一定不要使用select*,而只需要取出必要的列,不需要TEXT列的数据时不要对该列进行查询
-
-
情况四:避免使用ENUM类型,可以使用tinyint代替
总之,遇到数据量大的项目,一定要在充分了解业务需求的前提下,合理优化数据类型,这样才能充分发挥资源的效率,使系统达到最优
3.5 优化插入记录的速度
该案例主要针对大数据量插入,分两个不同存储引擎分析
首先,对于使用MyISAM引擎的表
- 禁用索引,插入前禁用索引,数据插入完毕再开启索引
- 禁用唯一性检查,插入前禁用唯一性检查,数据插入完毕再开启唯一性检查
- 使用批量插入
- 使用 load data infile 批量插入
其次,对于使用InnoDB引擎的表
- 禁用唯一性检查
- 禁用外键检查
- 禁止自动提交
3.6 使用非空约束
- 进行比较和计算时,省去对NULL值的字段判断是否为空的开销,提高存储效率
- 节省存储空间,对应索引列不需要NULL列(每个字段一个bit)
3.7 分析表、检查表与优化表
分析表 主要是分析关键字的分布,检查表 主要是检查表是否存在错误,优化表 主要是消除删除或者更新造成的空间浪费。
1. 分析表
MySQL中提供了ANALYZE TABLE语句分析表,ANALYZE TABLE语句的基本语法如下:
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name[,tbl_name]…
默认的,MySQL服务会将 ANALYZE TABLE语句写到binlog中,以便在主从架构中,从服务能够同步数据。可以添加参数LOCAL 或者 NO_WRITE_TO_BINLOG取消将语句写到binlog中。
使用 ANALYZE TABLE 分析表的过程中,数据库系统会自动对表加一个 只读锁 。在分析期间,只能读取表中的记录,不能更新和插入记录。ANALYZE TABLE语句能够分析InnoDB和MyISAM类型的表。
ANALYZE TABLE分析后的统计结果会反应到 cardinality 的值,该值统计了表中某一键所在的列不重复的值的个数。该值越接近表中的总行数,则在表连接查询或者索引查询时,就越优先被优化器选择使用。也就是索引列的cardinality的值与表中数据的总条数差距越大,即使查询的时候使用了该索引作为查询条件,存储引擎实际查询的时候使用的概率就越小。cardinality可以通过 SHOW INDEX FROM 表名查看
2. 检查表
了解即可,该部分内容也可跳过,有时候表会因为一些原因损坏,但一般不会。MySQL中可以使用 CHECK TABLE 语句来检查表。CHECK TABLE语句能够检查InnoDB和MyISAM类型的表是否存在错误。CHECK TABLE语句在执行过程中也会给表加上 只读锁 。
对于MyISAM类型的表,CHECK TABLE语句还会更新关键字统计数据。而且,CHECK TABLE也可以检查视图是否有错误,比如在视图定义中被引用的表已不存在。该语句的基本语法如下:
CHECK TABLE tbl_name [, tbl_name] ... [option] ...
option = {QUICK | FAST | MEDIUM | EXTENDED | CHANGED}
option只对MyISAM类型的表有效,对InnoDB类型的表无效,不想研究可跳过下面部分内容。
其中,tbl_name是表名;option参数有5个取值,分别是QUICK、FAST、MEDIUM、EXTENDED和CHANGED。各个选项的意义分别是:
- QUICK :不扫描行,不检查错误的连接。
- FAST :只检查没有被正确关闭的表。
- CHANGED :只检查上次检查后被更改的表和没有被正确关闭的表。
- MEDIUM :扫描行,以验证被删除的连接是有效的。也可以计算各行的关键字校验和,并使用计算出的校验和验证这一点。
- EXTENDED :对每行的所有关键字进行一个全面的关键字查找。这可以确保表是100%一致的,但是花的时间较长。
该语句对于检查的表可能会产生多行信息。最后一行有一个状态的 Msg_type 值,Msg_text 通常为 OK。如果得到的不是 OK,通常要对其进行修复;是 OK 说明表已经是最新的了。表已经是最新的,意味着存储引擎对这张表不必进行检查。
3. 优化表
MySQL中使用 OPTIMIZE TABLE 语句来优化表。但是,OPTILMIZE TABLE语句只能优化表中的 VARCHAR 、 BLOB 或 TEXT 类型的字段。一个表使用了这些字段的数据类型,若已经 删除 了表的一大部分数据,或者已经对含有可变长度行的表(含有VARCHAR、BLOB或TEXT列的表)进行了很多 更新 ,则应使用OPTIMIZE TABLE来重新利用未使用的空间,并整理数据文件的 碎片 。
OPTIMIZE TABLE 语句对InnoDB和MyISAM类型的表都有效。该语句在执行过程中也会给表加上 只读锁。
OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
在MyISAM中,是先分析这张表,然后会整理相关的MySQL datafile,之后回收未使用的空间;在InnoDB中,回收空间是简单通过Alter table进行整理空间。在优化期间,MySQL会创建一个临时表,优化完成之后会删除原始表,然后会将临时表rename成为原始表。
说明: 在多数的设置中,根本不需要运行OPTIMIZE TABLE。即使对可变长度的行进行了大量的更新,也不需要经常运行, 每周一次 或 每月一次 即可,并且只需要对 特定的表 运行。
3.8 小结
上述这些方法都是有利有弊的。比如:
- 修改数据类型,节省存储空间的同时,要考虑到数据不能超过取值范围;
- 增加冗余字段的时候,不要忘了确保数据一致性;
- 把大表拆分,也意味着你的查询会增加新的连接,从而增加额外的开销和运维的成本
因此,一定要结合实际的业务需求进行权衡。
4. 大表优化
当MySQL单表记录数过大时,数据库的CURD性能会明显下降,一些常见的优化措施如下:
- 限定查询的范围
- 读/写分离
- 垂直拆分,当数据量级达到
千万级以上时,有时候我们需要把一个数据库切成多份,放到不同的数据库服务器上,减少对单一数据库服务器的访问压力- 如果数据库中的数据表过多,可以采取
垂直分库的方式,将关联的数据表部署在同一个数据库上 - 如果数据表中的列过多,可以采用
垂直分表的方式,将一张数据表拆分成多张数据表,把经常一起使用的列放到同一张表里 - 垂直拆分的优点: 可以使得列数据变小,在查询时减少读取的Block数,减少I/O次数。此外,垂直分区可以简化表的结构,易于维护
- 垂直拆分的缺点: 主键会出现冗余,需要管理冗余列,并会引起 JOIN 操作。此外,垂直拆分会让事务变得更加复杂
- 如果数据库中的数据表过多,可以采取
- 水平拆分,尽量控制单表数据量的大小在
1000万以内- 1000万并不是MySQL数据库的限制,过大会造成修改表结构、备份、恢复都会有很大的问题。此时可以用
历史数据归档(应用与日志数据),水平分表(应用于业务数据)等手段来控制数据量大小 - 这里我们主要考虑业务数据的水平分表策略。将大的数据表按照
某个属性维度分成不同的小表每张小表保持相同的表结构。比如可以按照年份来划分,把不同年份的数据放到不同的数据表中。2017 年、2018 年和 2019 年的数据就可以分别放到三张数据表中 - 水平分表仅是解决了单一表数据过大的问题,但由于表的数据还是在同一台机器上,其实对于提升MySQL并发能力没有什么意义,所以
水平拆分最好分库,从而达到分布式的目的
- 1000万并不是MySQL数据库的限制,过大会造成修改表结构、备份、恢复都会有很大的问题。此时可以用
下面补充一下数据库分片的两种常见方案:
- 客户端代理: 分片逻辑在应用端,封装在jar包中,通过修改或者封装JDBC层来实现。 当当网的Sharding-JDBC 、阿里的TDDL是两种比较常用的实现。
- 中间件代理: 在应用和数据中间加了一个代理层。分片逻辑统一维护在中间件服务中。Mycat 、360的Atlas、网易的DDB等等都是这种架构的实现。
5. 其它调优策略
5.1 服务器语句超时处理
在MySQL 8.0中可以设置 服务器语句超时的限制 ,单位可以达到 毫秒级别 。当中断的执行语句超过设置的毫秒数后,服务器将终止查询影响不大的事务或连接,然后将错误报给客户端。
设置服务器语句超时的限制,可以通过设置变量 MAX_EXECUTION_TIME 来实现。默认情况下,MAX_EXECUTION_TIME的值为0,代表没有时间限制。
5.2 创建全局通用表空间
MySQL 8.0使用 CREATE TABLESPACE 语句来创建一个 全局通用表空间。全局表空间可以被所有的数据库的表共享,而且相比于独享表空间,使用手动创建共享表空间可以节约元数据方面的内存。可以在创建表的时候,指定属于哪个表空间,也可以对已有表进行表空间修改等
下面创建名为 a 的共享表空间,SQL语句如下:
CREATE TABLESPACE a ADD datafile 'a.ibd' file_block_size=16k;
指定表空间,SQL语句如下:
CREATE TABLE test(id int,name varchar(10)) engine=innodb default charset utf8mb4 tablespace a;
相关文章:

【MySQL索引与优化篇】数据库调优策略
数据库调优策略 文章目录 数据库调优策略1. 数据库调优的措施1.1 调优目标1.2 如何定位调优问题1.3 调优的维度和步骤第1步:选择合适的DBMS第2步:优化表设计第3步:优化逻辑查询第4步:优化物理查询第5步:使用 Redis 或 …...

基于BP神经网络的风险等级预测,BP神经网络的详细原理,
目录 背影 BP神经网络的原理 BP神经网络的定义 BP神经网络的基本结构 BP神经网络的神经元 BP神经网络的激活函数, BP神经网络的传递函数 代码链接:基于BP神经网络的风险等级评价,基于BP神经网络的风险等级预测(代码完整,数据齐全)资源-CSDN文库 https://download.csdn.n…...
最新Ai智能创作系统源码V3.0,AI绘画系统/支持GPT联网提问/支持Prompt应用+搭建部署教程
一、AI创作系统 SparkAi创作系统是基于OpenAI很火的ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如…...
项目资源不足,常见的5种处理方式
软件开发中,经常会遇到项目资源不足的情况,项目团队如果无法及时获得所需的人力、财力、物力等资源,往往会影响团队士气以及任务质量,造成无法按时完成任务,进而影响项目进度。 因此及时处理和应对资源不足的情况&…...
ER图设计神器,帮你省时省力,高效完成工作!
ER图(Entity-Relationship Diagram)工具用于设计数据库模型,通常用于表示数据实体、关系和属性之间的关系。以下是10个好用的ER图工具。 一、Lucidchart Lucidchart 是一款基于云的协作式图表设计工具,它允许用户创建、编辑和共享…...
Notepad++下载、使用
下载 https://notepad-plus-plus.org/downloads/ 安装 双击安装 选择安装路径 使用 在文件夹中搜索 文件类型可以根据需要设置 如 *.* 说明是所有文件类型; *.tar 说明是所有文件后缀是是tar的文件‘;...
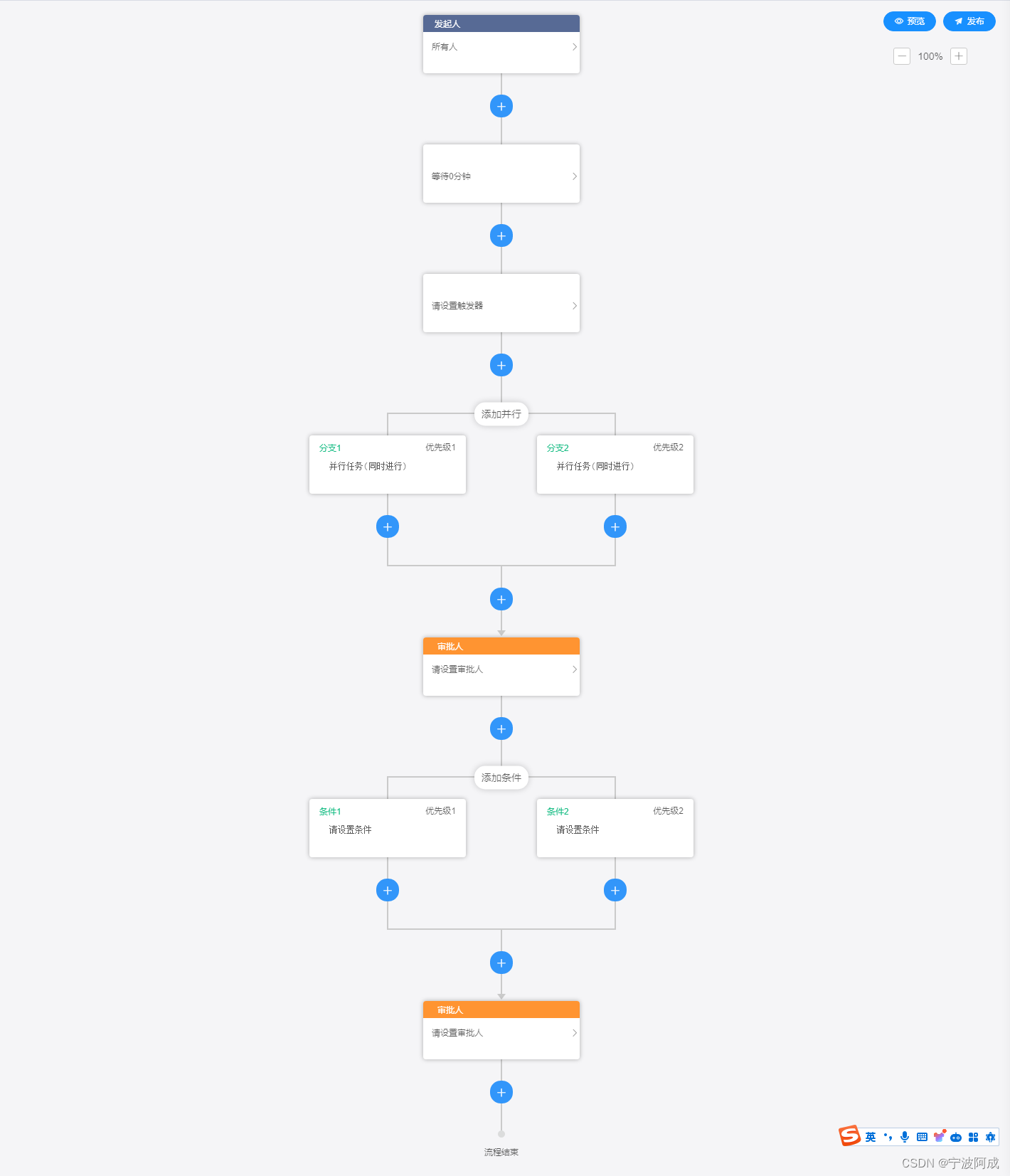
基于若依的ruoyi-nbcio流程管理系统增加仿钉钉流程设计(一)
更多ruoyi-nbcio功能请看演示系统 gitee源代码地址 前后端代码: https://gitee.com/nbacheng/ruoyi-nbcio 演示地址:RuoYi-Nbcio后台管理系统 仿钉钉的开源项目网上也不少,而且很多功能已经也比较完善了,但大部分都不是MIT协议…...

【知网检索征稿】第九届社会科学与经济发展国际学术会议 (ICSSED 2024)
第九届社会科学与经济发展国际学术会议 (ICSSED 2024) 2024 9th International Conference on Social Sciences and Economic Development 第九届社会科学与经济发展国际学术会议(ICSSED 2024)定于2024年3月22-24日在中国北京隆重举行。会议主要围绕社会科学与经济发展等研究…...
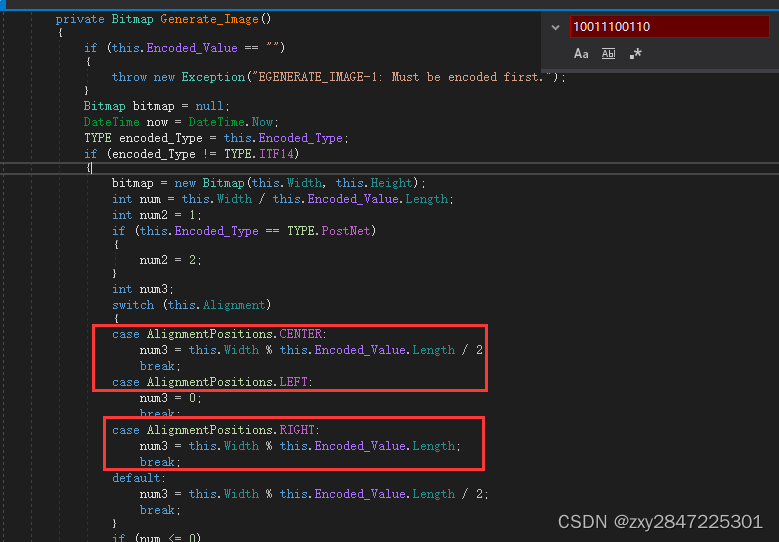
带你人工识别C#开源库BarcodeLib生成的一维码Code128
我们是做HIS系统开发的,前段时间发现某些处方的一维码出现无法识别的情况。看了一下一维码生成的逻辑,使用到了BarcodeLib库,经过反复确认,我们程序是没有问题的。后面不得不反编译看一下BarcodeLib生成一维码的逻辑。最后调整一维…...
)
软考 系统架构设计师系列知识点之系统架构评估(6)
接前一篇文章:软考 系统架构设计师系列知识点之系统架构评估(5) 所属章节: 第8章. 系统质量属性与架构评估 第2节. 系统架构评估 8.2.1 系统架构评估中的重要概念 相关试题 3. 正确识别风险点、非风险点、敏感点和权衡点是进行软…...

指挥通信车360度3d虚拟互动展示系统的优势及特点
通信车是装有通信装备,用于保障通信联络的专用车辆,用于偏僻/特殊环境下的机动通信。并且机动通信局装备通常分为应急综合通信车、网络管理车、程控电话车、自适应跳频电台车、数字扩频接力车、散射通信车、卫星通信车、光缆引接车、线缆收放车和通信电源…...

根据Aurora发送时序,造Aurora 发送数据包
首先Aurora采用AXIS接口 由于后续需要进行AXIS接口 不同时钟域的数据位宽转换(64bit和256bit之间的转换),因此分两次走。 第一种方法:采用AXIS数据位宽转换IP AXIS跨时钟域IP 第二种方法:逻辑完成 下面记录逻辑…...

vue实现一个账号在同一时间只有一个能登录的效果
目录 1.实现方法 2.实现示例 1.实现方法 要实现一个账号在同一时间只有一个能登录的效果,你可以使用以下步骤来实现: 在后端服务器端设置一个标志位,用于标记用户是否已登录。这个标志位可以存储在数据库中或者缓存在服务器内存中。当用户…...
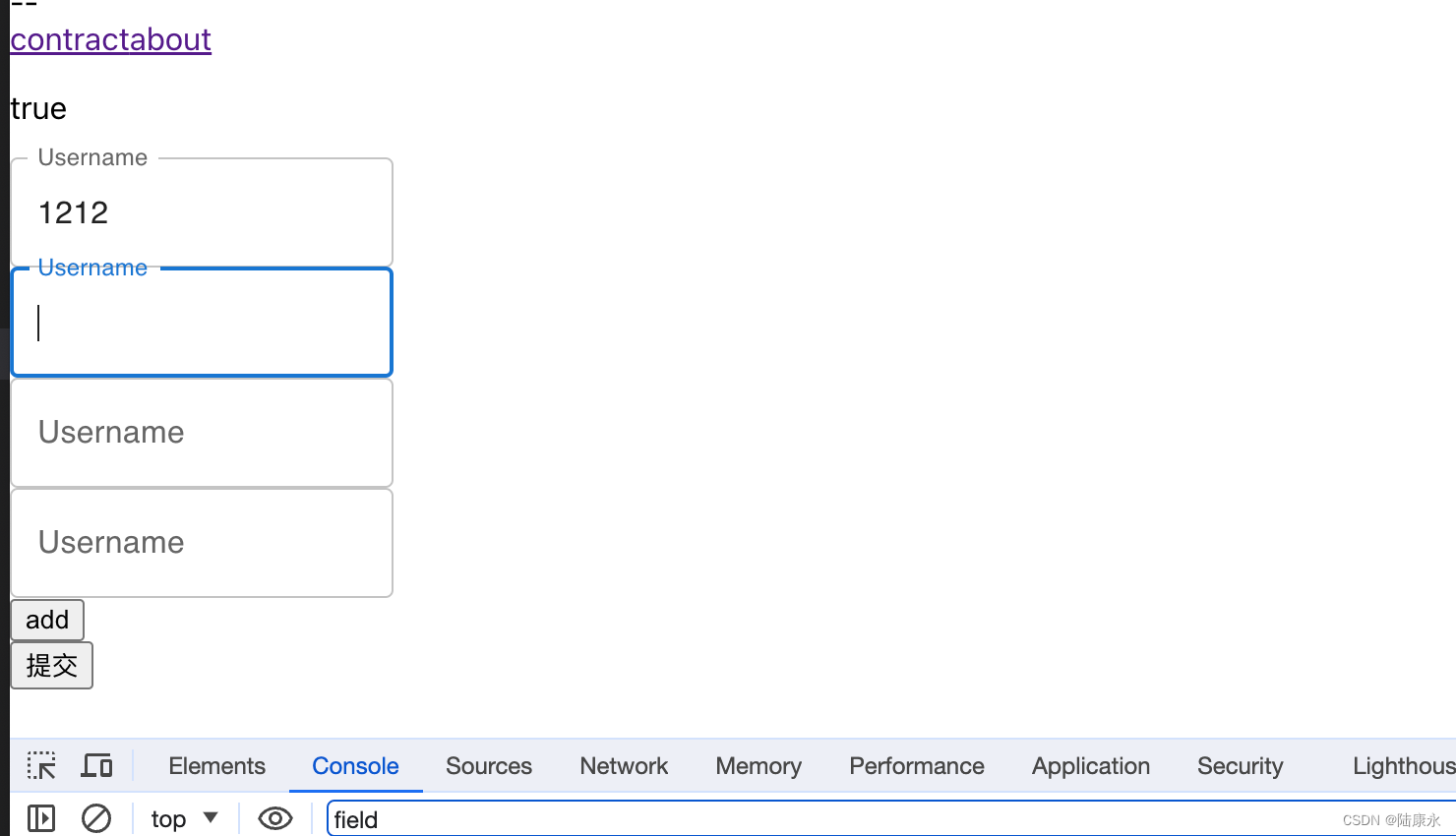
react-hook-form。 useFieldArray Controller 必填,报错自动获取较多疑问记录
背景 动态多个数据Controller包裹时候,原生html标签input可以add时候自动获取焦点,聚焦到最近不符合要求的元素上面 matiral的TextField同样可以可是x-date-pickers/DatePicker不可以❌ 是什么原因呢,内部提供foucs??属…...

最近收藏的各类好用API接口,含免费次数
IP应用场景- IPv4:IPv4应用场景是获取IP场景属性的在线调用接口,具备识别IP真人度,提升风控和反欺诈等业务能力。IP应用场景基于地理和网络特征的IP场景划分技术,将IP划分为含数据中心、交换中心、家庭宽带、CDN、云网络等共计18类…...

第01章 Linux下MySQL的安装与使用
第01章 Linux下MySQL的安装与使用 1. 安装前说明 1.1 查看是否安装过MySQL 如果你是用rpm安装, 检查一下RPM PACKAGE: rpm -qa | grep -i mysql # -i 忽略大小写检查mysql service: systemctl status mysqld.service1.2 MySQL的卸载 1. 关闭 mysql…...
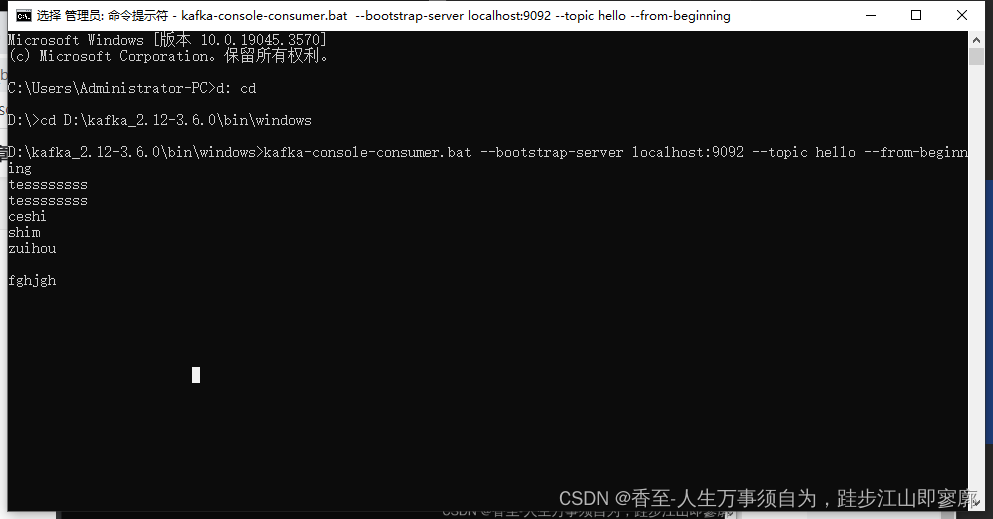
kafka入门教程,介绍全面
1、官网下载最新版本的kafka,里面已经集成zookeeper。直接解压到D盘 2、配置文件修改,config目录下面的zookeeper.properties. 设置zookeeper数据目录 dataDirD:/kafka_2.12-3.6.0/tmp/zookeeper 3、修改kafka的配置文件server.properties. 主要修…...
万字解析设计模式之原型模式与建造者模式
一、原型模式 1.1概述 原型模式是一种创建型设计模式,其目的是使用已有对象作为原型来创建新的对象。原型模式的核心是克隆,即通过复制已有对象来创建新对象,而不是通过创建新对象的过程中独立地分配和初始化所有需要的资源。这种方式可以节…...

深度学习数据集大合集—疾病、植物、汽车等
最近又收集了一大批深度学习数据集,今天分享给大家!废话不多说,直接上数据! 1、招聘欺诈数据集 招聘欺诈数据集:共收集了 200,000 条数据,来自三个网站。 该数据集共收集了 200.000 条数据,分别…...

物联网中的ESP8266该这么用!
🙌秋名山码民的主页 😂oi退役选手,Java、大数据、单片机、IoT均有所涉猎,热爱技术,技术无罪 🎉欢迎关注🔎点赞👍收藏⭐️留言📝 获取源码,添加WX 目录 1. 前言…...

Mac NTFS读写终极指南:Free NTFS for Mac完整解决方案
Mac NTFS读写终极指南:Free NTFS for Mac完整解决方案 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management fo…...

全球首创 XR+AGV 融合技术,超元力 XR 黑暗乘骑无轨AGV开启星际探险新纪元
传统黑暗乘骑项目长期受困于"被动观影"模式:游客坐在固定轨道车上观看预设影片,缺乏互动性,复购率低。广东超元力文化科技有限公司推出的全球首创 XR 黑暗乘骑无轨 AGV 产品,以 XRAGV 融合技术为核心,将被动…...

Gemini3.1Pro如何使用代码教程
概要Gemini 3.1 Pro是Google DeepMind于2026年2月推出的旗舰级多模态大语言模型。ARC-AGI-2得分77.1%,SWE-Bench Verified 80.6%,GPQA Diamond 94.3%,在推理能力和代码生成上相比前代有明显提升。本文面向开发者,从零开始讲解Gemi…...

keil5下载配置Samsung固件包
我们要找的是非常经典的 S3C2440、S3C6410 或 S3C44B0X,这些属于早期的 ARM7 / ARM9 / ARM11 架构,它们使用的是旧版的数据库管理方式。直接访问这个网址:www.keil.com/mdk5/legacy网页往下拉,找到 ARM7, ARM9 & Cortex-R 这一…...

Perforce 2025.2 REST API 技术预览版发布:开启“无客户端”运维新时代
Perforce 2025.2 REST API 技术预览版发布:开启“无客户端”运维新时代 在上一期“ Perforce on Tour 游戏研发效能进阶沙龙”回顾文章中,我们分享了Perforce 资深技术工程师 Kory Luo关于P4 MCP(Model Context Protocol)服务器的…...

向量化映射框架优化图着色问题的FPGA实现
1. 问题背景与核心挑战图着色问题作为组合优化领域的经典NP难问题,在集成电路布局分解、寄存器分配、逻辑最小化等场景中具有广泛应用。传统Ising机采用独热编码(one-hot encoding)方案,将每个节点的q种颜色状态映射为q个物理比特…...

Motrix Next v3.8.10 | 开源多线程下载管理器神器
Motrix Next v3.8.10是一款全新重构升级的开源多线程下载管理器,老牌原版 Motrix 早已停止更新,老旧架构存在诸多安全漏洞与性能缺陷。而 Motrix Next 基于 Tauri 2Vue3 全新重构开发,补齐了原版技术短板,软件全程纯净无任何广告加…...

为什么我看不到我的图库中的照片?修复并恢复图片
照片在我们生活中占据着特殊的地位,它们帮助我们重温珍贵的回忆,并与远近的亲人保持联系。照片就像一扇通往我们最珍贵时刻的私人窗口,因此,当它们突然从相册应用中消失时,会格外令人沮丧。如果你曾经疑惑过“为什么我…...

OpenAI 与 Anthropic 财务大比拼:一家亏损求上市,一家盈利逆袭在望!
57亿 vs 48亿5月中旬,两家AI巨头同时亮出底牌,OpenAI秘密提交IPO申请,Anthropic拿出首个盈利季度财务预测。OpenAI第一季度营收57亿美元,每赚1美元亏1.22美元;Anthropic同期营收48亿美元,落后近10亿&#x…...

如何让微信聊天记录成为你的数字记忆银行?WeChatMsg完全指南
如何让微信聊天记录成为你的数字记忆银行?WeChatMsg完全指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we…...